CVPR 2025 | MambaVision:一种 Mamba-Transformer 混合视觉骨干网络

文章目录
一、论文信息
- 论文题目:MambaVision: A Hybrid Mamba-Transformer Vision Backbone
- 论文作者:Ali Hatamizadeh, Jan Kautz
- 发表单位:NVIDIA
- 发表会议\期刊:CVPR 2025
- 代码链接:https://github.com/NVlabs/MambaVision
二、论文主要贡献
- 重新设计了适配视觉任务的 Mamba 模块,相比原始 Mamba 架构,同时提升了视觉任务的精度与图像推理吞吐量。
- 系统性地研究了 Mamba 与 Transformer 模块的融合范式,证实了在网络最终阶段引入自注意力模块,能够显著提升模型捕捉全局上下文与长距离空间依赖关系的能力。
- 提出了全新的 Mamba-Transformer 混合模型 MambaVision,该分层架构在 ImageNet-1K 数据集上,实现了 Top-1 准确率与推理吞吐量的全新 SOTA 帕累托前沿。
三、论文创新点
3.1 Mamba 基础原理
在 Mamba 中,一维连续输入 x ( t ) ∈ R x(t) \in \mathbb{R} x(t)∈R 通过可学习的隐藏状态 h ( t ) ∈ R M h(t) \in \mathbb{R}^{M} h(t)∈RM,被转换为输出 y ( t ) ∈ R y(t) \in \mathbb{R} y(t)∈R,对应的参数为 A ∈ R M × M A \in \mathbb{R}^{M \times M} A∈RM×M、 B ∈ R M × 1 B \in \mathbb{R}^{M \times 1} B∈RM×1 与 C ∈ R 1 × M C \in \mathbb{R}^{1 \times M} C∈R1×M,计算公式如下:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) , \begin{aligned} h'(t) &= A h(t) + B x(t), \\ y(t) &= C h(t), \end{aligned} h′(t)y(t)=Ah(t)+Bx(t),=Ch(t),
离散化
为了进一步提升计算效率,我们将上述公式中的连续参数 A , B , C A, B, C A,B,C 转换为离散参数。具体而言,给定时间尺度 Δ \Delta Δ,可通过零阶保持准则,得到离散参数 A ˉ ∈ R M × M \bar{A} \in \mathbb{R}^{M \times M} Aˉ∈RM×M、 B ‾ ∈ R M × 1 \overline{B} \in \mathbb{R}^{M \times 1} B∈RM×1 与 C ˉ ∈ R 1 × M \bar{C} \in \mathbb{R}^{1 \times M} Cˉ∈R1×M,转换公式如下:
A ‾ = exp ( Δ A ) , B ‾ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ ( Δ B ) , C ‾ = C , \begin{aligned} \overline{A} &= \exp(\Delta A), \\ \overline{B} &= (\Delta A)^{-1}(\exp(\Delta A) - I) \cdot (\Delta B), \\ \overline{C} &= C, \end{aligned} ABC=exp(ΔA),=(ΔA)−1(exp(ΔA)−I)⋅(ΔB),=C,
此时,上述连续状态方程可通过离散参数表示为:
h ( t ) = A ‾ h ( t − 1 ) + B ‾ x ( t ) , y ( t ) = C ‾ h ( t ) , \begin{aligned} h(t) &= \overline{A} h(t-1) + \overline{B} x(t), \\ y(t) &= \overline{C} h(t), \end{aligned} h(t)y(t)=Ah(t−1)+Bx(t),=Ch(t),
此外,对于长度为 T T T 的输入序列,可通过核为 K ˉ \bar{K} Kˉ 的全局卷积,计算上述公式的输出,具体如下:
K ‾ = ( C B ‾ , C A B ‾ , … , C A ‾ T − 1 B ‾ ) , y = x ∗ K ‾ , \begin{aligned} \overline{K} &= (C \overline{B}, C \overline{A B}, \dots, C \overline{A}^{T-1} \overline{B}), \\ y &= x * \overline{K}, \end{aligned} Ky=(CB,CAB,…,CAT−1B),=x∗K,
选择性机制
Mamba 在 S4 范式的基础上进一步扩展,引入了选择性机制,实现了依赖于输入的序列处理。该机制允许模型根据输入动态调整参数 B , C B, C B,C 与 Δ \Delta Δ,过滤掉无关信息。
3.2 层架构设计
给定输入 X ∈ R T × C X \in \mathbb{R}^{T \times C} X∈RT×C,其中 T T T 为序列长度, C C C 为嵌入维度,第 3、第 4 阶段中第 n n n 层的输出可通过以下公式计算:
X ^ n = Mixer ( Norm ( X n − 1 ) ) + X n − 1 , X n = MLP ( Norm ( X ^ n ) ) + X ^ n , \begin{aligned} \hat{X}^{n} &= \text{Mixer}\left(\text{Norm}\left(X^{n-1}\right)\right) + X^{n-1}, \\ X^{n} &= \text{MLP}\left(\text{Norm}\left(\hat{X}^{n}\right)\right) + \hat{X}^{n}, \end{aligned} X^nXn=Mixer(Norm(Xn−1))+Xn−1,=MLP(Norm(X^n))+X^n,
其中, Norm \text{Norm} Norm 与 Mixer \text{Mixer} Mixer 分别代表层归一化与令牌混合模块。在无特殊说明的情况下, Norm \text{Norm} Norm 均采用层归一化实现。
若某阶段共设置 N N N 层网络,前 N 2 \frac{N}{2} 2N 层将采用 **MambaVision 混合器(MambaVision Mixer)模块,剩余 N 2 \frac{N}{2} 2N 层则采用自注意力(Self-Attention)**模块。下文将详细介绍各混合器模块的设计细节。
