Claude 新功能:Sonnet 遇到难题,现在可以直接问 Opus 了。
哈喽,大家好,我是顾北!
Anthropic 推出 Advisor Tool:一行代码让小模型"请教"大模型,成本降低、智能提升
你可能也遇到过这个两难
用 Sonnet 跑 Agent 任务,成本低、速度快,但偶尔在关键决策点翻车——架构选错了、任务路径走偏了,后面几十步全废掉。
换成 Opus 跑全程?成本直接上去,而且大多数机械性步骤根本用不到那个级别的智能,纯属浪费。
这个问题我相信很多做 Agent 开发的人都想过,也有人自己攒了"大模型编排小模型"的方案。但大多数实现起来挺麻烦——要维护两个对话流、管理上下文传递、处理轮次路由……
Anthropic 在 2026 年 4 月 9 日直接把这件事做成了 API 原生能力,叫 Advisor Tool。
这个设计思路,比功能本身更值得关注
先说思路,因为这才是有意思的地方。
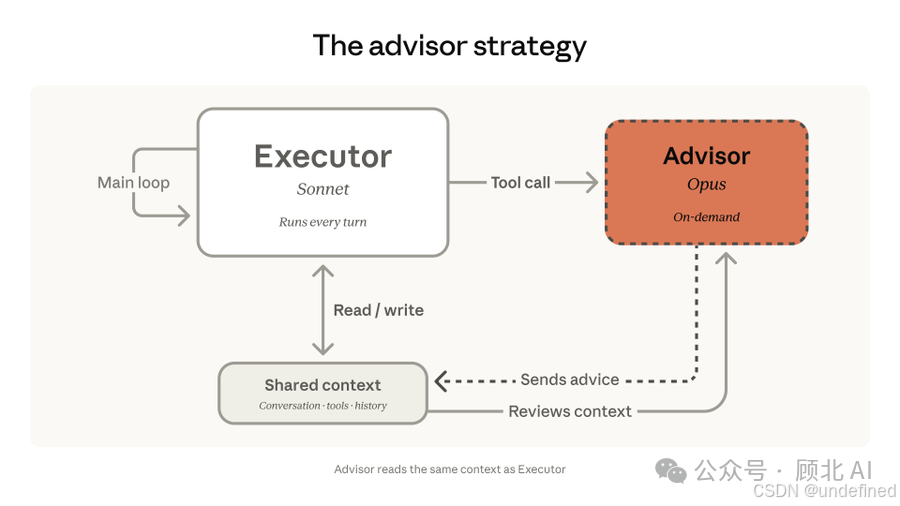
Advisor Tool 的核心模式叫"顾问策略"(Advisor Strategy):
-
执行者(Executor):Sonnet 或 Haiku,负责全程跑任务——调工具、读结果、一步步往前走
-
顾问(Advisor):Opus,只在执行者卡壳、需要决策、或任务快结束时被呼叫,读全部上下文,给一个计划或纠偏建议,然后退场
顾问不调用工具,不直接输出给用户,只给执行者看一段 400-700 token 的建议文字,然后执行者继续干活。
这和常见的"大模型拆解任务、小模型执行"完全是反过来的逻辑。
通常我们的直觉是:用聪明的大模型做规划,用便宜的小模型执行。但这样做有个问题——规划和执行是分离的,执行过程中冒出来的新信息无法反馈给规划层,要么你需要额外的协调逻辑,要么大模型根本看不到执行细节。
Advisor Strategy 的逻辑反过来:让便宜的模型先跑起来,积累上下文,在真正需要高智能的时刻才触发大模型介入。这样 Opus 看到的是"带着大量执行细节的完整上下文",给出的建议也更贴合实际情况。
顾问见证了整个过程,然后给出建议——而不是在开始时盲目规划。 这个区别挺本质的。
数字说话
光说思路不够,来看实际效果:
|
配置 |
基准测试 |
对比 |
|---|---|---|
|
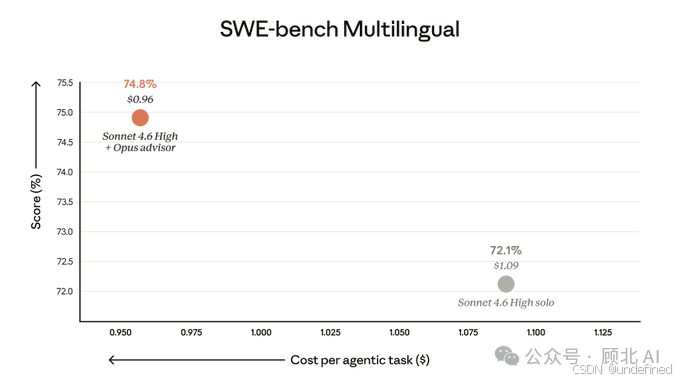
Sonnet + Opus 顾问 vs Sonnet 单独 |
SWE-bench Multilingual |
+2.7 个百分点,成本降低 11.9% |
|
Haiku + Opus 顾问 vs Haiku 单独 |
BrowseComp |
41.2% vs 19.7%,得分翻倍 |
|
Haiku + Opus 顾问 vs Sonnet 单独 |
BrowseComp |
得分低 29%,但成本低 85% |
最后那组数据最有意思:如果你的任务对智能要求不是极致,Haiku + Opus 顾问可以用 Sonnet 15% 的成本跑出七成多的效果——对于高并发、高频次的场景,这个算法非常划算。
三个真实用户的评价也值得留意:
Bolt CEO Eric Simmons:"在复杂任务上做出更好的架构决策,而简单任务不增加任何开销。计划和执行轨迹有了天壤之别。"
Genspark 联创兼CTO Kay Zhu:"在 agent 轮次、工具调用和整体得分上都有明显提升——比我们自己搭建的规划工具还好。"
Eve Legal ML工程师 Anuraj Pandey:"在结构化文档抽取任务上,顾问工具让 Haiku 4.5 能按需咨询 Opus 4.6,以五分之一的成本达到前沿模型质量。"
注意 Kay Zhu 说的那句话——"比我们自己搭建的规划工具还好"。自己搭的方案在功能上可以对标,但工程代价完全不同。
