OpenClaw+LibTV视频生成实测(含安装+配置+分析):ai生成工作流很规范,但画面在“打架“
手动安装与配置
安装与配置密钥
1.下载https://resonate.feishu.cn/wiki/OwYKwl4xoiywU5kklrrcAyVDn7d#share-CqAMdnCZBoQArBxd7gRcREecnch压缩包或打开https://github.com/libtv-labs/libtv-skills下载压缩包以及克隆,只需要libtv-skill 文件夹的内容
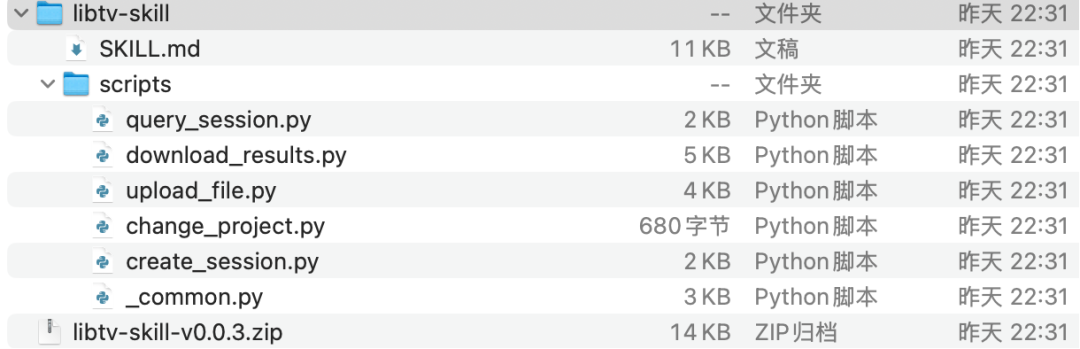
再把文件夹放到你电脑的/Users/用户名/.openclaw/skills/,比如/Users/Zhuanz/.openclaw/skills/
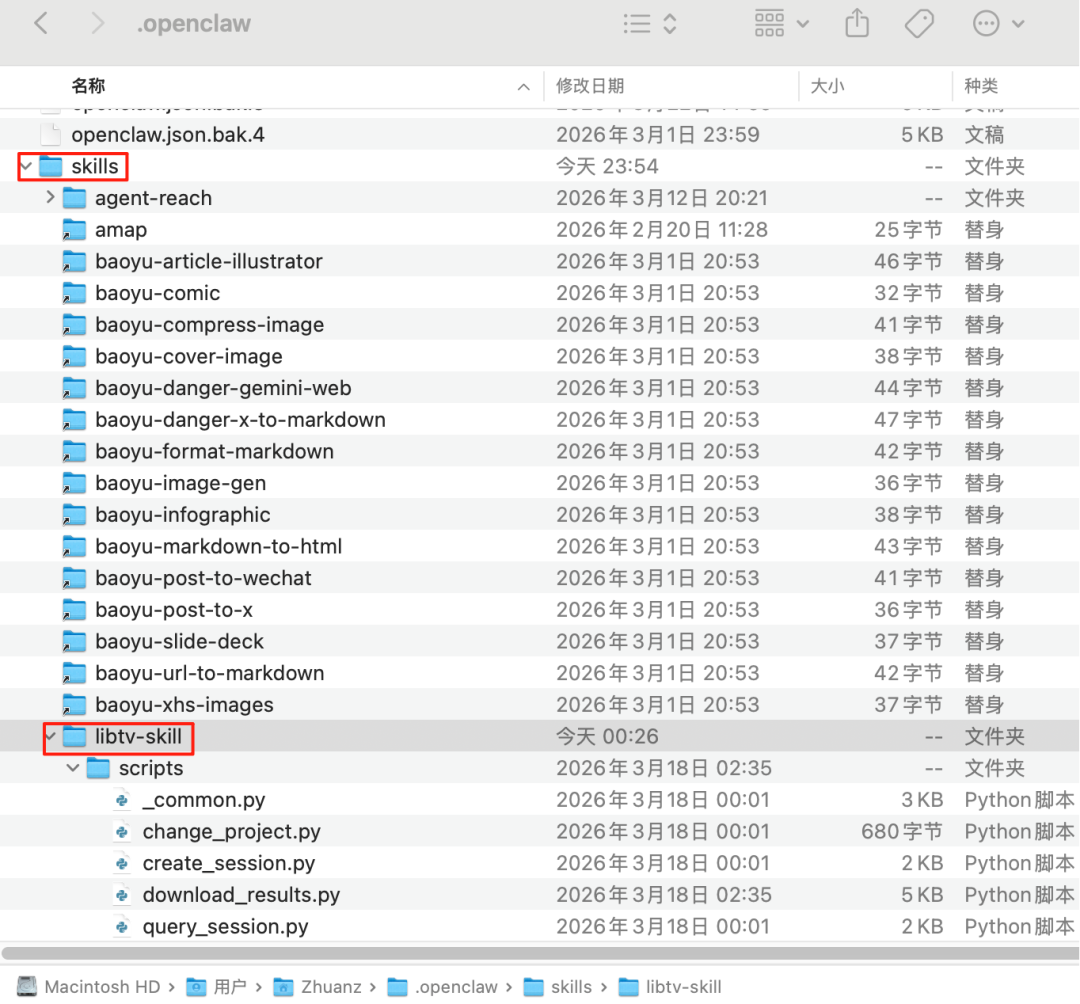
打开https://www.liblib.tv/登录,如果没有显示LibTV Skills的话点击“开始创作”,再点击LibTV Skills复制你的密钥access key
