大模型长文本核心架构全解析(非常详细),搞懂“边读边学”看这篇就够了!
一句话讲清楚👉🏻 这篇 ICLR 2026 Oral 论文提出了 In-Place TTT 框架,让已部署的大模型在推理时直接更新 MLP 层权重,无需重新训练即可获得"边读边学"的能力,一个 4B 参数的模型就能在 128K 长上下文任务上打出远超同体量模型的成绩。
为什么大模型需要「边读边学」?
当前大语言模型的标准范式是「先训练、后部署」——训练结束后权重就被冻结了。这就好比一个学生考完试后再也不学新东西,只能靠考前记住的知识来回答所有问题。
这种静态范式在处理长上下文时矛盾尤为突出。想象一个 4B 参数模型要理解一份 128K token 的长文档:随着文本不断输入,前面的信息逐渐被"挤出"注意力窗口,模型只能依赖有限的 KV Cache 来"回忆"。
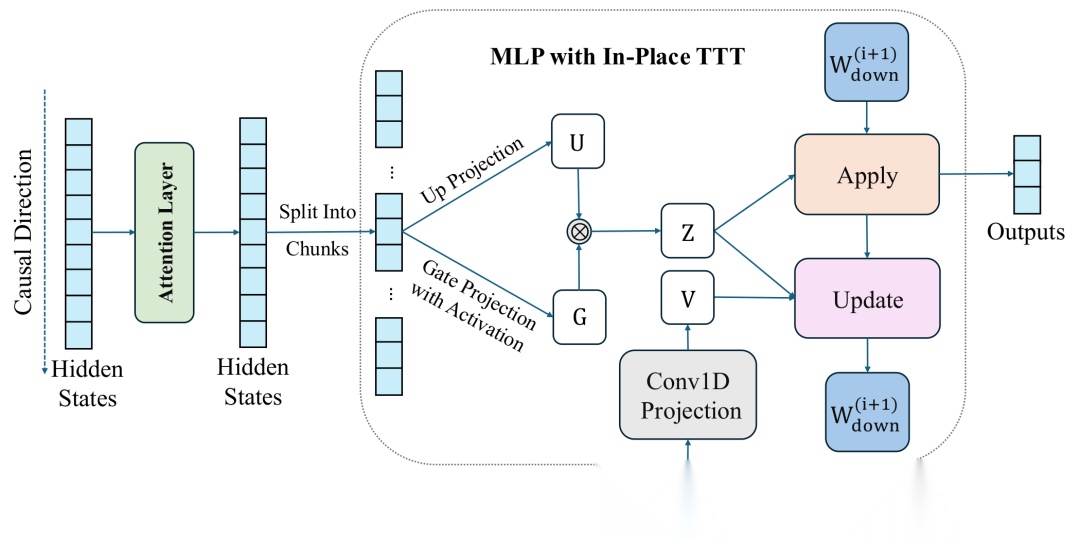
In-Place TTT 的核心思路:让模型在推理时动态调整自身权重,将上下文信息"写入"参数中。
测试时训练( Test-Time Training, TTT ) 提供了一条不同的路径:让模型在推理阶段也能更新部分参数(称为"快速权重"),把读到的上下文信息直接编码进权重里。但此前的 TTT 方法存在三个拦路虎:
•架构不兼容:需要引入额外的模块,无法直接用在现有 Transformer 上
•计算开销大:推理时做反向传播,显存和延迟都翻倍
•目标函数不匹配:用通用的重构损失来更新权重,与语言模型的"下一词预测"任务南辕北辙
北京大学与字节跳动 Seed 团队提出的 In-Place TTT 正是瞄准这三个问题,给出了一套完整的解决方案。
In-Place TTT :三板斧拆解三大难题
第一板斧:把快速权重藏在 MLP 里
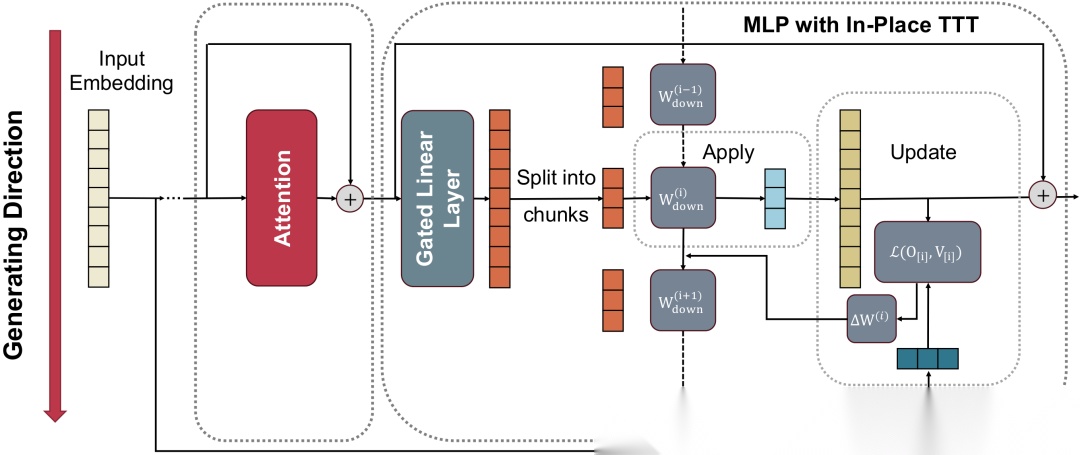
In-Place TTT 框架全貌:在每个 chunk 上先用当前快速权重计算输出,再用输入激活和值向量更新权重。
传统 TTT 方法通常在模型中插入额外的"记忆模块",这会破坏原有架构。 In-Place TTT 的做法更优雅——它直接将标准 Transformer 中每个 MLP 块的最终投影矩阵 W _ down W\_{\text{down}} W_down 作为快速权重。
为什么选 W _ down W\_{\text{down}} W_down ?
