从YOLO,RCNN到DETR和deformable-DETR
从 YOLO 到 DETR 到 Deformable DETR
—— 只聚焦 Detection:anchor 到底是不是必须的?
这篇帖子我只干一件事:把 object detection 这条主线讲透,而且只围绕一个最容易被说空的话题展开——anchor 到底是不是必须的。
结论我先扔出来,免得你后面又被一堆模型名绕晕:
Anchor 不是必须的。
但几何先验(geometric prior)、正负样本分配机制(assignment)、去重机制(duplicate suppression)、多尺度建模(multi-scale modeling),这些东西一个都跑不掉。
你能去掉的是 anchor box 这种具体实现,你去不掉的是 detection 这件事本身的结构性难题。
1. 先把 detection 任务本身看清楚:它到底难在哪?
目标检测不是单纯分类。分类只回答 what,而检测要同时回答 what + where + how many。这立刻带来四个硬问题:
第一,候选位置特别多;第二,类别和位置要一起学;第三,同一个物体可能会被多次命中,必须去重;第四,尺度变化极大,小目标尤其难。R-CNN 时代的方案是先做 proposal,再分类;one-stage 时代的方案是 dense prediction;DETR 时代则试图把它改写成 direct set prediction。你必须从这几个问题出发看模型,否则永远在记“架构八股”,根本没理解范式。
更直白一点说:
anchor 之争,本质不是“用不用一个框模板”这么浅,而是“模型如何把连续空间上的目标实例,转成可训练的监督对象”。这件事在不同时代有不同答案:
- R-CNN:先找候选区域,再分类回归。
- Faster R-CNN / RetinaNet / YOLOv2-v3:用 anchor 把连续空间离散化。
- FCOS / YOLOX:按点或中心做 dense prediction,anchor-free。
- DETR:直接把目标当作一个集合,用 bipartite matching 一次性分配。
2. R-CNN:检测的第一阶段,本质是“先候选,后识别”
R-CNN 的经典之处,不在于它今天还能不能打,而在于它第一次把深度 CNN 真正压进现代 detection pipeline。它的系统由三个模块组成:
(1) 生成 category-independent region proposals;(2) 对每个 proposal 提 CNN feature;(3) 用 class-specific SVM 做分类。 原始 R-CNN 对每张图大约抽 ~2000 个 proposals,每个 proposal warp 成固定尺寸,再分别跑 CNN。这个思路当年很强,但代价巨大:它本质上是“对候选框逐个分类”。
注意这里一个关键事实:R-CNN 还没有 anchor 这个核心结构。
它靠的是 external proposals,例如 selective search。也就是说,早期 detection 并不是“天然就需要 anchor”;它首先需要的是某种 candidate generation mechanism。在 R-CNN 里,这个机制是外部 proposal 算法,而不是网络内部的 anchor design。
但 R-CNN 的缺陷也极其致命。Fast R-CNN 论文对它批得很直接:
R-CNN 是一个 multi-stage pipeline,先 fine-tune ConvNet,再训练 SVM,再训练 bbox regressor;而且需要把 proposal features 写盘缓存,训练和测试都很慢。Fast R-CNN 甚至明确写到:在 VGG16 下,R-CNN 的测试速度可以慢到 47 秒/图,因为它对每个 proposal 都单独做一次前向传播。这个代价决定了它不可能成为真正的工业常规形态。
3. Fast R-CNN:共享卷积,把“每框一遍 CNN”变成“整图一次 CNN”
Fast R-CNN 的核心贡献不是 proposal,而是 shared computation。它先对整张图做卷积,得到 shared feature map,然后对每个 proposal 做 RoI pooling,把任意大小的候选区域映射成固定大小特征,再接分类和回归头。论文明确写了,RoI pooling 会把任意 valid RoI 里的特征变成固定空间尺寸,比如 7×7。这一下把 R-CNN 那种 per-proposal CNN 计算彻底干掉了。
更重要的是,Fast R-CNN 把训练改成了 single-stage multi-task loss:分类和框回归一起学,不再像 R-CNN 那样拆三段跑。论文直接把 R-CNN 的多阶段、写盘、慢测试作为痛点,而把 Fast R-CNN 的优势总结成:更高 mAP、单阶段训练、所有层可更新、不需要 feature caching。这个变化非常关键,因为它说明 detection 的第一条进化主线是:共享特征 + 端到端程度提升。
但是,Fast R-CNN 仍然没有解决 proposal 来源问题。
它只是把 “proposal 之后的识别” 做快了,却没有把 “proposal 本身” 内生进网络。proposal 依然是瓶颈。Faster R-CNN 之所以诞生,正是因为这个瓶颈已经暴露得太明显。
4. Faster R-CNN:anchor 真正成为主角的地方
Faster R-CNN 的革命点,是把 proposal generator 也卷进神经网络内部,变成 Region Proposal Network (RPN)。论文直说:过去 state-of-the-art detectors 依赖 region proposal algorithms,而 Fast R-CNN 把 detector 加快以后,proposal 计算反而成了瓶颈;RPN 的目标就是把 proposal 变成共享卷积特征上的一个几乎“免费”的子网络。
而 anchor,就是 RPN 里把“proposal generation”变成可学习 dense prediction 的核心离散化工具。
Faster R-CNN 在每个 sliding position 上放若干 reference boxes,论文里用的是 3 scales × 3 aspect ratios = 9 anchors。网络不是直接从零生成框,而是相对这些 anchors 输出 objectness 和 box regression。对于一个 (W \times H) 的 conv feature map,总共有 (WHk) 个 anchor hypotheses。这个设计第一次把“候选框空间”系统化地参数化了。
你必须理解:
anchor 的本质作用不是“让模型有框可画”,而是让连续空间上的 box search 变成离散候选上的局部修正问题。
这会带来三件事:
- 先验尺度和长宽比被显式编码进模型;
- 正负样本分配可以通过 IoU 阈值完成;
- box regression 的学习目标变成“相对 anchor 的偏移”。
Faster R-CNN 的正负样本分配方式非常典型:
一个 anchor 若与某个 gt 的 IoU 超过阈值,或是某个 gt 的最高 IoU anchor,就会被标成 positive;低于下阈值则为 negative。论文明确写了:一个 ground-truth box 可能给多个 anchors 分配 positive labels。这句话很重要,因为它揭示了 anchor-based training 的本质:
它不是 one-to-one,而是 one-to-many supervision。
这就是 anchor-based dense detection 后来能训得很稳的原因:
监督信号密,recall 高,优化路径短。
但代价也从这里开始累积:
- 你要选 anchor 尺寸和比例;
- 你要定 IoU 正负阈值;
- 你要处理海量 easy negatives;
- 你还得做 NMS 去掉重复 proposal。Faster R-CNN 论文里明确写到 RPN 测试时会用 NMS 压冗余,并保留 top proposals。
所以,anchor 不是免费午餐。
它是一种非常有效的工程折中:用大量先验和启发式,把 detection 变成一个好优化的问题。 这就是它后来统治一大批 detector 的原因。
5. YOLOv1:它其实先于很多 anchor-based one-stage,走的是“直接回归”路线
很多人现在一提 YOLO,就下意识把它和 anchor 绑定,这是错的。
YOLOv1 本身不是 anchor-based detector。 它把 detection 明确表述为一个 regression problem:输入整张图,输出 bounding boxes 和 class probabilities。模型把图像划成 (S \times S) grid,每个 grid cell 预测 (B) 个框和对应 confidence;如果一个物体的中心落入某个 cell,就由这个 cell 负责预测该物体。论文还给出了 confidence 的定义:
(\text{Pr(Object)} \times \text{IoU})。([CV Foundation][3])
这意味着 YOLOv1 的核心思想是:
不要 proposal,不要 per-region classification,直接整图一次前向,端到端回归最终检测结果。
这在范式上非常激进,也非常漂亮。它比 R-CNN 家族更像今天大家口中的 “end-to-end detector”,虽然它并没有 DETR 那套 set prediction 理论。([CV Foundation][3])
但你别神化 YOLOv1。
它的直接回归虽然快,但约束也很死:
- 一个 cell 负责中心落在其中的物体;
- 网格太粗时,小目标和密集目标天然吃亏;
- 分类和定位强耦合;
- 负样本过多时,confidence learning 很容易失衡。YOLOv1 论文自己就指出:大量不含目标的网格会把 confidence 往 0 推,容易淹没真正含目标的网格梯度,导致训练不稳定。
所以,YOLOv1 证明了两件事:
第一,不用 proposal 也能做 detection;
第二,不用 anchor 也不是没有代价。
它只是把“候选框设计”的问题,换成了“网格责任分配 + 粗粒度回归”的问题。
6. 为什么后来一大批 one-stage detector 又走回了 anchor?
