基于大模型、SKills 的知识管理
今天不聊新工具,聊点更高级的东西——三个巨佬的知识管理哲学
还有我自己的知识管理及内容生成工作流
Karpathy
昨天 Andrej Karpathy(斯坦福 PhD、OpenAI 创始成员、前特斯拉 AI 总监、CS231n(全球最火深度学习课程)缔造者)发了条长推,炸了整个 AI 圈子。

这条推文的核心观点是:他现在把大部分 token 预算花在了"操作知识"上,而不是"操作代码"。
什么意思?
他搭了一套 LLM 驱动的个人知识库系统,用 Obsidian 做前端,Markdown 做底层格式,LLM 负责一切脏活累活。
整个系统的架构可以拆成五个模块:
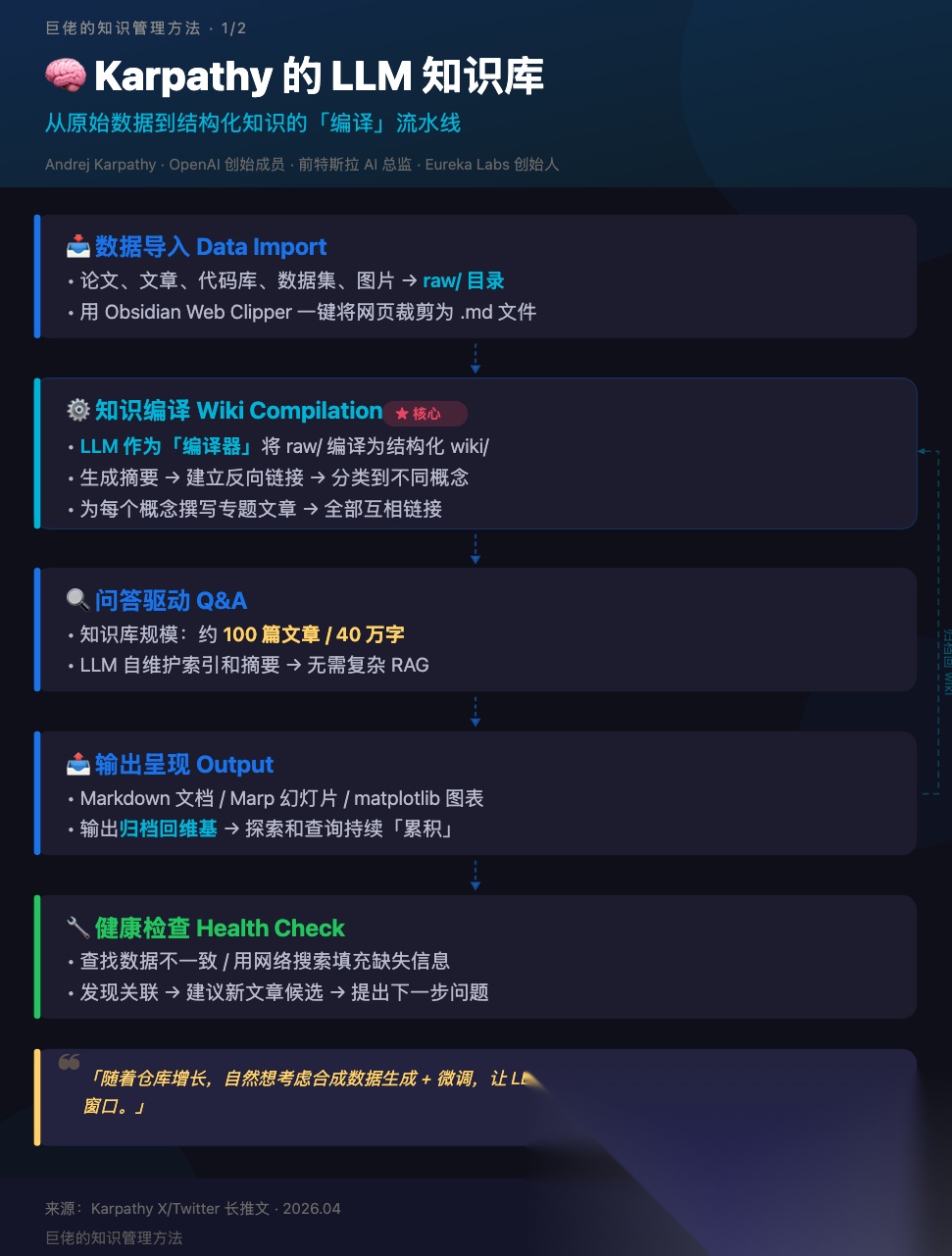
🧠 Karpathy 知识库系统:五大模块
1. 数据导入(Data Import)
把各种原始素材——论文、文章、代码库、数据集、图片——统统丢进 raw/ 目录。
用 Obsidian Web Clipper 浏览器插件一键裁剪网页文章为 .md 文件,配合快捷键把相关图片下载到本地。
核心思路:先不管三七二十一,把所有原始材料攒在一起。
2. 知识编译(Wiki Compilation)
这是整个系统最核心的一步——让 LLM 把 raw/ 目录里的散碎材料"编译"成一个结构化的维基。
具体做什么?
