基于AI大神Karpathy的LLM Wiki设计模式思路搭建属于个人的知识库
一、AI大神Karpathy的LLM Wiki设计模式简介
1.0、目前大多数人使用AI的现状
想象一下这样的场景:你带领着两个实习生(1号、2号),但她两的做事方式完全不一样:
1号实习生,你每次问她一个问题,她回答完后就忘记了,下次再问她类似的问题,她根本没有记住上次的内容,又从头说了另一种回答,十分不稳定,并没有任何改善。
2号实习生是你每次问她一个问题,她都会在每次回答后将资料整理在一篇笔记中,下次你在问她类似的问题,她翻开笔记就能回答,且还会对笔记内容进行更新优化,回答效果趋于稳定,且回答的越来越好。
而我们大部分人使用AI的方式就很像1号实习生;每次都是打开新的对话,之前聊过的内容都消失了,这就导致AI对你的研究内容是没有记忆的,每次都是从新开始,十分不稳定。而Karpathy大神做的事,就是将AI尽可能的变为2号实习生。
1.1、Karpathy的LLM Wiki设计模式
Karpathy的LLM Wiki设计模式是:让AI帮你搭建一座会自己长大的百科全书。搭建流程分为如下六个步骤:
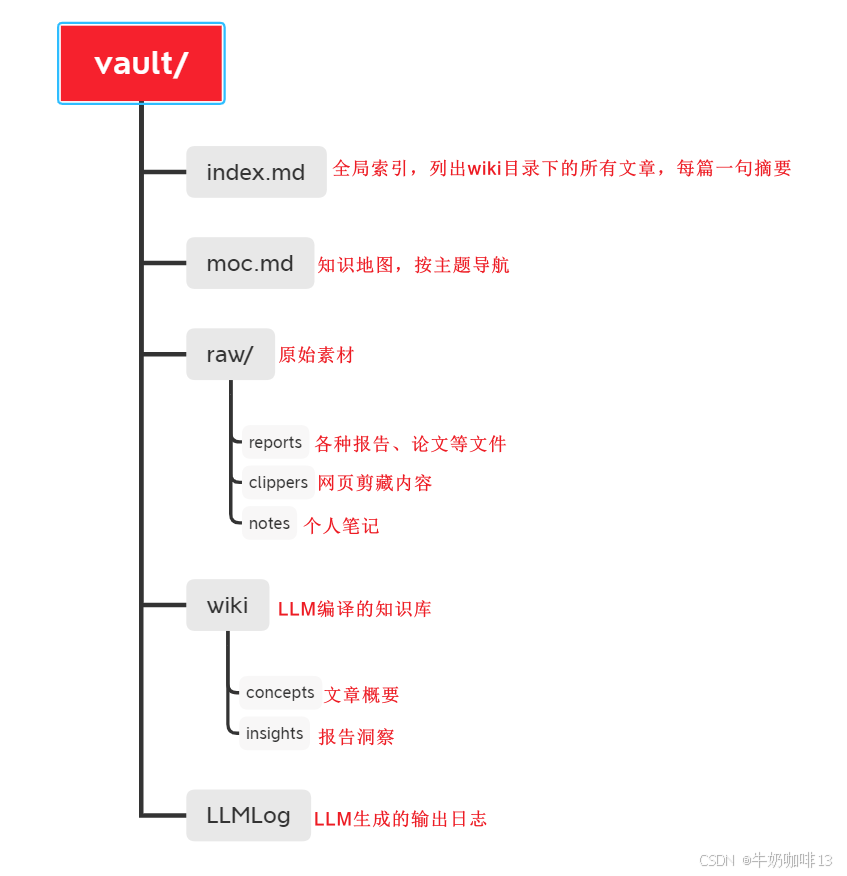
1.1.1、把资料全部放在一个文件夹中
Karpathy在网上看到一些好的文章、论文、Github上的源码、图片等内容,就会借助名为【Web Clipper、Obsidian Web Clipper】的浏览器插件将看到的这些网页内容存到电脑本地的【raw】文件夹中。
raw:表示原生、未加工,是“原始素材”,没有经过任何整理的内容。
1.1.2、告诉AI将原始素材编译为百科全书
LLM Wiki设计模式的关键就是这里,Karpathy自己并不整理笔记,他是让AI自己阅读完【raw】文件夹中的所有原始文件,然后自动生成一本Wiki的(即:这是一组有结论的笔记,包含【自动写摘要】【自动分类】【自动在相关主题之间建立连接】)。他自己只是负责将新的资料丢到【raw】文件夹中,AI就负责将新的资料消化进现有的知识体系里。
注意:你自己的笔记和AI产出的知识库应该分开存放(若混在一起,则你搜寻的结果、连接图、反向连接都会被AI生成的内容淹没;这样你就没办法分清哪些是自己的想法、哪些是AI整理出来的了)【raw】文件夹中的内容是属于自己亲自整理出来的权威来源,AI产出的Wiki则独立存放,且AI产出Wiki的每篇文章都有反向连接指向原始资料,随时可以追溯来源。
1.1.3、直接对这本百科全书提问
当wiki长到一定的规模(Karpathy说他某个主题的知识库大约有100篇文章、40万字)时就可以直接对AI提问了;AI会去翻这本百科全书来回答你。Karpathy本以为要用RAG技术,但是发现AI自己维护的索引和摘要已经够好了,不需要额外的搜寻系统.
