手把手教你做 AI 猫狗分类【PyTorch 从数据处理到模型保存一站式实现】

一、技术栈概述
1.1 前端技术栈
| 类别 | 技术/工具 | 版本 | 用途说明 |
|---|---|---|---|
| 核心语言 | HTML5 | - | 页面结构,语义化标签,表单和输入控件 |
| CSS3 | - | 样式设计,响应式布局,动画效果 | |
| JavaScript (ES6+) | - | 交互逻辑,API调用,事件处理 | |
| UI框架 | 原生JavaScript | - | 不依赖框架,轻量级实现 |
| UI组件库 | Font Awesome | 6.0+ | 图标库,界面图标展示 |
| 布局技术 | Flexbox | - | 弹性盒模型布局 |
| CSS Grid | - | 网格布局系统 | |
| 网络请求 | Fetch API | - | 与后端API通信,异步数据获取 |
| 文件处理 | File API | - | 文件上传和读取 |
| Drag & Drop API | - | 拖放文件上传功能 | |
| 本地服务器 | Python HTTP Server | - | 本地静态文件服务 |
1.2 后端技术栈
| 类别 | 技术/工具 | 版本 | 用途说明 |
|---|---|---|---|
| Web框架 | Flask | 2.3.0 | 轻量级Web框架,RESTful API开发 |
| Flask-CORS | 4.0.0 | 跨域资源共享支持 | |
| 深度学习框架 | PyTorch | 2.0.0 | 深度学习模型构建和训练 |
| torchvision | 0.15.0 | 计算机视觉工具,数据预处理 | |
| 数据处理 | NumPy | 1.24.0 | 数值计算,数组操作 |
| Pillow (PIL) | 9.5.0 | 图像处理,图片格式转换 | |
| 科学计算 | scikit-learn | 1.2.0 | 机器学习工具,评估指标 |
| 可视化 | Matplotlib | 3.7.0 | 数据可视化,训练曲线绘制 |
| 编程语言 | Python | 3.8+ | 后端主要开发语言 |
1.3 模型相关技术
| 类别 | 技术/工具 | 用途说明 |
|---|---|---|
| 神经网络架构 | CNN (卷积神经网络) | 猫狗图像分类模型 |
| 网络层类型 | Conv2d | 卷积层,特征提取 |
| BatchNorm2d | 批归一化层,加速训练 | |
| MaxPool2d | 最大池化层,下采样 | |
| Linear | 全连接层,分类决策 | |
| Dropout | 正则化层,防止过拟合 | |
| 激活函数 | ReLU | 激活函数,非线性变换 |
| Softmax | 输出层激活,概率分布 | |
| 损失函数 | CrossEntropyLoss | 分类损失函数 |
| 优化器 | Adam | 自适应优化算法 |
| 学习率调度 | StepLR | 学习率衰减策略 |
| 数据处理 | DataLoader | 数据批量加载 |
| Transform | 数据预处理和增强 |
1.4 项目架构
| 类别 | 技术/模式 | 用途说明 |
|---|---|---|
| 架构风格 | 前后端分离 | 前端独立,后端API服务 |
| 通信协议 | HTTP/HTTPS | 网络通信协议 |
| 数据格式 | JSON | 前后端数据交换格式 |
| 文件格式 | FormData | 文件上传数据格式 |
| API设计 | RESTful API | REST风格接口设计 |
| 模块化 | Python模块 | 代码组织和管理 |
| 虚拟环境 | venv | Python环境隔离 |
1.5 开发工具和环境
| 类别 | 工具/技术 | 用途说明 |
|---|---|---|
| 包管理 | pip | Python包管理工具 |
| 虚拟环境 | venv | 创建隔离的Python环境 |
| 代码编辑 | 任意编辑器 | VS Code, PyCharm, Vim等 |
| 版本控制 | Git | 代码版本管理 |
| 终端/命令行 | 系统终端 | 项目运行和操作 |
1.6 部署技术
| 类别 | 工具/技术 | 用途说明 |
|---|---|---|
| 开发服务器 | Flask内置服务器 | 开发环境运行 |
| 生产服务器 | Gunicorn | WSGI HTTP服务器 |
| uWSGI | 另一种WSGI服务器 | |
| 容器化 | Docker | 应用容器化部署 |
| Docker Compose | 多容器编排 | |
| Web服务器 | Nginx | 反向代理,静态文件服务 |
| Apache | 可选Web服务器 |
1.7 测试和监控
| 类别 | 工具/技术 | 用途说明 |
|---|---|---|
| 单元测试 | unittest | Python单元测试框架 |
| API测试 | requests | HTTP请求库,API测试 |
| 性能监控 | 自定义监控 | 响应时间,准确率监控 |
1.8 数据管理
| 类别 | 工具/技术 | 用途说明 |
|---|---|---|
| 数据获取 | Kaggle API | 数据集下载(可选) |
| 数据格式 | 图片格式 | JPG, PNG, JPEG |
| 数据组织 | 目录结构 | 按类别分文件夹存储 |
1.9 功能特性对应技术
| 功能特性 | 实现技术 |
|---|---|
| 图片上传 | HTML5 File API + Flask文件接收 |
| 拖放上传 | HTML5 Drag & Drop API |
| 图片预览 | FileReader API + Canvas |
| 模型训练 | PyTorch训练循环 |
| 模型预测 | PyTorch推理 + Flask API |
| 批量处理 | FormData多文件上传 |
| 进度显示 | 自定义加载动画 |
| 响应式设计 | CSS媒体查询 + Flexbox/Grid |
| 结果可视化 | CSS动画 + 进度条 |
| 错误处理 | JavaScript异常捕获 + Flask错误处理 |
1.10 浏览器兼容性
| 浏览器 | 支持情况 | 说明 |
|---|---|---|
| Chrome | ✅ 完全支持 | 60+版本 |
| Firefox | ✅ 完全支持 | 60+版本 |
| Safari | ✅ 完全支持 | 12+版本 |
| Edge | ✅ 完全支持 | 79+版本 |
| IE | ❌ 不支持 | 不兼容现代API |
1.11 安全技术
| 安全方面 | 技术措施 |
|---|---|
| 文件上传安全 | 文件类型验证,大小限制 |
| 跨域安全 | CORS配置 |
| 输入验证 | 前端+后端双重验证 |
| 错误处理 | 安全的错误信息返回 |
1.12 性能优化技术
| 优化方面 | 技术措施 |
|---|---|
| 前端性能 | 图片压缩,懒加载,缓存 |
| 后端性能 | 模型量化,GPU加速,批处理 |
| 网络性能 | 连接复用,响应压缩 |
二、项目结构
cat-dog-classifier/
├── backend/
│ ├── app.py # Flask后端主程序
│ ├── model.py # 模型定义
│ ├── train.py # 训练脚本
│ ├── utils.py # 工具函数
│ ├── requirements.txt # Python依赖
│ └── static/ # 静态文件
├── frontend/
│ ├── index.html # 前端页面
│ ├── style.css # 样式文件
│ └── script.js # 交互脚本
├── data/ # 数据集目录
├── models/ # 保存的模型
└── README.md # 项目说明
三、环境搭建
3.1 Python环境配置
# 创建项目目录
mkdir cat-dog-classifier
cd cat-dog-classifier
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
# Windows:
venv\Scripts\activate
# Linux/Mac:
source venv/bin/activate
3.2 安装依赖
创建 backend/requirements.txt:
torch==2.0.0
torchvision==0.15.0
flask==2.3.0
flask-cors==4.0.0
pillow==9.5.0
numpy==1.24.0
matplotlib==3.7.0
scikit-learn==1.2.0
requests
kaggle~=2.0.1
kagglehub~=1.0.0
安装依赖:
cd backend
pip install -r requirements.txt
四、项目源码
4.1 模型定义 (backend/model.py)
"""
猫狗分类模型定义
基于CNN的卷积神经网络模型
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class CatDogClassifier(nn.Module):
"""
猫狗分类器模型
使用卷积神经网络结构
"""
def __init__(self, num_classes=2):
"""
初始化模型
参数:
num_classes: 分类数量,默认2(猫和狗)
"""
super(CatDogClassifier, self).__init__()
# 卷积层块1: 提取低级特征
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
# 卷积层块2: 提取中级特征
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
# 卷积层块3: 提取高级特征
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
# 最大池化层
self.pool = nn.MaxPool2d(2, 2)
# Dropout层防止过拟合
self.dropout = nn.Dropout(0.5)
# 全连接层
self.fc1 = nn.Linear(128 * 28 * 28, 512) # 假设输入图片大小为224x224
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, num_classes)
def forward(self, x):
"""
前向传播
参数:
x: 输入图片张量
返回:
分类概率
"""
# 卷积块1
x = self.pool(F.relu(self.bn1(self.conv1(x))))
# 卷积块2
x = self.pool(F.relu(self.bn2(self.conv2(x))))
# 卷积块3
x = self.pool(F.relu(self.bn3(self.conv3(x))))
# 展平特征图
x = x.view(x.size(0), -1)
# 全连接层
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
