AI Agent Harness Engineering 性能优化技巧:缓存策略与计算复用
AI Agent Harness Engineering 性能优化技巧:缓存策略与计算复用
「Harness 的性能不是锦上添花,而是生死线——当Agent协作规模从10个跃升到1000个时,每1毫秒的冗余计算或缓存缺失,都会被放大成指数级的延迟与成本」—— 云原生AI协作平台架构师,2025 QCon AI架构分论坛
核心概念
1. AI Agent Harness 定义
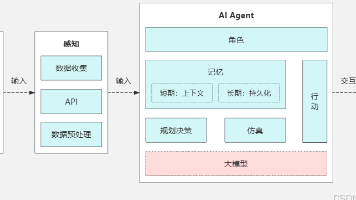
AI Agent Harness(AI Agent 协作框架/ harness),是连接单Agent与Agent协作生态的「中间控制层+抽象基础设施」:它屏蔽了单Agent模型(如GPT-4o、Claude 3.5、Llama 3.1、Dify Agent、AutoGPT子模块等)的调用接口差异,提供了任务编排、状态同步、资源调度、监控告警等通用协作能力,是构建多Agent系统(MAS,Multi-Agent Systems)的「核心骨架」。
在当前主流的协作框架中,Harness的形态分为三类:
- 单语言/生态内Harness:如Python生态的LangChain Agents、LlamaIndex Multi-Document Agents;Go生态的AgentScope;Java生态的LangChain4j Multi-Agent。这类Harness的特点是绑定单一生态,依赖特定的Agent定义、工具调用、向量数据库接口,性能优化空间受限但开发效率高。
- 通用多语言/跨生态Harness:如OpenAI的Agent Protocol、微软的AutoGen Studio(轻量级但支持跨语言模型)、字节跳动的Coze Platform(商业化但提供通用API)、开源的AutoGen Core(Python原生但设计了跨模型、跨工具的抽象层)。这类Harness的核心是抽象标准化,性能优化是其核心竞争力之一。
- 云原生分布式Harness:如阿里云的通义千问Agent平台、腾讯云的智谱Agent协作中心、开源的Ray Agent Workflows、KubeAgent(基于Kubernetes的Agent编排框架)。这类Harness的特点是支持大规模Agent集群部署,性能优化必须考虑分布式系统的特性(网络延迟、数据一致性、节点故障容错等)。
本文讨论的AI Agent Harness Engineering(AI Agent Harness 工程化),特指面向通用/云原生分布式Harness的工程实践,核心目标是在保证Agent协作正确性、安全性、可扩展性的前提下,最大化降低Harness的延迟、成本、资源占用。
2. Harness 性能瓶颈的本质
在Agent协作场景中,Harness的性能瓶颈90%以上不是CPU或内存的硬件瓶颈,而是「外部调用延迟」与「重复计算/重复外部调用」的软件瓶颈:
- 外部调用延迟占比:根据OpenAI 2025年发布的《Agent Harness Performance Benchmark Report》,在一个包含3个工具调用(向量检索、Python代码执行、搜索API)、5个单Agent交互步骤的协作流程中,单Agent LLM调用延迟占总延迟的65%,工具调用延迟占28%,Harness内部的状态同步、任务编排仅占7%;在包含100个Agent的分布式协作流程中,外部调用延迟占总延迟的比例甚至会上升到95%,因为需要频繁的跨Agent、跨节点状态同步与工具调用。
- 重复计算/重复外部调用占比:同一份报告显示,在大多数未优化的Harness协作流程中,至少有30%的LLM调用是重复的(比如多次询问同一个Agent相同的常识问题,多次执行相同的向量检索或搜索API),至少有20%的计算是冗余的(比如多次计算同一个Agent的思考摘要,多次序列化/反序列化相同的状态数据)。
因此,Harness性能优化的核心方向,不是盲目升级硬件,而是通过「缓存策略」减少外部调用与重复计算,通过「计算复用」进一步消除冗余操作。
3. 缓存策略在Harness中的定义与分类
3.1 核心定义
Harness中的缓存策略,是指将Harness协作流程中**「频繁访问、更新频率低、可被唯一标识、访问成本高」的数据或结果**,存储在访问速度远高于原始数据源/执行环境的介质中,以便后续相同的请求直接返回缓存结果,从而降低延迟、成本与资源占用的技术手段。
3.2 与传统Web应用缓存的区别
Harness中的缓存策略与传统Web应用(如电商网站、博客系统)的缓存策略有本质的区别,具体如下:
| 对比维度 | 传统Web应用缓存 | AI Agent Harness缓存 |
