实战分享:ChatBI与智能查询体系搭建,搞定业务查询3大痛点
做后端开发这么多年,最头疼的不是写复杂接口,而是应对业务同事的各种数据查询需求——“帮我查一下近3个月各区域的销售数据,还要和去年同期对比”“能不能导出客户复购率前10的明细,关联订单表和用户表”“这个PDF里的报表数据,能不能快速导入系统查询”。
相信做过数据相关开发的朋友都有同感,业务人员不懂SQL,复杂业务数据查询全靠技术兜底,多表关联分析更是耗时费力,有时候一个查询需求要折腾大半天,既耽误自己的开发进度,也满足不了业务的实时决策需求。
我们熙瑾会悟团队牵头搭建了一套ChatBI与智能查询体系,核心就是解决“复杂业务数据难查询、非技术人员不会写SQL、多表关联难分析”这3个痛点,用到了ES数据建模、SQL自动生成、ReAct/Planning Agent等7项核心技术,今天就结合实操经验,跟大家好好唠唠,全程口语化,不搞虚的,都是能直接落地的干货,新手也能看懂。
先跟大家吐个槽,在没搭这套体系之前,我们的数据查询有多乱:业务人员要查数据,先填需求单,技术人员拿到后,先梳理业务逻辑,再写SQL,遇到多表关联,还要反复核对表结构、字段关联关系,有时候一个SQL写错一个关联条件,就要重新跑一遍,耗时又耗力。更麻烦的是,很多业务查询需求是突发性的,比如运营要实时看活动效果,等我们写完SQL、跑完数据,最佳调整时机可能就错过了。
而且,非技术人员根本无法自主查询,哪怕是简单的“查本月销售额”,也要找技术人员帮忙;复杂一点的多表关联分析,比如“查询各产品的销售情况,关联库存表看缺货风险,再关联用户表看客户画像”,不仅要写复杂的JOIN语句,还要处理数据过滤、聚合,技术人员都要花不少时间,更别说业务人员了。
基于这些痛点,我们确定了智能查询体系的7个核心模块,逐个突破,最终实现了“业务人员输入自然语言,就能快速拿到精准数据”的目标,下面逐个跟大家拆解,结合技术细节和实操踩坑经验,尽量讲得通俗。
一、核心模块拆解:7项技术,逐个解决业务痛点
1. ES数据建模:给数据“分门别类”,解决复杂数据查询慢的问题
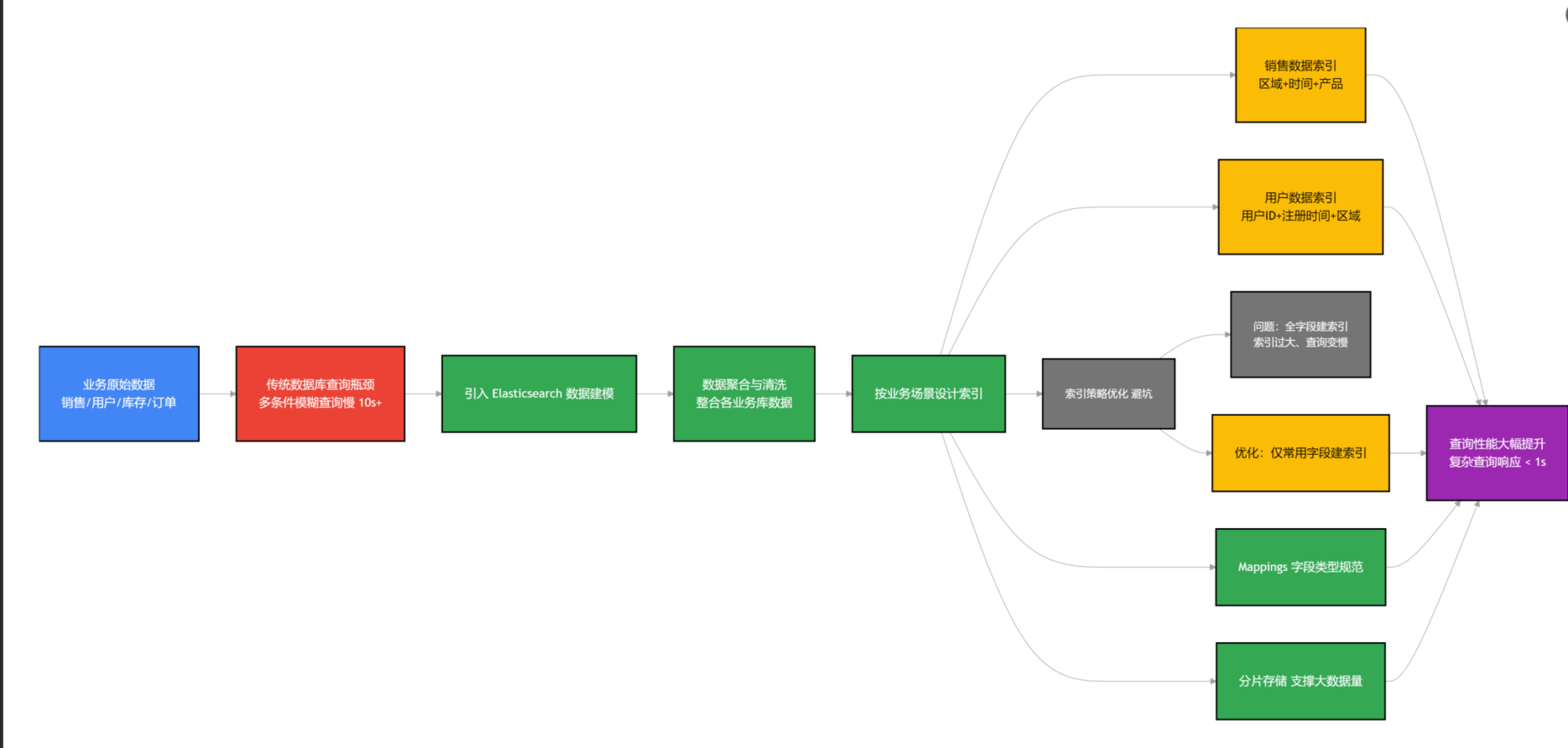