1.1.4、答案不只是文字
Karpathy不是让AI回一段文字就结束了,他会让AI产出各种不同格式的输出:
| AI输出格式 | 说明 |
|---|---|
| Markdown文件 | 格式化的笔记,可以在支持Markdown的软件中漂亮展示(如:obsidian、Joplin) |
| Marp简报 | 一种可以将Markdown笔记之间转换为投影片的工具,不用打开PowerPoint。 |
| matplotlib图表 | 可用程序画出来条形图、折线图、圆饼图等效果图 |
真正聪明的地方是:他会把这些查询结果【回存】到百科全书里面(也就是说:你每次问的问题与得到的答案,都会变成知识库的一部分)【知识库越用越厚,越用越好用】。
1.1.5、定期让AI帮知识库做“健康检查”
Karpathy会让AI扫描整本百科全书,找出资料相互矛盾的地方,补上缺漏的资讯(用网络搜索)发现不同主题之间有趣的关联。这可应对到现实工作中的一种情况(每个季度需要盘点一次档案,看看有没有过时的资料、重复的内容、或者是漏掉的东西)。
1.1.6、自己做小工具
Karpathy使用vibe coding的方式做了一个简易的搜索引擎,有网页界面也有命令行版本(这一步的目的是:当知识库大到一定的程度,你会想要更好的方式来搜寻和操作它)一切为了便利。除了可以生成静态的图表与简报外,还可以让AI直接生成动态可交互的仪表盘,这样就可以让知识的表现更加灵活。
1.2、LLM Wiki设计模式的适用场景
| LLM Wiki设计模式的适用场景 | 说明 |
|---|---|
| 个人体系管理 | 可用于将个人的日记、文章、相关资料、知识体系等内容分析整理,搭建出个性化的知识库,方便自我提升、追踪自己的目标、查缺补漏。 |
| 主题的深度研究 |
可针对特定的主题——不断充实相关的论文、笔记、报告、文章等原始素材,便可逐步构建出一个不断演进论点的主题百科。 |
| 阅读梳理书籍 | 可对书籍边读边将每章的内容归档整理出核心观点与摘要,为书籍中的人物、主题、叙事情节登线索建立各自的页面,并相互关联。这样读完书籍后,你就拥有了一本丰富的伴读知识库(可在极短的时间内消化书籍,充实自己)。 |
| 商业百科 |
可根据产品相关的需求、数据、SOP内容维护产品的体系化百科,为产品赋能。 团队内可根据聊天记录、会议记录、项目文档等资料产出对应项目的知识库,并不断跟踪进展,信息共享。 |