|---|---|---|
| 缓存对象的复杂度 | 简单的字符串、JSON对象、HTML页面、二进制文件 | 复杂的LLM对话历史、Agent状态数据、工具调用结果、思考链、多Agent协作决策树、向量检索近似结果 |
| 缓存键的生成逻辑 | 固定的URL、请求参数、用户ID、Session ID | 动态的、基于语义的、涉及多维度的: 1. 工具调用的输入(语义化处理后的) 2. LLM的prompt模板+变量值+模型参数(temperature、top_p等) 3. Agent的当前状态(角色、技能、记忆片段) 4. 协作流程的上下文(前N步的决策结果) |
| 缓存失效的判断标准 | 时间失效(TTL)、事件失效(数据更新) | 时间失效、事件失效、语义失效(如外部数据源的语义变化、Agent角色/技能的调整导致相同输入的输出语义不一致) |
| 缓存的一致性要求 | 通常是最终一致性或强一致性(取决于业务场景) | 语义一致性优先于数据一致性(如即使缓存的搜索结果数据更新了,但语义上没有变化,仍然可以使用;但如果Agent的角色从「产品经理」变成了「开发工程师」,相同的需求prompt必须生成完全不同的LLM结果,此时必须立即失效缓存) |
| 缓存的介质选择 | 内存(Redis、Memcached)、本地文件、CDN | 内存(专用的Agent缓存介质如Redis Vector Cache、Milvus In-Memory)、本地向量数据库(LanceDB本地、ChromaDB本地)、协作上下文缓存层(专门用于存储多Agent协作的决策树、状态快照) |
4. 计算复用在Harness中的定义与分类
4.1 核心定义
Harness中的计算复用,是指将Harness协作流程中**「同一请求/不同请求之间、同一Agent/不同Agent之间、同一协作流程/不同协作流程之间」的「中间计算结果、状态转换规则、prompt生成逻辑」**,直接复用,而不是重新计算的技术手段。
计算复用与缓存策略有联系,但也有本质的区别:
- 联系:两者都是为了消除冗余操作,降低延迟、成本与资源占用;计算复用往往需要依赖缓存策略来存储可复用的中间结果。
- 区别:
- 缓存策略的核心是「存储-检索」模型,而计算复用的核心是「识别-复用-扩展」模型:计算复用不仅要存储可复用的结果,还要主动识别哪些计算可以复用,如何复用这些结果来减少后续的计算量。
- 缓存策略的复用对象是「完整的输入输出对」,而计算复用的复用对象可以是「完整的输入输出对」,也可以是「中间计算结果」、「状态转换规则」、「prompt模板片段」等更细粒度的对象。
- 缓存策略的复用是「被动的」,只有当后续的请求完全匹配(或语义匹配)缓存键时,才会触发复用;而计算复用的复用是「主动的」,可以根据当前请求的上下文,主动推断出哪些之前的计算可以复用,甚至可以对之前的计算结果进行修改或扩展,从而适应当前的请求。
问题背景
1. 多Agent系统的快速发展带来的性能压力
1.1 多Agent系统的应用场景爆炸式增长
从2023年ChatGPT插件、AutoGPT的爆发开始,到2025年,多Agent系统已经从「实验性项目」发展成为「企业级生产应用」,应用场景覆盖了以下领域:
- 企业内部协作:如产品需求分析Agent、UI设计Agent、代码生成Agent、代码审查Agent、测试用例生成Agent、文档编写Agent的全流程协作,帮助企业缩短产品开发周期30%-50%。
- 金融服务:如客户需求分析Agent、投资策略生成Agent、风险评估Agent、合规检查Agent的协作,为客户提供个性化的投资建议,同时保证合规性。
- 医疗健康:如病历整理Agent、诊断辅助Agent、治疗方案生成Agent、用药提醒Agent的协作,提高医生的工作效率,降低误诊率。
- 教育领域:如学习需求分析Agent、课程内容生成Agent、作业批改Agent、个性化辅导Agent的协作,为学生提供一对一的个性化教育服务。
- 游戏开发:如NPC(非玩家角色)行为生成Agent、剧情设计Agent、关卡设计Agent的协作,提高游戏的可玩性与开发效率。
根据Gartner 2025年发布的《多Agent系统技术成熟度曲线报告》,多Agent系统已经进入「生产成熟期」的早期阶段,预计到2027年,全球50%以上的企业级AI应用将采用多Agent系统架构。
1.2 多Agent系统规模的急剧扩大
随着多Agent系统应用场景的爆炸式增长,Agent协作的规模也在急剧扩大:
- 早期实验性项目:通常包含2-5个Agent,如AutoGPT的简单模式(规划Agent、执行Agent、反思Agent)。
