体系结构论文(102):KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta 【META 26年报告】
这篇文章在做什么
这篇文章研究的是一个非常“产业级”的问题:
在 Meta 这种超大规模推荐系统里,模型很多、算子很多、硬件平台也很多,如何让 kernel 开发和优化不再依赖人类工程师一份一份地手工写,而是交给一个 agentic kernel coding 系统自动完成?
作者提出的系统叫 `KernelEvolve`。它的目标不是只在 benchmark 上生成一个快 kernel,而是面向真实生产环境,在以下多重异构条件下自动生成和优化 kernel:
- 模型架构异构
- kernel primitive 异构
- 硬件平台与代际异构而且它不是只针对 NVIDIA GPU,还包括:
- NVIDIA GPU
- AMD GPU
- Meta 自己的 MTIA v3
一、背景
为什么这个问题在 Meta 这类公司会变得特别痛。
Meta 的广告推荐系统每天要跑海量 inference,而且是多阶段、多模型、多硬件平台协同运行。作者强调几个关键压力:
- 上千个模型同时在线
- latency 非常严格,sub-second 甚至更细
- marginal kernel-level 提升就会变成巨大的成本节约
- 某些 operator 如果在目标加速器上没有 kernel,就会直接阻塞模型上线
这意味着 kernel 不再只是“底层实现细节”,而是:
- 性能问题
- 成本问题
- 架构可部署性问题
- 新硬件可编程性问题
这也是这篇文章和很多学术 benchmark 文章最大的差别:它不是在证明“AI 会不会写 kernel”,而是在证明“AI 能不能替代一部分现实工业 kernel 工程流水线”。
作者提出的“维度灾难”是这篇文章的核心问题定义
文章把这个问题概括成三重多样性带来的 curse of dimensionality:
1. 硬件异构
不同平台有不同 memory hierarchy、不同编程抽象、不同代际特性。
例如:
- NVIDIA 有 CUDA、Tensor Core、TMA、warp-group 等
- AMD 有 ROCm/HIP、Infinity Cache 等
- MTIA 有自己的 C++ kernel DSL、SRAM / PE / function unit 特性
2. 模型异构
Meta 的推荐模型不是一种模式,有 retrieval、early-stage ranking、late-stage ranking,还有 transformer-based sequence models、embedding-heavy 模型等。
3. kernel 异构
不仅有 GEMM,还有大量:
- 数据预处理
- feature transform
- sparse normalization
- hash / bucketize / truncate
- operator fusion 场景
这三维一组合,就不是“写几个高性能 kernel”能解决的问题,而是一个组合爆炸的系统问题。
“新硬件会放大编程鸿沟”

图 1 展示的是 MTIA,从数据中心、机架、板卡到芯片核心多层次展示。
这张图的作用不是技术细节,而是一个强烈信号:
- Meta 不只是用现成 GPU
- 它有自己的 AI 加速器
- 新硬件一出来,kernel coverage 和 programmability 就成了第一道门槛
这意味着,如果没有自动 kernel generation / optimization 系统,新硬件的可用性会严重受限。文章后面不断强调这一点:KernelEvolve 不只是做性能优化,也是在降低新硬件的编程门槛。
“业务约束”
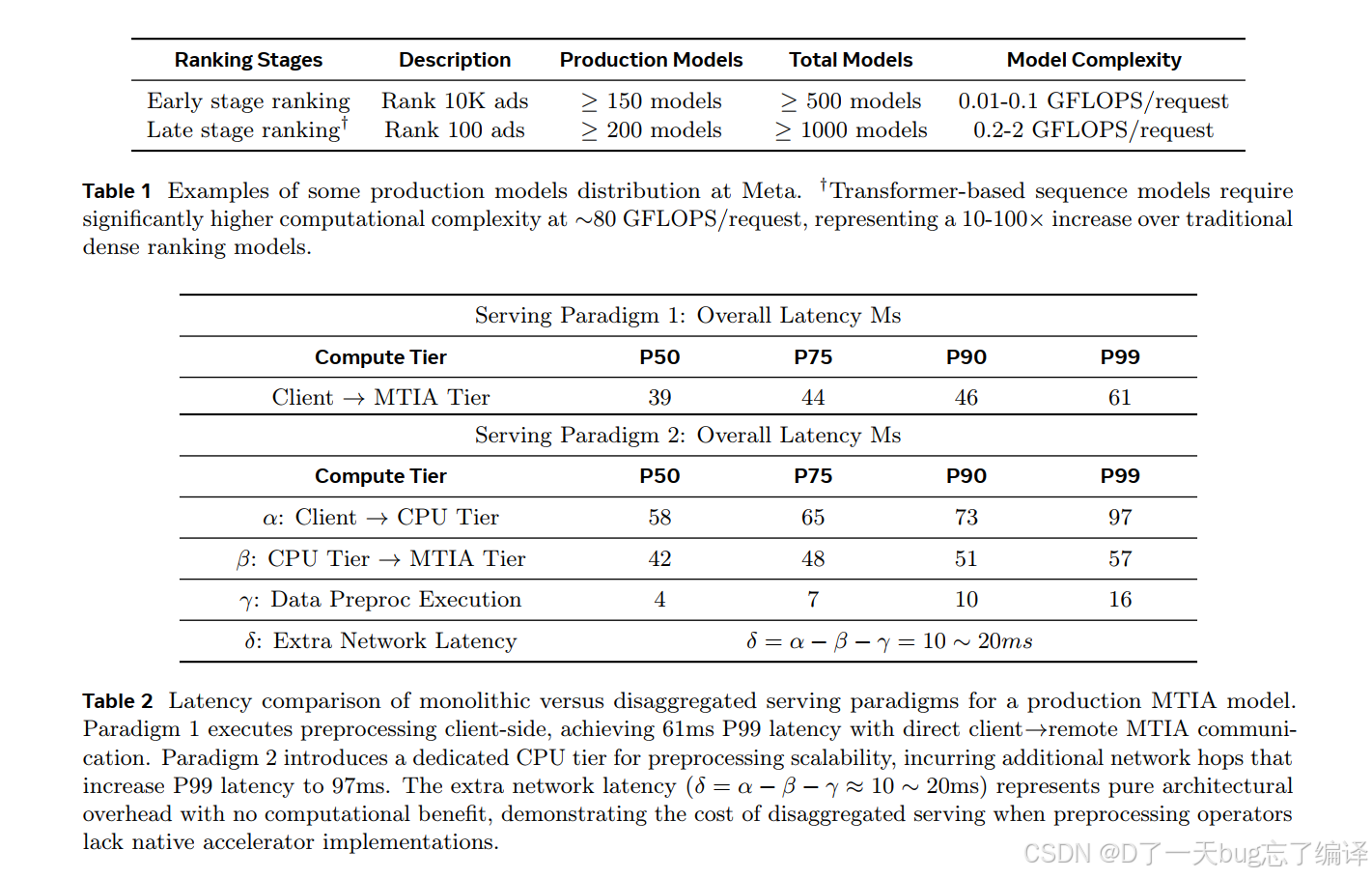
Table 1 讲的是生产模型分布。
作者把不同 ranking stage 的模型复杂度列出来,说明:
- early stage 和 late stage 的算子需求不一样
- transformer-based sequence models 会把每次请求算力拉高 10 到 100 倍
这张表帮助你理解:为什么 kernel optimization 不能只有单一策略。
Table 2 比较了 monolithic serving 和 disaggregated serving 的延迟。
作者指出:如果某些预处理算子在 MTIA 上没有原生 kernel,就不得不:
- 在 CPU tier 上做预处理
- 再把结果发到 MTIA tier
结果就是额外多出 10 到 20ms 的纯网络架构开销,P99 latency 从 61ms 拉到 97ms。
kernel coverage 不只是“少一个优化点”,而是会改变整个 serving architecture,并且产生很贵的延迟代价。
Triton 多目标编译架构
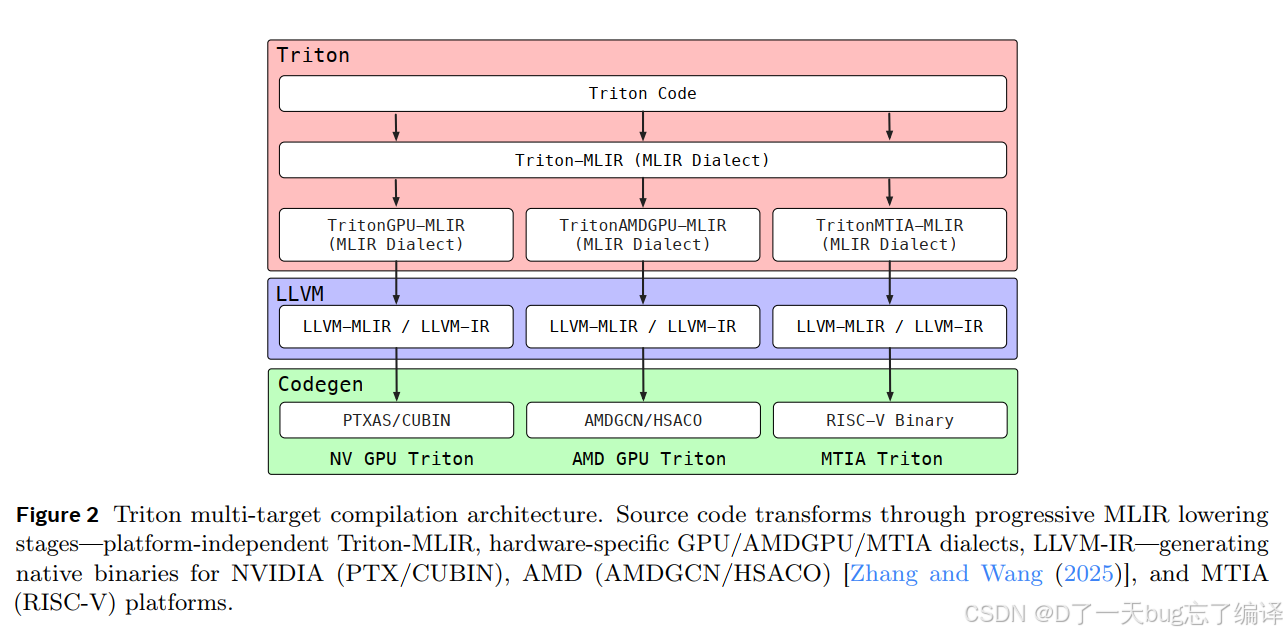
图 2 画出了 Triton 的 multi-target compilation 路线:
- Triton code
- Triton-MLIR
- 再到不同平台的 GPU / AMDGPU / MTIA dialect
- 再 lower 到 LLVM / PTX / AMDGCN / RISC-V 等
这张图的重要性在于,它解释了为什么作者选择 Triton 作为核心编程抽象。
原因不是 Triton 已经完美支持所有平台,而是:
- 它有相对统一的高层表达
- 又有往不同后端延伸的空间
这让 KernelEvolve 可以在统一框架下,同时面向 NVIDIA、AMD 和 MTIA 做代码生成与优化。
但作者也没有掩盖现实:不同平台最终还是需要不同硬件知识和不同 lower-level 技巧,光靠“写一份 Triton 到处跑”是远远不够的。
为什么强调 Triton 在 Meta 内部“超越 CUDA”
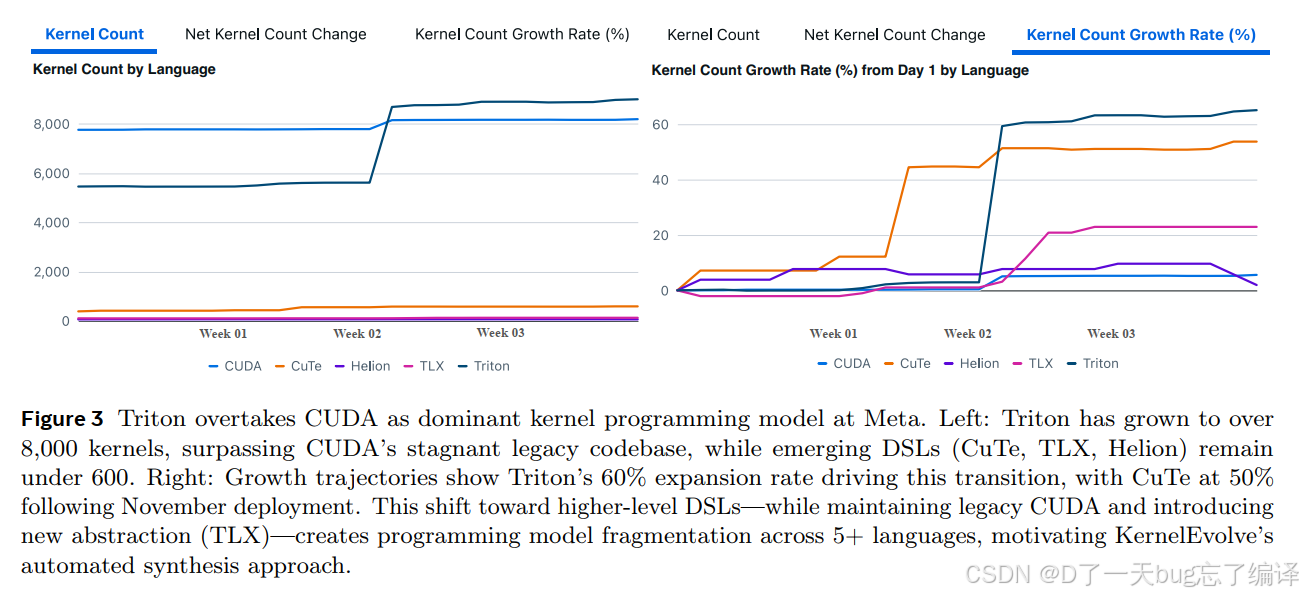
Figure 3 左图:
- Triton kernel 数量已经超过 8000;
- 超过 CUDA 的 legacy codebase。
右图:
- Triton 增长率约 60%;
- CuTe 约 50%;
- 同时还存在 TLX、Helion 等新抽象。
它不是简单展示“Meta 很爱 Triton”,而是在证明两点:
(1)Triton 已经是现实中的主力目标
所以 KernelEvolve 选 Triton 不是学术偏好,而是组织现实。