- 为每份原始数据生成摘要
- 建立反向链接(backlinks)
- 将数据分类到不同的概念
- 为每个概念撰写专题文章
- 将所有文章互相链接
注意这个词:编译(compile)
Karpathy 用的是编程的隐喻——原始数据是"源码",维基是"编译产物",LLM 就是那个"编译器"
3. 问答驱动(Q&A)
当维基长到足够大(他举例说他某个研究方向的维基有约 100 篇文章、40 万字),就可以开始向 LLM Agent 提各种复杂问题了。
一个关键的发现:他本以为需要搞复杂的 RAG,但实际上 LLM 自己维护的索引文件和摘要就够用了。
在这个规模下,Agent 可以比较轻松地读取所有重要的相关数据。
这点我必须插一嘴——40 万字对现在的长上下文模型来说真不算什么。
Gemini 的百万 token 窗口,Claude 的 200K 上下文,处理这个量级的知识库绑绑有余。
Karpathy 说不需要 RAG,在这个规模下我同意
4. 输出呈现(Output)
Karpathy 不喜欢在终端里看答案
他更倾向于让 LLM 生成 Markdown 文件、Marp 格式的幻灯片、matplotlib 图表,然后在 Obsidian 里直接查看
更聪明的是:他会把输出"归档"回维基,这样每次探索和查询都会"累积"在知识库里,让它越用越富
5. 健康检查(Health Check)
定期让 LLM 对维基做"体检":
- 查找数据不一致的地方
- 用网络搜索填充缺失信息
- 发现有趣的关联,建议新的文章候选
- 提出下一步要调查的问题
他说 LLM 在"建议进一步的问题"这件事上做得相当好。这不就是我们说的 Agent 自主探索 吗?
用一张流程图来理解 Karpathy 的系统:
Lex Fridman:把知识库变成跑步伙伴
Karpathy 发完推,Lex Fridman 秒回——他也有类似的系统。
Lex 的身份不用多介绍了吧?全球最火的 AI 播客主持人,他的 Lex Fridman Podcast 采访过 Elon Musk、Sam Altman、Mark Zuckerberg、Karpathy 本人,以及一堆你叫得出名字的科技大佬
Lex 的设置和 Karpathy 类似,但有几个独特的点:
前端混合体:Obsidian + Cursor(用来编辑 .md 文件)+ 自己 vibe-coded 的网页终端
Lex 不满足于 Markdown 的静态渲染——他经常让 LLM 生成动态 HTML 页面(带 JavaScript),这样他可以对数据排序、筛选,交互式地调整可视化
做播客的知识管理需求:因为播客嘉宾覆盖的领域极广,Lex 的研究兴趣数量和多样性远超普通人。
这种场景下知识库方法的优势更明显——你不可能把所有领域的知识都记在脑子里。
最炸裂的用法——跑步语音播客:Lex 会让系统为特定主题生成一个临时的迷你知识库,加载进 LLM,然后在 7-10 英里的长跑中开启语音模式。
跑步的时候,它就变成了一个交互式播客——他可以随时提问、听答案、深入探讨。
你品品:一个人一边跑步一边跟 AI 讨论量子力学或者神经科学。
知识的摄入方式从"坐着读"变成了"边跑边聊"
kepano:Obsidian 创始人的"冷水"
然后 Obsidian 的创始人 kepano(Steph Ango)出来说话了
他没有否定 Karpathy 的方法,而是提出了一个很微妙的警告:
“我更喜欢我的个人 Obsidian 仓库具有高信号噪声比,并且所有内容都有已知的来源。”
kepano 的核心观点:你的个人笔记库应该是"你"的思想的体现,而不是 AI 的。
他的建议是:
- 保持个人仓库干净——这是你的思维主场
- **给 Agent 一个单独的"杂乱仓库"**——让 AI 在那里随便折腾
- 只在 Agent 产出有用工件时,才手动搬到主仓库