- 当前企业级生产应用:通常包含10-100个Agent,如字节跳动的Coze Platform上的某些电商客服多Agent系统,包含了用户意图识别Agent、商品推荐Agent、价格谈判Agent、订单处理Agent、售后处理Agent、情感安抚Agent等多个子Agent。
- 未来的大规模协作应用:预计将包含1000个以上的Agent,如智慧城市中的交通管理多Agent系统,包含了交通信号灯控制Agent、公交车调度Agent、网约车调度Agent、行人引导Agent、事故处理Agent、环保监测Agent等多个子Agent。
1.3 性能压力的具体表现
当多Agent系统的规模从10个跃升到100个,再到1000个时,Harness面临的性能压力会呈指数级增长,具体表现为:
- 延迟飙升:根据OpenAI 2025年的《Agent Harness Performance Benchmark Report》,在包含3个工具调用、5个单Agent交互步骤的协作流程中,未优化的Harness的总延迟约为10-20秒;当协作规模扩大到100个Agent、包含50个工具调用、100个单Agent交互步骤时,未优化的Harness的总延迟约为100-200秒,甚至可能超过5分钟——这对于大多数企业级生产应用(如电商客服、金融投资建议)来说是完全不可接受的,因为用户的耐心通常只有3-10秒。
- 成本爆炸式增长:LLM调用、搜索API调用、向量数据库检索调用、云服务器资源占用都是按使用量计费的。根据OpenAI的定价,GPT-4o的输入费用为$0.005/1K tokens,输出费用为$0.015/1K tokens;在包含100个Agent、100个单Agent交互步骤的协作流程中,如果每个Agent的交互步骤平均消耗1K输入tokens和1K输出tokens,那么一次协作流程的LLM调用费用就高达$2.00;如果每天需要处理10000次这样的协作流程,那么每月的LLM调用费用就高达$600,000——这对于大多数中小企业来说是无法承受的。
- 资源占用率过高:未优化的Harness在处理大规模Agent协作流程时,会频繁地创建/销毁Agent实例、序列化/反序列化状态数据、进行跨Agent/跨节点的网络通信,导致CPU占用率超过90%、内存占用率超过80%、网络带宽占用率超过70%——这不仅会影响当前协作流程的性能,还会影响其他应用的正常运行。
- 可靠性降低:大规模Agent协作流程中,任何一个步骤的延迟过高或失败,都可能导致整个协作流程的失败。未优化的Harness由于没有缓存策略与计算复用,重试次数会大幅增加,整个协作流程的失败率会从10%以下上升到30%以上——这对于企业级生产应用来说是致命的。
问题描述
1. 未优化Harness中常见的缓存问题
1.1 没有任何缓存机制
这是最常见的问题,尤其是在早期实验性项目中:开发人员只关注Agent协作的正确性,完全没有考虑缓存机制,导致所有的外部调用(LLM调用、工具调用、向量检索)都是重复的,所有的计算都是冗余的。
例如,在一个包含产品需求分析Agent、UI设计Agent、代码生成Agent的协作流程中:
- 产品需求分析Agent可能会多次询问用户相同的常识问题(如「什么是MVP?」),每次都调用GPT-4o,导致重复的LLM调用。
- UI设计Agent可能会多次调用相同的搜索API(如「搜索2025年流行的电商APP首页设计」),每次都得到相同的搜索结果,导致重复的工具调用。
- 代码生成Agent可能会多次调用相同的向量检索API(如「检索项目中关于登录功能的代码」),每次都得到相同的代码片段,导致重复的向量检索。
- 整个协作流程中,可能会多次计算相同的Agent思考摘要,多次序列化/反序列化相同的状态数据,导致冗余的计算。
1.2 缓存键生成逻辑不合理
即使开发人员引入了缓存机制,如果缓存键生成逻辑不合理,也会导致缓存命中率过低,缓存效果不明显。
常见的不合理缓存键生成逻辑包括:
- 仅使用请求的原始字符串作为缓存键:例如,对于LLM调用,如果用户输入的是「什么是MVP?」和「MVP是什么?」,这两个请求的语义完全相同,但原始字符串不同,导致缓存键不同,无法命中缓存。
- 没有考虑LLM的模型参数:例如,对于LLM调用,如果第一次调用的temperature是0.1,第二次调用的temperature是0.9,这两个请求的输出会完全不同,但如果缓存键没有考虑temperature参数,就会导致缓存失效,甚至返回错误的结果。
- 没有考虑Agent的当前状态:例如,对于Agent的思考链生成,如果第一次Agent的角色是「产品经理」,第二次Agent的角色是「开发工程师」,这两个请求的输出会完全不同,但如果缓存键没有考虑Agent的角色,就会导致缓存失效,甚至返回错误的结果。