(2)编程模型碎片化在加剧
虽然 Triton 变多了,但并不是“一统天下”:
- CUDA 还在;
- CuTe 在增;
- TLX 在引入;
- 还有别的 DSL。
所以作者的结论是:
正因为语言/DSL 越来越多,才更需要自动 synthesis 系统。
这和一般人的直觉相反。很多人会觉得“有统一 DSL 就够了”,但作者这里的论点是:
- 高层 DSL 带来 portability;
- 但新 DSL 和新硬件特性又不断出现;
- 所以人工维护仍然不可持续。
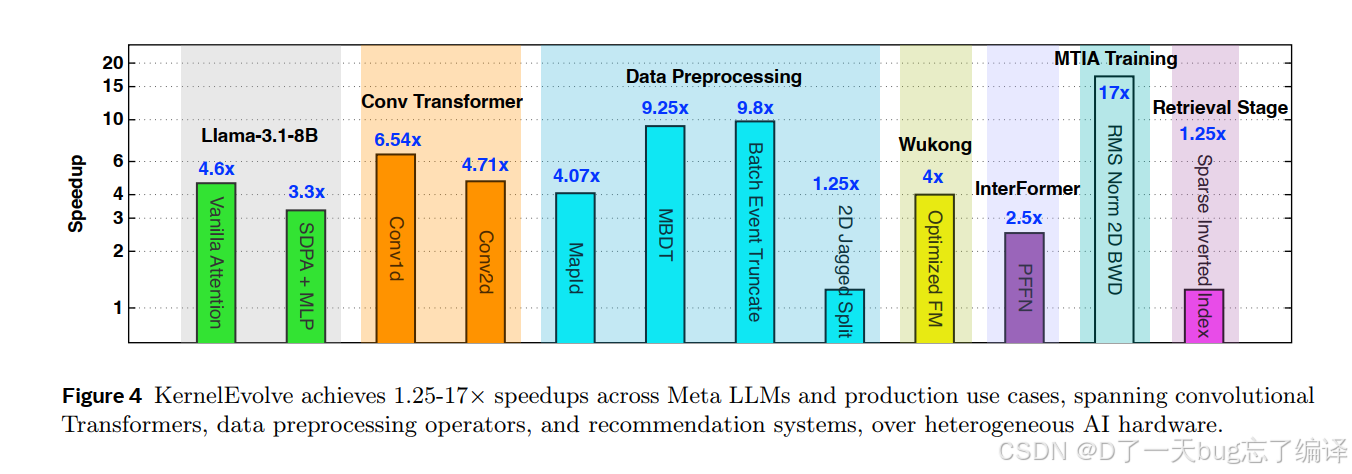
Figure 4 给了多个 workload 的 speedup
它不是只挑一个最强结果,而是刻意覆盖多个类别:
- LLM inference
- conv transformer
- data preprocessing
- recommendation fusion
- MTIA-specific training
- retrieval stage。
这说明作者想证明的不是“某个 kernel 优化得很好”,而是:
KernelEvolve 对多种工作负载、不同算子类别、不同硬件都有效。
换句话说,Figure 4 是“广泛性证据”,不是“单点英雄结果”。
作者特意把 memory-bound preprocessing 和 compute-bound fusion 放在一起展示。
这再次呼应全文主线:
生产级部署
表面是:
- 第一个 industrial-scale production-grade AI kernel optimization system。
实质是:
- 不是 benchmark demo;
- 而是真正持续运行在 Meta 生产环境里;
- 支持 hundreds of models;
- 面向 billions of users。
开发效率 + 性能都要
表面是:
- 从 weeks 到 hours;
- speedup 1.2× 到 17×。
实质是:
- 作者想证明 agent 系统不只是“节省人力”,还可以达到甚至超过 baseline compiler-generated code。
第三条贡献:生产经验
这条其实也很重要:
- failure mode analysis;
- incorrect kernel debugging;
- performance validation;
- organizational integration patterns。
说明这篇文章不只是算法论文,也是一篇system deployment paper。
二、方法
核心定位
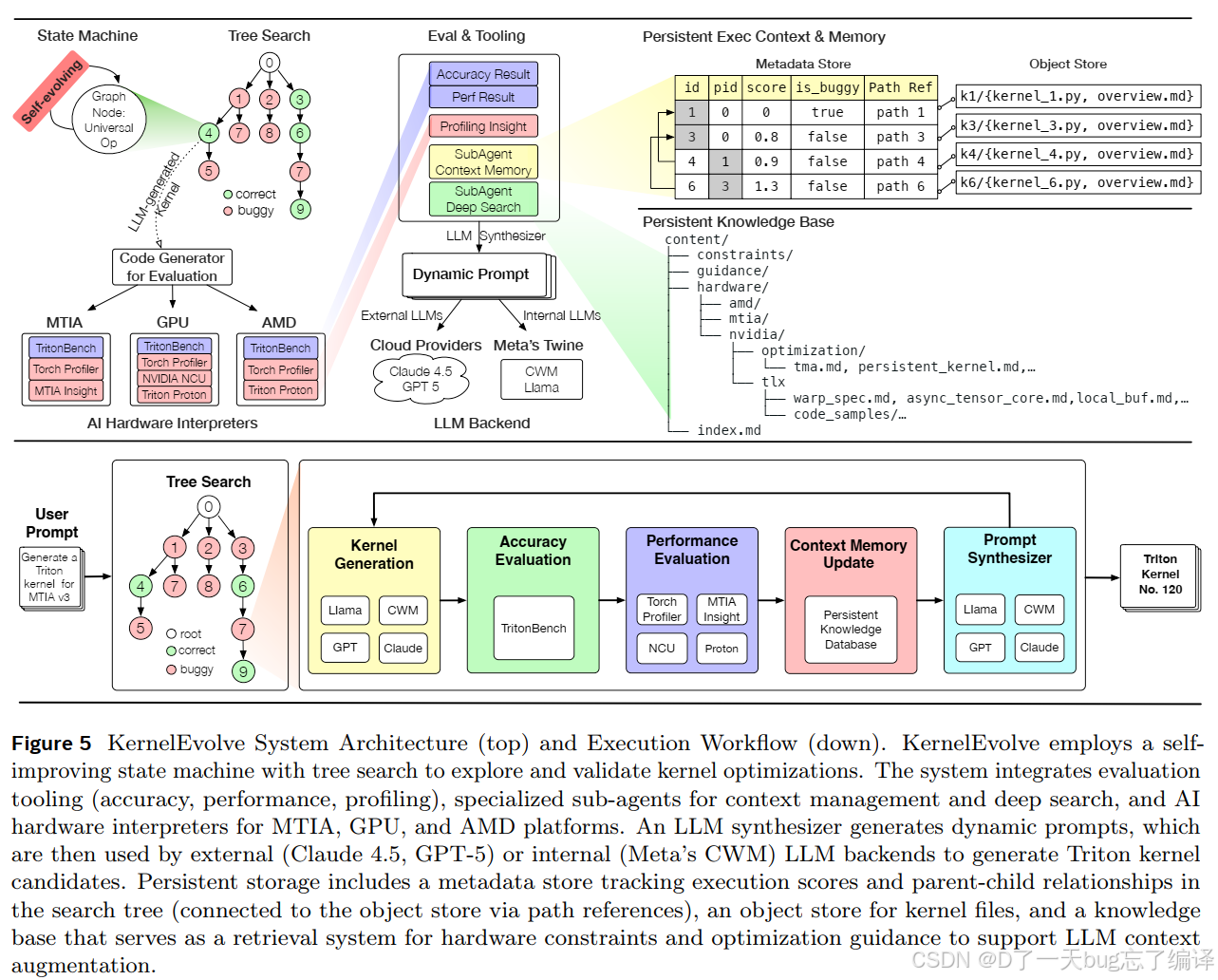
图 5 是整篇文章最重要的系统图。
这张图上半部分是系统架构,下半部分是执行工作流。
系统里有几块核心组件:
- tree search / state machine
- LLM synthesizer
- context memory sub-agent
- deep search sub-agent
- persistent knowledge base
- TritonBench / profiler / hardware interpreters
