基于 ConvNeXt-Transformer 的颈动脉超声图像分割算法研究
0 引言
心血管疾病是全球范围内导致死亡和残疾的主要原因之一,颈动脉作为人体重要的供血血管,其与动脉粥样硬化、脑卒中等心脑血管疾病的发生、发展密切相关,是临床诊断与病情监测的重要对象[1]。超声成像技术因具有无创、实时、低成本、无辐射等优势,已成为颈动脉病变筛查、诊断及随访的首选影像学手段,广泛应用于临床常规检查与科研工作中[2-3]。颈动脉超声图像的分割是后续病变量化分析的前提与基础。传统的颈动脉超声图像分割主要依赖临床医师手动标注,该方式不仅耗时费力,且分割结果易受医师经验、主观判断、疲劳程度等因素影响,存在个体差异大、重复性差、效率低下等问题,难以满足大规模临床数据处理与诊断的需求。因此,研发精准自动化的颈动脉超声图像分割算法,对提高临床诊断效率、降低医师工作负担、推动心脑血管疾病的早期筛选与治疗具有重要的意义。
近年来,深度学习技术在医学图像分割领域取得了突破性进展,基于卷积神经网络(CNN)的分割算法被广泛应用于颈动脉超声图像分割任务中[4-5]。其中,UNet及其改进模型凭借其对称的U型结构、跳跃连接等设计,能够有效融合浅层细节特征与深层语义特征,在医学图像分割中表现出优异的性能,成为该领域的主流算法[6]。然而,传统UNet及其改进模型依赖CNN的局部感受野特性,难以捕捉图像中的长距离依赖关系。Transformer模型基于自注意力机制,能够有效捕捉图像中的全局依赖关系,突破CNN局部感受野的局限,在自然图像分类、目标检测等领域展现出强大的特征提取能力[7-8]。将Transformer与UNet相结合,可充分发挥两者的优势:利用UNet的U型结构与跳跃连接捕捉图像浅层细节特征,保障分割结果的空间准确性;借助Transformer的自注意力机制捕捉全局语义特征与长距离依赖关系,精准识别颈动脉血管的整体形态与连续走向,从而提升复杂超声图像下的分割性能。
针对传统UNet在颈动脉超声图像分割中存在的全局特征捕捉不足、分割精度有限等问题,本文提出一种融合Transformer与UNet的颈动脉超声图像分割算法。为颈动脉超声图像的自动化分割提供一种新的可行方案,助力临床心脑血管疾病的精准诊断与科研工作的深入开展。
目录
1 数据
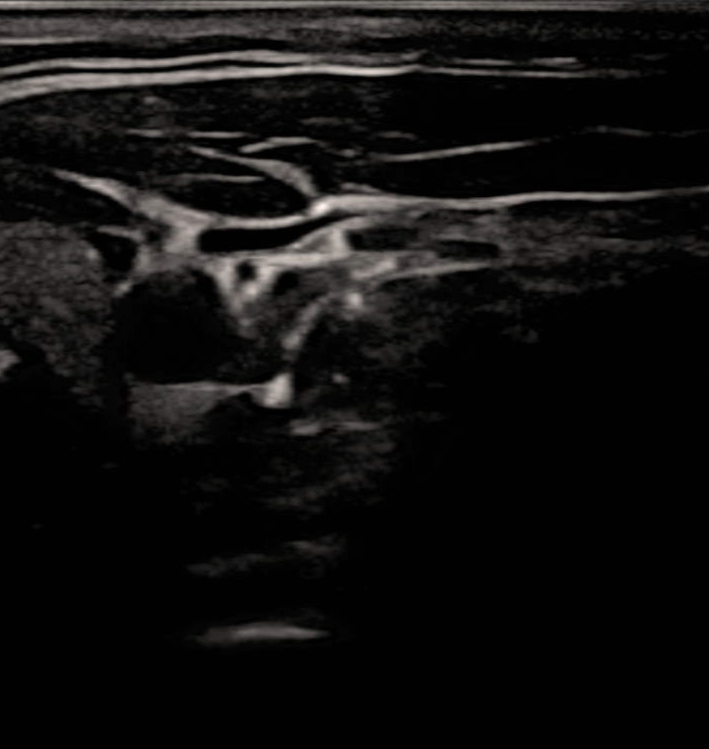
本文实验所用颈动脉超声图像均来源于Kaggle公开平台,该数据集共包含2200张高质量超声图像,数据采集自11名不同受试者,每名受试者均完成至少双侧颈部(左右两个部位)的超声检查,数据集整体分为两个文件夹,其中超声图像文件夹包含1100张图像,每名受试者对应采集100张颈动脉超声图像,为分割任务提供原始输入数据,专家标注掩码文件夹包含1100张掩码图像,该类掩码由专业技术人员制作,并经临床专家审核验证,可作为颈动脉分割任务的标准参考标签,为模型训练与性能评估提供依据;所有超声图像均采用Mindary UMT-500Plus超声机搭配L13-3s线性探针拍摄采集,在11名受试者中,2人采用血管法进行超声检查,8人采用颈动脉法完成检查,原始采集的时间序列DICOM格式图像经预处理转换为PNG格式,并进行适当裁剪,以去除无关背景区域、聚焦颈动脉目标区域,提升后续模型训练效率与分割精度,该数据集图像基本特征为:分辨率709×749×3(RGB三通道彩色图像),存储格式为PNG,数据量总计2200张(含1100张原始超声图像、1100张专家标注掩码)。如图1和图2所示,一名受试者的原始超声图像和对应的掩码。
