企业知识库怎么做,才不会变成新的资料堆?
很多企业在数字化转型中,都得了一种名叫“知识囤积症”的时代病:花几十万买了一套知识管理系统(KMS),号召全员把方案、规章、图纸上传到系统里。然而不出半年,这个系统就变成了一个巨大的、无人问津的“数字垃圾场”。为什么?因为企业知识库不是把 PDF 全部丢进系统,而是先把资料整理成可被大模型检索和复用的知识。在 AI 时代,静态的文本如果不被激活,毫无价值。逐米时代长期聚焦企业知识沉淀与 RAG(检索增强生成)技术,我们认为,真正的知识库不是用来“存”的,而是用来“答”的。今天,我们就来彻底讲透,如何搭建一个“活”的企业知识库。
 图 1:如果不建立有效的检索机制,企业知识库最终都会变成落满灰尘的档案馆
图 1:如果不建立有效的检索机制,企业知识库最终都会变成落满灰尘的档案馆
一、为什么传统的知识库注定会“脑死亡”?
著名作家博尔赫斯在一篇名为《巴别图书馆》的小说中,构想了一个包含世间所有书籍的无尽图书馆。然而,里面的人却处于极度绝望之中——因为书籍太多,且没有检索目录,人们终其一生也无法找到自己需要的那一页。这,简直就是现代企业知识库的完美写照。
当一个新员工接到任务:“请查一下我们公司去年对头部互联网客户的通用报价折扣标准。”他打开公司的知识库,输入关键词“互联网 报价 折扣”。系统转了两秒圈圈,吐出了 150 份包含这些词汇的 Word 和 PDF 文件,这些文件里甚至包括了三年前的废弃草案和同事的周报。
面对这 150 份文件,员工崩溃了,他最终选择去微信上拍一拍老员工。这就是传统知识库走向“脑死亡”的全过程。人们缺的从来不是信息,而是从海量信息中提取答案的“确定性”。
二、信息的“坟墓”与知识的“引擎”
信息论的奠基人克劳德·香农(Claude Shannon)提出,信息的本质是“用来消除不确定性的东西”。如果一个系统给出的结果让你更加困惑,那它提供的就不是信息,而是噪音。
传统知识库为什么难用?因为它采用的是“关键词匹配(Keyword Matching)”技术。这种技术极其死板,它只认字,不认理。你搜“离职补偿”,如果文档里写的是“辞退违约金”,系统就搜不出来。
而大模型时代的 RAG(检索增强生成)知识库,引入了“语义空间”的概念。它不仅把字存了下来,还把字的“灵魂(含义)”存了下来。真正关键的不是你存了多少个 GB 的文件,而是当员工提出一个业务问题时,AI 能不能瞬间锁定文件中的某一段话,并直接生成答案。
 图 2:从“给一堆文件”到“给一个答案”,是知识库的跨时代进化
图 2:从“给一堆文件”到“给一个答案”,是知识库的跨时代进化
三、知识库建设的 3 个致命误区
在企业试图用大模型重构知识库时,往往会因为认知偏差而重蹈覆辙:
- 误区一:把原始文档当成知识“直供”给 AI。
很多企业以为只要接了某个大模型的 API,然后把几百兆的标书丢进去,它就能融会贯通。其实不然。一本排版复杂的画册,大模型根本不知道标题在哪、表格的表头是什么。没有经过深度的 OCR(光学字符识别)和版面分析,强行喂给 AI 的数据,只会产出令人哭笑不得的“AI 幻觉”。 - 误区二:重“模型”,轻“检索”。
在 RAG(检索增强生成)技术中,“检索”的质量占了结果好坏的 80% 权重。如果你公司库里搜出来的本身就是错误的、过期的、不相关的段落,大模型的文笔再好,也只能写出一篇“优美的废话”。 - 误区三:忽略了极其重要的“权限隔离”。
