大模型开发框架LangChain
什么是LangChain?请解释其核心组件和设计思想。
## 🎯 面试回答标准结构
### 第一层:一句话定义(破冰)
> "LangChain 是一个**用于构建大语言模型应用的开源框架**。它的核心目标是**标准化和模块化**LLM应用的开发流程,让我们能够轻松地将大模型与外部工具、数据和记忆组件连接起来。"
**关键词**:开源框架、标准化、模块化、连接外部世界
---
### 第二层:核心设计思想(展示深度)
LangChain 的设计思想可以概括为 **"可组合性"** ,就像乐高积木一样:
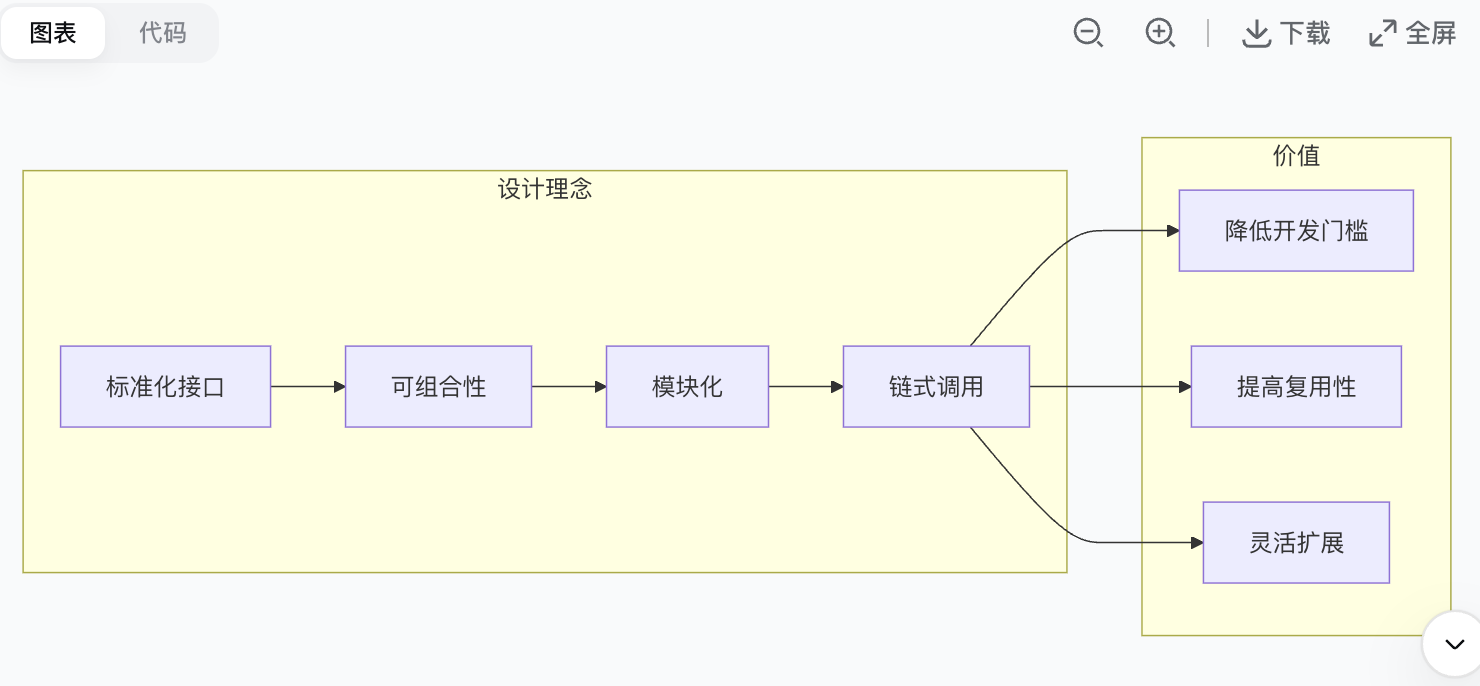
**具体体现**:
1. **标准化接口**:所有模型(OpenAI、Ollama、Anthropic)都遵循统一的调用规范
2. **可组合性**:通过 `|` 管道操作符将组件串联成链
3. **关注点分离**:每个组件只做一件事(提示词模板只负责格式化、模型只负责生成)
4. **LCEL(LangChain Expression Language)**:声明式的链式语法,让代码更简洁
---
### 第三层:五大核心组件(展示广度)
LangChain 有五个核心模块,我用一个**RAG应用**来串联说明:
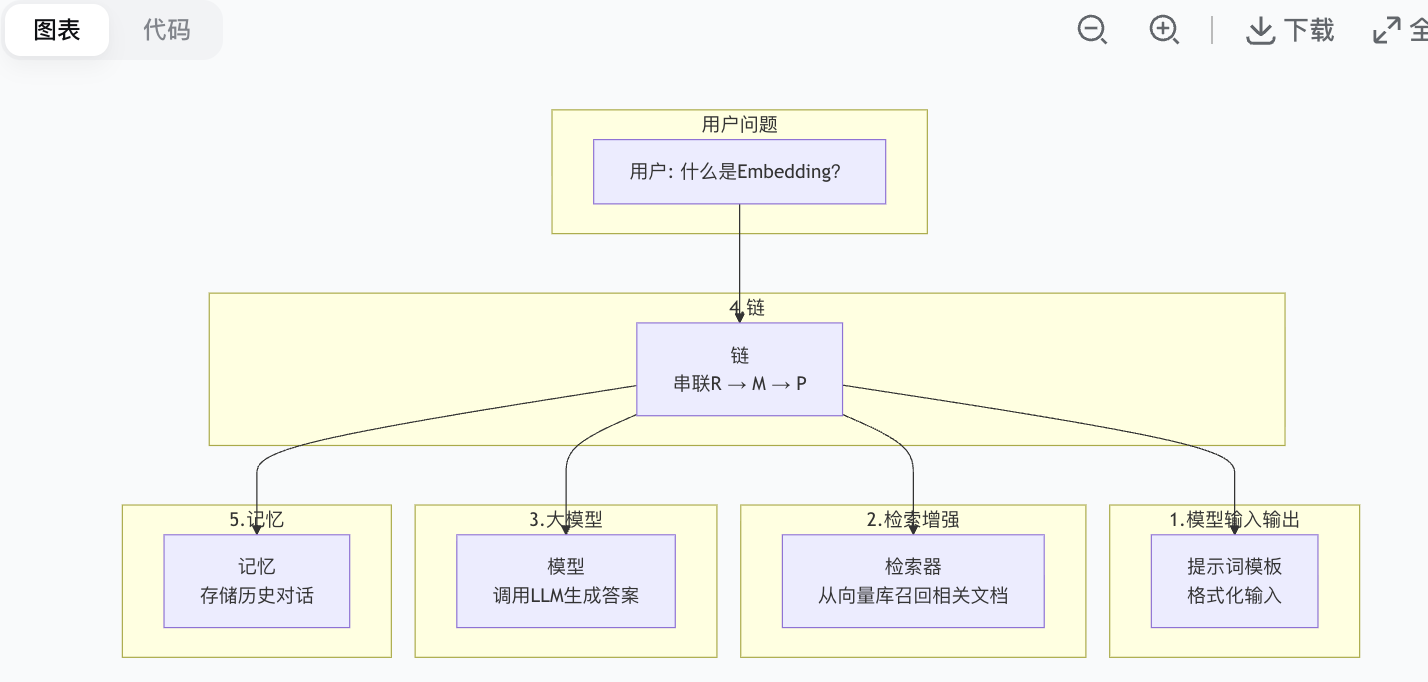
#### 1. Model I/O(模型输入输出)
- **作用**:标准化与大模型的交互
- **包含**:提示词模板(PromptTemplate)、输出解析器(OutputParser)
- **示例**:
```python
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role}专家"),
("human", "{question}")
])
```
#### 2. Retrieval(检索增强生成 - RAG)
- **作用**:从外部知识库检索相关信息,让模型基于私有数据回答
- **包含**:文档加载器(Document Loaders)、文本分割器(Text Splitters)、向量存储(Vector Stores)、Embedding模型、检索器(Retrievers)
- **示例**:
```python
from langchain_community.document_loaders import PDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PDFLoader("doc.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
chunks = splitter.split_documents(docs)
```
#### 3. Chains(链)
- **作用**:将多个组件串联成完整的工作流
- **核心**:LCEL 语法,使用 `|` 管道操作符
- **示例**:
```python
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
llm = ChatOllama(model="llama3.2:3b")
chain = prompt | llm | StrOutputParser()
```
#### 4. Memory(记忆)
- **作用**:让对话有上下文连续性
- **类型**:会话缓冲(ConversationBuffer)、滑动窗口(SlidingWindow)、摘要(Summary)
- **示例**:
```python
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
memory = ConversationBufferMemory()
conversation = ConversationChain(llm=llm, memory=memory)
```
#### 5. Agents(代理)
- **作用**:让LLM自主决定调用哪些工具、按什么顺序调用
- **核心**:ReAct(Reasoning + Acting)模式
- **示例**:搜索、计算器、数据库查询等工具的组合调用
---
### 第四层:设计思想的深度解读(加分项)
面试官可能追问:"为什么 LangChain 要这样设计?"