因为 YOLOv1 的“纯直接回归”太硬。
它快,但对尺度变化、长宽比变化、密集目标重叠的适应性不够。于是后来的 one-stage detector 大多转向了 anchor-based dense prediction:不是让每个位置从零猜框,而是让每个位置基于若干先验框去做局部修正。RetinaNet、SSD、YOLOv2/v3,本质上都站在这条思路上。([CVF开放获取][4])
RetinaNet 之所以值得插进来,不是因为它属于 YOLO,而是因为它点明了 anchor-based dense detectors 的另一个根本难题:
extreme foreground-background class imbalance。论文直接说,这是 one-stage dense detectors 过去精度落后 two-stage 的中心原因;Focal Loss 的作用就是压低大量 easy negatives 对训练的主导。你不理解这件事,就不理解为什么 anchor-based dense detection 后来需要那么多 loss engineering。([CVF开放获取][4])
换句话说,anchor-based one-stage 之所以能站稳,是因为它做了两层工程折中:
- 第一层:用 anchor 把 box space 离散化;
- 第二层:用 Focal Loss 一类方法处理 dense negatives。
这套系统很强,但也很“脏”:超参数多、设计自由度大、迁移时需要重新调。([CVF开放获取][4])
7. YOLOv2 / YOLOv3:YOLO 家族正式进入 anchor-based 时代
YOLOv2 明确引入了 anchor boxes。论文写得很直白:它移除了全连接层,改用 anchor boxes 预测 bounding boxes;同时类别预测从原来按 cell 绑定,变成对每个 anchor box 预测 class 和 objectness。它还直接承认:使用 anchor boxes 后,模型会从原来很少的 boxes 变成上千个预测,这会带来 recall 的提升。([ar5iv][5])
更关键的是,YOLOv2 并不是简单照搬 Faster R-CNN 的 anchor 偏移形式。
论文专门讨论了一个问题:直接按 RPN 那种 unconstrained offset 去预测 box center,会导致早期训练不稳定。因此 YOLOv2 用了更受约束的参数化:中心坐标相对 grid cell 位置做 sigmoid 约束,宽高则相对 dimension priors 做指数变换。这本质是在说:
“我要 anchor,但我要一种更容易学的 anchor parameterization。”([ar5iv][5])
YOLOv2 还有一个很有价值的动作:dimension clustering。
它不想手工拍脑袋选 anchor 尺寸,于是对训练集上的 box dimensions 做 k-means,得到 data-driven priors。论文甚至明确比较了 hand-picked anchor boxes 和 clustering priors 的平均 IoU,说明 clustering 让起始表示更适合数据分布。这里你要看穿一件事:
anchor 的价值从来不在“框模板”本身,而在于把数据分布编码成优化起点。([ar5iv][5])
到了 YOLOv3,这条思路继续强化:
它仍然使用 dimension clusters 作为 anchor boxes,同时开始显式做 多尺度预测。论文明确写到:YOLOv3 在 3 个不同尺度上预测 boxes,并借鉴了类似 FPN 的思想;在 COCO 上每个尺度预测 3 个 boxes,总共 9 个 priors。这里的逻辑很清楚:anchor-based dense detection 真正变强,不只是因为有 anchor,而是因为 anchor + multi-scale feature hierarchy 一起上了。
所以从 YOLOv1 到 YOLOv2/v3,你应该得到的不是“YOLO 后面都得靠 anchor”,而是更精确的结论:
YOLOv1 证明了无需 proposal 的整图回归可行;YOLOv2/v3 证明了,在 one-stage dense setting 下,anchor 是一种非常有效的工程增强手段。([CV Foundation][3])
8. Anchor 真正解决了什么?又带来了什么新问题?
它解决的东西
anchor 主要解决三件事。
第一,提供显式几何先验,让不同尺度和长宽比的目标在训练初期更容易对上;第二,把 box 回归从“从零预测绝对框”改成“相对 reference 的局部修正”,通常更容易优化;第三,通过 one-to-many assignment 增加正样本密度,提高 recall。Faster R-CNN 的 RPN、YOLOv2/v3 的 dimension priors,本质都在做这个。
就这个词儿原本在英语里面是那个航海的船的锚,抛锚的那个⚓️,这玩意儿干嘛的?那就是让船可以依靠,说白了就是先给个大概得位置让你有法可依,所以就好比我们在数据集先找出常见分布的boundingbox尺寸作为anchor就很合理,inference阶段出现的BBox大概率就在这个框的尺寸附近波动,收敛回来肯定会更快。
它带来的副作用
但 anchor 同时引入了一长串系统复杂度:
- 尺寸和比例怎么选;
- 不同层分配哪些 anchor;
- 正负样本阈值怎么定;
- 忽略区间怎么定;
- 大量 dense negatives 怎么压;
- 最后重复框怎么靠 NMS 清掉。
FCOS 论文专门批评了这一点:预定义 anchor boxes 带来了复杂计算和很多对最终精度很敏感的超参数,而这些都是 heuristic tuning。
这就是 brutal truth:
anchor 不是“必要条件”,它更像一个历史上极成功的 optimization scaffold。
它之所以统治多年,是因为它把 detection 这个难问题拆成了一个工程上特别好训的形式;但一旦你找到更好的 assignment 和更好的 representation,它就可以被替代。
9. 重要插曲:FCOS 证明了“anchor-free dense detector”在 CNN 时代就成立
这里必须插一句,否则很多人会产生错觉,以为“去 anchor”必须等到 Transformer / DETR。不是。
FCOS 在纯 CNN 的 one-stage dense setting 下,就明确提出:几乎所有主流 detector 都依赖预定义 anchor boxes,而它要做一个 anchor box free, proposal free 的 detector。它把 detection 改成更像 semantic segmentation 的 per-pixel prediction:一个位置若落在某个 gt box 内,就预测到该 box 四边的距离。([CVF开放获取][6])
FCOS 的意义非常大,因为它证明了:
你完全可以保留 dense prediction + CNN + NMS 这条路线,同时把 anchor 删掉。
也就是说,anchor-free ≠ 非 dense;anchor-free ≠ 非 CNN;anchor-free ≠ 必然 NMS-free。 这是很多人最容易混淆的地方。FCOS 仍然使用 NMS,只是避免了 anchor-related 计算与超参数。([CVF开放获取][6])
这对理解后来的 YOLOX 也很重要。
YOLOX 明确写到,它把 YOLO detector 切换成了 anchor-free manner,再配合 decoupled head 和 SimOTA label assignment,取得了很强的结果。它等于在 YOLO 体系内部承认了一件事:
YOLO 家族并不被 anchor 绑定;真正绑定它的是实时 dense detection 的范式。([arXiv][7])
10. DETR:它不是“去 anchor”这么简单,它是把 detection 问题重写了
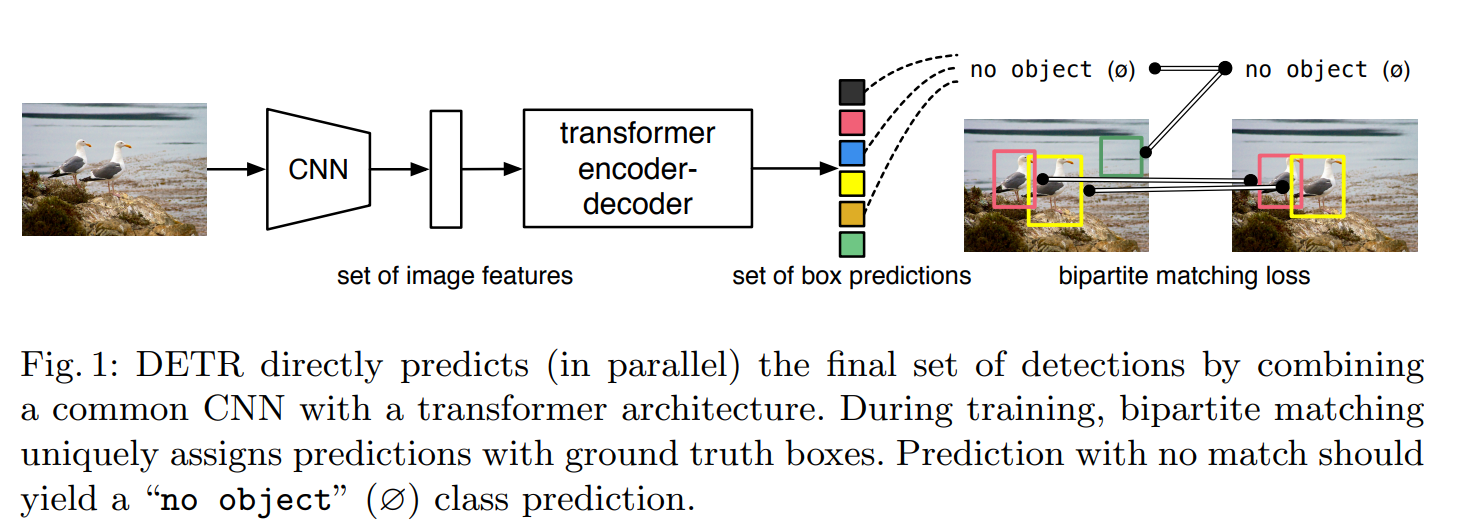
