RAG技术学习记录(一)
RAG简介
RAG(Retrieval Augmented Generation)为生成式模型提供了与外部世界互动的一个很有前景的解决方案。主要作用类似于搜索引擎,找到用户提问最相关的知识或者是相关的对话历史,并结合原始提问(查询),创造信息丰富的prompt,指导模型生成准确输出。其本质上应用了In-Context Learning的原理
RAG(检索增强生成)= 检索技术 + LLM(大语言模型)提示
LLM本身的局限性:
•知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备
•幻觉问题hallucination:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识
•数据安全性:对于企业来说数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍
RAG的特点:
•依赖LLM来强化信息检索和输出:RAG需要结合LLM来进行信息的检索和生成,但如果单独使用RAG,它的能力会受到限制。也就是说,RAG需要依赖强大的语言模型支持,才能更有效地生成和提供信息
•能与外部数据有效集成:RAG能够很好地接入和利用外部数据库的数据资源。这一特性弥补了通用大模型在某些垂直或专业领域的知识不足或者数据时效问题,比如行业特定的术语和深度知识,能提供更精确的答案
•数据隐私和安全保障:通常RAG所连接的私有数据库不会参与到大模型的数据集中训练。因此,RAG既能提升模型的输出表现,又能有效地保护这些私有数据的隐私性和安全性,不会将敏感信息暴露给大模型的训练过程
•表现效果因多方面因素而异:RAG的效果受多个因素影响,比如所使用的语言模型的性能、输入数据的质量、算法以及检索系统的设计等。这意味着不同的RAG系统之间效果差异较大,不能一概而论
RAG流程与分类
大概流程就可以分为这几个: 首先是提前准备好的,知识文档的准备,然后是Embedding模型的构建或者选择,然后是构建vector DB,也就是向量数据库, 然后是Retrieval 和 Generation,也就是查询检索和生成回答。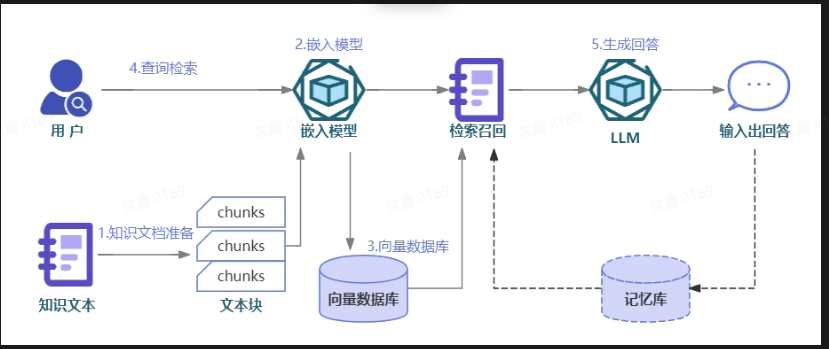
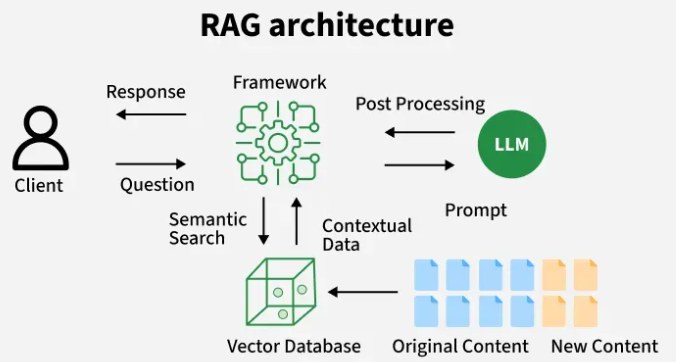
•知识文档的准备:在构建一个高效的RAG系统时,首要步骤是准备知识文档。现实场景中,我们面对的知识源可能包括多种格式,如Word文档、TXT文件、CSV数据表、Excel表格,甚至是PDF文件、图片和视频等。因此,第一步需要使用专门的文档加载器(例如PDF提取器)或多模态模型(如OCR技术),将这些丰富的知识源转换为大语言模型可理解的纯文本数据。例如,处理PDF文件时,可以利用PDF提取器抽取文本内容;对于图片和视频,OCR技术能够识别并转换其中的文字信息。此外,鉴于文档可能存在过长的问题,我们还需执行一项关键步骤:文档切片。我们需要将长篇文档分割成多个文本块,以便更高效地处理和检索信息。这不仅有助于减轻模型的负担,还能提高信息检索的准确性
•Embedding模型:核心任务是将文本转换为向量形式,的日常语言中充满歧义和对表达词意无用的助词,而向量表示则更加密集、精确,能够捕捉到句子的上下文关系和核心含义,来识别语义上相似的句子。Word2Vec,BERT,GPT系列,BGE系列等等Embedding模型
•向量数据库:专门设计用于存储和检索向量数据的数据库系统。在RAG系统中,通过嵌入模型生成的所有向量都会被存储在这样的数据库中。这种数据库优化了处理和存储大规模向量数据的效率,使得在面对海量知识向量时,我们能够迅速检索出与用户查询最相关的信息
•查询检索:用户的问题会被输入到嵌入模型中进行向量化处理。然后,系统会在向量数据库中搜索与该问题向量语义上相似的知识文本或历史对话记录并返回
•生成回答:将用户提问和上一步中检索到的信息结合,构建出一个提示模版,输入到大语言模型中,静待模型输出答案即可
RAG的分类或者说发展
从 Naive RAG 到 Advanced RAG、Modular RAG,再到 Agentic RAG
1. 先把一个根本问题说透:这四个词不是完全统一的“官方分级”
RAG 最初来自 2020 年的经典工作,它的核心思想是:把语言模型的参数化记忆和外部可检索的非参数化记忆结合起来,在推理时检索知识,再基于检索结果生成答案。之后,业界和学界逐渐把 RAG 的演化概括为 Naive → Advanced → Modular;而到了近两年,又进一步出现了 Agentic RAG 这一类强调规划、反思、工具调用与动态控制流的系统。需要注意的是,这四个名字更接近一种工程范式演化图谱,而不是严格统一、边界毫无争议的教科书定义。不同论文和框架对分类方式并不完全一致。
