从零构建大模型(第四章)
总览
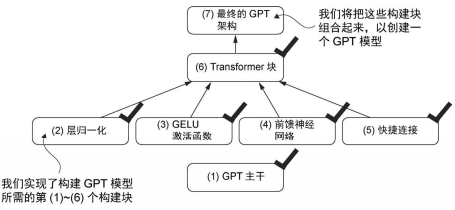
本章按照图中层级,从下往上实现了层归一化、GELU、前馈网络、残差连接、Transformer 块,最终组装成完整的 GPT 模型,并实现了自回归文本生成。
- 预归一化(Pre-LN):每个子层前做 LayerNorm,梯度流动更顺畅
- 残差连接:每个子层输出加回输入,保证深度网络可训练
- 多头因果注意力:只能看到前面的 token(遮罩未来)
- 前馈网络升维:扩大至 4 倍维度,用 GELU 激活,再降维
- 可配置 dropout:嵌入层、注意力、残差后均可独立设置
📝 4.2 层归一化(Layer Normalization)
🧠 归一化是什么?
在机器学习中,归一化(也叫标准化)是一种将数据“拉”到某个标准范围的操作。最常见的做法是让数据均值为0、方差为1:
x^=x−μσ \hat{x} = \frac{x - \mu}{\sigma} x^=σx−μ
其中 μ\muμ 是均值,σ\sigmaσ 是标准差。
为什么需要归一化?
深度神经网络中,每层输入分布会随着前面参数的更新而变化(内部协变量偏移),导致训练不稳定、收敛慢。归一化能让每层的输入分布保持稳定,从而加速训练、提高稳定性。
🎯 层归一化的动机
在自然语言处理中,输入是变长的句子,且训练时往往使用小批量(batch size 较小)。如果使用批归一化(Batch Normalization),它会依赖批次中的统计量,在小批量或变长序列上表现不稳定。
层归一化则不同:它对每个样本的每个 token,在特征维度上独立进行归一化。
不依赖 batch 大小
对变长序列友好
成为 Transformer 的标准组件
📐 层归一化公式
对于输入向量 x∈Rd\mathbf{x} \in \mathbb{R}^{d}x∈Rd(一个 token 的嵌入):
均值:
μ=1d∑i=1dxi\mu = \frac{1}{d} \sum_{i=1}^{d} x_iμ=d1∑i=1dxi
方差:
σ2=1d∑i=1d(xi−μ)2\sigma^2 = \frac{1}{d} \sum_{i=1}^{d} (x_i - \mu)^2σ2=d1∑i=1d(xi−μ)2
标准化:
x^i=xi−μσ2+ϵ\hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}x^i=σ2+ϵxi−μ(ϵ\epsilonϵ 为小常数,防除零)
缩放和平移(可学习):
yi=γix^i+βiy_i = \gamma_i \hat{x}_i + \beta_iyi=γix^i+βi
γ\gammaγ(scale)和 β\betaβ(shift)是可训练参数,初始值分别为 1 和 0,让模型可以选择性地“恢复”某些维度的重要性。
💻 代码实现
python
class LayerNorm(nn.Module):
def __init__(self, emb_dim, eps=1e-5):
super().__init__()
self.eps = eps
self.scale = nn.Parameter(torch.ones(emb_dim)) # γ
self.shift = nn.Parameter(torch.zeros(emb_dim)) # β
def forward(self, x):
# x shape: (batch, seq_len, emb_dim)
mean = x.mean(dim=-1, keepdim=True) # (batch, seq_len, 1)
var = x.var(dim=-1, keepdim=True, unbiased=False) # 有偏估计
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
关键点:
dim=-1:在特征维度上操作
keepdim=True:保留维度,便于广播
unbiased=False:使用有偏估计(除以 n),与 GPT 原始实现一致
