(2024|AAAI|南科大&腾讯,UCAD,持续学习,记忆库,无监督异常检测和分割,对比学习,ViT)基于对比学习提示的无监督持续异常检测
Unsupervised Continual Anomaly Detection with Contrastively-Learned Prompt

论文地址:https://arxiv.org/abs/2401.01010
项目页面:https://github.com/jiaq-liu/UCAD
进学术交流群:922230617 或加 CV_EDPJ 进交流群
目录
1. 引言
无监督异常检测(Unsupervised Anomaly Detection,UAD)专注于仅依靠 “正常” 数据的固有分布来识别异常模式,在工业制造中尤为实用,因为获取标注缺陷数据困难且昂贵。
近期 UAD 研究为不同类别训练独立模型,测试时依赖类别身份信息。此外,顺序学习独立模型会带来沉重的计算负担。另一些方法尝试训练统一模型(如 UniAD),但在真实生产中,数据是顺序到达的,统一模型要求同时训练所有数据不切实际,且在频繁产品变更时无法保持已学知识。灾难性遗忘和计算负担阻碍了 UAD 在实际场景中的应用。
持续学习(Continual Learning,CL)以单个模型解决灾难性遗忘问题。现有 CL 方法根据测试时是否需要任务身份分为任务感知与任务不可知两类。任务不可知方法更普遍,如 L2P 动态学习提示作为任务标识。尽管任务不可知 CL 方法在监督任务中有效,但其在 UAD 中的效果尚未验证。工业中由于高成功率和隐私问题,难以获取大量异常数据,因此探索 CL 在 UAD 中的应用至关重要。
迄今为止,除高斯分布估计器(DNE,Distribution of Normal Embeddings,正态嵌入分布)外,尚无将 CL 融入 UAD 的工作。但 DNE 仍依赖数据增强提供伪监督,且不适用于异常分割。在实际工业制造中,精确分割异常区域对异常量化至关重要。因此,迫切需要一种能同时执行无监督持续异常检测与分割的方法。
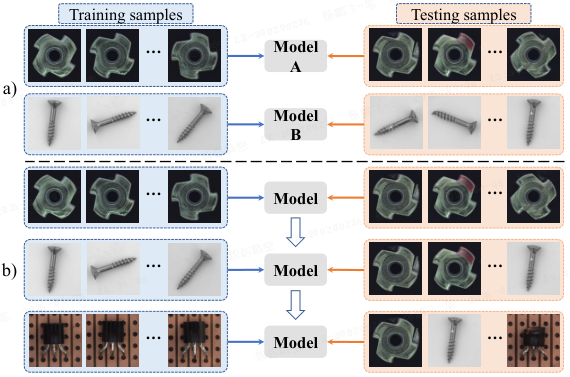
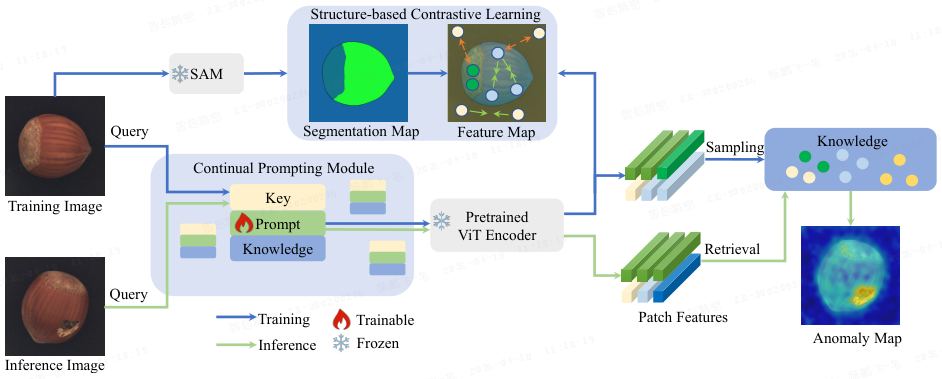
本文提出无监督持续异常检测 (Unsupervised Continual Anomaly Detection,UCAD)框架,如图 1b 所示,使用单个模型顺序学习不同类别的异常检测。UCAD 包含持续提示模块(Continual Prompting Module,CPM)和基于结构的对比学习(Structure-based Contrastive Learning,SCL)。
