模态×空间×时间:一篇119页综述定义了世界模型该长什么样
亮点
- • 提出"三重一致性"(Trinity of Consistency)框架:模态一致性是语义接口,空间一致性是几何基础,时间一致性是因果引擎,三者缺一不可。
- • 系统梳理了从专用模块到统一架构的演化路径,覆盖CLIP、NeRF、3DGS、DiT、Flow Matching等核心技术栈。
- • 发布CoW-Bench基准,18个子任务、约1485个样本,首次在统一协议下同时评测视频生成模型和统一多模态模型。
- • 实测19个主流模型(GPT-image-1.5、Sora、Kling、Emu3.5等),发现当前最强模型在跨维度一致性任务上仍有显著短板——"看起来对"和"真正满足约束"之间存在结构性鸿沟。
- • 论文119页、50张图,24位作者来自上海AI Lab、中科院、西湖大学、NUS等机构。
一、视频生成≠世界模型
Sora发布后,"世界模型"成了AI圈的高频词。但一个能生成逼真视频的模型,就是世界模型吗?
这篇综述给出了明确的否定。作者的论点很直接:当前的视频生成模型,无论画面多逼真,本质上仍然是"纹理合成器",而非世界模拟器。它们学到的是像素统计规律,不是物理原理。
刚体悬浮、流体动量不守恒、弹性系数随手势漂移——这些都是"朴素物理学家"的典型表现。模型在模仿像素分布,没有内化物理法则。
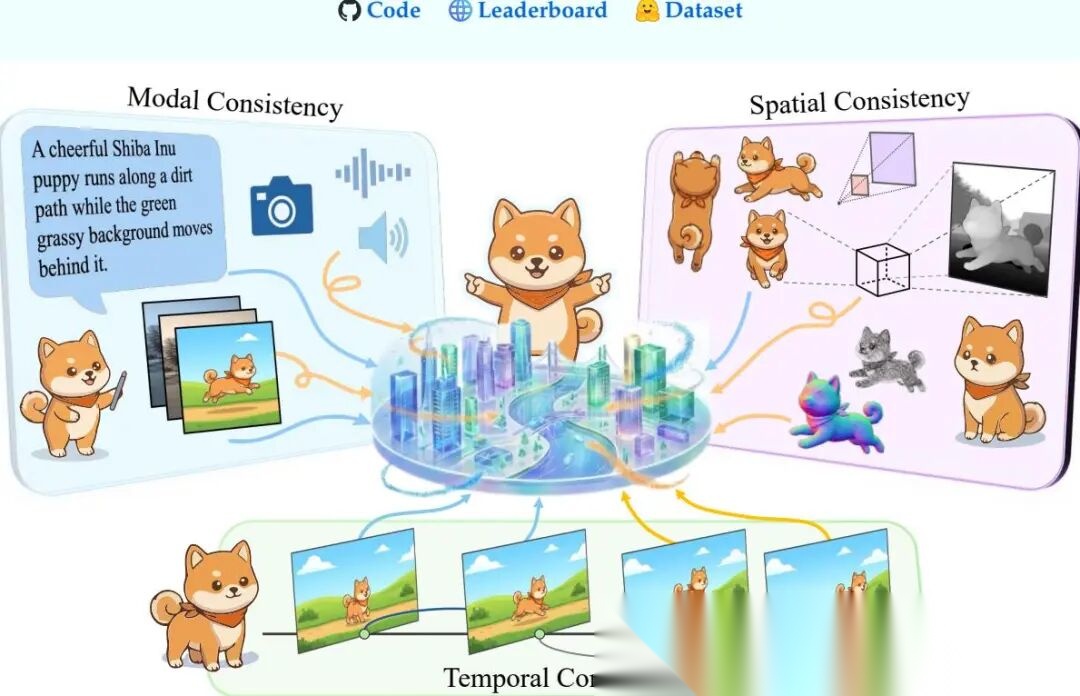
为了回答"什么才算世界模型",作者提出了三重一致性(Trinity of Consistency)框架:
- • 模态一致性(Modal Consistency):语义接口。把文本、图像、触觉等异构信息对齐到统一语义空间。
- • 空间一致性(Spatial Consistency):几何基础。构建尊重几何、遮挡和物体恒常性的3D感知表示。
- • 时间一致性(Temporal Consistency):因果引擎。确保动态演化遵循物理法则和因果逻辑。
三者正交但协同,只有同时满足,才称得上通用世界模型。
二、模态一致性:从对齐到推理
2.1 柏拉图洞穴与模态鸿沟
模态一致性的核心挑战是异构模态的语义对齐。论文从两个理论假说出发。
柏拉图表示假说认为,现实世界存在一个客观的潜在物理状态空间 ,图像和文本只是这个高维实体在不同低维子空间上的投影。模态一致性本质上是求解联合逆投影问题——从观测到的"影子"重建共享潜变量。但这是个病态问题:视觉投影保留了大量高频物理熵,文本投影高度抽象为离散符号逻辑。这种熵不对称性是直接对齐的首要障碍。
超球面假说是CLIP等范式的数学基础,强制特征向量均匀分布在单位超球面上。但Liang等人的实证研究揭示了锥效应(cone effect):联合优化导致视觉和文本嵌入坍缩到两个狭窄且分离的锥形区域,破坏了特征空间的各向同性。
从流形学习角度看,这个gap指向更深层的拓扑不匹配:视觉数据分布在连续稠密的低维流形上,语言数据呈现稀疏离散的聚类结构。内在维度和数据密度的根本差异导致流形不同构,完美等距对齐本身就是病态的。
