[特殊字符] 彻底吃透 Transformer:从原理到架构,AI大模型的底层核心全拆解 | 附公式详解
摘要:2017 年谷歌论文《Attention Is All You Need》提出的 Transformer 架构,彻底颠覆了传统序列建模的范式,凭借自注意力机制解决了 RNN 系列模型的核心痛点,成为如今 ChatGPT、GPT-4o、Gemini、Claude 等所有主流大语言模型的底层通用底座。本文以机器翻译任务为实战案例,从零拆解 Transformer 的全流程运行逻辑,从输入预处理、自注意力核心、多头注意力升级,到编码器 - 解码器架构完整实现,用通俗化讲解 + 专业公式 + 结构化梳理,帮你彻底吃透大模型的核心心脏。
关键词:Transformer 自注意力机制 大语言模型 ChatGPT 深度学习 NLP 多头注意力

🎯 本文导读
读完本文你将系统掌握以下核心知识点:
- Transformer 诞生的核心背景,以及 RNN 系列模型被淘汰的根本原因
- Transformer 文本输入的完整预处理流程(Token 化 + Embedding + 位置编码)
- 自注意力机制的核心逻辑与数学实现,QKV 三向量的本质作用
- 多头注意力的设计思路与模型能力升级逻辑
- Transformer 编码器 - 解码器的完整架构与全流程运行原理
- Transformer 如何演进为如今的 ChatGPT 等主流大模型
- 适合人群
- 深度学习 / NLP 入门学习者
- 大模型应用 / 微调从业者
- 想彻底搞懂大模型底层原理的技术人
🔹 一、Transformer 诞生前:RNN 的致命痛点,为何被时代淘汰
在 Transformer 诞生之前,自然语言处理(NLP)的序列建模任务,几乎被 RNN(循环神经网络)及其改进版 LSTM、GRU 垄断。
这类模型的核心逻辑是逐字串行处理文本,就像人读书必须一个字一个字顺着读,每一步的输入都依赖上一步的输出。但这种串行设计,带来了两个无法根治的致命硬伤,也注定了它无法支撑起大模型时代的需求。
📌 1. 长程依赖失效,长文本信息严重丢失
RNN 处理文本时,每读取一个新的 Token,只会保留上一步的 “记忆状态”。随着句子长度增加,开头的文本信息会被不断稀释、衰减,最终彻底丢失。
举个直观的例子:当我们翻译「我上周六在济南长清区大学城旁边那家安静的、有落地窗的咖啡厅里,看完了一本关于人工智能发展史的书」这个长句时,RNN 处理到最后「书」这个字的时候,几乎已经完全丢失了开头「我上周六」的时间信息,更无法捕捉「咖啡厅」和「看书」的长距离语义关联,翻译效果大打折扣。
📌 2. 无法并行计算,训练效率极低
RNN 的串行特性,决定了它必须按语序逐字输入 —— 前一个 Token 处理完成后,才能处理下一个。
这就意味着,哪怕是 GPU 的强大并行算力,也完全无法发挥作用。在工业级的机器翻译任务中,用 RNN 训练一个合格的模型,往往需要数周甚至数月的时间,训练成本极高,完全无法支撑模型参数量的规模化扩张。
正是为了解决这两个核心痛点,谷歌团队在 2017 年提出了 Transformer 架构,用一句石破天惊的 **「Attention Is All You Need」**,彻底推翻了循环模型的串行范式,开启了大模型的全新时代。