接入有多简单?真的是一行
这是 Anthropic 这次做得很克制的一个地方:整个 advisor 机制发生在一次 /v1/messages 请求内部,你不需要管理额外的上下文传递或轮次路由。
response = client.messages.create(
model="claude-sonnet-4-6", # 执行者
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
"max_uses": 3, # 每次请求最多调用顾问3次
},
# 你原来的其他工具照常放这里
],
messages=[...]
)
加入 advisor_20260301 到 tools 数组,完成。Sonnet 会自己决定什么时候叫顾问,你不需要写额外的调用逻辑。
费用怎么算:顾问产生的 token 按 Opus 费率计,执行者的 token 按 Sonnet/Haiku 费率计,分开统计在 usage.iterations 里。顾问通常只输出 400-700 token 的建议文字(含思考约 1400-1800 token),不生成最终输出——最终输出由便宜的执行者完成,所以整体成本比全程 Opus 低很多。
有几个细节要注意:
-
max_uses是成本保险丝。设成 3 意味着这个请求里顾问最多被叫 3 次,超了就返回错误,执行者继续跑不退出。 -
Prompt caching 建议 3 次以上才开。顾问每次调用都会写一条缓存,第二次起才能读到节省。调用次数少的话,写缓存本身的成本会超过节省的部分。
-
多轮对话要把
advisor_tool_result带回去。这个块不能丢,否则下一轮 API 会报 400。
适合哪些场景,不适合哪些
适合用 Advisor Tool 的情况:
-
代码 Agent 任务:大多数步骤是读文件、跑命令、看结果,机械性高;但关键的"怎么改这个架构"需要高智能。典型场景就是 SWE-bench 那类 bug 修复任务。
-
多步研究流水线:搜索 → 筛选 → 汇总,中间偶尔需要判断"这条信息值不值得深挖"。
-
Computer Use 类任务:大量重复性点击操作,偶尔需要判断下一步走哪个路径。
不太适合的情况:
-
单轮问答:没有执行过程积累,顾问也没什么可看的
-
每一轮都需要 Opus 级别判断:这种情况直接用 Opus 全程跑更合适,advisor 的设计假设是"大多数步骤机械性强"
我的判断
这个功能目前是 Beta,需要加 anthropic-beta: advisor-tool-2026-03-01 请求头。但即便是 Beta,设计思路已经很完整了。
我觉得它真正的价值不只是省钱和提分——而是 把"什么时候需要更高智能"这个决策权还给了模型本身。
以前我们做 Agent 系统,需要在代码层面决定"哪些步骤用大模型、哪些用小模型",这是一个脆弱的工程决策,因为任务的难度分布往往不规律。现在可以让执行者自己感知到"我卡了,需要帮助",然后触发顾问——这更接近人类工作的方式。
对于正在做 Agent 系统的开发者,我建议:先跑一遍你自己的 eval,对比"Sonnet 单独"和"Sonnet + Opus 顾问"的结果。如果你的任务里有明显的"关键决策点",大概率会看到显著提升。
相关文档:
https://claude.com/blog/the-advisor-strategy
https://platform.claude.com/docs/en/agents-and-tools/tool-use/advisor-tool
你在 Agent 项目里遇到过"小模型在关键点翻车"的情况吗?欢迎评论区聊聊你的解法。
我是顾北,关注我,我们下期再见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)