def create_simple_model():
"""
创建一个简化版本的模型
适合快速训练和测试
"""
model = nn.Sequential(
nn.Conv2d(3, 16, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(64 * 28 * 28, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 2)
)
return model
if __name__ == "__main__":
# 测试模型
model = CatDogClassifier()
sample_input = torch.randn(1, 3, 224, 224)
output = model(sample_input)
print(f"模型输出形状: {output.shape}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
4.2 数据准备和训练脚本 (backend/train.py)
"""
猫狗分类模型训练脚本
包含数据加载、模型训练、评估和保存功能
"""
import os
import time
import warnings
from PIL import Image, UnidentifiedImageError
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split, Dataset
from torchvision import datasets, transforms
from torchvision.datasets.folder import default_loader
from model import create_simple_model
# 忽略图片警告
warnings.filterwarnings("ignore", category=UserWarning)
# ---------------------- 新增:自定义数据集,自动跳过损坏图片 ----------------------
class SafeImageFolder(Dataset):
def __init__(self, root, transform=None):
self.dataset = datasets.ImageFolder(root=root)
self.transform = transform
self.classes = self.dataset.classes
self.class_to_idx = self.dataset.class_to_idx
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
# 循环尝试,直到拿到有效图片
while True:
try:
path, label = self.dataset.samples[idx]
# 安全加载图片
image = default_loader(path)
if self.transform:
image = self.transform(image)
return image, label
except (UnidentifiedImageError, OSError, IOError):
# 损坏图片:跳过,取下一个
idx = (idx + 1) % len(self.dataset)
continue
# ---------------------- 原函数修改:使用安全数据集 ----------------------
def prepare_data(data_dir='../data', batch_size=32, img_size=224):
"""
准备训练和验证数据(自动跳过损坏图片)
"""
# 数据增强和预处理
train_transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 使用安全数据集
full_dataset = SafeImageFolder(
root=data_dir,
transform=train_transform
)
# 划分训练集和验证集
train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
# 验证集使用不同的transform
val_dataset.dataset.transform = val_transform
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0, # 关键:多线程会导致异常无法捕获,必须设为0
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0, # 关键
pin_memory=True
)
return train_loader, val_loader, full_dataset.classes
# ---------------------- 以下代码完全不变 ----------------------
def train_model(model, train_loader, val_loader, epochs=10, lr=0.001):
"""
训练模型
"""
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 记录训练历史
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
# 训练循环
for epoch in range(epochs):
start_time = time.time()
# 训练一次
# if epoch >= 1:
# break
# 训练阶段
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
for batch_idx, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
optimizer.step()
# 统计
train_loss += loss.item()
_, predicted = outputs.max(1)
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
if batch_idx % 10 == 0:
print(f'Epoch: {epoch + 1}/{epochs} | '
f'Batch: {batch_idx}/{len(train_loader)} | '
f'Loss: {loss.item():.4f}')
# 验证阶段
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
val_total += labels.size(0)
val_correct += predicted.eq(labels).sum().item()
# 计算指标
avg_train_loss = train_loss / len(train_loader)
avg_val_loss = val_loss / len(val_loader)
train_accuracy = 100. * train_correct / train_total
val_accuracy = 100. * val_correct / val_total
# 记录历史
history['train_loss'].append(avg_train_loss)
history['val_loss'].append(avg_val_loss)
history['train_acc'].append(train_accuracy)
history['val_acc'].append(val_accuracy)
# 更新学习率
scheduler.step()
epoch_time = time.time() - start_time
print(f'\nEpoch {epoch + 1}/{epochs} 完成')
print(f'时间: {epoch_time:.2f}s')
print(f'训练损失: {avg_train_loss:.4f} | 训练准确率: {train_accuracy:.2f}%')
print(f'验证损失: {avg_val_loss:.4f} | 验证准确率: {val_accuracy:.2f}%')
print('-' * 50)
return model, history
def plot_training_history(history, save_path='../models/training_history.png'):
"""
绘制训练历史图表
"""
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 损失图表
axes[0].plot(history['train_loss'], label='训练损失')
axes[0].plot(history['val_loss'], label='验证损失')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('损失')
axes[0].set_title('训练和验证损失')
axes[0].legend()
axes[0].grid(True)
# 准确率图表
axes[1].plot(history['train_acc'], label='训练准确率')
axes[1].plot(history['val_acc'], label='验证准确率')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('准确率 (%)')
axes[1].set_title('训练和验证准确率')
axes[1].legend()
axes[1].grid(True)
plt.tight_layout()
os.makedirs(os.path.dirname(save_path), exist_ok=True)
plt.savefig(save_path, dpi=100)
plt.show()
def save_model(model, path='../models/cat_dog_classifier.pth'):
"""
保存模型
"""
os.makedirs(os.path.dirname(path), exist_ok=True)
torch.save(model.state_dict(), path)
print(f"模型已保存到: {path}")
def load_model(model_class, path='../models/cat_dog_classifier.pth', num_classes=2):
"""
加载模型
"""
model = model_class(num_classes=num_classes)
model.load_state_dict(torch.load(path, map_location='cpu'))
model.eval()
return model
def main():
"""主训练函数"""
print("开始训练猫狗分类器...")
