大模型入门必懂:Token到底是什么?
一、一句话搞懂:Token就是大模型的“文字最小单位”
我们人类看书、说话,是按“字、词、句”来理解的,比如看到“今天天气真好”,我们会自然地把它拆成“今天”“天气”“真好”这几个词来理解。但大模型不一样,它不直接“认识”汉字、英文单词这些原始文字,它只能处理经过拆分和转换的“小片段”——这个小片段,就是Token。
简单来说,Token就是大模型眼里的“文字积木”,不管你输入多长的文本,大模型做的第一件事,就是把文本拆成一个个这样的“积木”,再通过计算这些“积木”的关系,来理解你的需求、生成对应的回答。
举个最直观的例子:我们输入“我喜欢吃苹果”,大模型会把它拆成【我】【喜】【欢】【吃】【苹】【果】这6个Token(中文常用字基本1字对应1个Token);如果输入英文“我喜欢吃苹果”(I like eating apples),则会拆成【I】【like】【eat】【ing】【apples】这5个Token。
二、为什么大模型非要拆成Token?不拆不行吗?
很多人会疑惑,直接让大模型识别文字不好吗?为啥非要多此一举拆成Token?其实答案很简单——大模型“读不懂”原始文字,它只认识“数字”。
大模型的本质是复杂的数学模型,所有的计算都是基于数字进行的。而我们输入的文字(不管是中文、英文),对它来说就是一堆无意义的符号,必须先通过一个叫“Tokenizer(分词器)”的工具,把这些文字拆成Token,再把每个Token转换成对应的数字ID,大模型才能进行后续的理解和生成操作。
打个比方,这就像我们去国外买东西,对方听不懂中文,我们需要把中文转换成对方能听懂的语言(比如英文),才能顺利沟通。Token,就是大模型能“听懂”的“语言单位”,分词器就是那个“翻译官”。
三、中文&英文Token换算
很多人关心,1个Token到底对应多少个汉字、多少个英文单词?其实没有绝对固定的换算比例(因为分词规则会根据模型不同有细微差异),但有两个非常实用的粗略换算公式,日常使用完全够用:
中文Token换算
- 常用汉字:1个汉字 ≈ 1个Token(比如“你好”就是2个Token,“明天去公园”就是5个Token)
- 标点符号:单独算1个Token(比如“!”“,”“?” each都是1个Token)
- 生僻词、长词:可能会被拆成多个Token(比如“魑魅魍魉”,可能会拆成4个Token;“人工智能”一般是4个Token,个别模型会合并为1个)
核心记住:100个Token ≈ 70~80个汉字;1000个Token ≈ 700~800个汉字(比如一篇500字的短文,大概需要600~700个Token)。
英文Token换算
- 短单词:1个单词 ≈ 1个Token(比如“hello”“cat”“go”,都是1个Token)
- 长单词:会被拆分成多个Token(比如“unhappiness”,会拆成“un”+“happiness”,共2个Token;“information”一般是1个Token,极长单词会拆分为2个)
核心记住:100个Token ≈ 75个英文单词;1000个Token ≈ 750个英文单词(一篇300词的英文短文,大概需要400个Token)。
四、Token和我们用大模型有啥关系?