这个投影矩阵负责将 MLP 的高维中间表示映射回模型的隐藏维度。它天然具备大容量的参数空间(通常是隐藏维度的 4 倍),非常适合用来"存储"上下文信息。更关键的是,这种方式是真正的"即插即用"——你可以拿一个已经训练好的 LLM ,不改一行架构代码,直接赋予它 TTT 能力。
具体来说,对于输入 Z Z Z, In-Place TTT 的前向过程是:
输出 y _ t y\_t y_t 由快速权重 W _ t W\_t W_t 与输入 z _ t z\_t z_t 相乘得到。注意这里不是全局固定的 W W W,而是随着上下文的读入, W _ t W\_t W_t 在不断变化。
第二板斧: LM-Aligned Value——让更新方向与预训练目标一致
此前的 TTT 方法普遍采用"自重构"损失( Self-Reconstruction Loss )——让模型尝试重构输入自身。但这个目标和语言模型的核心任务"下一词预测"毫无关系,相当于让模型在推理时做一件与本职工作完全不同的事来更新权重。
In-Place TTT 提出了 LM-Aligned Value Objective(语言模型对齐的值目标)。核心思路是:快速权重的更新目标不再是重构输入,而是让更新后的输出能更好地预测下一个 token 。
具体做法分两步:
构造对齐目标值 V V V:从 token embedding 出发,通过一个轻量的投影和卷积操作,生成一个与下一词预测任务语义对齐的目标值。其中卷积操作引入了局部上下文感知能力。
定义损失函数:快速权重 W W W 的优化目标是让 W ⋅ z _ t W \cdot z\_t W⋅z_t 尽可能接近 v _ t v\_t v_t(对齐后的值向量),而非简单地重构 z _ t z\_t z_t 自身。
论文的消融实验明确证实:去掉卷积( w/o Conv )或去掉投影( w/o Proj )都会导致 RULER 得分明显下降,说明这两个组件对于目标对齐都是不可或缺的。
第三板斧:分块更新——线性复杂度下的高效实现
逐 token 做反向传播在计算上是灾难性的。 In-Place TTT 采用了分块更新机制( Chunked Update ):
1.将输入序列切成固定大小的 chunk (如 512 或 1024 个 token )
2.在每个 chunk 内,先用当前的 W _ t W\_t W_t 计算所有 token 的输出( Apply 阶段)
3.然后累积整个 chunk 的梯度,一次性更新 W W W( Update 阶段)