# 准备数据
print("准备数据...")
train_loader, val_loader, class_names = prepare_data(
data_dir='../data',
batch_size=32,
img_size=224
)
print(f"类别: {class_names}")
print(f"训练集大小: {len(train_loader.dataset)}")
print(f"验证集大小: {len(val_loader.dataset)}")
# 创建模型
print("创建模型...")
model = create_simple_model()
# 训练模型
print("开始训练...")
trained_model, history = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
epochs=10,
lr=0.001
)
# 绘制训练历史
print("绘制训练历史...")
plot_training_history(history)
# 保存模型
print("保存模型...")
save_model(trained_model)
print("训练完成!")
if __name__ == "__main__":
main()
3.4 后端API (backend/app.py)
"""
Flask后端API服务
提供模型预测接口
"""
from flask import Flask, request, jsonify, send_from_directory
from flask_cors import CORS
import torch
from PIL import Image
import io
import os
from model import create_simple_model
from utils import predict_image
import json
# 创建Flask应用
app = Flask(__name__)
CORS(app) # 允许跨域请求
# 全局变量
model = None
device = None
class_names = ['猫', '狗']
MODEL_PATH = 'models/cat_dog_classifier.pth'
def load_model():
"""加载训练好的模型"""
global model, device
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 创建模型架构
model = create_simple_model()
# 加载模型权重
if os.path.exists(MODEL_PATH):
model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
else:
print(f"警告: 模型文件 {MODEL_PATH} 不存在,使用随机权重")
model.to(device)
model.eval()
print("模型加载完成")
@app.before_first_request
def initialize():
"""在第一个请求之前初始化模型"""
load_model()
@app.route('/')
def index():
"""主页"""
return jsonify({
'status': 'online',
'service': 'Cat Dog Classifier API',
'endpoints': {
'/predict': 'POST - 上传图片进行预测',
'/health': 'GET - 服务健康检查',
'/model_info': 'GET - 获取模型信息'
}
})
@app.route('/health')
def health_check():
"""健康检查接口"""
return jsonify({
'status': 'healthy',
'model_loaded': model is not None,
'device': str(device)
})
@app.route('/model_info')
def model_info():
"""获取模型信息"""
if model is None:
return jsonify({'error': '模型未加载'}), 500
num_params = sum(p.numel() for p in model.parameters())
return jsonify({
'model_name': 'CatDogClassifier',
'parameters': num_params,
'device': str(device),
'classes': class_names
})
@app.route('/predict', methods=['POST'])
def predict():
"""预测接口 - 接收图片并返回预测结果"""
if model is None:
return jsonify({'error': '模型未加载'}), 500
# 检查请求中是否有文件
if 'file' not in request.files:
return jsonify({'error': '没有文件上传'}), 400
file = request.files['file']
# 检查文件是否为空
if file.filename == '':
return jsonify({'error': '没有选择文件'}), 400
try:
# 读取图片
image_bytes = file.read()
image = Image.open(io.BytesIO(image_bytes)).convert('RGB')
# 进行预测
result = predict_image(model, image, class_names, device)
# 返回结果
return jsonify({
'success': True,
'prediction': result['class'],
'confidence': result['confidence'],
'probabilities': [
{'class': class_name, 'probability': prob}
for class_name, prob in zip(result['class_names'], result['probabilities'])
],
'all_classes': class_names
})
except Exception as e:
return jsonify({
'error': f'预测失败: {str(e)}',
'success': False
}), 500
@app.route('/predict_url', methods=['POST'])
def predict_from_url():
"""从URL预测图片"""
if model is None:
return jsonify({'error': '模型未加载'}), 500
data = request.get_json()
if not data or 'url' not in data:
return jsonify({'error': '没有提供URL'}), 400
try:
import requests
from io import BytesIO
# 从URL下载图片
response = requests.get(data['url'])
response.raise_for_status()
image = Image.open(BytesIO(response.content)).convert('RGB')
# 进行预测
result = predict_image(model, image, class_names, device)
return jsonify({
'success': True,
'prediction': result['class'],
'confidence': result['confidence']
})
except Exception as e:
return jsonify({
'error': f'预测失败: {str(e)}',
'success': False
}), 500
@app.route('/batch_predict', methods=['POST'])
def batch_predict():
"""批量预测接口"""
if model is None:
return jsonify({'error': '模型未加载'}), 500
if 'files' not in request.files:
return jsonify({'error': '没有文件上传'}), 400
files = request.files.getlist('files')
if len(files) == 0:
return jsonify({'error': '没有选择文件'}), 400
results = []
for file in files:
try:
# 读取图片
image_bytes = file.read()
image = Image.open(io.BytesIO(image_bytes)).convert('RGB')
# 进行预测
result = predict_image(model, image, class_names, device)
results.append({
'filename': file.filename,
'prediction': result['class'],
'confidence': result['confidence']
})
except Exception as e:
results.append({
'filename': file.filename,
'error': str(e),
'success': False
})
return jsonify({
'success': True,
'results': results,
'total': len(results)
})
if __name__ == '__main__':
# 加载模型
load_model()
# 启动Flask应用
print("启动猫狗分类器API服务...")