🔹 二、Transformer 的第一步:文本输入的完整预处理流程
计算机无法直接识别文字,所有文本都必须先转化为可计算的向量,才能进入 Transformer 的核心计算环节。
这个预处理过程分为不可拆分的三步,我们以「我喜欢在安静的咖啡厅看书」这个中文句子为例,完整拆解每一步的作用。
📌 1. Token 化(分词):把句子拆成最小语义单元
Token 是 Transformer 处理文本的最小单位,Token 化就是把完整的句子,切分成一个个独立的、有语义的最小单元,同时给每个 Token 分配唯一的数字编号(Token ID)。
比如例句「我喜欢在安静的咖啡厅看书」,会被切分为:['我', '喜欢', '在', '安静', '的', '咖啡厅', '看书']共 7 个 Token,每个 Token 对应一个唯一的数字 ID,比如我→101,喜欢→2345,在→176。
📌 2. Embedding(词嵌入):把数字转化为语义向量
单纯的数字 ID 只是一个编号,无法表达字词的语义关联 —— 比如「咖啡厅」和「餐厅」的语义相近,但它们的数字 ID 之间没有任何关联。
Embedding 层的作用,就是把每个 Token 的数字 ID,映射成一个固定维度的语义向量(原始论文中采用 512 维向量)。这个向量蕴含了字词的全部语义信息:
- 语义越相近的词,向量在高维空间中的距离越近(比如
咖啡厅≈餐厅) - 向量可进行数学运算表达语义关系(经典案例:
国王 - 男人 + 女人 ≈ 女王)
📌 3. 位置编码(Positional Encoding):给模型补上 “语序感知能力”
Transformer 和 RNN 最大的区别之一,就是它会同时处理句子里的所有 Token,而非按顺序逐字处理。
这带来了并行计算的优势,但也带来了一个致命问题:模型无法识别语序。比如「狗咬人」和「人咬狗」,Token 完全相同,仅语序不同,语义天差地别,但如果没有位置信息,Transformer 会把这两个句子当成完全相同的输入。
为了解决这个问题,Transformer 通过正弦 / 余弦函数,为每个位置的 Token 生成一个唯一的位置向量,和 Token 的语义向量直接相加,让最终的输入向量同时包含「语义信息」和「位置信息」。
预处理完成完成这三步之后,文本就变成了一组「带位置信息的语义向量矩阵」,正式进入 Transformer 的核心 —— 自注意力机制的计算环节。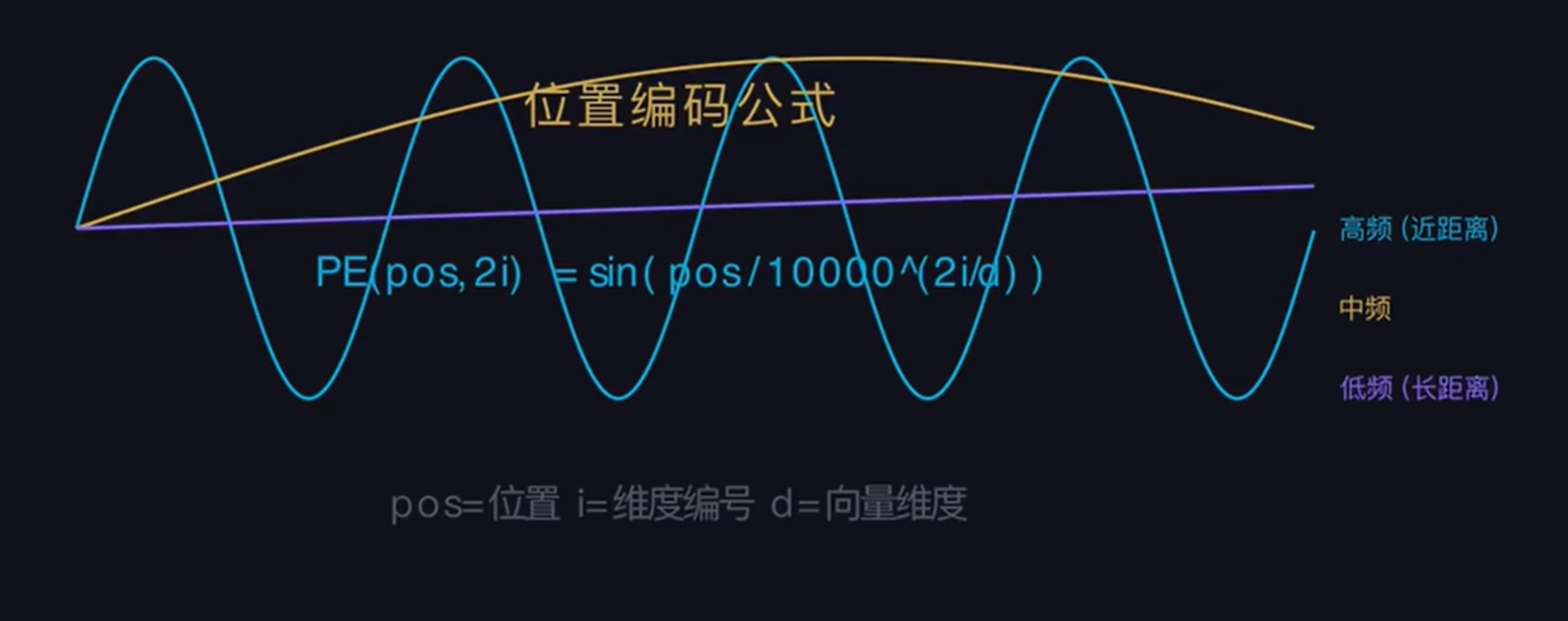
🔹 三、Transformer 的核心灵魂:自注意力机制(Self-Attention)
自注意力机制,是 Transformer 能颠覆行业的核心。
它的本质是:让句子里的每个 Token,都能和全文所有 Token 进行 “交互”,自动关注和自己语义关联最强的字词,吸收上下文信息,更新自己的语义表示。
还是用例句「我喜欢在安静的咖啡厅看书」:Token「看书」会自动重点关注「安静」「咖啡厅」这些关联度高的词,而对「的」这种无实义的词关注度极低。最终「看书」的语义向量,会融合更多来自「咖啡厅」「安静」的信息,变得更精准。
📌 1. QKV 三向量:自注意力的计算基础
自注意力的计算,核心围绕三个向量展开:Q(Query,查询向量)、K(Key,键向量)、V(Value,值向量)。