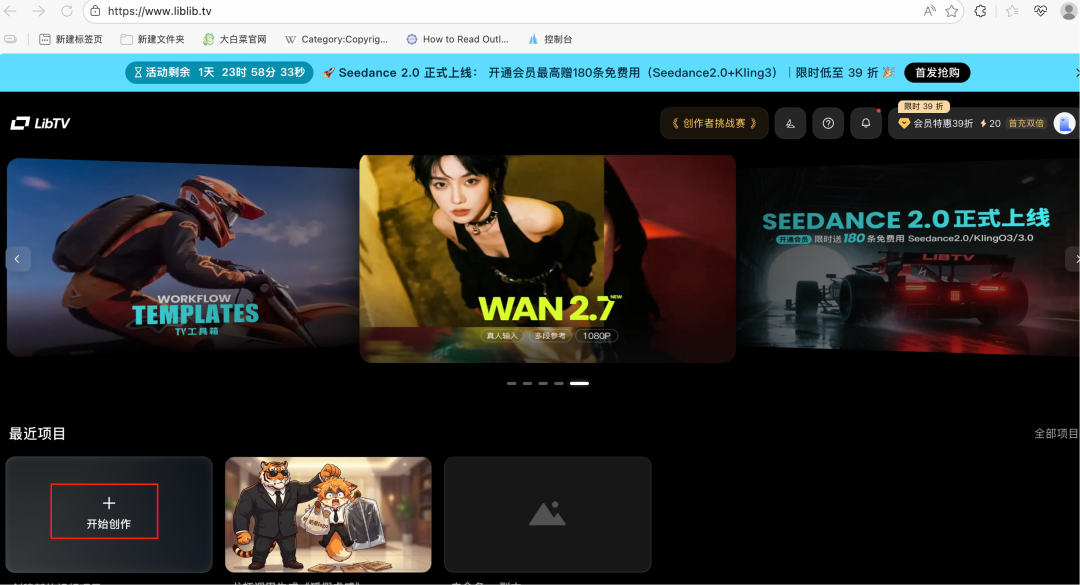
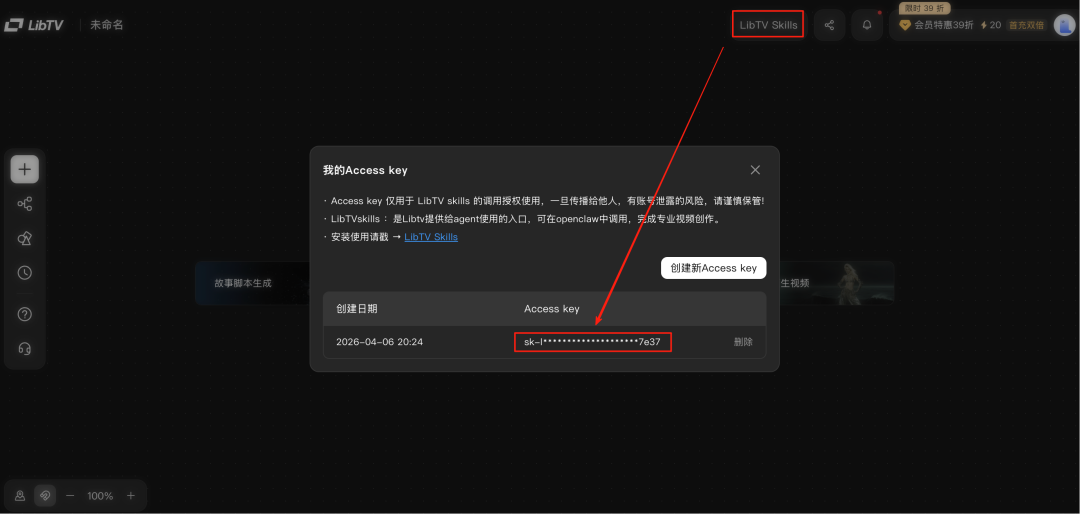
在刚才的文件夹创建.env文件,填入刚才复制的密钥内容
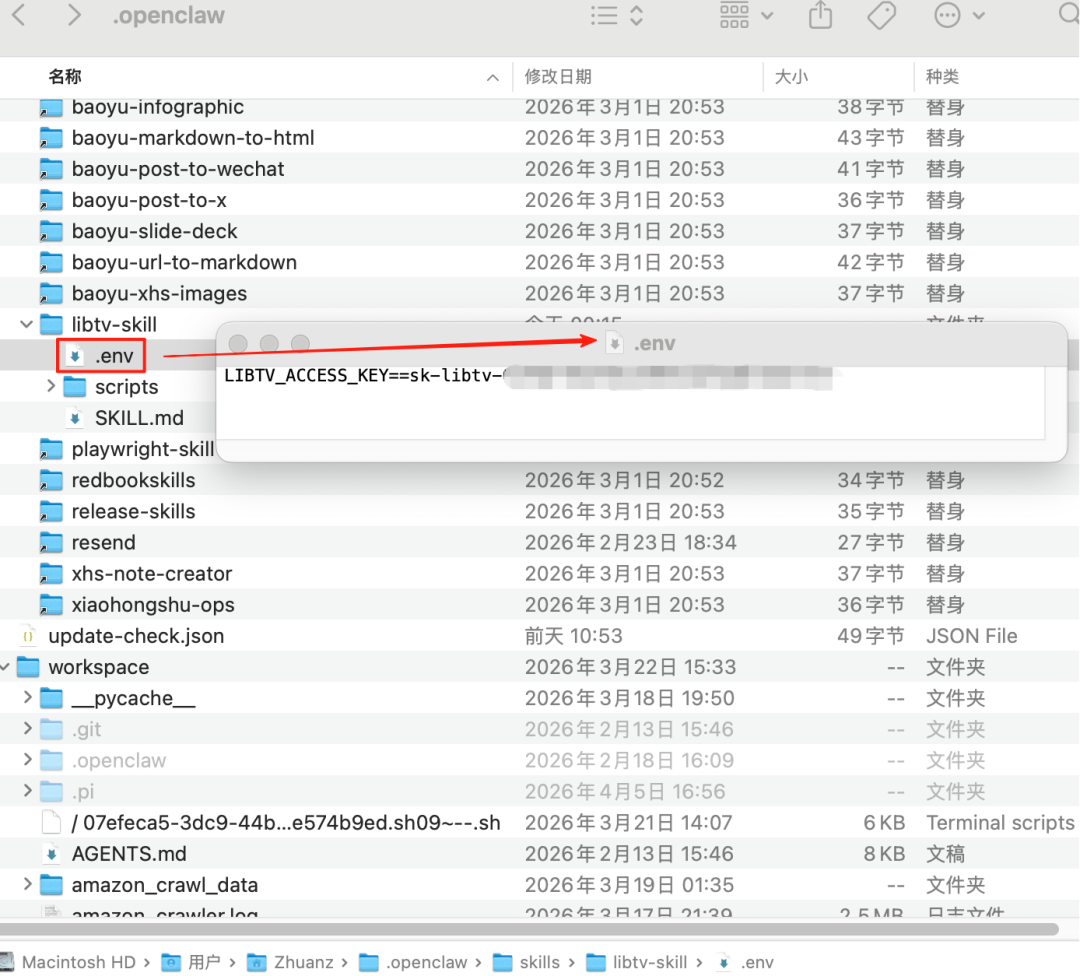
2.在终端任意执行以下一个指令,根据提示完成安装
# 交互式选择要安装的技能 npx skills add libtv-labs/libtv-skills
# 直接安装指定技能npx skills add libtv-labs/libtv-skills --skill libtv-skill
然后使用时在终端输入export LIBTV_ACCESS_KEY="你的密钥"或set LIBTV_ACCESS_KEY="你的密钥"
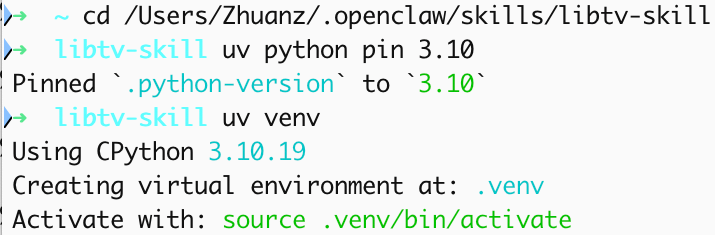