首先要解决的就是“复杂业务数据难查询”的痛点,我们业务数据量很大,涉及销售、用户、库存、订单等多个维度,传统的关系型数据库查询,尤其是多条件过滤、模糊查询时,速度特别慢,有时候一个复杂查询要等十几秒,甚至几十秒。
所以我们引入了Elasticsearch(ES),核心就是做数据建模,把分散在各个业务库的数据,按照业务场景进行聚合、清洗,建立合适的索引,让查询速度翻倍。这里跟大家说个实操要点,ES建模不是简单的把数据导入就行,要结合查询场景来设计索引。
比如,我们把销售数据按照“区域、时间、产品”三个核心维度建立聚合索引,把用户数据按照“用户ID、注册时间、所属区域”建立主键索引,这样业务人员查询“某区域某产品近3个月的销售额”时,ES能快速定位到相关数据,响应时间控制在1秒内。
这里踩过一个坑,一开始我们把所有字段都建立了索引,导致索引体积过大,查询速度反而变慢,后来优化了索引策略,只对常用查询字段、过滤字段建立索引,非必要字段不建索引,同时采用分片存储,解决了大数据量下的查询性能问题。另外,ES的 mappings 设计要合理,比如时间字段用date类型,数值字段用integer、double类型,避免用text类型存储数值,否则会影响聚合查询的效率。
2. SQL自动生成:让非技术人员“告别SQL”,解决不会写SQL的痛点
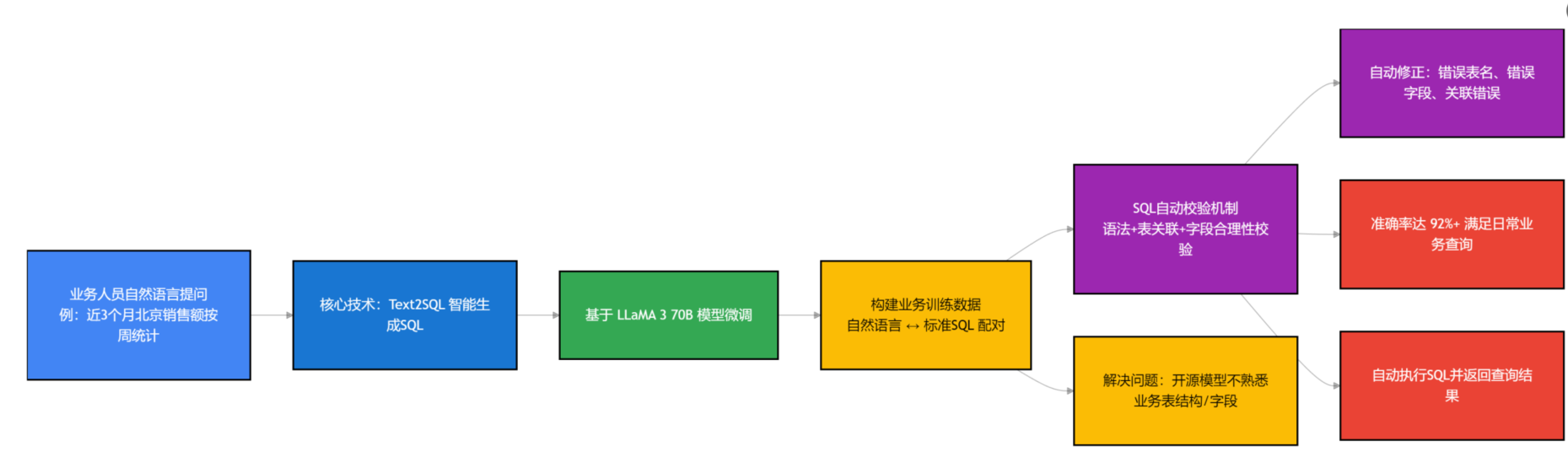
这是整个体系的核心,也是业务人员最关注的功能——不用写一行SQL,只要输入自然语言,比如“查询近3个月北京地区的销售额,按周统计”,系统就能自动生成对应的SQL语句,然后执行查询,返回结果。
这里用到的核心技术是Text2SQL,我们没有直接用开源的模型,而是基于LLaMA 3 70B进行微调,结合我们的业务场景,训练了专属的SQL生成模型。为什么要微调?因为开源模型对我们的业务字段、表结构不熟悉,直接用的话,生成的SQL经常出错,比如把“订单金额”写成“订单数量”,或者关联错表。