传统网盘有严格的权限体系,但很多早期的 AI 知识库做不到。结果就是一个普通实习生,通过向 AI 提问巧妙的话术,套出了公司核心高管的薪酬架构。企业知识库,必须在向量级实现数据的行级/列级权限控制。
四、让知识“活”起来的 4 个关键环节
一个真正好用、不会变成资料堆的企业知识库,在底层必须经历四道精密的手术(这就是 RAG 核心链路):
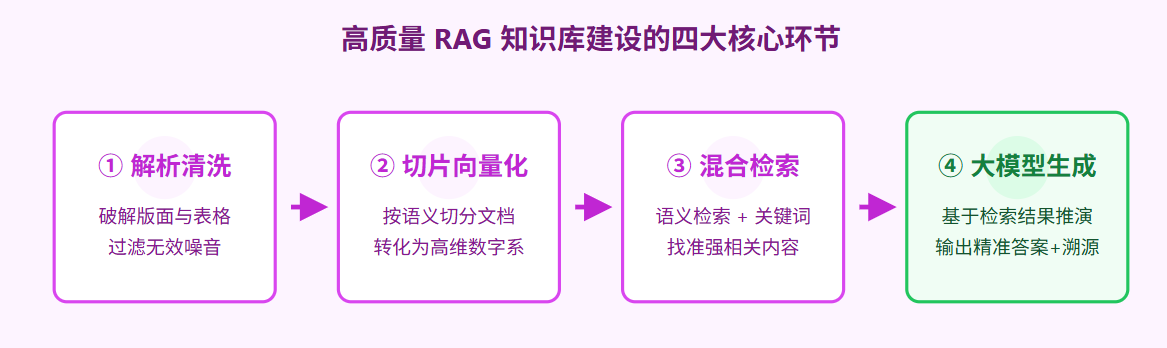 图 3:知识库从物理文档转化为智能问答的 4 个关键工序
图 3:知识库从物理文档转化为智能问答的 4 个关键工序
1. 解析与清洗(打破文档的物理结界)
企业资料不是干净的 TXT 文本,而是长达几百页的双栏 PDF、带合并单元格的复杂报表、甚至包含红头文件的扫描图。第一步,需要使用高级的文件解析引擎,把文档里的文字、表格、图像结构化地“抠”出来。去除掉页眉页脚、空白页等噪音,留下纯粹的信息骨架。
2. 切片与向量化(给知识赋予数学灵魂)
一本 300 页的手册太长了,大模型一口吃不下,也容易抓错重点。因此,我们需要将清洗后的文本按逻辑(比如按段落、按章节标题)切分成一个个小的“知识切片(Chunk)”。接着,将这些切片送入向量模型,把人类的自然语言翻译成高维空间的“数学坐标”。这段文字谈论的理念越相似,它们在宇宙中的距离就越近。
3. 混合检索(AI 时代的智能捕网)
当员工提问时,系统会用同样的机制把问题变成数学坐标,然后在向量库里寻找距离最近的知识切片。为了极致的准确,业内现在普遍采用“混合检索”——即不仅对比语义的相似度(向量检索),同时还保留了极其严谨的字面词汇比对(BM25 关键词检索),确保专有名词绝不匹配错。
4. 基于约束的生成与流转(大模型的“开卷考试”)
最后一步,系统把员工的问题,连同刚刚检索出来的最相关的几个“知识切片”,一起发给大模型。大模型基于这几张“小抄”进行汇总、推演,生成一句人话,并附带上文件链接。随后,这个答案会通过钉钉、企业微信或者内部 OA,无缝流转到员工眼前。
五、哪些企业最迫切需要 RAG 知识库?
判断你的企业是否需要立刻升级 RAG 知识库,只需审视一个核心指标:企业中是否流转着大量需要反复查阅的标准规范,且人员咨询耗时极长?
- 制造业与高端装备: 产品型号众多,设备维修手册动辄上百页。售后工程师在客户现场遇到故障,不可能去翻书,他们需要问 AI:“报错代码 E404 怎么处理”,并要求立刻得到维修步骤图。
- 法律与政企服务机构: 过往的判例、各省市繁复的招投标文件。员工需要迅速比对几十份历史标书中的特定条款。
- 大规模的人事与客服中心: 新员工入职培训、客服话术培训。他们需要一个 24 小时在线的智能助理,基于公司最新更新的培训材料,随时解答各种极度边缘的奇葩问题。
让企业的隐性记忆,成为第一生产力
彼得·德鲁克曾说,21世纪企业最有价值的资产,是知识工人和他们的生产力。然而现实是,知识工人们每天把 30% 的时间浪费在“找一份不知道在哪里的文件”上。传统知识库只是提供了一个巨大的地下室,而 AI 时代,我们需要的是一台精密的物流传送带。
不要再让企业用血汗沉淀下来的宝贵经验,在网盘里发霉了。作为在 AI 大数据与智能体落地领域的实战派,逐米时代深知 RAG 知识库的搭建绝非一日之功。我们为企业提供的,不是一套空壳的搜索软件,而是一条涵盖复杂文档解析、向量检索调优、私有化安全部署的完整知识链路。让每一次搜索都能触达真知,让企业的隐性记忆,真正化作驱动组织向前的第一生产力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)