Piggy_Packages V2026.1 帮助文档(八)WRFDA背景误差协方差矩阵
获取Piggy_Packages
Piggy_Packages 是⼀个在 Windows 操作系统环境下“开箱即⽤”的便捷式气象科研环境。⽆需复杂的安装和配置步骤,就能快速投⼊到实际的科研⼯作中。
还没有Piggy_Packages的同学,请参考这篇帖子获取:
Piggy_Packages V2026.1 帮助文档(一)开箱即用
背景误差协方差矩阵
背景误差协方差矩阵(B 矩阵)是资料同化系统中的核心组件。它代表了对模型背景场误差的统计估计。
在同化过程中,B 矩阵决定了背景场与观测场之间信任程度的相对权重。它定义了观测增量如何在空间上进行传播,即将一个点上的观测信息扩散到周围网格点以及其他物理变量上的方式。在变分同化中,通过控制变量变换(如 B=UUT)对代价函数进行预处理,使其在最小化迭代过程中更容易收敛。
WRFDA 提供了多种背景误差协方差定义选项,它们具有不同的物理属性:
- CV3 (NCEP 全局 BE): 这是一个全局性的背景误差模型,可用于任何区域领域。它基于 NMC 方法,利用 NCEP 全球预报模型(GFS)长期运行的差异统计得出,控制变量处于物理空间,使用垂直递归滤波器来模拟垂直协方差。
- CV5和 CV7 (区域 BE):它们是区域相关的,必须针对特定的模拟区域生成。控制变量处于特征向量空间,使用经验正交函数 (EOF) 来表示垂直协方差。其中CV5使用流函数 (Ψ)、不平衡速度势 (χu)、不平衡温度 (Tu)、伪相对湿度 (RHs) 和不平衡地面气压 (Ps,u) 作为控制变量。CV7使用 u、v、温度 (T)、伪相对湿度 (RHs) 和地面气压 (Ps) 作为控制变量。
我们在上一节的同化过程中,就使用了CV3背景误差协方差矩阵,在这一节中我们来构建CV7背景误差协方差矩阵。上面已经提到了CV7背景误差协方差矩阵是区域相关的,必须针对我们要模拟的区域进行构建。
NMC方法认为,如果两个针对同一时刻但起报时间不同的预报(如48小时预报和24小时预报)在某个区域差异很大,说明模式在该区域的预报不确定性较高,因此模型在该区域应该更加相信观测,反之,则应该更加相信背景场。
在实际操作中,我们会制作若干组(至少覆盖一个月时间)这样两个针对同一时刻但起报时间不同的预报资料。生成具有统计学意义的BE矩阵。本文出于演示目的,仅制作几组数据来进行BE矩阵的统计。
准备预报资料
首先我们回到Home目录,创建一个名称为Case6的目录,并进入。
cd
mkdir -p Case6
cd Case6将WRF-Real拷贝到当前目录,并进入其中的run目录,将Case1中生成好的met_em文件、WRF的配置文件namelist.input拷贝到run目录。
cp -r /pp_model/WRF-4.7.1/WRF-Real .
cd WRF-Real/run
ln -s ~/Case1/WPS/met_em.d01.* .
cp -f ~/Case1/WRF-Real/run/namelist.input .返回到上级目录,我们通过脚本来完成几天时间的批量运行。
cd ..