微调的过程也很简单,我们整理了上千条业务场景下的“自然语言查询-正确SQL”配对数据,比如“查询用户复购率”对应“SELECT COUNT(DISTINCT user_id) FROM orders WHERE order_time > DATE_SUB(NOW(), INTERVAL 30 DAY) GROUP BY user_id HAVING COUNT(order_id) > 1”,然后用这些数据对LLaMA 3进行微调,让模型熟悉我们的表结构、字段含义和业务逻辑。
另外,我们还做了SQL校验机制,生成SQL后,系统会自动校验SQL的语法正确性、表关联合理性,避免出现语法错误、关联错误导致的查询失败。比如,如果模型生成的SQL中,关联了不存在的表,系统会自动提示,并修正表名;如果字段名写错,会根据关键词联想,修正字段名。这里可以参考SQLGenie的思路,通过表结构预处理、反馈增强的方式,提升SQL生成的准确率,我们目前的SQL生成准确率能达到92%以上,基本能满足大部分业务查询需求。
3. ReAct / Planning Agent:给系统“加个大脑”,解决多表关联难分析的痛点
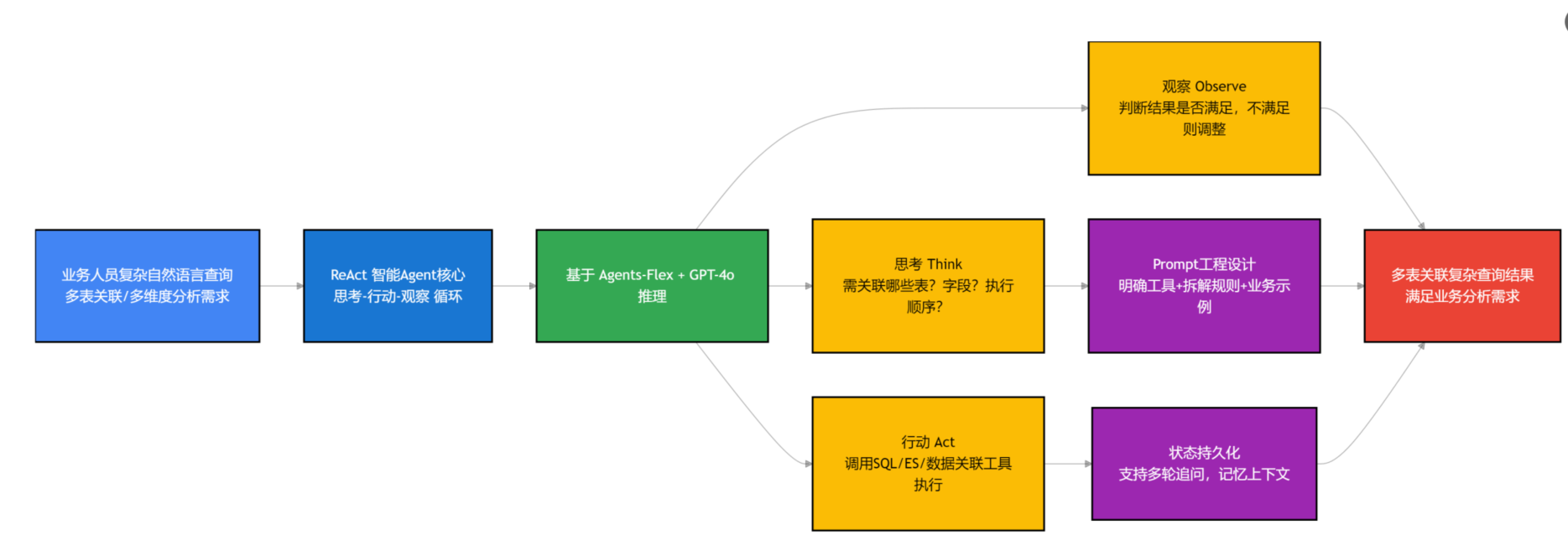
业务人员的查询需求,很多时候不是单表查询,而是多表关联分析,比如“查询各产品的销售额,关联库存表看库存剩余,关联用户表看购买用户的年龄段分布”,这种复杂的查询,单纯的SQL自动生成还不够,需要系统能“思考”,拆解查询步骤,这就是ReAct / Planning Agent的作用。
ReAct Agent的核心逻辑就是“思考-行动-观察”的循环,简单来说,就是系统接到复杂查询需求后,先“思考”:这个查询需要关联哪些表?每个表需要哪些字段?查询的逻辑顺序是什么?然后“行动”:调用对应的工具(比如SQL生成工具、ES查询工具),执行每一步查询,再“观察”查询结果,判断是否满足需求,若不满足,再调整步骤,直到拿到最终结果。