| 其他 | 可实现其他方面(如:竞品分析、旅游规划、内容梳理、学习指导、信息共享等)随着时间的推移提供的原始素材越来越多,即可将这些内容按照你的要求梳理、归纳、提炼出各种有意义的场景 |
1.3、LLM Wiki设计模式的基础架构
| LLM Wiki设计模式架构 | 说明 |
|---|---|
| 原始素材【raw】 | 你收集的原始资料(如:文章、论文、图片、数据文件等),这些内容是不可改变的,是知识库的基础来源;【LLM(大语言模型)只能读取它们,但是决不能修改它们】。 |
| 知识库【wiki】 | 是由LLM(大语言模型)生成的所有Markdown格式文件的根目录(包含核心观点、概念、摘要、对比表格、概览与综合分析等内容);【LLM完全拥有这一层的所有权,它可以负责创建、更新、维护交叉引用并保持一致性】。 |
| 约束配置【agent】 | 是一个配置文件(如:claude code的CLAUDE.md、Codex的AGENTS.md)主要是用于告诉LLM这个wiki的结构是什么、命名约定是什么,以及在读取资料、回答问题或者维护wiki时应该要遵守什么流程,如何操作等约束说明。这个约束配置会随时时间的推移需要你不断的优化。 |
| 索引目录【index】 | 它是wiki中所有内容的目录;每个页面都包含核心的观点、摘要及其日期与来源等元数据;按类别组织,LLM在每次读取新资料时都会更新它。LLM回答问题时,会先查看index找到相关页面,在中等规模下(约100份资料,数百个页面)时,该方法效果很好,不用搭建复杂的向量检索(RAG)基础设施。 |
|
操作日志 【LLM output log】 |
它是按照时间顺序记录的;这是一个【只能追加的记录】(记录了何时发生什么【查询、检查、新增的内容】)。注意:若每条记录都以一致的前缀开头,则日志就能用最简单的工具进行解析,这能让LLM了解最近做了什么。 |
1.4、为什么LLM Wiki设计模式有效
大家知道,维护知识库最繁琐的工作是将内容记录清楚(即:记录的内容、交叉引用、保持核心概念、摘要的最新;以及新旧数据的冲突,且要保持多个页面间保持一致性)这个维护负担是十分繁重且枯燥的。但这个工作给到LLM将是如鱼得水,因为LLM就擅长处理这些重复性高的枯燥内容,且效率十分高效,它可以一次性就能操作多个文件进行关联操作,可以轻而易举的保持知识库的最新良好状态。
