Server 弹性内存扩展实现模型部署
目录
摘要
当前在针对大模型训练/推理的时候会多次存在加载模型文件时OOM的状态,其主要原因是这部分是模型在运行时动态产生的,其中最主要的是 KV 缓存 (KV Cache),其生成文本时token是逐字预测的,为了避免在生成下一个字时重复计算之前所有字的注意力信息,系统会将这些中间计算结果(键K和值V张量)缓存起来,这就是KV缓存,它的主要大小由上下文长度 (Sequence Length)以及批处理大小 (Batch Size)以及模型结构所决定的,但是上下文长度增加的情况下极容易出现内存/显存超限OOM,在服务器方案硬件有限的情况下,可以采取存储充当弹性内存的解决方案临时充当内存参与数据交换计算。
为什么会有这个问题:大模型执行时内存开销主要包含:
基于 Docker 容器化部署的模型测试方案,它内部通常包含以下组件,每个都需要消耗内存:
Docker 守护进程:约 50-100 MB。
主服务 (Node.js/Python):取决于模型文件执行(无上限)。
数据库 (SQLite/PostgreSQL/Redis):至少 100-200 MB。
依赖库与缓存:运行时动态加载,极易突破 100 MB。
系统本身开销:Linux 系统内核及基础进程需占用 300-400 MB
除此以外最重要的部分为:模型权重
Model Weights
两部分构成:
1.模型参数量 (Parameter Count)
2.数据精度 (Data Precision)
|
数据精度 |
单个参数字节数 |
核心特点 |
|
FP32 (单精度) |
4 字节 |
效果最佳,显存占用最高 |
|
FP16 (半精度) |
2 字节 |
效果接近FP32,占用减半 |
|
INT8 (8位量化) |
1 字节 |
效果损耗小,占用为FP32的1/4 |
|
INT4 (4位量化) |
0.5 字节 |
效果略有损耗,占用为FP32的1/8 |
以常见的deepseek 671B(蒸馏模型)为例
一个仅仅被激活370亿参数(671B)的模型,在不同精度下,仅模型权重的显存占用就不同:
- FP16精度(8-bit): 671B × 2字节 = 1.34TB
- INT4精度(4-bit): 671B × 0.5字节 = 336 GB
这还没算上 Java 虚拟机(如果涉及)、日志缓冲、网络包缓冲等额外开销。一旦总需求超过物理内存,Linux 内核会触发 OOM Killer 机制,或者直接导致系统因频繁进行 Swap(虚拟内存交换)而彻底卡死,无法响应 SSH 命令。
当前我们的测试环境很多情况下除了系统盘很多情况下是假负载,内存也会出现不足的情况。
具体解决方案及流程
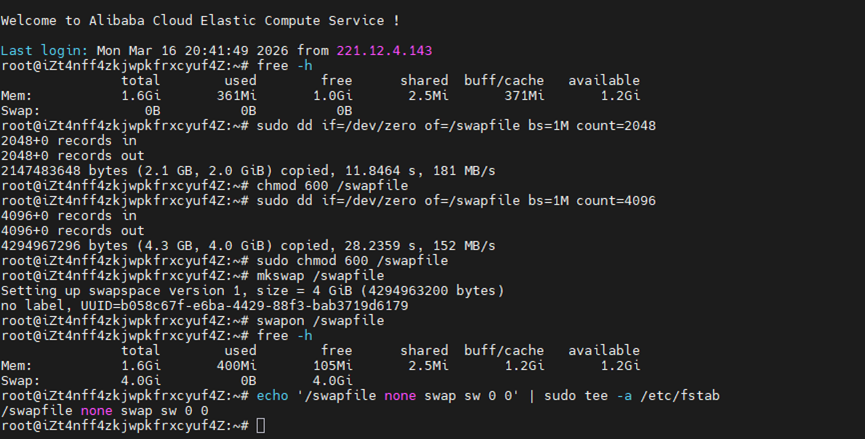
针对于这个现象,我们对此的解决方案:swap扩展基础内存(存储当作弹性内存来作为缓冲过度) 以创建swap文件举例。
# 1. 创建 2GB 的 swap 文件
sudo dd if=/dev/zero of=/swapfile bs=1M count=2048
# 2. 设置权限
sudo chmod 600 /swapfile
# 3. 格式化为 swap
sudo mkswap /swapfile
# 4. 启用 swap
sudo swapon /swapfile
# 5. 验证是否生效
free -h
# 看到 swap 行有 2G 左右数值即为成功
# 6. (可选) 设置开机自动挂载
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
以阿里云上服务器为例,我们可以观察到:执行日志前后出现的区别
后续整体测试流程改进方案
使用蒸馏模型:
在推理模型内使用蒸馏模型完成推理在实际性能检测与原有模型推理测试gpu性能没有区别,均可以完成推理性能测试(衡量指标)
验证一个模型的推理性能,往往需要进行成千上万次的推理测试。使用庞大的教师模型(如671B参数的DeepSeek-R1)进行这种规模的测试,成本极高且速度缓慢。
- 大幅降低成本: 蒸馏模型(学生模型)的参数量远小于教师模型。例如,一个7B的蒸馏模型,其硬件需求和能耗可能仅为671B教师模型的几十分之一。这使得在有限预算下进行大规模、多轮次的性能验证成为可能。
- 显著提升速度: 更小的模型意味着更快的推理速度。有案例显示,32B的蒸馏模型推理速度可比原始大模型提升约50倍。这意味着你可以在相同时间内完成更多的测试用例,极大地加速了验证迭代周期。
蒸馏的目的不是100%复制教师模型,而是在性能和效率之间找到最佳平衡点。验证蒸馏模型,本质上是在验证这个平衡点的价值。
