数据集蒸馏论文(六):Dataset Distillation by Matching Training Trajectories
·
文章目录
Dataset Distillation by Matching Training Trajectories
论文:Dataset Distillation by Matching Training Trajectories
代码:GeorgeCazenavette/mtt-distillation
主页:mtt-distillation
分析:数据集蒸馏 by Matching Training Trajectories
摘要
- 引导网络在多个训练steps中达到与在真实数据上训练的网络相似的状态
- 给定一个网络,进行多次迭代,并计算合成数据训练参数与真实数据训练参数之间的距离,优化蒸馏数据
- 为了有效地获得大规模数据集的初始和目标网络参数,预先计算和存储在真实数据集上训练的专家网络的训练轨迹
介绍
- 蒸馏算法必须通过在不完全消除判别特征的情况下大量压缩信息来取得微妙的平衡
- 为了降低优化难度,其他方法[45,47]专注于短期行为,对蒸馏数据强制执行单个训练step以匹配真实数据。然而,错误可能会在评估中积累。
[45] Bo Zhao and Hakan Bilen. Dataset condensation with differentiable siamese augmentation. In ICML, 2021.
[47] Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. In ICLR, 2020.
- 为了解决上述挑战,本文试图直接模仿在真实数据集上训练网络的长期训练动态,将在合成数据上训练的参数轨迹段与在真实数据上训练模型中预先记录的轨迹段进行匹配,从而避免短视(即专注于单个步骤)或难以优化(即对完整轨迹进行建模)。
- 将真实数据集视为指导网络训练动态的黄金标准,可以将网络参数的诱导序列视为专家轨迹。
- 如果合成数据集诱导网络的训练动态遵循这些专家轨迹,那么经过综合训练的网络将降落在靠近在真实数据上训练模型的地方(在参数空间中),并获得类似的测试性能。
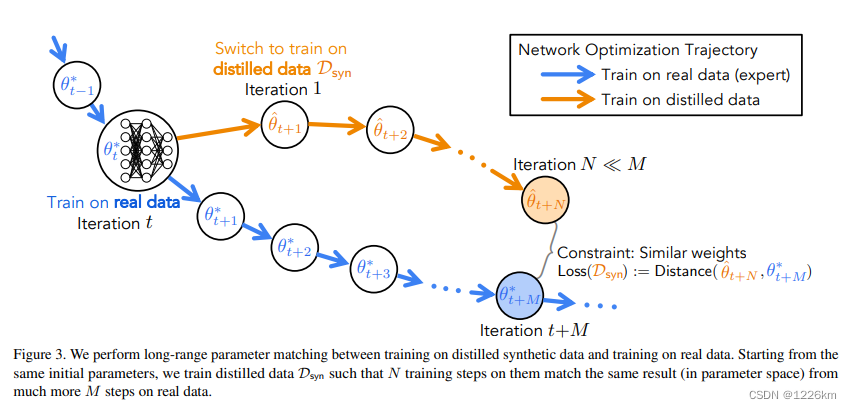
- 本文损失函数直接鼓励合成数据集沿着相似的轨迹引导网络优化(图3)。
- 首先在真实数据集上从头开始训练一组模型,并记录它们的专家训练轨迹。然后,从随机选择的专家轨迹中以随机时间步长初始化一个新模型,并在合成数据集上进行多次迭代训练。最后,根据这个经过综合训练的网络偏离专家轨迹的程度来惩罚合成数据,并通过训练迭代进行反向传播。
- 从本质上讲,本文将多个专家训练轨迹中的知识转移到蒸馏图像中。
方法
3.1 Expert Trajectories
- 核心:使用专家轨迹指导合成数据蒸馏。
- 专家轨迹获取:基于真实数据集训练多个epoch,保存每一次的参数。
- 这些参数序列就称为专家轨迹,它们代表了数据集蒸馏任务的理论上限(在完整的、真实的数据集上训练的网络的性能)。
- 学生参数 θ t ^ \hat{\theta_{t}} θt^:基于合成数据集训练的第t个训练step时的参数。
- 目标:提取一个数据集,该数据集将产生与真实训练集诱导轨迹相似的轨迹(给定相同的起点),从而得到一个类似的模型。由于这些专家轨迹仅使用真实数据,可以在蒸馏前预先计算它们。
3.2 Long-Range Parameter Matching
- 每个蒸馏step,首先在一个随机时间步内的一个专家轨迹 θ t ∗ \theta^{*}_{t} θt∗中采样参数,并使用这些参数初始化学生参数 θ t ^ : = θ t ∗ \hat{\theta_{t}} := \theta^{*}_{t} θt^:=θt∗。
- 给 t t t 一个上限 T T T ,使忽略专家轨迹中信息较少的后面部分,其中参数变化不大。