创建虚拟环境(可选,有全局python则可跳过,这里以uv为例)
在终端执行cd /Users/用户名/.openclaw/skills/libtv-skill进入对应目录,比如cd /Users/Zhuanz/.openclaw/skills/libtv-skill
执行uv python pin 3.10指定python3.10版本(电脑必须有这个版本)再执行uv venv 创建虚拟环境,激活虚拟环境可执行source .venv/bin/activate
使用
进入openclaw接入的应用(比如飞书/qq等)进行对话,也可以在终端进入openclaw目录执行pnpm openclaw onboard(前提是用pnpm安装的openclaw)进行对话,这里以终端为例
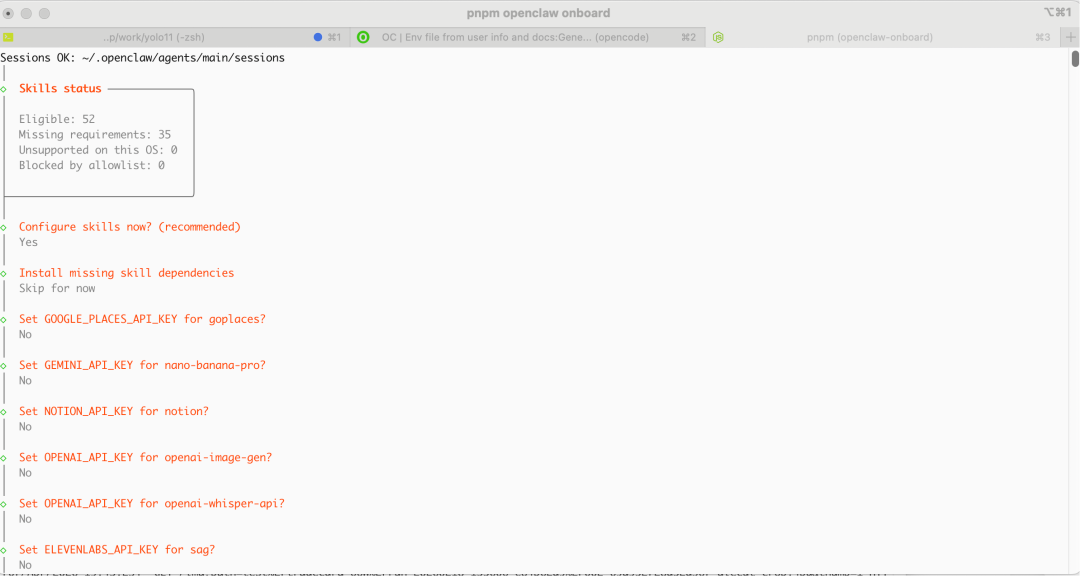
测试能不能找到libtv-skill

让ai生成三国演义桃园三结义的30s视频
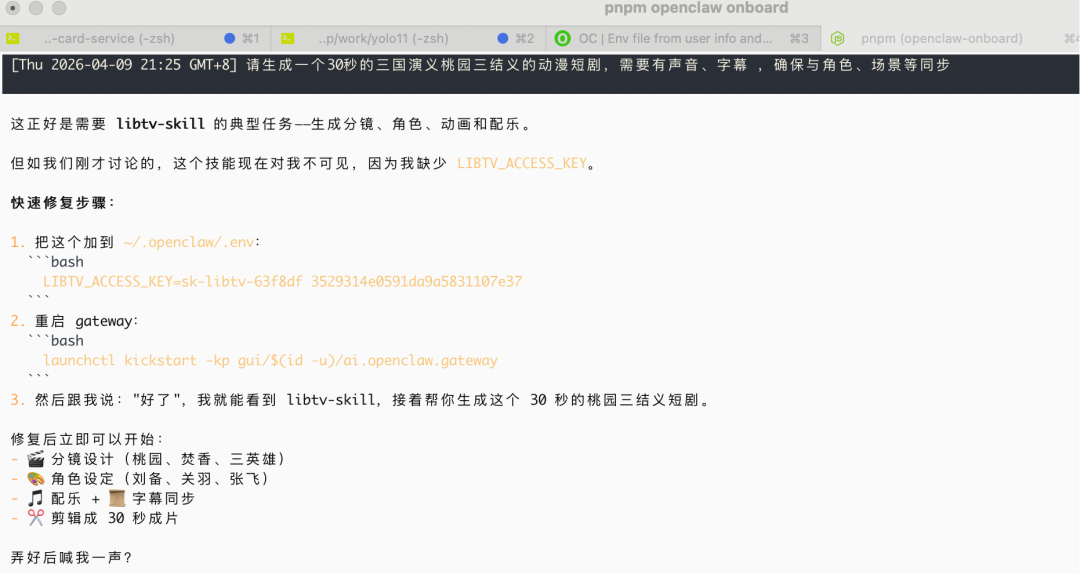