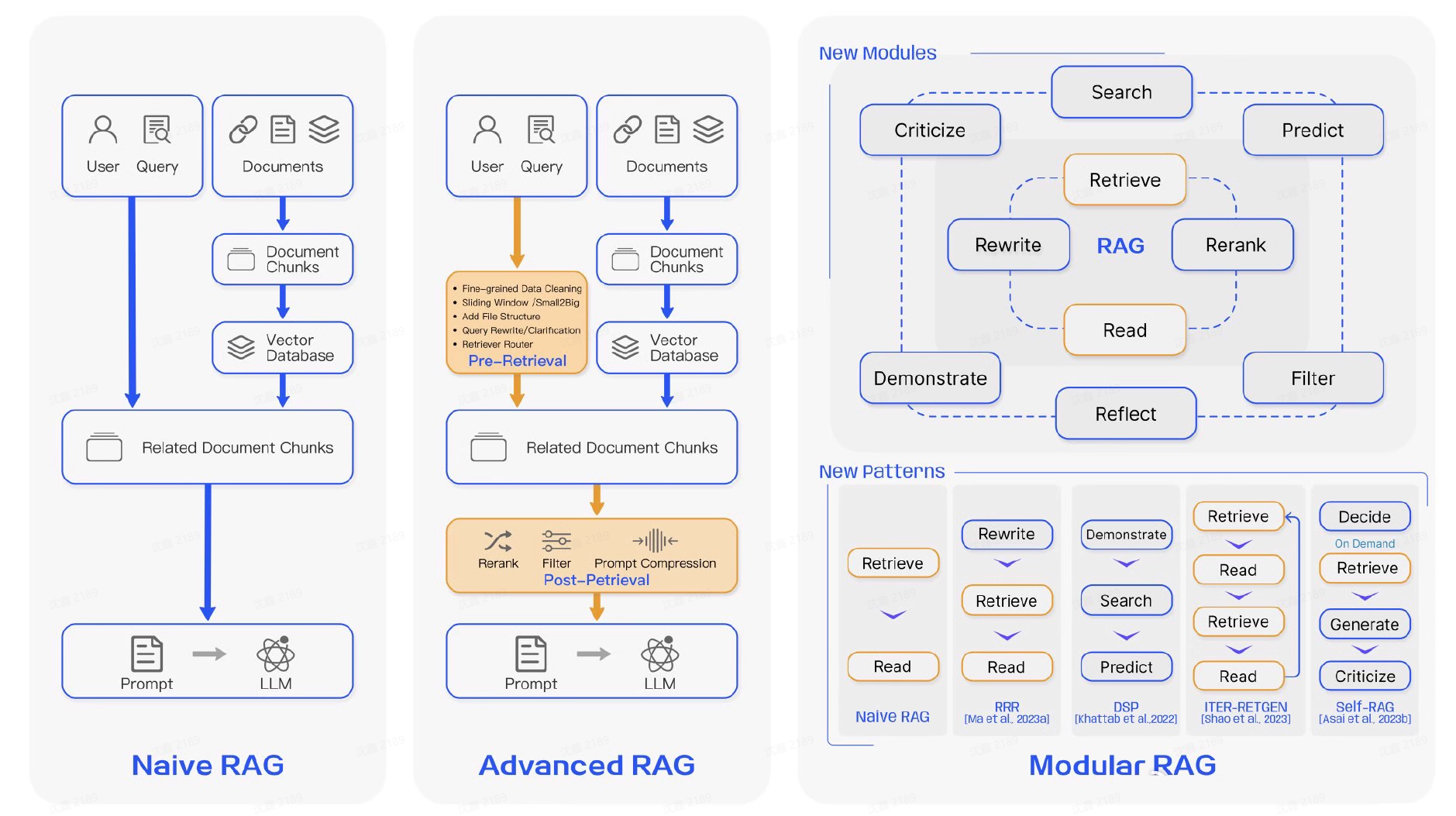
2. RAG 的基本骨架:无论怎么进化,底层仍然是这三段
RAG 系统无论如何复杂,底层都绕不开三个核心环节:retrieval(检索)、augmentation(上下文构造/增强)、generation(生成)。最早的 RAG 工作本质上是在生成前,从外部知识库中取回与问题相关的文档片段,把这些片段作为额外上下文交给生成模型;而后续各种改进,几乎都是围绕这三段去做增强:让检索更准、让上下文更干净、让生成更受控、让整个流程从静态单通路变成动态多通路。
3. Naive RAG:最原始、最直观、最容易搭起来的 retrieve-then-read pipeline
3.1 定义
Naive RAG 可以理解为最基础的 one-shot retrieve-then-generate 流程。它通常是一次性把用户 query 送进检索器,拿回 top-k 文档块,再把这些块直接拼进 prompt,让 LLM 一次性作答。2020 年原始 RAG 论文虽然在模型形式上比今天常见的工程版 RAG 更“学术”,但它奠定的核心思想就是这种“先取外部知识,再生成”的框架。后来的 survey 也把 Naive RAG 视为最早的、最基础的范式。
3.2 典型流程
Naive RAG 的标准流程通常是:
- 文档切分为 chunks
- 对 chunks 建索引
- 用户输入 query
- 用 query 检索 top-k chunks
- 将检索结果拼入 prompt
- LLM 直接生成答案
这就是最常见的 single-pass pipeline。它非常像一条固定流水线:输入问题,检索一次,生成一次,结束。
3.3 它为什么“naive”
“naive”不是贬义,而是说它有几个显著特征:
- 检索一次就结束,没有迭代修正
- 控制流静态,没有基于中间结果的动态决策
- 上下文拼接粗糙,常常是 top-k chunk 直接塞给模型
- 对检索错误高度敏感,一旦召回错了,生成就跟着歪
- 不区分问题复杂度,简单问题和复杂多跳问题都走同一条路径
这类限制正是后面 Advanced、Modular、Agentic RAG 产生的根源。
3.4 Naive RAG 的优点
Naive RAG 之所以长期存在,不是因为它先进,而是因为它有非常现实的优势:
- 架构最简单,开发成本低
- 易于 debug,问题定位清晰
- 延迟可控,适合很多 straightforward QA 场景
- 对中小规模知识库非常实用
它是几乎所有 RAG 系统的起点,也是很多“看起来很 fancy 的 RAG”骨子里的最小内核。这个基础不扎实,后面全是空中楼阁。
3.5 Naive RAG 的根本缺陷
Naive RAG 的致命问题,不是“不能用”,而是一旦任务复杂化,它的静态单跳结构会系统性失效:
- 问题本身需要拆解,但它不会拆
- 检索召回不全,但它不会补
- 返回文档很多噪声,但它不会筛
- 问题跨多个证据源,但它不会做证据整合
- 回答过程中发现证据不足,但它不会再搜
所以它对复杂、长文档、多跳、跨源、含歧义问题通常不稳。(arXiv)
4. Advanced RAG:不是推翻 RAG,而是把每个环节做“精修”
4.1 定义
Advanced RAG 可以理解为:保持 RAG 的基本串行主干不变,但在检索、索引、上下文构造、生成控制等局部环节上进行系统增强。 一篇广泛引用的 survey 明确把它视作对 Naive RAG 缺陷的回应;另一篇关于 reasoning/agentic RAG 的 survey 也指出,Advanced RAG 主要通过更强的检索精度、更细致的索引设计,以及多跳/重排等方法来补齐 Naive RAG 的短板。
4.2 它的本质
Advanced RAG 的核心不是“让系统会思考”,而是先把 retrieval quality 和 context quality 做对。它仍然大体上属于 pipeline 思维,但 pipeline 里的每一环不再粗糙。
一个很实用的理解是:
- Naive RAG:先搜,再答
- Advanced RAG:更聪明地搜,更干净地喂,更稳地答
4.3 Advanced RAG 常见增强点
4.3.1 Query 侧增强
用户原始问题通常不适合作为最优检索 query。于是会出现:
- query rewriting
- query expansion
- multi-query retrieval
- HyDE 一类的假设答案辅助检索
- 对复杂问题先做 decomposition,再分步检索
这些手段的目标是提升 recall 和 semantic alignment。(arXiv)
4.3.2 Retriever 侧增强
Naive RAG 往往只做一种检索;Advanced RAG 则经常使用:
