数据集蒸馏论文(七):Dataset Distillation using Neural Feature Regression
文章目录
Dataset Distillation using Neural Feature Regression
论文:Dataset Distillation using Neural Feature Regression
网页:https://sites.google.com/view/frepo
摘要
- 数据集蒸馏可以被表述为一个双层元学习问题,其中外环优化元数据集,内环在蒸馏数据上训练模型。
- 元梯度计算是该公式中的关键挑战之一,因为通过内环学习过程进行区分会引入显著的计算和内存成本。
- 本文使用带有池化的神经特征回归(FRepo)来解决这些挑战,实现了最先进的性能,且内存需求减少了一个数量级,训练速度快了两个数量级。
- 所提出的算法类似于用模型池截断时序反向传播,以缓解数据集蒸馏中的各种类型的过拟合。
The proposed algorithm is analogous to truncated backpropagation through time with a pool of models to alleviate various types of overfitting in dataset distillation.
介绍
- 提出一种高效的元梯度计算方法和一个“模型池”,以解决过拟合问题。
- 元梯度计算的瓶颈源于内部优化的复杂性,需要知道内部参数如何随外部参数而变化[24]。
- 如果只训练神经网络的最后一层收敛,同时保持特征提取器固定,内部优化可能会非常简单。
- 在这种情况下,使用在蒸馏数据上训练的模型计算对真实数据的预测可以表示为相对于共轭核的核岭回归(KRR)[25]。
- 因此,计算元梯度只是通过核和固定特征提取器进行反向传播。
- 为了缓解过度拟合,本文建议维护多样化的模型池,而不是像以前工作那样定期训练和重置单个模型。
- 本文算法针对以下问题:当前特征提取器训练线性分类器的最佳数据是什么?
- 由于本文使用的不同特征提取器,蒸馏数据可以很好地推广到广泛的模型分布。
[24] Jonathan Lorraine, Paul Vicol, and David Duvenaud. Optimizing millions of hyperparameters by implicit differentiation. In Silvia Chiappa and Roberto Calandra, editors, The 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020, 26-28 August 2020, Online[Palermo, Sicily, Italy], volume 108 of Proceedings of Machine Learning Research, pages 1540–1552. PMLR, 2020. URL http://proceedings.mlr.press/v108/lorraine20a.html.
[25] Radford M. Neal. Bayesian learning for neural networks. 1995.
方法
2.1 Dataset Distillation as Bi-level Optimization 数据集蒸馏作为双层优化
-
大数据集: T = { ( x 1 , y 1 ) , . . . , ( x ∣ T ∣ , y ∣ T ∣ ) } \mathcal{T}=\{(x_1,y_1),...,(x_{|\mathcal{T}|},y_{|\mathcal{T}|})\} T={(x1,y1),...,(x∣T∣,y∣T∣)},具有 T \mathcal{T} T 对图像-标签对;
-
合成小数据集: S = { ( x 1 , y 1 ) , . . . , ( x ∣ S ∣ , y ∣ S ∣ ) } \mathcal{S}=\{(x_1,y_1),...,(x_{|\mathcal{S}|},y_{|\mathcal{S}|})\} S={(x1,y1),...,(x∣S∣,y∣S∣)},其保留了 T \mathcal{T} T 的大部分信息;
-
基于合成数据集 S \mathcal{S} S 训练几个由 θ \theta θ 参数化的神经网络;
-
