医疗AI智能体:多意图命中下的智能路由:高风险优先的医疗SKILL调度算法详解.141
一、核心概念
1. 基础定义
SKILL(技能单元):是大模型在医疗场景下的专业化功能模块,比如血糖监测SKILL、血压预警SKILL、饮食指导SKILL、危急重症SKILL,每个SKILL只负责一类精准医疗任务,不做泛化闲聊。
意图路由:当用户输入一句话,如“我血糖12、血压180,该吃什么”,大模型先识别这句话里包含的所有医疗意图,再把请求精准分配给对应的SKILL处理。
竞争调度:多个SKILL同时命中用户意图时,血糖 + 血压 + 饮食3个SKILL都被触发,算法通过打分、优先级判断,决定先处理哪个、后处理哪个、不处理哪个,避免意图混乱。
医疗场景核心规则:危急问题(高血压危象、低血糖昏迷)绝对优先,绝不被饮食指导、闲聊等低优先级SKILL抢占,保障医疗安全。

2. 算法价值
普通大模型是聊天机器人,用户问什么就答什么,没有优先级、没有安全管控:
- 用户说“我血压 200,头晕想吐,中午吃什么”,普通模型可能先回答饮食,延误危急病情;
- 多个医疗问题同时问,模型会混淆答案,给出不专业、有风险的回复。
SKILL调度算法让大模型升级为医疗决策单元,具备3大核心能力:
- 1. 可调度:统一管理所有医疗 SKILL,请求不混乱、不遗漏;
- 2. 可优先级:高风险 SKILL(危急预警)> 中风险 SKILL(血糖血压监测)> 低风险 SKILL(饮食指导)> 闲聊 SKILL;
- 3. 可安全管控:杜绝危急问题被闲聊抢占,屏蔽非医疗违规请求,保障诊疗安全。
3. 核心组件
关键词匹配层:基础识别,快速命中用户输入中的医疗关键词,如血糖、血压、饮食、头晕、昏迷;
置信度打分模块:给每个命中的SKILL打分数,判断意图匹配的可信度;
上下文衰减模块:结合对话上下文,降低过时意图的权重,比如10分钟前问血糖,现在问血压,血糖权重衰减;
历史偏好加权模块:根据用户历史使用习惯,提升高频SKILL的权重,比如用户常年监测血糖,血糖SKILL加权加分;
竞争调度核心:综合分数 + 固定优先级,最终路由到唯一、优先执行的 SKILL。
4. 场景示例
用户输入:“我空腹血糖13.5,血压185/110,头晕眼花,今天该吃什么”
- 命中SKILL:血糖监测 SKILL、血压预警 SKILL、饮食指导 SKILL;
- 算法判断:血压185/110属于高血压急症(高风险),血糖13.5属于高血糖(中风险),饮食是低风险;
- 调度结果:优先触发血压预警SKILL,立即推送危急提示,再处理血糖,最后回答饮食,绝不颠倒顺序。
二、算法运行原理
1. 医疗 SKILL分级标准
医疗场景的优先级是固定且不可篡改的,这是算法的核心规则,所有调度都以此为依据:
| 优先级 | SKILL 类型 | 风险等级 | 典型功能 | 调度规则 |
|---|---|---|---|---|
| P0(最高) | 危急重症 SKILL | 极高 | 昏迷、休克、心梗、高血压危象 | 绝对优先,屏蔽所有其他 SKILL |
| P1 | 生命体征预警 SKILL | 高 | 血压≥180、血糖≥16、心率异常 | 优先于 P2 及以下,不可被抢占 |
| P2 | 慢病监测 SKILL | 中 | 常规血糖 / 血压 / 血脂记录 | 优先于 P3,可被 P0/P1 抢占 |