| 设计决策 | 解决的问题 | 带来的价值 |
|:---|:---|:---|
| **抽象出统一接口** | 不同模型的API千差万别 | 换模型只需改一行代码 |
| **链式组合(LCEL)** | 复杂逻辑难以维护 | 代码可读性高,易于调试 |
| **关注点分离** | 提示词、模型、输出解析耦合 | 每个组件可独立测试和升级 |
| **回调系统** | 难以追踪LLM调用过程 | 支持日志、监控、成本统计 |
---
## 📋 完整回答范例(可直接背诵)
> **面试官,关于 LangChain,我从四个方面来回答:**
>
> **第一,它是什么?**
> LangChain 是一个构建 LLM 应用的开源框架,核心价值是标准化开发流程。
>
> **第二,它的设计思想是什么?**
> 核心是"可组合性",通过 LCEL 语法将独立组件像乐高一样拼接。这带来了三个好处:降低开发门槛、提高代码复用性、方便灵活扩展。
>
> **第三,它的核心组件有哪些?**
> 有五个核心模块:
> - **Model I/O**:统一模型调用和提示词管理
> - **Retrieval**:实现 RAG,让模型能访问私有数据
> - **Chains**:串联组件,构建完整流程
> - **Memory**:管理对话历史
> - **Agents**:让 LLM 自主决策调用工具
>
> **第四,我实际使用时有什么体会?**
> 我最近用 LangChain + Ollama 搭建了一个本地 RAG 问答系统。最直观的感受是:以前需要 200 行代码实现的文档检索+问答,用 LangChain 的 LCEL 语法只需要 20 行。而且通过回调系统,我可以很方便地追踪每一步的耗时和 token 消耗。
>
> **总的来说,LangChain 不是要让事情变得更复杂,而是通过标准化抽象,让开发者能够更专注于业务逻辑,而不是重复造轮子。**
---
## 🔧 可能的追问与应对
| 追问问题 | 回答要点 |
|:---|:---|
| "LangChain 和 LlamaIndex 有什么区别?" | LangChain 更通用(支持 Agent、Chain),LlamaIndex 更专注 RAG(索引和检索)。现在两者有融合趋势。 |
| "LCEL 是什么?有什么优势?" | 声明式语法,用 `|` 连接组件。优势:自动支持流式、异步、批处理、回滚、重试。 |
| "你遇到过什么坑?" | 版本兼容性(0.1→0.2→0.3 拆分了很多包)、回调函数的使用、异步编程的复杂度。 |
| "什么时候不该用 LangChain?" | 简单场景(单次调用 API)、需要极致性能、对依赖数量敏感的项目。 |
---
## 💡 加分小技巧
1. **画图辅助**:回答时可以边说边画组件关系图,展示体系化理解
2. **对比记忆**:提一下 LangChain 之前的做法(手写 requests 调用 API、自己实现 prompt 拼接),突出框架价值
3. **反向提问**:"贵公司目前的 LLM 应用主要使用什么框架?有没有考虑引入 LangChain?"