每个 Token 的输入向量,都会通过三个独立的可训练权重矩阵,分别生成对应的 Q、K、V 三个向量,三个向量的分工非常明确:
Q(查询向量):代表「当前 Token 想要找什么信息」K(键向量):代表「当前 Token 能提供什么信息」V(值向量):代表「当前 Token 的实际语义内容」
tip 通俗理解这就像你在图书馆查资料:Q 是你写的「检索关键词」,K 是每本书的「目录 / 简介」,V 是书的「正文内容」。你会用自己的检索词 Q,去匹配所有书的目录 K,找到匹配度最高的书,然后从书的正文 V 里提取你需要的信息。:::
📌 2. 缩放点积注意力:核心计算流程
自注意力的核心计算,叫做缩放点积注意力,原始论文中的公式如下:
Attention(Q,K,V)=Softmax(dkQKT)V
我们把这个公式拆解成 4 个可理解的步骤,每一步都对应着实际的语义逻辑:
步骤 1:计算语义相似度
用当前 Token 的 Q 向量,和句子里所有 Token 的 K 向量分别做点积运算,得到一组相似度分数。核心逻辑:点积结果越大,代表两个 Token 的语义关联度越高,当前 Token 对它的关注度就越高。
步骤 2:数值缩放
点积的结果会随着向量维度dk的增大而变大,过大的数值会让后续 Softmax 的结果变得极端(非 0 即 1),导致梯度消失。所以要除以dk,把数值缩放回合理的范围,保证训练的稳定性。
步骤 3:归一化得到注意力权重
把缩放后的分数输入 Softmax 函数,进行归一化处理,最终得到一组和为 1 的注意力权重。核心逻辑:权重越大,代表当前 Token 对对应位置的 Token 关注度越高。
步骤 4:融合上下文信息
用得到的注意力权重,分别乘以对应 Token 的 V 向量,再把所有结果相加,最终得到当前 Token 融合了全文上下文信息的新语义向量。
:::note 核心总结自注意力机制,就是让每个 Token 都能自主决定「我要多看谁、少看谁」,最终让每个词的语义都能精准贴合上下文,彻底解决了 RNN 长程信息丢失的问题。
🔹 四、能力升级:多头注意力(Multi-Head Attention)
单头的自注意力,已经能解决长程依赖的问题,但语言的语义关联是多维度的:有语法关系、逻辑关系、距离关系、指代关系等等。
单头注意力只能同时学习一种关联,无法全面捕捉文本的复杂语义。为了解决这个问题,Transformer 提出了多头注意力机制。
📌 多头注意力的核心逻辑
把 Q、K、V 三个向量分别拆分成多个头(原始论文中采用 8 个头),每个头独立进行缩放点积注意力计算,并行学习不同类型的语义关联。最后把所有头的计算结果拼接起来,通过一个线性层变换,得到最终的输出。
还是用例句「我喜欢在安静的咖啡厅看书」,8 个注意力头可以并行学习不同的关联:
- 头 1:学习主谓宾语法关系,比如「我」-「喜欢」-「看书」的关联
- 头 2:学习修饰关系,比如「安静」-「咖啡厅」的关联
- 头 3:学习场景关联,比如「咖啡厅」-「看书」的关联
- 其余头:学习指代关系、长距离关联等其他语义维度
每个头专注于一种语义维度的学习,最终拼接起来的结果,就能捕捉到文本里全方位的语义信息,让模型对文本的理解能力实现质的飞跃。
