jina-embeddings-v5-text:新的最先进水平小型多语言 embeddings
作者:来自 Elastic JINA

两个参数量低于 1B 的多语言 embeddings,在性能上达到业界最佳水平,可在 Elastic Inference Service、Llama.cpp 和 MLX 上使用。
我们发布了 jina-embeddings-v5-text,这是我们 embedding 模型家族的第五代,在 sub-1B 多语言 embeddings 的质量与效率边界上进一步推进:
- jina-embeddings-v5-text-small(677M 参数):MMTEB 67.0,MTEB English 71.7
- jina-embeddings-v5-text-nano(239M 参数):MMTEB 65.5,MTEB English 71.0
small 模型支持 32K token 上下文(nano 为 8K),支持 4 个任务专用 LoRA adapters(retrieval、text-matching、classification、clustering),以及 Matryoshka 维度截断能力(从 1024 到 32)。在 239M 参数规模下,nano 模型在检索质量上可匹配参数量是其两倍的模型。
与上一代相比:v5-text-small 在检索任务上可匹配 jina-embeddings-v4(3.8B),但体积小 5.6 倍;同时在参数量相近的情况下,全面优于 jina-embeddings-v3(572M)。
| 特性 | v5-text-small | v5-text-nano |
|---|---|---|
| 基础模型 | Qwen3-0.6B-Base | EuroBERT-210m |
| 参数量 | 677M | 239M |
| Embedding 维度 | 1024 | 768 |
| 上下文长度 | 32,768 | 8,192 |
| 语言支持 | 119(Qwen3 tokenizer) | 15+(EuroBERT tokenizer) |
| Pooling | last-token | last-token |
| LoRA adapters | 4(retrieval、text-matching、classification、clustering) | 4(retrieval、text-matching、classification、clustering) |
| Matryoshka 维度 | 32–1024 | 32–768 |
| MMTEB 分数 | 67.0 | 65.5 |
| MTEB English 分数 | 71.7 | 71.0 |
| 许可证 | CC BY-NC 4.0 | CC BY-NC 4.0 |
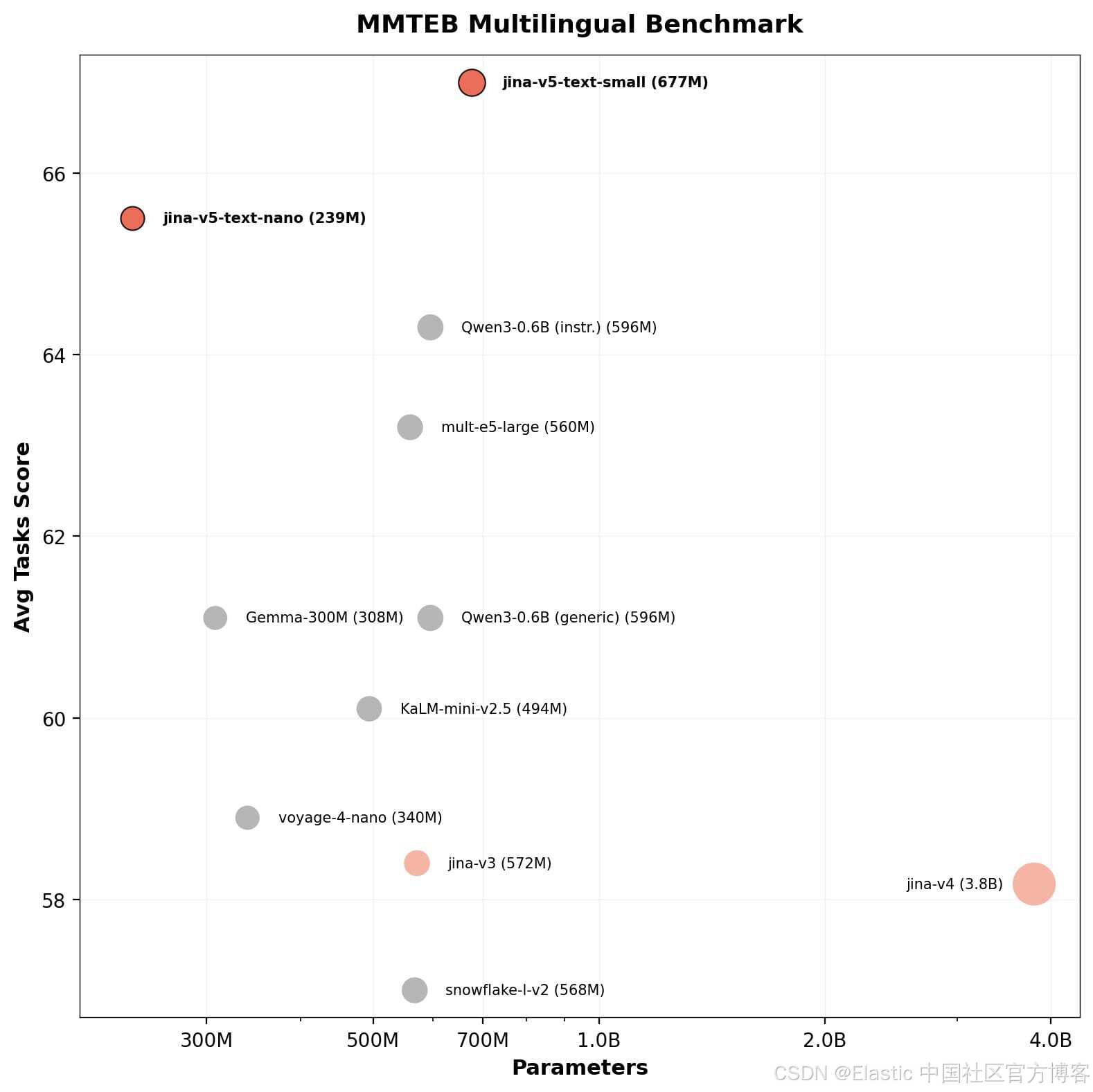
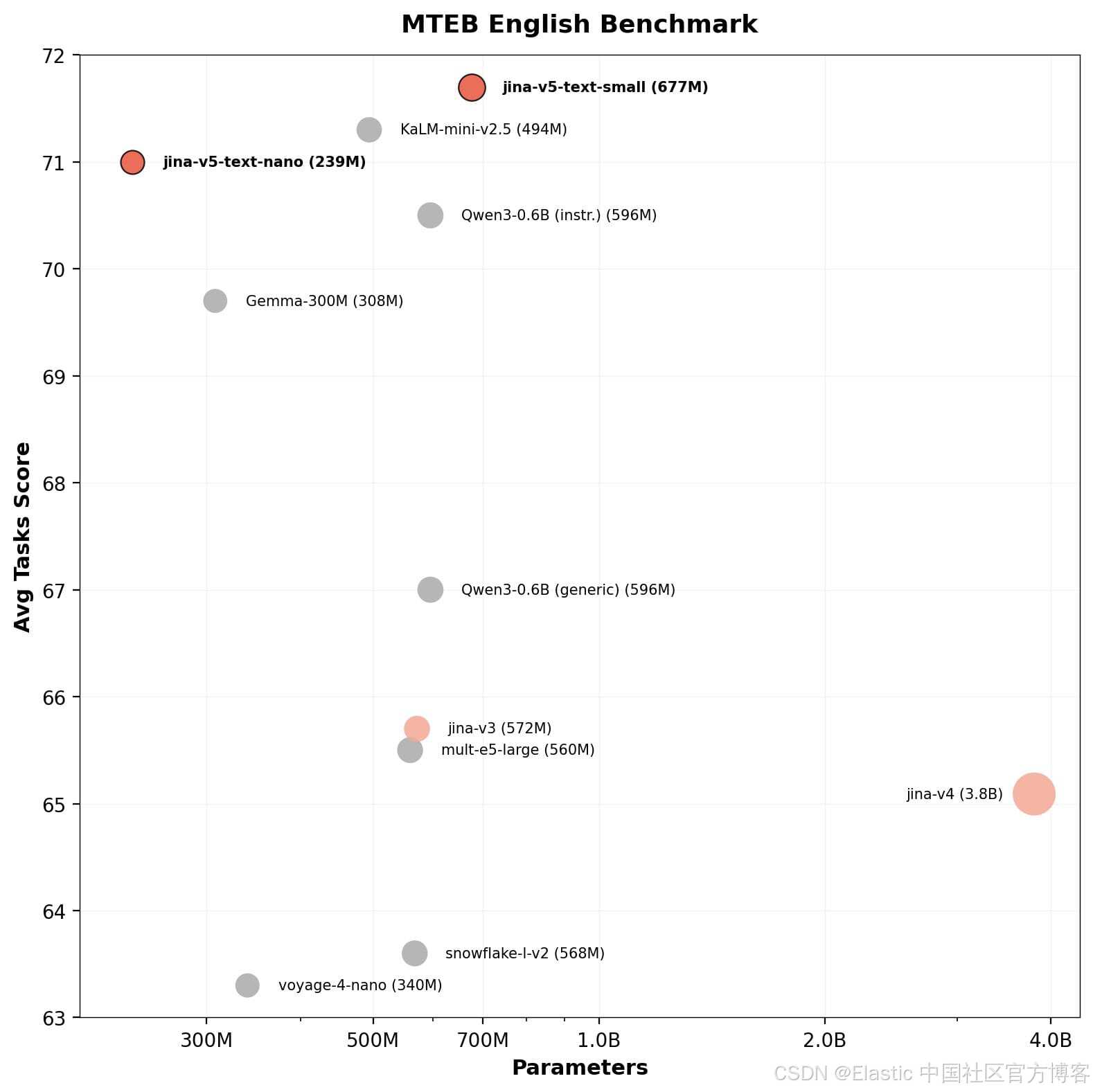
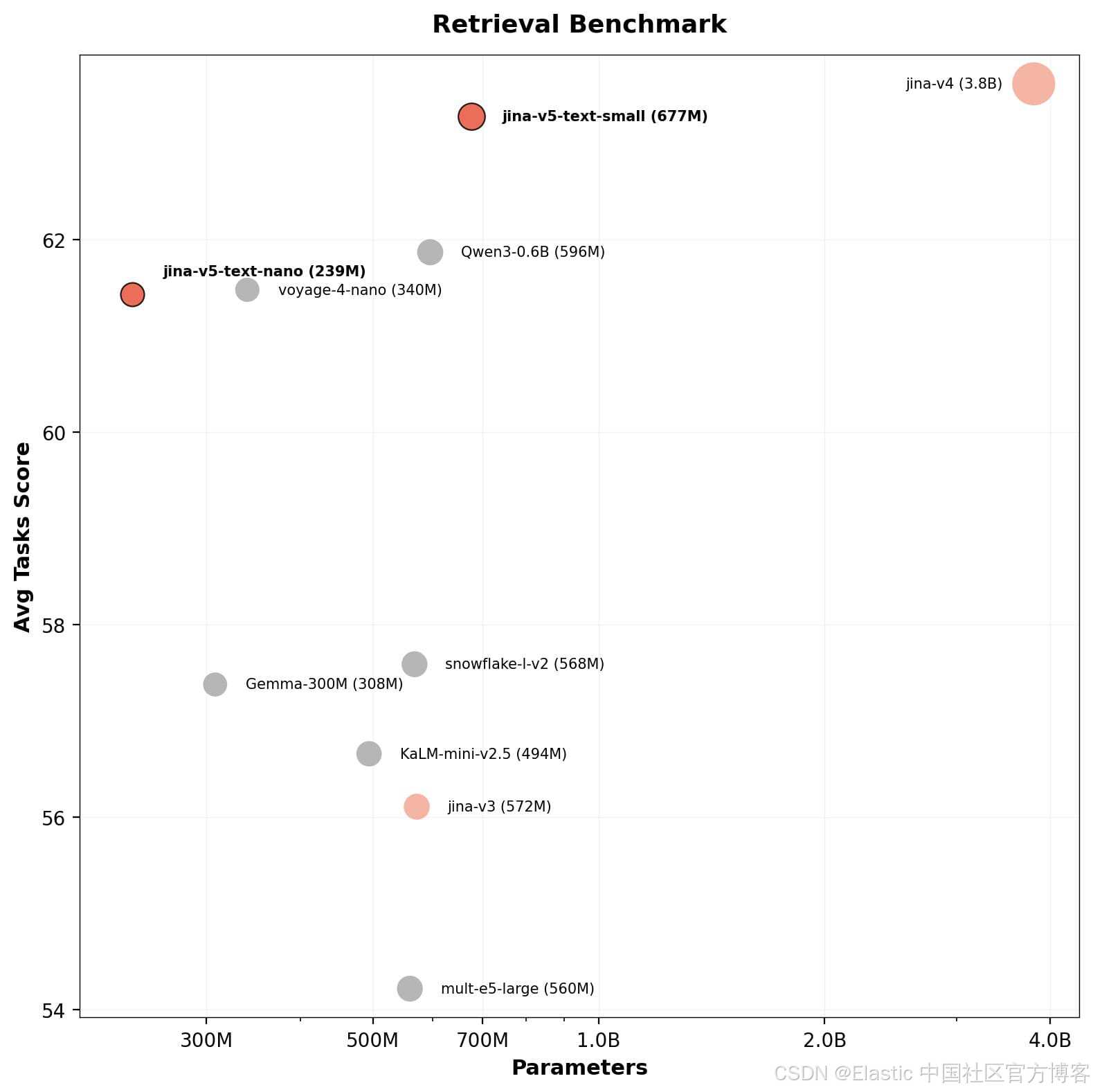
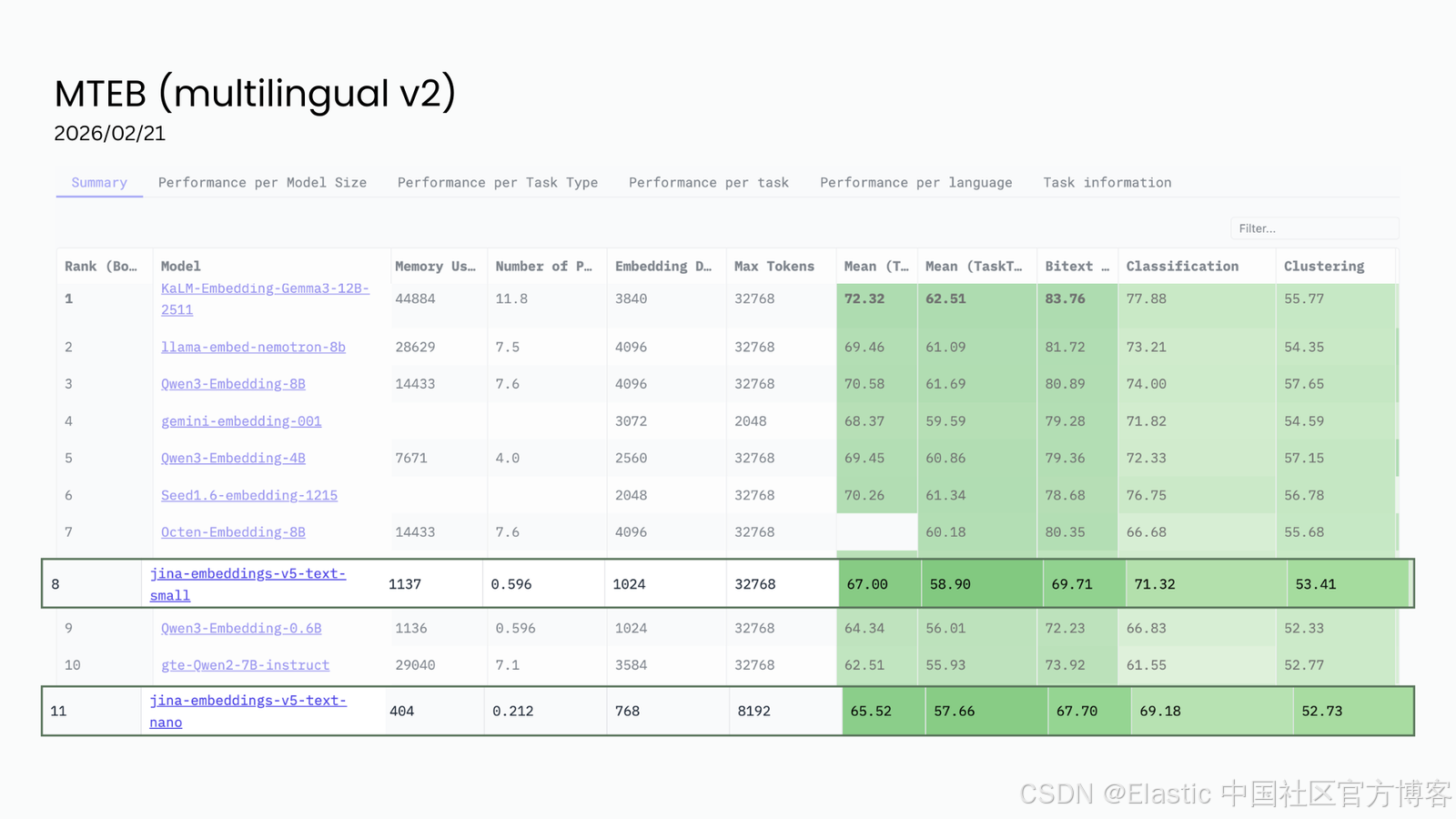
jina-embeddings-v5-nano(0.2B 参数,排名 #11)在极小参数规模下取得了 top-11 的表现,以极低的模型体量达到这一水平,在同参数级别中没有其他模型能够接近这一性能。