DETR 的真正革命,不是 Transformer 三个字,而是它把 detection 明确定义成了 direct set prediction。论文开篇就说,它试图去掉现代 detector 中大量 hand-designed components,比如 anchor generation 和 NMS;核心是 set-based global loss + bipartite matching。这意味着它不再沿用 dense prediction + post-hoc suppression 的传统流程,而是直接让模型输出一个目标集合。
DETR 的架构可以概括成:
CNN backbone 提 2D feature,flatten 后加 positional encoding,送入 Transformer encoder;decoder 接收一组 object queries,每个 query 最终独立输出一个 class + box,或者输出 “no object”。论文明确说 decoder 输入的是一小组 learned positional embeddings,也就是 object queries;每个输出通过共享 FFN 预测 detection 或 no-object。
最关键的是训练目标。
DETR 不再像 anchor-based detector 那样做 one-to-many IoU assignment,而是对预测集合和 gt 集合做 optimal bipartite matching。论文直接给出:先找一个代价最小的 permutation,再在 matched pairs 上计算分类和 box loss,这个最优匹配通过 Hungarian algorithm 计算。这个设计把“谁负责哪个 gt”从 heuristic IoU rule,改成了全局最优的一对一分配。
你必须看到这背后的范式变化:
- Faster R-CNN / RetinaNet / YOLOv3:one-to-many assignment + NMS
- DETR:one-to-one assignment + no-object class
于是 DETR 不再需要 anchor,也不再需要依靠 NMS 在推理后把重复框砍掉,因为训练时它已经强迫预测集合学成“每个真实物体只由一个预测负责”。这才是它比“anchor-free”更深的一层。
11. 但 DETR 不是完美答案:它去掉了 anchor,也去掉了很多“好训的偏置”
别浪漫化。
DETR 很优雅,但原版的优化代价非常高。论文里给出的实验细节表明,它用了远长于常规 detector 的训练 schedule;同时 Deformable DETR 论文进一步直说:DETR 在 COCO 上需要 500 epochs 才能收敛,约比 Faster R-CNN 慢 10 到 20 倍。
为什么会这样?因为你删掉的不只是 anchor,也删掉了很多“局部几何归纳偏置”。
在 anchor-based detector 里,某个位置配哪些尺度、哪些长宽比、怎么通过 IoU 变成正样本,这些都帮模型把搜索空间压缩了。DETR 则要从 object queries 出发,在全局注意力里自己学会“谁该负责哪里、哪个框对哪个 gt”。这更干净,但也更难。
另一个明确问题是小目标。
DETR 论文自己承认,它在 APS 上落后 Faster R-CNN;而 Deformable DETR 论文则更直白地指出:DETR 对 small objects 表现相对较低,因为现代 detectors 通常依赖 multi-scale features,而原始 Transformer attention 在高分辨率 feature maps 上代价太高。
所以,别再说“DETR = 不要先验,更先进”。
更准确的话是:
DETR 用更少的手工规则,换来了更重的优化难度。
它不是无先验,而是把原来显式写死在 anchor / NMS / assignment 里的先验,改成了 object queries、global attention 和 bipartite matching 这套形式。
12. Deformable DETR:它不是回到 anchor,而是把“几何偏置”以更优雅的形式加回来
Deformable DETR 的出发点非常明确:
原始 DETR 有两个硬伤——收敛慢、小目标差。为解决这个问题,它提出 deformable attention,让 attention 不再对整张 feature map 做 dense 全局扫描,而是只在一个 reference 周围采样少量关键点。论文摘要直接写到:其 attention modules only attend to a small set of key sampling points around a reference,因此在更少训练轮数下获得更好的表现,尤其对 small objects 更好。
这里最容易被误解的点是:
Deformable DETR 不是把 anchor 捡回来。
它引入的是 reference point,不是预定义的多尺度多比例 anchor box bank。reference point 更像一个可学习的几何索引或初始对齐位置;它让 query 的注意力集中在少数有意义的采样点上,从而大幅缓解原始 DETR 那种“全图搜、全局配”的笨重优化。
更进一步,Deformable DETR 还显式接入了 multi-scale feature maps。论文说明它在 encoder 中用 multi-scale deformable attention 处理 feature maps,并强调这能在没有传统 FPN top-down 结构帮助的情况下整合多尺度信息。与此同时,它在摘要和引言部分明确给出结果:相比 DETR,Deformable DETR 用 10× fewer training epochs 达到更好性能,尤其在小目标上改进明显。
这件事的本质是:
原始 DETR 去掉了太多结构性偏置;Deformable DETR 没回到 anchor,而是把“几何偏置”以 reference-based sparse attention 的方式重新注入。
这说明什么?
说明 detection 不可能彻底脱离几何归纳偏置。区别只在于:
你是用 hand-crafted anchors 注入,还是用 learned sparse reference mechanism 注入。
13. 把整条线拉直:proposal、anchor、point、set prediction 分别在解决什么?
你可以把 detection 的主流路线简化成四代:
第一代:proposal-based(R-CNN / Fast R-CNN)
先生成候选区域,再对候选区域分类回归。
核心问题是:proposal 太重、训练分阶段、推理太慢。
第二代:anchor-based dense detection(Faster R-CNN / RetinaNet / YOLOv2-v3)
通过 anchor 把 box space 离散化,做 one-to-many dense supervision。
核心优点是:好训、recall 强、多尺度长宽比可显式建模。
核心代价是:超参数多、正负样本不平衡、后处理依赖 NMS。
第三代:anchor-free dense detection(FCOS / YOLOX)
保留 dense prediction,但去掉 anchor box 这层显式模板。
核心优点是:设计更简洁,避免 anchor-related tuning。
核心代价是:仍然要解决 assignment、center prior、NMS 等问题。([CVF开放获取][6])
第四代:set prediction / NMS-free detection(DETR / Deformable DETR)
不再 dense enumerate + NMS,而是直接输出目标集合。
核心优点是:训练目标更统一,pipeline 更干净。
核心代价是:优化更难;原始版本收敛慢,小目标弱;Deformable DETR 则通过 sparse multi-scale attention 做了现实修复。
14. 所以,anchor 到底是不是必须的?