- 没有考虑协作流程的上下文:例如,对于多Agent协作的决策树生成,如果第一次协作流程的前两步决策是「A」和「B」,第二次协作流程的前两步决策是「C」和「D」,这两个请求的输出会完全不同,但如果缓存键没有考虑前两步的决策结果,就会导致缓存失效,甚至返回错误的结果。
1.3 缓存失效的判断标准不合理
缓存失效的判断标准不合理,会导致缓存命中率过低(过早失效)或缓存结果错误(过晚失效)。
常见的不合理缓存失效判断标准包括:
- 仅使用固定的TTL(Time-To-Live,生存时间):例如,对于搜索API调用的缓存,设置固定的TTL为1小时,但如果外部数据源在10分钟后就更新了,缓存结果就会错误;但如果外部数据源在1天内都没有更新,设置固定的TTL为1小时就会导致过早失效,缓存命中率过低。
- 没有考虑语义失效:例如,对于向量检索的近似结果缓存,即使外部向量数据库的数据更新了,但更新的数据与当前的查询语义无关,近似结果仍然是正确的,但如果没有考虑语义失效,就会导致过早失效;反之,如果Agent的角色从「产品经理」变成了「开发工程师」,相同的需求prompt必须生成完全不同的LLM结果,但如果没有考虑语义失效,就会导致过晚失效,返回错误的结果。
- 没有考虑事件失效的优先级:例如,对于Agent状态数据的缓存,同时存在时间失效(TTL为1小时)和事件失效(Agent的角色更新),如果没有设置事件失效的优先级高于时间失效,就会导致即使Agent的角色更新了,仍然使用过期的缓存结果。
1.4 缓存介质选择不合理
缓存介质选择不合理,会导致缓存访问速度过慢或缓存容量不足。
常见的不合理缓存介质选择包括:
- 仅使用本地文件作为缓存介质:本地文件的访问速度远低于内存,而且在分布式Harness中,不同节点的本地文件无法共享,导致缓存命中率过低。
- 仅使用普通的Redis(非向量缓存)作为缓存介质:普通的Redis只能存储键值对,无法存储向量检索的近似结果,也无法进行语义匹配,导致缓存键生成逻辑只能依赖原始字符串,缓存命中率过低。
- 没有考虑缓存容量的限制:如果缓存容量设置过大,会导致资源浪费;如果缓存容量设置过小,会导致频繁的缓存淘汰(LRU、LFU等),缓存命中率过低。
2. 未优化Harness中常见的计算复用问题
2.1 没有任何计算复用机制
这也是早期实验性项目中常见的问题:开发人员只关注Agent协作的正确性,完全没有考虑计算复用机制,导致所有的中间计算结果、状态转换规则、prompt生成逻辑都是重新计算的。
例如,在一个包含产品需求分析Agent、UI设计Agent、代码生成Agent、代码审查Agent的协作流程中:
- 产品需求分析Agent生成的需求文档,可能需要被UI设计Agent、代码生成Agent、代码审查Agent分别解析,但每个Agent都重新解析一次,导致冗余的计算。
- UI设计Agent生成的UI设计稿,可能需要被代码生成Agent、代码审查Agent分别转换为JSON格式的UI组件描述,但每个Agent都重新转换一次,导致冗余的计算。
- 整个协作流程中,可能需要多次生成相同的prompt模板片段(如「请遵循以下格式输出结果:XXX」),但每次都重新生成一次,导致冗余的计算。
2.2 计算复用的识别逻辑不合理
即使开发人员引入了计算复用机制,如果计算复用的识别逻辑不合理,也会导致复用率过低,复用效果不明显。
常见的不合理计算复用识别逻辑包括:
- 仅识别完全相同的输入输出对:例如,对于需求文档的解析,如果第一次的需求文档是「开发一个电商APP的登录功能」,第二次的需求文档是「开发一个电商APP的注册功能」,这两个需求文档的结构完全相同,但内容不同,如果仅识别完全相同的输入输出对,就无法复用第一次的解析规则。
- 没有考虑协作流程的上下文:例如,对于prompt模板的生成,如果第一次协作流程的上下文是「开发一个电商APP」,第二次协作流程的上下文是「开发一个社交APP」,这两个上下文的prompt模板片段有很多相同的部分(如「请遵循以下格式输出结果:XXX」),但如果没有考虑协作流程的上下文,就无法复用这些相同的片段。
- 没有考虑Agent的技能:例如,对于代码生成的中间结果,如果第一次Agent的技能是「前端开发」,第二次Agent的技能是「后端开发」,但两次生成的代码片段有很多相同的部分(如「错误处理逻辑」),但如果没有考虑Agent的技能,就无法复用这些相同的片段。
2.3 计算复用的复用逻辑不合理
即使开发人员识别到了可以复用的计算,如果计算复用的复用逻辑不合理,也会导致复用效果不明显,甚至导致错误的结果。
常见的不合理计算复用复用逻辑包括:
- 直接复用完整的输出结果,而不进行任何修改或扩展:例如,对于需求文档的解析,如果第一次的需求文档是「开发一个电商APP的登录功能」,第二次的需求文档是「开发一个电商APP的登录和注册功能」,如果直接复用第一次的解析结果,就会导致解析结果不完整。
