为什么AI做项目中途突然“失忆“?Anthropic工程师找到了答案
当用 Claude Code 或者 Cursor 写一个稍微有点复杂的项目时,前半段很丝滑,感觉AI 马上就要碾压式地取代我了。
然后,到了某个时间点,它开始犯一些奇怪的错误……
- 忘了之前做过的决定。
- 直接说“已完成”,但功能跑起来完全不对?
你不由的开始反思:到底是我 Prompt 写得差?还是模型本来就不够强?
但其实,那都不是问题。
这不是单纯的 Prompt 问题,也不是模型“智力不足”的问题,而是一个长任务场景下的结构性问题。
1、AI在长项目里为什么总会翻车?
因为所有大语言模型,都有一个叫做 Context Window 的上限,也就是它在一次对话里能“记住”的信息总量。
任何稍微复杂一点的项目,都需要跨越多个 Context Window 才能完成。而每次新 Session,模型都是失忆重启。
就好比你雇了一个人帮你做项目。
但这个人有一个特点:他每隔几个小时就会完全失忆。你说这工作能干好吗?Anthropic 的工程师在做内部实验的时候,就踩到了这个坑。
他们用最强的编程模型 Opus 4.5,在 Claude Agent SDK 里跑了一个任务:克隆 claude.ai 网站。
结果发现,光靠一个高层次的 Prompt,Opus 4.5 连这个任务都搞不定。它会以两种非常典型的方式翻车。
第一种:冲太猛,做到一半 Context 耗尽,留下一个烂摊子。
第二种:Context 快满时,模型开始主动"宣告完成"。
Anthropic 工程师给这个现象起了个名字:Context 焦虑(Context Anxiety)。
症状是:任务没做完,模型却开始说"基本框架已搭好""核心功能已实现,剩下的可以继续扩展"——然后停下来。
你以为它交棒了,其实它是跑了。
这两种失控,靠写更好的 Prompt 都解决不了。这是结构性问题,需要结构性的解法。
这就是 Harness Engineering 存在的原因。
2、Harness:给AI搭一套工作制度
Harness,直译的话是“马具”“脚手架”,但放在 AI 工程领域,我觉得用“工作制度”来理解最合适。
它给模型搭建一套规矩,让模型的工作变得可控、可持续、可验收。
具体来说,Harness 包含四件事:
- 任务怎么拆
- 状态怎么记录
- 完成怎么验收
- 出错怎么回退
而 Harness Engineering,就是专门设计和维护这套“工作制度”的工程学科。
但这里有一个重要的认知:
Harness Engineering 的核心动作,不是“搭建一套最优结构”,而是持续判断,哪些约束现在还需要,哪些已经可以去掉了。
这个点非常非常重要。
可以把 Harness 理解成一套面向 AI Agent 的“工作制度”,而不是一套为了炫技而存在的复杂框架。
3、Harness 解决了哪四个具体问题
Anthropic 工程师在实验里,系统梳理了四个最常见的失控模式。

针对这些问题,Anthropic 设计了对应的解法。
4、Anthropic设计的两个核心机制
机制一:初始化 + 增量推进
同时解决任务失控和状态丢失两个问题。
思路是把第一个 Agent 变成一个“项目基础设施搭建者”,而不是让它直接开始写功能。
在 Anthropic 的实验里,第一个 Agent(叫做 Initializer)负责做四件事。
1. 写功能清单(JSON 格式)
所有功能条目,初始全部标记为 "passes": false。
为什么用 JSON 而不是 Markdown?
因为实验发现,模型面对 JSON 时,比 Markdown 更不容易自作主张地修改或覆盖内容,JSON 更安全。
{
"category": "functional",
"description": "新建对话按钮能创建一个新的会话",
"steps": [
"导航到主界面",
"点击「新建对话」按钮",
"验证新会话已创建",
"验证对话区域显示欢迎状态",
"验证对话出现在侧边栏"
],
"passes": false}2. 建立进度文件(claude-progress.txt)
每次 Session 结束,模型把自己做了什么写进这个文件。
下一个 Session 启动,第一件事就是读这个文件,知道自己接棒的位置在哪里。
3. 写一键启动脚本(init.sh)
之后每个新 Session 启动时,Agent 会主动用 Puppeteer 跑一遍基础端到端测试。
如果上一个 Session 留下了隐性 Bug,新 Session 必须在动手之前就知道,否则会在已经坏掉的基础上继续叠代。
4. 初始 Git commit
建立版本历史,出了问题随时能回退。
有了这套基础设施,后续每个 Coding Agent 的工作流变成:启动服务器 → 跑基础测试 → 读进度文件 → 从功能清单挑一个未完成的功能做 → 做完提交 Git + 更新进度文件。
“一次只做一个功能,是最关键的约束。
这套机制也解决了 Context 焦虑。
真正有效的不是压缩上下文(Compaction),而是 Context Reset:Session 结束时完全清空上下文,启动一个全新的 Agent,通过进度文件和 Git 历史交接状态。
这也是为什么进度文件和 Git commit 如此关键。它们不只是“方便下一个 Session 了解情况”,而是让 Context Reset成为可能的基础设施。