print("访问 http://localhost:5000 查看API文档")
app.run(host='0.0.0.0', port=5000, debug=True)
四、前端开发
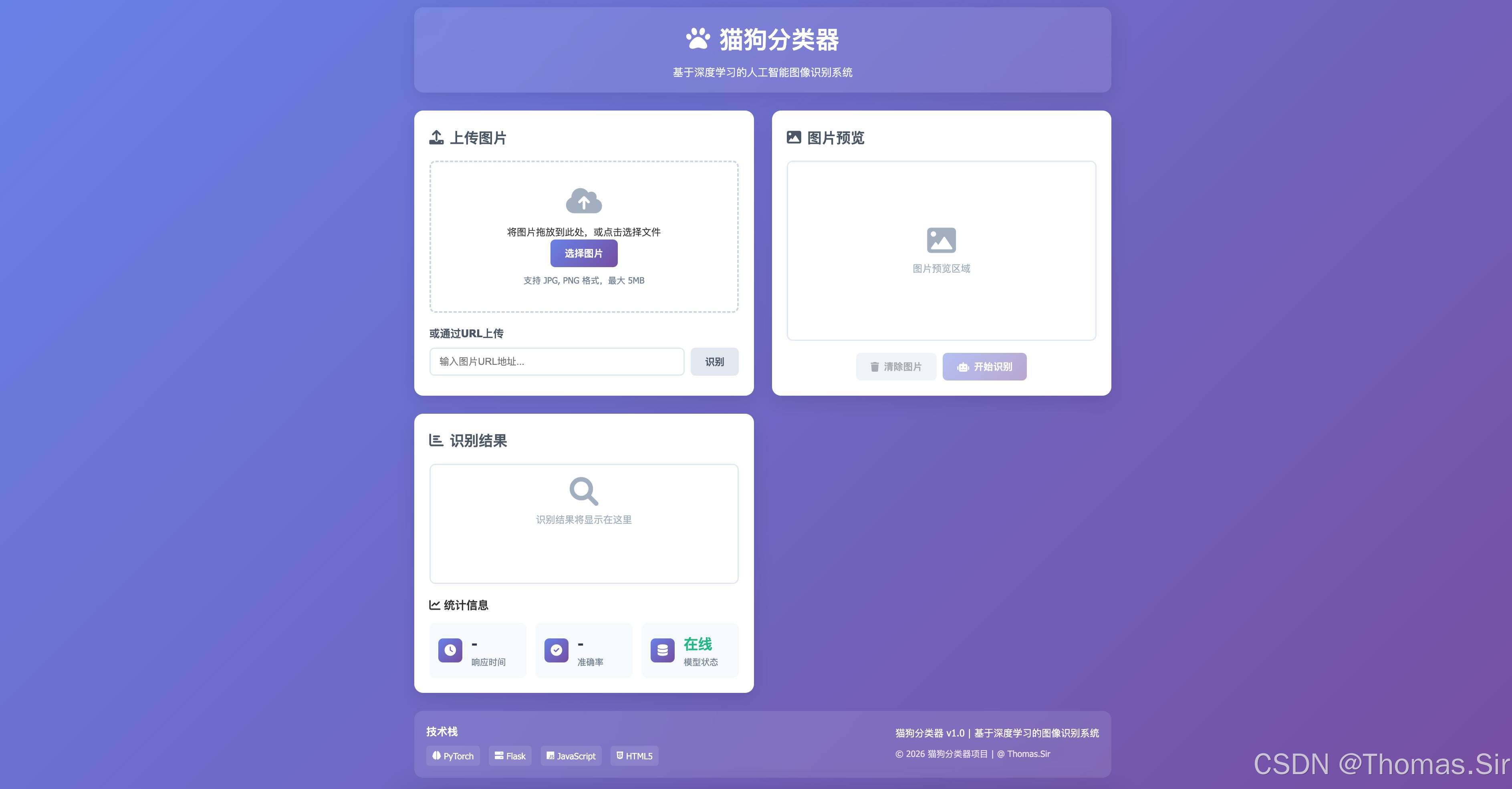
4.1 前端HTML页面 (frontend/index.html)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>猫狗分类器 - AI图像识别</title>
<link rel="stylesheet" href="style.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0/css/all.min.css">
</head>
<body>
<div class="container">
<header class="header">
<h1><i class="fas fa-paw"></i> 猫狗分类器</h1>
<p class="subtitle">基于深度学习的人工智能图像识别系统</p>
</header>
<main class="main-content">
<div class="upload-section">
<h2><i class="fas fa-upload"></i> 上传图片</h2>
<div class="upload-area" id="uploadArea">
<i class="fas fa-cloud-upload-alt upload-icon"></i>
<p>将图片拖放到此处,或点击选择文件</p>
<input type="file" id="imageInput" accept="image/*" hidden>
<button class="btn btn-primary" onclick="document.getElementById('imageInput').click()">
选择图片
</button>
<p class="file-info">支持 JPG, PNG 格式,最大 5MB</p>
</div>
<div class="url-upload">
<h3>或通过URL上传</h3>
<div class="url-input-group">
<input type="text" id="imageUrl" placeholder="输入图片URL地址...">
<button class="btn btn-secondary" onclick="predictFromUrl()">识别</button>
</div>
</div>
</div>
<div class="preview-section">
<h2><i class="fas fa-image"></i> 图片预览</h2>
<div class="preview-container">
<img id="previewImage" src="" alt="预览图片" style="display: none;">
<div id="previewPlaceholder" class="preview-placeholder">
<i class="fas fa-image"></i>
<p>图片预览区域</p>
</div>
</div>
<div class="preview-actions">
<button class="btn btn-secondary" onclick="clearImage()" id="clearBtn" disabled>
<i class="fas fa-trash"></i> 清除图片
</button>
<button class="btn btn-primary" onclick="predictImage()" id="predictBtn" disabled>
<i class="fas fa-robot"></i> 开始识别
</button>
</div>
</div>
<div class="result-section">
<h2><i class="fas fa-chart-bar"></i> 识别结果</h2>
<div id="resultContainer" class="result-container">
<div class="result-placeholder">
<i class="fas fa-search"></i>
<p>识别结果将显示在这里</p>
</div>
</div>
<div class="stats-section">
<h3><i class="fas fa-chart-line"></i> 统计信息</h3>
<div class="stats-grid">
<div class="stat-card">
<div class="stat-icon">
<i class="fas fa-clock"></i>
</div>
<div class="stat-content">
<div class="stat-value" id="responseTime">-</div>
<div class="stat-label">响应时间</div>
</div>
</div>
<div class="stat-card">
<div class="stat-icon">
<i class="fas fa-check-circle"></i>
</div>
<div class="stat-content">
<div class="stat-value" id="accuracy">-</div>
<div class="stat-label">准确率</div>
</div>
</div>
<div class="stat-card">
<div class="stat-icon">
<i class="fas fa-database"></i>
</div>
<div class="stat-content">
<div class="stat-value" id="modelStatus">离线</div>
<div class="stat-label">模型状态</div>
</div>
</div>
</div>
</div>
</div>
</main>
<footer class="footer">
<div class="footer-content">
<div class="tech-stack">
<h4>技术栈</h4>
<div class="tech-icons">
<span class="tech-icon" title="PyTorch">
<i class="fas fa-brain"></i> PyTorch
</span>
<span class="tech-icon" title="Flask">
<i class="fas fa-server"></i> Flask
</span>
<span class="tech-icon" title="JavaScript">
<i class="fab fa-js"></i> JavaScript
</span>
<span class="tech-icon" title="HTML5">
<i class="fab fa-html5"></i> HTML5
</span>
</div>
</div>
<div class="footer-info">
<p>猫狗分类器 v1.0 | 基于深度学习的图像识别系统</p>
<p class="copyright">© 2024 猫狗分类器项目 | @ Thomas.Sir</p>
</div>
</div>
</footer>
</div>
<div id="loadingOverlay" class="loading-overlay">
<div class="loading-content">
<div class="spinner"></div>
<p>正在识别中,请稍候...</p>
</div>
</div>
<script src="script.js"></script>
</body>
</html>
4.2 前端样式 (frontend/style.css)
/* 重置和基础样式 */
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
min-height: 100vh;
color: #333;
line-height: 1.6;
}
.container {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
}
/* 头部样式 */
.header {
text-align: center;
color: white;
margin-bottom: 30px;
padding: 20px;
background: rgba(255, 255, 255, 0.1);
border-radius: 15px;
backdrop-filter: blur(10px);
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.1);
}
.header h1 {
font-size: 2.5rem;
margin-bottom: 10px;
display: flex;
align-items: center;
justify-content: center;
gap: 15px;
}
.subtitle {
font-size: 1.1rem;
opacity: 0.9;
}
/* 主要内容区域 */
.main-content {
display: grid;
grid-template-columns: 1fr 1fr;
gap: 30px;
margin-bottom: 30px;
}
@media (max-width: 768px) {
.main-content {
grid-template-columns: 1fr;
}
}
/* 上传区域 */
.upload-section,
.preview-section,
.result-section {
background: white;
border-radius: 15px;
padding: 25px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
}
.upload-section h2,
.preview-section h2,
.result-section h2 {
color: #4a5568;
margin-bottom: 20px;
display: flex;
align-items: center;
gap: 10px;
font-size: 1.5rem;
}
/* 上传区域样式 */
.upload-area {
border: 3px dashed #cbd5e0;
border-radius: 10px;
padding: 40px 20px;
text-align: center;
transition: all 0.3s ease;
margin-bottom: 20px;
cursor: pointer;
}
.upload-area:hover {
border-color: #667eea;
background: #f7fafc;
}
.upload-area.drag-over {
border-color: #667eea;
background: #ebf4ff;
}
.upload-icon {
font-size: 48px;
color: #a0aec0;
margin-bottom: 15px;
}
.file-info {
color: #718096;
font-size: 0.9rem;
margin-top: 10px;
}
/* URL上传 */
.url-upload {
margin-top: 20px;
}
.url-upload h3 {
color: #4a5568;
margin-bottom: 10px;
font-size: 1.1rem;
}
.url-input-group {
display: flex;
gap: 10px;
}
.url-input-group input {
flex: 1;
padding: 12px 15px;
border: 2px solid #e2e8f0;
border-radius: 8px;
font-size: 1rem;