- CPM 学习 “键-提示-知识” 记忆空间,存储自动选择的任务查询、任务适配提示以及不同类别的 “正常” 知识。给定图像,自动选择键以检索对应任务提示,进而提取图像特征并与正常知识比较进行异常检测。
- 然而,冻结的 ViT 主干无法提供跨任务的紧凑特征表示。为此,SCL 利用 SAM 的通用分割能力,提取更 dominant 的特征表示并减少领域差异。
2. 相关工作
2.1 无监督图像异常检测
随着 MVTec AD 数据集的发布,工业图像异常检测从监督范式转向无监督范式。训练集仅含正常图像,测试集包含正常和异常图像。现有方法分为两类:基于特征 embedding 的方法和基于重建的方法。
基于特征 embedding 的方法包括:教师-学生模型、单类分类、基于映射的方法和基于记忆的方法。基于重建的方法包括:自编码器、GAN、ViT 和扩散模型。
然而,现有 UAD 方法旨在提升单一类别的检测能力,缺乏持续学习场景下的异常检测能力。本文方法专为持续学习设计,实现了无监督的持续异常分割。
2.2 持续图像异常检测
工业制造中数据流常见。
- 已有方法如 IDDM 基于少量标注样本进行增量异常检测,LeMO 在正常样本持续增加时进行增量检测,但两者均关注类内持续异常检测,未解决类间增量挑战。
- 最相关的工作是 DNE,它进行图像级别的持续异常检测,但仅存储类别级信息,无法进行细粒度定位,不适用于异常分割。
- 本文方法超越了持续异常分类,扩展到像素级持续异常检测。
3. 方法
3.1 无监督持续异常检测问题定义
无监督异常检测旨在仅使用正常数据识别异常样本,因为在实际工业制造场景中获取带标注的异常样本十分困难。
训练集仅包含来自不同类别的正常样本,测试集则同时包含正常与异常样本。
定义多类别训练集和测试集为:
![]()
![]()
在无监督持续异常检测与分割设定下,单个模型在新增类别上顺序训练,不重复使用旧数据。模型依次在子训练集 T^i_train 上训练,并在所有历史测试子集 T^total_test 上评估。
3.2 持续提示模块(CPM)
本文设计了一个持续提示模块(Continual Prompting Module, CPM),包含两个阶段:任务识别与任务适配。该模块采用键-提示-知识记忆空间 M=(K_e, V, K_n)。
1)任务识别阶段
输入图像 x∈R^{H×W×C} 经冻结的预训练 ViT 编码器 f 提取键 k ∈ K_e 作为任务标识。
本文选取第 i 层(本文取 i=5,而不是最后一层)的输出特征作为键:
![]()
其中 N_p 为 patch 数量。
为提高效率,要避免存储所有图像的特征。本文采用最远点采样(farthest point sampling method,FPS)选取代表性单图像特征而不是所有特征作为任务键(即,使用一个特征代表一个任务):
![]()
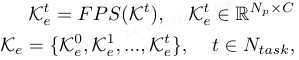