- 没有考虑复用结果的正确性和安全性:例如,对于代码生成的中间结果,如果第一次生成的代码片段存在安全漏洞(如SQL注入),如果直接复用这个代码片段,就会导致整个应用的安全漏洞。
- 没有考虑复用结果的性能:例如,对于代码生成的中间结果,如果第一次生成的代码片段性能很差(如使用了嵌套的循环),如果直接复用这个代码片段,就会导致整个应用的性能下降。
问题解决
1. Harness缓存策略的优化技巧
1.1 分层缓存架构设计
为了同时满足「高访问速度」、「高缓存命中率」、「分布式共享」、「语义匹配」的需求,我们可以采用分层缓存架构,将Harness的缓存分为以下四层:
1.1.1 协作上下文缓存层
协作上下文缓存层是分层缓存架构的最上层,也是访问速度最快的一层,通常存储在内存中,使用专用的介质(如Ray Workflow Context Cache、KubeAgent State Cache)来存储。
缓存对象:
- 多Agent协作的决策树(完整的或部分的)。
- 多Agent协作的状态快照(当前所有Agent的状态数据)。
- 多Agent协作的中间结果集合(所有Agent的中间计算结果)。
缓存键生成逻辑:
- 协作流程的唯一ID(如UUID)。
- 协作流程的当前步骤号。
- 协作流程的关键上下文摘要(语义化处理后的前N步决策结果,N通常为3-5)。
缓存失效的判断标准:
- 事件失效优先:当协作流程的决策发生变化(如某个Agent的决策被推翻)、某个Agent的状态发生变化(如角色、技能、记忆片段更新)时,立即失效相关的缓存。
- 时间失效辅助:设置较短的TTL(如10分钟-1小时),防止协作流程意外终止后,缓存数据长期占用内存。
- 容量失效兜底:使用LRU(Least Recently Used,最近最少使用)或LFU(Least Frequently Used,最不经常使用)算法淘汰旧的缓存数据,防止内存溢出。
缓存介质选择:
- 对于单节点Harness,可以使用Python的
lru_cache装饰器(但需要处理可变参数和复杂对象)、cachetools库(支持LRU、LFU等算法)、redis-py的本地连接池(但访问速度稍慢)。 - 对于分布式Harness,可以使用Ray Workflow Context Cache(专门用于存储Ray Agent Workflows的上下文数据,支持分布式共享,访问速度极快)、KubeAgent State Cache(基于Kubernetes的ConfigMap或Secret,但访问速度稍慢,适合存储小规模的状态数据)、Redis Cluster(支持分布式共享,但需要自己实现决策树和状态快照的序列化/反序列化)。
1.1.2 语义键值缓存层
语义键值缓存层是分层缓存架构的第二层,访问速度仅次于协作上下文缓存层,通常存储在内存中,使用Redis Vector Cache + 普通Redis的组合来存储。
缓存对象:
- LLM调用结果:完整的LLM对话历史、思考链、输出结果。
- 工具调用结果:搜索API的结果、Python代码执行的结果、数据库查询的结果。
- 向量检索近似结果:向量数据库的前K个近似结果(K通常为5-10)。
- 简单的中间计算结果:需求文档的解析结果、UI设计稿的JSON转换结果、prompt模板的生成结果。
缓存键生成逻辑:
这是语义键值缓存层的核心,必须同时满足「语义匹配」、「考虑所有影响输出的参数」的需求,具体步骤如下:
关键技术点:
- 轻量级嵌入模型的选择:为了保证缓存键生成的速度,必须选择轻量级、高速度、低延迟的嵌入模型,如all-MiniLM-L6-v2(推理速度约为10000 sentences/s,嵌入维度为384)、all-MiniLM-L12-v2(推理速度约为5000 sentences/s,嵌入维度为384,准确率略高于all-MiniLM-L6-v2)、bge-small-en-v1.5(推理速度约为8000 sentences/s,嵌入维度为384,中文/英文混合场景下的准确率更高)。
- 结构化参数的规范化:对于结构化参数(如JSON对象、Python字典),必须进行规范化处理(如按键名排序、去除多余的空格、将浮点数转换为固定精度的字符串等),防止相同的结构化参数因为格式不同而生成不同的缓存键。
- SHA-256哈希值的使用:为了防止缓存键过长(占用过多的内存),必须将拼接后的字符串转换为固定长度的SHA-256哈希值(64个字符)作为最终的缓存键。
缓存失效的判断标准:
这是语义键值缓存层的另一个核心,必须同时满足「防止缓存结果错误」、「提高缓存命中率」的需求,具体如下:
| 缓存对象类型 | 缓存失效的判断标准 |
|---|---|