transition: border-color 0.3s ease;
}
.url-input-group input:focus {
outline: none;
border-color: #667eea;
}
/* 按钮样式 */
.btn {
padding: 12px 24px;
border: none;
border-radius: 8px;
font-size: 1rem;
font-weight: 600;
cursor: pointer;
transition: all 0.3s ease;
display: inline-flex;
align-items: center;
gap: 8px;
}
.btn-primary {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
}
.btn-primary:hover {
transform: translateY(-2px);
box-shadow: 0 5px 15px rgba(102, 126, 234, 0.4);
}
.btn-secondary {
background: #e2e8f0;
color: #4a5568;
}
.btn-secondary:hover {
background: #cbd5e0;
}
.btn:disabled {
opacity: 0.5;
cursor: not-allowed;
transform: none !important;
box-shadow: none !important;
}
/* 预览区域 */
.preview-container {
width: 100%;
height: 300px;
border: 2px solid #e2e8f0;
border-radius: 10px;
overflow: hidden;
position: relative;
margin-bottom: 20px;
}
#previewImage {
width: 100%;
height: 100%;
object-fit: contain;
background: #f7fafc;
}
.preview-placeholder {
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
height: 100%;
color: #a0aec0;
}
.preview-placeholder i {
font-size: 48px;
margin-bottom: 10px;
}
.preview-actions {
display: flex;
gap: 10px;
justify-content: center;
}
/* 结果区域 */
.result-container {
min-height: 200px;
border: 2px solid #e2e8f0;
border-radius: 10px;
padding: 20px;
margin-bottom: 20px;
}
.result-placeholder {
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
height: 100%;
color: #a0aec0;
}
.result-placeholder i {
font-size: 48px;
margin-bottom: 10px;
}
/* 结果卡片样式 */
.result-card {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
border-radius: 10px;
padding: 20px;
text-align: center;
animation: slideIn 0.5s ease;
}
@keyframes slideIn {
from {
opacity: 0;
transform: translateY(20px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
.prediction {
font-size: 2rem;
font-weight: bold;
margin-bottom: 10px;
}
.confidence {
font-size: 1.2rem;
opacity: 0.9;
}
.probability-bar {
height: 20px;
background: rgba(255, 255, 255, 0.2);
border-radius: 10px;
margin: 15px 0;
overflow: hidden;
}
.probability-fill {
height: 100%;
background: white;
border-radius: 10px;
transition: width 1s ease;
}
.probabilities {
display: flex;
justify-content: space-between;
margin-top: 15px;
text-align: center;
}
.probability-item {
flex: 1;
}
.probability-label {
font-size: 0.9rem;
opacity: 0.8;
margin-bottom: 5px;
}
.probability-value {
font-size: 1.1rem;
font-weight: bold;
}
/* 统计信息 */
.stats-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
gap: 15px;
margin-top: 15px;
}
.stat-card {
background: #f7fafc;
border-radius: 10px;
padding: 15px;
display: flex;
align-items: center;
gap: 15px;
transition: transform 0.3s ease;
}
.stat-card:hover {
transform: translateY(-2px);
box-shadow: 0 5px 15px rgba(0, 0, 0, 0.1);
}
.stat-icon {
width: 40px;
height: 40px;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
border-radius: 8px;
display: flex;
align-items: center;
justify-content: center;
color: white;
font-size: 1.2rem;
}
.stat-value {
font-size: 1.5rem;
font-weight: bold;
color: #2d3748;
}
.stat-label {
font-size: 0.9rem;
color: #718096;
}
/* 页脚样式 */
.footer {
background: rgba(255, 255, 255, 0.1);
border-radius: 15px;
padding: 20px;
backdrop-filter: blur(10px);
color: white;
margin-top: 30px;
}
.footer-content {
display: flex;
justify-content: space-between;
align-items: center;
flex-wrap: wrap;
gap: 20px;
}
.tech-stack h4 {
margin-bottom: 10px;
font-size: 1.1rem;
}
.tech-icons {
display: flex;
gap: 15px;
flex-wrap: wrap;
}
.tech-icon {
display: inline-flex;
align-items: center;
gap: 5px;
padding: 5px 10px;
background: rgba(255, 255, 255, 0.1);
border-radius: 5px;
font-size: 0.9rem;
}
.footer-info p {
margin-bottom: 5px;
}
.copyright {
font-size: 0.9rem;
opacity: 0.8;
margin-top: 10px;
}
/* 加载遮罩 */
.loading-overlay {
position: fixed;
top: 0;
left: 0;
right: 0;
bottom: 0;
background: rgba(0, 0, 0, 0.7);
display: none;
align-items: center;
justify-content: center;
z-index: 1000;
}
.loading-overlay.active {
display: flex;
}
.loading-content {
background: white;
padding: 30px;
border-radius: 10px;
text-align: center;
animation: fadeIn 0.3s ease;
}
@keyframes fadeIn {
from { opacity: 0; transform: scale(0.9); }
to { opacity: 1; transform: scale(1); }
}
.spinner {
width: 50px;
height: 50px;
border: 5px solid #f3f3f3;
border-top: 5px solid #667eea;
border-radius: 50%;
animation: spin 1s linear infinite;
margin: 0 auto 20px;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
/* 响应式调整 */
@media (max-width: 768px) {
.header h1 {
font-size: 2rem;
}
.main-content {
padding: 10px;
}
.footer-content {
flex-direction: column;
text-align: center;
}
}
4.3 前端交互脚本 (frontend/script.js)
/**
* 猫狗分类器前端交互脚本
* 处理文件上传、API调用和结果展示
*/
// API配置
const API_BASE_URL = 'http://localhost:5000';
let selectedFile = null;
let startTime = null;
// DOM元素
const imageInput = document.getElementById('imageInput');
const previewImage = document.getElementById('previewImage');
const previewPlaceholder = document.getElementById('previewPlaceholder');
const uploadArea = document.getElementById('uploadArea');
const clearBtn = document.getElementById('clearBtn');
const predictBtn = document.getElementById('predictBtn');
const resultContainer = document.getElementById('resultContainer');
const loadingOverlay = document.getElementById('loadingOverlay');
const imageUrlInput = document.getElementById('imageUrl');
const responseTimeElement = document.getElementById('responseTime');
