MIDiffusion基于互信息引导扩散在零样本跨模态医学图像翻译中的应用

文献提出了一种新的无监督零样本学习方法,称为互信息引导扩散模型,该方法通过利用不同模态之间互信息的固有统计一致性,学习将看不见的源图像转换为目标模态。
一、研究背景
- 在医学图像领域,跨模态医学图像翻译是一种有前景的解决模态缺失的方案;
- 尝试在无源域训练数据的情况下进行跨模态转换,这一任务被称为零样本跨模态转换;
- 现有模型的局限(本文提出的方法隶属于扩散模型范畴)
基于映射的模态转换方法需要配对数据,构建源模态与目标模态之间的直接映射关系;
GAN通常需要设计复杂的对抗架构,并且针对不同的转换任务还需设计特定于模态任务的损失函数;
基于分数的生成模型,扩散模型,主要说了两个模型:
SDEdit方法,采用扩散模型(Diffusion Model) 进行图像转换,通过零样本学习的方式在保真度与真实感之间取得平衡,但其依赖基于扰动的引导方式,需要优化初始时间;
SynDiff方法,这是一种具有双边扩散结构的循环一致性架构,用于保证语义一致性,但计算成本翻倍,需要预训练一个生成器来估计配对的源域图像;
我们方法的动机是通过利用跨不同领域的图像中常见的统计特征一致性来引导扩散过程,从而克服现有跨模态翻译方法的零样本学习挑战。
统计特征用于扩散引导核心逻辑在于:对于同一物体的不同模态成像,尽管观测结果存在差异,但不同模态下的统计语义特征应保持一致性。基于这一假设,我们可通过所提互信息算法在统计空间中提取这些一致性特征,并利用它们调节扩散过程,最终生成目标模态影像
图2 对比了所提方法中基于扰动的调节方式与基于统计特征的调节方式(即局部互信息调节,LMI)在扩散引导机制上的差异;
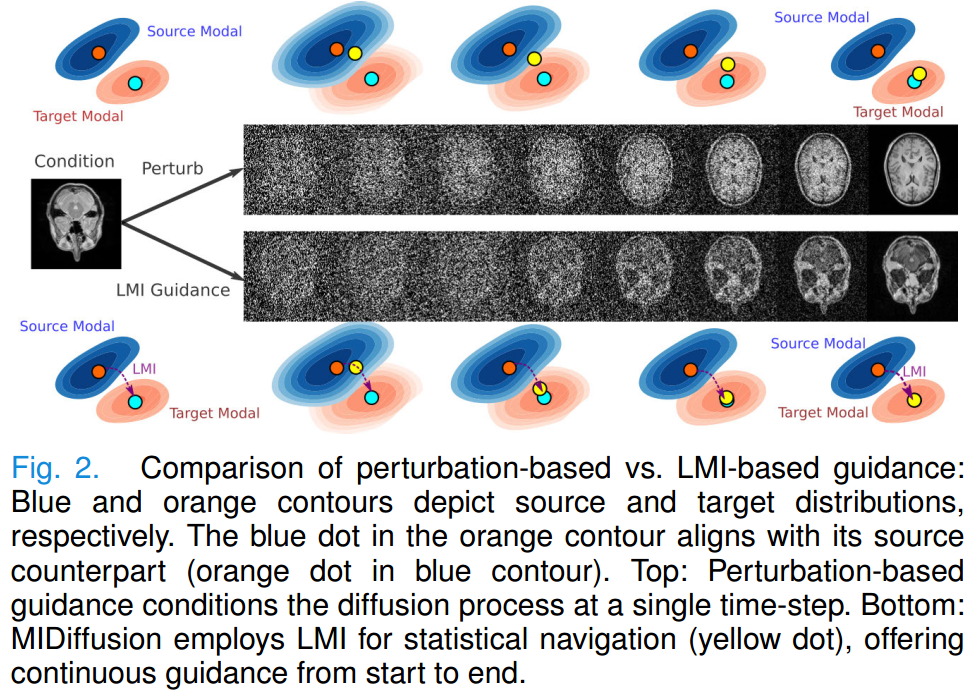
上图:基于扰动的引导仅在单个时间步对扩散过程进行调节;
下图:MIDiffusion(互信息引导扩散模型)采用局部互信息(LMI)进行统计引导(黄色点),持续引导。
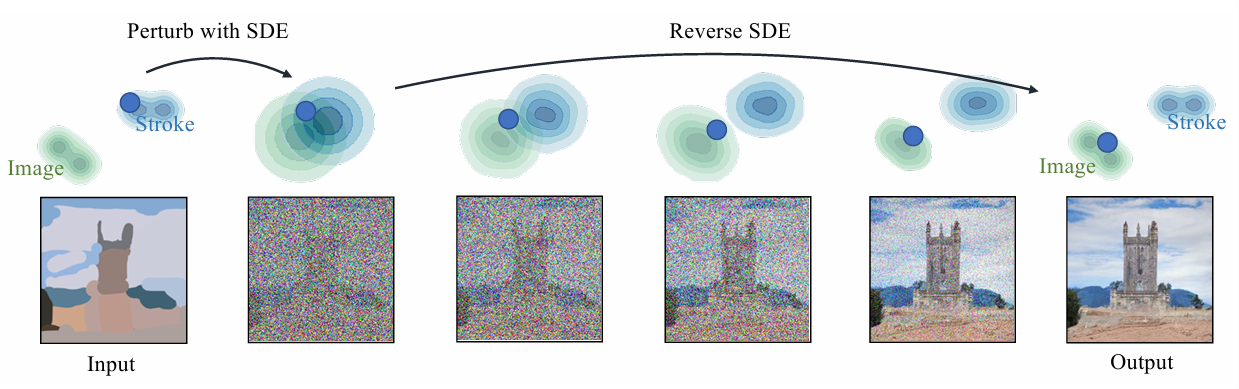
(上图来源SDEdit-使用随机微分方程进行引导图像合成和编辑)
以SDEdit为例,基于扰动的扩散方法流程为:
1.正向扰动,训练阶段,对目标域干净图像F0施加随时间步t增强的噪声,生成扰动图像Ft,模拟“真实分布”退化到“噪声分布”,让模型学习目标域的分布特征;
2.反向引导,测试阶段,先对源域图像G施加噪声扰动至某一中间时间步t0,再以该扰动图像为初始值,通过反向去噪生成目标模态图像𝐹。此时,扰动的强度与起始时间步t0需手动优化。
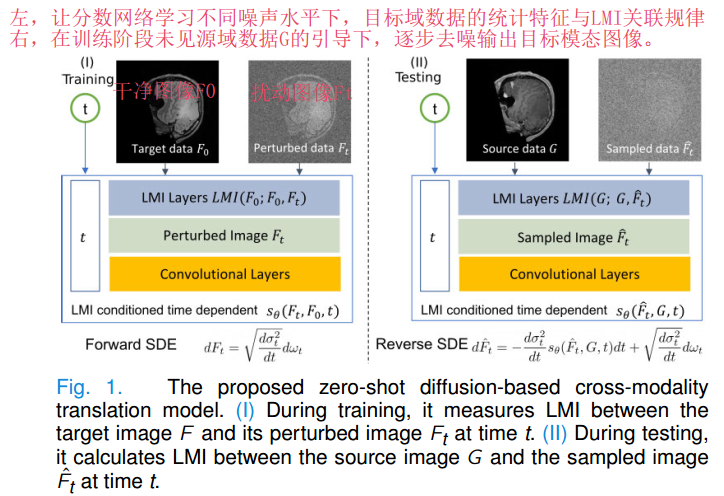
针对每个时间步t,模型都会计算图像之间的局部互信息LMI,作为统计引导嵌入分数网络sθ。
图像输入→卷积层提取特征→基于特征计算 LMI→特征 + LMI + 时间步t融合→输入分数网络
- 训练阶段:用LMI让分数网络学会“如何基于统计一致性进行去噪”;
- 测试阶段:将统计一致性的参考对象从目标域内部F与Ft迁移为跨模态G与hat{Ft},用LMI指导分数网络完成跨模态语义对齐;
二、相关工作
1.基于生成学习的跨模态图像翻译
已有大量研究通过条件生成对抗网络(cGAN)探索跨模态图像转换;
2.基于分数的生成式学习(扩散模型)
Song 等人 [29] 提出了一种基于随机微分方程(SDE)的框架;一些研究利用注意力机制来调节扩散模型;一些工作集中在扩散模型中的文本到图像引导或图像引导;Diff模型利用了来自分类器引导的软标签引导技术。
3.零样本学习
当无法获取源模态数据时(在训练阶段未接触过某类数据),便需要用到基于零样本学习(ZSL)的跨模态图像转换技术。
基于学习的方法在处理未见过的数据时往往存在局限性,而零样本学习能够有效解决这一问题。传统零样本学习方法通过判别式方法或生成式模型将图像特征空间直接投影到语义空间。
“基于学习的方法”(Learning-Based Methods)是一类通过从数据中自动学习规律、模式或决策规则来解决问题的方法论,核心是让系统 / 模型通过 “经验(数据)” 提升性能,而非依赖人工预先编写的固定规则。
4.基于零样本学习的跨模态图像转换
基于零样本学习的生成对抗网络;基于扰动扩散的跨模态图像转换
三、预备知识
1.跨模态图像转换
源域图像G∈V与目标域图像F∈U的跨模态图像转换可形式化为:
![]()
其中,𝛷𝐹表示一个映射算子,能源数据G映射到目标域数据𝐹,理想状态下𝐹应与目标域中的真实数据F一致。