2.2 两条生成路径:离散AR vs. 连续Flow Matching
学术界探索了两条路径来建模条件概率密度 。
离散自回归(AR):以Token为中心,通过VQ-GAN将连续图像量化为离散符号,再用Transformer因果注意力掩码最大化序列对数似然。接口统一是优势,但有两个内生缺陷——码本维度增加时有效利用率指数衰减(Dirichlet过程的维度灾难);误差累积,自回归生成本质是递归算子应用,初始量化误差经T步后累积漂移为 ,指数增长。这也解释了AR模型在长序列尾部经常出现结构坍塌。
连续Flow Matching(FM):回到连续潜空间,用ODE视角构建连接噪声和数据的确定性传输路径。核心是直接拟合概率流的速度场,中间状态定义为数据与噪声的线性插值。Rectified Flow证明Reflow操作将传输轨迹矫直,对应Lipschitz常数 ,误差累积变为线性增长 。FM在极少步数内就能生成高保真样本,同时保留潜空间的连续语义流形。
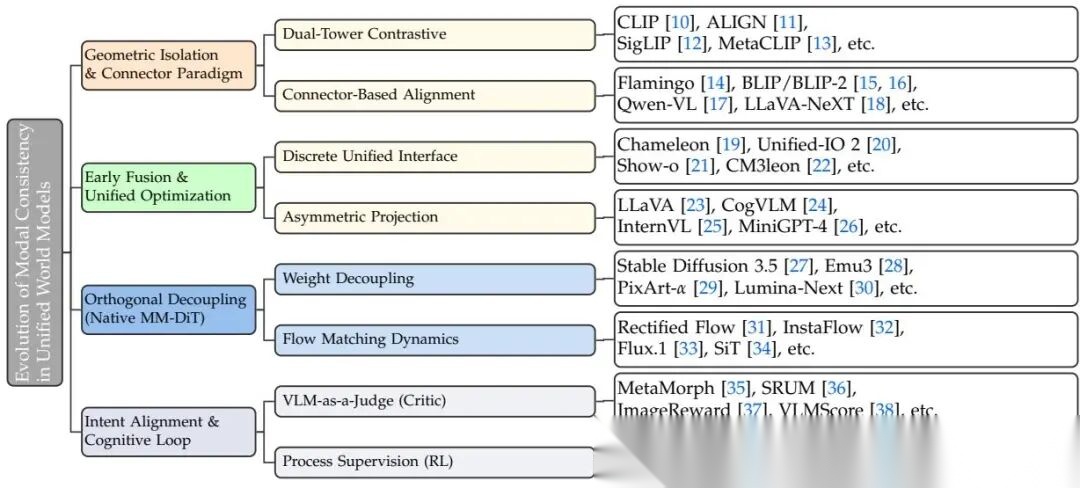
2.3 架构演化:从几何隔离到正交解耦
多模态架构的演化经历了三个阶段。
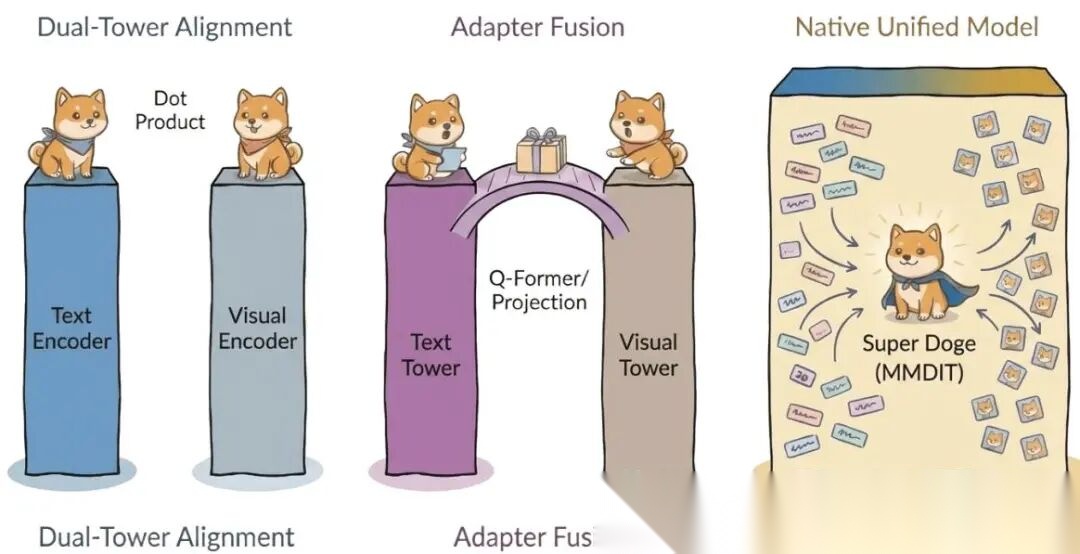
双塔架构(CLIP、ALIGN):对比学习将异构模态投射到共享超球面。检索任务表现好,但独立编码器导致几何拓扑天然不对称,缺乏深层细粒度交互。
连接器范式(Flamingo、BLIP-2):冻结预训练视觉编码器,引入可学习桥接模块(Perceiver Resampler或Q-Former)对齐视觉特征与LLM语义空间。训练成本低,建立了后续LMM的标准架构模板。
正交解耦(MM-DiT):当前主流。SD3.5和Emu3为代表,核心是权重解耦——文本和图像维持独立权重集 ,仅在注意力操作时交换数据。这迫使联合损失函数的Hessian矩阵呈现近似块对角结构,有效隔离模态特定曲率,梯度冲突率从AR范式的50%以上降至约30%。
2.4 意图对齐与测试时计算
传统MLE捕获像素统计相关性,缺乏显式监督时容易语义漂移。学术界引入RLHF,将对齐重构为超球面流形上的奖励引导搜索。
几个值得关注的进展:SPO和VisualPRM引入逐步评估机制,对去噪路径的每个推理步做细粒度监督;PhyGDPO引入物理感知VLM反馈,通过惩罚物理违规项处理重力违反等非物理现象。
更前沿的方向是测试时计算(test-time compute)。这个范式承认单次逆投影的局限性,在推理阶段引入显式状态空间搜索。UniGen和EvoSearch结合蒙特卡洛树搜索与验证器机制,在生成过程中实现推理时缩放。
三、空间一致性:从2D代理到3D原语
3.1 几何分解
空间一致性的核心使命是将语义潜变量锚定到符合物理法则的三维几何流形 上。论文将其分解为两层拓扑约束:
- • 微观层面:局部邻域拓扑一致性,对应Lipschitz条件。流形上任意两个相邻点的物理属性差异严格受其欧氏距离线性约束。