保留核心推理能力: 大量实践证明,通过蒸馏,小模型可以继承教师模型的核心推理模式(如思维链CoT),在特定任务上达到教师模型80%-95%的性能。例如,DeepSeek-R1蒸馏出的32B模型在AIME 2024数学竞赛中的得分(72.6%)甚至超越了GPT-4o(9.3%)。验证这样的模型,就是验证“用小模型解决复杂问题”这一路径的可行性。
突破基础模型的限制: 与强化学习(RL)等方法相比,蒸馏能更有效地拓展基础模型的能力边界。强化学习更像是提升了模型找到已有解法的效率,而蒸馏通过学习更强教师模型的思维模式,能让小模型学会它原本不具备的新推理能力。因此,验证蒸馏模型,也是在验证一种更强大的能力注入方式。
总而言之,使用蒸馏模型验证推理性能的优势在于,它将验证工作从“不计成本的理论探索”转变为“兼顾效率与效果的工程实践”。它让你能以更低的成本、更快的速度、在更贴近真实场景的环境中,去确认一个模型是否具备了满足实际需求的、足够优秀的推理能力。
弹性内存扩展:
在模型推理中,使用弹性内存扩展技术的核心优势在于打破显存(VRAM)的物理限制,从而以更低的成本实现更高的并发量、更快的响应速度和更长的上下文处理能力。
简单来说,它让昂贵的GPU不再因为“显存装不下”而被迫闲置,而是通过借用系统内存(DRAM)或高速存储,让推理服务更加流畅和经济。
以下是具体的四大优势:
1. 显著提升并发能力(吞吐量翻倍)
大模型推理时,显存通常被两部分占用:模型参数(权重)和 KV Cache(上下文记忆)。
传统痛点: 为了保证速度,KV Cache 必须放在显存里。但显存有限,一旦存满,系统就无法处理新的并发请求,或者必须拒绝长文本请求。
弹性扩展优势: 通过将 KV Cache 卸载(Offloading) 到容量更大的系统内存(DRAM)或弹性内存服务(EMS)中,显存被释放出来处理更多的计算任务。
效果: 单张显卡的并发请求数可以翻倍。例如,华为云的数据显示,使用弹性内存扩展后,单卡并发从 8 个提升到了 16 个,推理吞吐量提升了 100%。
2. 降低首字延迟(“以存代算”)
在多轮对话场景中,用户的历史提问和模型的回答构成了庞大的上下文。
传统痛点: 为了省显存,系统通常会丢弃上一轮对话的 KV Cache。当用户发起新一轮对话时,系统必须重新计算所有历史信息的 KV 值,导致首字延迟(TTFT)往往超过 1 秒,用户会感到明显的卡顿。
弹性扩展优势: 利用弹性内存的大容量,系统可以将历史对话的 KV Cache 持久化保存下来。当用户继续提问时,直接读取缓存,无需重复计算。
效果: 首字延迟可降低 80% 以上(例如从 1 秒降至 0.2 秒以内),带来“秒回”的丝滑体验。
3. 支持超长上下文(长文本处理)
随着大模型处理长文档、长视频的需求增加,上下文窗口(Context Window)越来越大(如 128k, 262k tokens)。
传统痛点: 长文本的 KV Cache 极其占用显存。如果不做优化,处理长文本时显存瞬间溢出(OOM),导致推理失败。
弹性扩展优势: 弹性内存技术(如 eLLM、FlexGen 等)允许显存和内存之间动态借调空间。当显存不足时,自动将不活跃的数据“交换”到内存中,从而支持远超显存物理限制的超长上下文。
效果: 即使是消费级显卡,也能运行需要超长上下文的模型,或者在高端显卡上处理 262k 甚至更长 的文本序列。
4. 降低硬件成本(减少 GPU 堆砌)
传统痛点: 为了运行更大的模型(如万亿参数模型)或应对高并发,企业通常需要购买更多的大显存 GPU(如 A100/H100),成本极高。
弹性扩展优势: 通过“显存扩展”,可以用较少的 GPU 卡数存下同样的模型。例如,通过分层存储,将不频繁更新的参数放在廉价的高速内存中,频繁计算的放在显存中。
效果: 部署万亿参数模型所需的 NPU/GPU 数量可减少 50%,大幅降低了基础设施建设成本。
|
维度 |
传统推理模式 |
弹性内存扩展模式 |
核心收益 |
|
显存管理 |
显存满了就报错或排队 |
显存与内存动态交换,自动扩容 |
不再受物理显存限制 |
|
多轮对话 |
每次都要重新计算历史 |
历史 KV Cache 缓存复用 |
响应速度提升 5-10 倍 |
|
并发能力 |
受限于 KV Cache 大小 |
KV Cache 卸载至内存 |
单卡并发提升 2 倍 |
|
硬件成本 |
需堆砌昂贵的高显存显卡 |
可用较少显卡+大内存替代 |
算力成本节省 50% |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)