我们用的是Agents-Flex框架中的ReActAgent实现,搭配GPT-4o作为推理模型,让Agent能精准拆解复杂查询需求。比如,当业务人员输入“查询近3个月各产品的销售额,同时看各产品的库存是否充足(库存低于100为不足)”,Agent会先拆解步骤:第一步,查询近3个月各产品的销售额(关联订单表、产品表);第二步,查询各产品的当前库存(关联库存表、产品表);第三步,将销售额和库存数据进行关联,筛选出库存不足的产品;第四步,生成最终的统计结果。
这里要注意,Agent的Prompt设计很关键,我们在Prompt中明确了可用的工具(SQL生成工具、ES检索工具、数据关联工具),以及步骤拆解的规则,同时加入了少量业务场景的示例,让Agent能更快理解业务逻辑。另外,我们还做了状态持久化,比如用户中途追问“再加上各产品的用户复购率”,Agent能记住之前的查询步骤和结果,不用重新拆解,直接补充查询,提升多轮交互的体验。
4. Excel/PDF/Word 解析:打破数据“孤岛”,让非结构化数据可查询
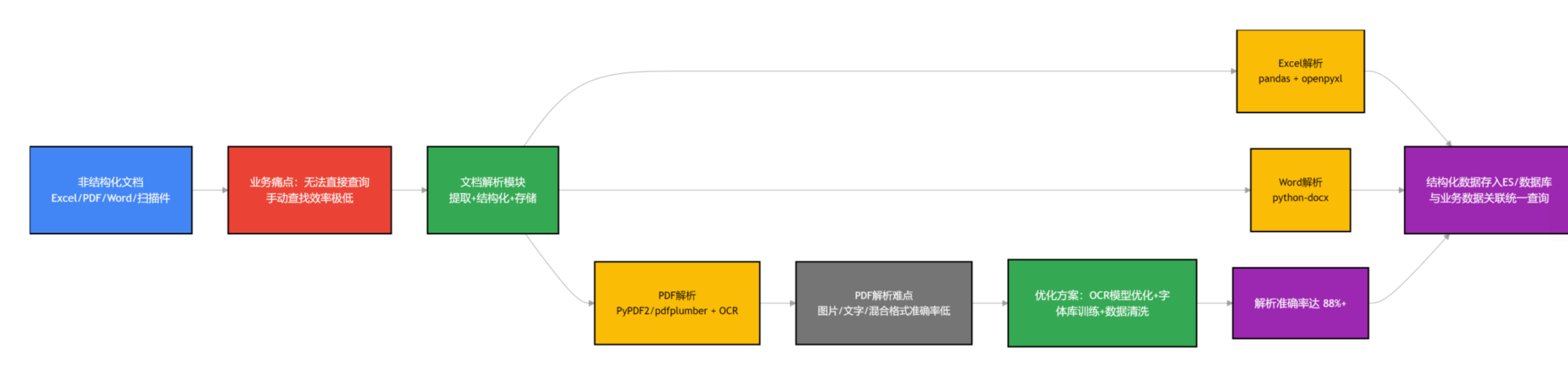
业务中很多数据都是以Excel、PDF、Word的形式存储的,比如财务报表、客户档案、产品手册等,这些非结构化数据无法直接查询,之前业务人员要查这些数据,只能手动打开文件,逐行查找,效率极低。
所以我们加入了文档解析模块,核心是解决非结构化数据的提取和结构化存储问题。Excel解析我们用的是Python的pandas库,搭配openpyxl,能快速读取Excel中的数据,提取表头、内容,然后转化为结构化数据,存入ES或关系型数据库;PDF解析用的是PyPDF2和pdfplumber,针对扫描版PDF,还加入了OCR识别(用的是Tesseract),能精准提取PDF中的表格、文本数据;Word解析用的是python-docx,提取文档中的文本、表格,然后进行结构化处理。
这里踩过一个坑,不同格式的PDF解析难度不一样,比如有的PDF是图片格式,有的是文字格式,还有的是混合格式,一开始解析准确率很低,后来我们优化了OCR识别模型,加入了字体库训练,同时对解析后的 data 进行清洗,去除冗余信息,现在解析准确率能达到88%以上,基本能满足业务需求。解析后的结构化数据,会和系统中的其他业务数据关联,比如PDF中的财务报表数据,会关联到销售数据,方便业务人员统一查询。