- dense retrieval
- sparse + dense hybrid search
- metadata-aware retrieval
- domain-tuned retriever
- reranking / cross-encoder reranking
这里的重点是:召回和精排开始分层。先粗召回,再精排序,比“一步到位”更现实。(arXiv)
4.3.3 Indexing 侧增强
Naive RAG 的一个大坑是 chunking 过于机械。Advanced RAG 往往会引入:
- fine-grained chunking
- overlap 策略
- hierarchical chunking
- section-aware chunking
- metadata enrichment
- 摘要索引、标题索引、实体索引
也就是说,索引不再只是“把文本切成 500 字一段”,而是变成一套面向检索的知识组织工程。关于多粒度、分层检索,RAPTOR 是一个非常有代表性的例子:它通过递归地嵌入、聚类、摘要,构建出一个多层摘要树,在推理时从不同抽象层级检索信息。(arXiv)
4.3.4 Post-retrieval 侧增强
Advanced RAG 很强调 retrieved context ≠ final context。检索回来不代表可以直接喂给生成器,中间常常还要做:
- dedup
- context compression
- sentence selection
- evidence filtering
- relevance scoring
- conflict detection
CRAG 就体现了这种思路:它在检索结果和生成之间加入轻量级 evaluator,对检索质量进行评估;如果置信度低,还会触发扩展检索,例如 web search,并通过 decompose-then-recompose 机制提纯上下文。(arXiv)
4.3.5 Generation 侧增强
Advanced RAG 并不只盯着检索,也会管生成阶段,例如:
- 强制 citation
- answer groundedness checking
- hallucination control
- answer abstention(证据不足时拒答)
- multi-passage fusion
这说明 RAG 并不是“检索做好就结束”,而是检索质量 + 上下文质量 + 生成约束共同决定效果。
4.4 Advanced RAG 的代表性方向
严格说,很多论文的归类有交叉,但以下方向常被视为 Advanced RAG 的代表或过渡形态:
- RAPTOR:用树状摘要支持多粒度检索,解决长文档整体语义理解不足的问题。(arXiv)
- CRAG:对检索质量做校正,不盲信 top-k。(arXiv)
- Self-RAG:让模型在生成过程中决定是否需要检索,并对检索与生成进行自我反思。这个已经开始逼近 agentic 思路,但依然可以视为从 Advanced 向更动态 RAG 过渡的重要节点。(arXiv)
4.5 Advanced RAG 的局限
Advanced RAG 已经比 Naive RAG 强很多,但它通常仍然有一个问题:虽然模块更精细了,整体控制流依然相对固定。
也就是说,它解决的是“每个零件做得更好”,但未必解决“系统是否应该换一条路走”的问题。复杂任务往往不是一个更强 retriever 就能搞定,而是需要真正的动态决策、任务分解和多步执行。Advanced RAG 到这里就开始接近天花板。(arXiv)
5. Modular RAG:重点不再只是“优化零件”,而是把系统拆成可重组的模块图
5.1 定义
Modular RAG 的关键思想是:不把 RAG 当成一条固定流水线,而是把 indexing、retrieval、routing、compression、fusion、generation、verification 等拆成离散模块,再按任务需求重新拼装。 相关 survey 明确指出,Modular RAG 是对 Naive RAG 的重构:把原本端到端的检索-生成过程拆成可配置模块,以获得更强的结构灵活性。
5.2 它和 Advanced RAG 的真正区别
这是很多人最容易混淆的地方。
一个很锋利的区分方式是:
- Advanced RAG:主要在组件能力上升级
- Modular RAG:主要在系统拓扑上升级
也就是说,Advanced 更像“把发动机、变速箱、轮胎都换好的”;Modular 更像“整车从固定结构改成平台化架构,可按场景组装不同版本”。这是一个architecture-level shift。这一点可以从 survey 对“离散、可配置模块”和“重构/迭代模块设计”的强调中看出来。(arXiv)
5.3 Modular RAG 的结构特征