2)任务适配阶段
引入可学习的提示 p ∈ V 传递任务相关信息。对第 i 层,将提示加至输入特征:
![]()
随后,适配后的特征 k^i 被用于构建知识库 K_n。为降低存储,采用 coreset 采样:
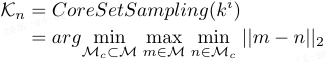
其中,M 是训练过程中的代表图像特征,M_c 是 patch 级别特征 k^i 的 coreset 空间,是 M 的子集。本文实验中选择 i=5,因为中间层特征同时包含上下文和语义信息。
通过建立键-提示-知识对应关系,CPM 能够将历史任务知识迁移至当前图像。
3.3 基于结构的对比学习(SCL)
为将模型适配到当前任务,增强特征表示的紧凑性(同掩码特征更近、异掩码特征更远),本文设计了基于结构的对比学习(Structure-based Contrastive Learning, SCL)。
- 利用 SAM 生成分割图像 I_s,不同区域对应不同结构。
- 同时获得特征图 F_s ∈ k^i,下采样 I_s 使其与 F_s 尺寸匹配,得到标签图 L_s。
对比学习损失函数为:
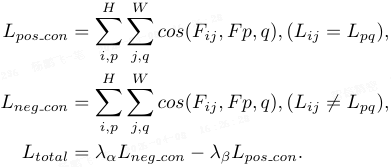
其中 F_ij 为位置 (i, j) 处的特征 embedding,L_ij 为对应标签,λ_α = λ_β = 1。
3.4 测试时任务不可知推理
任务自动选择与适配:对于集合 K_e 中的任务代表特征,根据测试图像 x_test 与特征的最大相似度确定任务:
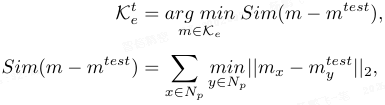
根据选中的任务,检索对应的提示 ν 和知识库 K_n,将提示与测试 patch 结合后经 ViT 提取适配特征,并计算与 K^t_n 的最小距离作为异常得分。
异常检测与分割:定义测试特征集 P(x_test),异常得分计算如下:
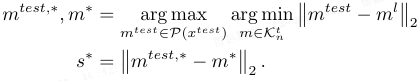
通过邻居 m* ∈ K^t_n 进行加权,得到更鲁棒的得分:
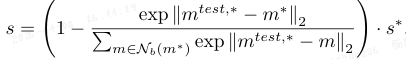
图像级异常得分为所有 patch 得分的最大值 S_img=max(si)。粗分割图 S_cmap 由各 patch 得分构成,经上采样和高斯平滑,最终得到分割结果 S_map。
4. 实验与讨论
4.1 实验设置
数据集:MVTec AD 和 VisA 数据集。
对比方法:包括 CFA、CSFlow、CutPaste、DNE、DRAEM、FastFlow、FAVAE、PaDiM、PatchCore、RD4AD、SPADE、STPM、SimpleNet、UniAD 等。其中 DNE 是 SOTA 无监督持续 AD 方法。本文还对 PatchCore 和 UniAD 进行了基于重演(replay)的实验,为其提供可存储 100 个训练样本的缓存池。