这个回答框架既覆盖了定义、设计思想、核心组件,又有实际经验和对比分析,面试官会认为你对 LangChain 有比较全面的理解。
解释LangChain中的链(Chain)概念,并介绍主要的链类型。
面试官,关于链,我从三个方面回答:
第一,链是什么?
链是 LangChain 中把多个组件串联成工作流的机制。比如"提示词模板 → 模型 → 输出解析器"就是一个链。第二,如何构建链?
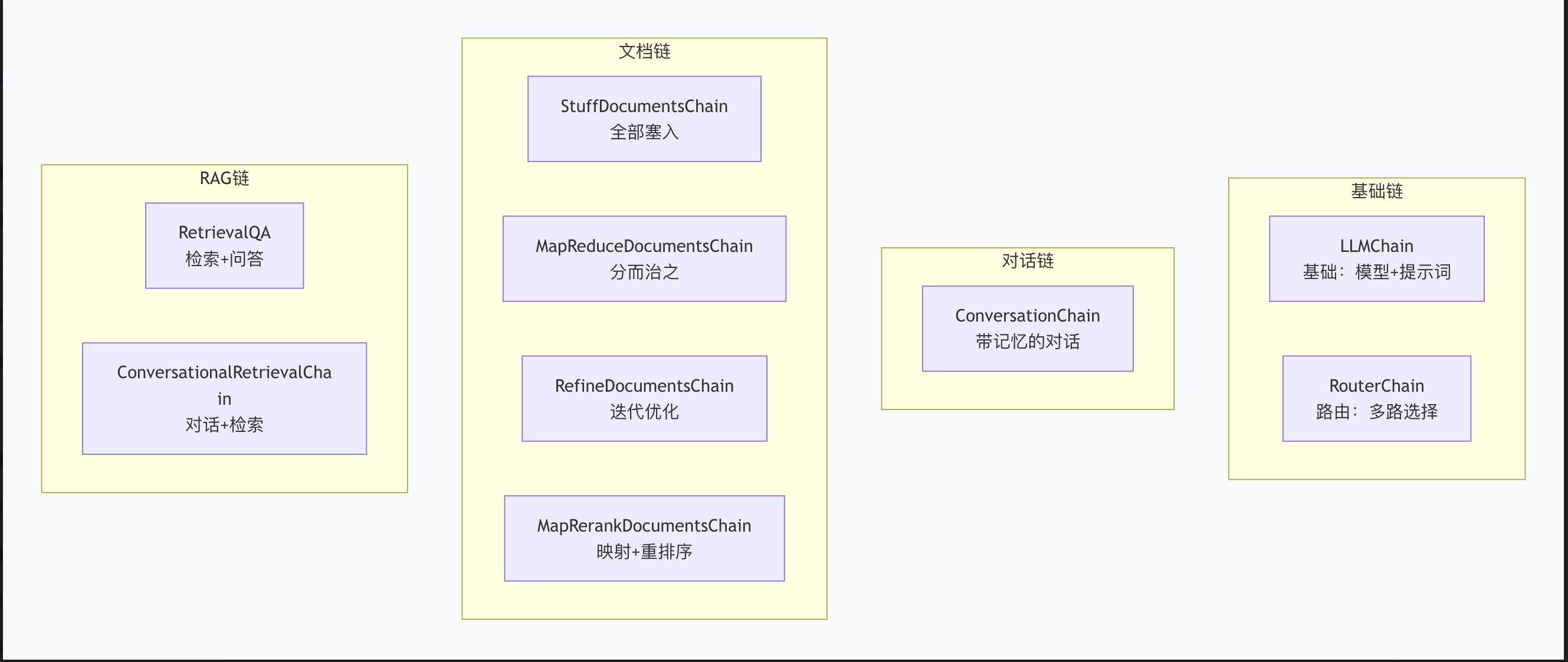
现代 LangChain 推荐使用 LCEL 语法,用|管道操作符连接组件。这种方式代码简洁、自动支持流式和异步。第三,有哪些主要的链类型?