我的结论非常明确:
不是必须的。
但你要把这句话说完整:
14.1 anchor 不是 detection 的必要条件
R-CNN 没靠 anchor;YOLOv1 没靠 anchor;FCOS 明确是 anchor-free;DETR 明确去掉 anchor generation。
因此,任何“检测必须靠 anchor”之类的话,都是过时甚至错误的。
14.2 anchor 曾经是最成功的工程解之一
Faster R-CNN、RetinaNet、YOLOv2/v3 这一整代 detector 的强势,说明 anchor 是一种极强的 practical prior。它把学习问题变简单,把 recall 顶起来,把多尺度/比例编码进去。对很长一段时期的工业场景来说,它不是理论最优,但它非常有效。
14.3 去掉 anchor,不等于去掉先验
这是最关键的一句。
FCOS 用 center-ness 和 per-pixel assignment;DETR 用 object queries 和 Hungarian matching;Deformable DETR 用 reference points 和 sparse sampling。
你能去掉的是 anchor boxes,你去不掉的是 “谁负责哪个目标” 和 “如何编码几何关系” 这两个核心问题。([CVF开放获取][6])
14.4 真正的问题不是“要不要 anchor”,而是“你准备用什么来替代它的作用”
如果你去掉 anchor,却没有提供足够强的 assignment 机制、中心先验、multi-scale 结构或者 set-level matching,那你不是先进,你只是把问题从显式模块里删掉,最后让优化崩掉。原始 YOLOv1 的一些局限、原始 DETR 的慢收敛,本质上都说明了这一点。([CV Foundation][3])
15. 一个很多人嘴上不说、但工程上必须承认的事实
Anchor-free 这个词,营销味太浓。
真正重要的不是“free”,而是你背后有没有一套更强的训练归纳偏置。
- Faster R-CNN 的偏置是 anchor + IoU thresholds + proposal ranking + NMS。
- YOLOv3 的偏置是 grid cell + dimension priors + multi-scale heads。
- FCOS 的偏置是 point-based regression + center-ness + FPN。
- DETR 的偏置是 object queries + bipartite matching + no-object class。
- Deformable DETR 的偏置是 reference point + sparse multi-scale deformable attention。
所以别再用那种幼稚判断:
“有 anchor 就落后;没 anchor 就先进。”
这是典型的外行视角。
专业判断应该是:这个 detector 用什么机制在完成 candidate parameterization、assignment、duplicate handling 和 multi-scale modeling。
16. 如果你是做工程,该怎么选?
16.1 你追求的是成熟、稳定、可解释、调参路径清晰
Faster R-CNN / RetinaNet 这类体系依然有价值。
尤其是在你需要很强的 proposal quality、成熟生态、明确的正负样本控制时,anchor-based two-stage 或 dense one-stage 方案仍然是靠谱选择。它们的 heuristic 多,但也正因为 heuristic 多,所以很多行为是“可控的”。
16.2 你追求的是实时部署、工业吞吐、边缘侧友好
YOLO 系路线更自然,尤其是 YOLOv2/v3 以后那种 multi-scale dense detection 范式;而 YOLOX 这类 anchor-free YOLO 说明实时路线并不必然依赖 anchor。重点不在“是不是 YOLO”,重点在它是否给你足够好的 speed/accuracy tradeoff 和部署链路。
16.3 你追求的是更统一的端到端目标、减少 hand-crafted post-processing
那就看 DETR 系列,尤其是 Deformable DETR 之后的版本。
原始 DETR 更像“理论范式转换”;Deformable DETR 才更接近“可用的端到端 detection backbone”。
17. 面试时应该怎么讲,才像真的懂了
可以这样说:
“Object detection has evolved from proposal-based pipelines to anchor-based dense prediction, then to anchor-free dense prediction, and finally to set-prediction-based end-to-end detectors. Anchors are not fundamentally required for detection, but they were a very effective way to inject geometric priors, simplify assignment, and improve optimization. Removing anchors does not remove the need for inductive bias; it only forces the model to encode that bias elsewhere, such as point-based assignment in FCOS or bipartite matching and object queries in DETR. Deformable DETR further shows that even end-to-end detectors still benefit from explicit geometric structure, through reference points and sparse multi-scale attention rather than handcrafted anchors.”
这段话的价值在于:
它没有停留在“哪个模型快、哪个模型准”,而是直接命中 detection 演化的本质:
你用什么形式表达空间先验,如何分配监督,如何处理重复预测。
18. 最后的结论:真正该记住的,不是模型名,而是 detection 的三次哲学转向
第一次转向:
从 region classification 到 shared-feature detection
——R-CNN → Fast/Faster R-CNN。
第二次转向:
从 proposal-based 到 dense prediction
——Faster R-CNN / RetinaNet / YOLO。
第三次转向:
从 anchor / NMS / heuristic assignment 到 set prediction / matching-based end-to-end detection
——DETR → Deformable DETR。
而贯穿这三次转向的那条暗线,就是你问的这个问题:
Anchor 不是必须的;但 detection 永远需要某种形式的几何先验与分配机制。
旧时代用 anchor,新时代用 point、query、reference、matching。
形式在变,问题没变。([CVF开放获取][6])
A more natural English phrasing would be:
“I need this in the style of a technical article. Don’t mention interviews or use a conversational tone. I’m going to copy it as a technical post. What’s already written is fine; I’ll edit it myself. Please continue with the next part.”
19. 训练目标、样本分配与框参数化:从 R-CNN 到 Deformable DETR 的核心差异
如果只从网络结构图出发理解检测器,结论通常会非常肤浅。真正决定一个 detector 行为边界的,往往不是 backbone 或 neck,而是三件更底层的机制:训练目标(objective)、样本分配(assignment)、以及 bounding box parameterization。同样是输出框与类别,不同检测器在这三处的选择几乎决定了它的优化难度、收敛速度、正负样本密度、对小目标的适应性,以及是否需要 NMS。(turn887423search0, turn887423search5, turn887423search2, turn815089search0)
更准确地说,检测任务的训练并不是单纯的“分类 + 回归”,而是一个更复杂的组合问题:首先必须决定哪个预测单元负责哪个目标;然后才谈得上这个单元应该输出什么类别、什么框、以及哪些预测应该被压成背景。R-CNN 系列、YOLO 系列、FCOS、DETR 与 Deformable DETR,正是在“负责关系”的定义上发生了范式分裂:proposal-based、anchor-based one-to-many、anchor-free dense point assignment、以及 set prediction 的 one-to-one matching。(turn887423search2, turn996617search2, turn815089search0)
19.1 R-CNN:训练目标是“候选区域分类器 + 类别特定回归器”
原始 R-CNN 的训练方式并不是今天常见的统一多任务学习,而是明显的多阶段训练。其流程包括:使用 region proposal 方法生成约两千个候选区域,对候选区域做 CNN 特征提取,再训练类别特定的线性 SVM 分类器,最后为每个类别单独训练 bounding-box regressor。也就是说,R-CNN 并没有一个从输入图像到最终检测输出的单一联合损失函数;它依赖 proposal mechanism,并把“分类”与“框修正”拆成互相独立的阶段。(turn887423search0)
这种训练方式的直接后果是:候选区域生成的质量决定了上限,proposal 数量决定了计算负担,而监督信号不会直接回流影响 proposal 生成本身。R-CNN 的 box regression 也不是“在整图上找框”,而是对已经由候选区域覆盖到的区域做局部修正。因此,R-CNN 的核心问题不在于是否使用 anchor,而在于proposal 是否足够好,以及 proposal 和 recognition 是否共享优化目标。(turn887423search0)
19.2 Fast R-CNN:统一为 multi-task loss,但 proposal 仍然外置
Fast R-CNN 的关键变化在于,它把 R-CNN 后半段改造成了一个单阶段的 multi-task loss。在共享卷积特征和 RoI pooling 的基础上,每个 RoI 会输出一个类别分布 § 和一个类别特定的框回归向量 (t^u)。其损失可写为:
[
L(p, u, t^u, v)=L_{\text{cls}}(p,u)+\lambda [u\ge 1] L_{\text{loc}}(t^u,v)
]
其中 (u) 是真值类别,(v) 是真值回归目标,只有当 RoI 属于前景类别时才启用定位损失。论文中定位损失采用 smooth L1。这个设计第一次在 region-based detector 中把分类和框修正放进同一个 end-to-end 可优化框架里。(turn887423search5)