这种"先应用再更新"( Apply-then-Update )的设计确保了严格的因果性——每个 chunk 只能看到自己和之前的信息,不会发生信息泄露。同时,由于梯度是在 chunk 级别累积的,显存占用与 chunk 大小成正比,而非与总序列长度成正比。
关键的是,这种分块策略与上下文并行( Context Parallelism ) 完全兼容,可以在多卡上高效分布式运行。
实验:从预训练到即插即用,全面验证
论文设计了两条实验路线来验证 In-Place TTT 的有效性:一是从头预训练,与各类 TTT 变体正面对决;二是作为即插即用增强,直接升级现有模型。
从头预训练: 500M 和 1.5B 规模的全面对比
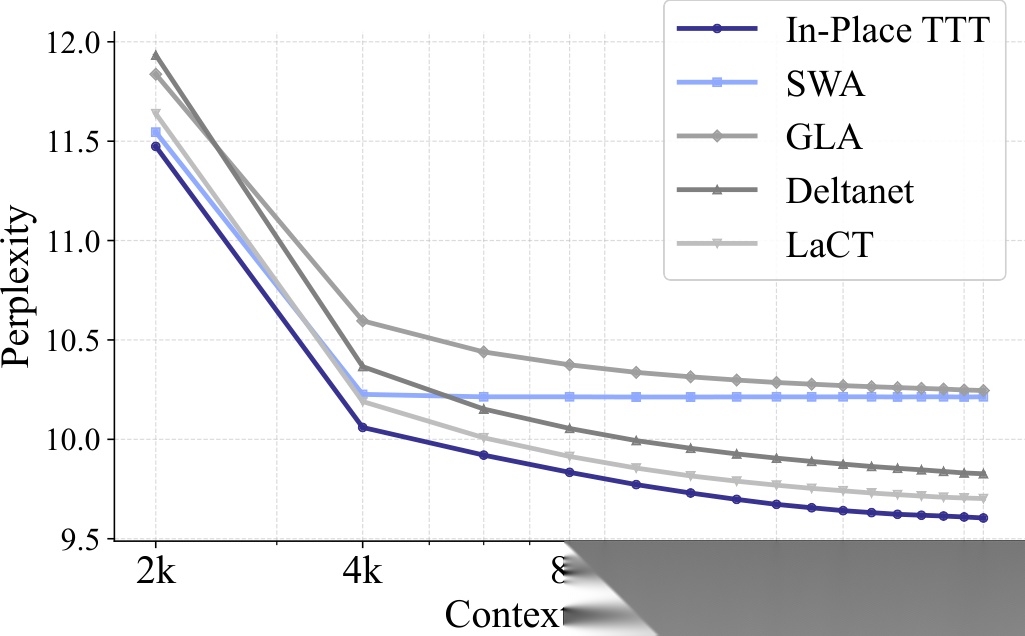
500M 参数模型在 Pile 数据集上的滑动窗口困惑度( Perplexity ): In-Place TTT 在所有上下文长度上均优于竞争对手。
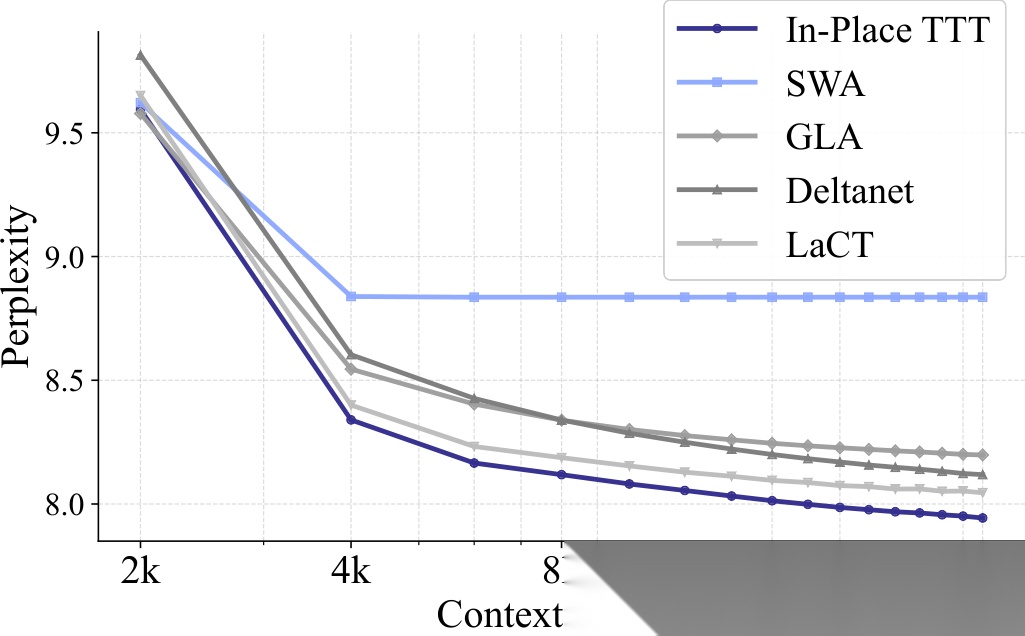
1.5B 参数模型结果:规模增大后优势依旧明显。
在 Pile 数据集上, In-Place TTT 在 500M 和 1.5B 两个规模上都取得了最低的滑动窗口困惑度。值得注意的是,随着上下文长度从 4K 增加到 64K , In-Place TTT 与 TTT-Linear 、 Mamba 等基线的差距反而在拉大——这说明 In-Place TTT 对长上下文信息的利用效率确实更高。
即插即用: 4B 模型直接解锁 128K 上下文
这是论文最具实用价值的实验:拿一个现成的 4B 参数 Transformer (基于 Qwen3-8B 架构),不改架构,只通过持续预训练注入 In-Place TTT 能力。
在 RULER 基准测试(覆盖 NIAH 、 CSI 、 VT 、 FWE 等子任务)上,增强后的 4B 模型在 128K 上下文长度上展现出卓越的性能表现,在多个子任务上均大幅超过未增强的基线版本。
特别是在大海捞针( Needle-In-A-Haystack ) 任务上,这个 4B 模型在 128K 长度下的检索准确率甚至接近了 8B 级别的全注意力模型。这意味着通过 In-Place TTT ,一个小模型能在长上下文场景下发挥出远超自身体量的能力。
消融实验:每个设计都有据可循
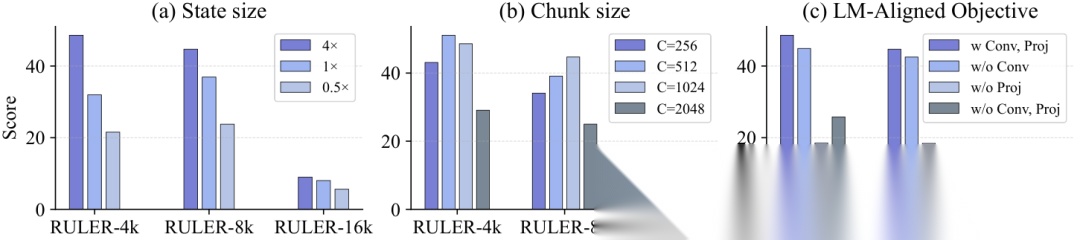