多头注意力的公式如下:
MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WO其中
🔹 五、Transformer 的完整架构:编码器(Encoder)+ 解码器(Decoder)
(CSDN 发布建议:此处插入 Transformer 完整架构图,直观展示编码器 - 解码器结构,提升阅读体验)
原始的 Transformer,采用的是 ** 编码器 - 解码器(Encoder-Decoder)** 的经典架构,其中:
- 编码器(Encoder):负责「理解输入文本」,把输入的源语言文本,转化为包含完整上下文语义的特征矩阵
- 解码器(Decoder):负责「生成目标文本」,基于编码器输出的语义特征,自回归逐词生成目标语言的翻译结果
原始论文中,编码器和解码器都由 6 层完全相同的结构堆叠而成,层数越多,模型对语义的抽象理解能力越强。
📌 1. 编码器(Encoder):读懂输入的核心
编码器的每一层,都由两个核心子层组成:
- 多头自注意力层:捕捉输入文本内部的语义关联
- 前馈神经网络(FFN):对注意力输出的特征进行非线性变换,学习更复杂的语义模式
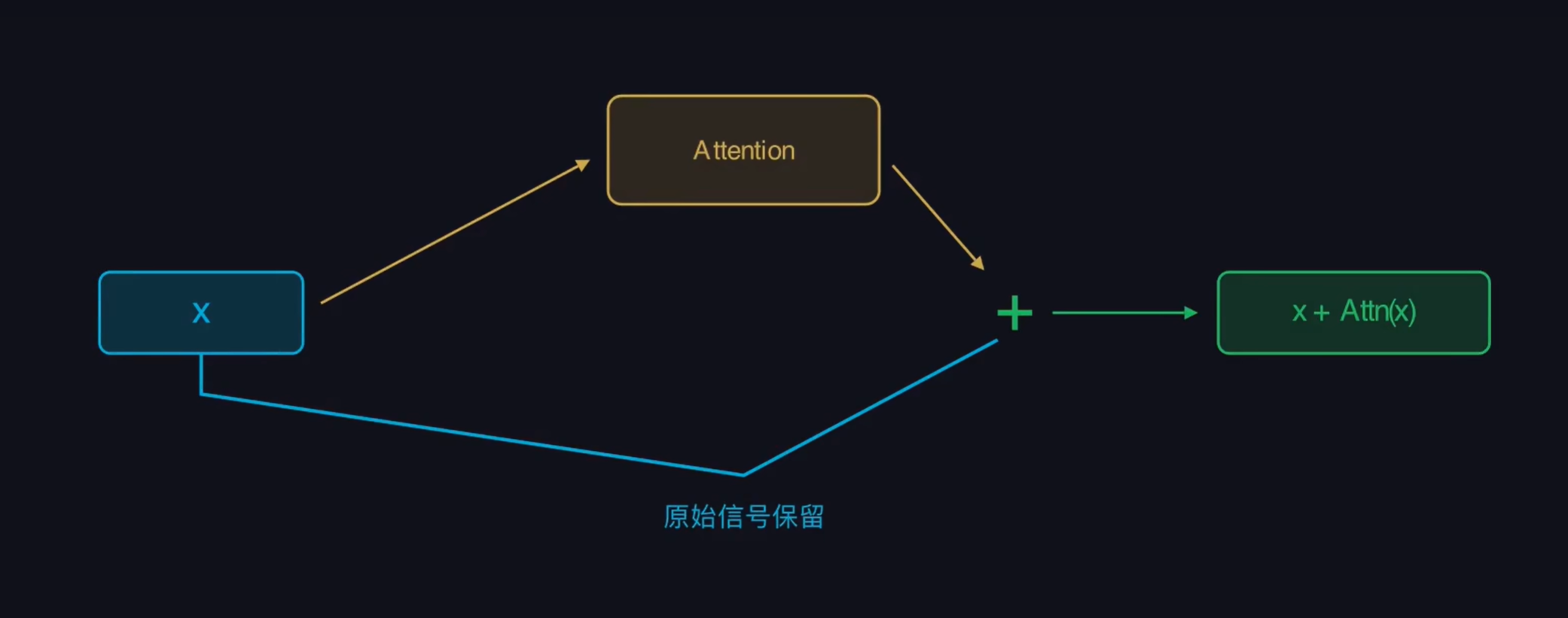
同时,每个子层都搭配了残差连接(Residual Connection)和层归一化(Layer Normalization),防止深层网络训练时的梯度消失,保证模型的训练稳定性。
6 层编码器的语义理解是逐层递进的:
- 第 1-2 层:捕捉基础的字词关联、字面语义
- 第 3-4 层:学习语法结构、句式逻辑
- 第 5-6 层:理解深层的上下文逻辑、整体语义
最终,编码器会输出一个包含输入文本全部语义信息的特征矩阵,传递给解码器。
📌 2. 解码器(Decoder):生成文本的核心
解码器的结构和编码器基本一致,但在编码器的基础上,新增了两个核心模块,来适配文本生成的需求。
(1)掩码多头自注意力(Masked Multi-Head Attention)
解码器是自回归逐词生成文本的 —— 生成第 n 个词的时候,只能看到前 n-1 个已经生成的词,不能看到后面还没生成的词,否则就相当于「考试偷看了答案」。
掩码注意力的作用,就是通过一个掩码矩阵,把当前位置之后的所有 Token 的注意力权重强制置为 0,让模型只能关注到已经生成的内容,保证生成的合理性。
(2)交叉注意力(Cross Attention)
交叉注意力是连接编码器和解码器的核心桥梁。
它的 Q 向量来自解码器的上一层输出(当前已经生成的内容),而 K、V 向量则全部来自编码器的最终输出(源文本的完整语义)。
它的作用,就是让解码器在生成每一个词的时候,都能精准关联到源语言输入的对应语义,保证生成的翻译内容和原文对齐,不会偏离原意。
解码器的最后,会通过一个线性层 + Softmax 函数,把输出的特征向量转化为词表中每个 Token 的生成概率,选择概率最高的 Token 作为当前步的输出,然后重复这个过程,直到生成结束符,完成整个翻译任务。

🔹 六、Transformer 的三大核心优势,为何能成为大模型的通用底座
Transformer 之所以能彻底取代 RNN,成为如今所有大模型的底层底座,核心在于它解决了传统模型的所有痛点,同时具备极强的可扩展性。