touch batch_runwrf.py
open -e batch_runwrf.py粘贴下方内容:
import os
import shutil
import f90nml
import subprocess
from datetime import datetime, timedelta
def prepare_and_run_nmc():
# --- 配置参数 ---
base_run_dir = os.path.abspath("run")
output_flist = "flist.txt"
# 定义有效时间(Valid time)的起止和间隔
valid_time_start = datetime(2026, 3, 30, 0, 0, 0)
valid_time_end = datetime(2026, 3, 31, 0, 0, 0)
interval = timedelta(hours=6)
# 需要生成的预报时效对
forecast_hours = [12, 24]
# --- 检查基础目录 ---
if not os.path.exists(base_run_dir):
print(f"错误: 找不到基础目录 {base_run_dir}")
return
flist_paths = []
current_valid_time = valid_time_start
run_index = 1
# --- 主循环:遍历每一个有效时间 ---
while current_valid_time <= valid_time_end:
print(f"\n{'='*50}")
print(f"[处理目标有效时间]: {current_valid_time.strftime('%Y-%m-%d %H:00:00')} (run{run_index})")
print(f"{'='*50}")
for f_hour in forecast_hours:
# 1. 计算起报时间 (Start time)
start_time = current_valid_time - timedelta(hours=f_hour)
# 2. 定义并拷贝新目录
new_run_name = f"run{run_index}_{f_hour}h"
new_run_dir = os.path.abspath(new_run_name)
if os.path.exists(new_run_dir):
print(f" -> 清理已存在的目录: {new_run_name}")
shutil.rmtree(new_run_dir)
print(f" -> 正在拷贝目录至: {new_run_name} ...")
shutil.copytree(base_run_dir, new_run_dir)
# 3. 修改 namelist.input
nml_path = os.path.join(new_run_dir, "namelist.input")
if os.path.exists(nml_path):
nml = f90nml.read(nml_path)
tc = nml['time_control']
tc['run_days'] = 0
tc['run_hours'] = f_hour
tc['run_minutes'] = 0
tc['run_seconds'] = 0
tc['start_year'] = [start_time.year]
tc['start_month'] = [start_time.month]
tc['start_day'] = [start_time.day]
tc['start_hour'] = [start_time.hour]
tc['end_year'] = [current_valid_time.year]
tc['end_month'] = [current_valid_time.month]
tc['end_day'] = [current_valid_time.day]
tc['end_hour'] = [current_valid_time.hour]
nml.write(nml_path, force=True)
print(f" -> 已修改 namelist.input (起报: {start_time.strftime('%m-%d %HZ')}, 时长: {f_hour}h)")
else:
print(f" -> 错误: {new_run_name} 中没有找到 namelist.input!跳过当前运行。")
continue
# 4. 运行 real.exe 和 wrf.exe
try:
print(f" -> [执行] 开始运行 real.exe (np=4)...")
# cwd=new_run_dir 确保是在新目录下执行命令
subprocess.run(["mpirun", "-np", "4", "./real.exe"], cwd=new_run_dir, check=True)
print(f" -> [执行] real.exe 完成!开始运行 wrf.exe (np=4)...")
subprocess.run(["mpirun", "-np", "4", "./wrf.exe"], cwd=new_run_dir, check=True)
print(f" -> [执行] wrf.exe 运行成功!")
except subprocess.CalledProcessError as e:
print(f" -> [报错] 模型运行失败,命令返回非零状态码: {e}")
print(f" -> 请检查 {new_run_dir} 目录下的 rsl.error.0000 文件。跳过记录此目录。")
continue # 如果运行失败,就不把它加入 flist.txt 中
# 5. 预测并记录生成的最后一个(最新)wrfout 的绝对路径
wrfout_filename = f"wrfout_d01_{current_valid_time.strftime('%Y-%m-%d_%H:%M:%S')}"
wrfout_abs_path = os.path.join(new_run_dir, wrfout_filename)
flist_paths.append(wrfout_abs_path)
current_valid_time += interval
run_index += 1
# --- 将所有成功的 wrfout 路径写入 flist.txt ---
print(f"\n正在将 {len(flist_paths)} 个成功的 wrfout 路径写入 {output_flist}...")
with open(output_flist, "w") as f:
for path in flist_paths:
f.write(f"{path}\n")
print("全部操作完成!")
if __name__ == "__main__":
prepare_and_run_nmc()
运行脚本:
python batch_runwrf.py运行需要较长时间,运行完成后生成对应的预报场和文件列表flist.txt
制作BE矩阵
然后我们返回上级目录,将gen_be_v3拷贝过来,进入目录,拷贝flist.txt。
cd ..
cp -r /pp_model/WRF-4.7.1/WRFDA/var/gen_be_v3 .