数据连接:Carotid Ultrasound Images

2 方法
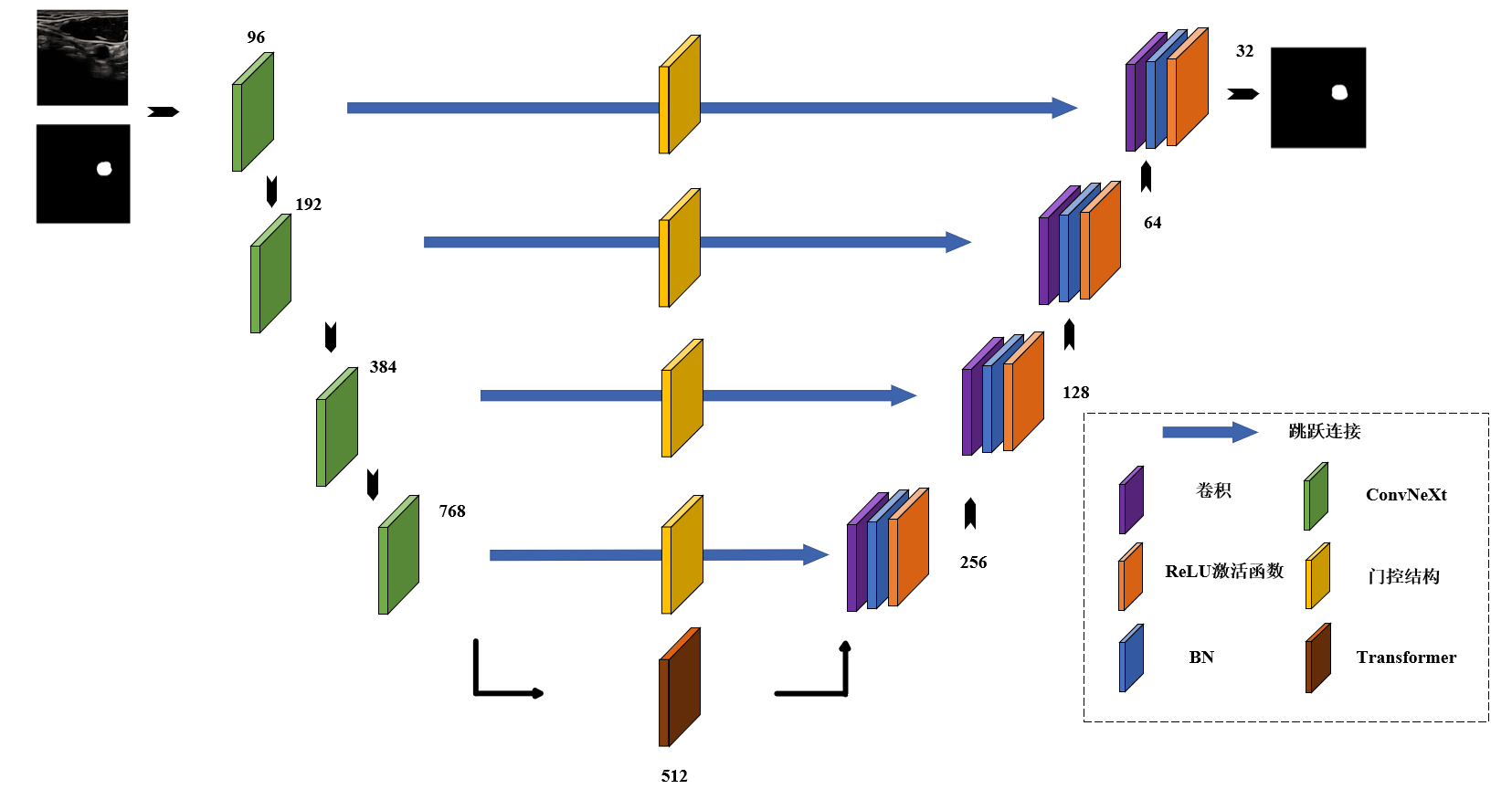
本文提出一种基于ConvNeXt-Transformer 混合编码器与注意力门控解码器的颈动脉超声图像分割网络,遵循编码器 - 解码器(Encoder-Decoder)的 U 型结构设计。网络核心分为三部分:混合编码器实现多尺度局部特征提取与全局长距离依赖建模;注意力门控解码器通过门控机制优化跳跃连接,实现高保真特征融合;多尺度监督输出头提升模型对动脉结构的学习能力,最终实现颈动脉超声图像的精准分割。网络整体架构如图3所示。
3.1 ConvNeXt结构
首先,为提升编码器的特征提取能力,研究摒弃传统 U-Net 采用的基础卷积堆叠方式,采用基于 timm 库实现的 ConvNeXt 架构作为主干网络。结构如图4所示。该模块以 7×7 深度卷积提取空间局部特征,通过层归一化稳定训练;随后采用 1×1 卷积实现 4 倍通道扩张(96→384),经 GELU 激活函数引入非线性变换后,再通过 1×1 卷积将通道数恢复至 96;最终通过残差连接融合输入特征,完成特征变换。该结构融合了 CNN 的局部归纳偏置与 Transformer 的 MLP 设计,在保证计算效率的同时,显著提升了特征表达能力,为颈动脉超声图像提供鲁棒的多尺度局部特征[9]。

注:图来自于 ConvNeXt详解 - 知乎
代码展示:
class HybridEncoder(nn.Module):
def __init__(self, img_size=709, patch_size=4, dim=512, depth=12, backbone_name='convnext_tiny'):
super().__init__()
self.backbone_name = backbone_name
self.backbone = timm.create_model(backbone_name, pretrained=False, features_only=True)
self.dim = dim
self.patch_size = patch_size
if 'resnet50' in backbone_name:
self.patch_in_ch = 1024
self.skip_channels = [64, 256, 512, 1024]
elif 'convnext_tiny' in backbone_name or 'convnext_small' in backbone_name:
self.patch_in_ch = 768