搞懂了Token是什么,更重要的是搞懂它的实际意义——它直接影响我们使用大模型的体验、成本和限制,这3点一定要记牢:
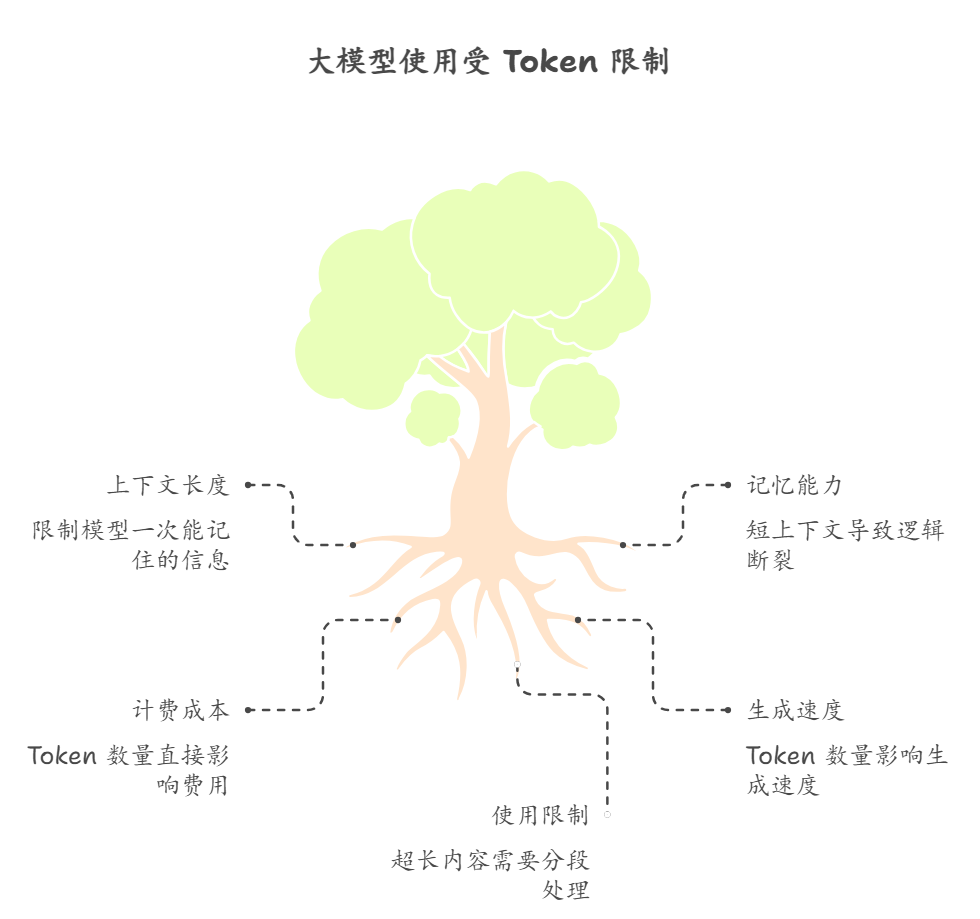
1. 决定“上下文长度”
我们常说某模型支持“8k Token”“32k Token”,这里的Token数量,就是模型一次能处理的最大文本长度(也就是上下文窗口)。比如支持8k Token的模型,一次最多能处理约5000~6000个汉字,如果你输入的文本(比如一篇长论文、一段多轮对话)超过这个长度,模型就会“记不住”前面的内容,后续生成的回答就会偏离主题、逻辑断裂。
比如你用8k Token的模型,粘贴一篇8000字的文章让它总结,模型会自动截断前面的内容,只处理后面的部分,导致总结不完整——这就是Token长度限制的影响。
2. 决定“使用成本”
绝大多数大模型的API调用(比如企业使用、开发者调用),都是按Token数量计费的,而且是“输入+输出”都算Token。比如你输入100个Token的Prompt(提示词),模型输出500个Token的回答,总共就会消耗600个Token,按对应的单价收费。
这也是为什么很多人用API时,会尽量精简提示词——减少输入Token,就能降低使用成本。
3. 决定“生成速度”
模型生成回答时,是逐Token生成的,Token数量越多,生成所需的时间就越长。比如生成100个Token的回答,可能只要1~2秒;但生成1000个Token的回答,可能需要5~10秒(具体看模型性能)。如果你的需求是快速得到简短回复,就可以控制输出Token的数量,提升响应速度。
五、最后总结Token的核心
Token就是大模型的“文字计量单位”,用来衡量文本长度、计算使用成本、限制处理范围。中文粗略记“1Token≈0.7~0.8个汉字”,英文记“1Token≈0.75个单词”,日常使用完全够用。
以后再看到“Token限制”“Token计费”,就不会再懵啦——知道它是什么、怎么换算、有啥影响,就能更高效地使用大模型,避免踩坑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)