nn.Parameter:使 scale 和 shift 可被优化器更新
🆚 与批归一化对比
以下是整理后的对比表格:
| ### 对比维度 | 层归一化 (Layer Normalization) | 批归一化 (Batch Normalization) |
|---|---|---|
| 归一化方向 | 对每个样本的特征维度进行归一化 | 对同一特征在不同样本间的统计量进行归一化 |
| 统计依赖 | 仅依赖当前样本的数据 | 依赖整个 batch 的统计量 |
| 变长序列支持 | ✅ 天然支持变长序列(如 NLP 任务) | ❌ 需要固定长度或特殊处理(如 padding/masking) |
| 小批量稳定性 | ✅ 对小批量数据表现稳定 | ❌ 小批量时统计量估计不准确(易波动) |
| 典型应用领域 | NLP、Transformer 等序列模型 | CV(如 CNN)等固定输入结构的模型 |
📍 在 Transformer 中的位置
GPT 采用 预归一化(Pre-LN) 结构:
输入 → LayerNorm → 多头注意力 → 残差 → LayerNorm → 前馈 → 残差
每个 Transformer 块内,注意力之前和前馈之前都先做层归一化
最终输出之前再做一个层归一化,然后送进输出线性层
💡 直观理解
层归一化就像给每个 token 的嵌入向量重新校准:
不管原来各个维度的数值相差多大,都先标准化为“0 中心、1 方差”的分布
然后通过可学习的 γ\gammaγ 和 β\betaβ,让模型选择性地“放大”某些维度(如果它们重要)或“缩小”某些维度(如果它们不重要)
这使得模型更关注特征之间的相对关系,而不是绝对数值大小。
✅ 总结
归一化是让数据分布稳定的技术,层归一化是其中一种,专为序列模型设计。
它通过计算每个 token 特征维的均值和方差,进行标准化,再应用可学习的缩放和平移。
在 Transformer 中扮演稳定训练、加速收敛的关键角色。
📝 4.3 GELU激活函数与前馈网络
🔄 前置概念
归一化:让数据均值0、方差1,稳定训练。层归一化(LayerNorm)是其一。
激活函数:引入非线性,让神经网络能拟合复杂模式。
❌ ReLU的局限
负值直接归零 → 神经元可能“死亡”(梯度永远为0)
在0处不可导,优化困难
无法区分不同大小的负输入
🧠 GELU核心思想
概率加权:用高斯分布的累积分布函数 Φ(x)\Phi(x)Φ(x) 决定保留多少信息。
以下是格式化的数学公式:
GELU(x)=x⋅Φ(x)
正值 → 权重接近1(完全保留)
负值 → 权重平滑衰减(不直接归零)
💡 类比:ReLU是“硬开关”,GELU是“渐变调光器”。
✨ 优势
处处可导,梯度平稳
负区仍有微弱梯度 → 无神经元死亡
非单调,表达能力更强
🏗 在GPT中的应用:前馈网络(FFN)
输入(768) → 线性层(升维到3072) → GELU → 线性层(降维回768) → 输出
- 先升维4倍(让模型探索更丰富组合)
- GELU激活
- 再降维(保持维度一致)
📌 总结
GELU = ReLU的平滑升级版,大模型标配(GPT、BERT、LLaMA等)。核心是用概率权重替代硬阈值,让负值也能贡献微弱学习信号。
📝 4.4 残差连接
🎯 解决的问题
深度网络(如12层Transformer)训练时梯度消失:梯度从输出层反向传播,每经过一层都会衰减,导致靠近输入层的参数几乎不更新。
🧠 核心思想
让输入跳过中间层,直接与输出相加,为梯度提供一条“高速公路”。
📐 数学形式
输出 = 层(输入) + 输入
层(输入) 可以是多头注意力或前馈网络
加法是逐元素相加(要求形状相同)
🏗️ 在GPT中的位置(预归一化结构)
每个Transformer块内部顺序:
x → LayerNorm → 注意力 → y1 → x + y1 → LayerNorm → 前馈 → y2 → (x + y1) + y2
↑_______________| ↑______________________|
先做层归一化,再经过注意力/前馈,最后加回原始输入
每个子层(注意力、前馈)都有独立的残差连接