基于真实数据集 T \mathcal{T} T 计算验证损失 L ( A l g ( θ , S ) , T ) \mathcal{L}(\mathcal{A}lg(\theta,\mathcal{S}),\mathcal{T}) L(Alg(θ,S),T),
其中,
A l g ( θ , S ) \mathcal{A}lg(\theta,\mathcal{S}) Alg(θ,S) 表示由学习算法 A l g \mathcal{A}lg Alg 优化的神经网络参数,
A l g \mathcal{A}lg Alg 以模型初始化 θ \theta θ 和合成数据集 S \mathcal{S} S 为输入; -
验证损失 L ( A l g ( θ , S ) , T ) \mathcal{L}(\mathcal{A}lg(\theta,\mathcal{S}),\mathcal{T}) L(Alg(θ,S),T) 是一个噪声目标,其随机性来自随机模型初始化和内部学习算法;
-
需要最小化这个损失的期望值,将其表示为 F ( S ) F(\mathcal{S}) F(S);
-
数据集蒸馏表述为 b i − l e v e l bi-level bi−level 优化问题:
S ∗ : − a r g m i n S F ( S ) ⏞ o u t e r − l e v e l , 其中 F ( S ) = E θ ∼ P θ [ L ( A l g ( θ , S ) ⏞ i n n e r − l e v e l , T ) ] (1) \stackrel{outer-level}{\overbrace{\mathcal{S}^*:-\underset {\mathcal{S}}{argmin}F(\mathcal{S})}},其中F(\mathcal{S})=\mathbb{E}_{\theta{\sim}P_{\theta}}[\mathcal{L}(\stackrel{inner-level}{\overbrace{\mathcal{A}lg(\theta,\mathcal{S})}},\mathcal{T})]\tag{1} S∗:−SargminF(S) outer−level,其中F(S)=Eθ∼Pθ[L(Alg(θ,S) inner−level,T)](1) -
在这个 b i − l e v e l bi-level bi−level 设置中,
外环优化合成数据,以最小化 F ( S ) F(\mathcal{S}) F(S),
内环使用学习算法 A l g \mathcal{A}lg Alg 训练神经网络,以最小化合成数据 S \mathcal{S} S 上的训练损失。 -
从元学习的角度来看,任务是由模型初始化 θ \theta θ 定义的,本文希望学习一个元参数 S \mathcal{S} S,它能很好地推广到从模型分布 P θ P_θ Pθ中采样的不同模型。
-
在学习过程中,通过最小化元训练损失 F ( S ) F(\mathcal{S}) F(S) 来优化元参数 S \mathcal{S} S。
-
相比之下,元测试时在 S \mathcal{S} S 上从头开始训练一个新模型,并在一个held-out真实数据集上评估训练后的模型。
-
这种元测试性能反映了合成数据的质量。
2.2 Dataset Distillation using Neural Feature Regression with Pooling (FRePo) 使用带池化的神经特征回归进行数据集蒸馏
- outer-level问题可以使用基于梯度的方法来解决,其形式为 S ← S − α ∇ S F ( S ) \mathcal{S}\leftarrow\mathcal{S}-\alpha{\nabla_\mathcal{S}}F(\mathcal{S}) S←S−α∇SF(S),其中 α \alpha α 是蒸馏数据的学习率,而 ∇ S F ( S ) \nabla_\mathcal{S}F(\mathcal{S}) ∇SF(S) 是元梯度[27]。
[27] Aravind Rajeswaran, Chelsea Finn, Sham M. Kakade, and Sergey Levine. Meta-learning with implicit gradients. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 113–124, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/072b030ba126b2f4b2374f342be9ed44-Abstract.html.