消融实验:(a) 状态大小——越大越好;(b) chunk 大小——中等最优;© LM-Aligned Value 的各组件都不可或缺。
论文对三个关键超参数进行了系统的消融研究:
状态大小( State Size ):快速权重矩阵的参数量直接影响模型"记忆"上下文的容量。实验表明,随着状态大小增加, RULER 得分持续提升,但增长斜率逐渐放缓,存在一个性价比最优点。
Chunk 大小:过小的 chunk (如 64 )会导致更新频率过高、单次更新信息量不足;过大的 chunk (如 4096 )则让模型对最新上下文的响应变得迟缓。实验显示 512 到 1024 是最优的 chunk 大小区间。
LM-Aligned Value 各组件:去掉卷积或投影任一组件,性能都会显著下降。完整的 LM-Aligned Value 设计比朴素的自重构目标高出数个百分点。
效率分析:几乎零额外开销
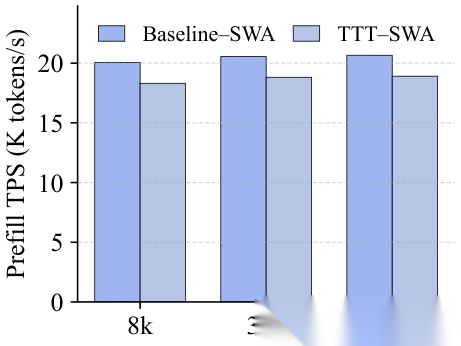
效率分析( SWA 模式下的 prefill 吞吐量): In-Place TTT 引入的额外开销可以忽略不计。
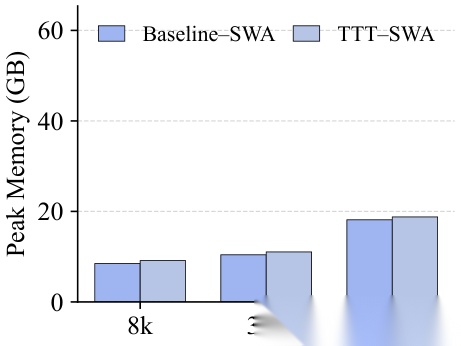
显存占用对比( SWA 模式): In-Place TTT 的显存开销与标准 Transformer 接近。
在 4B 模型上, In-Place TTT 在 Sliding-Window Attention ( SWA )和 Full Attention 两种模式下都做了效率对比:
•Prefill 吞吐量:与标准 Transformer 相比, In-Place TTT 的吞吐量下降非常微小,远优于此前的 TTT-Linear 方法
•峰值显存:由于采用分块更新策略,显存占用几乎与标准 Transformer 持平,比 TTT-Linear 节省了约 33%
这意味着 In-Place TTT 在"推理时学习"的同时,几乎不给部署带来额外的成本负担。
与现有方法的对比:定位与优势
为了更清晰地理解 In-Place TTT 的定位,这里梳理几类相关方法的核心区别:
标准 Transformer + RoPE 长上下文扩展:通过位置编码插值等手段让模型处理更长序列,但本质上权重不变,对长距离信息的建模能力受限于 KV Cache 大小。