self.skip_channels = [96, 192, 384, 768]
else:
raise ValueError(f"Unsupported backbone: {backbone_name}. Please add config.")
self.patch_embed = nn.Conv2d(self.patch_in_ch, dim, kernel_size=patch_size, stride=patch_size)
self.blocks = nn.ModuleList([TransformerBlock(dim) for _ in range(depth)])
def forward(self, x):
features = self.backbone(x)
x1, x2, x3, x4 = features[0], features[1], features[2], features[3]
patch_feat = self.patch_embed(x4)
B, C, h, w = patch_feat.shape
pos_emb = torch.randn(1, h * w, self.dim, device=x.device)
tokens = patch_feat.flatten(2).transpose(1, 2)
tokens = tokens + pos_emb
for blk in self.blocks:
tokens = blk(tokens)
return tokens, x1, x2, x3, x4, h, w3.2 门控结构
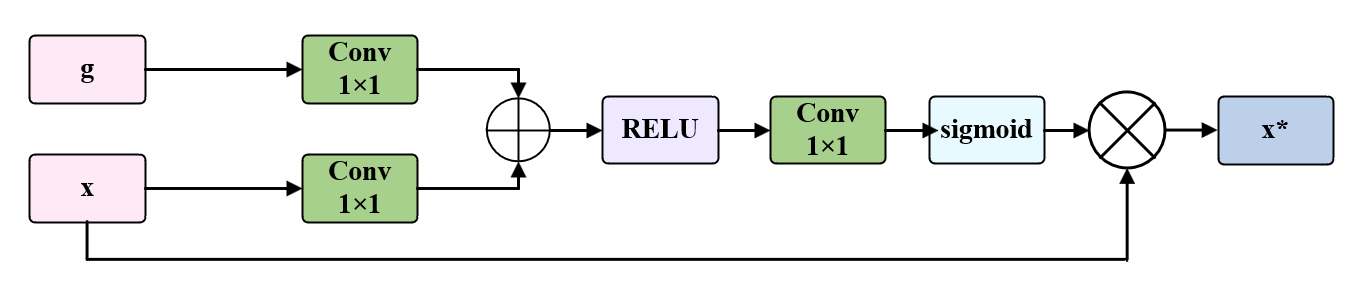
其次,为了在编码器与解码器之间实现较高的特征融合,本文在跳跃连接处构建了门控注意力结构(Attention Gate)。传统 U-Net 直接拼接编码器与解码器特征,容易引入大量背景噪声与冗余信息,尤其对颈动脉超声这类噪声干扰的图像,会显著降低边缘分割精度。为此,本模型以解码器上采样生成的高层语义特征作为门控信号(Gating Signal),对编码器传来的低层细节特征进行加权筛选。结构图5所示,该结构以解码器上采样生成的高层语义特征 g 为门控引导信号,对编码器输出的低层细节特征 x 进行自适应加权筛选:首先通过 1×1 卷积对齐两类特征的通道维度,经逐元素相加完成语义与细节的特征融合;随后经 ReLU 激活与 1×1 卷积压缩通道,通过 Sigmoid 函数生成取值范围为[0,1]的注意力权重掩码;最终将原始跳跃特征与权重掩码逐元素相乘,输出加权增强特征 x*。该门控机制可自动聚焦血管区域的有效特征、抑制超声图像的背景噪声干扰,解决传统 U-Net 直接拼接跳跃特征导致的噪声传递问题,显著提升多尺度特征融合的精准度,为颈动脉图像的高精度分割提供可靠支撑。
代码展示:
class AttentionGate(nn.Module):
def __init__(self, g_channels, x_channels, inter_channels):