| P3 | 健康指导 SKILL | 低 | 饮食、运动、用药建议 | 最后执行,可被所有高优先级抢占 |
| P4(最低) | 闲聊 / 通用 SKILL | 无 | 问候、无关问题 | 仅无医疗意图时执行 |
重点说明:P0-P1级SKILL 有抢占权,一旦命中,立即中断当前低优先级SKILL的执行,保障医疗安全。
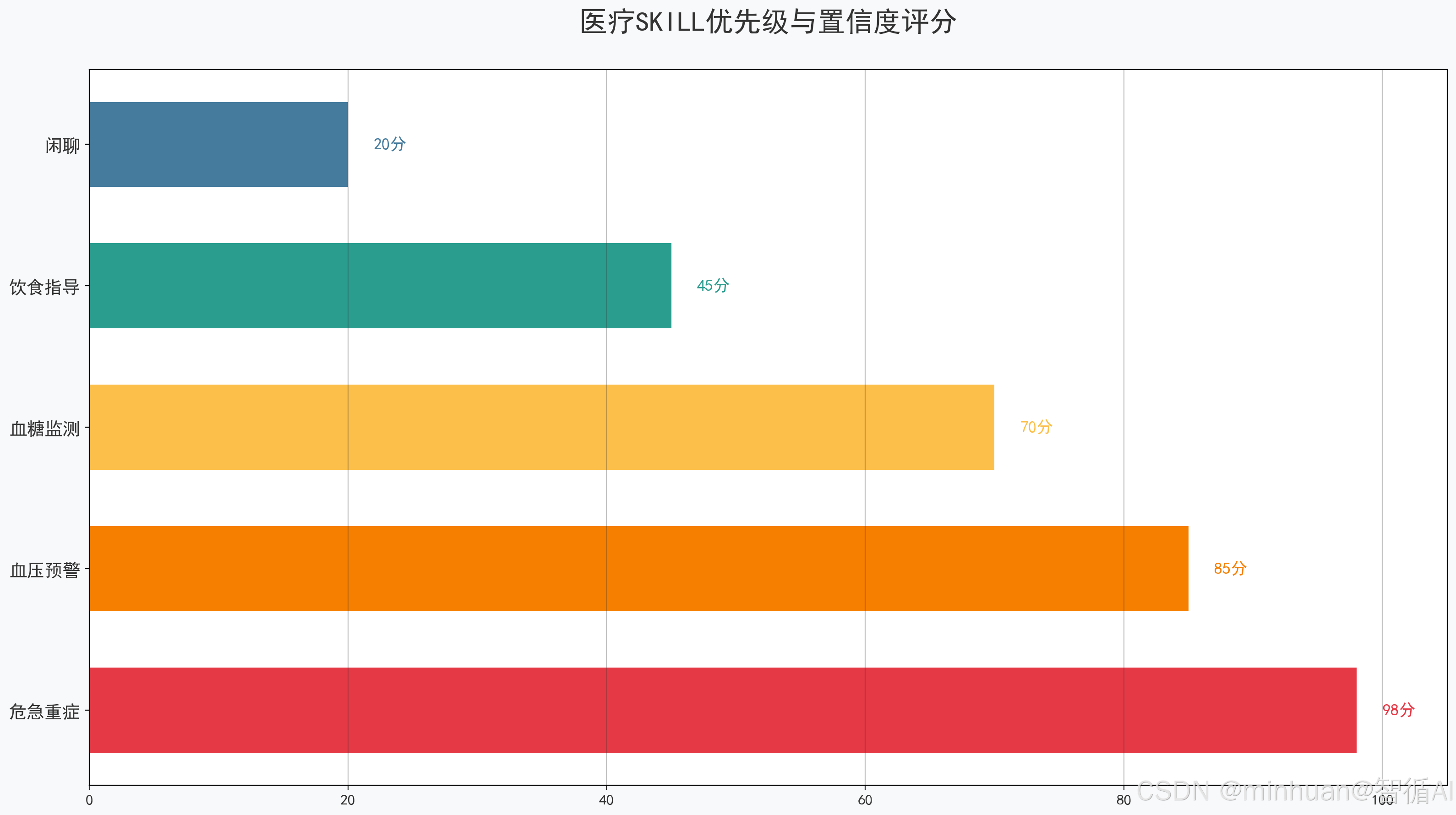
2. 置信度打分原理
计算意图匹配可信度,置信度是算法对“用户意图与SKILL匹配度”的量化评分,满分100分,分数越高,匹配越准确。
基础打分规则:
- 1. 关键词完全匹配:+40 分,如用户说“血压180”,血压SKILL关键词完全命中;
- 2. 语义相关匹配:+20 分,如用户说“头晕心慌”,关联血压SKILL;
- 3. 数值异常匹配:+30 分,如血压≥180、血糖≥13,医疗数值超标,额外加分;
- 4. 无匹配:0 分。
示例:用户说“血压185,头晕”,血压SKILL打分 = 40(完全匹配)+20(语义相关)+30(数值异常)=90 分。

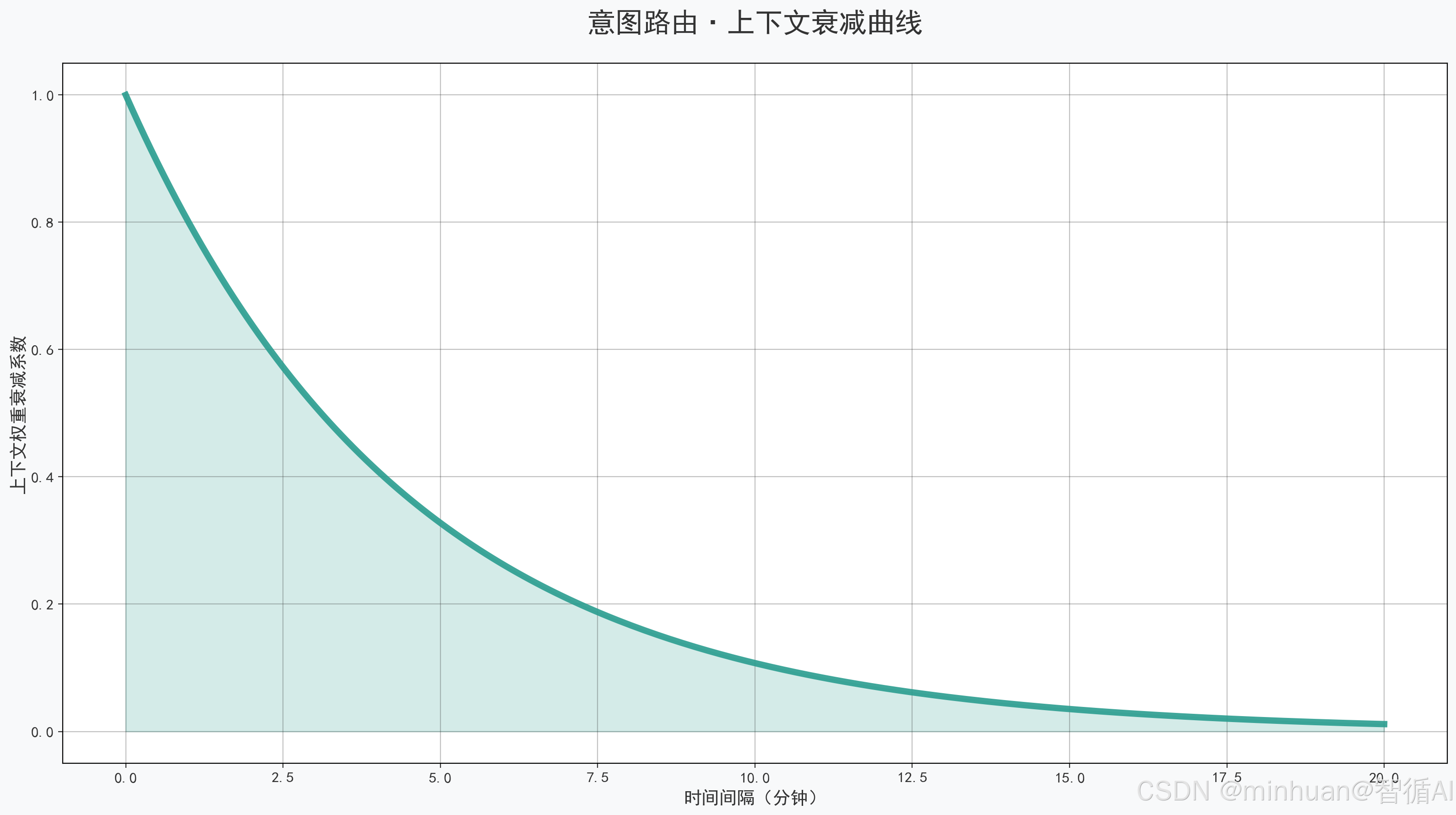
3. 上下文衰减原理
核心是避免过时意图干扰,因为对话是动态的,用户10分钟前问的血糖,现在问血压,旧意图的权重需要随时间衰减,避免算法误判。
衰减公式:当前上下文权重 = 原始权重 × 衰减系数 ^ 时间间隔(分钟)
- 衰减系数:医疗场景固定为 0.8,时间越久,权重降得越快;
- 时间间隔:当前请求与上一次同 SKILL 请求的时间差。
示例:用户 10 分钟前触发血糖SKILL,原始权重100,当前时间间隔10分钟:
- 当前权重 = 100×(0.8)^10≈10.7 分,权重大幅降低,不会干扰当前血压意图。
4. 历史偏好加权原理
目的是贴合用户习惯,算法会记录用户历史使用 SKILL 的频率,给高频 SKILL额外加权,提升匹配准确性:
加权规则:
- 1. 近7天使用次数≥10 次:+15 分;
- 2. 近7天使用次数 5-9 次:+10 分;
- 3. 近7天使用次数 1-4 次:+5 分;
- 4. 首次使用:0 分。
示例:用户常年监测血糖,近7天使用12次血糖SKILL,触发时额外+15分,提升置信度。

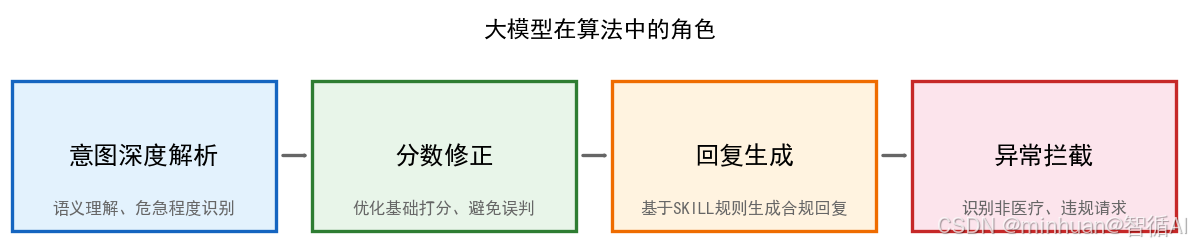
5. 大模型在算法中的角色
- 1. 意图深度解析:基础关键词匹配做不到的语义理解,如“我头很晕,眼前发黑”,大模型能精准识别危急程度;
- 2. 分数修正:对算法基础打分进行优化,避免关键词误判;
- 3. 回复生成:调度到目标SKILL后,大模型基于SKILL的专业规则生成合规、安全的医疗回复;
- 4. 异常拦截:识别非医疗、违规请求,直接屏蔽,保障安全。
三、算法执行流程
通过流程图展示技能路由决策:用户输入经粗匹配、语义识别、多维度打分(置信度、上下文、历史偏好)后,按固定优先级(P0-P4)路由至目标SKILL并执行回复。
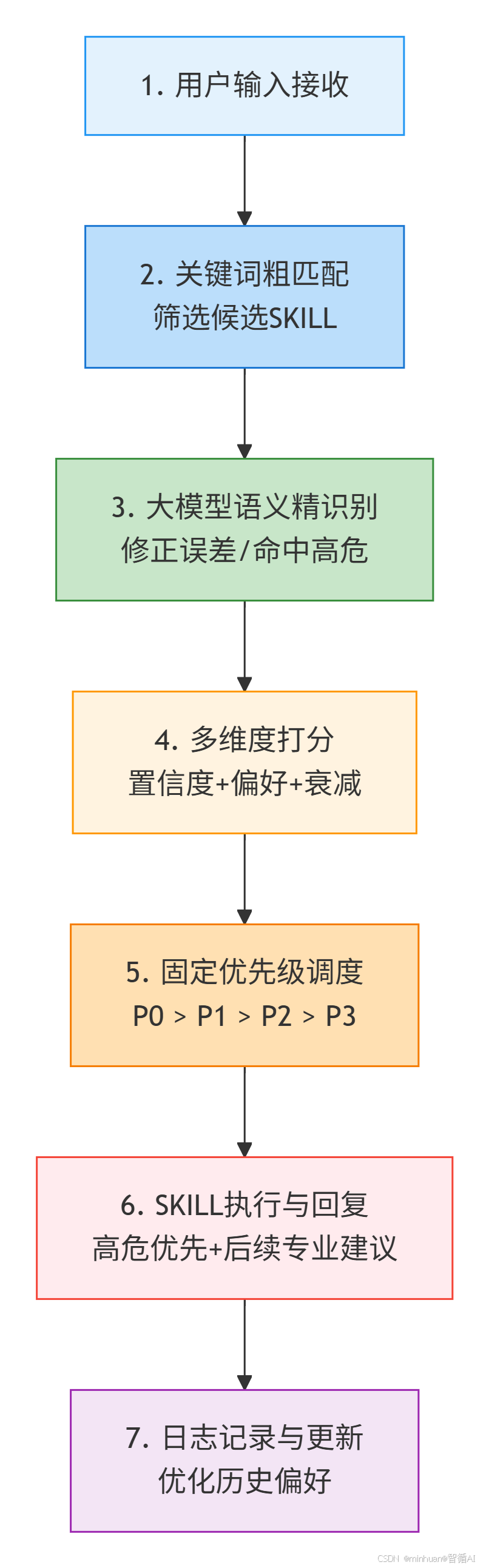
流程详细说明:
- 1. 用户输入接收
接收用户文本/语音请求,比如:“我血糖 14,血压 190,心慌,该吃什么”。