MambaVision 混合器
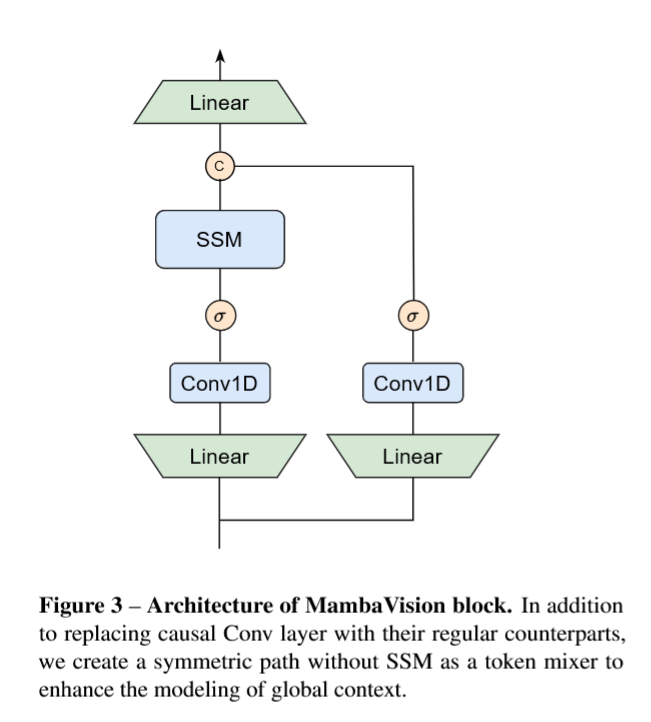
如图 3 所示,我们对原始 Mamba 混合器进行了重新设计,使其更适配视觉任务:
- 替换因果卷积:用常规卷积替换原始的因果卷积——因果卷积会将特征的影响限制在单一方向,这对于视觉任务而言不仅没有必要,还会带来很强的约束限制。
- 新增对称分支:新增一条不含 SSM 的对称分支,该分支由额外的卷积层与 S 型线性单元(SiLU)激活函数构成,用于弥补 SSM 序列约束导致的内容信息丢失。
- 拼接融合:将两个分支的输出拼接,并通过最终的线性层完成投影,保证最终的特征表征能够同时融合序列信息与空间信息。
为了保证参数量与原始模块设计相当,每个分支的输出都会被投影至维度为 C 2 \frac{C}{2} 2C 的嵌入空间(即原始嵌入维度的一半)。给定输入 X in X_{\text{in}} Xin,MambaVision 混合器的输出 X out X_{\text{out}} Xout 计算公式如下:
X 1 = Scan ( σ ( Conv ( Linear ( C , C 2 ) ( X in ) ) ) ) , X 2 = σ ( Conv ( Linear ( C , C 2 ) ( X in ) ) ) , X out = Linear ( C 2 , C ) ( Concat ( X 1 , X 2 ) ) , \begin{aligned} X_{1} &= \text{Scan}\left(\sigma\left(\text{Conv}\left(\text{Linear}\left(C, \frac{C}{2}\right)\left(X_{\text{in}}\right)\right)\right)\right), \\ X_{2} &= \sigma\left(\text{Conv}\left(\text{Linear}\left(C, \frac{C}{2}\right)\left(X_{\text{in}}\right)\right)\right), \\ X_{\text{out}} &= \text{Linear}\left(\frac{C}{2}, C\right)\left(\text{Concat}\left(X_{1}, X_{2}\right)\right), \end{aligned} X1X2Xout=Scan(σ(Conv(Linear(C,2C)(Xin)))),=σ(Conv(Linear(C,2C)(Xin))),=Linear(2C,C)(Concat(X1,X2)),
其中, Linear ( C in , C out ) ( ⋅ ) \text{Linear}(C_{\text{in}}, C_{\text{out}})(\cdot) Linear(Cin,Cout)(⋅) 代表输入维度为 C in C_{\text{in}} Cin、输出维度为 C out C_{\text{out}} Cout 的线性层, Scan \text{Scan} Scan 为选择性扫描操作, σ \sigma σ 为 SiLU 激活函数, Conv \text{Conv} Conv 与 Concat \text{Concat} Concat 分别代表一维卷积与拼接操作。