- metadata store / object store
树搜索
作者把 kernel optimization 看成图搜索问题。
每个节点代表一个 kernel 实现候选,每条边代表一次变换。系统每轮做三件事:
1. 选节点
根据 selection policy 选择值得继续扩展的 kernel 候选。
2. 变换
用 universal operator 生成新 kernel。
3. 打分
用 fitness function 根据 correctness + speedup 给候选打分。
fitness 很直接,就是:
- Triton kernel 相对 PyTorch baseline 的 speedup
- 如果 correctness 不过或运行失败,则记 0
这种 formulation 很自然,而且非常适合 kernel optimization 这种“空间巨大、反馈可量化”的问题。
universal operator
这篇文章有一个挺有意思的观点:很多多 agent / 多 operator 框架的问题,不是搜索不够聪明,而是 operator 设计太死。
传统做法常见的是:
- Draft operator
- Debug operator
- Improve operator
每个 operator 绑定固定 prompt 模板。
作者批评这种做法,因为 runtime context 在变:
- 有时是 correctness 问题
- 有时是 memory bottleneck
- 有时是 hardware-specific constraint
- 有时是 tiling / launch config 的问题
如果 operator prompt 是静态的,就会把模型的思考空间“框死”。
因此作者提出 single universal operator,通过 retrieval-augmented dynamic prompting 动态适配当前上下文。
这个设计很有道理。它本质上是在说:kernel optimization 不是几个固定意图类别,而是一个需要综合看 profiling、错误、硬件知识的连续推理过程。
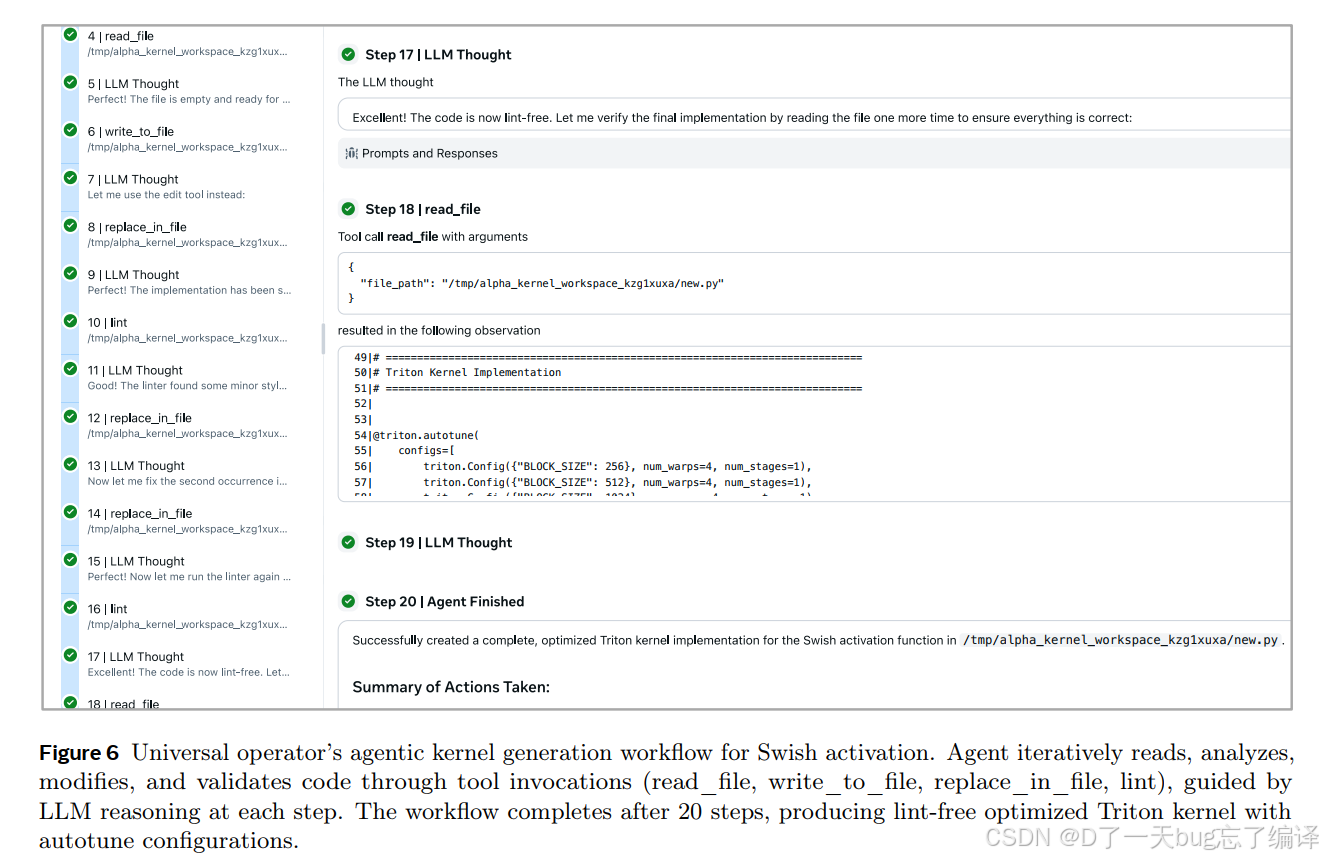
图 6 给了一个 swish activation kernel 的 agent 过程示意。
这个 agent 会反复:
- 读文件
- 写文件
- 替换代码
- 跑 lint
- 再继续修改
它看起来有点像代码 agent 的普通循环,但放在这篇文章里意义不同:它强调 KernelEvolve 不是“prompt 一次,生成一个版本”,而是持续以工具反馈为中心地修改 kernel。
也就是说,作者不是把 LLM 当成 code completion,而是当成“可以在工具环境里行动的 kernel engineer”。
检索和长期记忆
KernelEvolve 有两个很关键的子 agent:
- context memory sub-agent
- deep search sub-agent
再加上 persistent knowledge base。
其中 knowledge base 里放的是:
- 各硬件平台约束
- 优化指南
- code samples
- 硬件特定文档,比如 MTIA / NVIDIA / AMD 的技巧