在零样本跨模态影像转换中,训练阶段仅能获取目标域样本F。零样本学习的目标是在训练阶段未见过源域数据G的情况下,学习得到算子𝛷𝐹。由于训练阶段无法获取源域样本,构建并利用辅助信息实现域迁移至关重要。
2.互信息
互信息用于度量两个随机变量之间的相关性,依赖程度;
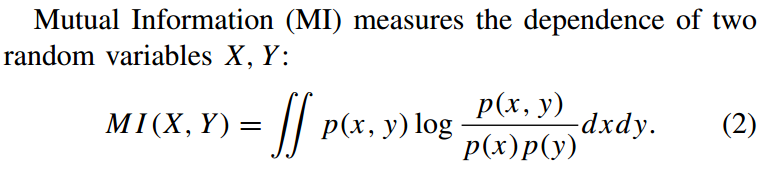
特别地,MI(X,X)称为熵。
在跨模态相关任务中,互信息具有重要应用价值,这是因为不同模态的统计特征被假设为一致的。
3.分数匹配及其去噪等价形式
基于分数的模型通过学习概率分布logp(x)的偏导数∂logp𝑥∂𝑥(即分数函数)来表示该概率分布;![]()
去噪分数匹配通过直接估计分数函数来规避明确数据真实分布的复杂形式,目标函数定义为:
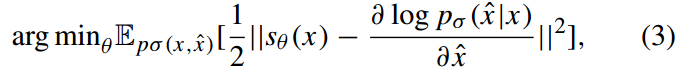
4.基于随机微分方程SDE的分数生成建模
在随机微分框架SDE中,神经网络𝑠𝜃以隐式去噪的形式进行训练,具体而言,将加噪步骤视为一个扩散过程。在势函数Ut(x)的作用下,由标准正态分布N(0,1)驱动的扩散过程可通过随机微分方程建模为:
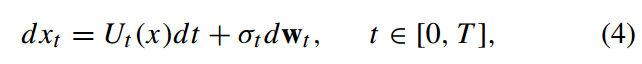
其中,σt∈[0,∞)用于控制输入噪声的强度,wt表示维纳过程,t表示时间变量取值从 0 开始,以无穷小增量逐步变化到T;
由式 (4) 定义的扩散过程,其训练目标与式 (3) 的去噪分数匹配目标具有相似性,但前者需考虑时间t在区间[0,T]上的均匀采样期望;因此,其训练目标变为多步条件分布q(xt|x0)的匹配,而非单步条件分布𝑞(𝑥|𝑥)的匹配,具体形式:
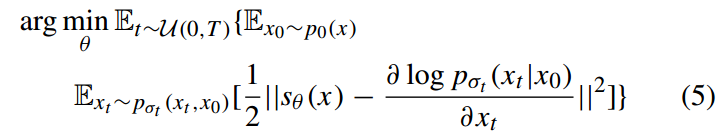
当分数模型𝑠𝜃学习到分布分数后,可通过反向随机微分方程,按时间T到0的逆向动态过程进行数据采样,反向随机微分方程形式:
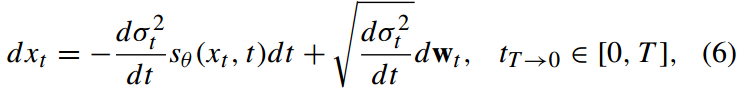
四、模型方法
1.跨模态翻译
我们通过将目标数据F生成任务适配到分数匹配的框架中,然后使用扰动的源域G来引导,来实现跨模态图像平移。
我们希望生成的数据hat(F)遵循引导数据G的语义含义,并将特征共享为目标域真实F,从而平衡真实性和忠实性。
真实性realism:生成图像转换到目标域F;