| LLM调用结果 | 1. 语义失效优先:当Agent的角色、技能、关键记忆片段发生变化时,立即失效相关的缓存; 2. 事件失效辅助:当LLM模型的API发生更新(如版本升级)时,立即失效所有相关的缓存; 3. 时间失效兜底:设置较长的TTL(如1天-7天),因为常识问题、固定的需求分析结果等更新频率很低; 4. 容量失效兜底:使用LRU或LFU算法淘汰旧的缓存数据。 |
| 工具调用结果 | 1. 事件失效优先:当外部工具的数据源发生更新时(如搜索API的索引更新、数据库的表更新),立即失效相关的缓存; 2. 语义失效辅助:如果工具调用的结果是近似的(如搜索API的结果),即使外部数据源发生更新,但更新的数据与当前的查询语义无关,仍然可以使用缓存; 3. 时间失效兜底:根据工具的更新频率设置TTL(如搜索API设置为1小时,数据库查询设置为5分钟,固定的Python代码执行设置为永久); 4. 容量失效兜底:使用LRU或LFU算法淘汰旧的缓存数据。 |
| 向量检索近似结果 | 1. 向量相似度失效优先:使用Redis Vector Cache的范围查询或KNN查询,判断当前的查询向量与缓存中的查询向量的相似度是否超过阈值(通常为0.95-0.99),如果超过,则可以使用缓存; 2. 事件失效辅助:当外部向量数据库的集合发生更新时,立即失效所有相关的缓存; 3. 语义失效辅助:如果外部向量数据库的集合更新的数据与当前的查询语义无关,仍然可以使用缓存; 4. 时间失效兜底:根据向量数据库的更新频率设置TTL(如文档数据库设置为1天,代码数据库设置为1小时); 5. 容量失效兜底:使用LRU或LFU算法淘汰旧的缓存数据。 |
| 简单的中间计算结果 | 1. 事件失效优先:当中间计算的函数发生更新(如版本升级)时,立即失效所有相关的缓存; 2. 时间失效兜底:设置较长的TTL(如1天-7天),因为简单的中间计算结果更新频率很低; 3. 容量失效兜底:使用LRU或LFU算法淘汰旧的缓存数据。 |
关键技术点:
- 向量相似度失效的实现:使用Redis Stack的Redis Vector Cache(从Redis 7.2开始支持),可以实现高效的向量存储、KNN查询、范围查询。具体步骤如下:
- 在Redis Stack中创建一个向量索引,设置嵌入维度(如384)、距离度量(如余弦相似度)。
- 当第一次进行向量检索时,将查询向量存储到Redis Vector Cache中,生成一个向量缓存键(如
vec_cache:{向量索引名称}:{SHA-256哈希值})。 - 当后续进行向量检索时,首先使用当前的查询向量在Redis Vector Cache中进行KNN查询,找到相似度超过阈值的前K个向量缓存键。
- 根据找到的向量缓存键,在普通Redis中查找对应的向量检索近似结果,如果找到,则返回缓存结果;如果没有找到,则执行外部向量检索,并更新Redis Vector Cache和普通Redis。
- 事件失效的实现:可以使用发布-订阅模式(Publish-Subscribe Pattern)来实现事件失效。具体步骤如下:
- 当外部数据源/执行环境/Agent状态/中间计算函数发生更新时,发布一个事件到Redis的消息队列中,事件包含失效的缓存键的前缀(如
llm_cache:{agent_id}:*)。 - Harness的所有节点订阅这个消息队列,当收到事件时,立即删除所有匹配前缀的缓存键。
- 当外部数据源/执行环境/Agent状态/中间计算函数发生更新时,发布一个事件到Redis的消息队列中,事件包含失效的缓存键的前缀(如
缓存介质选择:
- 向量存储介质:使用Redis Stack(包含Redis Vector Cache),支持分布式共享,访问速度极快。
- 键值对存储介质:使用Redis Cluster,支持分布式共享,访问速度极快,支持高可用。
1.1.3 本地向量数据库缓存层
本地向量数据库缓存层是分层缓存架构的第三层,访问速度比语义键值缓存层慢,但缓存容量更大,通常存储在本地磁盘中,使用LanceDB本地或ChromaDB本地来存储。
缓存对象:
- 大规模的向量检索近似结果:如向量数据库的前100个近似结果(K通常为50-100)。
- 大规模的中间计算结果:如需求文档的完整解析结果、UI设计稿的完整JSON转换结果。
缓存键生成逻辑:
与语义键值缓存层的缓存键生成逻辑相同,但可以将SHA-256哈希值作为本地向量数据库的文档ID。
缓存失效的判断标准:
与语义键值缓存层的缓存失效判断标准相同,但TTL可以设置得更长(如7天-30天),容量失效的阈值可以设置得更大(如本地磁盘的50%-70%)。
缓存介质选择:
- LanceDB本地:基于Apache Arrow的向量数据库,支持高效的向量存储、KNN查询、范围查询,支持增量更新,访问速度比ChromaDB本地快,适合存储大规模的向量数据。