该模块是MambaVision对原始Mamba模块做视觉任务适配的核心改造,采用 SSM长距离序列建模分支 + 纯卷积局部空间建模分支的并行双路对称设计,核心创新点有两个:
- 把原始Mamba的因果卷积替换为普通非因果卷积,适配视觉特征的双向空间关联特性;
- 新增一条无SSM的纯卷积分支,弥补序列建模丢失的局部视觉细节,最终通过双分支融合,同时兼顾全局长距离依赖与局部空间特征,完美适配计算机视觉任务。
逐模块数据流拆解(自下而上,从输入到输出)
1. 输入与分支拆分
最底部的箭头为模块的输入特征 X in X_{\text{in}} Xin(来自上一层的输出,维度为 T × C T \times C T×C, T T T 为token序列长度, C C C 为特征通道数)。
输入特征进入模块后,被等维度拆分为两路,分别送入左右两个并行分支;两个分支底部的Linear层会分别将输入投影到 C 2 \frac{C}{2} 2C 通道维度,保证双分支总参数量和原始Mamba单分支相当,无额外计算开销。
2. 左分支:SSM序列建模主分支(对应公式的 X 1 X_1 X1)
该分支是改造后的Mamba核心分支,负责长距离全局语义依赖建模,数据流自下而上依次为:
(1) Linear线性层:对输入特征做通道投影,将维度映射到 C 2 \frac{C}{2} 2C,完成特征的初步线性变换;
(2)Conv1D一维卷积层:论文的核心改造之一——用普通非因果一维卷积,替换了原始Mamba的因果卷积。原始Mamba的因果卷积只能单向建模序列,不符合视觉特征的空间双向关联性,普通卷积可双向捕捉上下文信息,更适配图像任务;
(3) σ \sigma σ 激活层:即SiLU(S型线性单元)激活函数,对卷积后的特征做非线性变换,增强模型的特征表达能力;
(4)SSM状态空间模型层:即Mamba的核心选择性状态空间模型,内部执行选择性扫描(Scan)操作,以线性复杂度对一维token序列做长距离依赖建模,捕捉视觉token之间的全局语义关联,是Mamba高效建模的核心单元;
(5)分支输出送入后续的拼接融合节点。
3. 右分支:新增对称空间建模分支(对应公式的 X 2 X_2 X2,论文核心创新)
该分支是论文为视觉任务新增的纯卷积分支,无SSM序列建模,专门负责保留局部空间细节,弥补SSM分支的视觉信息丢失,数据流自下而上依次为:
(1)Linear线性层:和左分支完全对称,同样将输入特征投影到 C 2 \frac{C}{2} 2C 通道维度,和左分支保持参数量平衡;
(2)Conv1D一维卷积层:和左分支同配置的一维卷积,专门提取输入特征的局部空间细节,不经过序列建模处理,完整保留原始的视觉空间信息;
(3) σ \sigma σ 激活层:和左分支对称的SiLU激活函数,对特征做非线性变换;
(4)分支输出直接送入拼接融合节点,和左分支的输出形成特征互补。
4. 特征融合与最终输出
(1) 拼接节点c:左分支SSM的输出,和右分支卷积激活后的输出,在该节点做通道维度的拼接(Concat),将两个 C 2 \frac{C}{2} 2C 维度的特征,重新合并为和输入一致的 C C C 维度特征,对应公式中的拼接操作;