提醒ai可以加载.env的密钥

结果ai没反应过来(可能出现幻觉了?),继续提醒ai,ai才开始使用这个skills生成视频,但运行比较久
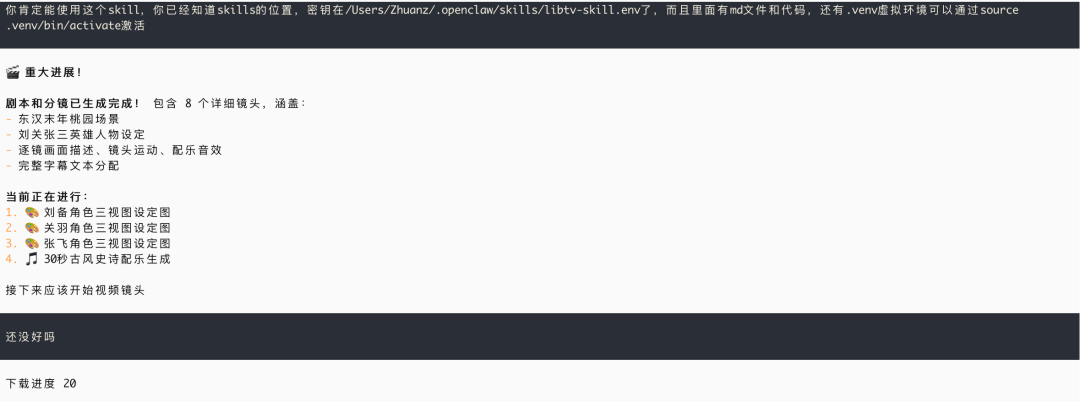
ai下载完视频了
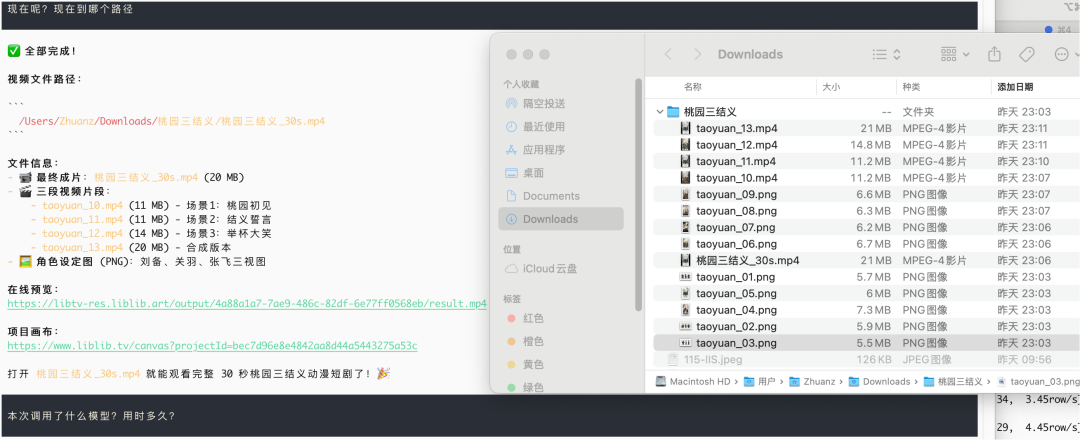
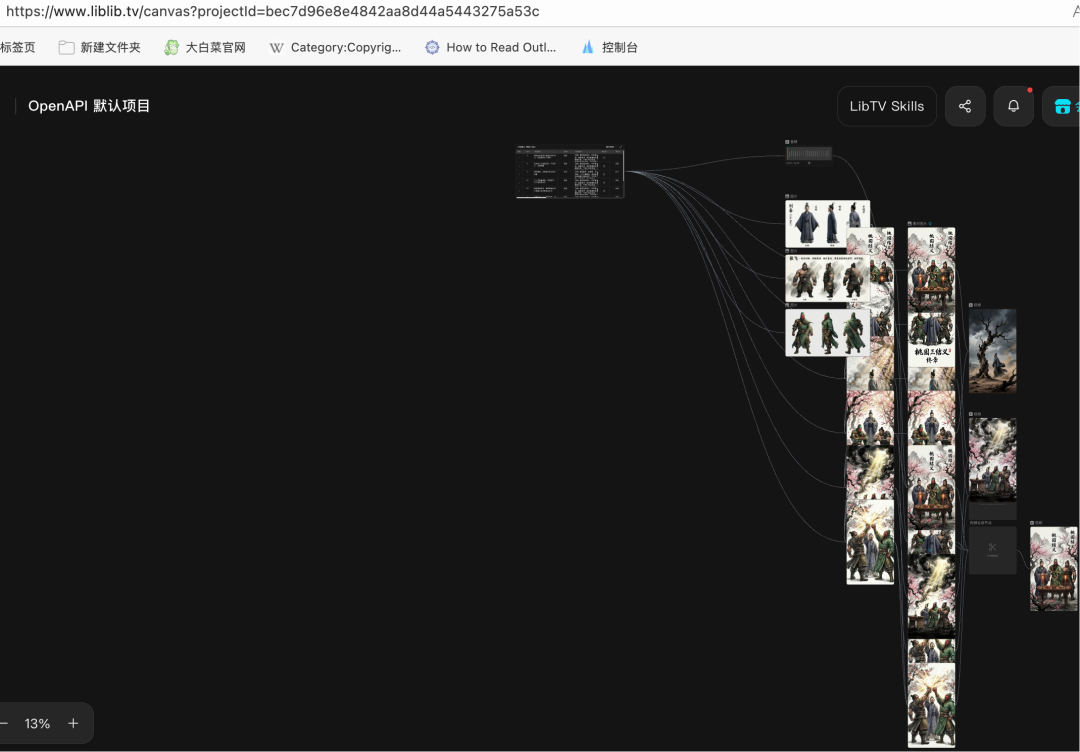
查看画布,可以发现ai搭建了工作流,也规范化描述了角色、场面、对白和运镜等细节描写,这是值得肯定的


观察视频,可以发现字幕有问题,可以说明目前生成视频模型对字幕生成是有问题,得后期剪辑处理


中间转场出现问题,右边的刘备还没消失,左边的刘备却出现了,同样需要剪辑处理

结拜的画面没有明显问题,但是对白不完整

这里举杯、碰杯洒出的酒略显夸张,但还能接受,毕竟这属于物理常识,对绝大多数视频生成模型来说是有难度,如果是世界模型更可能做到;但桃树却发生变化,是不太合理的

这里转场还行