| 核心优势 | 具体说明 | 对大模型的价值 |
|---|---|---|
| 极致并行计算能力 | 所有 Token 同时处理,注意力计算完全并行化,完美适配 GPU 算力 | 训练速度较 RNN 提升上百倍,极大降低大模型训练成本 |
| 完美解决长程依赖 | 任意两个 Token 的信息传递路径长度永远为 1,无信息衰减 | 长文本理解能力拉满,支撑万级 Token 的上下文窗口 |
| 极强的可扩展性 | 架构完全模块化,层数、头数、向量维度可自由调整 | 支持模型规模化扩张,从千万参数量到万亿参数量,核心架构不变 |
🔹 七、从 Transformer 到 ChatGPT:大模型的演进之路
原始的 Transformer 是为机器翻译任务设计的 Encoder-Decoder 架构,而如今的主流大模型,都是在 Transformer 的基础上,针对不同任务做了架构的拆分与优化,主要分为三大分支。
📌 1. Encoder-Only 架构:专注文本理解
代表模型:BERT、RoBERTa这类模型只保留了 Transformer 的编码器部分,擅长对文本进行深度理解,主要用于文本分类、命名实体识别、情感分析、阅读理解等理解类任务,是 NLP 领域的「理解专家」。
📌 2. Decoder-Only 架构:专注文本生成
代表模型:GPT 全系列、LLaMA、Claude、Gemini这类模型只保留了 Transformer 的解码器部分,也就是我们常说的「自回归语言模型」,擅长开放式的文本生成。
OpenAI 的 GPT 系列,就是在 Decoder-Only 架构的基础上,不断扩大模型规模、优化训练数据,再叠加人类反馈强化学习(RLHF)等对齐技术,最终进化为我们现在使用的 ChatGPT。
📌 3. Encoder-Decoder 架构:专注序列到序列任务
代表模型:T5、BART、工业级翻译模型这类模型保留了原始 Transformer 的完整架构,擅长输入到输出的序列转换任务,比如机器翻译、文本摘要、语音识别等,是「转换专家」。
可以说,如今所有的大语言模型,无论形态如何变化,底层的核心都是 Transformer 的注意力机制,真正印证了那句 「Attention Is All You Need」。
🔹 八、总结
Transformer 的诞生,是 AI 发展史上的里程碑式事件。
它用极简的注意力机制,彻底推翻了循环模型的串行范式,解决了困扰 NLP 领域多年的长程依赖和并行计算两大核心痛点,为大模型的规模化发展铺平了道路。
它的本质,不是「理解语言」,而是通过矩阵计算和注意力权重,让文本中的每个 Token 都能高效融合上下文的语义信息,最终实现对语言的精准建模。从最初的机器翻译任务,到如今的通用人工智能,Transformer 的核心逻辑从未改变。
对于所有想要进入大模型领域的技术人来说,吃透 Transformer,就是掌握了大模型的核心密码,无论是算法研发、模型微调,还是应用层的开发,这都是必须牢牢掌握的基础知识点。
如果本文对你有帮助,欢迎点赞👍、收藏⭐、关注➕,有任何问题都可以在评论区留言交流,我会一一回复!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)