- 2. 关键词粗匹配
算法扫描输入中的医疗关键词,筛选出候选SKILL:
- 关键词:血糖、血压、心慌、吃什么;
- 候选SKILL:血糖监测(P2)、血压预警(P1)、危急重症(P0)、饮食指导(P3)。
- 3. 大模型语义精识别
大模型分析语义,修正粗匹配误差:
- “心慌 + 血压 190”= 高血压急症,命中P0 危急重症SKILL;
- 血糖 14 = 高血糖,命中 P2;饮食 = P3。
- 4. 多维度打分计算
- 1. 基础置信度:危急重症SKILL=95 分,血压SKILL=90 分,血糖 = 80 分,饮食 = 60 分;
- 2. 上下文衰减:无历史请求,权重不变;
- 3. 历史偏好:用户常用血压SKILL,+10 分;
- 4. 最终得分:危急重症 95 > 血压 100 > 血糖 80 > 饮食 60。
- 5. 固定优先级调度
无论分数多少,优先级高于一切:
- P0 危急重症SKILL > P1 血压 > P2 血糖 > P3 饮食;
- 最终路由:优先执行 P0 危急重症 SKILL。
6. SKILL执行与回复输出
- 1. 立即推送危急提示:“您的血压190mmHg属于高血压急症,伴随心慌症状,请立即停止活动,拨打 120”;
- 2. 危急提示后,依次执行血压、血糖、饮食SKILL,输出专业回复;
- 3. 全程不触发闲聊,不被低优先级请求干扰。
7. 日志记录与更新
记录本次调度结果、用户意图、SKILL执行情况,更新历史偏好数据,为下一次调度优化。
四、算法公式与逻辑
1. 最终得分计算公式
SKILL最终得分 = 基础置信度 × 上下文衰减系数 + 历史偏好加权分
- 基础置信度:0-100分,关键词 + 语义 + 数值异常打分;
- 上下文衰减系数:0-1,时间越久,系数越小;
- 历史偏好加权分:0-15分,用户使用频率加成。
2. 优先级调度逻辑
if 存在P0级SKILL命中:
路由到P0 SKILL
elif 存在P1级SKILL命中:
路由到P1 SKILL
elif 存在P2级SKILL命中:
路由到P2 SKILL
elif 存在P3级SKILL命中:
路由到P3 SKILL
else:
路由到P4闲聊SKILL
核心逻辑:优先级第一,分数第二,保障高风险问题绝对优先。
3. 上下文衰减数学原理
衰减系数遵循指数衰减规律,符合人类对话逻辑:时间越远,意图越不重要。医疗场景选择0.8作为衰减系数,兼顾灵敏度与稳定性:
- 5 分钟:权重≈0.327;
- 10 分钟:权重≈0.107;
- 15 分钟:权重≈0.035,基本忽略。
4. 置信度修正原理
基础关键词匹配容易误判,如用户说“血压计坏了”,关键词匹配血压SKILL,但无医疗风险,大模型会做置信度修正:
- 识别无风险意图,将置信度降至<30 分,剔除出调度列表;
- 识别隐藏危急意图,如“我喘不上气”,提升置信度至 90 分以上,触发高优先级SKILL。
五、对大模型的意义
1. 能力升级:从泛化回答到专业决策
普通大模型的局限:
- 无专业边界,什么问题都答,医疗回复易出错;
- 无优先级,危急问题与闲聊同等对待,存在安全风险;
- 无管控,无法屏蔽违规请求,不符合医疗合规要求。
SKILL调度算法带来的升级:
- 专业化:每个SKILL对应医疗细分领域,回复精准、合规;
- 决策化:算法自主判断风险、调度资源,像医生一样分轻重缓急;
- 安全化:高风险问题优先,杜绝医疗事故隐患。
2. 架构升级:可管控、可扩展、可维护
- 可管控:统一调度所有 SKILL,可随时禁用、启用某类SKILL,满足医疗监管要求;
- 可扩展:新增 SKILL,如心电监测、血氧监测,只需加入优先级列表,无需修改核心算法;
- 可维护:每个 SKILL 独立运行,故障不影响其他模块,降低维护成本。
3. 医疗场景的不可替代性
- 生命安全保障:P0级SKILL的绝对优先,是医疗场景的底线要求;
- 合规性满足:算法可记录所有调度日志,满足医疗数据监管、溯源要求;
- 用户体验提升:用户无需重复说明,算法自动识别核心需求,快速给出关键回复。
4. 未来价值:大模型医疗的核心基础设施
SKILL意图路由竞争调度算法是医疗大模型的核心骨架:
- 前端:用户自然交互,无需专业指令;
- 中端:算法智能调度,分优先级处理;
- 后端:各 SKILL 专业执行,保障精准安全;
三者结合,让大模型真正成为辅助诊疗的医疗决策单元,而非简单的聊天工具。
六、应用实践
1. 医疗SKILL调度算法基础实现
以下示例展示了一个医疗AI助手的核心调度逻辑。其意义在于通过多维度评分(关键词匹配、历史偏好、时效性衰减)和高风险优先原则,确保紧急医疗情况能被及时识别并分配给最合适的处理模块,避免因低优先级请求延误高危状况,保障患者安全。
重点包括:
- 1. 高风险优先策略;
- 2. 动态评分机制;
- 3. 用户行为学习。
import time
from typing import Dict, List
# 1. 定义医疗SKILL优先级与配置(核心规则)
SKILL_CONFIG = {
"critical_emergency": {"name": "危急重症SKILL", "priority": 0, "base_score": 95}, # P0最高
"bp_warning": {"name": "血压预警SKILL", "priority": 1, "base_score": 80},
"glucose_monitor": {"name": "血糖监测SKILL", "priority": 2, "base_score": 75},
"diet_guide": {"name": "饮食指导SKILL", "priority": 3, "base_score": 60},
"chat": {"name": "闲聊SKILL", "priority": 4, "base_score": 0}
}
# 2. 关键词匹配库
KEYWORD_MAP = {
"critical_emergency": ["昏迷", "休克", "心梗", "血压≥180", "血糖≥16", "心慌", "喘不上气"],
"bp_warning": ["血压", "高血压", "头晕"],
"glucose_monitor": ["血糖", "空腹血糖", "餐后血糖"],
"diet_guide": ["吃什么", "饮食", "饭菜", "食谱"],
"chat": ["你好", "谢谢", "在吗", "问候"]
}
class MedicalSkillScheduler:
def __init__(self):
self.user_history = {} # 记录用户历史SKILL使用记录
self.last_request_time = {} # 记录上一次请求时间
# 计算上下文衰减系数
def calculate_decay(self, skill_name: str) -> float:
last_time = self.last_request_time.get(skill_name, 0)
if last_time == 0:
return 1.0 # 从未调用过,不衰减,使用基础分
now = time.time()
interval_min = (now - last_time) / 60 # 时间间隔(分钟)
decay = 0.8 ** interval_min # 衰减公式
return round(decay, 3)
# 计算历史偏好加权分
def calculate_preference(self, skill_name: str, user_id: str) -> int:
history = self.user_history.get(user_id, {}).get(skill_name, 0)
if history >= 10:
return 15
elif 5 <= history < 10:
return 10
elif 1 <= history < 5:
return 5
return 0
# 关键词匹配命中SKILL
def match_skills(self, query: str) -> List[str]:
matched_skills = []
for skill, keywords in KEYWORD_MAP.items():
for kw in keywords:
if kw in query:
matched_skills.append(skill)
break
return matched_skills if matched_skills else ["chat"]
# 计算SKILL最终得分
def calculate_final_score(self, skill_name: str, user_id: str) -> float:
base = SKILL_CONFIG[skill_name]["base_score"]
decay = self.calculate_decay(skill_name)
preference = self.calculate_preference(skill_name, user_id)
final_score = base * decay + preference
return round(final_score, 2)
# 核心调度算法
def schedule(self, query: str, user_id: str = "default_user") -> Dict:
# Step1:匹配候选SKILL
matched_skills = self.match_skills(query)
# Step2:计算每个SKILL得分
skill_scores = {}
for skill in matched_skills:
skill_scores[skill] = self.calculate_final_score(skill, user_id)
# Step3:按优先级排序(优先级第一,分数第二)
sorted_skills = sorted(
skill_scores.keys(),
key=lambda x: (SKILL_CONFIG[x]["priority"], -skill_scores[x])
)
# Step4:选定目标SKILL
target_skill = sorted_skills[0]
target_name = SKILL_CONFIG[target_skill]["name"]
final_score = skill_scores[target_skill]
# Step5:更新历史记录
self.user_history[user_id] = self.user_history.get(user_id, {})
self.user_history[user_id][target_skill] = self.user_history[user_id].get(target_skill, 0) + 1
self.last_request_time[target_skill] = time.time()
# Step6:生成调度结果
return {
"user_query": query,
"matched_skills": {SKILL_CONFIG[s]["name"]: skill_scores[s] for s in matched_skills},
"target_skill": target_name,
"final_score": final_score,
"priority": SKILL_CONFIG[target_skill]["priority"]
}
# 测试示例
if __name__ == "__main__":
scheduler = MedicalSkillScheduler()
# 测试用例:危急重症场景
query1 = "我血压190,心慌头晕,眼前发黑,该吃什么"
result1 = scheduler.schedule(query1)
print("=== 测试用例1:危急重症场景 ===")
print(f"用户输入:{result1['user_query']}")
print(f"命中SKILL及得分:{result1['matched_skills']}")
print(f"最终调度:{result1['target_skill']},优先级:{result1['priority']},最终得分:{result1['final_score']}")
print("-" * 80)
# 测试用例:常规慢病场景
query2 = "我空腹血糖7.0,今天饮食注意什么"
result2 = scheduler.schedule(query2)
print("=== 测试用例2:常规慢病场景 ===")
print(f"用户输入:{result2['user_query']}")
print(f"命中SKILL及得分:{result2['matched_skills']}")