LLMChain:最基础,提示词+模型
ConversationChain:带记忆的对话
RouterChain:根据输入路由到不同子链
文档处理链:Stuff(全量塞入)、MapReduce(分而治之)、Refine(迭代优化)
RetrievalQA:RAG 问答链,从向量库检索后回答
在实际项目中,我用 RetrievalQA 配合 MapReduce 处理过长文档问答,用 ConversationChain 做过客服机器人。LCEL 的
|语法让代码非常直观,调试也很方便。
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "Stuff 和 MapReduce 怎么选?" | 文档短(<2000字)用 Stuff,长文档用 MapReduce,追求质量用 Refine |
| "LCEL 比传统 Chain 好在哪里?" | 自动支持流式、异步、批处理、回滚,代码量减少 50%+ |
| "链和 Agent 什么区别?" | 链是"固定流程",Agent 是"动态决策"。链按预定顺序执行,Agent 让 LLM 自主决定下一步。 |
💡 加分小技巧
-
代码记忆:记住 LCEL 的
prompt | model | parser这个经典模式,面试时写出来 -
场景匹配:提到具体链时,附带适用场景(如"MapReduce 适合总结长文档")
-
版本意识:提一下"LangChain 0.1 时代用 LLMChain,0.3 时代推荐 LCEL",展示你对框架演进的了解
这个回答覆盖了定义、设计思想、主要类型和实际选择,面试官会认为你对 LangChain 有比较深入的实践理解。
解释LangChain中的Prompts概念,并介绍主要类型。
面试官,关于 Prompts,我从三个方面回答:
第一,Prompt 是什么?
它是 LangChain 中管理模型输入的标准化组件,把原始文本抽象成可配置的模板。第二,为什么需要它?
如果没有它,提示词会散落在代码各处,难以维护和调优。LangChain 的 Prompt 实现了模板与逻辑分离,支持复用和动态生成。第三,有哪些主要类型?
PromptTemplate:最基础的字符串模板
ChatPromptTemplate:管理多角色对话(system/user/assistant)
FewShotPromptTemplate:提供示例,让模型学会怎么做
MessagesPlaceholder:预留位置,动态插入历史消息
在实际使用中,我常用 ChatPromptTemplate 配合 MessagesPlaceholder 做对话机器人,用 FewShotPromptTemplate 做分类任务。而且 LangChain 的 Prompt 可以配合 Pydantic 输出解析器,让模型直接返回结构化数据。
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "PromptTemplate 和 ChatPromptTemplate 有什么区别?" | 前者输出字符串,后者输出消息列表(带角色)。对话场景必须用后者。 |
| "如何管理大量 Prompt?" | 用 load_prompt 从 YAML/JSON 文件加载,或用 LangSmith 做版本管理。 |
| "FewShot 的示例数量怎么选?" | 3-10 个效果最好,太多会超上下文,太少学不会模式。 |
💡 加分小技巧
-
版本演进:提一下"旧版用
from langchain.prompts,新版推荐from langchain_core.prompts" -
对比说明:对比"硬编码字符串"和"PromptTemplate"的差异,突出框架价值
-
实战细节:提到
partial变量处理动态内容(如日期、随机数)
这个回答覆盖了定义、设计思想和主要类型,面试官会认为你对 Prompt 的理解既有广度也有深度。
实现LangChain中的output_parsers的具体使用方式
Output Parsers(输出解析器)是 LangChain 中将模型输出的原始文本转换成结构化数据的关键组件。
什么是Memory组件?请解释LangChain中不同类型的记忆机制。
面试官,关于 Memory,我从四个方面回答:
第一,Memory 是什么?
它是 LangChain 中存储和管理对话历史的组件,让模型具备多轮对话能力。第二,为什么需要 Memory?
大模型本身是无状态的,每次调用都是独立的。Memory 解决了这个问题,让模型能"记住"之前聊过什么。第三,有哪些主要类型?