const accuracyElement = document.getElementById('accuracy');
const modelStatusElement = document.getElementById('modelStatus');
// 初始化
document.addEventListener('DOMContentLoaded', function() {
checkAPIStatus();
setupEventListeners();
});
/**
* 检查API服务状态
*/
async function checkAPIStatus() {
try {
const response = await fetch(`${API_BASE_URL}/health`);
const data = await response.json();
if (data.status === 'healthy') {
modelStatusElement.textContent = '在线';
modelStatusElement.style.color = '#10B981';
} else {
modelStatusElement.textContent = '异常';
modelStatusElement.style.color = '#EF4444';
}
} catch (error) {
console.error('无法连接到API服务:', error);
modelStatusElement.textContent = '离线';
modelStatusElement.style.color = '#EF4444';
}
}
/**
* 设置事件监听器
*/
function setupEventListeners() {
// 文件输入变化事件
imageInput.addEventListener('change', handleFileSelect);
// 拖放事件
uploadArea.addEventListener('dragover', handleDragOver);
uploadArea.addEventListener('dragleave', handleDragLeave);
uploadArea.addEventListener('drop', handleDrop);
// 点击上传区域触发文件选择
uploadArea.addEventListener('click', () => {
imageInput.click();
});
// 键盘事件
imageUrlInput.addEventListener('keypress', (e) => {
if (e.key === 'Enter') {
predictFromUrl();
}
});
}
/**
* 处理文件选择
*/
function handleFileSelect(event) {
const file = event.target.files[0];
if (file && file.type.startsWith('image/')) {
if (file.size > 5 * 1024 * 1024) { // 5MB限制
alert('文件大小不能超过5MB');
return;
}
selectedFile = file;
previewImageFile(file);
} else {
alert('请选择图片文件(JPG、PNG格式)');
}
}
/**
* 处理拖放事件 - 拖拽进入
*/
function handleDragOver(event) {
event.preventDefault();
event.stopPropagation();
uploadArea.classList.add('drag-over');
}
/**
* 处理拖放事件 - 拖拽离开
*/
function handleDragLeave(event) {
event.preventDefault();
event.stopPropagation();
uploadArea.classList.remove('drag-over');
}
/**
* 处理拖放事件 - 放置文件
*/
function handleDrop(event) {
event.preventDefault();
event.stopPropagation();
uploadArea.classList.remove('drag-over');
const files = event.dataTransfer.files;
if (files.length > 0) {
const file = files[0];
if (file.type.startsWith('image/')) {
if (file.size > 5 * 1024 * 1024) {
alert('文件大小不能超过5MB');
return;
}
selectedFile = file;
previewImageFile(file);
} else {
alert('请拖放图片文件(JPG、PNG格式)');
}
}
}
/**
* 预览图片文件
*/
function previewImageFile(file) {
const reader = new FileReader();
reader.onload = function(e) {
previewImage.src = e.target.result;
previewImage.style.display = 'block';
previewPlaceholder.style.display = 'none';
// 启用按钮
clearBtn.disabled = false;
predictBtn.disabled = false;
};
reader.readAsDataURL(file);
}
/**
* 清除图片
*/
function clearImage() {
selectedFile = null;
previewImage.src = '';
previewImage.style.display = 'none';
previewPlaceholder.style.display = 'flex';
imageInput.value = '';
// 禁用按钮
clearBtn.disabled = true;
predictBtn.disabled = true;
// 清除结果
resultContainer.innerHTML = `
<div class="result-placeholder">
<i class="fas fa-search"></i>
<p>识别结果将显示在这里</p>
</div>
`;
// 重置统计信息
responseTimeElement.textContent = '-';
accuracyElement.textContent = '-';
}
/**
* 显示加载状态
*/
function showLoading() {
loadingOverlay.classList.add('active');
startTime = Date.now();
}
/**
* 隐藏加载状态
*/
function hideLoading() {
loadingOverlay.classList.remove('active');
// 计算响应时间
if (startTime) {
const responseTime = Date.now() - startTime;
responseTimeElement.textContent = `${responseTime}ms`;
startTime = null;
}
}
/**
* 显示错误消息
*/
function showError(message) {
resultContainer.innerHTML = `
<div class="error-message" style="
background: #FEE2E2;
border: 2px solid #DC2626;
border-radius: 10px;
padding: 20px;
text-align: center;
color: #DC2626;
">
<i class="fas fa-exclamation-triangle" style="font-size: 2rem; margin-bottom: 10px;"></i>
<h3 style="margin-bottom: 10px;">错误</h3>
<p>${message}</p>
</div>
`;
}
/**
* 预测图片
*/
async function predictImage() {
if (!selectedFile) {
alert('请先选择图片');
return;
}
showLoading();
const formData = new FormData();
formData.append('file', selectedFile);
try {
const response = await fetch(`${API_BASE_URL}/predict`, {
method: 'POST',
body: formData
});
const data = await response.json();
if (data.success) {
displayResult(data);
} else {
showError(data.error || '识别失败');
}
} catch (error) {
console.error('预测错误:', error);
showError('网络错误,请检查API服务是否运行');
} finally {
hideLoading();
}
}
/**
* 通过URL预测图片
*/
async function predictFromUrl() {
const url = imageUrlInput.value.trim();
if (!url) {
alert('请输入图片URL');
return;
}
// 简单验证URL格式
if (!url.startsWith('http://') && !url.startsWith('https://')) {
alert('请输入有效的URL(以http://或https://开头)');
return;
}
showLoading();
try {
const response = await fetch(`${API_BASE_URL}/predict_url`, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ url: url })
});
const data = await response.json();
if (data.success) {
// 加载并显示图片
previewImage.src = url;
previewImage.style.display = 'block';
previewPlaceholder.style.display = 'none';
selectedFile = url; // 将URL视为选中的文件
// 启用按钮
clearBtn.disabled = false;
predictBtn.disabled = false;
// 显示结果
displayResult(data);
} else {
showError(data.error || '识别失败');
}
} catch (error) {
console.error('URL预测错误:', error);
showError('网络错误,请检查API服务是否运行');
} finally {
hideLoading();
}
}
/**
* 显示识别结果
*/
function displayResult(data) {
const catProb = data.probabilities.find(p => p.class === '猫').probability * 100;
const dogProb = data.probabilities.find(p => p.class === '狗').probability * 100;
// 更新准确率显示
accuracyElement.textContent = `${data.confidence.toFixed(1)}%`;
// 确定图标