print(f"最终调度:{result2['target_skill']},优先级:{result2['priority']},最终得分:{result2['final_score']}")代码说明:
- SKILL_CONFIG:定义医疗 SKILL 的优先级、基础分数,P0 危急重症优先级最高;
- KEYWORD_MAP:关键词匹配库,快速识别用户意图;
- 上下文衰减:根据时间间隔自动降低旧意图权重;
- 历史偏好:根据用户使用频率加分,提升匹配精度;
- 核心调度:先按优先级排序,再按分数排序,保障高风险优先;
- 测试用例:模拟危急场景和常规场景,可直接运行查看调度结果。
输出结果:
=== 测试用例1:危急重症场景 ===
用户输入:我血压190,心慌头晕,眼前发黑,该吃什么
命中SKILL及得分:{'危急重症SKILL': 95.0, '血压预警SKILL': 80.0, '饮食指导SKILL': 60.0}
最终调度:危急重症SKILL,优先级:0,最终得分:95.0
--------------------------------------------------------------------------------
=== 测试用例2:常规慢病场景 ===
用户输入:我空腹血糖7.0,今天饮食注意什么
命中SKILL及得分:{'血糖监测SKILL': 75.0, '饮食指导SKILL': 60.0}
最终调度:血糖监测SKILL,优先级:2,最终得分:75.0
2. 可视化图表生成示例
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 1. 医疗SKILL优先级可视化
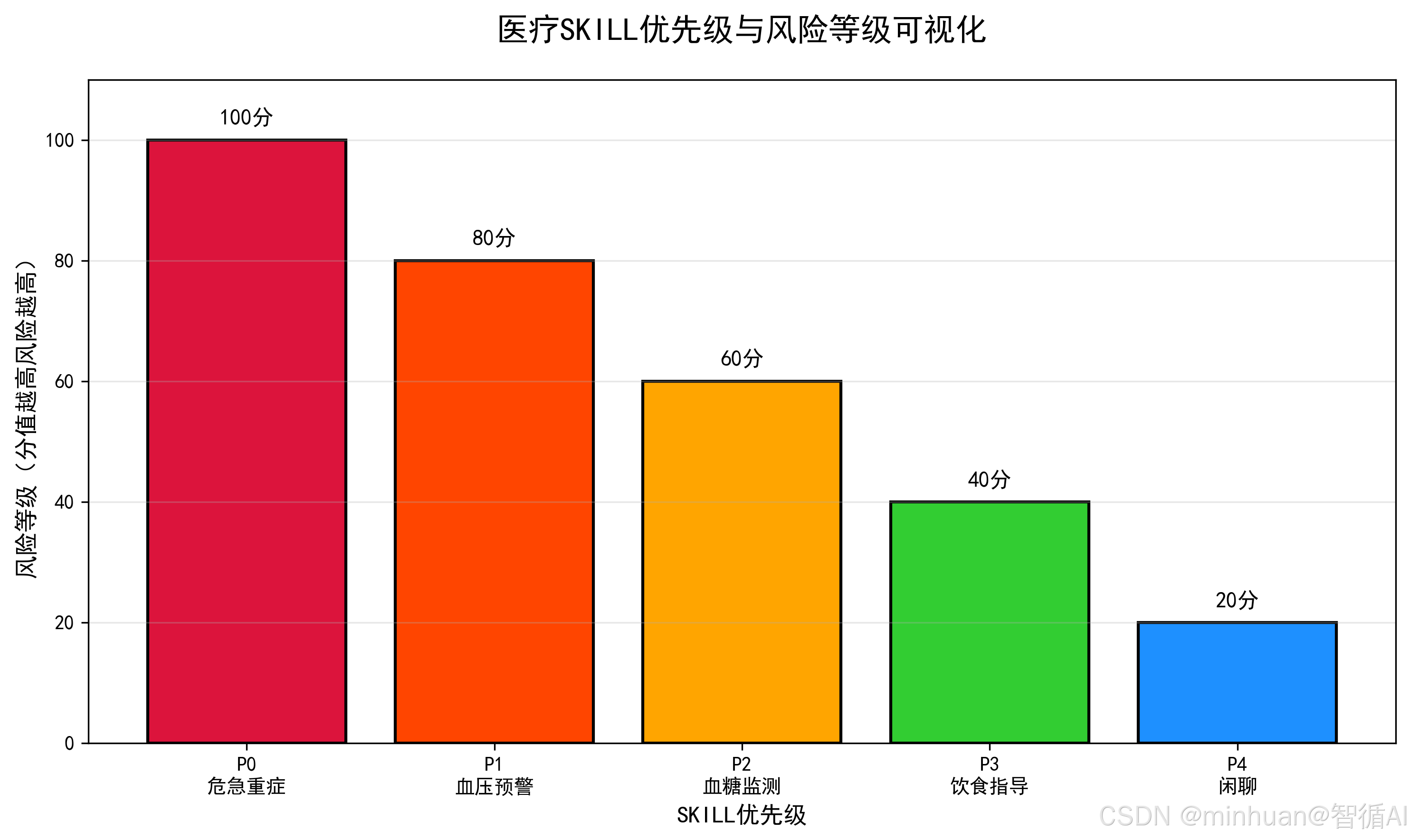
def draw_skill_priority():
priorities = ["P0\n危急重症", "P1\n血压预警", "P2\n血糖监测", "P3\n饮食指导", "P4\n闲聊"]
levels = [100, 80, 60, 40, 20]
colors = ["#DC143C", "#FF4500", "#FFA500", "#32CD32", "#1E90FF"]
plt.figure(figsize=(10, 6))
bars = plt.bar(priorities, levels, color=colors, edgecolor="black", linewidth=1.5)
plt.title("医疗SKILL优先级与风险等级可视化", fontsize=16, pad=20)
plt.xlabel("SKILL优先级", fontsize=12)
plt.ylabel("风险等级(分值越高风险越高)", fontsize=12)
plt.ylim(0, 110)
# 添加数值标签
for bar, level in zip(bars, levels):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 2,
f"{level}分", ha="center", va="bottom", fontsize=11, fontweight="bold")