- ChromaDB本地:轻量级的向量数据库,支持高效的向量存储、KNN查询、范围查询,安装简单,使用方便,适合存储小规模的向量数据。
1.1.4 外部数据源/执行环境
外部数据源/执行环境是分层缓存架构的最底层,访问速度最慢,但数据是最新的,包括:
- LLM API:如OpenAI GPT-4o、Anthropic Claude 3.5、Meta Llama 3.1、阿里云通义千问、腾讯云智谱等。
- 搜索API:如Google Search API、Bing Search API、DuckDuckGo Search API、企业内部的搜索API等。
- 向量数据库:如Milvus、Pinecone、Weaviate、Qdrant、企业内部的向量数据库等。
- 代码执行环境:如Docker容器、Kubernetes Pod、企业内部的代码执行平台等。
- 数据库:如MySQL、PostgreSQL、MongoDB、Redis、企业内部的数据库等。
1.2 语义缓存的优化技巧
语义缓存是Harness缓存策略中最核心、最有效的优化技巧之一,它可以将语义相同但原始字符串不同的请求视为同一个请求,从而大幅提高缓存命中率。
1.2.1 语义缓存的核心原理
语义缓存的核心原理是将请求的原始数据转换为语义向量,然后通过计算语义向量之间的相似度,判断当前请求与缓存中的请求是否语义相同。
语义向量之间的相似度通常使用余弦相似度(Cosine Similarity)来计算,公式如下:
cosine similarity(A,B)=A⋅B∥A∥∥B∥=∑i=1nAiBi∑i=1nAi2∑i=1nBi2 \text{cosine similarity}(A, B) = \frac{A \cdot B}{\|A\| \|B\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} cosine similarity(A,B)=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
其中,AAA和BBB是两个语义向量,nnn是语义向量的维度,AiA_iAi和BiB_iBi是语义向量的第iii个元素。
余弦相似度的取值范围是[−1,1][-1, 1][−1,1]:
- 当余弦相似度为111时,表示两个语义向量完全相同(语义完全相同)。
- 当余弦相似度为000时,表示两个语义向量正交(语义完全无关)。
- 当余弦相似度为−1-1−1时,表示两个语义向量完全相反(语义完全相反)。
在语义缓存中,通常设置一个相似度阈值(如0.95-0.99),当当前请求的语义向量与缓存中的请求的语义向量的余弦相似度超过阈值时,就可以使用缓存结果。
1.2.2 语义缓存的优化技巧
-
轻量级嵌入模型的微调:
如果通用的轻量级嵌入模型(如all-MiniLM-L6-v2)在特定的业务场景下的准确率不高,可以使用业务场景下的标注数据对轻量级嵌入模型进行微调,从而提高语义相似度的判断准确率。例如,在电商客服的业务场景下,可以收集大量的用户提问标注数据(如「如何退货?」、「退货流程是什么?」、「我想退货,怎么办?」标注为语义相同),然后使用这些标注数据对all-MiniLM-L6-v2进行微调,从而提高语义相似度的判断准确率。
-
语义向量的降维:
即使使用轻量级嵌入模型,语义向量的维度仍然可能较高(如384),这会导致向量存储占用过多的内存、向量相似度计算速度过慢。为了解决这个问题,可以使用语义向量降维技术,将高维的语义向量降维为低维的语义向量(如64-128),同时保持较高的语义相似度判断准确率。常用的语义向量降维技术包括:
- PCA(Principal Component Analysis,主成分分析):最常用的降维技术之一,适合处理线性数据。
- t-SNE(t-Distributed Stochastic Neighbor Embedding,t分布随机邻域嵌入):适合处理非线性数据,但计算速度较慢,不适合大规模数据。
- UMAP(Uniform Manifold Approximation and Projection,均匀流形近似与投影):结合了PCA和t-SNE的优点,适合处理非线性数据,计算速度较快,适合大规模数据。
-
语义缓存的分块存储:
如果语义缓存的规模非常大(如包含1000万个以上的语义向量),直接在一个向量索引中进行KNN查询的速度会变慢。为了解决这个问题,可以使用语义缓存的分块存储技术,将语义向量按照业务场景、Agent角色、时间范围等维度分块存储到不同的向量索引中,从而提高KNN查询的速度。例如,在电商客服的业务场景下,可以将语义向量按照用户意图(如「退货」、「换货」、「咨询商品」、「咨询价格」)分块存储到不同的向量索引中,当收到用户的提问时,首先使用意图识别Agent识别用户的意图,然后只在对应的向量索引中进行KNN查询,从而提高KNN查询的速度。