评估指标:AUROC、AUPR(AUP/R/AP)以及遗忘度量(FM)。
4.2 定量分析
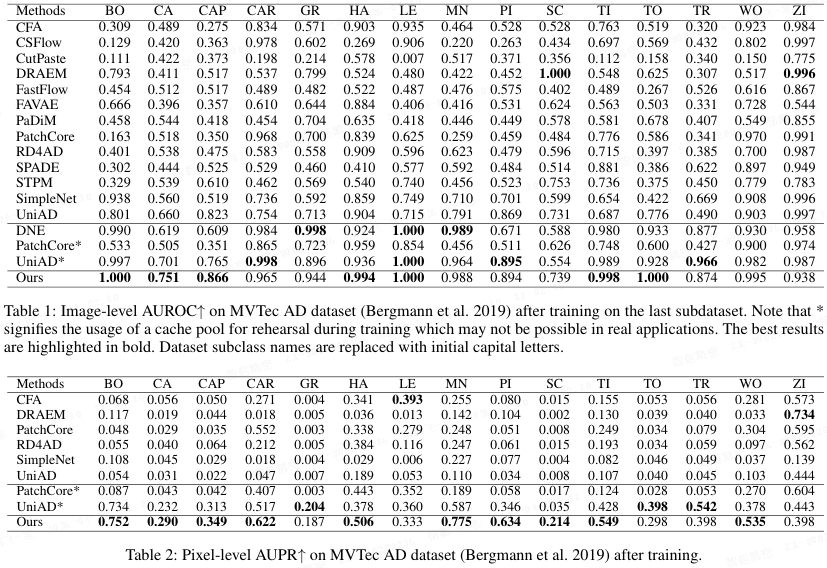
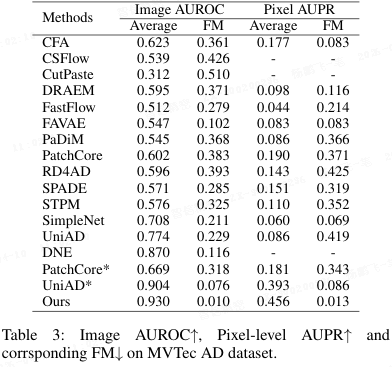
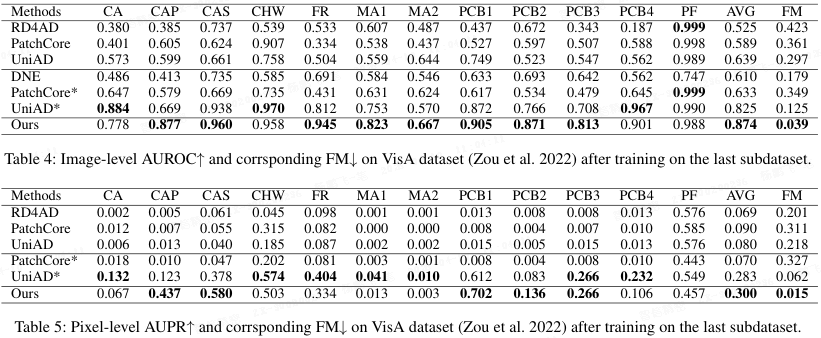
表格 1-5 展示了实验结果。大多数异常检测方法在持续学习场景下性能显著下降。有趣的是,使用重演(replay)后,UniAD 在 MVTec AD 上超越了 DNE。在 VisA 数据集上,即使不使用重演,UniAD 也优于 DNE。本文方法在不使用重演的情况下大幅领先第二名方法。具体而言,在 MVTec AD 上,本文方法在图像级 AUROC 上领先第二名 2.6 个百分点,在像素级 AUPR 上领先 6.3 个百分点;在 VisA 数据集上,分别领先 4.9 和 1.7 个百分点。在结构更复杂的 VisA 数据集上,仅依靠类别 token 进行异常判别的 DNE 检测能力显著下降,而本文方法不受影响。
4.3 定性分析
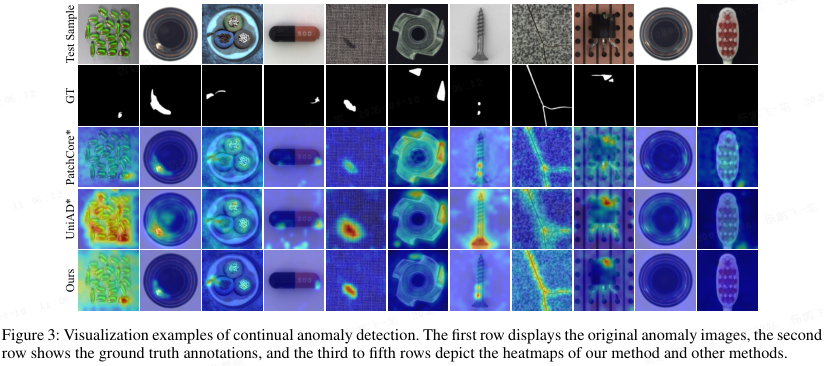
如图 3 所示,本文方法能够预测异常区域,相比 DNE 有显著进步。与 PatchCore* 和 UniAD* 相比,本文方法有两个明显优势:异常定位更精确,且在正常图像上的假阳性更少。
4.4 消融研究
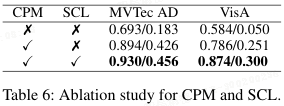
模块有效性:
- 表格 6 显示,CPM 和 SCL 均带来显著提升。
- 无 CPM 时,模型使用单一知识库并在新任务时重置,无法适应无监督持续学习;加入 CPM 后,图像级 AUROC 提升约 20 点。
- 无 SCL 时,模型仅依赖冻结的 ViT 提取特征,最终性能下降约 4 点。
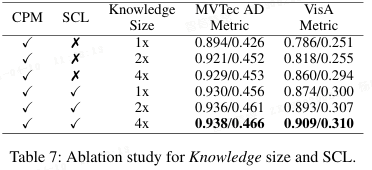
知识库大小:
- 表格 7 表明,在有 SCL 的情况下,增大知识库大小对性能提升边际效应很小;而无 SCL 时,增大知识库能带来明显增益。
- 这说明 SCL 使特征分布更紧凑,同等大小的特征能蕴含更多信息。
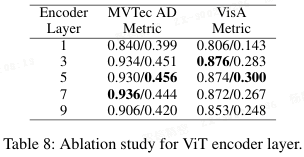
ViT 编码器层数选择:
- 表格 8 显示,浅层和深层均不适合无监督异常检测,中间层(如第 5 层)因同时包含上下文和语义信息而表现最佳。
- 本文为简单起见统一使用第 5 层。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)