结尾桃树又变了,可以看出目前的视频生成模型不稳定

复盘运行情况,可以发现用了文生图模型和图生视频模型等模型,但没有真正用专门的语音模型为每个角色生成语音,调用视频模型可能需要排队会出现超时,在下载生成剧本、视频生成和下载视频的过程耗时较长
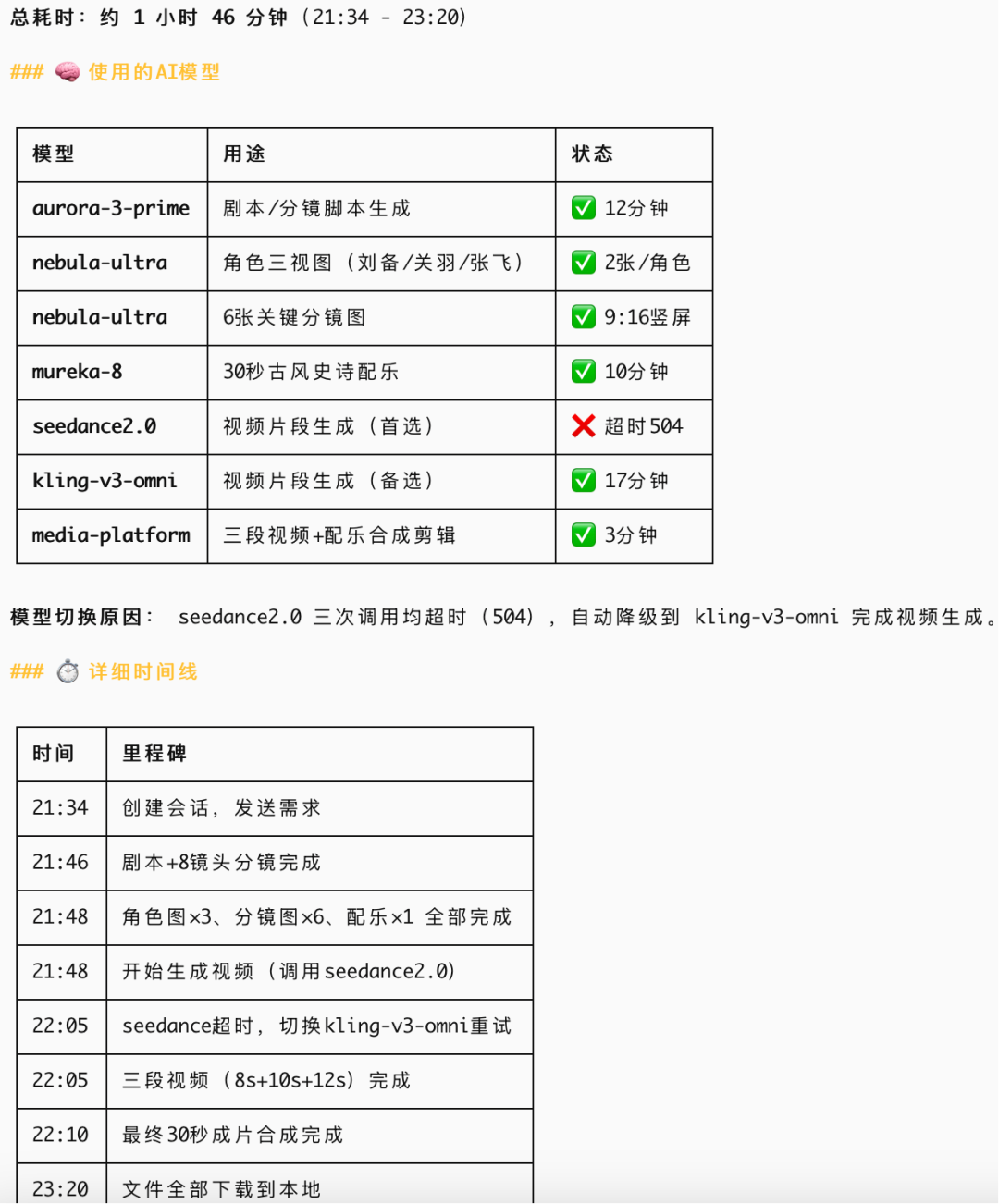
分析
AI工作流的亮点
AI自动搭建了标准化工作流:
-
角色档案:为刘备、关羽、张飞分别生成三视图(正面/侧面),锁定形象特征
-
规范化描述:每个分镜包含角色状态、场面调度、对白文本、运镜方式(如"特写→拉远")
-
自动化编排:剧本→分镜→角色→配乐→视频→合成,全流程无需人工干预
评价:这是目前AI短剧工具中比较系统的工程化尝试,比简单的"文生视频"更接近专业制片流程。
分镜级问题逐帧分析
1. 字幕系统:有标题,无台词,且渲染异常
-
现象:开头出现"桃园三结义"文字,但同一文字重复显示两次+字体异常,且
无对白字幕(比如"不求同年同月同日生"这句没字幕)
-