人类并不擅长这类重复枯燥的操作;人类更擅长的是精选资料、指导分析梳理、并进行思考、提出有建设性的问题等顶层操作,而LLM则是将剩下的内容搞定,呈现出来,人类在进行审阅优化,以此循环推进。
二、怎么做?才能搭建出LLM Wiki模式的知识库
2.1、建立你的原始素材库
你可以使用的免费工具有【Obsidian】【Notion(免费版)】【MarkText】;做法很简单,你只用将你看到值得保存的论文、报告、笔记、图片等内容全部保存到【原始素材】(raw)文件夹下,不用管格式与分类,直接存下。
在这里你还可以在浏览器中安装插件(如:Web Clipper或Obsidian Web Clipper),就可以将在网页存成笔记到本地了,十分便捷。
【重点:不需要花费大量的时间来整理内容,这些繁琐的工作教给AI】。
2.2、 定期让AI消化原始素材
每周或每月,定期的把你的原始素材给到AI(如:Claude、OpenCode、阿里千问、本地使用Ollama搭建的LLM),然后使用如下类似的提示让AI执行:
#让AI自动整理原始素材的约束配置(即:告诉AI怎么做)示例:
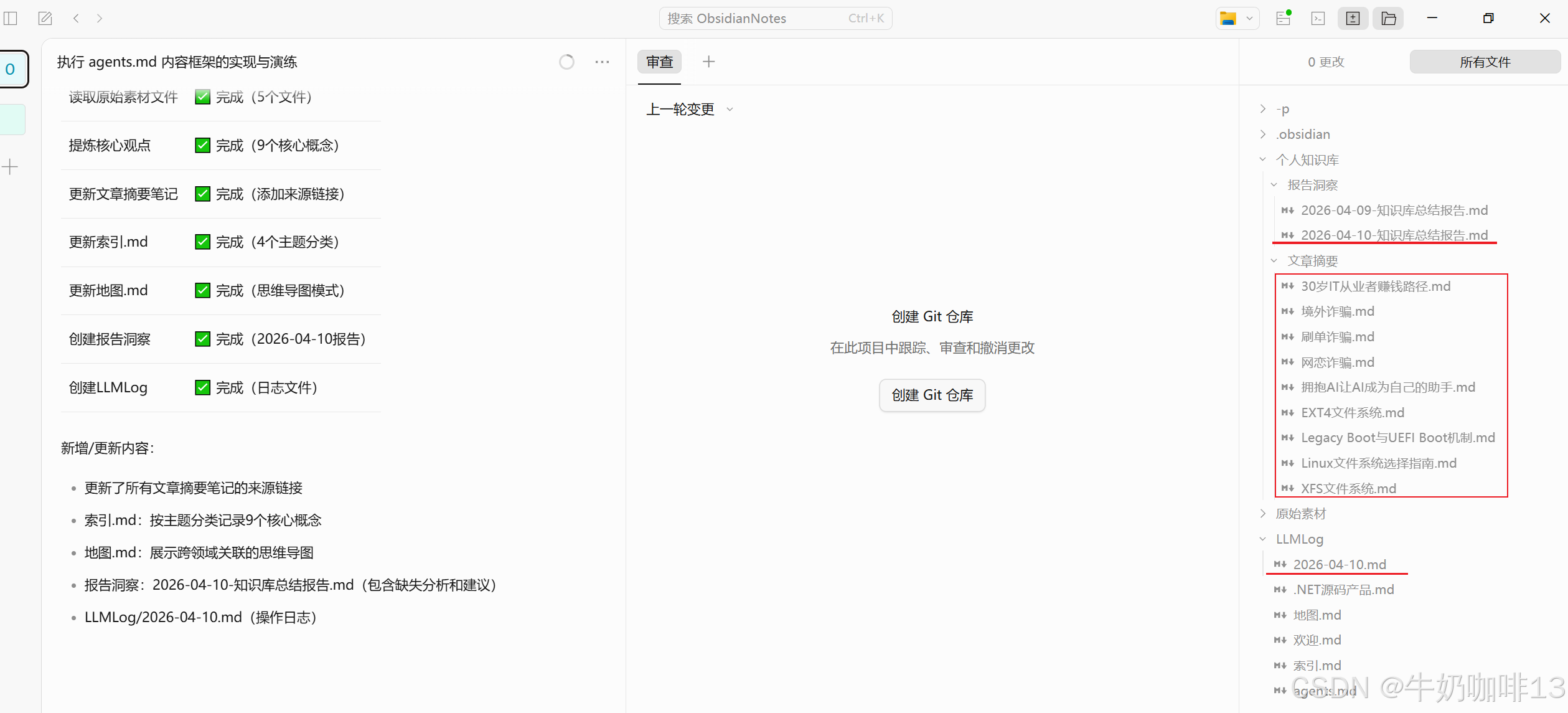
你是我个人知识库的管家,请阅读“原始素材”文件夹中的所有文件,读完后请执行如下操作:
1、提炼每个文件中的核心观点、概念;
2、为每个核心观点、概念写1-6句摘要;
3、在 “个人知识库”文件夹下的“文章摘要”文件夹中为每一个核心观点、概念创建一篇markdown格式的笔记,且该笔记需要指明主题,若笔记已存在则更新,否则创建新的,且该笔记在最后必须链接上它的来源;
4、在根目录下创建一个名为“索引.md”的文件中记录每个核心观点、概念的的链接,并将核心观点、概念按照主题分类,若遇到旧的内容,请更新;
5、在根目录下创建一个名为“地图.md”的文件中标出不同概念之间的关联,按照主题分类,以思维导图的模式呈现,若遇到旧的内容,请更新;
6、在 “个人知识库”文件夹下的“报告洞察”文件夹中按照当前的日期给出一篇markdown格式的总结报告;且该报告中也需要列出目前资料里面还缺少哪些方面;最后在报告末尾给出建议、方向。
7、将此次所有的思考与操作内容按照当前的日期生成一份markdown格式的文件,且按照追加方式将每条日志写入到该文件中,且每条日志以二级标题开头,包含时间戳、操作类型和内容,且该文件是位于根目录下名为“LLMLog”的文件夹中,且不能修改或删除历史记录。