他担心什么?如果人类写的和 AI 写的混在一起太多:
- 搜索会被 AI 生成内容淹没
- 反向链接不再局限于你真正思考过的内容
- 图谱视图变成 AI 的知识图谱,不再是你的
- 你无法追溯哪些想法是自己的、哪些是机器生成的
这段话的背后是 kepano 一贯的哲学
他写过一篇很有名的文章叫 **“File over app”**(文件优先于应用),核心主张是:
如果你希望你的写作在 2060 年甚至 2160 年的电脑上仍然可读,那它最好在 1960 年代的电脑上也能被读取。
他还写过 **“Don’t delegate understanding”**(不要把理解力外包)——你可以让 AI 帮你干活,但不能让 AI 替你思考
理解力本身就是你最大的资产
在他的个人 Obsidian 实践中,他甚至直接说:
“有人问我能不能用 LLM 自动化笔记整理,但我不想这么做。我享受这个过程。做这种维护工作帮助我理解自己的模式。”

老章的观点
Karpathy 的方法论是天才级别的,Lex 的应用场景让人拍案叫绝,kepano 的警告确实发人深省
他们三个人讲的是知识管理链路上不同的环节
🔥 我在做的事:补上"最后一公里"
Karpathy 搭的是一个知识积累与检索系统——把数据灌进去,编译成知识,然后查询和输出。
但作为一个每周要输出 3-5 篇技术文章、配套口播视频、社交媒体内容的人,我需要的不只是"积累"和"查询",我需要把知识变成内容产品推出去。
这就是我做的事——知识管理的下游:内容生产流水线。
zhangAI/ # Karpathy 说的"知识库"├── 1-Wechat/ # 公众号文章(成品库)│ ├── Archive/ # 已发布文章│ └── ing/ # 正在写的稿子├── .agent/skills/ # 58 个 AI Skill(执行层)│ ├── 1-write_tech_article_pro/ # 技术文章撰写│ ├── 1-title_generator/ # 标题生成(3种风格)│ ├── 1-video-script-converter/ # 文章→口播稿│ ├── 1-doubao-tts-voice-clone/ # 口播稿→克隆语音│ ├── audio-to-video/ # 语音→竖版短视频│ ├── 1-upload-images-to-picgo/ # 图片→个人图床│ ├── design_svg_card/ # 知识卡片设计│ └── ...还有 50 多个├── Video/ # 视频产物│ ├── 口播稿/│ ├── 口播音频/│ └── 成品视频/├── Clippings/ # Karpathy 说的 raw/ 目录├── CLAUDE.md # AI Agent 的"操作手册"├── AGENTS.md # Codex 的上下文配置└── GEMINI.md # Gemini 的指令文件
看出区别了吗?
Karpathy 的系统是 raw/ → wiki/ → query——知识的上游。
我的系统是 素材 → skills/ → 文章 → 视频 → 社交媒体——知识的下游。
它们不是竞争关系,是上下游互补关系
Karpathy 解决的问题是:大量散碎信息怎么变成可查询、可增长的结构化知识? 我解决的问题是:有了知识和选题,怎么高效地变成文章、视频、社交内容?
一篇文章从素材到成品视频,我的 Skill 流水线是这样的:
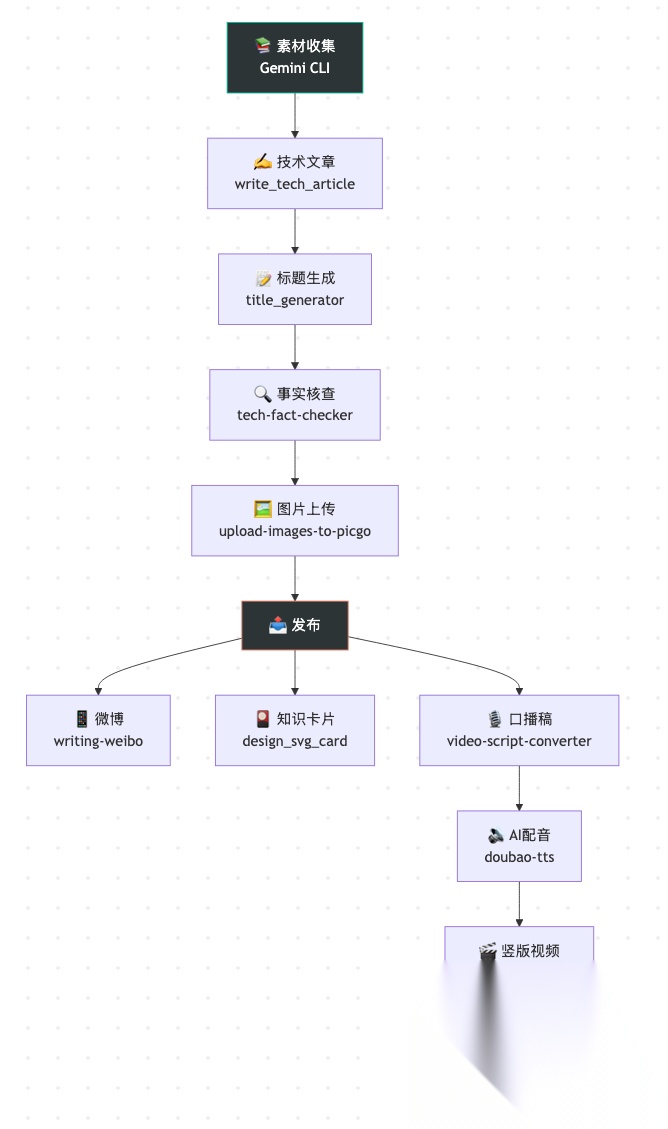
一条命令"帮我写篇技术文章"触发 write_tech_article_pro Skill,输出 Markdown 成品。然后"转成口播稿"触发 video-script-converter,接着"用豆包转成音频"触发 doubao-tts-voice-clone,最后"音频转视频"触发 audio-to-video