这部分的重要性非常大。因为像 MTIA 这种 proprietary accelerator,本来就不在通用 LLM 训练语料里。KernelEvolve 能在 MTIA 上成功,很大程度上靠的不是模型“天然懂”,而是系统会动态检索并注入 MTIA-specific knowledge。
这一点是非常真实、也非常有价值的工程 insight。
统一评估框架
KernelEvolve 不只是能生成 kernel,还把评估自动化做得非常完整。
它包含:
- TritonBench correctness validation
- speedup 测量
- Torch Profiler 系统级 profiling
- Triton Proton、NCU、MTIA Insight 等硬件特定 profiler
- MPP(Multi-Pass Profiler)做 cross-stack 指标统一
- FaaS 化远程 evaluation
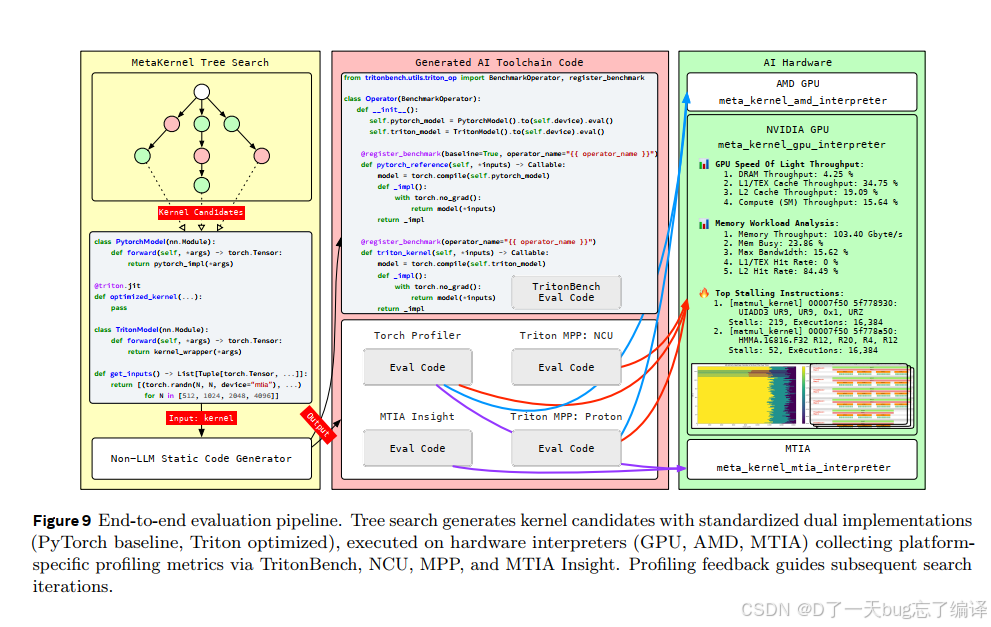
图 9:evaluation pipeline 展示的是“自动化实验工厂”,不是简单 benchmark 脚本
图 9 描述了 end-to-end evaluation pipeline。
作者把 tree search 生成的 kernel candidate,变成带标准接口的 artifact,再自动:
- 生成 evaluation harness
- 在不同平台 interpreter 环境中运行
- 收集 correctness、latency、speedup、profiling metrics
这张图的意义在于,它解释了为什么 KernelEvolve 能在多个平台上大规模跑,而不是停留在“人工拿几个 kernel 做 demo”。
这也是工业系统和学术原型的差别之一:你必须有批量、自动、可重复的评估流水线。
三、实验
FaaS 设计
作者甚至把 kernel evaluation 放到了 Meta 的 FaaS 平台上:
- generation 在 CPU 侧做
- evaluation 在远程 accelerator pool 上做
- 避免 GPU / MTIA 被生成阶段空占
- 支持弹性扩展
这个设计非常合理,也说明 KernelEvolve 真的是为了“在 Meta 内部规模化跑起来”而设计的,不是只为单机实验室环境服务。
OSS operator evaluation:100% correctness
在公开 ATen operator 评测里,作者选了 160 个 operator,覆盖:
- element-wise
- transcendental
- reductions
- activation
并在三个平台上生成 kernel:
- NVIDIA H100
- AMD MI350
- MTIA v3
总共 480 个 operator-platform 配置,作者报告:
- 100% correctness
另外,在 KernelBench 三个 level 上也达到了:
- 250 / 250 全通过
它说明:
- KernelEvolve 的 end-to-end correctness pipeline 确实做得非常稳
但也要注意:
- 这些 correctness 指标主要是数值正确和 benchmark 通过,不是形式验证意义上的 correctness
- OSS operator 大多是基础 building blocks,主要证明“系统能稳定生成可用 kernel”
所以这组结果更像“系统工程稳定性非常强”的证据,而不是“性能极限已经全部突破”的证据。
树搜索轨迹说明执行反馈确实在起作用
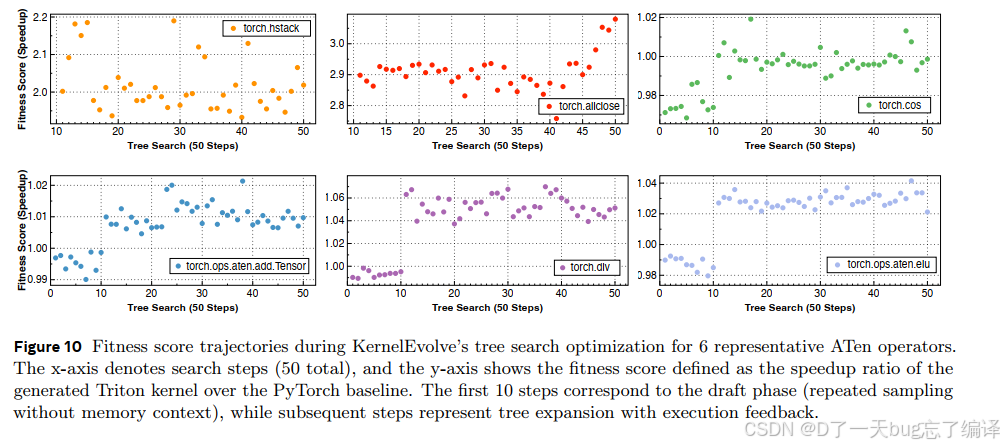
Figure 10 画了 6 个代表性 ATen operator 的 fitness trajectory。
有几个观察:
- draft phase(前 10 步)主要靠独立采样
- tree expansion phase(之后)开始利用 execution feedback
- 某些算子像 `torch.cos`,会从 2.8x 提升到 3.05x
- 某些算子如 `torch.div`、`torch.amax` 接近 1x,说明优化空间有限
这张图非常有意义,因为它说明 search 不是装饰。对于有优化空间的 operator,feedback-guided search 确实能继续往前推。
生产 monetization case study
作者自己也很清楚,真正能体现 KernelEvolve 价值的不是简单 operator,而是生产工作负载。
核心案例包括:
- Convolutional Transformer 的 conv1d
- Wukong 的 Optimized FM
- InterFormer 的 PFFN
- MTIA 上的数据预处理 kernel
- Batch Event Truncate 等 sequence learning operator
这些不是 textbook kernel,而是和 Meta 推荐业务强相关的 production operators。
Conv1d 案例
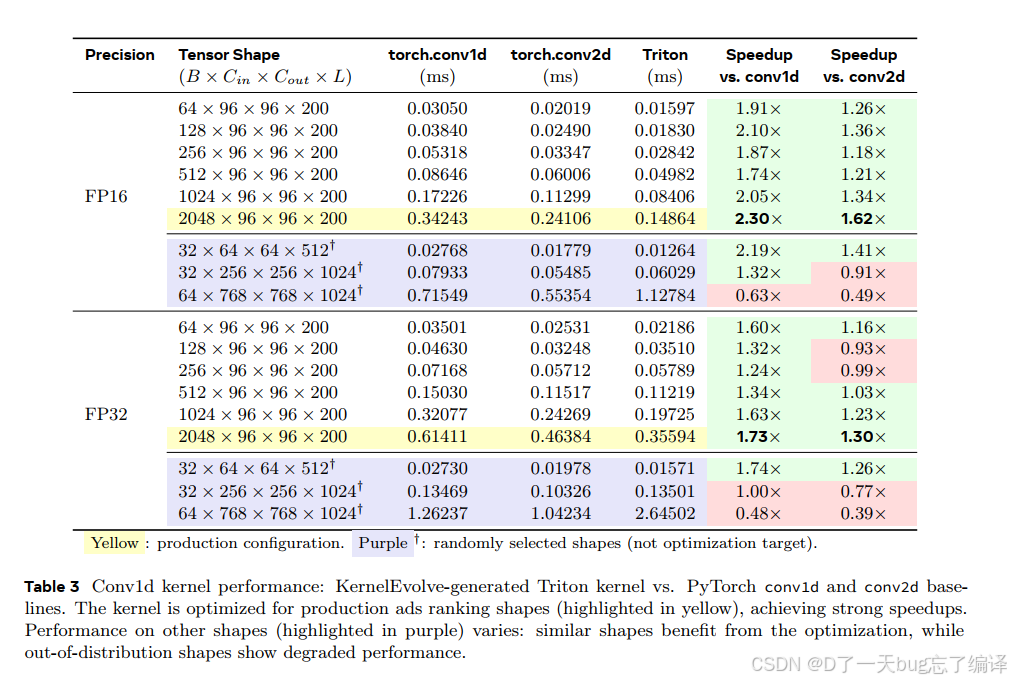
Conv1d 在 Convolutional Transformer 中是核心计算瓶颈。作者把 KernelEvolve 生成的 Triton kernel 跟两个 baseline 比:
- 原生 `torch.conv1d`
- 把 1D 重排成 2D 再走 `torch.conv2d` 的常见优化路径
Table 3 给出具体结果。对生产目标 shape `(2048, 96, 96, 200)`:
- FP16 下相对 `conv1d` 达到 2.30x
- 相对 `conv2d` workaround 达到 1.62x
而且在多种 batch size 上都稳定有收益。
这已经很强了,因为第二个 baseline 已经不是 naïve baseline,而是工程上常见的“借用成熟 conv2d 内核”的 workaround。
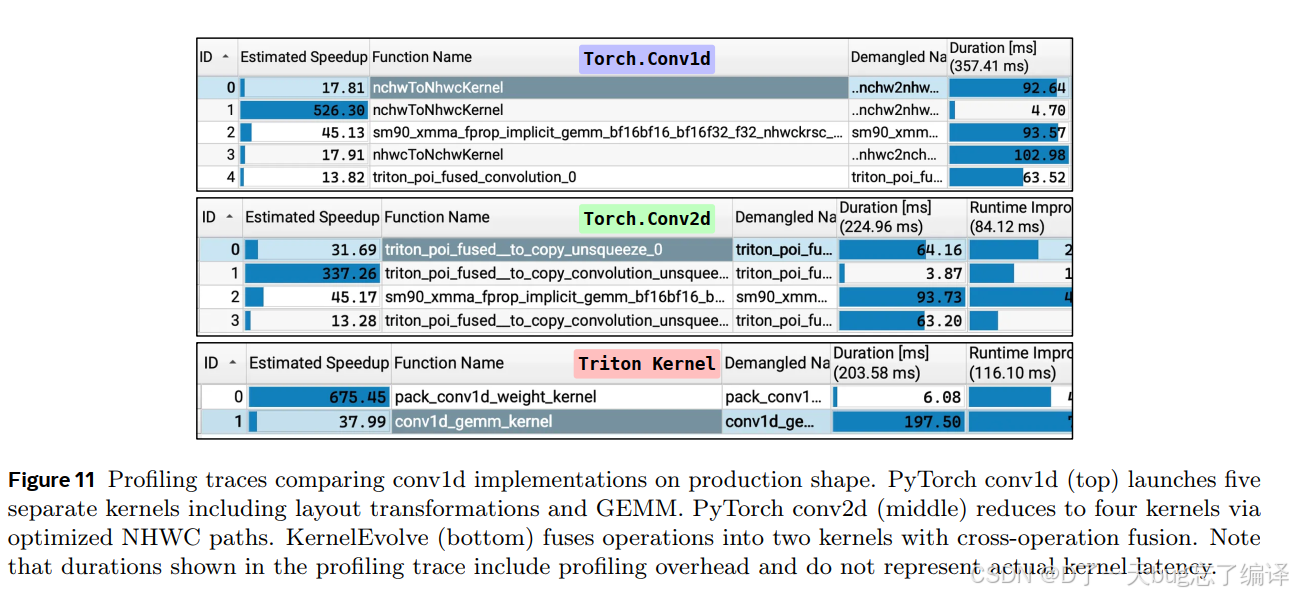
Figure 11 的 profiling trace 非常关键。
作者发现:
- PyTorch conv1d 版本会发 5 个 kernel
- conv2d workaround 也要发 4 个 kernel