(2)顶部Linear线性层:对拼接融合后的特征做最终的线性变换与特征整合,输出和模块输入维度完全一致的特征 X out X_{\text{out}} Xout,保证该模块可以即插即用,无缝嵌入到MambaVision的网络层级中。
自注意力模块
我们采用通用的 多头自注意力(Multi-Head Self-Attention) 机制,计算公式如下:
Attention ( Q , K , V ) = Softmax ( Q K ⊤ d h ) V , \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^{\top}}{\sqrt{d_{h}}}\right) V, Attention(Q,K,V)=Softmax(dhQK⊤)V,
其中, Q , K , V Q, K, V Q,K,V 分别代表查询(Query)、键(Key)与值(Value)矩阵, d h d_{h} dh 为注意力头的数量。此外,我们的框架支持窗口化注意力计算(窗口大小的消融实验可参见补充材料)。
四、方法
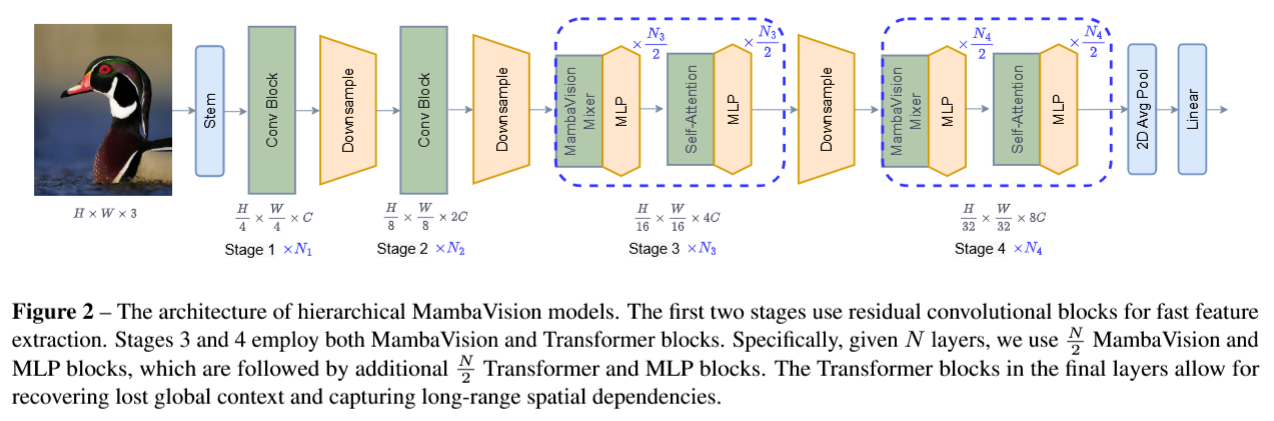
图 2 分层式 MambaVision 模型的架构
整个架构采用视觉任务经典的4阶段金字塔分层设计,遵循「分辨率逐步减半、通道维度逐步翻倍」的规律,核心设计思路是:
- 高分辨率特征阶段(前2个Stage)用轻量高效的CNN做局部特征快速提取,保证推理效率;
- 低分辨率特征阶段(后2个Stage)用「Mamba+Transformer」的混合结构做全局语义建模,兼顾长距离依赖捕捉与精度。
1. 输入层
最左侧是模型的输入:一张尺寸为 H × W × 3 H \times W \times 3 H×W×3 的RGB图像, H / W H/W H/W 是图像的高度/宽度, 3 3 3 对应RGB三通道,是计算机视觉任务的标准输入格式。
2. Stem(输入主干)
紧随输入的Stem模块,是图像的初步特征映射单元:
- 由2个连续的 3 × 3 3 \times 3 3×3、步长2的卷积层构成,对原始图像做4倍下采样;
- 输出特征尺寸为 H 4 × W 4 × C \frac{H}{4} \times \frac{W}{4} \times C 4H×4W×C, C C C 是初始通道维度,完成「原始像素→高维视觉特征」的初步转换,为后续阶段做准备。
3. Stage 1 & Stage 2(CNN主导的高分辨率特征提取阶段)
这两个阶段是MambaVision效率优势的核心设计之一,全程使用卷积模块处理中高分辨率特征:
- Stage 1:输入是Stem输出的 H 4 × W 4 × C \frac{H}{4} \times \frac{W}{4} \times C 4H×4W×C 特征,核心是 N 1 N_1 N1 个Conv Block(卷积残差块),对应论文里的CNN残差公式,在高分辨率下高效提取局部空间特征;阶段末尾通过 Downsample(下采样) 模块( 3 × 3 3 \times 3 3×3、步长2的卷积),将分辨率减半、通道数翻倍,输出 H 8 × W 8 × 2 C \frac{H}{8} \times \frac{W}{8} \times 2C 8H×8W×2C 的特征。
论文中的CNN残差公式:
对应的公式如下:
z ^ = GELU ( BN ( Conv 3 × 3 ( z ) ) ) , z = BN ( Conv 3 × 3 ( z ^ ) ) + z , \begin{aligned} \hat{z} &= \text{GELU}(\text{BN}(\text{Conv}_{3 \times 3}(z))), \\ z &= \text{BN}(\text{Conv}_{3 \times 3}(\hat{z})) + z, \end{aligned} z^z=GELU(BN(Conv3×3(z))),=BN(Conv3×3(z^))+z,
其中, GELU \text{GELU} GELU 为高斯误差线性单元激活函数, BN \text{BN} BN 为批归一化, Conv 3 × 3 \text{Conv}_{3 \times 3} Conv3×3 为 3 × 3 3 \times 3 3×3 卷积层, z z z 为输入到该残差块的中间特征图(三维张量,维度为「高度 × 宽度 × 通道数」)。
- Stage 2:结构与Stage 1完全一致,由 N 2 N_2 N2 个Conv Block构成,继续强化中分辨率的局部特征提取;阶段末尾再次下采样,输出 H 16 × W 16 × 4 C \frac{H}{16} \times \frac{W}{16} \times 4C 16H×16W×4C 的特征,进入核心混合建模阶段。
4. Stage 3 & Stage 4(Mamba-Transformer混合核心阶段)
这两个阶段是论文的核心创新,蓝色虚线框标注了每个阶段的混合结构,严格遵循论文验证的 前 N 2 \frac{N}{2} 2N 层MambaVision Mixer + 后 N 2 \frac{N}{2} 2N 层自注意力 最优设计:
-
Stage 3:
- 输入为 H 16 × W 16 × 4 C \frac{H}{16} \times \frac{W}{16} \times 4C 16H×16W×4C 的特征,总层数为 N 3 N_3 N3;
- 前半段:重复 N 3 2 \frac{N_3}{2} 2N3 次 MambaVision Mixer + MLP 组合。MambaVision Mixer是论文重新设计的视觉适配版Mamba模块,以线性复杂度高效捕捉长距离序列依赖;MLP(多层感知机)是标准的特征非线性变换单元。
- 后半段:重复 N 3 2 \frac{N_3}{2} 2N3 次 Self-Attention(自注意力) + MLP 组合。采用窗口多头自注意力,弥补Mamba在全局上下文、空间依赖建模上的短板,强化特征的全局语义关联。
- 阶段末尾再次下采样,输出 H 32 × W 32 × 8 C \frac{H}{32} \times \frac{W}{32} \times 8C 32H×32W×8C 的特征。
-
Stage 4:
结构与Stage 3完全一致,总层数为 N 4 N_4 N4,前半段MambaVision Mixer、后半段自注意力。作为网络的最深层,这里特征分辨率最低、语义信息最丰富,自注意力能最大化发挥全局建模能力,补全Mamba丢失的全局上下文信息。
5. 分类输出头
Stage 4输出特征后,经过两个模块完成最终的分类预测:
- 2D Avg Pool(二维全局平均池化):在空间维度上对特征图做聚合,把 H 32 × W 32 × 8 C \frac{H}{32} \times \frac{W}{32} \times 8C 32H×32W×8C 的二维特征图,压缩为一维的全局语义特征向量,聚合整张图像的核心信息。
- Linear(全连接线性层):把池化后的特征向量,映射到最终的分类类别数(比如ImageNet-1K的1000个类别),输出每个类别的预测概率,完成图像分类任务。
五、实验分析
5.1 图像分类
表1展示了模型在ImageNet-1K数据集上的分类性能对比结果。将MambaVision与基于卷积、Transformer、卷积-Transformer混合、纯Mamba四大类架构的主流模型进行了全面对比,结果表明:在ImageNet Top-1准确率与图像推理吞吐量两项核心指标上,我们的模型大幅超越了此前的同类工作,刷新了该领域的帕累托前沿。
表1 ImageNet-1K数据集分类基准对比
(图像吞吐量在A100 GPU上测试,批大小为128)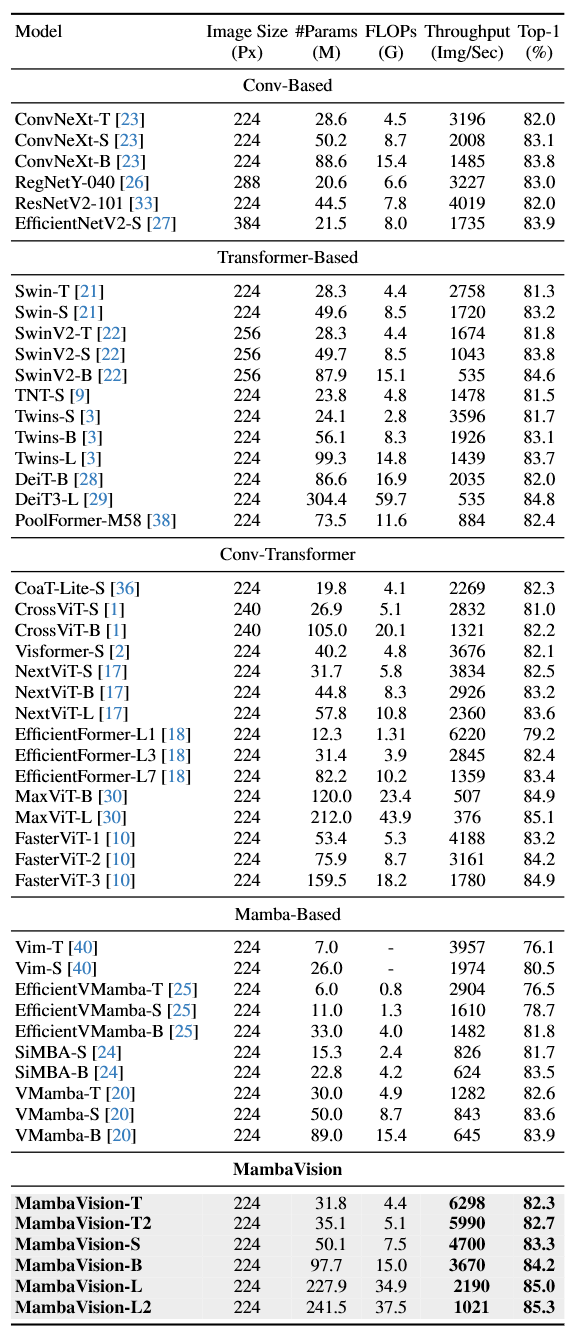
5.2 目标检测与分割
我们在MS COCO数据集上评估了模型的目标检测与实例分割性能,结果如表2所示。为全面验证MambaVision的有效性,我们在完全相同的实验条件下,训练了不同尺寸的MambaVision模型,并与同规模的主流视觉骨干网络进行了对比。
表2 基于Cascade Mask R-CNN的MS COCO数据集目标检测与实例分割基准
(所有模型均采用3倍学习率调度策略训练,输入裁剪分辨率为1280×800)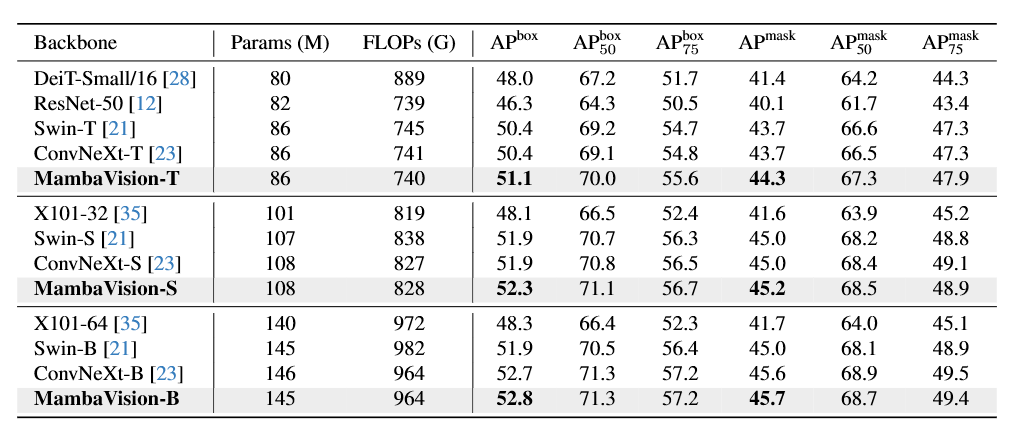
在语义分割任务中,我们基于UperNet框架,在ADE20K数据集上完成了性能评估,结果如表3所示。可以观察到,在所有尺寸变体中,MambaVision的性能均优于同规模的竞品模型。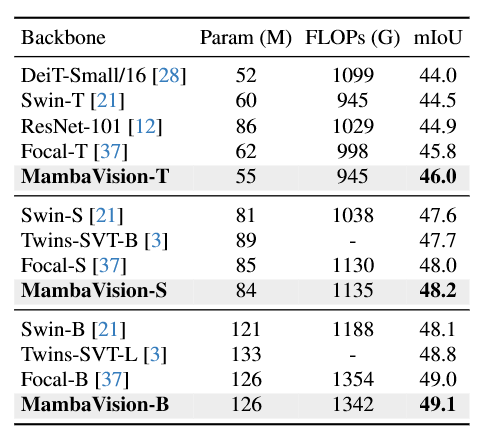
值得注意的是,这些性能提升均无需针对下游任务进行大量超参数优化,充分证明了MambaVision作为通用视觉骨干网络的鲁棒性,尤其在高分辨率场景中具备巨大潜力。此外,在全尺寸对比中,我们的模型mIoU始终优于Focal Transformer,同时模型规模与之相当。
5.3 消融实验
5.3.1 ImageNet-21K大规模训练
本工作首次在所有Mamba基方法中,将模型训练扩展到了超大规模的ImageNet-21K数据集,并完成了大尺寸模型的训练,结果如图4所示,性能表现极具竞争力。
图4 基于ImageNet-21K预训练的MambaVision模型,在不同模型尺寸与分辨率下的性能可扩展性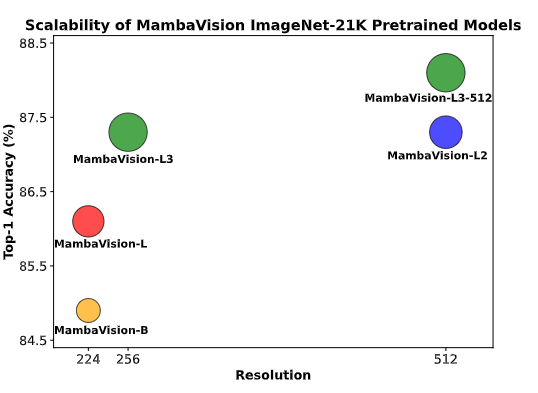
5.3.2 令牌混合器的设计验证
我们开展了全面的消融实验,对MambaVision令牌混合器进行了系统性的设计验证。实验以MambaVision-T为基础架构,在图像分类、目标检测、实例分割、语义分割全任务上评估了不同设计的性能表现,结果如表4所示。
表4 MambaVision令牌混合器的系统性设计消融
(w/o代表无该设计,concat代表拼接融合;conv1与conv2分别为图3中SSM分支与对称分支的卷积操作;COCO实验采用Mask-RCNN检测头、1倍学习率调度策略)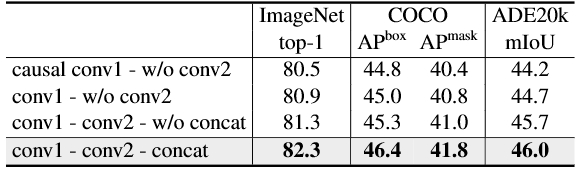