BufferMemory:完整存储,适合短对话
BufferWindowMemory:只保留最近 K 轮,适合客服场景
SummaryMemory:自动生成摘要,适合长对话
SummaryBufferMemory:摘要+窗口,平衡性能和细节
EntityMemory:提取实体信息,适合多角色对话
VectorStoreMemory:向量检索,适合超大规模记忆
第四,如何选择?
短对话(<10轮)→ BufferMemory
中等长度 → BufferWindowMemory
长对话 → SummaryBufferMemory
需要跟踪多个实体 → EntityMemory
海量历史 → VectorStoreMemory
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "Memory 如何与 LCEL 配合?" | LCEL 推荐使用 RunnableWithMessageHistory 类,而不是传统的 ConversationChain |
| "Token 超限怎么处理?" | 用 SummaryBufferMemory 或 BufferWindowMemory,或用 VectorStoreMemory 做检索 |
| "Memory 可以持久化吗?" | 可以。VectorStoreMemory 天然持久化;其他类型可以自定义 chat_memory 参数,用 Redis、数据库等存储 |
💡 加分小技巧
-
对比说明:提一下"传统做法是手动拼接历史字符串",突出 Memory 组件的价值
-
实际案例:举例说明某个场景下的 Memory 选择(如客服机器人用 BufferWindowMemory)
-
版本意识:提一下"LangChain 0.3 后推荐使用
RunnableWithMessageHistory"
解释LangChain中的提示工程及其最佳实践。
这个回答覆盖了定义、设计思想和主要类型,面试官会认为你对 Memory 有比较全面的理解。
面试官,关于 LangChain 中的提示工程,我从三个方面回答:
第一,与传统提示工程的区别
传统提示工程关注的是"怎么写提示词",而 LangChain 把它提升到了工程化层面,提供了 PromptTemplate、FewShot、OutputParser 等标准化工具。第二,核心最佳实践
模板化:用 PromptTemplate 替代字符串拼接
结构化输出:配合 PydanticOutputParser 强制格式
少样本学习:用 FewShotPromptTemplate 提供示例
角色设定:在 System Prompt 中明确身份和规则
动态内容:用 partial variables 处理时间、随机数等
版本管理:将提示词配置文件化,与代码分离
第三,一个完整的例子
python
# 一个生产级别的提示工程示例 prompt = ChatPromptTemplate.from_messages([ ("system", "你是{role},{rules}"), MessagesPlaceholder("examples"), ("human", "{question}") ]).partial( role="技术专家", rules="回答要简洁、准确,用中文" )总结:LangChain 的提示工程核心是让提示词变得可控、可测、可复用,而不是玄学。
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "提示词太长怎么办?" | 使用 SummaryMemory 或向量检索;或者拆分成多步链 |
| "如何测试提示词效果?" | 用 LangSmith 做追踪和 A/B 测试;或写单元测试验证输出格式 |
| "如何做提示词版本管理?" | 存 YAML/JSON 文件,或用 Prompt Hub(LangSmith 功能) |
| "FewShot 示例数量怎么选?" | 3-10 个效果最好,太多会超 token,太少学不会模式 |
💡 加分小技巧
-
对比说明:对比"手写提示词"和"LangChain 模板"的差异,突出工程化价值
-
实际案例:举例说明用 PydanticOutputParser 将错误率从 30% 降到 5%
-
成本意识:提到"提示词越长,token 成本越高",体现工程权衡思维
-
可观测性:提到配合 LangSmith 可以追踪每次 prompt 的效果
这个回答覆盖了定义、最佳实践和工程化思维,面试官会认为你对提示工程有比较深入的理解。
LangChain的Document Loaders?请介绍其功能和主要类型。
面试官,关于 Document Loaders,我从三个方面回答:
第一,它是什么?
Document Loaders 是 LangChain 中用于从各种数据源读取数据并转换为统一 Document 对象的组件。每个 Document 包含page_content(文本内容)和metadata(元数据)两部分。第二,核心接口是什么?
所有 Loader 都实现BaseLoader接口,提供load()和load_and_split()两个核心方法。这种统一抽象让开发者可以用相同的代码处理 PDF、网页、数据库等不同来源的数据。第三,有哪些主要类型?