架构
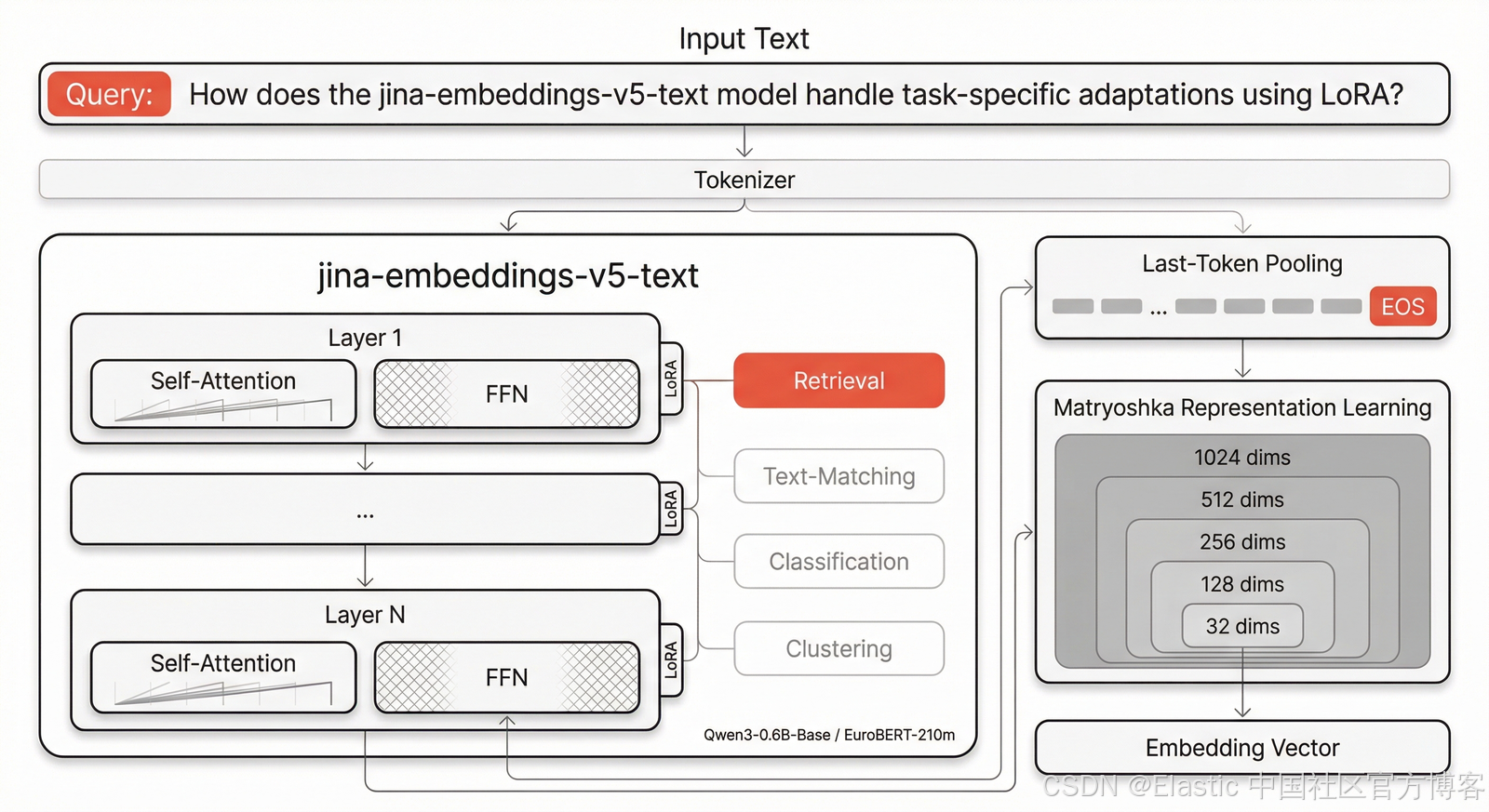
v5-text 使用 decoder-only 架构作为 backbone,并采用 last-token pooling 代替 mean pooling。
在模型结构中,每一层 Transformer 都注入了四个轻量级 LoRA adapters,分别用于 retrieval、text-matching、classification 和 clustering,这些 adapter 在功能上彼此独立,用户可以在推理阶段按需选择。
在检索任务中,query 会添加 “Query:” 前缀,document 会添加 “Document:” 前缀,以增强语义区分能力。
上下文长度方面,v5-text-small 支持 32K tokens(v5-text-nano 为 8K),相比 v3 提升 4 倍。
入门
Elastic Inference Service
使用 v5-text 的最快方式是通过 Elastic Inference Service(EIS)上线生产环境。EIS 提供托管式 embedding 推理能力,并具备内置扩缩容能力,使你可以在 Elastic 部署中直接生成 embeddings,而无需自行管理基础设施。
PUT _inference/text_embedding/jina-v5
{
"service": "elastic",
"service_settings": {
"model_id": "jina-embeddings-v5-text-small"
}
}
请查看 EIS 文档以获取具体配置说明。
Jina Embedding API