5.3.1 模块显式化
典型模块可能包括:
- document loaders
- chunkers
- embedding/index builders
- sparse retriever
- dense retriever
- graph retriever
- reranker
- router
- query planner
- context compressor
- summarizer
- answer generator
- verifier / critic
- citation formatter
在 Naive RAG 里,这些很多是“隐含在一起”的;在 Modular RAG 里,它们被显式抽出来,成为独立能力单元。
5.3.2 可替换性
不同领域、不同数据源、不同时延要求下,可以只替换某几个模块,而不重写整个系统。例如:
- 检索层从向量检索换成 hybrid retrieval
- 结构化数据接一个 SQL retriever
- 长文档场景加一个 hierarchical retriever
- 安全要求高的场景加一个 verifier
- 多源系统加一个 router 决定去哪种知识源搜
这种 plug-and-play 正是 Modular 的价值。(arXiv)
5.3.3 多路检索与多路融合
Modular RAG 很自然地支持并行或分层检索,例如同时走:
- vector store
- keyword engine
- graph store
- SQL / API
- web search
然后由 reranker 或 fusion 模块完成证据融合。此时 RAG 不再是“一个检索器 + 一个 prompt”,而是“一个 retrieval fabric”。这是走向复杂企业知识系统的必经之路。(arXiv)
5.3.4 支持不同知识结构
Modular RAG 的一个重要意义,是允许不同结构的知识表示共存:
- 平面 chunk
- 层次摘要树
- 知识图谱
- 表格/数据库
- API 工具返回结果
GraphRAG 是很典型的例子。微软把它定义为一种将文本抽取、网络分析、LLM 提示与摘要整合为端到端系统的图式 RAG,用于更丰富地理解文本数据集。它实际上代表了 Modular RAG 中一种很重要的分支:knowledge structure 从 flat chunks 走向 graph-structured retrieval。(Microsoft)
5.4 Modular RAG 的代表性形态
Modular RAG 不是单一算法,而是一种系统思想,因此代表例子也常常是“模块化体系”而不是“单篇论文”:
- RAPTOR:把长文档检索模块化为多层摘要树。(arXiv)
- GraphRAG:引入图结构知识组织与 query-focused summarization。(Microsoft)
- 带 router / reranker / verifier 的企业级 RAG:本质上也都属于 Modular RAG。(arXiv)
5.5 Modular RAG 的价值与局限
它的价值在于工程扩展性:
- 更适合生产系统
- 更适合多源异构知识
- 更适合 A/B 测试与模块替换
- 更适合 observability 与局部优化
但它仍然可能缺一个东西:自主决策能力。
模块很多,不代表系统就真的“聪明”。如果流程图仍然是写死的,那么它本质上只是一个更复杂的 deterministic workflow,而不是 agent。(arXiv)
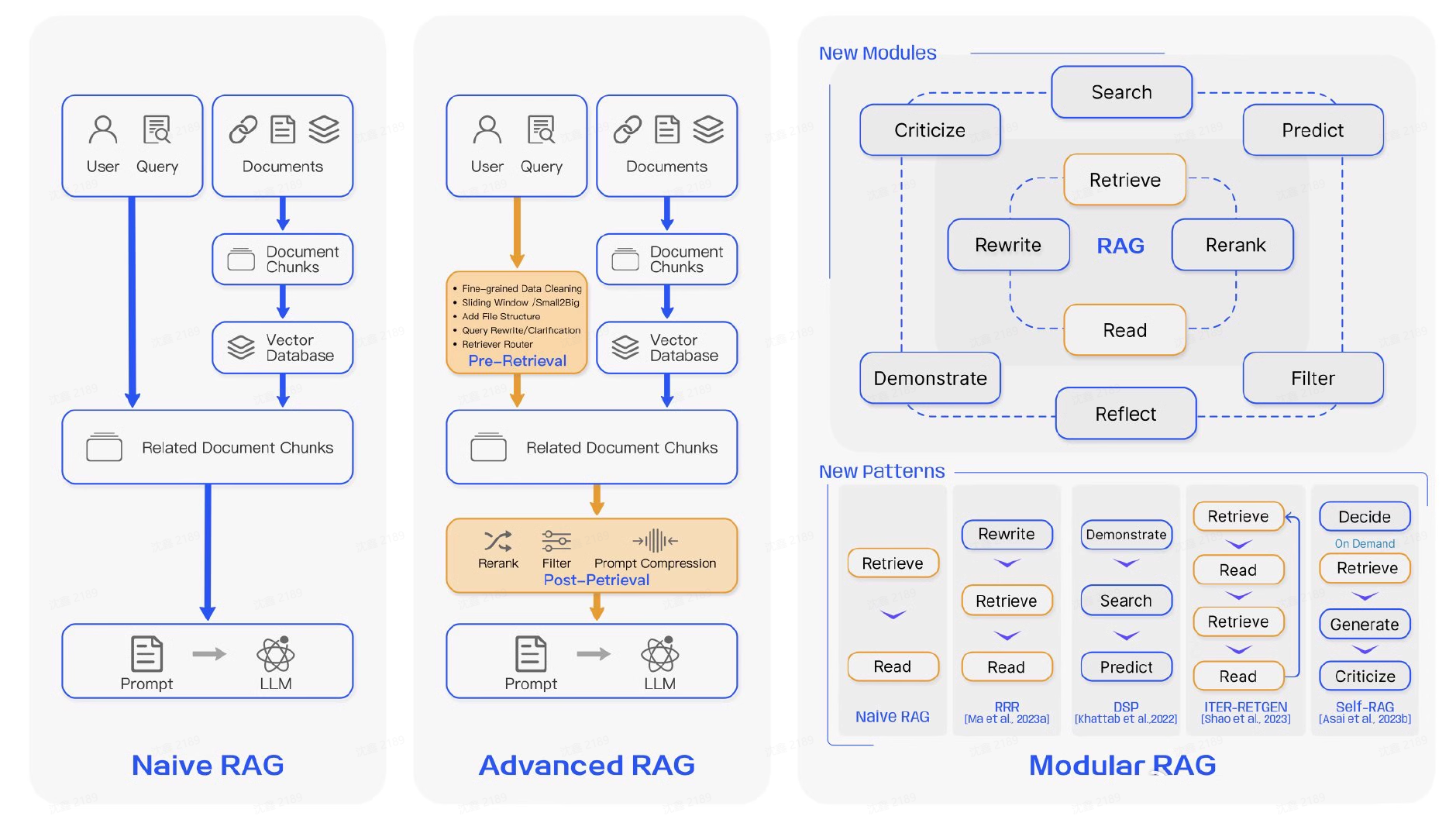
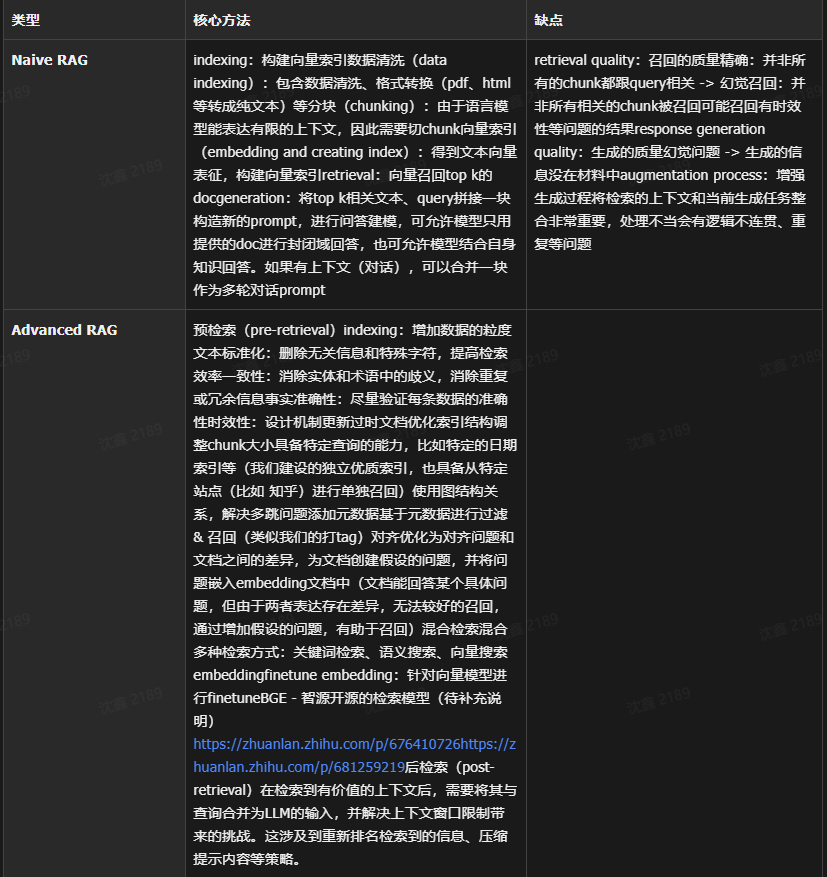
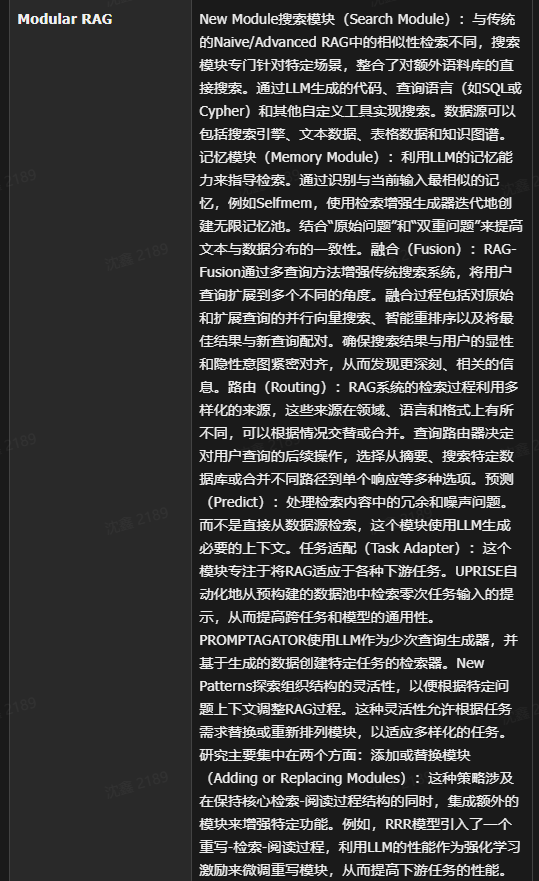

三个图展示三种模式范式的区别
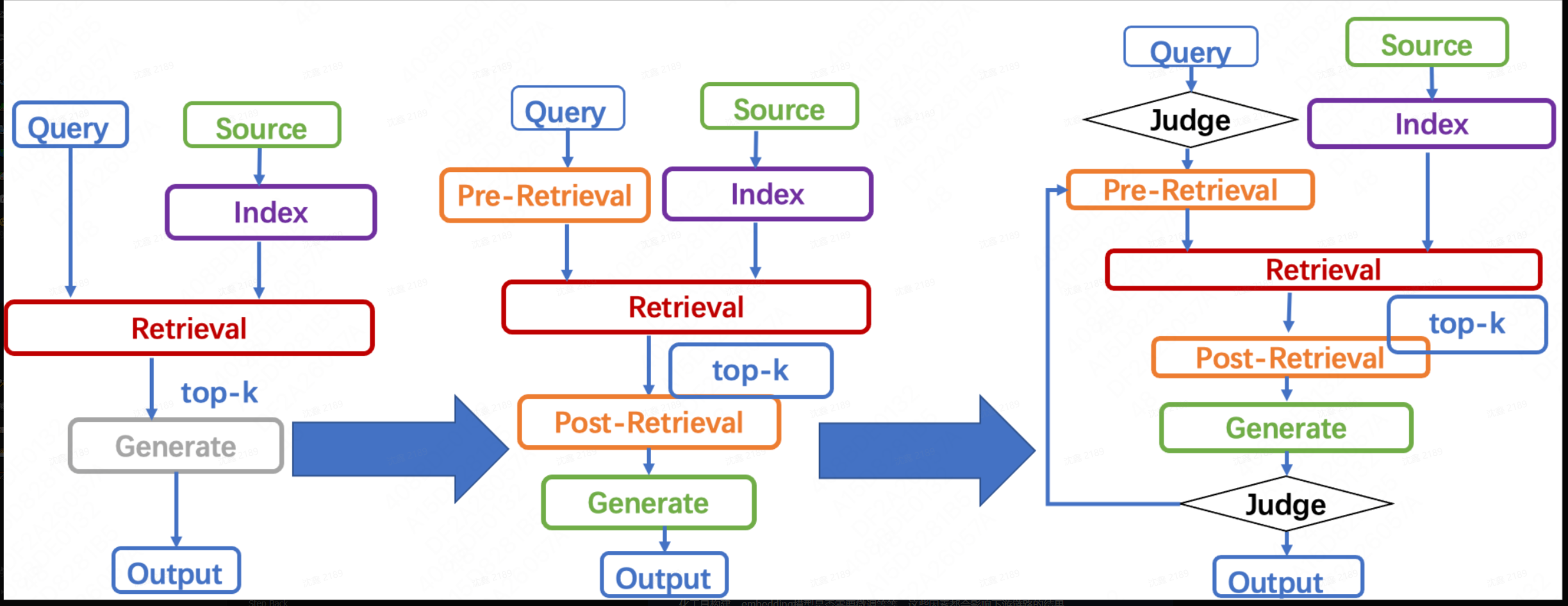

6. Agentic RAG:把“检索增强生成”推进到“可规划、可反思、可调用工具的动态认知流程”
6.1 定义
Agentic RAG 的核心不是简单地“在 RAG 里加一个 agent 壳子”,而是把 planning、reflection、tool use、memory、multi-step control 真正引入检索增强流程。相关 survey 将其定义为:在 RAG pipeline 中嵌入 autonomous agents,使系统能够动态管理检索策略、迭代修正上下文理解,并通过顺序式或协作式工作流自适应地完成复杂任务。(arXiv)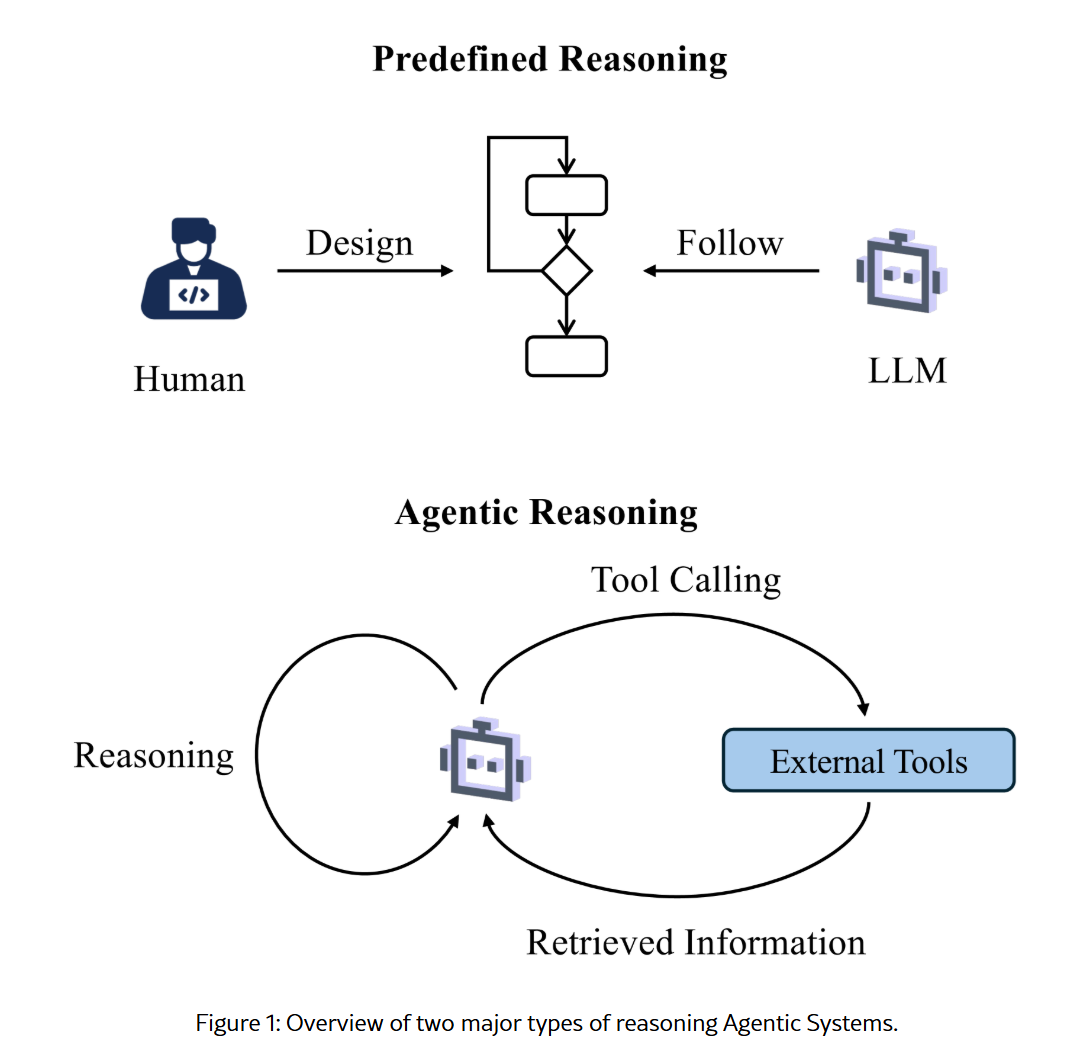
6.2 它为什么出现
传统 RAG 的根本问题,是它通常只回答一个问题:
“拿到 query 后,搜什么?”