文件加载器:TextLoader、PyPDFLoader、CSVLoader,处理本地文件
网页加载器:WebBaseLoader、PlaywrightLoader,支持静态和动态网页
云服务加载器:S3Loader、AzureBlobStorageLoader
数据库加载器:AthenaLoader、CouchbaseLoader
应用集成加载器:NotionLoader、ConfluenceLoader、GitHubLoader、YouTubeLoader
在实际项目中,我常用 PyPDFLoader 处理技术文档,用 WebBaseLoader 抓取在线 API 文档,用 DirectoryLoader 批量处理整个文件夹。这些 Loader 配合 TextSplitter 和 VectorStore,可以快速搭建 RAG 知识库系统。
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "load() 和 load_and_split() 的区别?" | load() 返回原始文档;load_and_split() 会在内部调用 TextSplitter 进行分块,适合大文档。 |
| "如何处理超大 PDF?" | 使用 load_and_split() 配合 RecursiveCharacterTextSplitter;或用 PyMuPDFLoader 逐页加载。 |
| "如何处理需要登录的网页?" | 使用 PlaywrightLoader 或 PuppeteerLoader,支持 Cookie 和 Session。 |
| "如何自定义 Loader?" | 继承 BaseLoader,实现 load 方法;或继承 BaseBlobParser 处理自定义格式。 |
💡 加分小技巧
-
版本提示:新版本中 Loader 位于
langchain_community.document_loaders,不是langchain.document_loaders -
性能考虑:加载大文档时使用
load_and_split()边加载边分割,避免内存溢出 -
元数据利用:metadata 中的
source字段可用于答案溯源,告诉用户信息来源
这个回答覆盖了定义、接口设计和主要类型,面试官会认为你对 Document Loaders 有比较全面的理解。
什么是LangChain的代理(Agent)?请说明其工作原理和应用。
面试官,关于 Agent,我从四个方面回答:
第一,Agent 是什么?
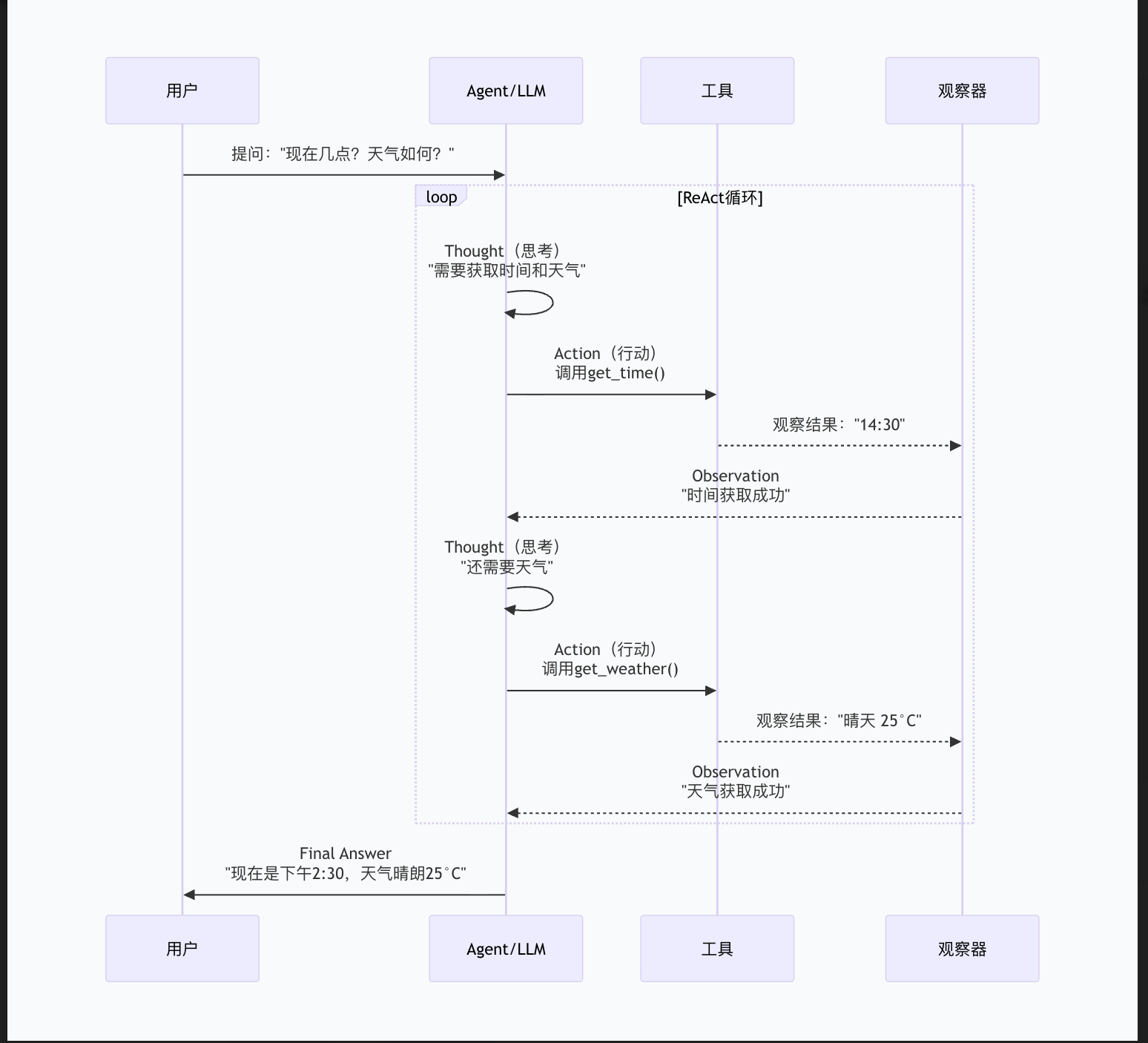