cd gen_be_v3
cp ../WRF-Real/flist.txt .编辑配置文件:
touch namelist.gen_be_v3
open -e namelist.gen_be_v3粘贴下方内容:
&gen_be_nml
nc_list_file = 'flist.txt'
be_method = 'NMC'
varnames = 'T', 'U', 'V', 'RH', 'PSFC', 'PSI', 'CHI_U', 'T_U', 'PSFC_U'
do_pert_calc = .true.
do_slen_calc = .true.
slen_opt = 2
do_eof_transform = .true.
pert1_read_opt = 1
/
&ens_nml
/
然后运行统计程序:
mpirun -np 4 ./gen_be_v3.exeCV7矩阵
我们首先将T、U、V、RH、PSFC统计结果组装为CV7矩阵:
util/combine_be_cv7.exe
mv be.dat be.dat.cv7回到Case5的WRFDA运行目录:
cd ~/Case5/WRFDA/var/da将上次运行的结果和计算的分析增量重命名,加上_cv3后缀,以进行区分:
mv wrfvar_output wrfvar_output_cv3
mv analysis_increment.nc analysis_increment_cv3.nc将新的be.dat拷贝到当前目录:
rm be.dat
cp ~/Case6/gen_be_v3/be.dat.cv7 ./be.dat修改namelist.input
open -e namelist.input将cv_options修改为7:
&wrfvar7
cv_options = 7,
/
运行WRFDA,并将运行结果加上_cv7后缀,计算分析增量并可视化:
mpirun -np 4 ./da_wrfvar.exe
mv wrfvar_output wrfvar_output_cv7
cdo sub wrfvar_output_cv7 fg analysis_increment_cv7.nc
Panoply analysis_increment_cv7.ncCV5矩阵
【Piggy_Packages V2026.1.1 及更新版本支持使用GEN_BE_V3生成CV5矩阵】
返回刚才的目录:
cd -将PSI、CHI_U、T_U、RH、PSFC_U统计结果组装为CV5矩阵:
util/combine_be_cv5.exe
mv be.dat be.dat.cv5回到Case5的WRFDA运行目录:
cd ~/Case5/WRFDA/var/da将新的be.dat拷贝到当前目录:
rm be.dat
cp ~/Case6/gen_be_v3/be.dat.cv5 ./be.dat修改namelist.input
open -e namelist.input将cv_options修改为5:
&wrfvar7
cv_options = 5,
/
运行WRFDA,并将运行结果加上_cv5后缀,计算分析增量并可视化:
mpirun -np 4 ./da_wrfvar.exe
mv wrfvar_output wrfvar_output_cv5
cdo sub wrfvar_output_cv5 fg analysis_increment_cv5.nc
Panoply analysis_increment_cv5.nc结果对比
可以发现,CV3、CV5和CV7的分析增量有很大不同:
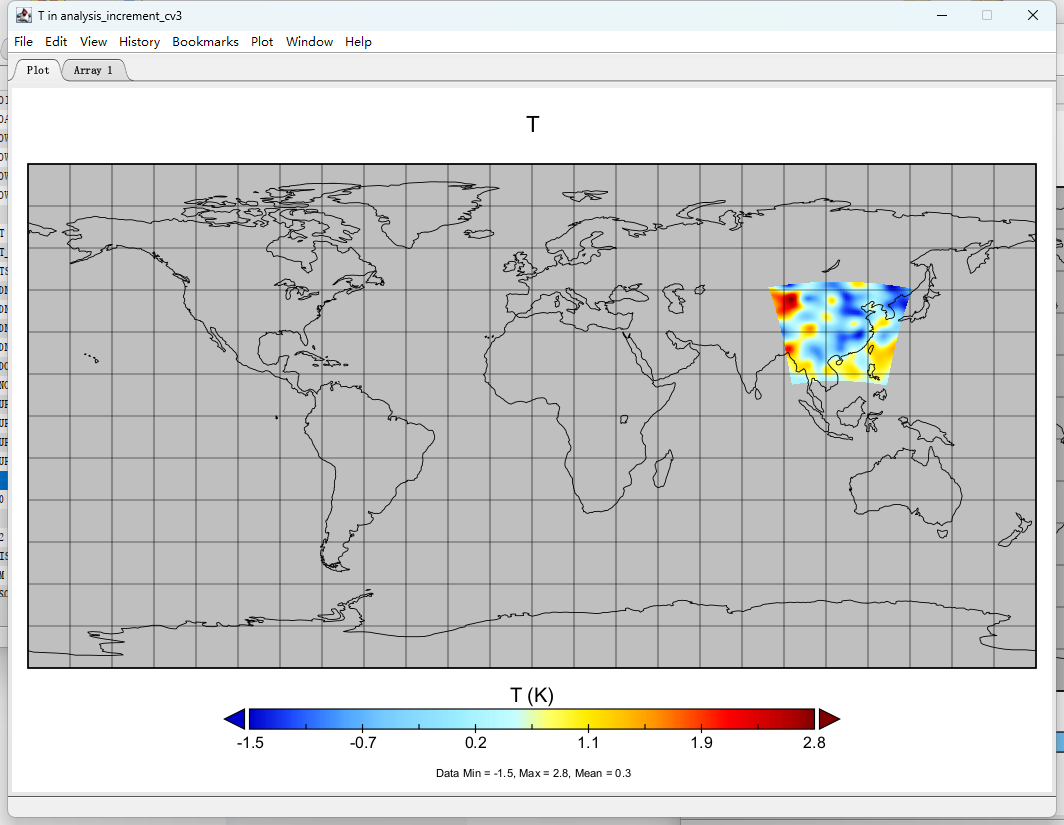
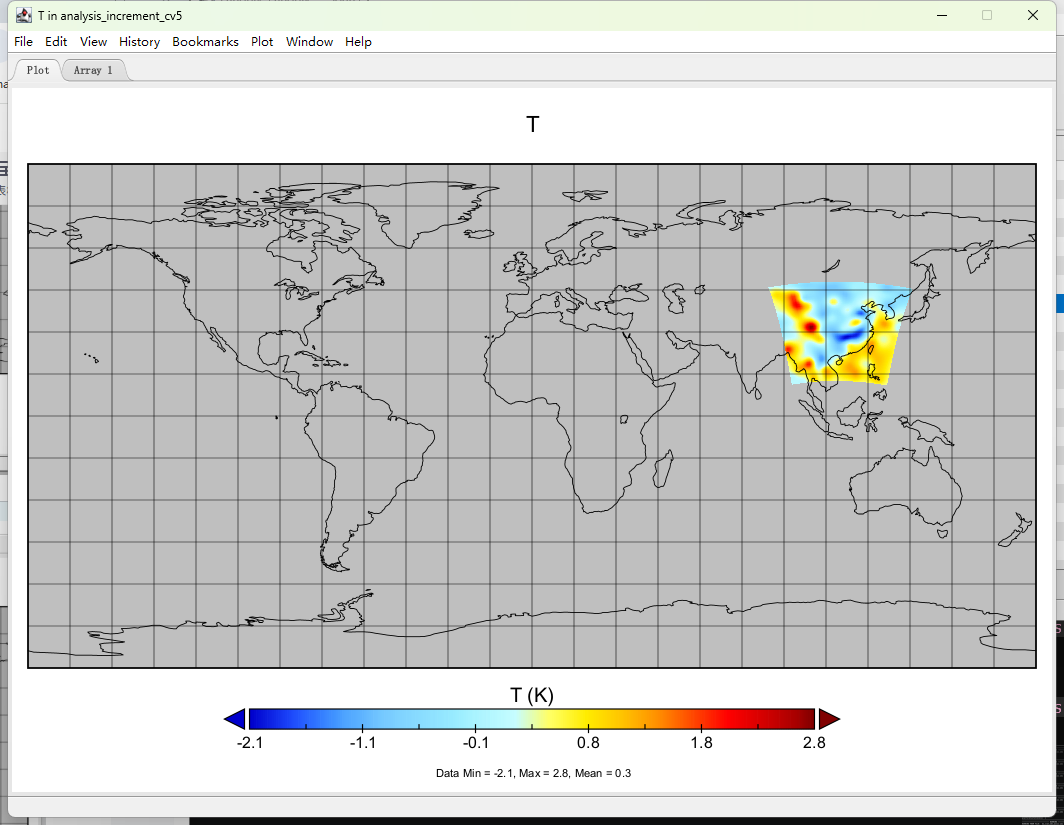
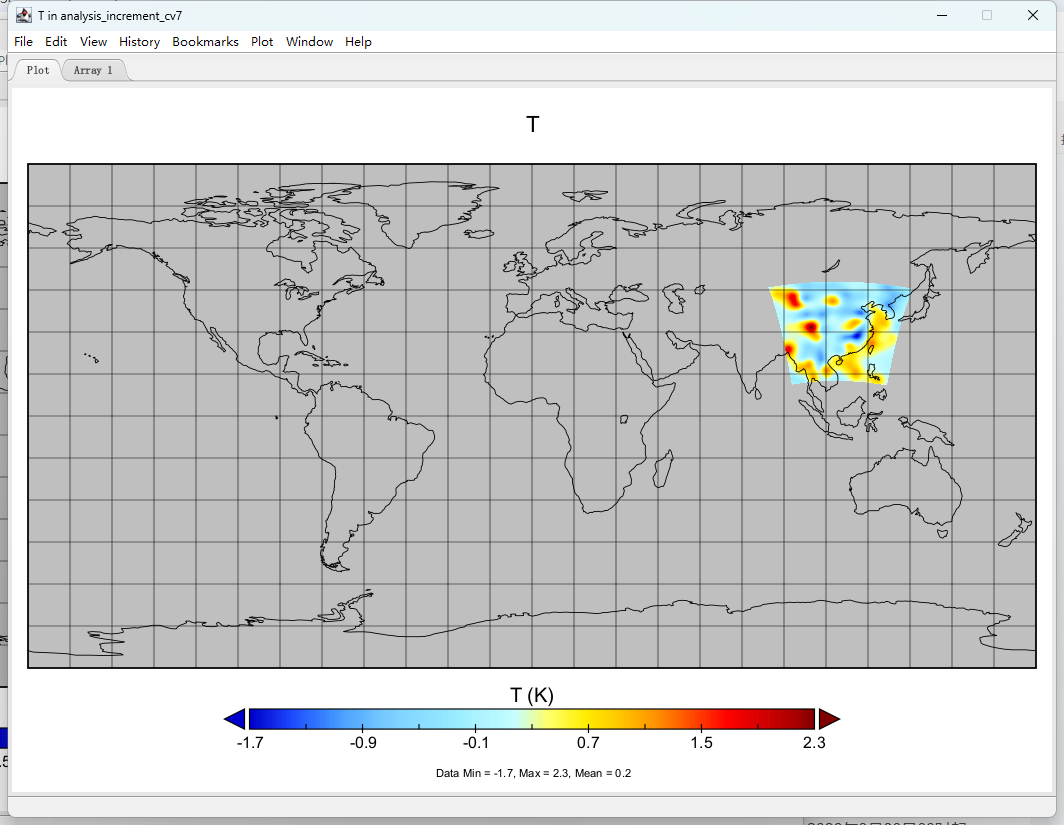
单点同化试验
WRFDA 单点同化试验是资料同化中的一种重要诊断手段。通过在系统中人为加入一个“伪观测”点,可以直观地观察到背景误差协方差矩阵和观测误差统计数据如何在模型变量空间内发挥作用。
编辑namelist.input
open -e namelist.input加入以下两段配置:
&wrfvar15
num_pseudo = 1, ! 开启伪观测功能。注意:当此项为 1 时,所有真实观测资料都会被自动屏蔽
pseudo_x = 23.0, ! 观测点在模拟网格中的 X 方向(I)坐标