从一篇文章到一条短视频,全程约 8 分钟,传统方式需要 2-3 小时。
所以理想的完整架构,应该是把上下游接起来:
Karpathy 的知识编译层(上游:积累、编译、检索) ↓ 老章的内容生产流水线(下游:写作、配音、视频) ↓ 发布 & 多形态分发 ↓ 反馈回知识库(闭环)← 这一步大家都还没完全做好
这也是我接下来要补的课——给自己的系统加上 Karpathy 式的"知识编译层",让过去写的每一篇文章都成为未来创作的养料。
🧊 关于 kepano 的"污染论"
kepano 担心 AI 生成的内容会"污染"个人知识库
他的解决方案是两个仓库——一个干净的给自己,一个脏的给 AI
这个担心是合理的
不过在我的实际操作中,我用的是另一条路:溯源标记。
在我的系统里,每个 Skill 生成的文件都有清晰的来源标记——YAML 头部的 author 字段、文件路径本身(比如 Video/口播稿/ 一看就知道是 AI 转的)、以及 Skill 的执行日志。这样不需要物理隔离,也能知道每一段内容是谁写的、用什么工具写的、基于什么素材写的
两种方案各有道理
kepano 的物理隔离更干净纯粹,适合把 Obsidian 当"思维延伸"的人;
我的溯源标记更灵活,适合人机协作频繁、产出量大的场景
不过 kepano 有句话我是完全同意的——**“Don’t delegate understanding”**
你可以让 AI 帮你整理知识,但你不能让 AI 替你理解知识
如果你连自己知识库里的内容都没读过、没消化过,那这个知识库再大也不是你的
🚀 Karpathy 最有远见的一句话
Karpathy 整个推文我认为最有远见的一句话:
“随着仓库的增长,自然地也想考虑合成数据生成 + 微调,让你的 LLM '知道’数据在其权重中,而不仅仅是上下文窗口。”
这才是真正的终局——从上下文到权重
现在所有的知识管理方案,本质上都是在"上下文工程"的范畴内打转
把知识塞进上下文窗口让 LLM 读取——管你是 RAG 还是直接长上下文
但想象一下:如果你能用自己积累的 40 万字知识库微调一个专属的小模型,让它从骨子里"理解"你的领域知识和思考方式。那就不是"你问它答"了,那是你训练了一个数字分身。
📊 三人观点对比
| 维度 | Karpathy | Lex Fridman | kepano |
|---|---|---|---|
| 核心身份 | AI 研究者 / 教育者 | 播客主持人 / 研究者 | Obsidian CEO / 产品哲学家 |
| 知识库用途 | 研究探索 | 多领域播客准备 | 个人思维记录 |
| 对 LLM 的态度 | 全面拥抱,让 LLM 管理一切 | 拥抱但重视多模态输出 | 审慎,警惕过度依赖 |
| Obsidian 角色 | 只是"前端渲染器" | 混合前端之一 | 思维的延伸 |
| 核心哲学 | “编译知识” | “知识要可交互” | “文件优先于应用” |
| 最大贡献 | 完整方法论框架 | 语音交互式学习 | 人机边界思考 |
One More Thing
三位巨佬给了我们三个视角:
- Karpathy 搭了知识管理的上游基建——
raw/ → compile → wiki → query - Lex 打开了知识消费的新维度——语音对话、动态可视化、运动中学习
- kepano 守住了最重要的底线——知识库的主人是你,不是 AI
而我在做的事情,是补上下游的最后一公里——把知识变成文章、视频、社交媒体内容,让它流动起来:
积累(Karpathy)→ 消费(Lex)→ 守护(kepano)→ 生产(老章)→ 反哺积累
你的知识管理系统,走到了哪一环?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)