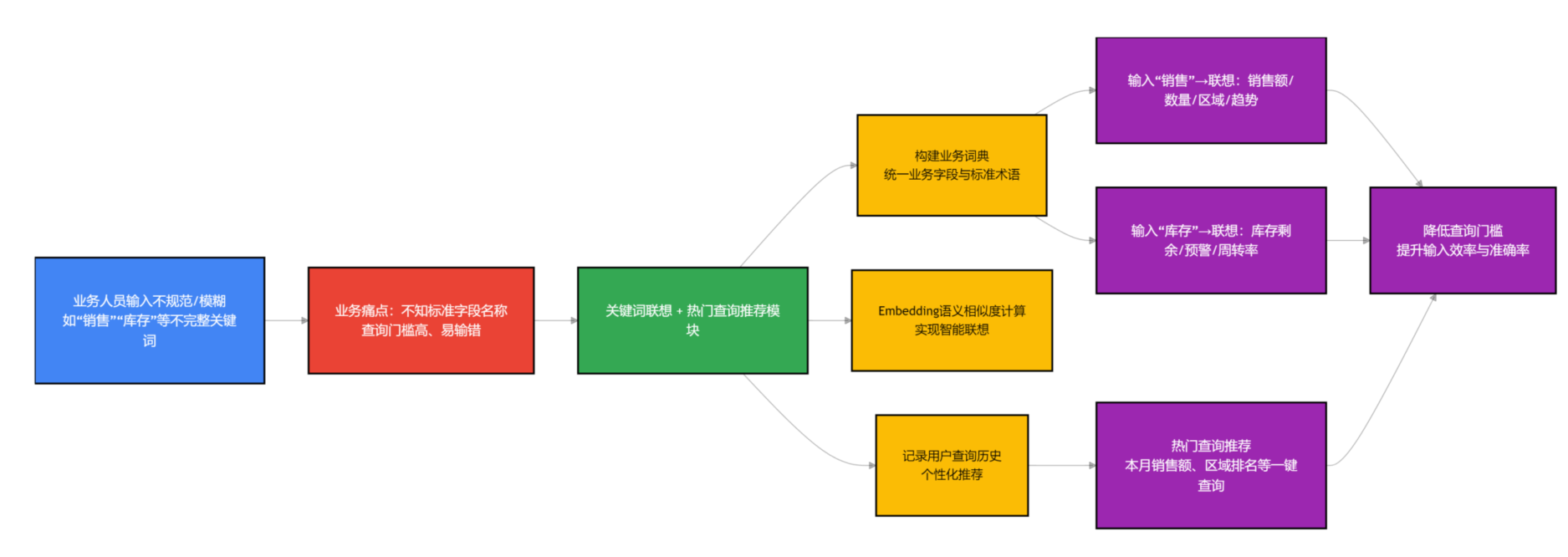
5. 关键词联想:降低查询门槛,提升交互体验
很多业务人员不知道该怎么描述查询需求,比如想查“销售额”,但不知道该用“销售额”“销售金额”还是“成交金额”,这时候关键词联想就很重要了。我们做的关键词联想,核心是基于业务词典和用户查询历史,当用户输入部分关键词时,系统会自动联想相关的查询词、业务字段、查询场景。
比如,用户输入“销售”,系统会联想出“销售额、销售数量、销售区域、销售趋势”等关键词;用户输入“库存”,会联想出“库存剩余、库存预警、库存周转率”等。这里用到的技术是关键词匹配和语义相似度计算,我们基于业务字段,构建了专属的业务词典,同时记录用户的查询历史,通过Embedding计算语义相似度,让联想更精准。
另外,我们还做了热门查询推荐,把业务人员常用的查询需求,比如“本月销售额统计”“各区域销售排名”,放在查询界面的显眼位置,业务人员直接点击就能查询,不用手动输入,进一步降低了查询门槛。
6. 多轮查询规则:记住上下文,实现“连续对话式查询”
业务人员的查询需求,很多时候是连续的,比如先查“近3个月的销售额”,然后追问“其中北京地区的占比多少”,再追问“北京地区各产品的销售额分布”,这就需要系统能记住上下文,不用用户每次都重复描述查询条件。
我们的多轮查询规则,核心是会话状态管理,通过记录用户的每一轮查询需求、查询结果,提取查询上下文(比如时间范围、区域、产品等条件),当用户进行下一轮查询时,自动继承上一轮的上下文,同时支持用户手动修改上下文条件。
比如,用户第一次输入“查询近3个月的销售额”,系统记录时间范围为“近3个月”,查询维度为“整体销售额”;用户第二次输入“其中北京地区的占比多少”,系统自动继承“近3个月”的时间范围,查询维度调整为“北京地区销售额占比”;用户第三次输入“各产品的分布”,系统继承“近3个月、北京地区”的条件,查询各产品的销售额分布。
这里用到的技术是会话上下文存储,我们用Redis存储每一轮的会话信息,包括查询条件、查询结果、上下文参数,同时设置会话过期时间,避免占用过多内存。另外,我们还做了上下文清理功能,用户可以手动清除上下文,重新开始查询,提升交互的灵活性。