Fast R-CNN 虽然统一了检测头的训练,但 proposal 依然来自 Selective Search 之类的外部算法,因此它仍不是完全端到端的 detector。换句话说,Fast R-CNN 解决的是 per-proposal computation 太重 和 训练割裂 的问题,但并没有解决“候选区域如何由网络本身产生”这一更本质的问题。(turn887423search5, turn887423search2)
19.3 Faster R-CNN:anchor-based one-to-many assignment 的标准范式
Faster R-CNN 的 RPN 把 proposal generation 内生进网络,并通过 anchor 将连续的 box 空间参数化为一组离散参考框。对于每个 anchor,RPN 同时预测 objectness score 和 bounding-box regression offsets。论文中的回归目标采用相对 anchor 的参数化形式:
t x = x − x a w a , t y = y − y a h a , t w = log w w a , t h = log h h a t_x=\frac{x-x_a}{w_a}, \quad t_y=\frac{y-y_a}{h_a}, \quad t_w=\log \frac{w}{w_a}, \quad t_h=\log \frac{h}{h_a} tx=wax−xa,ty=hay−ya,tw=logwaw,th=loghah
其中 ((x_a,y_a,w_a,h_a)) 为 anchor,((x,y,w,h)) 为真值框。(turn887423search2, turn887423search8)
RPN 的多任务损失写成:
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L\left(\left\{p_i\right\},\left\{t_i\right\}\right)=\frac{1}{N_{\mathrm{cls}}} \sum_i L_{\mathrm{cls}}\left(p_i, p_i^*\right)+\lambda \frac{1}{N_{\mathrm{reg}}} \sum_i p_i^* L_{\mathrm{reg}}\left(t_i, t_i^*\right) L({pi},{ti})=Ncls1∑iLcls(pi,pi∗)+λNreg1∑ipi∗Lreg(ti,ti∗)
其中 (p_i^*\in{0,1}) 表示第 (i) 个 anchor 是否为正样本。正负样本分配规则并不是 learned matching,而是基于 IoU 的 heuristic:与某个 gt 的 IoU 最高的 anchor,或 IoU 高于上阈值的 anchor 被标为 positive;IoU 低于下阈值的被标为 negative。论文中给出的经典设置是 IoU > 0.7 为 positive,IoU < 0.3 为 negative。(turn887423search2, turn887423search8)
这一机制的本质是 one-to-many assignment:一个 gt 通常可以对应多个正 anchor。这使得监督非常密,训练早期也更稳定,因为即使某个 anchor 没有精确对齐,只要 IoU 足够高,它仍能贡献正样本梯度。与此同时,这也天然带来重复候选,因此 Faster R-CNN 必须在 proposal 阶段和最终检测阶段使用 NMS 进行去重。也就是说,anchor-based design 与 NMS 在很大程度上是成对出现的:前者通过冗余覆盖提高 recall,后者在推理阶段负责压缩重复预测。(turn887423search2, turn887423search11)
20. YOLO 系列:从直接回归到 anchor-based dense prediction
20.1 YOLOv1:grid responsibility + direct regression
YOLOv1 并不使用 anchor。它将图像划分为 (S\times S) 网格,每个 cell 预测固定数量的框、confidence 以及类别条件概率。如果某个目标的中心落入某个网格单元,则由该单元负责预测该目标。这种 assignment 完全由 object center 所在网格 决定,而不是由 IoU 匹配到 anchor 决定。(turn887423search3)
YOLOv1 的损失函数是一个加权平方误差目标,其中坐标误差、目标存在时的 confidence、无目标时的 confidence,以及分类误差被分别加权。论文中使用了 (\lambda_{\text{coord}}) 提高定位误差的权重,并使用 (\lambda_{\text{noobj}}) 压低大量背景单元对 confidence 学习的干扰。这个设计体现出 YOLOv1 的根本特征:它是一个手工设计的 joint regression objective,而不是基于 proposal 或 anchor 的局部偏移学习。(turn887423search3)
但这套机制的代价也非常明确。由于一个 grid cell 的责任由中心点唯一决定,YOLOv1 对小目标和密集目标天然不友好;同时,它的框学习缺少显式尺度先验,训练初期更容易出现不稳定的绝对回归。也就是说,YOLOv1 证明了 detection 不需要 anchor 才能成立,但它并没有解决 dense multi-scale detection 的几何建模难题。(turn887423search3)
20.2 YOLOv2:anchor 进入 YOLO,box regression 被改写为“受约束偏移”
YOLOv2 将 YOLO 从纯直接回归推进到 anchor-based detection。不同于 Faster R-CNN 那种围绕任意 anchor 做无约束偏移,YOLOv2 对 box 参数化做了更强约束。对于位于网格单元 ((c_x, c_y)) 的某个 anchor prior ((p_w,p_h)),预测框可写为:
b x = σ ( t x ) + c x , b y = σ ( t y ) + c y , b w = p w e t w , b h = p h e t h b_x=\sigma\left(t_x\right)+c_x, \quad b_y=\sigma\left(t_y\right)+c_y, \quad b_w=p_w e^{t_w}, \quad b_h=p_h e^{t_h} bx=σ(tx)+cx,by=σ(ty)+cy,bw=pwetw,bh=pheth
其中 (\sigma) 将中心偏移限制在当前网格单元附近。这样的 parameterization 明确地把中心学习约束在局部邻域内,从而降低训练初期中心点回归发散的风险。(turn996617search0)
YOLOv2 的 assignment 机制通常表述为:首先由目标中心决定负责的 grid cell,然后在该 cell 内选择与 gt 宽高最匹配的 anchor prior 作为负责预测单元。这里出现了一个关键转变:YOLO 的 supervision 从 “cell predicts object” 变成了 “cell-anchor pair predicts object”。这使它获得了更强的尺度与长宽比建模能力,同时也意味着检测头输出开始大规模膨胀,必须靠 objectness 学习和后续 NMS 控制重复预测。(turn996617search0)
YOLOv2 进一步用训练集 bounding boxes 的 dimension clustering 生成 anchor priors,而不是手工拍脑袋设定。这一做法的本质,不是为了让 anchor 看起来“更科学”,而是把数据集中的尺度分布显式编码为初始几何先验。于是 anchor 的角色被进一步明确:它不是检测的本体,而是一种 data-dependent optimization scaffold。(turn996617search0)
20.3 YOLOv3:多尺度 anchor-based dense detection 的成熟形态
YOLOv3 延续 anchor-based 设计,并将多尺度预测系统化。其检测头在三个不同尺度上输出框,每个尺度使用若干 anchor priors,从而提升对不同尺寸目标的覆盖能力。与 YOLOv2 相比,YOLOv3 在类别预测上使用独立 logistic classifiers,而不是单一 softmax;在结构上也更明确地引入了类 FPN 的跨尺度融合。(turn996617search1)
从训练角度看,YOLOv3 的本质仍然是 one-to-many dense prediction:大量 cell-anchor 对在整张特征图上竞争匹配目标,正样本通常通过中心所在网格和最佳 anchor prior 规则确定,最终再通过 NMS 合并重复预测。与 Faster R-CNN 相比,YOLOv3 省去了 proposal stage,但并没有脱离 anchor + objectness + post-hoc suppression 这条技术路线。(turn996617search1, turn887423search2)
因此,YOLOv2/v3 的演进说明的不是“YOLO 依赖 anchor 才成立”,而是另一件更本质的事:在 dense one-stage detection 中,anchor 作为几何先验能够显著降低训练难度,并与多尺度特征一起形成非常有效的工程解。(turn996617search0, turn996617search1)
21. FCOS:anchor-free dense detection 的代表性反例
在讨论 DETR 之前,必须先插入 FCOS,因为它证明了:在 CNN + dense prediction + NMS 的框架下,anchor 也完全可以被移除。 FCOS 将 detection 重新表述为 per-pixel prediction。对于位于特征图上某个位置 ((x,y)) 的正样本点,其回归目标不是相对 anchor 的偏移,而是到 gt box 四条边的距离:
[
l^=x-x_0,\quad
t^=y-y_0,\quad
r^=x_1-x,\quad
b^=y_1-y
]
其中 ((x_0,y_0,x_1,y_1)) 为真值框坐标。(turn996617search2)
FCOS 的正样本定义基于点是否落在 gt box 内,同时配合 FPN 层级的尺度范围约束,以减少不同尺寸目标之间的 assignment 冲突。当一个位置落在多个 gt box 内时,FCOS 使用面积更小的 gt 作为监督对象。这个规则清楚地表明:即便去掉 anchor,样本分配问题依然存在,只是从 “IoU to anchors” 改成了 “point-in-box + scale range + ambiguity resolution”。(turn996617search2)
为了进一步压低低质量预测在推理阶段的影响,FCOS 还引入了 center-ness 分支:
center-ness = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) ⋅ min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ∗ ) =\sqrt{\frac{\min \left(l ~^*, r ~^*\right)}{\max \left(l ~^*, r ~^*\right)} \cdot \frac{\min \left(t ~^*, b ~^*\right)}{\max \left(t^*, b^{*^*}\right)}} =max(l ∗,r ∗)min(l ∗,r ∗)⋅max(t∗,b∗∗)min(t ∗,b ∗)
这个量在 box 中心附近更高,在边缘更低,从而在推理时可作为 score calibration 使用。这里可以清楚看到,anchor-free 并不意味着“无几何先验”,而是意味着几何先验从 anchor templates 转移到了 center prior 与 point-based regression。(turn996617search2)