- • 宏观层面:全局几何一致性,即多视图几何中的对极等变性。不同视角观察同一物体时,投影坐标必须满足 。违反这个约束就是Janus问题的根源。
3.2 三大物理法则
论文将空间一致性形式化为在时空流形上求解一组耦合微分方程逆问题。
辐射传输方程(RTE):显式和隐式3D表示都可以物理地视为RTE的离散化解。NeRF通过体渲染积分逼近解,3DGS将连续场离散化为拉格朗日高斯基函数集,将积分转化为高效的解析光栅化。前者保证连续性,后者实现实时性。
随机微分方程(SDE):在生成先验范式中,空间一致性源于预训练模型的概率分布。从高斯白噪声恢复到数据流形的过程建模为SDE。扩散项为0时退化为确定性ODE,即Flow Matching。
拉格朗日输运:确保空间结构沿时间轴的拓扑一致性,物质点运动必须遵循拉格朗日流,物质导数为0。这直接对应显式原语范式中的粒子追踪机制。
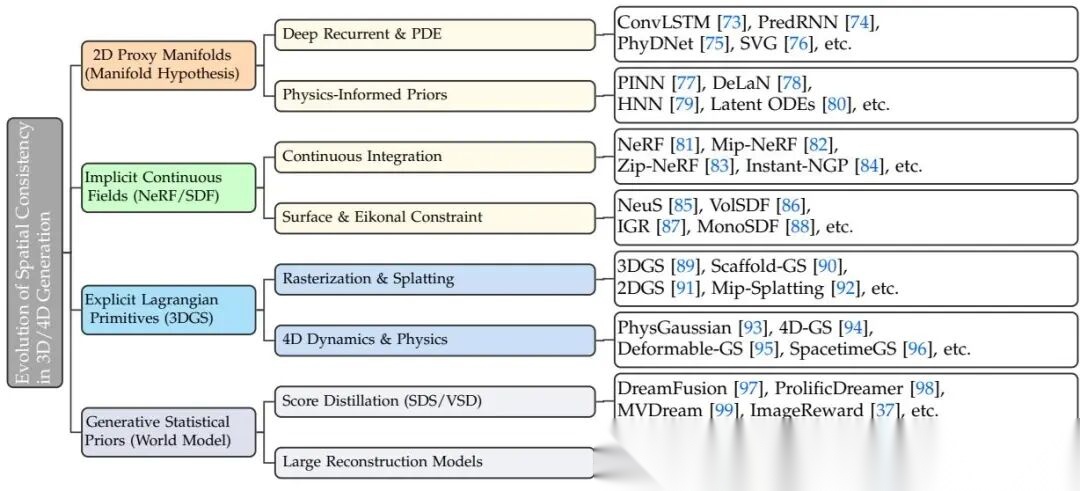
3.3 演化路径
2D代理流形:早期方法(ConvLSTM、PredRNN)在2D图像流形上拟合动力学,但卷积操作只具有平移等变性,无法感知3D旋转群SO(3)。大视角变换时不可避免地产生非物理的非刚性畸变。PhyDNet尝试将隐状态解纠缠为物理动力学分支和残差纹理分支,但2D流形建模遇到遮挡导致的深度突变时,光流场变得不可微,PDE约束立即失效。
隐式连续场(NeRF):直接在3D欧氏空间中定义状态场。用MLP参数化场景为连续坐标映射,通过可微体渲染积分连接3D场与2D观测。Instant-NGP引入多分辨率哈希网格,EG3D提出三平面表示。Mip-NeRF从信号处理角度纠正了混叠缺陷,引入锥追踪和集成位置编码。NeuS和VolSDF将表示从密度场转换为符号距离场(SDF),通过Eikonal正则化确保物理有效性。
显式拉格朗日原语(3DGS):将场景离散化为各向异性高斯原语集合,通过可微光栅化重建投影算子。核心优势在于前向推送的梯度流绕过MLP直接稀疏反传到几何参数,自适应密度控制动态调整粒子密度。4D动力学演化有三条路径:拉格朗日粒子追踪(PhysGaussian)、欧拉张量分解(4D-GS)、规范变形(Deformable-GS)。
生成统计先验:开放世界生成任务中,观测条件极度稀疏,问题退化为病态。SDS(Score Distillation Sampling)通过计算预训练扩散模型的得分函数获取梯度;VSD引入变分分布最小化KL散度,恢复高频纹理细节。MVDream修改U-Net架构,把空间自注意力升级为3D对应注意力,实现软几何一致性。
四、时间一致性:从帧插值到因果推理
4.1 评估演化
传统FVD主要表征空间特征分布的相似性,检测时间高频闪烁和非物理变形时能力有限。VCD(Video Consistency Distance)在时间频谱中测量生成视频与自然视频的特征差异,通过短时傅里叶变换捕捉高频能量波动。