Agent 是 LangChain 中能够自主决策、调用工具、完成复杂任务的智能体。与按固定路径执行的 Chain 不同,Agent 会动态决定下一步做什么。第二,核心原理是什么?
基于 ReAct 模式(Reasoning + Acting),通过 Thought → Action → Observation 循环来解决问题。LLM 先思考需要什么信息,然后调用工具,观察结果,再继续推理,直到能给出最终答案。第三,核心组件有哪些?
LLM:决策的大脑
Tools:工具箱,如计算器、搜索、数据库查询
AgentExecutor:管理循环的执行器
Memory:保存对话历史
第四,实际应用场景
数据分析:Agent 自主决定查哪些表、算什么指标
智能客服:需要查询订单、查物流、计算退款等多步操作
研究助手:搜索互联网、阅读文档、整合信息
代码助手:写代码、执行测试、调试
我最近用 LangChain + Ollama 搭建了一个数据分析 Agent,它可以接收自然语言问题,自主决定查哪个数据库表、写什么 SQL、然后解释结果。这种能力是传统 Chain 无法实现的。
🔧 可能的追问
| 追问 | 回答 |
|---|---|
| "Agent 的缺点是什么?" | 不可预测、token 消耗大、可能陷入循环、成本较高 |
| "如何控制 Agent 不失控?" | 设置 max_iterations、early_stopping_method、添加工具使用限制 |
| "Agent 和 Chain 能结合吗?" | 可以,Agent 内部可以调用 Chain,Chain 内部也可以包含 Agent |
| "如何调试 Agent?" | 设置 verbose=True 查看 Thought 过程;用 LangSmith 追踪 |
💡 加分小技巧
-
ReAct 原文:可以提一下 ReAct 是 2022 年 Google 和 Princeton 的论文《ReAct: Synergizing Reasoning and Acting in Language Models》
-
成本意识:Agent 每次迭代都会调用 LLM,复杂任务可能消耗 10+ 次调用,需要设置预算控制
-
工具设计:好的工具需要清晰的描述(docstring),LLM 根据描述决定何时使用
-
安全考虑:生产环境中需要对 Agent 的工具权限做限制,避免危险操作(如删除文件)
这个回答覆盖了定义、原理、组件和应用,面试官会认为你对 Agent 有比较深入的理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)