Agentic RAG 则会继续追问:
- 这个问题到底需不需要检索?
- 需要一次搜完,还是多步搜?
- 该去哪个数据源搜?
- 检索结果够不够?
- 证据冲突了怎么办?
- 是否该调用别的工具,例如 SQL、API、web、代码执行器?
- 现在该回答,还是继续搜,还是先拆问题?
这就是 static pipeline → dynamic reasoning workflow 的本质跃迁。(arXiv)
6.3 Agentic RAG 的关键能力
6.3.1 Planning
Agent 不直接答,而是先形成 plan:
- 拆子问题
- 确定检索顺序
- 决定先查局部事实还是全局背景
- 决定何时停止
这使得多跳问题、开放问题、复杂分析问题的表现明显不同于固定 pipeline。(arXiv)
6.3.2 Reflection / Critique
系统不仅检索,还会检查:
- 检索结果是否相关
- 证据是否支持结论
- 当前回答是否缺关键证据
- 是否出现幻觉或证据冲突
Self-RAG 就把这种思想做得很典型:它训练一个模型按需检索,并通过 special reflection tokens 对检索内容和自己的生成进行反思与控制。(arXiv)
6.3.3 Tool Use
Agentic RAG 的检索对象不再只是向量库,还可能是:
- 搜索引擎
- SQL 数据库
- 知识图谱
- 企业 API
- 外部系统
- 代码/函数工具
LangChain 的文档里就明确区分了 RAG chain 和 RAG agent:后者把检索作为一个工具,由 agent 在运行时决定如何调用,而不是把检索写死在固定两步链路中。(LangChain文档)
6.3.4 Iterative Retrieval
Agentic RAG 强调 retrieve-think-retrieve-think-answer,而不是只检索一次。Active Retrieval/FLARE 就说明了这一类思路:系统在生成过程中主动决定什么时候再检索、检索什么,甚至利用对下一句内容的预测来组织未来检索。(arXiv)
6.3.5 Adaptive Routing
不同问题不该一刀切。Adaptive-RAG 的思路就是根据问题复杂度,动态选择从无检索、单步检索到更复杂策略中的最合适路径。这个思想非常 agentic:先判断,再决定执行哪条链路。(arXiv)
6.3.6 Multi-Agent Collaboration
更复杂的 Agentic RAG 还会让多个 agent 分工,例如:
- planner agent
- retriever agent
- verifier agent
- summarizer agent
- answer composer agent
这时系统已经不再是“一个模型 + 一个检索器”,而是小型认知工作流。相关 survey 也明确把 single-agent、multi-agent、graph-based frameworks 作为 Agentic RAG 的重要分类。(arXiv)
6.4 Agentic RAG 的代表性形态
6.4.1 Self-RAG
它让模型按需检索,并对检索和生成进行自我反思,已经明显不是传统固定式 RAG。(arXiv)
6.4.2 CRAG
虽然常被放在高级/鲁棒性增强 RAG 里,但它引入“评估检索质量→决定是否扩展检索”的条件逻辑,实际上已经具备 agentic 雏形。(arXiv)
6.4.3 FLARE / Active Retrieval
它强调在生成过程中主动决定何时检索、检索什么,属于典型的动态迭代检索。(arXiv)
6.4.4 Adaptive-RAG
它根据 query complexity 决定走哪种策略,是典型的 policy-based routing 思维。(arXiv)
6.4.5 Graph-augmented Agentic workflows
GraphRAG 本身不必然等于 agentic,但一旦图检索、局部/全局搜索、query-focused summarization、动态社区选择之类逻辑被 agent 调度,它就会成为 Agentic RAG 的重要组成部分。(Microsoft)
6.5 Agentic RAG 的价值
Agentic RAG 最强的地方是:它终于承认一件现实——复杂知识任务本质上不是“一次检索 + 一次生成”就能完成的。
它适合:
- 多跳问答
- 长文档综合分析
- 跨系统证据整合
- 需要工具调用的任务
- 动态知识环境
- 需要 verification 的高风险场景
这是 RAG 从“检索增强生成”走向“外部知识驱动的问题求解系统”的关键一步。(arXiv)
6.6 Agentic RAG 的代价
代价也非常真实:
- 延迟更高
- 系统复杂度暴涨
- 控制流更难 debug
- 评估更难
- 工具调用带来更多 failure mode
- 安全与 governance 问题更突出
换句话说,Agentic RAG 不是“天然更高级就一定更好”,而是“在复杂任务上更有上限,但成本更重”。(arXiv)
7. 四者的核心差异,一张表说透
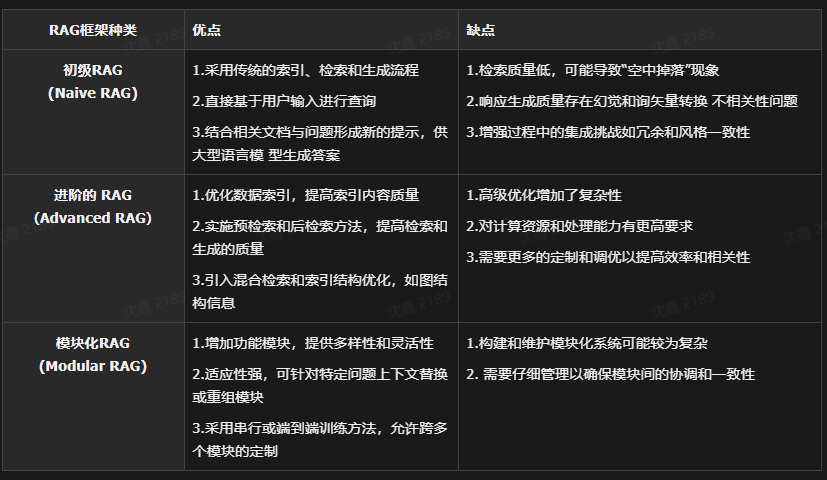
| 维度 | Naive RAG | Advanced RAG | Modular RAG | Agentic RAG |
|---|---|---|---|---|
| 核心思路 | 一次检索,一次生成 | 在各环节做精修 | 将系统拆成可重组模块 | 让系统动态规划、反思、调用工具 |
| 控制流 | 静态 | 基本静态,局部增强 | 可配置、可重组 | 动态、条件化、迭代式 |
| 检索次数 | 通常一次 | 一次或少量增强 | 视模块设计而定 | 往往多次、按需 |
| 系统重点 | 能跑通 | 提高精度与鲁棒性 | 提高架构灵活性 | 提高复杂任务求解能力 |
| 典型能力 | top-k 拼接 | rerank, rewrite, compression | router, graph, hybrid, verifier | planning, reflection, tool use |
| 适合任务 | 简单 FAQ、基础知识问答 | 企业知识问答、长文档问答 | 多源异构知识系统 | 多步推理、复杂分析、工具型任务 |
这一对比并不是官方标准表,而是对现有 survey、论文与框架实践的抽象总结。
8. 一个非常重要的认识:这四类不是完全互斥,而是“层层包裹”的关系
现实系统里,这四类往往不是非此即彼,而是递进叠加:
- 一个 Agentic RAG,几乎一定也是 Modular 的
- 一个好的 Modular RAG,通常也吸收了大量 Advanced 技术
- 几乎所有复杂 RAG,底层都还能看到 Naive RAG 的骨架
所以更准确地说,这不是四个平行物种,而是四层不断升级的系统观:
- Naive:先把 retrieve + generate 跑通
- Advanced:把检索质量、上下文质量、生成约束做好
- Modular:把系统拆成可重组能力模块
- Agentic:让系统具备动态决策与多步求解能力
这也是为什么很多论文很难被“唯一归类”。比如 Self-RAG、CRAG、Adaptive-RAG 这类方法,既可视为高级 RAG,也常被当作通向 agentic 的桥梁。(arXiv)
9. 如果只看技术演化主线,真正推动升级的不是“模型更大”,而是这四个方向
9.1 从 flat chunks 走向 structured knowledge
最早只是切块;后来出现层次树、图结构、多源检索。RAPTOR 和 GraphRAG 就是代表。(arXiv)
9.2 从 one-shot retrieval 走向 iterative retrieval
最早只搜一次;后来开始按需重复检索。Active Retrieval、FLARE、Adaptive-RAG 都体现了这一趋势。(arXiv)
9.3 从 retrieve-more 走向 retrieve-better
不是一味加 top-k,而是通过 rerank、compression、evaluation、correction 提高上下文纯度。CRAG 是典型例子。(arXiv)
9.4 从 pipeline 走向 cognition-like workflow
系统开始做规划、反思、路由、工具调用。此时 RAG 不再只是“外挂知识库”,而更像一个 knowledge-grounded problem-solving engine。(arXiv)
10. 最后给出一个简洁但锋利的结论
Naive RAG 解决的是“让模型别只靠参数记忆”;
Advanced RAG 解决的是“让检索和上下文质量真正可用”;
Modular RAG 解决的是“让系统架构适应复杂知识环境”;
Agentic RAG 解决的是“让系统在复杂任务中能够自主决定如何获取、验证和整合知识”。
关键 RAG 技术到底怎么做