const icon = data.prediction === '猫' ? 'fas fa-cat' : 'fas fa-dog';
const color = data.prediction === '猫' ? '#F59E0B' : '#3B82F6';
resultContainer.innerHTML = `
<div class="result-card">
<div style="font-size: 4rem; margin-bottom: 10px;">
<i class="${icon}"></i>
</div>
<div class="prediction">这是 ${data.prediction}!</div>
<div class="confidence">置信度: ${data.confidence.toFixed(1)}%</div>
<div class="probability-bar">
<div class="probability-fill" style="
width: ${data.confidence}%;
background: ${color};
"></div>
</div>
<div class="probabilities">
<div class="probability-item">
<div class="probability-label">猫</div>
<div class="probability-value" style="color: ${color}">${catProb.toFixed(1)}%</div>
</div>
<div class="probability-item">
<div class="probability-label">狗</div>
<div class="probability-value" style="color: ${color}">${dogProb.toFixed(1)}%</div>
</div>
</div>
</div>
<div style="margin-top: 20px; padding: 15px; background: #F3F4F6; border-radius: 8px;">
<h3 style="margin-bottom: 10px; color: #4B5563;">
<i class="fas fa-info-circle"></i> 识别详情
</h3>
<div style="display: grid; grid-template-columns: 1fr 1fr; gap: 10px;">
<div>
<strong>预测类别:</strong> ${data.prediction}
</div>
<div>
<strong>置信度:</strong> ${data.confidence.toFixed(2)}%
</div>
<div>
<strong>猫的概率:</strong> ${catProb.toFixed(2)}%
</div>
<div>
<strong>狗的概率:</strong> ${dogProb.toFixed(2)}%
</div>
</div>
</div>
`;
}
/**
* 批量预测(示例函数,可在未来扩展)
*/
async function batchPredict(files) {
if (!files || files.length === 0) {
alert('请选择至少一张图片');
return;
}
showLoading();
const formData = new FormData();
files.forEach((file, index) => {
formData.append('files', file);
});
try {
const response = await fetch(`${API_BASE_URL}/batch_predict`, {
method: 'POST',
body: formData
});
const data = await response.json();
if (data.success) {
displayBatchResults(data.results);
} else {
showError('批量识别失败');
}
} catch (error) {
console.error('批量预测错误:', error);
showError('网络错误');
} finally {
hideLoading();
}
}
/**
* 显示批量识别结果(示例函数)
*/
function displayBatchResults(results) {
let html = '<h3>批量识别结果</h3>';
results.forEach((result, index) => {
html += `
<div style="
padding: 10px;
margin: 10px 0;
background: ${result.success === false ? '#FEE2E2' : '#D1FAE5'};
border-radius: 5px;
border-left: 4px solid ${result.success === false ? '#DC2626' : '#10B981'};
">
<strong>${result.filename}:</strong>
${result.success === false ?
`<span style="color: #DC2626">${result.error}</span>` :
`${result.prediction} (${result.confidence.toFixed(1)}%)`
}
</div>
`;
});
resultContainer.innerHTML = `<div>${html}</div>`;
}
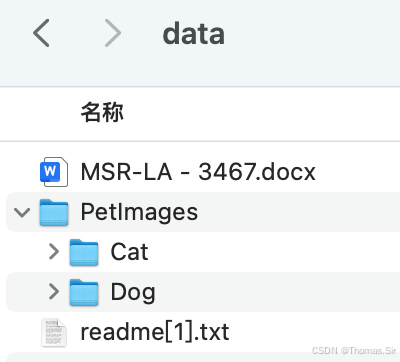
五、数据准备
请到 kaggle官网下载训练图片解压到 data 目录,如下:
六、部署说明
6.1 生产环境部署
创建 backend/wsgi.py 用于生产部署:
from app import app
if __name__ == "__main__":
app.run()
使用Gunicorn部署:
pip install gunicorn
gunicorn -w 4 -b 0.0.0.0:5000 wsgi:app
6.2 Docker部署
创建 Dockerfile:
FROM python:3.9-slim
WORKDIR /app
# 安装系统依赖
RUN apt-get update && apt-get install -y \
libgl1-mesa-glx \
libglib2.0-0 \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件
COPY backend/requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制项目文件
COPY backend/ .
COPY frontend/ /app/frontend/
COPY models/ /app/models/
COPY data/ /app/data/
# 暴露端口
EXPOSE 5000
# 启动命令
CMD ["python", "app.py"]
创建 docker-compose.yml:
version: '3.8'
services:
catdog-classifier:
build: .
ports:
- "5000:5000"
volumes:
- ./models:/app/models
- ./data:/app/data
restart: unless-stopped
environment:
- PYTHONUNBUFFERED=1
构建和运行:
docker-compose up -d
6.3 开发环境部署
后端:python3 app.py
前端:cd cat-dog-classifier/ frontend;python3 -m http.server 8000
七、项目测试
7.1 单元测试 (backend/test_model.py)
"""
模型单元测试
"""
import torch
import unittest
from model import CatDogClassifier, create_simple_model
from utils import preprocess_image
import os
class TestCatDogClassifier(unittest.TestCase):
"""猫狗分类器测试类"""
def test_model_creation(self):
"""测试模型创建"""
model = CatDogClassifier()
self.assertIsNotNone(model)
# 测试模型输出形状
sample_input = torch.randn(1, 3, 224, 224)
output = model(sample_input)
self.assertEqual(output.shape, (1, 2))
def test_simple_model(self):
"""测试简化模型"""
model = create_simple_model()
sample_input = torch.randn(1, 3, 224, 224)
output = model(sample_input)
self.assertEqual(output.shape, (1, 2))
def test_preprocess_image(self):
"""测试图片预处理"""
# 创建一个测试图片
from PIL import Image
import numpy as np
# 创建随机图片
test_image = Image.fromarray(np.random.randint(0, 255, (100, 100, 3), dtype=np.uint8))
# 预处理
tensor = preprocess_image(test_image, img_size=224)
# 检查形状
self.assertEqual(tensor.shape, (1, 3, 224, 224))
# 检查值范围
self.assertTrue(tensor.min() >= -3) # 归一化后的范围
self.assertTrue(tensor.max() <= 3)
def test_model_save_load(self):
"""测试模型保存和加载"""
import tempfile
# 创建临时文件
with tempfile.NamedTemporaryFile(suffix='.pth', delete=False) as tmp:
model_path = tmp.name
try:
# 创建并保存模型
model = create_simple_model()
torch.save(model.state_dict(), model_path)
# 检查文件是否存在
self.assertTrue(os.path.exists(model_path))
# 加载模型
loaded_model = create_simple_model()
loaded_model.load_state_dict(torch.load(model_path))
# 测试加载的模型
sample_input = torch.randn(1, 3, 224, 224)
output1 = model(sample_input)
output2 = loaded_model(sample_input)
# 检查输出是否相同
self.assertTrue(torch.allclose(output1, output2))
finally:
# 清理临时文件
if os.path.exists(model_path):
os.unlink(model_path)
if __name__ == '__main__':
unittest.main()
7.2 API测试脚本 (backend/test_api.py)
"""
API测试脚本
"""
import requests
import json
import time
def test_api_health():
"""测试API健康检查"""
print("测试API健康检查...")