我们提供托管的 Embedding API,采用按 token 计费(pay-per-token)的模式。
该 API 支持开箱即用的任务选择(task selection)、维度裁剪(dimension truncation)以及批量处理(batch processing),无需 GPU 即可使用。
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "jina-embeddings-v5-text-small",
"task": "retrieval.query",
"dimensions": 1024,
"input": ["What is knowledge distillation?"]
}'
在 jina.ai/embeddings 获取 API key。
Hugging Face + sentence-transformers
支持在本地运行并对推理过程拥有完全控制权。
模型权重已发布在 Hugging Face,并可与 sentence-transformers 直接集成使用,实现开箱即用的 embedding 推理能力。
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer(
"jinaai/jina-embeddings-v5-text-small-retrieval",
model_kwargs={"dtype": torch.bfloat16},
)
query_emb = model.encode("What is knowledge distillation?", prompt_name="query")
doc_embs = model.encode(["Knowledge distillation transfers...", "Venus is..."], prompt_name="document")
similarity = model.similarity(query_emb, doc_embs)
vLLM
面向生产级工作负载的高吞吐量推理服务框架。
vLLM 原生支持 v5-text,并采用 last-token pooling 机制以实现高效的 embedding 生成与服务化部署。
from vllm import LLM
from vllm.config.pooler import PoolerConfig
model = LLM(
model="jinaai/jina-embeddings-v5-text-small-retrieval",
dtype="float16",
runner="pooling",
pooler_config=PoolerConfig(seq_pooling_type="LAST", normalize=True),
)
outputs = model.encode(["Query: climate change impacts"], pooling_task="embed")
为了在本地实现优化推理(通过 llama.cpp 和 MLX),每个任务的 LoRA 权重都会与基础模型进行合并,从而生成独立的权重文件。
这也是为什么你会看到按任务划分的多个独立仓库(retrieval、text-matching、classification、clustering)——每个仓库都包含已经完成合并的完整权重,可直接加载使用,在推理时无需 LoRA 额外开销。
llama.cpp(GGUF)
支持在 CPU 或边缘设备上运行量化模型。
我们为每个模型提供 14 种 GGUF 量化版本,从 F16 到 IQ1_S 不等,以覆盖不同的性能与资源需求场景。
llama-server -hf jinaai/jina-embeddings-v5-text-small-retrieval-GGUF:Q4_K_M \
--embedding --pooling last -ub 32768
MLX
通过 MLX 实现原生 Apple Silicon 推理。
所有任务 adapter 均提供全精度(full precision)、4-bit 和 8-bit 量化版本,以适配不同的性能与资源需求场景。
import mlx.core as mx
from tokenizers import Tokenizer
from model import JinaEmbeddingModel
import json
with open("config.json") as f:
config = json.load(f)
model = JinaEmbeddingModel(config)
weights = mx.load("model-4bit.safetensors") # or model.safetensors, model-8bit.safetensors
model.load_weights(list(weights.items()))
tokenizer = Tokenizer.from_file("tokenizer.json")
texts = ["Query: What is machine learning?"]