1. Query Rewrite:先改写查询,再检索,而不是盲搜原始问题
1.1 它要解决的根问题
用户输入并不天然等于“最适合检索的查询”。自然语言问题常常带有省略、代词、上下文依赖、口语化表达,甚至把“回答任务”和“检索任务”混在一起。Query Rewrite 的核心思想,是先把原始输入改写成更适合 retriever 的形式,再进入检索阶段。EMNLP 2023 的 Rewrite-Retrieve-Read 明确提出把“rewrite”插在 retriever 前面,以弥合用户输入与检索需求之间的差距;HyDE 则提供了另一条路:不是直接重写 query,而是先让模型生成一个“假想文档/假想答案”,再把它编码后用于检索。(arXiv)
1.2 实际实现流程
工程上常见有两类实现。
第一类是 explicit rewrite:
把原始 query 送给一个 LLM 或小型 rewriter model,让它输出“检索版 query”。这个重写后的 query 通常会更显式地补足关键词、实体名、时间条件、问题意图,减少口语噪声。Rewrite-Retrieve-Read 的做法,就是先 prompt 一个 LLM 重写,再用重写版本去检索;进一步还可以训练一个更小的可学习 rewriter,让它专门适配固定的 retriever 和 reader。(arXiv)
第二类是 latent rewrite / hypothetical expansion:
HyDE 的做法不是输出一个“更好的搜索词”,而是让 LLM 先生成一段看起来像正确答案附近文档的“假设文档”,再对这段文档做 embedding,并在向量空间里检索相似真实文档。这样做的直觉是:真实问题往往很短、语义稀疏,而“假想文档”更接近目标文档分布,因此更容易把 dense retriever 拉到正确区域。(arXiv)
1.3 实践中通常怎么写 prompt
一个常见模板是把改写器限定成“只输出检索查询,不输出解释,不回答问题”,并明确要求:
- 补全缺失实体
- 保留用户真实意图
- 删除聊天噪声
- 保留时间、地点、版本等约束
- 输出适合 semantic search 或 hybrid search 的文本
另一种常见模板是 HyDE 风格:
“请写一段简短、事实性的段落,假设它来自一篇能回答该问题的文档。”
随后用这段文本去做 embedding 检索。这个方向直接来自 HyDE 的核心设计。(arXiv)
1.4 它的价值与代价
价值很直接:提高 recall,降低 query 表达噪声,缓解用户口语表达与文档书面表达之间的错位。 Rewrite-Retrieve-Read 和 HyDE 都表明,在知识密集型任务里,query 预处理本身就是重要杠杆。代价也很明确:多了一步模型调用;如果重写器“脑补过头”,就会把原问题改坏,导致 semantic drift。(arXiv)
1.5 什么时候最该上 query rewrite
它尤其适合以下场景:
- 用户输入口语化、上下文化
- 企业知识库里的写法和用户问法差距大
- 缩写、别名、内部术语多
- dense retrieval 对 query wording 很敏感
- 系统已经验证过“检索失败主要是 query 不好,而不是文档没有”
如果知识库本身就很小、问题形式高度标准化,rewrite 的收益会下降。(arXiv)
2. Rerank:先高召回,再精排序
2.1 它要解决的根问题
第一阶段 retrieval 的目标通常是“不要漏”,而不是“排得最准”。无论是 BM25 还是 dense retrieval,top-k 里经常混入噪声文档。Rerank 的作用,就是在候选集合已经缩小之后,用更贵但更准的模型做第二轮排序。BERT reranking 的经典工作就是这种思路:先用传统检索找候选,再对 query–passage 对逐个评分。(arXiv)
2.2 最典型的两段式架构
工程上几乎都是 two-stage retrieval:
- 第一阶段:用 BM25、dense retriever、hybrid retrieval 拉回 20~200 个候选
- 第二阶段:用 reranker 对这些候选重新打分
- 取新的 top-n 送给 LLM
BERT passage reranking 和后续 monoBERT / duoBERT 都建立在这种 multi-stage ranking 思想上。monoBERT 把排序看成点式分类,duoBERT 则引入 pairwise 视角,在候选之间做比较。(arXiv)
2.3 常见 reranker 类型
2.3.1 Cross-encoder reranker
这是最经典的一类。它把 query 和 candidate passage 一起输入同一个 Transformer,直接输出相关性分数。优点是交互充分,精度高;缺点是慢,因为每个候选都要和 query 做一次完整联合编码。BERT passage reranking 就是这一类的代表。(arXiv)
2.3.2 Pairwise / listwise reranker
monoBERT 是 pointwise,duoBERT 则更接近 pairwise:它不仅判断单个候选是否相关,还比较候选之间谁更应该排前面。这类方法排序质量通常更强,但成本也更高。(arXiv)
2.3.3 Late-interaction reranker / retriever
ColBERT 代表的是另一条路线:query 和 document 分别编码,但保留 token-level 细粒度交互,在最后用较便宜的相似度聚合。它比 cross-encoder 更高效,又比单向 embedding 更精细,因此经常被放在“强 retriever / 轻 reranker”之间的灰区。(arXiv)
2.4 实际系统里怎么接
最常见做法不是“让 reranker 对全库检索”,那样成本爆炸;而是:
- 先用 cheap retriever 拉回较大候选集
- 再用 expensive reranker 压缩到 3~10 个高质量 chunk
- 再做 context packing 或 compression
- 最后才送入生成器
也就是说,rerank 本质上是用算力买精度。这一点在信息检索里早就是常识,只是到了 RAG 时代变得更重要,因为 LLM 上下文窗口昂贵且“垃圾进垃圾出”。(arXiv)
2.5 典型失效点
rerank 不是万能药。它常见的失败方式包括:
- 候选集里根本没有正确文档,reranker 无法“凭空创造召回”
- 候选高度重复,rerank 只会把重复内容排得更靠前
- query 太模糊,reranker 也无法稳定对齐意图
- 成本过高,吞吐受限
所以系统设计里必须先问:问题到底在召回,还是在排序? 如果正确文档压根没进候选池,rerank 再强也没用。(arXiv)
3. Chunking:不是把文档切碎这么简单,而是在决定“知识最小可检索单元”
3.1 它要解决的根问题
RAG 之所以需要 chunking,不只是因为上下文窗口有限,也因为 embedding 和检索通常依赖一个相对稳定、粒度合适的文本单元。另一方面,长上下文并不自动等于模型能有效利用全部信息。Lost in the Middle 说明,长上下文模型对位于中间的关键信息往往利用不足,相关信息放在开头或结尾通常更容易被利用。也就是说,chunking 本质上在解决两个问题:检索单元设计 和 给生成器的上下文可用性。(arXiv)
3.2 最传统的做法:fixed-size chunking
最基础方案是按 token/字符长度固定切块,再加 overlap。这种方法实现简单、吞吐稳定、容易并行,但最大的问题是它不懂语义边界:一个定义可能被切成两半,一个表格说明可能被切断,一个论证链条可能被拆碎。很多对 chunking 的后续改良,都是在修 fixed-size 这个原罪。(arXiv)
3.3 结构感知 / 语义感知 chunking
这类方法尝试沿着自然边界切,例如:
- 段落
- 标题层级
- 章节
- 句群
- 语义主题变化点
本质是让 chunk 更接近“完整思想单元”。如果文档天然结构清晰,例如技术文档、论文、规章、SOP,这种方法通常比纯固定长度更稳。(arXiv)
3.4 Contextual retrieval / contextual chunking
Anthropic 提出的 Contextual Retrieval 进一步指出,很多 chunk 单独看语义是不完整的,因为它们失去了“在整篇文档中的位置和角色”。它的做法是为每个 chunk 生成一段短上下文说明,把这段说明与 chunk 一起参与 embedding 和 BM25 检索,从而让局部片段带上文档级语境。Anthropic 报告称,该方法通过 Contextual Embeddings 和 Contextual BM25 可显著降低 retrieval failure,并且和 reranking 叠加后效果更强。(Anthropic)
3.5 Late chunking