忠实性faithfulness:忠实的从引导数据G转换而来,即hat(F)与G相似;
2.扩散生成中的互信息引导
在基于零样本学习的转换任务中,训练过程中无法获取源域数据。尽管如此,我们假设源模态与目标模态之间的局部统计特征是一致的。互信息(MI)最大化已被证实是一种有效的方法,能够使神经网络学习非线性表示 。为捕捉这些共享表示并利用提取的信息进行引导,我们提出在去噪过程中采用互信息来度量局部统计表示。
2.1局部互信息local wise MI
由于互信息(MI)是一种统计度量指标,若要从数据中获取用于引导的语义信息,需先将原始数据转换为其统计表示形式。
所以,用像素点处xi邻域的概率密度函数PDF,来捕捉位置i处的局部统计信息。
给出了图像X到图像Y在点xi处的局部互信息,定义:
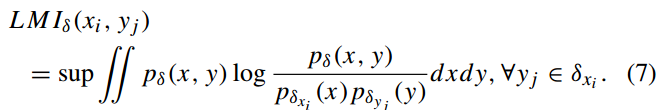
在前向步骤(训练),我们使用等式7作为参考信号来调节每个扩散步骤;这通过在评分神经网络的训练过程期间计算LMI(x0,yt)来实现。
基于局部互信息定义了卡方测度:

CSLMI的值越低,表明两种模态之间的LMI差异越小(统计特征差异越小),根据Thm.2,这会带来更好的翻译性能。
核心用途是量化两种模态之间的可转换性,为判断MIDiffusion模型是否适用于特定跨模态图像转换任务提供定量依据。
2.2可微分局部互信息层
然而局部互信息LMI的计算成本极高,为克服在分数匹配模型中应用局部互信息时存在的这一瓶颈,我们提出了一种高效方法,可在扰动步骤和去噪步骤中均完成局部互信息的计算。
两个定义:周期延拓、K步滑动延拓

给了命题1:在两个定义的基础上,计算局部互信息;通过将迭代互信息计算转换为张量运算来加速MI计算。
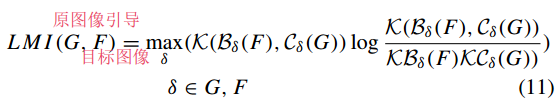
3.条件因子嵌入随机微分方程
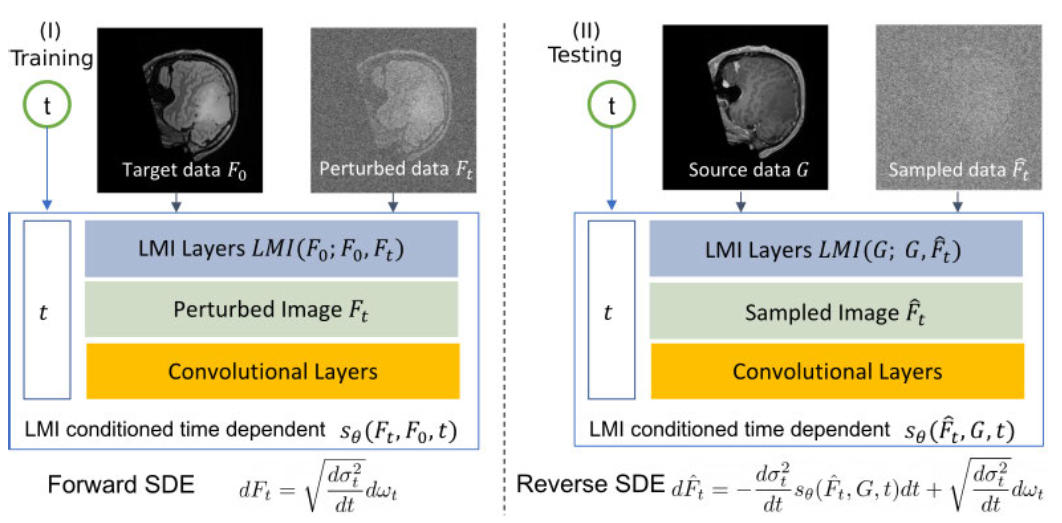
(左)在训练阶段,将目标数据F和中间扰动数据Ft的互信息LMI嵌入分数网络sθ中,来调节噪声扰动过程,
修改后的分数匹配训练目标实现:
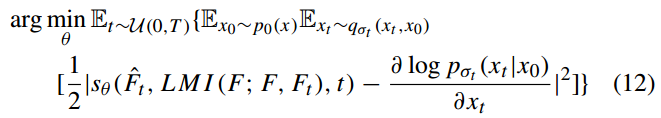