论文给出了跨代模型的经验数据(表3):从时间膨胀(AnimateDiff)到离散AR(VideoPoet),再到原生DiT(HunyuanVideo),最后到世界模型先验(Veo 3),在时间一致性、物理合规性、因果推理和频率保真度上呈现清晰的进步轨迹。Veo 3在零样本物理交互任务上的成功率超过70%,标志着视频生成开始从纯视觉模拟向逻辑推演过渡。
4.2 时间膨胀范式
Tune-A-Video和AnimateDiff建立了"空间冻结、时间插入"的范式——冻结2D U-Net的空间卷积层,仅在层间插入可学习的1D时间注意力模块。从概率图角度看,这本质上将视频生成的联合分布简化为一阶马尔可夫链,ELBO的松弛忽略了高阶依赖,长序列中KL散度项显著增加。实践中表现为语义漂移:生成帧数超过16时,初始帧的身份特征逐渐被噪声稀释。
Text2Video-Zero和FateZero采用零样本注意力注入,强制后续帧复用首帧的Key/Value特征矩阵。但物体运动幅度超过屏幕宽度20%时,强制特征注入就产生明显的涂抹伪影。
这个范式的理论边界很清楚:核心空间卷积层被冻结,模型本质上只是在静态图像上做微小弹性变形,不是生成真正的时间动力学。
4.3 离散自回归建模
VideoPoet、CogVideo和W.A.L.T借鉴LLM的缩放定律,建立两阶段自回归生成范式。MagViT-v2引入非对称时间填充和因果3D卷积,严格限制卷积核的感受野在当前帧及之前时刻。
误差累积是核心挑战。训练时的Teacher Forcing与推理时自回归生成之间的分布偏移(Exposure Bias)导致微小帧间预测误差随时间步指数放大。VAR提出Next-Scale Prediction,将推理步数从线性 降至对数 。FramePack引入帧上下文打包和双向反漂移采样。
离散化操作 不可微,高维视频空间中STE的梯度方差容易触发码本坍塌。这推动了技术焦点向连续潜空间转移。
4.4 原生时空DiT
Sora和HunyuanVideo为代表,彻底回到连续潜空间,采用DiT架构。原生3D DiT将视频视为3D Patch序列,通过3D-RoPE计算全序列联合注意力,捕获非局部物理交互。
基于Flow Matching的生成过程在数学上对应流形上的微分同胚,模型从高斯噪声平滑恢复细微纹理细节,消除离散化导致的边缘闪烁。
计算效率方面有几个有意思的工作:Video-TTT引入测试时训练,将历史上下文压缩到神经网络权重中,保持 线性复杂度的同时实现长视频记忆保持;Pyramid Flow利用时空冗余,层次解耦策略降低5-10倍计算成本;TeaCache利用扩散模型相邻时间步特征输出的极高相似性(Pearson相关>0.98),引入无训练动态缓存,实现2-3倍加速。
4.5 逻辑一致性与因果推理
DiT解决了视觉连续性,但长程物理逻辑(如因果不可逆性)仍是难点。学术界开始从纯拟合转向认知推理:
多模态感知中的图像-文本交织推理:Mini-O3和VisCoT在推理过程中生成或检索图像来辅助逻辑跳跃。UV-CoT探索无监督条件下的图像-文本思维对齐。