embeddings = model.encode(texts, tokenizer)
从 Hugging Face 下载: jinaai/jina-embeddings-v5-text-small-retrieval-mlx (也提供 text-matching 、 classification 和 clustering adapters )。
训练
两个模型都是从 Qwen3-Embedding-4B 蒸馏得到的,这是一个更大的已训练 embedding 模型。小型版本使用 Qwen3-0.6B-Base 作为其 backbone ,而 nano 使用 EuroBERT-210m 。
我们的 training 结合了两种互补信号:
- 来自 4B teacher 的 embedding distillation ,通过 cosine similarity loss 。 student 学习近似 teacher 的 embedding space ,无需 instruction-style prompts 。这对于 labeled data 稀缺的语言和任务尤其有效。
- 基于 Task-specific contrastive loss ( InfoNCE )在 labeled query-document pairs 上,结合 hard negative mining 和 in-batch negatives 。在冻结 distilled backbone 之后,我们为每个 task category 训练独立的 LoRA adapters 。
我们的 ablation studies 表明,这种组合方法始终优于单一方法。在 MTEB English retrieval 上,该组合方法在同一 backbone 上取得 60.1 nDCG@10 ,相比 distillation-only 的 58.6 和 contrastive-only 的 54.3 。
我们还在 training 中应用 GOR ( Generalized Orthogonal Regularization ),它鼓励 embedding components 更均匀分布。这不会显著提升 standard benchmark scores ,但它使 binary quantization 几乎 lossless ,这是 memory-constrained deployment 的关键特性。
一些来自 training 的观察值得注意:
- distillation 和 contrastive learning 在我们最初没有预料到的方式上是互补的。
- 从 loss mixture 中移除任何单一组件都会导致 performance 全面下降。
- Task-specific LoRA adapters 在几乎可忽略的 parameter overhead 下优于 multi-task training 。
- GOR regularization 使 binary quantization 几乎 lossless ,这对 deployment 比微小的 full-precision gains 更重要。
结论
Embedding models 越来越多地作为 tool-chain components 被用于更大的系统中。LLM agents 在 agentic workflows 中调用 embedding APIs ,用于 retrieval 、 memory 和 classification 。
像 OpenClaw 和 OpenViking 这样的项目将 embeddings 视为 agent context management 的 core infrastructure layer ,而不是 standalone search endpoints 。在这种 regime 下,inference cost 和 latency per call 与 benchmark scores 同样重要,而 compact models 成为自然选择。
向更小 embedding models 的趋势反映了更广泛的转变。on-device retrieval 、 browser-based search 和 edge deployment 都要求模型适配 constrained memory budgets 。
Matryoshka dimension support 使单一模型能够同时支持 high-precision 和 ultra-fast approximate search ,而无需 retraining 。结合 GGUF quantization (降至 1-2 bits ),production embedding service 的有效 memory footprint 降低一个数量级。
我们正在开发 jina-embeddings-v5-multimodal ,将相同 architecture 扩展到 vision 和 cross-modal retrieval 。早期结果表明,将 vision encoder 与 fine-tuned text embedding model 对齐是可行的,且不会降低 text performance 。
敬请期待。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)