以原始Mamba范式为基线:SSM分支包含因果卷积层,无对称分支的额外卷积层。该基线配置在所有指标上均表现不佳,ImageNet Top-1准确率仅80.5%(比最优设计低-1.8%),MS COCO数据集box AP 44.8(低-1.6)、mask AP 40.4(低-1.6),ADE20K数据集mIoU 44.2%(低-1.4%)。
将SSM分支的因果卷积替换为常规卷积,全任务性能均有提升;在此基础上新增对称分支的卷积层,同时保留Mamba原始的门控机制而非拼接融合,ImageNet Top-1准确率提升至81.3%,COCO box AP提升至45.3、mask AP提升至41.0,ADE20K mIoU提升至45.7%。
采用双分支拼接的融合方式,全任务性能实现了大幅跃升:ImageNet Top-1准确率提升+1.0%,COCO数据集box AP提升+1.1、mask AP提升+0.8,ADE20K mIoU提升+0.9。这些结果验证了我们的核心假设:拼接SSM分支与非SSM分支的输出,能够让模型学习到更丰富的特征表征,增强对全局上下文的理解能力。
5.3.3 混合架构的融合模式验证
探究自注意力与MambaVision令牌混合器的多种混合融合模式,为保证公平对比,所有实验均基于MambaVision-T架构,采用等参数量模型,仅在第3、第4阶段修改混合模块的部署方式,结果如表5所示。
随机融合模式的实验结果最差,Top-1准确率仅81.3%,验证了无规律的自注意力部署无法发挥模型的性能优势。当自注意力模块部署在每个阶段的前N/2层时,准确率提升+0.2%至81.5%;自注意力与MambaVision交替部署的模式,性能轻微下降-0.1%至81.4%,而调换顺序为“MambaVision在前、自注意力在后”的交替模式,准确率提升至81.6%。
仅将自注意力模块部署在每个阶段的最后N/4层时,准确率实现了显著提升+0.3%至81.9%,支撑了我们的核心结论:自注意力在网络最终阶段部署时效果最优。进一步的优化实验表明,将自注意力扩展至每个阶段的最后N/2层时,模型取得了最优的82.3% Top-1准确率,证明了平衡MambaVision层与自注意力层的部署,对特征学习的重要性。
表5 不同混合融合模式的有效性消融实验
(S代表自注意力模块,M代表MambaVision令牌混合器模块)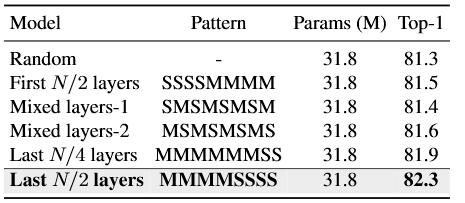
5.3.4 可解释性
为了更好地理解MambaVision对视觉信息的处理逻辑,我们对最终阶段自注意力层的注意力图进行了可视化,结果如图5所示。可视化结果表明,无需显式监督,模型就能自动学习到对语义显著区域的关注。
图5 MambaVision自注意力层的可视化结果,展示了模型如何通过注意力图(中间)与叠加图(右侧),学习聚焦于语义显著区域
这些可视化结果,进一步支撑了我们的架构设计选择:在网络最终阶段使用自注意力模块,能够有效捕捉全局上下文与长距离依赖关系。
六、个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解有限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)