plt.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig("medical_skill_priority.png", dpi=300, bbox_inches="tight")
plt.close()
print("优先级图表已保存:medical_skill_priority.png")
# 2. 上下文衰减曲线可视化
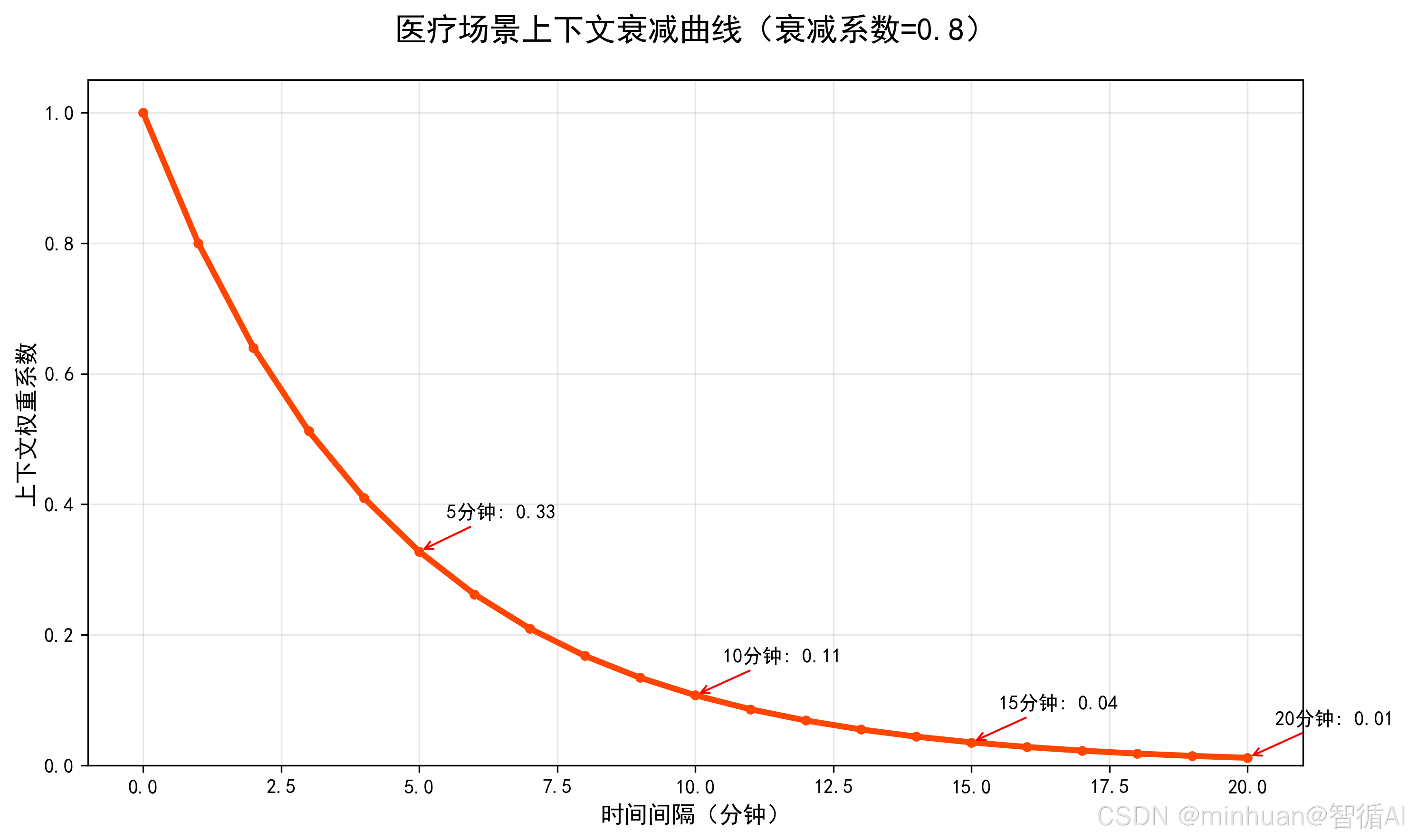
def draw_decay_curve():
minutes = np.arange(0, 21, 1)
decay = 0.8 ** minutes
plt.figure(figsize=(10, 6))
plt.plot(minutes, decay, color="#FF4500", linewidth=3, marker="o", markersize=4)
plt.title("医疗场景上下文衰减曲线(衰减系数=0.8)", fontsize=16, pad=20)
plt.xlabel("时间间隔(分钟)", fontsize=12)
plt.ylabel("上下文权重系数", fontsize=12)
plt.grid(alpha=0.3)
plt.ylim(0, 1.05)
# 标注关键节点
key_points = [5, 10, 15, 20]
for p in key_points:
plt.annotate(f"{p}分钟: {0.8**p:.2f}",
xy=(p, 0.8**p),
xytext=(p+0.5, 0.8**p+0.05),
arrowprops=dict(arrowstyle="->", color="red"),
fontsize=10)
plt.tight_layout()
plt.savefig("context_decay_curve.png", dpi=300, bbox_inches="tight")
plt.close()
print("衰减曲线图表已保存:context_decay_curve.png")
# 执行生成
if __name__ == "__main__":
draw_skill_priority()
draw_decay_curve()医疗SKILL优先级与风险等级可视化:
医疗场景上下文衰减曲线(衰减系数=0.8):
六、总结
SKILL级别意图路由竞争调度算法,就是给医疗大模型装了一套智能指挥中心,让AI从只会闲聊的机器人,变成能判断轻重缓急、懂风险分级的专业医疗决策单元。整套逻辑就是用户一句话里同时问到血糖、血压、饮食这类多个问题时,系统先通过关键词粗匹配 + 大模型语义解析,把所有相关SKILL都找出来,再用置信度打分、上下文时间衰减、历史使用偏好加权算出每个意图的靠谱程度。但分数只是参考,医疗场景最核心的是固定优先级,危急重症永远排第一,接着是血压血糖这类生命体征预警,再到慢病监测、饮食指导,闲聊放在最后。
这样一来就彻底解决了用户血压爆表、情况危急,AI却先扯吃什么的尴尬场面,高风险内容绝对不会被低优先级请求抢占。简单理解,它就是医疗AI的分诊台,既有人文温度,又有科技精度,既保证响应精准,又守住安全底线,是医疗大模型在真实场景里的关键骨架。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)