22. DETR:训练目标从 dense local supervision 转向 global set supervision
DETR 的根本变化不在于 backbone 变成 Transformer,而在于训练目标被重写为 set prediction。模型输出固定数量 (N) 个预测,每个预测由类别和框组成;真值目标集合不足 (N) 的部分用特殊的 “no object” 槽位补齐。训练时先在预测集合与真值集合之间执行最优二分匹配,然后仅对 matched pairs 计算检测损失。(turn815089search0, turn815089search12)
设预测集合为 ({\hat y_i}_{i=1}^N),真值集合为 (y)。DETR 通过 Hungarian algorithm 求解最优排列 (\hat{\sigma}):
σ ^ = arg min σ ∈ S N ∑ i L match ( y i , y ^ σ ( i ) ) \hat{\sigma}=\arg \min _{\sigma \in \mathfrak{S}_N} \sum_i \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right) σ^=argminσ∈SN∑iLmatch (yi,y^σ(i))
匹配代价由类别代价与框代价共同构成;框代价在论文中采用 L1 与 GIoU 的组合。匹配完成后,总损失写为 matched predictions 上的分类损失与 box loss 之和,而未匹配到任何 gt 的预测则被监督为 “no object”。(turn815089search0, turn815089search12)
DETR 的 box regression 也不再围绕 anchor 做局部偏移,而是直接预测归一化绝对框坐标。这一点非常关键:它把检测从 “围绕 reference templates 修正” 改成了 “由 query 直接输出最终框”。同时,由于训练使用 one-to-one matching,DETR 不再鼓励多个预测共同覆盖同一目标,因此理论上不需要 NMS。这正是 DETR 与 Faster R-CNN / YOLOv3 / FCOS 的范式分水岭。(turn815089search0, turn815089search4)
不过,one-to-one matching 也意味着监督变得更稀疏。原来一个 gt 可以对应多个正 anchor 或多个正位置,而在 DETR 中,一个 gt 只对应一个 query。与此同时,query 还必须在全局上下文中通过 cross-attention 学会“该看哪里”。这就是原始 DETR 训练明显更慢的重要原因之一。官方论文和仓库都表明,原始 DETR 在 COCO 上需要长 schedule 才能达到 42 AP 左右。(turn815089search0, turn815089search2)
23. Deformable DETR:保留 one-to-one matching,但重写 attention 的几何结构
Deformable DETR 没有改变 DETR 的核心 set-based loss;它依然沿用 bipartite matching 与一对一监督。但它重写了 query 如何从 feature maps 中收集信息的方式。原始 DETR 的问题在于:encoder / decoder 中的 attention 面向整张 feature map 进行全局建模,高分辨率下代价高,且优化初期缺少显式几何聚焦。Deformable DETR 的回答是 deformable attention。(turn815089search1, turn815089search5)
对某个 query (q),deformable attention 不再对全部空间位置求和,而是围绕一个 reference point (p_q) 在每个 attention head 上只采样少量 (K) 个位置。其单尺度形式可写为:
DeformAttn ( z q , p q , x ) = ∑ m = 1 M W m [ ∑ k = 1 K A m q k W m ′ x ( p q + Δ p m q k ) ] \operatorname{DeformAttn}\left(z_q, p_q, x\right)=\sum_{m=1}^M W_m\left[\sum_{k=1}^K A_{m q k} W_m^{\prime} x\left(p_q+\Delta p_{m q k}\right)\right] DeformAttn(zq,pq,x)=∑m=1MWm[∑k=1KAmqkWm′x(pq+Δpmqk)]
其中 (\Delta p_{mqk}) 为 learned offsets,(A_{mqk}) 为对应权重,非整数位置上的特征通过双线性插值获得。这个设计把原来 dense global attention 的“全图搜索”改造成 reference-guided sparse sampling。(turn815089search5, turn815089search9)
Deformable DETR 进一步将该机制扩展到 multi-scale feature maps,使得 query 可以在多个尺度上围绕 reference point 聚合信息。这样一来,小目标不再像原始 DETR 那样严重依赖单一低分辨率特征;同时,attention 复杂度与空间分辨率的关系也大幅缓解。论文明确指出,Deformable DETR 以约 10× fewer training epochs 达到更好的性能,尤其在小目标上显著优于原始 DETR。(turn815089search1, turn815089search5, turn815089search6)
从训练几何上看,Deformable DETR 的意义并不是“把 anchor 捡回来”,而是证明了另一件事:即使在 set prediction 框架下,检测器依然高度依赖某种显式几何聚焦机制。原始 DETR 把几何偏置压得太弱,导致优化代价过高;Deformable DETR 则通过 reference points 和 sparse sampling,把这种偏置以更柔性的方式重新注入模型。(turn815089search1, turn815089search5)
24. one-to-many 与 one-to-one:检测训练最根本的分水岭
从训练机制层面看,Faster R-CNN、YOLOv2/v3、FCOS 这类 detector 都可以归入 one-to-many supervision。其共同点是:一个 gt 通常会激活多个正样本——多个 anchors、多个 spatial locations,或多个 cell-anchor 对。这种设计的优点是监督密、recall 高、优化相对容易;缺点是天然会产生重复预测,因此几乎总需要 NMS 或某种去重后处理。(turn887423search2, turn996617search1, turn996617search2)
DETR 与 Deformable DETR 则属于 one-to-one supervision。每个 gt 只对应一个 query,每个 query 也只能最终匹配一个 gt。这种设计从根上压制了重复预测,使 NMS 在原则上变得多余;但它也让 early training 更难,因为模型无法像 dense detectors 那样依赖大量近似正样本来稳定学习。(turn815089search0, turn815089search1)
因此,anchor 是否存在并不是最深的问题。更深的问题是:监督是稠密冗余的,还是稀疏唯一的;几何先验是通过 anchor templates、center priors、还是 query-reference structures 注入的;重复预测是依靠 NMS 在推理后清理,还是在训练时通过 one-to-one matching 从源头压掉。 这三组选择共同构成了 detector 的技术立场。(turn996617search2, turn815089search0, turn815089search5)
25. anchor 是否必要:从训练机制角度的最终判断
如果只从存在性判断,结论非常简单:anchor 不是目标检测的必要条件。 R-CNN 不依赖 anchor,YOLOv1 不依赖 anchor,FCOS 明确是 anchor-free dense detector,DETR 与 Deformable DETR 也显式抛弃了 anchor generation。(turn887423search0, turn887423search3, turn996617search2, turn815089search0)
但如果从优化角度判断,结论必须更精确:anchor 之所以长期占据检测主流,不是因为检测在理论上必须依赖它,而是因为它在实践中非常有效地承担了三项职责:提供尺度与长宽比先验、把 box learning 转化为局部偏移问题、并通过 one-to-many assignment 提供密集监督。 Faster R-CNN 与 YOLOv2/v3 的成功,都说明 anchor 曾经是极其强力的 optimization device。(turn887423search2, turn996617search0, turn996617search1)
真正发生变化的,不是检测“摆脱了几何先验”,而是几何先验的载体发生了迁移。FCOS 用 point-in-box + center-ness 替代 anchor;DETR 用 object queries + bipartite matching 替代 anchor;Deformable DETR 再用 reference points + sparse multi-scale attention 强化这种替代。换言之,anchor 可以消失,但assignment mechanism、geometric bias、duplicate handling 不会消失。(turn996617search2, turn815089search0, turn815089search5)
26. 这一演化链条的真正技术主线
从 R-CNN 到 Deformable DETR,检测技术的核心演化并不是“CNN 变 Transformer”,也不是“速度越来越快”。更本质的主线只有三条。第一,proposal generation 是否外置:从 external proposals 走向 in-network prediction。第二,正样本是否基于冗余局部覆盖:从 anchor / point 的 one-to-many,走向 query-based one-to-one。第三,几何先验如何编码:从手工 anchor templates,走向更抽象的 reference-guided sparse attention。(turn887423search0,
turn887423search2](#), turn996617search2, turn815089search5)
如果将这一演化压缩成一句技术判断,那么可以表述为:
检测器并不是从“依赖先验”走向“摆脱先验”,而是从“显式手工离散化的先验”走向“可学习、可微、与全局匹配联合优化的先验”。 anchor 只是这一历史过程中的一个强力中间形态,而不是终点。(turn887423search2, turn815089search0, turn815089search5)
A more natural English phrasing would be:
“Yes. And don’t include paper hyperlinks. They make the post look messy. Please continue with the next section.”