生成视频中的时间链推理:Video-CoT和Video Espresso引入Chain-of-Frame范式,将视频生成分解为关键帧规划和中间帧合成——先在潜空间中显式推演未来关键状态,确定因果节点后再生成视觉过程。Think Sound把因果性扩展到听觉模态,通过音频线索约束视频的物理演化。
五、多维一致性的融合
论文第三章是全文最核心的部分,详细分析了三种一致性两两融合的技术路径。
5.1 模态×空间:语义到几何的绑定
四条并行路径。
像素空间操作:锚定数据分布,用规模换几何先验。指令驱动的图像编辑建立了梯度解耦与注意力注入的混合范式——冻结预训练基座只微调旁路网络,注意力图作为几何硬门控注入编辑步骤。通用图像生成从基于CLIP的外部对齐转向端到端交织建模,DreamLLM和Emu直接在原始图像-文本序列上联合建模。
视图空间映射:将3D几何信息作为结构化条件变量注入预训练扩散模型。Zero-1-to-3和ControlNet建立了"冻结骨干+旁路控制"的设计。MVDream和SyncDreamer把对极几何约束转化为注意力掩码,强制不同视图的token只与几何对应的对极线区域交互。
体空间表示:直接面对物体的三维本质。DreamFusion建立了SDS的基础公式——优化参数化3D场使任意视角渲染位于2D扩散模型的低能量区域。See3D和V3D利用视频扩散模型作多视图生成器,核心假设是"时间相关性≅空间一致性"。
强化学习对齐:DDPO将扩散去噪建模为MDP,引入开放词汇检测器计算IoU奖励。R-DPO提出空间掩码下的子流形优化,确保特定模态属性只反传到特定空间区域。Layout-CoT借鉴LLM推理范式,把生成过程分解为"规划→对齐→生成"的显式链。
5.2 模态×时间:从冻结时刻到连续推演
四个渐进式技术范式。
端到端可扩展建模:扩散模型方面,Flow Matching取代DDPM成为SOTA框架,Rectified Flow强制潜变量沿线性轨迹演化,显著降低传输曲率。因果时空压缩方面,现代编码器引入因果3D VAE,确保潜码 的生成只依赖历史帧。自回归方面,VideoPoet和MagViT-v2通过Lookup-Free Quantization和因果3D卷积实现突破。AR-Diffusion混合模型构建"因果逻辑+高质量生成"的联合概率密度。
显式结构化控制:将高维动力学流形投射到低维可解释控制流形(深度、光流、骨架)。VideoComposer提出运动向量的显式编码,DragNUWA和MotionCtrl引入轨迹热图与相机位姿联合编码。Animate Anyone和MagicAnimate引入独立ReferenceNet作为"外观流",实现外观-运动正交解耦。
统一理解与生成共生架构:打破感知与生成的壁垒。Gaia-1和Phenaki将视频编码、控制信号和文本描述统一为离散token序列,训练目标统一为Next-Token Prediction。Show-O利用混合注意力,在单个Transformer权重中实现理解与生成的无缝共存。