- KernelEvolve 最终只保留 2 个 kernel:一个 weight packing,一个主 convolution
这说明速度提升的根本原因不是“某个 block size 调好了”,而是它自动发现并实现了 cross-operation fusion,避免了大量 layout conversion 和中间 memory traffic。
这类优化往往最值钱,也最难人工系统化规模复制。

Figure 12 画了 conv1d 在 300 个 search step 中的搜索树。
作者报告:
- 初始 draft 阶段 fitness 在 2000 左右
- 随着反馈积累,上升到 4000、5000
- 最后收敛到 6889
这张图最重要的含义不是绝对值,而是说明:
- 系统不是“一次生成就结束”
- 而是在较长搜索中不断逼近更优实现
对复杂 kernel,这种 inference-time scaling 的收益很明显。
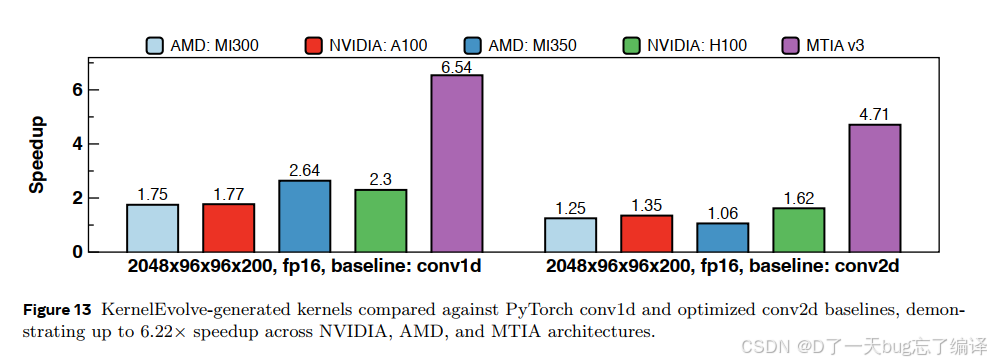
作者拿同一个 conv1d 生产形状,在五个平台上比较:
- AMD MI300
- NVIDIA A100
- AMD MI350
- NVIDIA H100
- MTIA v3
相对 `conv1d` baseline 的 speedup 分别达到:
- 1.75x
- 1.77x
- 2.54x
- 2.30x
- 6.54x
相对优化过的 `conv2d` baseline:
- NVIDIA 上还有 1.35x 到 1.62x
- AMD 上是 1.06x 到 1.25x
- MTIA 上是 4.71x
这组结果非常有说服力。尤其 MTIA 上收益最大,正好证明了文章的一个核心主张:
- 在成熟 vendor library 已经很强的平台上,AI agent 还能继续抠出一部分收益
- 在新型、库支持没那么成熟的 proprietary accelerator 上,agentic kernel synthesis 的价值会更大
Wukong 的 Optimized FM
Optimized FM 这个算子本质上是两个 batched matrix multiplication 串起来。
PyTorch baseline 会分两次做:
- 第一次算 `X^T Y`
- 中间结果写回 HBM
- 第二次再读回来算最终结果
KernelEvolve 发现了 fusion 机会,把中间结果尽量留在 SRAM / register,不做额外 HBM round-trip。
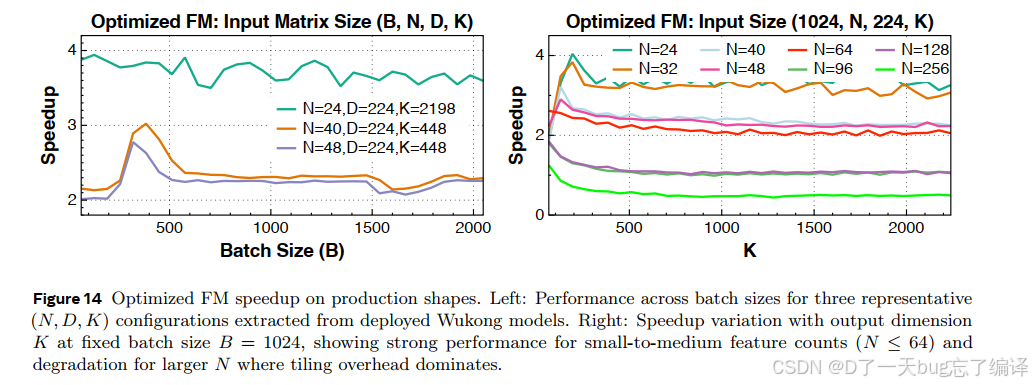
Figure 14 显示,在生产 shape 上能拿到:
- 大约 2x 到 4x 的 speedup,尤其在小到中等 feature count 下效果明显
这再次说明,KernelEvolve 的强项不是把单个 GEMM 再抠一点点,而是自动发现跨操作融合和 shape-specific tiling 机会。
InterFormer 的 PFFN
PFFN 的 operator chain 包括:
- FFN
- GELU
- RMSNorm
- another FFN / RMSNorm 组合
PyTorch baseline 虽然也有一定 fusion,但仍然会产生多次 memory pass。