Late Chunking 是近两年比较值得认真对待的一条路线。它不是先切文档再分别编码,而是先让长上下文 embedding model 编码整段长文本,得到 token-level contextualized representations,之后再在 pooling 前按 chunk 边界做切分并形成 chunk embedding。这样,每个 chunk 的向量里包含了更完整的全局上下文,而不是只看到自己的小片段。原论文明确把它定义为“先过 Transformer,再切块,再池化”。(arXiv)
3.6 Chunking 的现实 trade-off
chunking 的本质不是“越小越好”或“越大越好”,而是三者平衡:
- small chunk:召回粒度细,噪声少,但上下文容易断裂
- large chunk:语义更完整,但容易带入噪声,占满上下文窗口
- overlap/contextualization:缓解断裂,但增加存储、索引和重复召回成本
2025 年针对 advanced chunking 的评估指出,late chunking 和 contextual retrieval 各有优势:前者更高效,后者更能保持语义连贯,但资源成本也更高。(arXiv)
3.7 工程上怎么选
非常粗暴但有效的准则是:
- FAQ、短文档:固定块 + 小 overlap 往往够用
- 论文、法规、长报告:层级/语义 chunking 更合理
- 文档局部片段离开原上下文就看不懂:上 contextual retrieval
- 长文档且 embedding 模型支持长输入:考虑 late chunking
- 问题常常要求跨章节综合:仅靠 chunking 不够,应结合 hierarchical retrieval 或 GraphRAG
4. GraphRAG:把“平面文本切块检索”升级为“图结构索引 + 局部/全局推理”
4.1 它要解决的根问题
普通 RAG 擅长回答“具体事实在哪一段”,但对“整个语料的主题、趋势、结构关系是什么”这类 global questions 表现很差。微软提出的 From Local to Global 明确指出:这类问题本质上更像 query-focused summarization,而不是简单的显式检索。GraphRAG 正是为了解决这种“全局 sensemaking”问题。(arXiv)
4.2 GraphRAG 的标准流程
根据官方文档和论文,GraphRAG 的核心流程大致是:
- 从原始文本中抽取实体与关系
- 构建知识图谱
- 对图做 community detection / hierarchy construction
- 为各层社区生成 summary / report
- 推理时根据 query 走 local search 或 global search
- 把图结构证据、社区报告、原始 text units 组合给 LLM
官方文档把它概括为:从原始文本抽取知识图、构建社区层次、生成社区摘要,再在回答阶段利用这些结构。(GitHub上的微软)
4.3 Local search 怎么做
GraphRAG 的 local search 适合具体问题。官方文档说明,local search 会把 AI 提取的知识图数据与原始文档块结合起来生成答案。直白地说,它不是只查向量库,而是围绕查询命中的实体节点,往外扩张相关的 text units、关系边、社区报告等,再把这些证据拼接成上下文。这样做的优点是:能沿关系链条找证据,而不是只看表面语义相似度。(Mintlify)
4.4 Global search 怎么做
global search 针对的是“数据集整体主题/趋势/主线是什么”这类问题。微软官方文档指出,global search 使用某一层社区层级上的 LLM 生成 community reports 作为上下文,并通过 map-reduce 方式生成最终回答。论文中同样描述为:对每个社区摘要生成 partial response,再将这些 partial responses 汇总成最终响应。(GitHub上的微软)
4.5 它真正的技术本质
GraphRAG 的本质不是“把向量库换成图数据库”这么肤浅。它真正做了三件事:
- 把语料从 flat chunks 变成 structured knowledge representation
- 把检索从“相似文本召回”扩展成“实体/关系/社区引导的证据访问”
- 把回答从“局部证据抽取”扩展成“局部 + 全局 summarization”
所以它更适合跨文档主题分析、全局概览、复杂实体关系问答,而不仅是传统 fact lookup。(arXiv)
4.6 它的代价
GraphRAG 的代价不小:
- 前处理重:要抽实体、关系、社区、摘要
- 图质量高度依赖抽取质量
- 构建索引时间长
- 更新增量更复杂
- 系统解释链更长,debug 难度高
所以它不是“普通 RAG 的免费升级”,而是用大量 ingestion 成本换更高阶的结构化检索能力。(GitHub上的微软)
5. Self-RAG:把“是否检索、如何反思、是否继续”交给模型内部控制
5.1 它要解决的根问题
传统 RAG 的一个硬伤是:不管问题是否需要检索,都固定检索;不管检索结果是否有用,都固定塞给模型。 Self-RAG 正是冲这个问题来的。论文明确提出:固定检索固定数量 passage 会削弱模型 versatility,甚至引入无用上下文;因此它训练一个单一 LM,能够 按需检索、生成并自我反思。(arXiv)
5.2 Self-RAG 的核心机制
Self-RAG 的标志性设计是 reflection tokens。论文说明,它不是只预测普通文本 token,还学习预测一组新增 special tokens,用来触发检索、评价证据、评价自身生成。换句话说,它把“要不要搜”“这段证据好不好”“当前输出是否靠谱”这类控制信号,内化进了 token 生成过程。(ICLR 会议录)
5.3 推理时怎么跑
一个直观的 Self-RAG 推理循环是:
- 模型开始生成
- 当生成到某个阶段,它可能输出“需要检索”的 reflection token
- 系统执行检索,拿回 passages
- 模型继续生成,并同时输出对 passage relevance、support、utility 之类的自我评估信号
- 这些 reflection outputs 在推理时可被用作 soft reranking 或 hard constraint
- 最终形成更可控的 grounded response
Asai 的后续材料也明确提到:在 inference 阶段,reflection tokens 使 Self-RAG 变得可控,可用于软重排或硬约束。(akariasai.github.io)
5.4 它和普通 RAG 的根本差异
普通 RAG 是 system decides retrieval;
Self-RAG 更接近 model decides retrieval and critique。
这意味着控制逻辑从外部 pipeline 的固定规则,转向模型内部生成的自反信号。它不是单纯做 post-hoc verification,而是在生成过程中实时决定是否检索、如何利用检索。(arXiv)
5.5 它的强项与代价
强项是:
- 减少不必要检索
- 提升 factuality
- 更适合长文生成中的 citation / support control
- 比固定 top-k RAG 更灵活
代价是:
- 训练更复杂
- 需要构造带 reflection supervision 的数据
- 推理控制逻辑不再纯外部可解释
- 与现成黑盒 API 模型整合不如纯 pipeline 方法直接
所以它更像“把 RAG 和 self-critique 融成一个模型化方案”,而不是简单 workflow patch。(arXiv)
6. CRAG:先检查检索质量,再决定是否修正检索
6.1 它要解决的根问题
CRAG 的出发点非常务实:RAG 最怕 retriever 拿错东西。 一旦检索错误,生成阶段通常会把错当对,或者至少被噪声拖垮。CRAG 因此引入一个 retrieval evaluator,专门评估当前检索结果整体质量,再决定是否要修正。(arXiv)
6.2 核心流程
CRAG 的标准推理流程可以概括为:
- 先按普通 RAG 做初始检索
- 用轻量 evaluator 对 retrieved docs 做整体质量打分
- 根据置信度触发不同动作
- 如果检索质量不够好,则扩展到 web search 等外部知识源
- 对检索回来的文档做 decompose-then-recompose
- 去掉非关键噪声,只把精炼后的知识交给生成器
这正是论文摘要和 PDF 摘要里反复强调的主线。(arXiv)
6.3 Retrieval evaluator 到底在干什么
它不是逐字逐句证明真实性,而是做一个相对轻量的判断:
这批文档整体上值不值得信?够不够用?