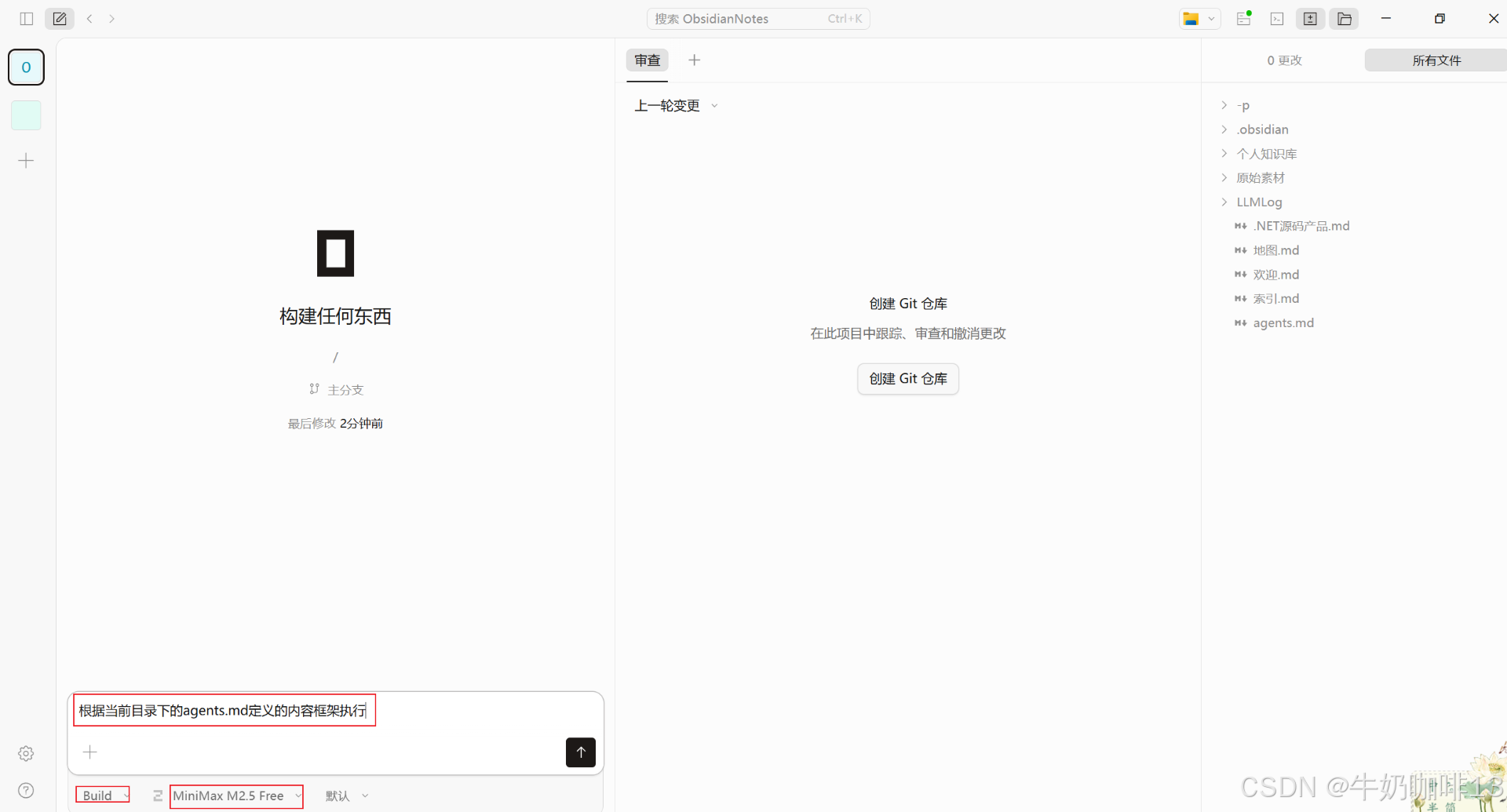
agents.md文件中对AI的框架进行约束后,则可以打开LLM(大语言模型)进行操作了,如下为使用obsidian为前端内容编辑查看工具,配合大语言模型OpenCode实现对个人知识库的操作【即:在opencode左侧的加号(+)选择知识库的根目录,然后在输入框中输入根据当前目录下的agents.md定义的内容框架执行】:
2.3、 对你的知识库提问
当你的wiki(知识库)积累到一定的程度,你就可以使用LLM进行对话了,且在开始对话的时候:
1、首先把自己的wiki(知识库)告诉AI,让它使用你自己的wiki作为背景资料。
2、接着你就可以咨询AI关于知识库内资料的相关问题了(此时AI就会根据你累积的所有资料来给出回答,而不是从零开始了);但要注意:AI的单次对话能读的上限(ChatGPT大概是10万字;Claude大概是15万字),因此若你的wiki太大,则可以在开始的时候就只告诉AI你此次想要咨询的相关资料作为背景资料。
进阶的做法是:Claude的Projects可以实现将档案上传为专业知识(即:可以将你的wiki设置为永久背景,这样每次新开对话就不用重新设置指定的wiki背景了)。
三、其他资料
AI员工——OpenCode、OpenClaw+Ollama的安装与配置![]() https://coffeemilk.blog.csdn.net/article/details/158777768免费笔记软件且优先本地私有化——Joplin、Obsidian
https://coffeemilk.blog.csdn.net/article/details/158777768免费笔记软件且优先本地私有化——Joplin、Obsidian![]() https://blog.csdn.net/xiaochenXIHUA/article/details/159675434?spm=1001.2014.3001.5501
https://blog.csdn.net/xiaochenXIHUA/article/details/159675434?spm=1001.2014.3001.5501

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)