(右)在采样步骤中(测试),生成过程是反向随机微分方程SDE的迭代求解过程。我们可将所提出的调节流程应用于该随机微分方程:
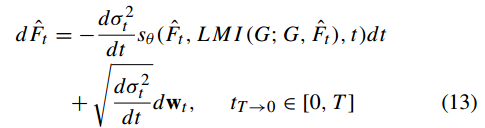
互信息引导扩散模型算法流程:

其中,该LMI是根据具有单位权重的看不见的引导图像G计算的,并使用朴素的Euler Maruyama数值求解器求解SDE。
输入:源域引导图像G,经训练的分数网络sθ,t,dt离散化步长
输出:高保真目标域图像𝐹
初始化所有参数与变量
迭代去噪:t→T
采样随机噪声
更新时间步长
计算噪声强度差(由正向SDE噪声函数推导,控制去噪幅度)
更新采样图像:分数网络输出去噪梯度,引导生成方向
五、实验
1.数据集(3个)切片数据
- Gold Atlas数据集包括19名男性患者的CT和T1加权(T1w)和T2加权(T2w)磁共振成像(MRI)数据。(xiazai)
- 公开的CuRIOUS数据集由22名低级别胶质瘤患者组成。本实验选择了T1w和FLAIR MRI扫描对。(xiazai)
- IXI数据集包括来自正常受试者的预先对齐的600幅图像。本实验选择PD-T1w翻译任务。
此外,我们利用IXI来自100名训练对象和25名测试对象的所有切片来训练和评估MIDiffusion模型的3D版本,从而展示其在基于3D零样本学习的跨模态分割中的下游应用。
2.baselines
两种具有代表性的基于GAN的图像翻译方法和两种最先进的基于扩散的方法作为比较基准。
(1)CycleGAN(少样本监督学习)
(2)基于GAN逆映射(GAN inversion)的无监督方法
(3)EGSDE(监督少样本学习)一种无配对影像转换方法
(4)SDEdit(无监督零样本学习)SDEdit是另一种基于扩散模型的转换方法,属于无监督零样本学习模型,其核心通过“分布扰动引导”实现转换。
3.评估指标
SSIM (structuralsimilarity index measure, higher better),
GMSD (gradient magnitude similarity deviation),
PSNR (peak signal-tonoise ratio),
MSE (mean square error),
FID (Fréchet Inception Distance),