-
对于特定的模型 θ \theta θ,元梯度可以表示为 ∇ S L ( A l g ( θ , S ) , T ) \nabla_\mathcal{S}{\mathcal{L}(\mathcal{A}lg(\theta,\mathcal{S}),\mathcal{T})} ∇SL(Alg(θ,S),T)。
-
计算这个元梯度需要通过内部优化进行微分。
-
如果 A l g \mathcal{A}lg Alg 是像梯度下降一样的迭代算法,那么通过展开的计算图进行反向传播[14]可以是一种解决方案。然而,这种类型的展开优化引入了大量的计算和内存开销,因为整个训练轨迹需要存储在内存中(图2(b))。
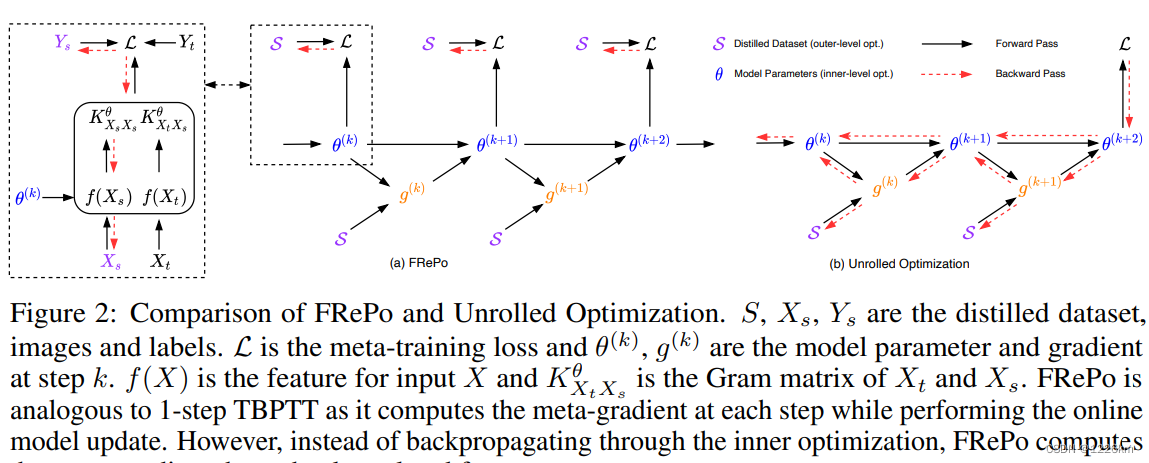
-
传统上,这些问题通过截断时序反向传播(truncated backpropagation through time,TBPTT)[28-30]得到缓解。TBPTT不是通过整个展开的序列反向传播,而是分别对每个子序列执行反向传播。它很有效,因为它的时间和内存复杂性相对于截断步骤呈线性扩展。
-
然而,截断可能会产生严重影响训练的高度偏置梯度。为了减轻这种截断偏差[14],考虑只训练网络的顶层收敛。关键的视角是,有助于训练输出层的数据也可以帮助训练整个网络。
-
因此,将神经网络分解为特征提取器和线性分类器。
-
在每次元梯度计算中修复特征提取器,并
在更新S之前训练线性分类器收敛。 -
之后,通过在更新的蒸馏数据上训练整个网络调整特征提取器。
-
类似的两阶段过程在表征学习的背景下进行了研究[31]。
-
元梯度计算:
如果考虑均方误差损失,那么线性分类器的最佳权重有一个封闭解。
此外,由于特征维度通常大于合成数据的数量,可以使用具有共轭核[25]的核岭回归(KRR),而不是显式求解权重[12]。 -
由此产生的元训练损失(式2)类似于KIP[22,23]中使用的损失,但本文使用更灵活的核而不是NTK。
L ( A l g ( θ , S ) , T ) = 1 2 ∣ ∣ Y t − K X t , X s θ ( K X s , X s θ + + λ I ) − 1 ) ) Y s ∣ ∣ 2 2 (2) {\mathcal{L}(\mathcal{A}lg(\theta,\mathcal{S}),\mathcal{T})}={1\over2}||{Y_t}-K^\theta_{X_\mathcal{t},X_\mathcal{s}}(K^\theta_{X_\mathcal{s},X_\mathcal{s}}++\lambda{I})^{-1})){Y_\mathcal{s}}||^2_2\tag{2} L(Alg(θ,S),T)=21∣∣Yt−KXt,Xsθ(KXs,Xsθ++λI)−1))Ys∣∣22(2)
其中,
X t , Y t X_\mathcal{t},Y_\mathcal{t} Xt,Yt、 X s , Y s X_\mathcal{s},Y_\mathcal{s} Xs,Ys 分别表示真实数据 T \mathcal{T} T、合成数据 S \mathcal{S} S 的输入和标签;
K X t , X s θ ∈ R ∣ T ∣ × ∣ S ∣ K^\theta_{X_\mathcal{t},X_\mathcal{s}}\in{\mathbb{R}^{|\mathcal{T}|×|\mathcal{S}|}} KXt,Xsθ∈R∣T∣×∣S∣ 表示真实输入与合成输入之间的Gram矩阵;
K X s , X s θ ∈ R ∣ S ∣ × ∣ S ∣ K^\theta_{X_\mathcal{s},X_\mathcal{s}}\in{\mathbb{R}^{|\mathcal{S}|×|\mathcal{S}|}} KXs,Xsθ∈R∣S∣×∣S∣ 表示合成输入之间的Gram矩阵;
λ \lambda λ 控制KRR的正则化强度。 -
给定输入 X X X 和模型参数 θ \theta θ 的神经网络特征表示为 f ( X , θ ) ∈ R N × d f(X,\theta)\in{\mathbb{R}^{N×d}} f(X,θ)∈RN×d,
其中,N为输入数量,d为特征维度。 -
共轭核由神经网络特征的内积定义。
-
因此,两个Gram矩阵计算如下:
K X t , X s θ = f ( X t , θ ) f ( X s , θ ) T , K X s , X s θ = f ( X s , θ ) f ( X s , θ ) T (3) K^\theta_{X_\mathcal{t},X_\mathcal{s}}=f(X_t,\theta)f(X_s,\theta)^\mathrm{T},K^\theta_{X_\mathcal{s},X_\mathcal{s}}=f(X_s,\theta)f(X_s,\theta)^\mathrm{T}\tag{3} KXt,Xsθ=f(Xt,θ)f(Xs,θ)T,KXs,Xsθ=f(Xs,θ)f(Xs,θ)T(3) -
现在,计算元梯度 ∇ S L ( A l g ( θ , S ) , T ) \nabla_\mathcal{S}{\mathcal{L}(\mathcal{A}lg(\theta,\mathcal{S}),\mathcal{T})} ∇SL(Alg(θ,S),T) 只是通过共轭核和固定特征提取器反向传播,这非常高效,并且比计算网络权重的梯度需要更少的操作。此外,将元梯度计算与模型在线更新解耦。
-
因此,可以使用任何优化器训练在线模型,并且提炼的数据将与特定的学习算法选择无关。
-
本文提出的方法类似于一步TBPTT,执行在线模型更新的同时在每一步计算元梯度。与传统的一步TBPTT不同,本文使用KRR输出层计算元梯度以减轻截断偏差,如图2(a)所示。
-
模型池:填充了从不同数量的训练steps和不同的随机初始化中获得的不同参数集。
-
与以前定期训练和重置单个模型的方法不同,FRepo在每次元梯度计算时从池中随机抽取模型,并使用当前蒸馏数据对其进行更新。
-
但是,如果模型更新超过K步,就会使用新的随机种子重新初始化它。
-
从元学习的角度来看,本文维护了一组多样化的元任务来进行采样,并避免在每次连续的梯度计算中采样非常相似的任务,以避免过度拟合到特定的设置。
-
池多样性:可以通过设置更大的K来增加模型池的多样性,在提炼数据上训练模型时使用数据增强,或者使用具有不同架构的模型来增加正则化强度。
-
为了保持本文方法简单,对池中的所有模型使用相同的架构,并且在提炼数据上训练模型时不使用任何数据增强。
-
因此,本文的模型池只包含具有不同初始化、处于不同优化阶段以及在提炼数据的不同time-step训练的模型。
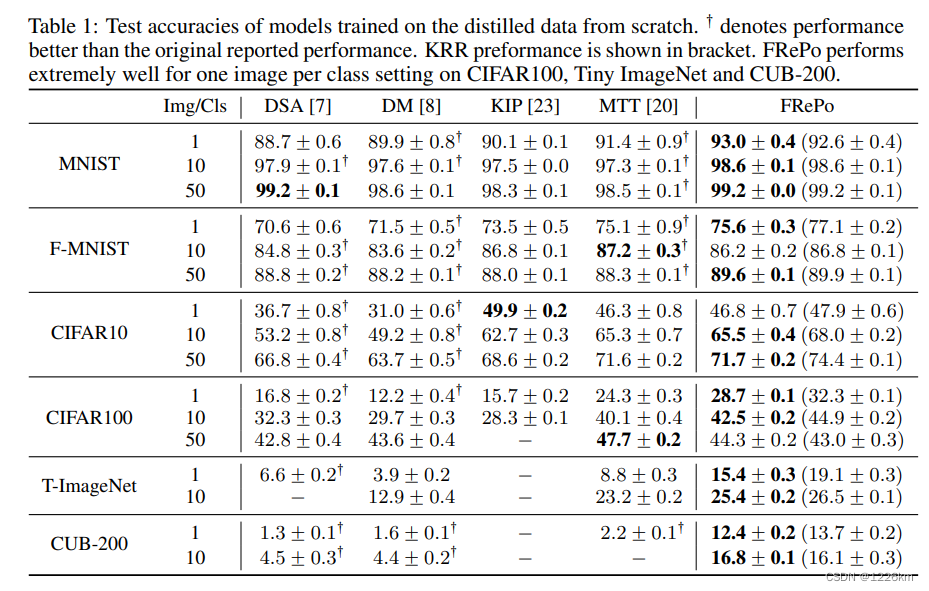
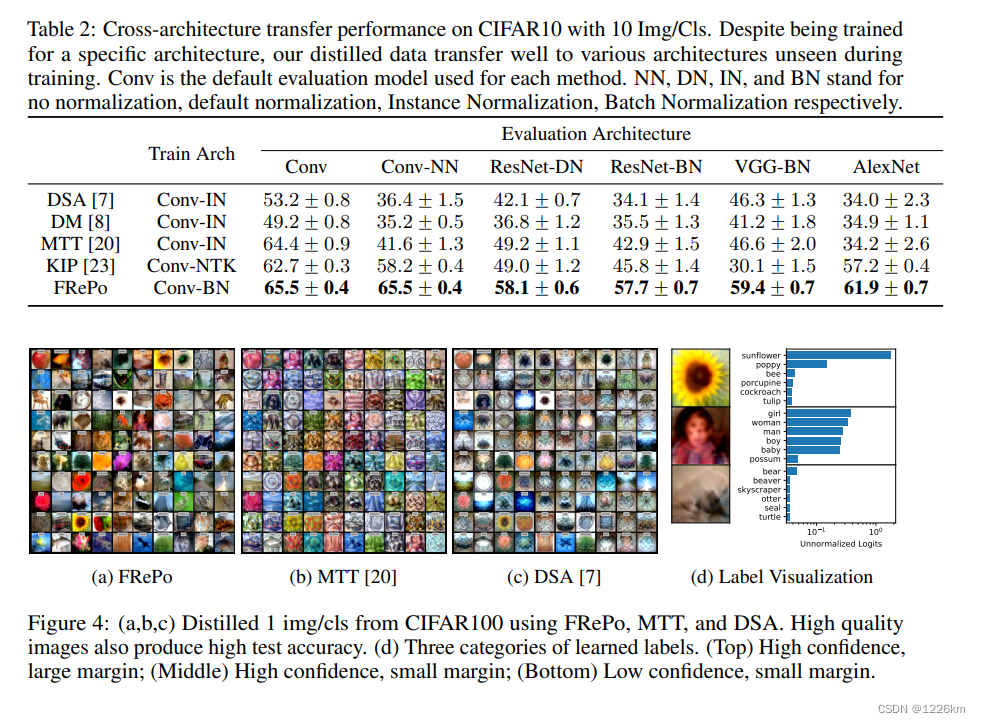
实验

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)