try:
response = requests.get('http://localhost:5000/health')
data = response.json()
print(f"状态: {data.get('status', '未知')}")
print(f"模型加载: {data.get('model_loaded', '未知')}")
return True
except Exception as e:
print(f"API健康检查失败: {e}")
return False
def test_model_info():
"""测试模型信息接口"""
print("\n测试模型信息接口...")
try:
response = requests.get('http://localhost:5000/model_info')
data = response.json()
print(f"模型名称: {data.get('model_name', '未知')}")
print(f"参数量: {data.get('parameters', '未知'):,}")
print(f"类别: {data.get('classes', [])}")
return True
except Exception as e:
print(f"模型信息接口测试失败: {e}")
return False
def test_predict_local_image(image_path):
"""测试本地图片预测"""
print(f"\n测试本地图片预测: {image_path}")
try:
with open(image_path, 'rb') as f:
files = {'file': f}
start_time = time.time()
response = requests.post('http://localhost:5000/predict', files=files)
end_time = time.time()
if response.status_code == 200:
data = response.json()
if data.get('success'):
print(f"预测结果: {data.get('prediction')}")
print(f"置信度: {data.get('confidence'):.2f}%")
print(f"响应时间: {(end_time - start_time)*1000:.2f}ms")
# 显示所有类别概率
for prob in data.get('probabilities', []):
print(f" {prob.get('class')}: {prob.get('probability')*100:.2f}%")
else:
print(f"预测失败: {data.get('error')}")
else:
print(f"请求失败: {response.status_code}")
print(response.text)
except Exception as e:
print(f"图片预测测试失败: {e}")
def test_batch_predict(image_paths):
"""测试批量预测"""
print(f"\n测试批量预测: {len(image_paths)}张图片")
try:
files = []
for i, path in enumerate(image_paths):
files.append(('files', (f'image_{i}.jpg', open(path, 'rb'), 'image/jpeg')))
response = requests.post('http://localhost:5000/batch_predict', files=files)
if response.status_code == 200:
data = response.json()
if data.get('success'):
for result in data.get('results', []):
print(f"{result.get('filename')}: {result.get('prediction', '未知')} "
f"({result.get('confidence', 0):.1f}%)")
else:
print(f"批量预测失败: {data.get('error')}")
except Exception as e:
print(f"批量预测测试失败: {e}")
def main():
"""主测试函数"""
print("开始API测试...")
print("=" * 50)
# 测试API健康状态
if not test_api_health():
print("API服务可能未启动,请先运行 python app.py")
return
# 测试模型信息
test_model_info()
# 测试预测
# 替换为你的测试图片路径
test_images = [
'../data/test/test_cat.jpg',
'../data/test/test_dog.jpg'
]
for img_path in test_images:
import os
if os.path.exists(img_path):
test_predict_local_image(img_path)
print("\n" + "=" * 50)
print("API测试完成!")
if __name__ == '__main__':
main()
八、项目总结
本项目构建了一个基于深度学习的猫狗图像分类Web应用,采用前后端分离架构,实现了从数据准备、模型训练到Web服务的完整深度学习应用流程。项目不仅展示了PyTorch在计算机视觉任务中的强大能力,还体现了现代Web开发中前后端协同工作的最佳实践。
8.1 技术架构与创新点
在技术架构上,项目采用了清晰的三层结构:前端交互层、后端服务层和深度学习模型层。前端使用原生HTML5、CSS3和JavaScript技术栈,实现了拖拽上传、实时预览、响应式设计等现代Web交互体验,避免了前端框架的臃肿,保持了应用的轻量性。后端基于Flask框架构建RESTful API服务,通过Flask-CORS处理跨域请求,采用模块化设计将模型预测、文件处理、错误处理等功能分离,提高了代码的可维护性。
深度学习层是项目的核心,基于PyTorch框架构建了卷积神经网络模型。模型设计考虑了实际应用场景,采用三组卷积-池化层提取图像特征,配合批归一化和Dropout层优化训练过程。训练模块实现了完整的数据管道,包含数据增强、学习率调度、训练验证循环等功能,并提供了详细的训练过程可视化。
8.2 工程实现亮点
项目的工程实现体现了生产级应用的质量标准。在前端实现中,通过原生的File API和Drag & Drop API提供了流畅的文件上传体验,Fetch API的合理使用确保了与后端服务的高效通信。CSS Grid和Flexbox的结合使用实现了完美的响应式布局,适配从桌面到移动设备的各种屏幕尺寸。
后端实现注重健壮性和可扩展性,设计了完整的API接口体系,包括健康检查、模型信息查询、单图预测、批量预测和URL预测等多种接口。错误处理机制全面,能够妥善处理各种异常情况,返回结构化的错误信息。模型服务层实现了高效的图片预处理流水线,确保输入数据符合模型要求。
模型训练模块提供了从数据准备到模型评估的完整工具链。数据加载器支持自动的数据集划分和增强变换,训练循环实现了标准的深度学习训练流程,包含损失计算、反向传播、参数更新等关键步骤。可视化模块能够生成训练曲线,帮助开发者分析模型性能。
8.3 部署与运维方案
项目提供了灵活的部署方案,支持从开发到生产的不同环境需求。开发环境使用Flask内置服务器和Python HTTP服务器,便于快速开发和调试。生产环境提供了Gunicorn WSGI服务器部署方案,以及完整的Docker容器化部署方案。Docker Compose配置文件使得多服务部署变得简单可靠。
项目还包含了完善的工具链支持,包括虚拟环境配置、依赖管理、单元测试、API测试等功能。代码结构清晰,注释详细,遵循PEP 8编码规范,便于其他开发者理解和二次开发。项目文档完整,从环境搭建到部署运维的每个步骤都有详细说明。
8.4 应用价值与扩展性
本项目的实际应用价值显著,不仅可以直接用于猫狗图像分类任务,其架构设计具有很好的通用性和扩展性。通过简单的修改,可以适应其他图像分类任务,如花卉识别、车辆识别、医学影像分析等。项目展示了如何将深度学习模型产品化,为AI算法工程师提供了从实验到生产的完整参考实现。
在教育意义上,项目是学习深度学习Web应用开发的优秀案例。它覆盖了深度学习、Web开发、系统部署等多个技术领域,展示了如何将这些技术有机整合。详细的代码注释和模块化设计使得代码易于理解和学习,适合作为深度学习工程化教学的实践项目。
总之,这个猫狗分类器项目不仅是一个功能完整的AI应用,更是一个展示了现代深度学习Web应用开发全貌的典范。它平衡了技术深度与工程实践,在模型性能、用户体验、代码质量和系统可维护性等方面都达到了较高标准,为类似项目的开发提供了有价值的参考。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)