TTT-Linear / TTT-MLP( Sun et al., 2024 ):最早提出将 TTT 思想用于序列建模的工作。但它需要从头训练整个模型,并且引入了额外的 TTT 层,与现有 LLM 架构不兼容。
Mamba / Linear Attention:通过线性复杂度的递推机制处理长序列,但信息压缩是固定模式,缺乏自适应能力。
In-Place TTT 的独特之处 在于:它不改架构、不加模块、不要求从头训练,只通过一段持续预训练就能让任意 Transformer LLM 获得测试时学习能力。这种"无侵入式"的方案对于已经部署在线上的模型来说极具实用价值。
TTT 的前世今生:一条被重新照亮的研究路径
测试时训练并不是一个全新的概念。早在 2020 年, Sun 等人就提出了 TTT 的原始框架,通过在测试时对自监督任务做梯度更新来适应分布偏移。但这条路线在很长时间里因为效率问题而未能成为主流。
2024 年, Sun 等人在 NeurIPS 上发表的 TTT-Linear/TTT-MLP 重新点燃了这个方向——他们证明 TTT 可以作为一种新的序列建模范式,在处理长序列时具备独特优势。但那篇工作要求从头训练新架构,限制了实际应用。
In-Place TTT 则在这条路线上迈出了关键一步:它证明了 TTT 能力可以被"移植"到任意已有的 Transformer LLM 上,且开销几乎为零。这为 TTT 从学术概念走向工程实践铺平了道路。
启示与展望
In-Place TTT 的核心贡献不仅是一个性能数字的提升,更是对"大模型该如何处理长上下文"这个问题给出了一种新思路:与其费力扩大注意力窗口或 KV Cache ,不如让模型在推理时真正"学习"——把读到的内容写进权重里。
当然,这个方向还有不少开放问题:
•更大规模的验证:目前最大的实验是 4B 模型,在 70B 甚至更大规模上效果如何,还需进一步验证
•多轮对话场景:在连续多轮交互中,快速权重的累积更新是否会导致灾难性遗忘?
•与其他长上下文技术的组合: In-Place TTT 能否与 Ring Attention 、 Context Parallelism 等技术形成协同效应?
不过, ICLR 2026 给它 Oral 的评价已经说明了学术界对这个方向的认可。随着代码开源(已在 GitHub 可用),相信很快会有更多后续工作涌现。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献218条内容
已为社区贡献218条内容

所有评论(0)