MI (mutual information);
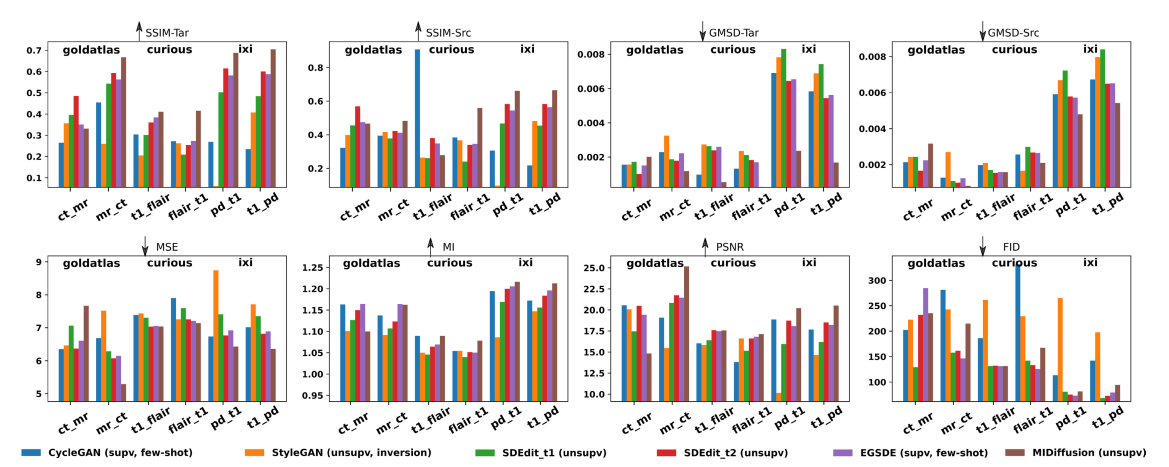
4.与基础模型比较分析(定量,定性)
定量:
定性:
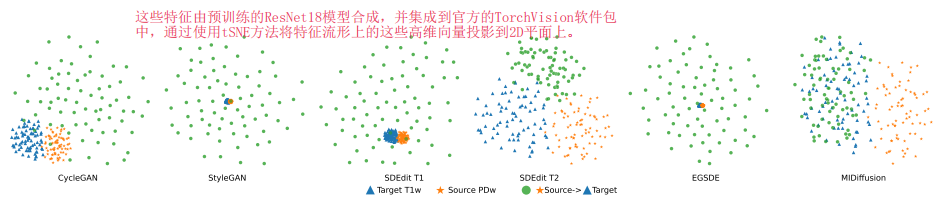
MIDiffusion实现了翻译后的(绿色)和目标(蓝色)特征之间的最佳对齐,这强调了MIDiffusion在基于零触发学习的数据翻译任务中的有效性。
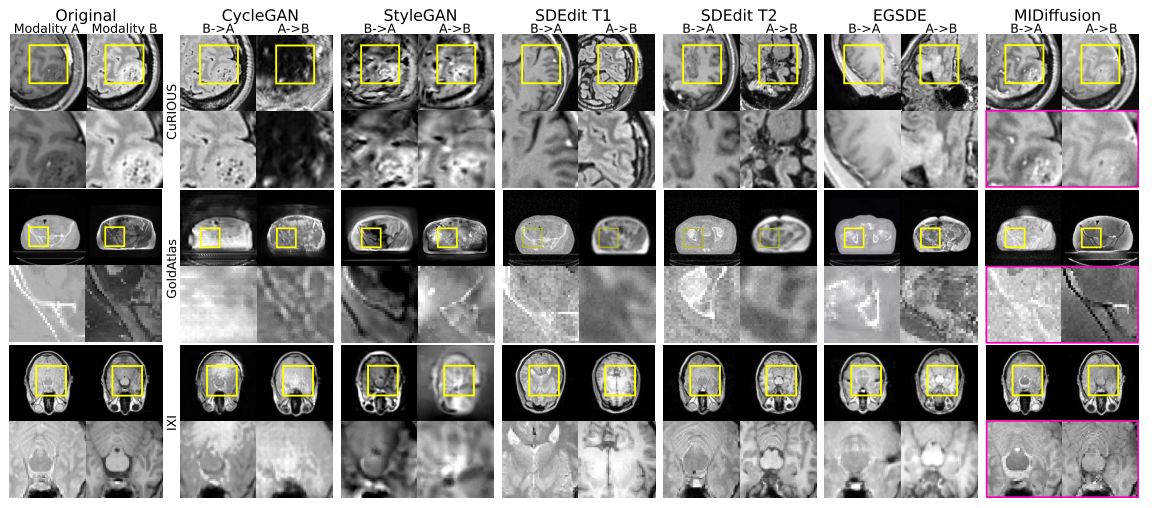
特别地,GoldAtlas数据上,CT→MR任务,MIDdiffusion未能与其他基线竞争。说明,当两种模态(如骨盆CT与MR)之间存在显著的统计不一致时,使用MID扩散是不可行的。
5.演示跨模态图像翻译在3D图像分割中的实际应用-证明了该方法在下游应用中的有效性
SDEdit的3D版本作为基线方法,T2,PD生成T1,生成后的图像用工具箱分割。(FreeSurfer[89]分割工具箱)
根据分割结果计算了25个受试者的30个解剖标签的Dice评分进行定量分析;基于测试集中患者的3D平移结果定性分析,结果比SDEdit好。
六、讨论:
本研究通过实验验证了:在无监督零样本学习跨模态影像转换任务中,利用统计信息引导扩散过程具备显著有效性。所提方法以条件扩散模型为核心,在学习目标数据分布分数函数的同时,联合学习统计语义特征,形成了兼顾零样本场景适配性与转换性能的解决方案。这种将统计特征用于扩散引导核心逻辑在于:对于同一物体的不同模态成像,尽管观测结果存在差异,但不同模态下的统计语义特征应保持一致性。基于这一假设,我们可通过所提互信息算法在统计空间中提取这些一致性特征,并利用它们调节扩散过程,最终生成目标模态影像。
MIDdiffusion局限
1.它需要迭代步骤来解决SDE问题,在Nvidia Tesla V100 GPU上翻译一张图像需要几十秒。与EGSDE的单个去噪步骤0.76秒和SDEdit的0.31秒相比,它仍然慢到0.82秒。
2.当两种模态(如骨盆CT与MR)之间存在显著的统计不一致时,使用MID扩散是不可行的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)