super().__init__()
self.w_g = nn.Conv2d(g_channels, inter_channels, kernel_size=1)
self.w_x = nn.Conv2d(x_channels, inter_channels, kernel_size=1)
self.psi = nn.Conv2d(inter_channels, 1, kernel_size=1)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
def forward(self, g, x):
g1 = self.w_g(g)
x1 = self.w_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
psi = self.sigmoid(psi)
return x * psi3.3 Transformer
为弥补卷积神经网络在长距离全局依赖建模上的局限性,本文在 ConvNeXt 骨干网络的深层特征后,引入 Transformer 模块构建混合编码器,实现局部细节与全局结构的互补建模。针对 ConvNeXt 输出的 768 通道深层语义特征,先通过将二维特征图转换为一维序列,将空间维度的特征映射为序列维度的特征表示;随后一维序列序列输入至 12 层堆叠的Transformer Block,完成全局特征的交互与增强。单个Transformer Block 遵循标准 “双残差” 结构设计,如图6所示,该模块以特征序列为输入,首先通过层归一化(LN)稳定特征分布,并输入至多头自注意力机制(MHSA),MHSA以 Query-Key-Value 的交互方式,计算特征序列中所有序列 之间的相似度权重,建模任意位置之间的长距离依赖关系,输出全局增强的特征表示;随后通过残差连接融合原始特征,保留原始信息并缓解梯度消失问题;经过第二次层归一化后,特征送入多层感知机(MLP)完成非线性变换,MLP 包含两个线性层及中间的 GELU 激活函数,实现特征的升维、非线性映射与降维,增强模型对特征组合的表达能力;最终通过二次残差连接输出增强后的特征。该结构使模型在捕捉颈动脉超声图像局部细节的同时,精准建模血管的全局结构,提升了特征表达的鲁棒性。

代码展示:
class TransformerBlock(nn.Module):
def __init__(self, dim, heads=8, mlp_ratio=4.):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(embed_dim=dim, num_heads=heads, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)),
nn.GELU(),
nn.Linear(int(dim * mlp_ratio), dim)
)
def forward(self, x):
x = x + self.attn(self.norm1(x), self.norm1(x), self.norm1(x))[0]