pseudo_y = 23.0, ! 观测点在模拟网格中的 Y 方向(J)坐标
pseudo_z = 14.0, ! 观测点在垂直层索引(K)位置,按自底向上顺序
pseudo_val = 1.0, ! 设置伪观测相对于背景场的差异量。对于温度,单位为 K
pseudo_err = 1.0, ! 设置伪观测的误差标准差,单位与 pseudo_val 一致
/&wrfvar19
pseudo_var = 't', ! 指定同化的变量名称。't' 代表温度
/
将cv_options修改为7:
&wrfvar7
cv_options = 7,
/
拷贝be.dat:
rm be.dat
cp ~/Case6/gen_be_v3/be.dat.cv7 ./be.dat运行WRFDA:
mpirun -np 4 ./da_wrfvar.exe
mv wrfvar_output wrfvar_output_cv7_sot
cdo sub wrfvar_output_cv7_sot fg analysis_increment_cv7_sot.nc
Panoply analysis_increment_cv7_sot.nc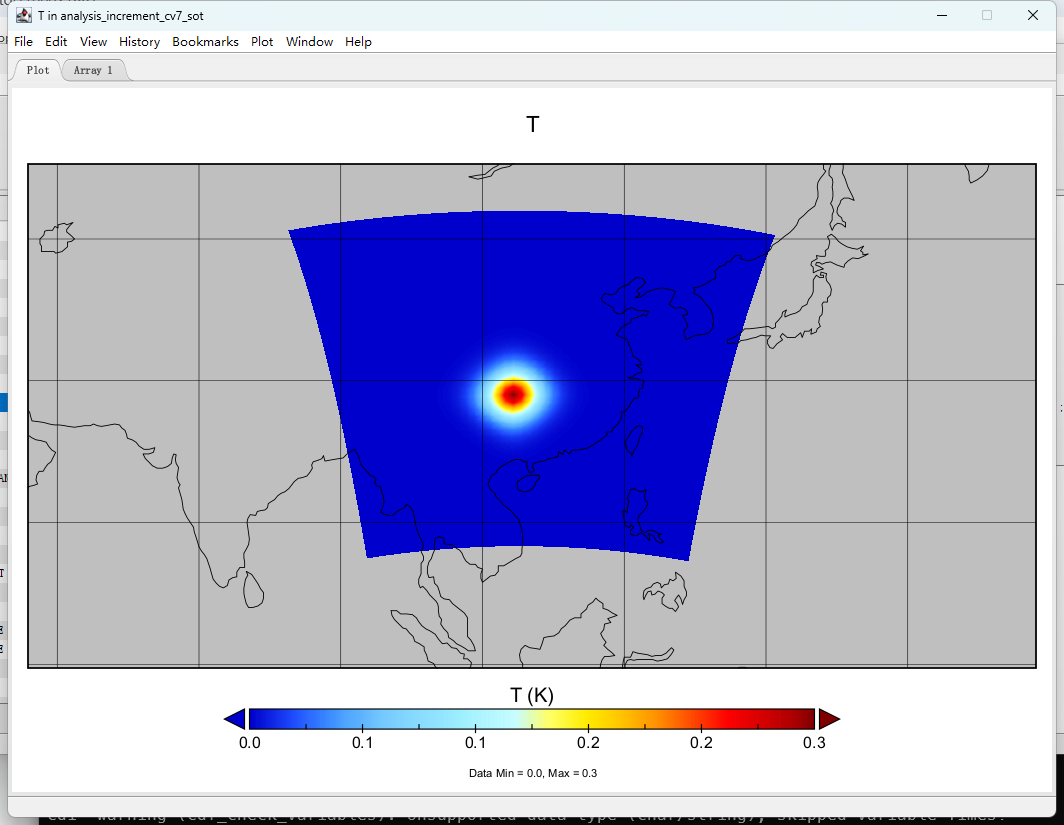
下面你可以自行尝试使用CV3、CV5矩阵进行单点同化试验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)