- 初始化学生网络后,根据合成数据的分类损失对学生参数执行N次梯度下降更新:
θ ^ t + n + 1 = θ ^ t + n − α ▽ l ( A ( D s y n ) ; θ ^ t + n ) (1) {\hat\theta}_{t+n+1}={\hat\theta}_{t+n}-\alpha\triangledown{\mathcal{l}}(\mathcal{A}(\mathcal{D}_{syn});\hat\theta_{t+n}) \tag{1} θ^t+n+1=θ^t+n−α▽l(A(Dsyn);θ^t+n)(1)
其中,
A \mathcal{A} A 是以前工作[45]中使用的可微增强技术,
α \alpha α 是用于更新学生网络的(可训练的)学习率。 - 蒸馏期间使用的任何数据增强都必须是可微的,以便可以通过增强层反向传播到合成数据。
- 本文方法不使用可微Siamese增强,因为在蒸馏过程中没有使用真实数据;目前只将增强应用于合成数据。
- 生成专家轨迹期间,在真实数据上使用了相同类型的可微增强。
- 从用于初始化学生网络 θ t + M ∗ \theta^{*}_{t+M} θt+M∗ 之后的M个训练更新中检索专家参数。
- 根据权重匹配损失更新蒸馏图像,即更新的学生参数 θ ^ t + N {\hat{\theta}}_{t+N} θ^t+N 和已知未来专家参数 θ t + M ∗ \theta^{*}_{t+M} θt+M∗ 之间的归一化平方L2误差:
L = ∣ ∣ θ ^ t + N − θ t + M ∗ ∣ ∣ 2 2 ∣ ∣ θ t ∗ − θ t + M ∗ ∣ ∣ 2 2 (2) \mathcal{L}={{||{{\hat{\theta}}_{t+N}}-{\theta^{*}_{t+M}}||^2_2}\over{||{\theta^{*}_{t}}-\theta^{*}_{t+M}||^2_2}}\tag{2} L=∣∣θt∗−θt+M∗∣∣22∣∣θ^t+N−θt+M∗∣∣22(2)
其中,通过专家行进的距离对L2误差进行归一化,这样仍然可以从专家没有移动太多的后期训练时期获得强烈的信号。这种归一化还有助于自校准神经元和层之间的幅度差异。 - 通过反向传播到学生网络的所有N个更新来最小化这个目标,以更新合成数据集的像素以及可训练的学习率 α \alpha α。
- 可训练学习率α的优化作为学生和专家更新数量(超参数M和N)的自动调整。
- 使用带有动量的SGD来优化 D s y n \mathcal{D}_{syn} Dsyn 和 α \alpha α。
- 算法1说明了主要算法。

3.3 Memory Constraints
- 为学生网络的每次更新(即算法1第10行中的内部循环)采样一个新的mini-batch b,这样在计算最终权重匹配损失(公式2)时,所有提炼的图像都将被看到。
- mini-batch b 仍然包含来自不同类别的图像,但每个类别的图像要少得多。
- 在这种情况下,学生网络更新就变成了:
b t + n D s y n b_{t+n}~\mathcal{D}_{syn} bt+n Dsyn
θ ^ t + n + 1 = θ ^ t + n − α ▽ l ( A ( b t + n ) ; θ ^ t + n ) (3) {\hat\theta}_{t+n+1}={\hat\theta}_{t+n}-\alpha\triangledown{\mathcal{l}}(\mathcal{A}(\mathcal{b}_{t+n});\hat\theta_{t+n}) \tag{3} θ^t+n+1=θ^t+n−α▽l(A(bt+n);θ^t+n)(3) - 这种批处理方法允许提取更大的合成数据集,同时确保同一类的提取图像之间存在一定的异质性。
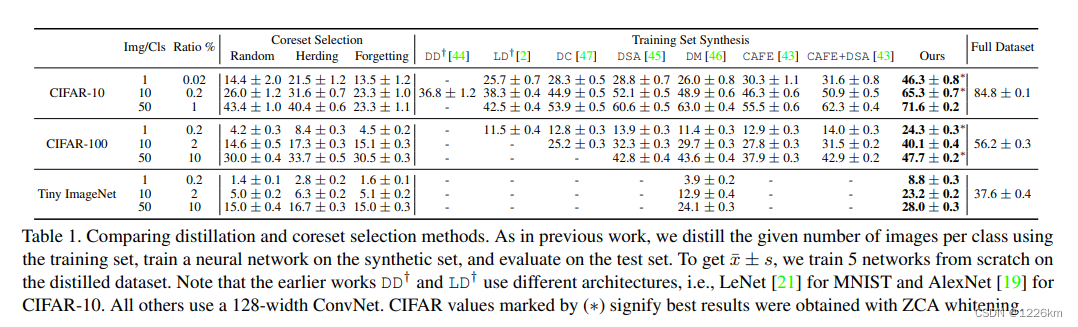
实验


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)