x = x + self.mlp(self.norm2(x))
return x
3 实验
3.1 数据预处理
实验采用颈动脉超声图像数据集(第1节所叙述),包含超声原图与标注的掩码。图像与标签按文件名一一对应,数据总量为1100名受试者。按照 8:2 比例随机划分为训练集与测试集,保证数据分布一致。数据预处理流程如下:(1)读取超声图像并转换为 RGB 格式,将像素值归一化至 [0,1];(2)分割标签采用灰度图读取,将前景像素值 255 映射为 1,背景为 0,构建二分类标签;(3)将图像与标签转换为张量格式,并调整通道顺序以适配 PyTorch 输入格式。
3.2 实验设置
实验模型基于 PyTorch 深度学习框架实现,使用 NVIDIA GPU 加速训练。训练参数设置如下:批次大小:16;训练轮次:50 轮;初始学习率:10−4;优化器:AdamW;学习率调度:余弦退火调度。研究采用交叉熵损失与Dice 损失加权构成的联合损失函数。此外,为强化多尺度特征学习,在解码器中间层引入辅助监督损失,主输出损失权重为 1,两路辅助输出损失权重均为 0.3,
联合主损失定义为交叉熵损失与Dice损失之和:
其中,交叉熵损失计算公式为:
Dice损失[10]用于缓解类别不平衡,其公式为:
其中,pred 为模型预测的分割结果集合;true 为金标准(真实标注)的分割结果集合;∣pred∩true∣ 为预测与真实区域的交集像素数;∣pred∣+∣true∣ 为预测与真实区域的总像素数之和。最终总损失由主损失与两路辅助损失加权构成(对解码器中间输出施加监督,主损失权重为 1,辅助损失权重各为 0.3):
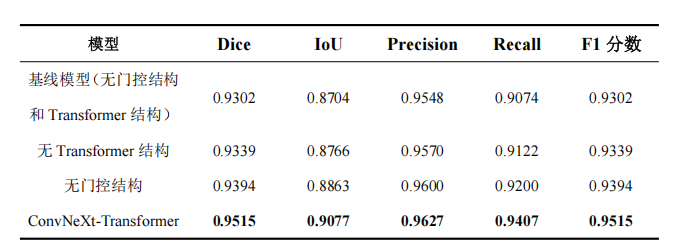
此外,为了评估各模块是否对颈动脉超声图像的分割任务有提升,明确门控结构与Transformer结构在该任务中的作用与贡献,研究设置了系统性的消融实验,通过构建三组对比模型,与所提完整模型进行性能比对,从而量化各模块的有效性。具体实验分组如下:第一组为基线模型,该模型不包含任何门控结构和Transformer结构;第二组为无Transformer结构模型,该模型保留了所提完整模型中的门控结构;第三组为无门控结构模型,该模型保留了完整模型中的Transformer结构,仅去除门控结构。为确保实验结果的公平性与可比性,所有消融实验均在相同的实验环境、数据集(训练集880幅、测试集220幅)及评价指标(如Dice相似系数、交并比IoU、像素准确率等)下进行,最终通过各组模型的性能差异,清晰界定门控结构与Transformer结构各自的核心贡献,为所提模型的结构设计提供实验支撑。
3.3 评价指标
为全面评估模型的分割性能,本研究采用Dice相似系数、交并比(IoU)、精确率(Precision)、召回率(Recall)与F1分数作为量化评价指标。
Dice和IoU分别定义如下[11]:
其中,A:模型预测的分割区域集合;B:真实标注(金标准)的分割区域集合;TP(True Positive):真正例,预测为正、实际为正的样本数;FP(False Positive):假正例,预测为正、实际为负的样本数;FN(False Negative):假负例,预测为负、实际为正的样本数。
Precision、Recall和F1分数定义如下[12]:
4 结果
4.1 训练损失曲线
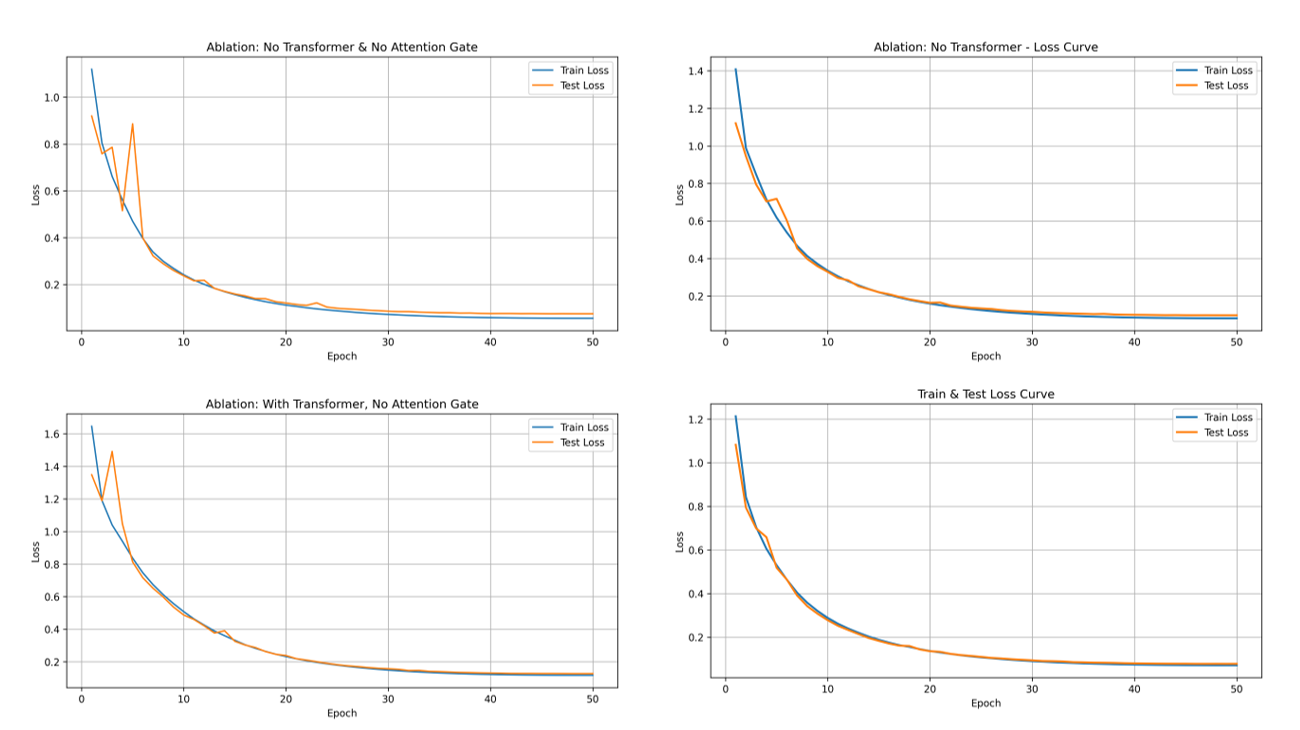
为验证所提 ConvNeXt-Transformer 模型中各核心模块的有效性,研究设计了多组消融实验,通过对比不同模块组合下的训练损失(Train Loss)与测试损失(Test Loss)曲线,系统分析 Transformer 结构与注意力门控机制对模型性能的影响,实验结果如图7所示。基线模型(无 Transformer 与注意力门控结构)作为基准对照组,从损失曲线可见,其训练损失随训练轮次(Epoch)增加快速下降并最终平稳收敛,验证了基础卷积架构具备基础的特征拟合能力;但测试损失在训练中后期存在明显波动,且最终收敛值高于完整模型,说明仅依靠卷积的局部特征提取能力,模型对未见数据的泛化稳定性存在局限,难以有效建模长距离特征依赖关系。在仅移除 Transformer 结构、保留注意力门控的实验组中,模型损失曲线的整体下降趋势与基线模型一致,但测试损失的波动幅度显著降低,收敛速度与最终收敛精度均优于基线模型。该结果表明,注意力门控机制可有效筛选有效特征、抑制冗余信息干扰,在不依赖 Transformer 全局建模的前提下,仍能提升模型的泛化能力,验证了门控结构对特征传递效率的优化作用。在仅移除注意力门控、保留 Transformer 结构的实验组中,模型训练损失的下降幅度与最终收敛水平显著优于基线模型,说明 Transformer 的全局自注意力机制大幅增强了模型对训练数据的特征拟合深度;同时测试损失的下降趋势更平缓、最终收敛值更低,证明 Transformer 结构有效弥补了纯卷积模型在长距离依赖建模上的短板,提升了模型对复杂全局特征的捕捉能力。所提 ConvNeXt-Transformer 完整模型(融合 Transformer 全局建模与注意力门控机制)的损失曲线呈现出最优性能:训练损失快速下降并稳定收敛至极低水平,测试损失不仅收敛速度最快、全程波动最小,且最终测试损失显著低于所有消融实验组。这一结果充分表明,卷积结构的局部特征提取能力、Transformer 的全局特征交互能力与注意力门控的特征筛选能力形成了有效协同,在保证模型对训练数据充分拟合的同时,最大程度提升了模型的泛化能力与鲁棒性,验证了所提架构设计的合理性与优越性。
4.2 定量分析与消融实验结果