机制二:Generator + Evaluator 分离
同时解决:虚假完成 + 自我评估偏差
这个设计的灵感来自机器学习里的经典架构 GAN(生成对抗网络)——用两个神经网络互相对抗,一个生成,一个判别,判别者不断挑毛病,生成者不断改进。
▶ Generator(生成者):负责做功能、写代码
▶ Evaluator(评估者):负责验收、找 Bug
核心逻辑超级简单:让做事的和评价的,不是同一个人。
两者协作节奏:Generator 做完一批功能(一个 Sprint),交给 Evaluator 验收,通过了才继续下一批。
但这里有个坑:仅仅把 Generator 和 Evaluator 分成两个实例,并不够用。
因为 Evaluator 也是 LLM,天然倾向于对 LLM 产出的工作给高分。Anthropic 工程师发现,Evaluator 会识别出真实的问题,然后自己说服自己"这其实不是大问题",最后还是给了通过。
真正有效的第二步,是专门把 Evaluator 调教成一个挑剔的审稿人。
需要多轮迭代:读 Evaluator 的判断日志,找到它和你判断出现分歧的地方,更新它的 Prompt,再跑一遍,再对比。
Anthropic 工程师针对 UI 质量设计了四个评分维度:
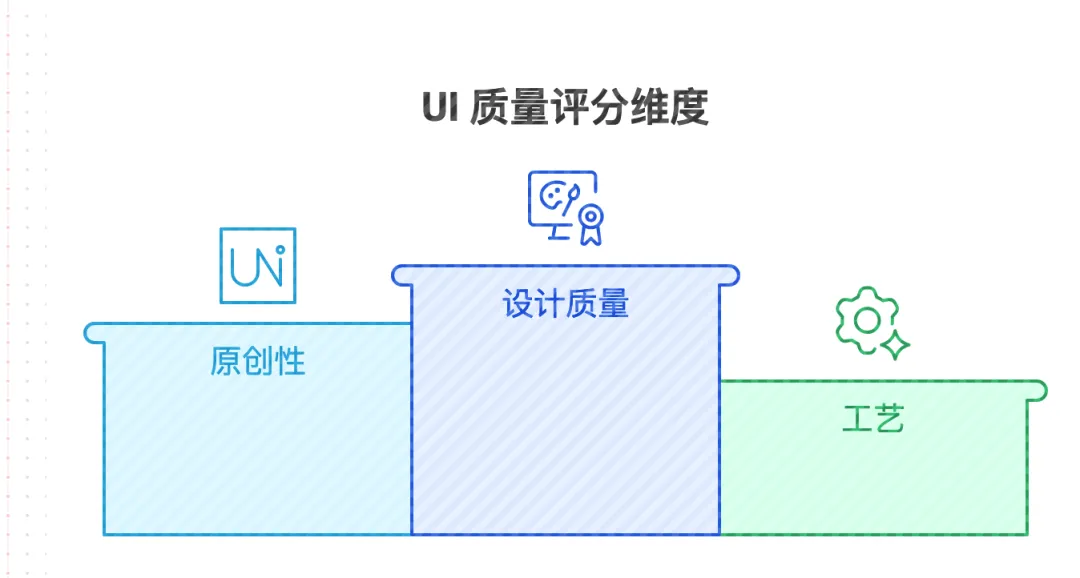
特意加重了"设计质量"和"原创性"的权重——因为模型在这两个维度上经常产出一眼认出来的"AI 糊弄货"。
到了全栈 App 的验收场景,Evaluator 的评分维度换了一套:
产品深度:功能有没有真正实现,还是只是一个看起来像样的壳?
功能完整性:用户能不能实际完成核心操作,还是点进去发现是 stub?
视觉设计:界面有没有统一的视觉语言,还是一堆默认组件拼在一起?
代码质量:代码结构是否清晰,有没有给后续维护留下明显的雷?
Evaluator 不是看代码,而是用 Puppeteer 像真实用户一样点击运行中的 App,截图,研究界面,然后才出评分和批评意见。 这和只跑 unit test 或看代码结构,是完全不同的层次。
5、Harness要随模型能力动态精简
Anthropic 工程师做完实验,发现了一件事:
给 Opus 4.5 设计的 Harness,在 Opus 4.6 上用,很多地方变成了多余的累赘。
比如 Sprint 分解结构,是因为 4.5 存在 Context 焦虑而设计的。
但 4.6 发布后,这个问题基本消失了——Opus 4.6 能更长时间保持连贯,能在更大代码库里可靠运行,还能更好地 catch 自己的错误。
这些,原来都是 Harness 在帮它补的能力。模型自己能做到,Harness 里对应的约束就变成了开销:更慢、更贵、更复杂,却没有对应的收益。
每次换了新模型,重新跑一次你的任务,看看哪些约束还需要,哪些可以去掉。越精简的 Harness,越容易维护,越能随模型升级保持活力。
📌 划重点:
- AI长任务失控,是结构性问题,不是Prompt问题
- 解法一:初始化+增量推进,解决任务失控和状态丢失
- 解法二:Generator/Evaluator分离,解决虚假完成和自评偏差
- Harness要随模型能力动态精简,不是越复杂越好

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)