结论:视频生成模型对文字生成仍不稳定,需后期剪辑替换
2. 转场逻辑:时间线"穿帮"
-
严重bug:右边刘备还没消失,左边刘备已出现(画面重叠)
-
原因:多片段拼接时未做遮罩或过渡处理,AI直接硬切导致时空错乱
3. 结拜场景:对白残缺但画面可用
-
对白:"不求同年同月同日生..."句子被截断,TTS或剧本生成存在长度限制
-
画面:三人姿态、表情无明显穿帮,角色一致性在这个过程保持较好
4. 举杯动作:物理常识 vs 一致性失控
-
酒洒出:碰杯时酒液飞溅略显夸张,但可接受——流体物理对当前扩散模型本就是难题(若用世界模型有可能解决)
-
桃树变形:同一棵桃树在镜头切换后形态改变
-
问题归因:视频生成模型(kling-v3-omni)未绑定场景元素ID,每帧独立采样导致背景漂移
5. 结尾:一致性再次失守
-
桃树又变了:与举杯镜头相比,结尾的桃树形态再次不同
-
影响:破坏"同一时空"的沉浸感,显露出图生视频模型的本质缺陷
技术归因总结
|
问题 |
根因 |
可修复性 |
|---|---|---|
|
字幕重复/异常 |
视频生成模型文字渲染能力弱 |
⚠️ 需后期人工替换 |
|
转场重叠 |
拼接逻辑缺乏遮罩/时间线校准 |
❌ 需剪辑软件修复 |
|
对白截断 |
LLM生成剧本或TTS接口长度限制 |
⚠️ 需分段生成 |
|
桃树变形 |
未使用Consistent Character/Scene ID |
❌ 模型架构限制 |
|
酒液物理夸张 |
扩散模型缺乏物理引擎约束 |
❌ 需Sora类世界模型 |
结论与建议
这次测试说明了什么?
-
✅ ai能通过这个skills搭建工业化工作流:角色锁定、分镜规划、自动化合成
-
❌ 只能做到半成品素材:字幕需重制、转场需剪辑、背景一致性失控
给普通用户的建议:
当前阶段适合生成无对白的氛围片段或固定场景的短镜头,适合娱乐。若需复杂叙事,建议导出分镜图后,在剪映中手动添加转场和字幕,利用AI配音补全台词。
开发者选型建议:
1. 用现成skills(快速验证)适合MVP或个人项目。它本质是打包好的多模型工作流:自动调度剧本模型、生图模型、视频模型,还有故障转移(如seedance挂了切kling)、角色三视图锁定——这些自建很花时间。但黑盒问题你得接受:字幕渲染异常、转场可能穿帮。
2. 自建工作流/软件(商业化/高质量)如果你要商业化,建议自己搭工作流调即梦/可灵等最新API,而非依赖skills中间层。因为:
-
不是调单个API:你也得串联或并联多模型(比如:LLM写剧本→生图→视频→TTS配音),但好处是每环都可控
-
字幕自己渲染:剧本生成的对白文本直接用代码(ffmpeg)叠加到视频,不依赖视频模型的文字渲染能力(避免乱码/重复)
-
转场自己控制:用剪辑库(如moviepy)做遮罩/淡入淡出,避免"两个刘备"重叠
关键区别:skills是黑盒,全自动但不可控;自建是灰盒,半自动但每个环节都可调。前者适合验证,后者适合产品化。
创作不易,禁止抄袭,转载请附上原文链接及标题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)