为进一步量化各模块的性能增益,本研究选取Dice 系数、IoU(交并比)、精确率(Precision)、召回率(Recall)、F1 分数5 项评价指标,对不同模型配置的分割性能进行定量评估,结果如表1所示。基线模型(无门控结构和 Transformer 结构)作为基准,其 Dice 系数为 0.9302、IoU 为 0.8704、精确率 0.9548、召回率 0.9074、F1 分数 0.9302,仅依靠基础卷积结构实现了基础分割性能,但各项指标均为全组最低,验证了纯卷积架构在复杂医学图像分割任务中的性能上限。在仅移除 Transformer 结构、保留注意力门控的实验组中,各项指标较基线模型均实现稳定提升:Dice 系数提升至 0.9339(+0.37),IoU 提升至 0.8766(+0.62),精确率、召回率与 F1 分数分别提升 0.22、0.48 与 0.37。该结果定量验证了注意力门控机制的有效性:通过对特征通道进行自适应加权筛选,有效抑制了冗余特征干扰,在不增加全局建模复杂度的前提下,提升了模型的分割精度与泛化能力。在仅移除注意力门控、保留 Transformer 结构的实验组中,模型性能实现进一步跃升:Dice 系数达 0.9394(较基线 + 0.92),IoU 达 0.8863(较基线 + 1.59),精确率、召回率与 F1 分数分别提升 0.52、1.26 与 0.92。这一结果充分证明,Transformer 结构的全局自注意力机制能够有效建模图像长距离依赖关系,捕捉卷积网络难以提取的全局上下文信息,从根本上提升了模型对目标区域的特征建模能力。所提 ConvNeXt-Transformer 完整模型在所有指标上均取得最优性能,实现了对消融组的全面超越:Dice 系数达 0.9515(较基线 + 2.13),IoU 达 0.9077(较基线 + 3.73),精确率 0.9627(+0.79)、召回率 0.9407(+3.33)、F1 分数 0.9515(+2.13)。
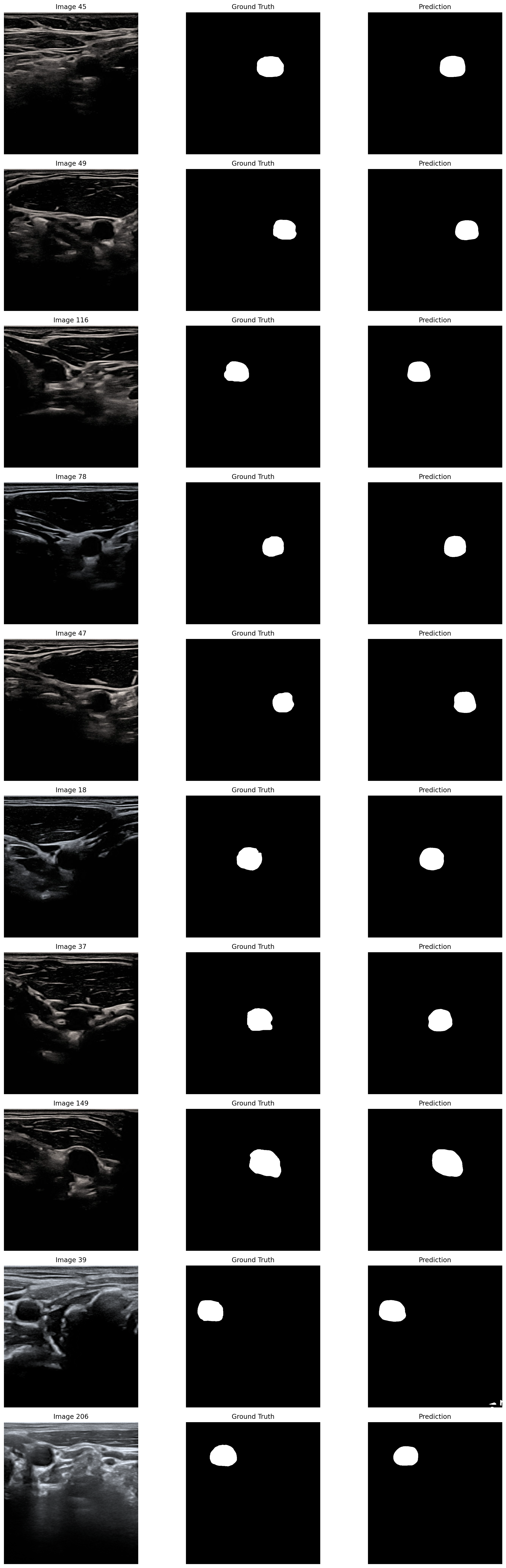
4.3 可视化分割结果
图8中展示了ConvNeXt-Transformer 模型在颈动脉超声图像测试集上的典型分割结果,每一行从左至右依次为原始超声图像、专家标注的标准(Ground Truth)与模型预测结果(Prediction)。从可视化结果可见,模型能够识别并分割出颈动脉血管区域,预测掩码与金标准在形状、位置、边缘轮廓上高度吻合,可有效应对超声图像的散斑噪声、灰度不均匀等干扰,准确区分血管区域与背景组织。对于不同大小、形态的血管截面,模型均能实现稳定、完整的分割,无明显漏分割、过分割现象,充分验证了所提混合编码 - 解码架构与注意力门控机制的有效性,证明模型具备优异的颈动脉图像分割性能与临床应用潜力。
5 讨论
本文针对颈动脉图像分割任务中纯卷积模型长距离依赖建模能力不足、特征冗余干扰等问题,提出了融合ConvNeXt卷积主干、Transformer全局建模与注意力门控机制的ConvNeXt-Transformer模型,并通过系统的消融实验,从定性损失曲线与定量分割指标两个维度,全面验证了各模块的有效性与协同作用。实验结果表明,注意力门控机制可通过对特征通道自适应加权,有效筛选目标相关有效特征、抑制冗余背景干扰,在不依赖全局建模的前提下优化特征传递效率与模型泛化稳定性,其作用与现有研究结论一致;仅保留Transformer结构的模型较基线模型实现更大幅度性能跃升,证明Transformer的全局自注意力机制能有效弥补纯卷积模型局部感受野的局限,精准建模目标区域全局结构信息,突破纯卷积模型性能上限;而完整的ConvNeXt-Transformer模型在所有评价指标上均取得最优性能,充分验证了ConvNeXt局部特征提取、Transformer全局建模与注意力门控特征筛选三者的深度协同效应,三有效解决了纯卷积模型漏检率高、泛化性不足的问题。