7. Embedding 检索:提升查询精准度,解决“语义模糊”问题
很多时候,业务人员的查询需求是模糊的,比如“查一下最近卖得好的产品”,“卖得好”没有明确的定义,可能是销售额高,也可能是销量高,这时候就需要通过Embedding检索,理解用户的语义意图,提升查询精准度。
Embedding的核心是将文本(用户的查询需求、业务字段、数据内容)转化为高维向量,通过计算向量之间的相似度,匹配最贴合的查询结果。我们用的是Sentence-BERT模型,将用户的自然语言查询转化为向量,同时将系统中的业务字段、数据内容也转化为向量,存入向量数据库(我们用的是Milvus),当用户查询时,计算查询向量与数据库中向量的相似度,返回最匹配的结果。
比如,用户输入“查一下最近卖得好的产品”,系统通过Embedding检索,识别出“卖得好”可能对应“销售额Top10”“销量Top10”,然后自动生成两个查询选项,让用户选择,同时返回对应的结果。另外,Embedding检索还能解决关键词检索的“漏检、错检”问题,比如用户输入“干旱”,能检索到含“水分胁迫”的相关数据,这一点在复杂业务查询中特别实用。
这里跟大家说个实操要点,Embedding模型的选择要结合业务场景Sentence-BERT适合短文本语义匹配,我们的查询需求大多是短文本,所以用这个模型很合适;如果是长文本,比如PDF文档的全文检索,可以考虑用GPT-4o的Embedding接口,准确率更高。另外,向量数据库的索引设计也很重要,我们用的是HNSW索引,能实现亿级向量的毫秒级检索,满足实时查询需求。

二、痛点解决效果:从“技术兜底”到“业务自主”
这套ChatBI与智能查询体系搭建完成后,我们彻底解决了之前的3大痛点,效果很明显:
1. 复杂业务数据查询:响应时间从之前的十几秒、几十秒,缩短到1秒内,哪怕是多表关联、大数据量查询,也能快速返回结果,再也不用业务人员长时间等待;