KernelEvolve 生成的 kernel 进一步把:
- matrix multiplication
- bias
- GELU
- RMSNorm
尽量压到单 pass / 更少 pass 里做,数据在 SRAM 内尽量复用。
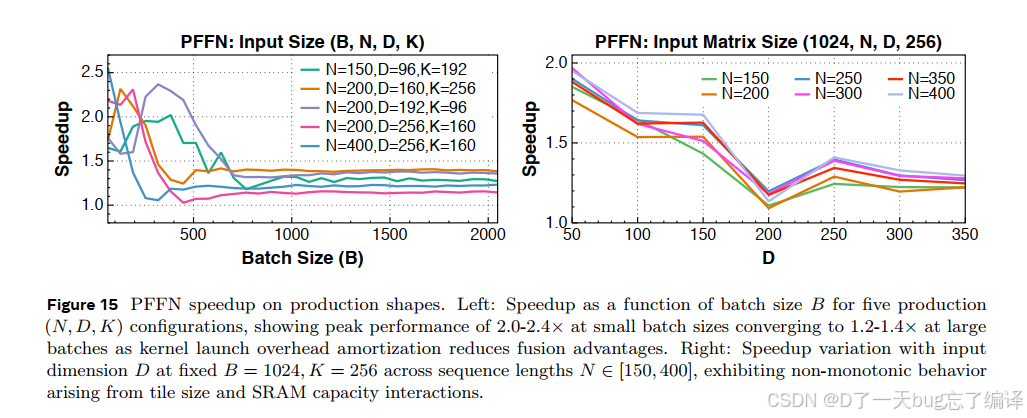
Figure 15 显示:
- 在生产配置上大约能达到 1.2x 到 2.6x 的 speedup
这类收益虽然没有 MTIA conv1d 那么夸张,但对生产 serving 来说已经非常可观。
MTIA 上的数据预处理 kernel
文章还评估了像:
- MapId Transform
- MergeBucketizedDense Transform
- Batch Event Truncate
这类数据预处理算子。
这部分的重要性甚至不亚于大算子加速,因为文章前面已经说过:
- 如果这些 preprocessing kernel 在目标 accelerator 上缺失
- 整个模型就可能被迫拆成 CPU + accelerator 的 disaggregated serving
所以这些 kernel 的自动生成,本质上是在解决 deployment viability 问题,而不仅是性能问题。

作者在这一部分强调了一个很好的 insight:
- 随着新加速器出现,真正阻碍上线的往往不是 GEMM,而是长尾 operator coverage
- KernelEvolve 的价值之一,就是快速补齐这些长尾 kernel
总体结论
KernelEvolve 是一篇非常强的工业系统论文。它最重要的贡献,不是某个单点优化技巧,而是把 agentic kernel coding 从“在 benchmark 上写几个算子”推进到了“在真实异构 AI 基础设施上规模化生成、评估、优化和部署 kernel”。图 5 展示的 tree search + universal operator + retrieval + profiling + persistent memory 框架,是这篇文章的核心;图 11 到图 15 给出的生产案例,则证明这套系统不是纸上谈兵。
从结果上看,100% 的 OSS correctness、KernelBench 全通过、以及在生产 workload 上 1.2x 到 17x 的 speedup,已经足以说明这不是普通的 prompt 工程,而是一整套成熟的 optimization machinery。尤其在 MTIA 这样的 proprietary accelerator 上,KernelEvolve 展示了最有价值的一点:它不仅能做性能优化,还能弥补新硬件最痛的 programmability gap。
如果一定要挑问题,那就是这套系统过于复杂、强依赖内部基础设施、外界不易完整复现;同时它的 correctness 仍然主要是数值和 benchmark 意义上的,而不是强形式保证。但即便如此,这篇文章依然非常值得重视。它已经不只是“AI 会不会写 kernel”的答案,而是在认真回答“AI 能不能成为大规模异构 AI 系统里的 kernel engineer”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)