该模型在颈动脉B超等医学图像分割任务中实现了Dice系数0.9515、IoU 0.9077的高性能,能更精准提取血管壁等目标区域轮廓,为后续心脑血管疾病相关研究提供可靠分割基础,同时具备更强泛化能力。同时本研究仍存在一定局限性:实验仅在特定数据集上验证性能,未来需在多中心、多模态大规模数据集上进一步验证通用性;Transformer结构增加了模型参数量与计算复杂度,后续需通过轻量化设计优化效率以提升临床实时应用潜力;此外,研究仅针对分割任务验证,未来可将该架构拓展至医学图像分类、配准等其他任务以挖掘更大应用价值。综上,本研究充分验证了所提模型的有效性,证明了Transformer与注意力门控机制对医学图像分割性能的提升作用,为该领域算法设计提供了参考。
参考
[1] 国家心血管病中心, 中国心血管健康与疾病报告编写组. 中国心血管健康与疾病报告2023概要[J]. 中国循环杂志, 2024, 39(7): 625-660.
[2] 李艳, 任俊红. 超声诊断颈动脉粥样硬化斑块的方法和规范化应用 [J] . 中华全科医师杂志, 2022, 21(2) : 105-108.
[3] 师绿江.中国健康体检人群颈动脉超声检查规范解读[C]//浙江医院,浙江省干部保健中心.2016年健康管理服务规范化提升国际论坛暨“1+X”健康体检专题研讨会暨浙江省医学会健康管理学分会预防保健学组学术会议论文集.空军航空医学研究所;,2016:55-56.
[4] 沈冲冲,周小安,安相静,等.深度学习算法在颈动脉超声图像斑块分割中的应用研究[J].智能计算机与应用,2021,11(01):84-88.
[5]吴雨.基于轻量化网络的颈动脉超声分割方法研究[D].华东师范大学,2024.
[6] [侯震昆,蔡隋雨,田宏.ASGE-UNet:用于皮肤病变分割的自适应协同组增强U-Net[J/OL].计算机系统应用,1-12
[7] 何志强,孙占全.基于Swin-Transformer的颈动脉超声图像斑块分割[J].电子科技,2024,37(09):48-56.
[8] 常国艳,张文勇,杨晓茹,等.基于自适应多特征融合Transformer的小样本医学时间序列预测[J/OL].计算机应用与软件,1-13
[9] ConvNeXt详解 - 知乎
[10] Dice 与损失函数-Dice Loss - 知乎
[11] 论文中常用的图像分割评价指标-附完整代码 - 知乎
[12] 基于EEGNet网络的脑电信号对阿尔茨海默与额颞叶痴呆的辅助诊断研究-CSDN博客
注:若有侵权部分,请留言将会删除。
个人观点 ,仅供参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)