强化学习驱动对齐:VideoDPO指出直接应用图像级DPO会导致"运动坍塌"。T2V-Turbo融合HPSv2(模态美学)和InternVideo2(时间一致性)的奖励信号。VideoScore基于Video-LMM构建通用自动评估指标,捕获深层时间因果逻辑。
5.3 空间×时间:从帧绘制到世界构建
四阶段演化。
隐式时空学习:视频先验蒸馏利用Tweedie公式,将去噪步建模为两个异构梯度场的线性组合,强制潜变量收敛到两个先验分布的重叠高密度区域。VIVID-1-to-3将新视角合成同构为"相机沿轨迹运动的视频生成"。VividZoo提出时变调制——早期去噪阶段赋予MVD更高梯度权重建立主拓扑,后期反转权重利用VDM的时间平滑特性消除高频闪烁。
显式几何锚定:引入点云和相机轨迹作为刚性骨架。Gen-3C利用单目深度估计反投影构建3D缓存,将时间维度演化转化为静态点云中的相机漫游。ViewCrafter用密集立体匹配重建高精度点云,把一致性的来源从网络权重的黑箱统计转移到输入侧的白箱几何。
统一时空表示:4D高斯原语或混合张量场,建立原生支持变形和光照的连续数学场。K-Planes和HexPlane将4D空间的特征查询转化为六个2D平面上的特征插值和Hadamard积,空间复杂度从 降至 。DynIBaR通过基于轨迹的渲染将时间维度集成到体渲染方程中。
强化学习对齐:T2V-Turbo-v2设计空间和时间解耦的混合奖励机制。VistaDPO提出细粒度分层对齐框架,将优化目标分解为实例级、时间级和感知级三个正交维度。InstructVideo显式引入闪烁惩罚和光流一致性作为代价函数。
六、世界模型的初步涌现
6.1 Sora:范式确立
Sora不依赖显式3D归纳偏置,而是通过大规模时空patch训练,验证了Scaling Law在视频生成中可以触发能力涌现。在潜空间中将视频压缩为时空patch后,模型以类似语言token的方式处理高维视觉数据。即使没有显式几何约束,Sora在复杂相机运动中保持了空间结构的透视恒常性,展现出符合时间因果性的物理交互。
Open-Sora复制并验证了Video DiT的核心逻辑:交替计算空间和时间注意力,在降低计算复杂度的同时平衡单帧空间保真度和跨帧时间连贯性。
6.2 从被动观察到主动交互
Genie 1/2/3、LingBot-World和GameNGen标志着三重一致性从被动观察到主动交互的跃迁。核心突破在于将动作算子 显式引入时空生成逻辑,把概率建模从 转化为受控状态转移 。
这些可编程世界证明了三重一致性的协同可以演化为可微分、可预测、可交互的World API,为具身智能体提供接近真实的心理沙盒环境。
七、挑战与展望
论文识别了四个核心挑战。
物理真实性的不可微性。 现有模型以像素级或token级似然最大化为最高目标,生成结果陷在视觉合理性的陷阱里。怎么将哈密顿量、守恒定律或微分方程嵌入损失函数作为软约束甚至可微算子,是摆在面前的硬问题。