27. 从 NMS、IoU、GIoU 到 Hungarian Matching:检测器如何定义“重复”“重叠”与“正确匹配”
在目标检测中,网络输出并不天然等于“最终结果”。无论是 proposal-based detector、anchor-based dense detector,还是 anchor-free dense detector,模型通常都会产生大量候选框,而这些候选框之间往往既相互重叠,又相互竞争。因此,检测问题从来不只是“预测框和类别”,还包括另外两个更深层的问题:第一,如何衡量一个预测框与真值框是否足够接近;第二,当多个预测框都指向同一目标时,应该如何决定保留谁、抑制谁。传统检测器主要依赖 IoU 与 NMS 来回答这两个问题,而 DETR 系列则试图用 one-to-one matching 在训练阶段直接重写这套逻辑。([NeurIPS 会议论文集][1])
这意味着,IoU、GIoU、NMS 与 Hungarian matching 并不是彼此独立的零散技术点,而是检测器在不同范式下对同一组核心问题给出的不同回答:什么叫匹配、什么叫重复、以及重复是在训练后被清理,还是在训练时就被禁止。 只有把这条逻辑线打通,才能真正理解为什么 Faster R-CNN、YOLOv3、FCOS 与 DETR 看起来都在“输出框”,但训练和推理的行为边界却如此不同。([NeurIPS 会议论文集][1])
27.1 IoU:检测领域最核心的“几何相似度”定义
在目标检测中,最基本的重叠度量是 Intersection over Union,记作 IoU。对于预测框 (B_p) 与真值框 (B_g),IoU 定义为二者交集面积与并集面积之比:
IoU ( B p , B g ) = ∣ B p ∩ B g ∣ ∣ B p ∪ B g ∣ \operatorname{IoU}\left(B_p, B_g\right)=\frac{\left|B_p \cap B_g\right|}{\left|B_p \cup B_g\right|} IoU(Bp,Bg)=∣Bp∪Bg∣∣Bp∩Bg∣
这个定义的意义非常直接:如果两个框完全重合,则 IoU 为 1;如果完全不相交,则 IoU 为 0。IoU 之所以成为检测任务中的核心指标,是因为它同时编码了位置偏差与尺度偏差,并且天然具有尺度归一化性质:相同的绝对坐标误差,在小框和大框上会体现为不同的 IoU 下降幅度。([CVF开放获取][2])
IoU 在检测系统中承担至少三层角色。第一,它是评测标准的一部分,用于判断一个预测是否算作正确检测;第二,它是assignment 的依据,例如 anchor-based detector 常用 IoU 阈值决定正负样本;第三,它是post-processing 的依据,例如 NMS 需要用 IoU 衡量两个预测框是否过于接近。也就是说,IoU 既是 metric,也是 training heuristic,还经常参与 inference-time suppression。([NeurIPS 会议论文集][1])
但 IoU 虽然直观,却并不完美。最大的问题在于:当两个框完全不相交时,IoU 恒为 0,此时它无法继续区分“差一点就碰到”和“离得很远”这两种情况。对于优化而言,这意味着以 IoU 为目标时会出现大面积的平坦区间,梯度信息极弱甚至直接消失。这正是后续 GIoU 被提出的直接原因。([CVF开放获取][2])
27.2 IoU 作为评测标准很自然,但作为回归损失并不充分
早期检测器中的框回归通常依赖坐标级别的损失,例如 L1、smooth L1 或相对 anchor 的参数回归误差。这类损失容易实现,也便于与神经网络训练结合,但它与检测任务真正关心的 metric——IoU——并不一致。换句话说,模型在训练时优化的是“坐标差距”,而评测时考核的是“几何重叠程度”。这两者并不总是同方向。两个预测框可能具有相似的坐标误差,却因为尺度和相对位置不同而对应完全不同的 IoU。([NeurIPS 会议论文集][1])
GIoU 论文明确指出了这种 mismatch:在 axis-aligned box regression 中,直接优化常规坐标距离并不等价于优化 IoU,而直接把 IoU 当损失又会在不重叠区域遭遇 plateau。这个 observation 非常关键,因为它揭示了 detection loss 的一个老问题:局部坐标误差并不能完整刻画全局几何质量。 这也是为什么后续很多更强的检测器会把 box loss 写成 “coordinate-style loss + overlap-style loss” 的组合,而不是只用一种简单的坐标损失。([CVF开放获取][2])
27.3 GIoU:给“不相交”的框也提供几何梯度
为了解决 IoU 在不重叠时为零的问题,GIoU 引入了一个额外项。设 © 为同时包住预测框和真值框的最小外接矩形,则 Generalized IoU 定义为:
G I o U = I o U − ∣ C \ ( B p ∪ B g ) ∣ ∣ C ∣ \mathrm{GIoU}=\mathrm{IoU}-\frac{\left|C \backslash\left(B_p \cup B_g\right)\right|}{|C|} GIoU=IoU−∣C∣∣C\(Bp∪Bg)∣
第二项衡量的是最小外接框中“未被两个框占据的空白区域”占比。直观上说,如果两个框彼此离得很远,那么虽然 IoU 同样为 0,但它们共同外接框里的空白区域会很大,因此 GIoU 会进一步变小。这样一来,即便两个框完全不重叠,损失函数仍然能够感知“距离远近”和“包围紧密程度”。([CVF开放获取][2])
GIoU 的价值不只在于多了一个公式,而在于它把 box regression 从“局部参数拟合”向“全局几何一致性”推进了一步。尤其在端到端检测器中,模型往往直接输出归一化框而不是围绕 anchor 做局部修正,此时加入 GIoU 会更自然,因为训练目标已经不再只是把某个 reference box 稍微调一调,而是要直接生成一个与真值在几何上高度一致的最终框。DETR 的 box loss 就明确采用了 L1 + GIoU 的组合。([arXiv][3])
27.4 NMS:传统检测器为什么几乎离不开它
在 anchor-based 或 point-based dense detector 中,one-to-many supervision 会让同一个 gt 对应多个正样本。这种冗余监督在训练时是优势,因为它增加了正样本密度,提高了 early training 的稳定性与 recall;但在推理时,它会自然地产生多个高度相似、位置接近、类别相同的候选框。于是,系统必须引入 Non-Maximum Suppression (NMS) 来删除重复预测。Faster R-CNN 的 RPN 和后续检测阶段都显式使用了 NMS;anchor-based dense detectors 也同样高度依赖它。([NeurIPS 会议论文集][1])
经典 NMS 的流程非常简单。对某一类别的所有候选框,先按 score 从高到低排序;取最高分框作为保留结果;然后删除所有与其 IoU 高于阈值的其余框;重复这一过程,直到候选为空。形式化地说,NMS 在做的不是学习,而是一个基于 score 排序和 IoU 阈值的贪心去重过程。这个过程的核心假设是:多个高度重叠的高分框大概率指向同一个目标,因此应保留置信度最高者。 ([NeurIPS 会议论文集][1])
NMS 的工程价值毋庸置疑,但它也有明显缺陷。首先,它是一个后处理启发式,而不是训练目标的一部分;其次,它对阈值敏感,不同数据集、不同密度场景下常常需要调参;再次,在拥挤场景中,两个相邻真实目标若相互重叠较大,NMS 可能会错误地把其中一个压掉。换句话说,NMS 之所以必要,恰恰说明检测器在训练阶段默认允许“重复预测”存在,而去重责任被推迟到了推理阶段。([NeurIPS 会议论文集][1])
27.5 NMS 的本质:它不是检测本体,而是对 one-to-many 冗余的补丁