CRAG 的 PDF 摘要显示,evaluator 会输出基于相关性的置信度,并触发不同的 retrieval actions,例如 Correct / Incorrect / Ambiguous 这类分支。也就是说,它更像一个“检索质量守门员”。(OpenReview)
6.4 Decompose-then-recompose 为什么重要
CRAG 认为,一个 retrieved document 里真正对答案有用的文本只占一部分,大量内容其实是噪声。于是它把文档先分解,再有选择地重构,让生成器只看到关键片段。这一步和 reranking 不同:rerank 主要处理“文档顺序”,而 decompose/recompose 处理的是“文档内部哪些部分该留下”。(arXiv)
6.5 CRAG 的真正定位
CRAG 不是要替代 retriever,而是给 retriever 加一个纠偏层。
它尤其适合:
- 内部知识库不完备
- 某些问题需要外部 web 补充
- retrieval 质量波动大
- 生成模型容易被噪声上下文带偏
换句话说,它的价值在于承认 retrieval 可能错,并把“检索错误恢复”设计成系统的一等公民。(arXiv)
7. Adaptive-RAG:先判断问题复杂度,再决定用不用检索、检索几步
7.1 它要解决的根问题
固定 RAG 策略最大的问题之一是 one-size-fits-all。简单问题还去走多步检索,是浪费;复杂多跳问题只做单次检索,又不够。Adaptive-RAG 的论文因此提出:根据 question complexity 动态选择最合适的策略。(arXiv)
7.2 标准框架
Adaptive-RAG 的核心是一个较小的 complexity classifier。根据论文,这个 classifier 使用自动收集的标签进行训练,然后把输入问题映射到不同复杂度层级,再对应选择不同 QA 策略。论文明确说,它在 no retrieval、single-step retrieval、iterative retrieval 之间做自适应切换。(arXiv)
7.3 实际执行长什么样
一个典型执行逻辑是:
- 简单问题:直接靠参数知识回答,不检索
- 中等问题:做一次标准 RAG
- 复杂问题:进入多步/迭代式检索与推理
它不是“模型自己边想边搜”的 Self-RAG 路线,而更像 policy routing:先做 query-level 决策,再把请求分流到不同 pipeline。(arXiv)
7.4 它和 Self-RAG 的区别
这两者很容易混。
- Self-RAG:控制信号在生成过程中由模型自己产出,偏“内生反思式”
- Adaptive-RAG:先由外部 classifier 判断 query complexity,再选 pipeline,偏“外部策略路由式”
前者更像把检索决策嵌进生成;后者更像系统层的 strategy selector。(ICLR 会议录)
7.5 它的强项与代价
强项是同时优化 accuracy 与 efficiency:该省则省,该重则重。论文报告称,这种方法在多种 query complexity 下比固定 baselines 更平衡。代价则在于:classifier 一旦误判,整个后续流程都走错方向。也就是说,Adaptive-RAG 的成败很大程度上取决于 复杂度判别质量。(arXiv)
8. Multi-agent orchestration:不是“多开几个模型”,而是把任务拆给角色化代理并设计协调协议
8.1 它要解决的根问题
单代理系统的一个常见问题是:一个 agent 同时负责规划、检索、工具调用、验证、总结,角色过载。 多代理编排的核心想法,是把不同职责拆给不同 agent,再用 supervisor、router、handoff 或 team chat 机制协调。AutoGen 明确把自己定义为一个多代理对话框架:多个可对话、可定制、可接工具与人类反馈的 agents 通过交互完成任务。CAMEL 也把重点放在 communicative agents 的协作与分工上。(arXiv)
8.2 最常见的编排模式
8.2.1 Supervisor pattern
LangChain/LangGraph 文档把它概括得很直接:一个 central supervisor 协调多个 specialized worker agents。主管 agent 负责任务理解、分配、汇总;子 agent 专注某类能力,如检索、SQL、web、总结、验证。这个模式的优点是控制集中、可观测性强。(LangChain 文档)
8.2.2 Router pattern
先做 routing,再交给特定 agent。LangChain 文档直接把 Router 当成核心多代理模式之一:分类输入,然后把请求路由到一个或多个专门 agent,再综合结果。它适合“问题类型边界相对清晰”的系统。(LangChain 文档)
8.2.3 Handoffs
handoff 不是中央调度每一步,而是允许 agent 之间转交控制权。LangChain 文档说明,handoff 可以通过单 agent 动态配置或多个 subgraph 节点实现。本质上,它更去中心化,适合问题流程天然会“转科室”的场景。(LangChain 文档)
8.2.4 Team conversation / agent chat
AutoGen 代表的是另一种思路:让多个 conversable agents 通过自动化对话协作解决任务,期间可以接入 tools 和 human feedback。它更像“会话驱动的编排”,而不是纯 DAG pipeline。(arXiv)
8.3 一个典型 RAG 多代理系统会怎么拆
在知识系统中,一个常见拆法是:
- planner agent:分解问题,决定路线
- retrieval agent:负责 query rewrite、检索、rerank
- tool agent:调用 SQL、web、API、代码工具
- verifier/critic agent:检查 grounding、冲突、证据充分性
- writer agent:合成最终回答
这类分工并不是某篇单独论文的唯一标准,而是从 AutoGen、LangGraph 这类多代理框架的角色化思想自然导出的工程形态。AutoGen 强调 agents 可接 LLM、tools、humans;LangGraph 则强调 stateful orchestration 与 custom workflows。(arXiv)
8.4 多代理真正难的不是“搭起来”,而是协调协议
真正难点不在于多造几个 agent,而在于设计 coordination protocol:
- 谁来决定下一步
- 状态如何共享
- 什么时候停止
- 冲突意见如何仲裁
- 工具调用结果如何回写
- 人类反馈何时介入
AutoGen 文档把 human-in-the-loop 直接作为系统级交互机制来讲,说明成熟多代理系统通常不是完全封闭自治的,而是保留人为干预点。(GitHub上的微软)
8.5 它与 Agentic RAG 的关系
多代理 orchestration 不是 Agentic RAG 的唯一形式,但它是最常见、最工程化的实现方式之一。因为一旦系统需要:
- 动态选择知识源
- 分阶段检索
- 多工具协作
- 自检与纠错
- 长流程状态管理
单 agent 往往就开始失控,多代理编排会成为更自然的架构选择。LangGraph 官方也明确把自己定位为低层 agent orchestration framework,用于构建、管理和部署 stateful agents。(LangChain 文档)
9. 这些技术之间真正的组合关系
这些方法不是互斥的,现实系统里往往是叠加关系:
- query rewrite + rerank:先改善 query,再做两阶段排序
- better chunking + rerank:先提升 chunk 质量,再精排
- GraphRAG + agent routing:复杂全局问题走 global graph search,局部问题走 local search
- CRAG + web tool agent:检索质量差时触发外部搜索与纠偏
- Adaptive-RAG + multi-agent orchestration:先由 classifier 决定用哪条 agent workflow
- Self-RAG + external verifier:模型内生反思,再叠加系统外审查
因此不能把这些词理解成并列功能菜单。它们分别作用于不同层级:
- query rewrite / chunking / rerank:偏检索与上下文工程
- CRAG / Self-RAG / Adaptive-RAG:偏检索控制策略
- GraphRAG:偏知识表示与检索结构
- multi-agent orchestration:偏系统级执行架构
10. 最后的硬结论
如果只保留最关键的一句话,那么这几个方法的本质可以压缩成这样:
- Query rewrite:先把问题改成更适合搜的形式
- Rerank:先高召回,再高精度排序
- Chunking:决定知识以什么粒度被索引和喂给模型
- GraphRAG:把知识从平面文本提升为图结构与社区层级
- Self-RAG:让模型自己决定何时检索、如何反思
- CRAG:先检查检索是否靠谱,再纠偏
- Adaptive-RAG:按问题复杂度动态选择检索策略
- Multi-agent orchestration:把复杂知识任务拆给多个角色化 agent 协同完成
再说得更直接一点:
普通 RAG 优化的是“搜得更准”;
高阶 RAG 开始优化“何时搜、搜几次、搜错了怎么办、知识如何组织、谁来做决策”。
这才是从基础检索增强,到真正复杂知识系统的分水岭。(arXiv)
下一个最值得继续展开的方向,是把这些技术按 Pre-retrieval / Retrieval / Post-retrieval / Generation / Orchestration 五层重新组织成一张完整技术地图。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)