2. 非技术人员查询:业务人员不用再找技术人员写SQL,输入自然语言就能查询,甚至能自主完成多表关联分析,查询效率提升了80%以上,我们技术人员也从繁琐的查询需求中解放出来,能专注于核心开发工作;
3. 多表关联分析:通过ReAct Agent的步骤拆解,复杂的多表关联查询能自动完成,业务人员只需输入查询需求,系统就能拆解步骤、执行查询,再也不用纠结表关联关系、SQL写法。
举个实际的例子,我们公司的运营同事,之前要查“近3个月各区域各产品的销售额、库存情况,以及对应区域的用户复购率”,需要找技术人员写3条复杂的SQL,耗时1-2小时,现在通过我们的智能查询体系,输入自然语言,10秒内就能拿到完整的查询结果,还能导出Excel,大大提升了工作效率。
三、实操踩坑总结
搭建这套体系的过程中,我们踩了不少坑,这里总结几个关键的,避免大家走弯路:
1. ES数据建模:不要盲目建立索引,只对常用查询字段、过滤字段建索引,非必要字段不建,同时合理设计分片,避免索引体积过大影响查询性能;
2. SQL自动生成:一定要结合业务场景微调模型,开源模型直接用准确率很低,另外要做SQL校验机制,避免生成错误的SQL;
3. ReAct Agent:Prompt设计很关键,要明确工具列表、步骤拆解规则,加入业务示例,同时做好状态持久化,提升多轮交互体验;
4. 文档解析:针对不同格式的文档(尤其是扫描版PDF),要优化OCR识别模型,同时对解析后的数据进行清洗,去除冗余信息;
5. Embedding检索:选择合适的Embedding模型和向量数据库,索引设计要适配业务场景,确保检索速度和精准度。
四、总结
熙瑾会悟深耕实用型技术落地,核心涵盖两大项目。ChatBI与智能查询体系以业务需求为导向,摒弃单纯技术堆砌,通过7大核心模块解决业务数据查询难、非技术人员不会写SQL等痛点,实现“数据民主化”,后续将持续优化模型与架构。离线AI会议秘书主打私有化部署,保障数据安全,具备语音转文字、声纹识别等核心功能,提供灵活服务模式与移动录音设备,助力提升会议效率。两大项目均聚焦实际痛点,适配多元需求,欢迎交流探讨、共促提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)