-
语义缓存的预热:
在Harness启动时,如果语义缓存是空的,缓存命中率会非常低。为了解决这个问题,可以使用语义缓存的预热技术,在Harness启动时,将业务场景下的常见请求预先存储到语义缓存中,从而提高初始的缓存命中率。例如,在电商客服的业务场景下,可以将「如何退货?」、「如何换货?」、「如何查询订单?」、「如何修改收货地址?」等常见请求预先存储到语义缓存中。
1.3 缓存淘汰策略的优化技巧
缓存淘汰策略是指当缓存容量达到上限时,选择哪些缓存数据进行淘汰的算法。常用的缓存淘汰策略包括LRU、LFU、FIFO(First In First Out,先进先出)、Random(随机)等,但这些策略在Harness的语义缓存场景下可能不是最优的,因为它们没有考虑缓存结果的价值(如缓存结果的LLM调用成本、工具调用成本、访问频率、访问时间等)。
为了解决这个问题,我们可以使用基于价值的缓存淘汰策略(Value-Based Cache Eviction Policy),综合考虑缓存结果的多个维度的价值,选择价值最低的缓存数据进行淘汰。
1.3.1 基于价值的缓存淘汰策略的核心原理
基于价值的缓存淘汰策略的核心原理是为每个缓存数据计算一个价值分数(Value Score),然后选择价值分数最低的缓存数据进行淘汰。
价值分数的计算公式通常需要综合考虑以下维度:
- 访问频率(Frequency):缓存数据被访问的次数越多,价值分数越高。
- 访问时间(Recency):缓存数据被访问的时间越近,价值分数越高。
- 访问成本(Cost):缓存数据的访问成本越高(如LLM调用成本、工具调用成本),价值分数越高。
- 缓存容量占用(Size):缓存数据占用的缓存容量越大,价值分数越低。
- 相似度阈值(Similarity Threshold):缓存数据的相似度阈值越高(表示越难被命中),价值分数越低。
价值分数的计算公式可以根据业务场景的不同进行调整,例如:
Value Score=Frequency×Recency×CostSize×(1−Similarity Threshold) \text{Value Score} = \frac{\text{Frequency} \times \text{Recency} \times \text{Cost}}{\text{Size} \times (1 - \text{Similarity Threshold})} Value Score=Size×(1−Similarity Threshold)Frequency×Recency×Cost
其中:
- Frequency\text{Frequency}Frequency:缓存数据被访问的次数,归一化到[0,1][0, 1][0,1]之间。
- Recency\text{Recency}Recency:缓存数据被访问的时间间隔的倒数,归一化到[0,1][0, 1][0,1]之间(如当前时间减去最后访问时间为ttt秒,则Recency=11+t/3600\text{Recency} = \frac{1}{1 + t/3600}Recency=1+t/36001,表示1小时内访问过的缓存数据的Recency\text{Recency}Recency至少为0.5)。
- Cost\text{Cost}Cost:缓存数据的访问成本,归一化到[0,1][0, 1][0,1]之间(如LLM调用成本为0.010.010.01,工具调用成本为0.0010.0010.001,则将它们归一化到[0,1][0, 1][0,1]之间)。
- Size\text{Size}Size:缓存数据占用的缓存容量,归一化到[0,1][0, 1][0,1]之间。
- Similarity Threshold\text{Similarity Threshold}Similarity Threshold:缓存数据的相似度阈值,取值范围是[0,1][0, 1][0,1]。
1.3.2 基于价值的缓存淘汰策略的优化技巧
-
价值分数的动态调整:
价值分数的计算公式中的权重(如Frequency的权重、Recency的权重、Cost的权重等)可以根据业务场景的变化进行动态调整,从而提高缓存淘汰策略的效果。例如,在LLM调用成本较高的业务场景下,可以提高Cost的权重;在访问频率较高的业务场景下,可以提高Frequency的权重;在缓存容量有限的业务场景下,可以提高Size的权重。
-
缓存数据的分层淘汰:
可以将缓存数据按照

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)