✅ 主要好处
缓解梯度消失 梯度可以直接从输出传到输入,不经过非线性层压缩
训练更深网络 没有残差,12层以上的Transformer几乎无法收敛
保留原始信息 即使中间层学歪了,原始输入仍能直达输出
加速收敛 模型可以更早学习微小调整,而非从头构建表示
💡 通俗类比
无残差:快递每层都要被经理处理,可能损坏或丢失
有残差:手里始终保留原始包裹副本,即使某层出问题也不影响送达
🔑 一句话总结
残差连接 = 给梯度和信息修一条“直达高速”,让深度网络真正可训练。
它是ResNet、Transformer、GPT等成功堆叠上百层的核心设计。
📝 4.5 组装Transformer块
🧱 一个Transformer块包含两个子层
子层组件作用
子层1 层归一化 → 多头因果注意力 → 残差连接 让每个token关注它之前的所有token,捕捉上下文依赖
子层2 层归一化 → 前馈网络(FFN) → 残差连接 对每个token独立做非线性变换,增强表达能力
📐 每个子层的统一模式(预归一化)
输出 = 核心处理( 层归一化(输入) ) + 输入
先归一化,再处理,最后加回原始输入(残差连接)
🔁 完整前向流程(代码形式)
def forward(x):
# 子层1:注意力
shortcut = x
x = ln1(x) # 归一化
x = multi_head_attn(x) # 注意力
x = shortcut + x # 残差
# 子层2:前馈
shortcut = x
x = ln2(x) # 归一化
x = feed_forward(x) # 升维→GELU→降维
x = shortcut + x # 残差
return x
✅ 关键设计
预归一化(Pre-LN):归一化放在子层之前,梯度流动更顺畅,训练更稳定
残差连接:让信息直达,解决梯度消失,支持深层网络
前馈网络:先升维4倍(如768→3072),GELU激活,再降维回原维度
🧩 输入输出形状
输入:(batch, seq_len, emb_dim)
输出:与输入形状完全相同
每个Transformer块都是“形状不变”的模块,可以任意堆叠
📌 一句话总结
每个Transformer块由两个子层串行组成:子层1(归一化→多头注意力→残差),子层2(归一化→前馈网络→残差)。
这个模块是GPT的基本积木,堆叠N层就构成完整模型。
总结
层归一化可以确保每个层的输出具有一致的均值和方差,从而稳定训练过程。
残差连接是通过将一层的输出直接传递到更深层来跳过一个或多个层的连接,它能帮助
缓解在训练深度神经网络(如大语言模型)时遇到的梯度消失问题。
作为 GPT 模型的核心模块组件,Transformer 块融合了掩码多头注意力模块和使用 GELU
激活函数的全连接前馈神经网络。
GPT 模型是具有许多重复 Transformer 块的大语言模型,这些 Transformer 块有数百万到数
十亿个参数。
GPT 模型具有多种规模,比如参数量分别为 1.24 亿、3.45 亿、7.62 亿和 15.4 亿的模型,
我们可以使用相同的 GPTModel Python 类来实现它们。
类 GPT 大语言模型的文本生成能力涉及根据给定的输入上下文来逐个预测词元,然后将
输出张量解码为人类可读的文本。
在没有训练的情况下,GPT 模型生成的文本是不连贯的,这显示了模型训练对于生成连
贯文本的重要性
GPT核心四步骤
1.预训练阶段
模型初始学习人类语言和知识
- 使用纯文字段落数据
- 通过预测下一个字学习
- 计算段落联合概率评估学习效果
2.有监督微调(SFT)
训练模型执行具体任务
- 使用人工撰写的一问一答数据
- 学习对话、分类等任务能力
- 数据量级远小于预训练
3.奖励模型训练
创建评估回答质量的"教练"模型
- 基于人类标注的偏好数据
- 学习给不同回答打分
- 用于指导强化学习
4.强化学习(PPO)
优化模型回答质量
- 模型生成多种回答方案
- 奖励模型提供反馈评分
- 通过迭代提高回答质量

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)