长程因果链的蝴蝶效应。 当前时空注意力只能维持数十秒的短程记忆。可能的出路是分层隐式动力学:宏观层通过符号叙事或场景图维持抽象因果性,中观层用稀疏4D表示压缩事件节点,微观层用高维注意力补全纹理细节。
可控性与交互性。 从提示词升级到API,意味着用户不再是被动描述者,而是主动的世界编辑器。用户应能在任意时空坐标插入力、修改材料、重置边界条件,并获得符合物理法则的实时反馈。
智能体演化与数字生态。 世界模型的最终形态不应止步于物理沙盒,而应容纳自主智能体的演化和博弈。多智能体博弈要求模型从建模物理因果性升级到建模社会因果性。
八、CoW-Bench:一致性评测基准
8.1 现有评测的四个困境
-
- 裁判幻觉:过度依赖MLLM(如GPT-4o)作裁判,VLM本身对细粒度物理属性的感知精度很低,缺乏基于仿真引擎真值的硬验证。
-
- 分布内记忆:现有数据集多来自真实世界视频,大模型容易死记硬背训练数据,掩盖了OOD泛化短板。
-
- 过程验证缺失:绝大多数基准只测短序列(<10s),掩盖了长程模拟中的状态漂移问题。
-
- 缺乏因果探针:现有评测在静态旁观者模式下运行,无法验证模型是否构建了结构化因果图。
8.2 任务体系
CoW-Bench围绕三重一致性及其两两融合,共6个任务类别、18个子任务,约1485个样本。每个子任务配备5个人工检查清单。
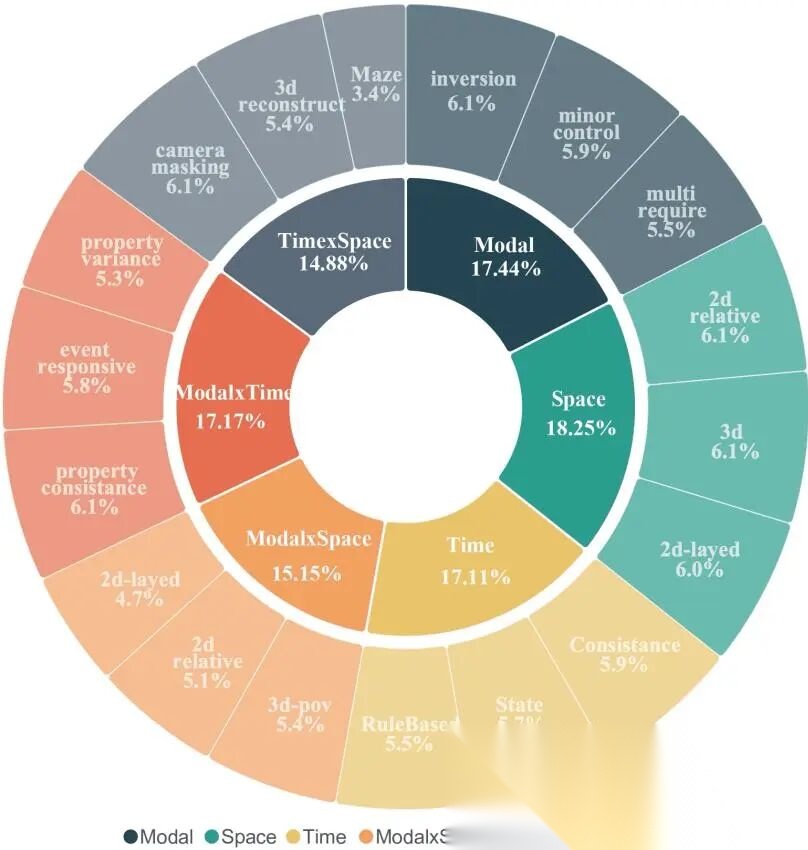
单一致性维度:
- • 模态:风格/材料迁移、细粒度控制、多约束组合
- • 空间:平面布局、层次遮挡、多视图3D结构
- • 时间:世界线持久性、规则引导演化、有序阶段转换
交叉一致性维度:
- • 模态×空间:语义平面绑定、语义层次控制、语义3D视图一致性
- • 模态×时间:长程锚定、属性动态对齐、触发事件合规
- • 时间×空间:平面迷宫轨迹、遮挡动力学、3D环路导航一致性
评估采用原子分解策略,定义了16个原子检查(A1-A16),每个对应特定失败机制(如身份漂移、属性重绑定、边界泄漏、世界线漂移、遮挡矛盾等)。评分用0-2序数量表,减少连续评分的主观噪声。
8.3 主要结果
CoW-Bench测试了19个主流模型,按AVG排序前10:
| 排名 | 模型 | AVG |
|---|---|---|
| 1 | GPT-image-1.5 | 85.62 |
| 2 | Nano Banana Pro | 82.57 |
| 3 | GPT-image-1 | 80.35 |
| 4 | Nano Banana | 78.38 |
| 5 | Emu3.5 | 77.76 |
| 6 | Kling | 73.96 |
| 7 | Seedream-4-5 | 73.82 |
| 8 | Sora | 73.66 |
| 9 | Seedream-4-0 | 71.33 |
| 10 | SkyReels-V2 | 65.37 |
注:榜单数据来自项目页静态数据,截至2026-03-06抓取。
几个关键发现:
时间控制才是瓶颈,连贯性反而不是。 多个视频模型在世界线持久性(T-WL)上得分很高(Sora达到9.32),说明生成视觉连续画面已不是最难的事。但需要规则引导演化或结构化状态推进的任务表现参差不齐。模型可以看起来时间上合理,但仍然违反因果约束。
空间一致性在单视图3D中很强,跨视图锚定仍然崩。 顶级模型在S-3D上得分很高(Nano Banana Pro达到9.61),但TS-Maze-2D等时空设置得分骤降。局部几何合理性比在运动和决策轨迹下维持全局空间锚定容易太多了。
融合任务暴露真正的世界模型差距。 最大的模型差距出现在跨一致性家族(MT、MS、TS)。一些高均分模型在TS-Maze-2D上仍有明显弱点(Nano Banana Pro只有4.46),表明全局世界状态维护和轨迹级约束执行,即使每帧保真度都很好,也远未解决。
开源模型暴露了典型失败模式。 开源视频生成器通常在模态锚定和跨一致性任务上偏弱,要么把罕见约束回退为常见默认值,要么保持了运动但在身份/属性上漂移。
8.4 细粒度分析
模态一致性:身份-属性绑定是最难的模态接口原语。即使顶级闭源图像模型在Id+Attr上也远未饱和(GPT-image-1.5: 1.19/2.0),许多视频生成器坍塌到接近零(HunyuanVideo: 0.01)。约束回退现象普遍——模型将不寻常的约束替换为常见默认值,生成的图像看起来真实,但悄悄放松了指令。
时间一致性:世界线持久性相对较强,但规则遵循演化才是主要瓶颈。许多视频模型在T2的Trend、Time-scale和Inter-state上急剧下降(通常低于0.6),即使Subj-lock很高。模型保持了主体和背景不变,却做不到单调的、正确节奏的过程演化。阶段排序在显式多步结构下仍然脆弱。
空间一致性:平面布局是入门测试,方向锚定仍然脆弱。Dir在所有模型家族中一致是最低的子指标(Sora: 0.64,多个开源模型≤0.5)。多视图3D一致性方面,顶级模型在Struct和Persp/Scale上接近天花板,但较弱的系统在Occ-update和Geo-self上大幅下降——生成一张合理的视图比维持经得起视角变化的持久3D场景假设容易得多。
九、总结
这篇综述通过三重一致性的视角重新审视了生成式AI的发展轨迹。核心信念简洁明确:一致性不是世界模型的可选属性——它是世界模型的存在判据。 一个产出视觉逼真像素但无法维持跨维度一致性的系统,无论规模多大,本质上仍然是纹理合成器。
论文最后描绘了世界模型交互范式的演化光谱(图50):从早期"向量即动作"范式(JEPA,依赖不可解释的潜空间预测),经过"按键即动作"范式(Genie系列,受限于预定义的离散控制空间),最终走向"提示即动作"——配备内部语义编译器的统一多模态模型,能够将自然语言提示翻译为遵循三重一致性的通用时空模拟。

三重一致性勾勒的不只是分析框架,更是一条边界——在生成"像世界的图像"和构建"理解世界的模型"之间的分水岭。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)