从更高层面看,NMS 的存在揭示了传统检测器的一个根本结构:训练时允许大量重叠预测共同指向同一目标,推理时再通过启发式规则将其压缩为单个输出。这种模式在 Faster R-CNN、YOLOv2/v3 以及 FCOS 这类 detector 中都成立。区别只在于:冗余的来源是 anchor bank、grid-anchor pairs,还是 point-based dense locations。无论形式如何,只要训练机制本质上是 one-to-many,NMS 就几乎不可避免。([NeurIPS 会议论文集][1])
因此,NMS 不是“检测器天生的一部分”,而是 one-to-many dense prediction 范式的一个后果。只要训练目标鼓励或容忍多个局部预测共同覆盖同一对象,推理端就需要某种 duplicate suppression。也正是在这个意义上,DETR 的真正突破不只是“没用 anchor”,而是它试图通过 one-to-one matching 从训练机制上消灭产生 NMS 的根源。([arXiv][3])
27.6 Hungarian Matching:DETR 如何把“去重”前移到训练阶段
DETR 将目标检测重写为 direct set prediction。模型输出固定数量的预测槽位,每个槽位给出一个类别和一个框。关键不在于输出固定数量,而在于训练时如何决定“哪个预测对应哪个真值”。DETR 的回答是:在预测集合和真值集合之间做最优二分匹配,即 Hungarian matching。([ECVA][4])
设预测集合为 { y ^ i } i = 1 N \left\{\hat{y}_i\right\}_{i=1}^N {y^i}i=1N,真值集合为 (y)。DETR 首先定义每个预测–真值对之间的匹配代价,再寻找使总成本最小的排列 (\hat\sigma)。简化地写,可表示为:
σ ^ = arg min σ ∈ G N ∑ i L match ( y i , y ^ σ ( i ) ) \hat{\sigma}=\arg \min _{\sigma \in \mathfrak{G}_N} \sum_i \mathcal{L}_{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right) σ^=argminσ∈GN∑iLmatch (yi,y^σ(i))
匹配代价同时考虑类别与框质量;论文中的训练损失则在匹配完成后,对 matched pairs 计算分类损失和 box loss,其中 box loss 使用 L1 与 GIoU。未被匹配到任何真值的预测,则被监督为特殊的 no-object 类。([ECVA][4])
这个机制的本质是:
每个真值目标只允许一个预测负责。
一旦某个 query 已经与该目标匹配,其余 query 就不能再因为“也差不多对准了这个目标”而获得正样本奖励。它们要么去匹配别的目标,要么就学成 no-object。这与 anchor-based detector 允许多个 anchor 同时成为 positive 的 one-to-many 监督截然相反。([NeurIPS 会议论文集][1])
27.7 Hungarian Matching 与 NMS 并不是同一件事
NMS 和 Hungarian matching 都与“重复”有关,但它们所在的阶段、依赖的信息以及目标完全不同。NMS 是推理时的贪心后处理:它只看模型已经给出的分数与框,用固定阈值清理重叠候选。Hungarian matching 则是训练时的全局分配机制:它利用真值信息,在每次训练迭代中显式规定“一个目标只能由一个预测学习”。([NeurIPS 会议论文集][1])
因此,Hungarian matching 并不是“更高级的 NMS”,而是对重复预测问题的另一种哲学回答。NMS 的思路是:先允许冗余,再在推理时砍掉。 Hungarian matching 的思路是:从训练开始就不给冗余预测正样本资格。 前者优化更容易,因为正样本密;后者输出更干净,因为唯一性约束被内生进了学习过程。([NeurIPS 会议论文集][1])
27.8 为什么 DETR 能摆脱 NMS,但原始版本更难训练
从优化角度看,DETR 的 one-to-one matching 非常优雅,但也明显更难。原因很直接:在 one-to-many 体系中,一个 gt 周围通常会有多个近似正样本,因此模型很容易在局部邻域里得到有用梯度;而在 DETR 中,一个 gt 只对应一个 matched query,其余即便框得差不多,也不会被当作正样本。训练信号因此变得稀疏得多。([NeurIPS 会议论文集][1])
这也是为什么原始 DETR 需要更长的训练 schedule,并且在小目标上表现相对较弱。其困难并不来自“Transformer 不会做检测”,而来自另一件更本质的事:模型被要求同时学会表示、定位、分类,以及唯一分配。 传统 detector 把这些责任分散给 anchor design、IoU thresholds 与 NMS;DETR 则把它们更集中地压进了训练目标本身。([ECVA][4])
27.9 Deformable DETR:改变信息采样方式,但不改变 matching 哲学
Deformable DETR 并没有回退到 NMS,也没有放弃 Hungarian matching。它保留了 DETR 的 set prediction 和 one-to-one supervision,只是重写了 query 从图像特征中读取信息的方式。原始 DETR 依赖全局 attention,导致高分辨率特征代价高、训练收敛慢;Deformable DETR 则让每个 query 围绕一个 reference point 只在少量采样点上聚合多尺度特征,从而显著改善优化。([arXiv][5])
这意味着,Deformable DETR 的技术立场可以概括为:
保留训练层面的 one-to-one 唯一性约束,同时在表示层面重新引入更强的几何归纳偏置。
因此,它既没有回到 anchor-based dense prediction,也没有回到 NMS;它只是承认了一件事实:想要把重复预测从训练中消灭,并不意味着可以彻底抛弃局部几何结构。([arXiv][5])
27.10 IoU、GIoU、NMS 与 Hungarian Matching 在检测范式中的位置总结
将这四者放在同一框架下,可以得到一条非常清晰的逻辑线。IoU 负责定义两个框几何上有多接近;GIoU 进一步把这种几何接近的定义扩展到不相交情形,从而更适合作为优化目标;NMS 在 one-to-many 检测器中承担推理阶段的去重职责;Hungarian matching 则在 DETR 系列中承担训练阶段的唯一分配职责。([arXiv][3])
因此,真正的技术分水岭并不是“有没有 IoU”——几乎所有检测器都离不开某种重叠度量;也不是“有没有 box regression”——所有检测器都在做某种形式的框预测。真正的分水岭在于:重复预测是被允许并在推理时通过 NMS 清除,还是在训练时通过 one-to-one matching 从源头禁止。 这正是从 Faster R-CNN / YOLO / FCOS 到 DETR / Deformable DETR 的范式转变所在。([NeurIPS 会议论文集][1])
27.11 一个更本质的结论:检测器从来不是“在预测框”,而是在定义责任分配规则
如果只看输出张量,所有检测器似乎都只是“给出很多框和很多分数”。但从训练与推理的实际机制看,检测器真正做的事情更像是:在空间中定义一套责任分配规则,然后在这套规则上学习类别与几何。 R-CNN 时代的责任分配由外部 proposals 决定;Faster R-CNN 与 YOLOv3 的责任分配由 anchors 或 grid-anchor pairs 决定;FCOS 的责任分配由点是否落在框内决定;DETR 的责任分配则由全局最优匹配决定。([NeurIPS 会议论文集][1])
从这个角度看,anchor、IoU threshold、NMS、Hungarian algorithm 都不该被视为局部技巧,而应该被视为检测器对“谁负责哪个目标”这一根问题的制度性回答。也正因如此,讨论 anchor 是否必要时,真正该比较的不是“有没有一个先验框模板”,而是该 detector 用什么机制完成 assignment、去重与几何对齐。 ([NeurIPS 会议论文集][1])

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)