大模型能直接做推荐吗?和传统推荐模型有什么区别?
大模型能直接做推荐吗?和传统推荐模型有什么区别?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、简介:当推荐系统遇到大模型
想象一下,你走进一家书店。
传统推荐就像一位经验丰富的店员。他记得你上次买了《三体》,所以推荐你买《流浪地球》;他看到很多买《百年孤独》的人也买了《霍乱时期的爱情》,于是把这两本书放在一起。这种推荐很精准,但有个问题——如果店里新到了一本小众的科幻小说,他无法立即推荐给你,因为他没有这本书的销售数据。
大模型推荐则像一位博学的文学教授。你告诉他"我喜欢有哲学思考的硬科幻,最好是探讨人工智能伦理的",他立刻能理解你的需求,即使是一本刚出版的新书,只要内容符合你的描述,他就能推荐给你。他还能解释:“推荐这本书是因为作者在前作中展现了扎实的物理学功底,而这本新作聚焦于AI意识觉醒的伦理困境,正好契合你对哲学思考的需求。”
这就是大模型推荐和传统推荐的本质区别:一个依赖历史行为数据的"记忆",一个依赖对内容的"理解"。今天,我们就来深入探讨这两种推荐方式的差异、优劣和适用场景。
二、什么是大模型推荐
大模型推荐(LLM-based Recommendation)是指将推荐任务转化为自然语言理解和生成问题,利用大语言模型的强大语义理解能力来生成推荐结果或推荐理由。
与传统的协同过滤、矩阵分解等推荐算法不同,大模型推荐的核心思想是:不再把用户和商品看作冰冷的ID编号,而是理解它们背后的语义信息。用户的历史行为、商品的描述、上下文信息都被转化为自然语言文本,大模型通过阅读理解这些文本,直接生成推荐结果。
核心特征
1. 零样本推荐能力(Zero-shot Recommendation)
传统推荐系统对新商品或新用户束手无策,因为它们没有历史交互数据。大模型则不同——只要商品有文字描述,它就能基于语义理解进行推荐。这就像图书管理员 vs 文学教授的区别:前者需要看到借书记录,后者读完书就能判断适合谁。
2. 可解释性推荐
大模型能生成自然语言的推荐理由。它不会只说"推荐指数:0.85",而是会告诉你:“推荐这款冲锋衣是因为你最近浏览了多款户外装备,收藏过Gore-Tex面料的商品,而这款采用三层压胶工艺,符合你对防水透气性的要求。”
3. 对话式交互
用户可以用自然语言描述需求:"我想找一本适合周末放松的推理小说,不要太血腥,最好是本格派。"大模型能理解这些复杂的约束条件,而传统推荐系统很难处理这种多维度、语义化的查询。
三、大模型推荐如何工作
大模型做推荐主要有三种技术路线,就像用不同方式培养一位推荐专家:
1. Prompt-based 方式:直接提问法
这是最简单直接的方式。我们把推荐任务写成一段自然语言提示词(Prompt),让大模型直接回答。
工作流程:
- 把用户画像、历史行为、商品信息写成一段描述
- 在末尾加上指令:“基于以上信息,请为这位用户推荐5个商品并说明理由”
- 大模型生成推荐列表和解释
优点:无需训练,即插即用;灵活多变,可以适应各种推荐场景
缺点:效果不稳定,大模型可能"走神";对Prompt工程依赖大
类比:就像你直接问ChatGPT"给我推荐几本书",它立刻就能回答,但推荐质量取决于你怎么提问。
2. Fine-tuning 方式:专项训练法
拿通用大模型,用推荐领域的海量数据继续训练,让它专门学会做推荐任务。
工作流程:
- 收集推荐场景的用户行为数据、商品描述、用户反馈
- 将数据转化为"输入(用户+商品描述)→输出(推荐结果)"的格式
- 用这些数据微调大模型,让它成为"推荐专家"
优点:推荐质量更稳定、更精准;能学习到领域特有的模式
缺点:训练成本高,需要大量标注数据和GPU资源;模型更新周期长
类比:把一位文学教授送到书店工作半年,让他专门学习如何根据顾客需求推荐书籍。
3. Embedding 增强方式:能力嫁接法
不直接用大模型做推荐,而是用它强大的语义理解能力生成商品和用户的向量表示,然后把这些向量喂给传统推荐系统使用。
工作流程:
- 用大模型提取商品描述的深度语义特征,生成embedding
- 用同样的方式生成用户兴趣embedding
- 将这些embedding作为特征输入传统召回排序模型
优点:结合了大模型的理解能力和传统系统的效率;部署成本低
缺点:需要维护两套系统;embedding的质量直接影响最终效果
类比:让文学教授读完所有新书,写一份详细的"内容摘要"给图书管理员,管理员再根据这些摘要做推荐。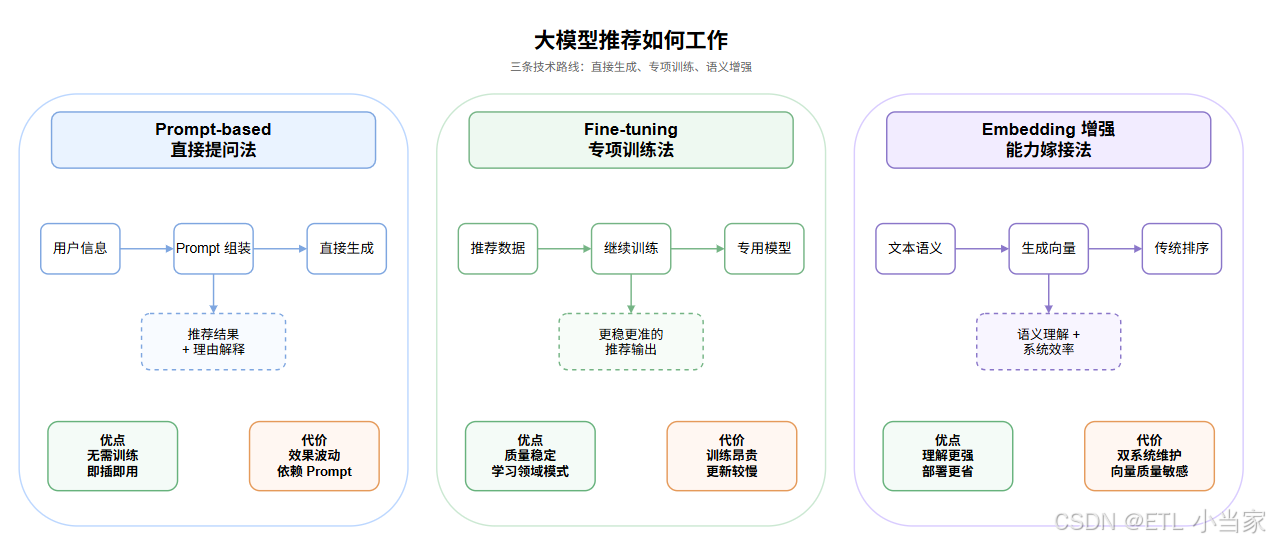
四、大模型推荐 vs 传统推荐模型的优缺点
| 对比维度 | 传统推荐模型 | 大模型推荐 |
|---|---|---|
| 核心机制 | 基于ID的协同过滤和矩阵分解,学习用户-商品交互模式 | 基于语义理解,将推荐转化为文本理解和生成任务 |
| 数据表示 | 用户=ID,商品=ID,世界=数字和向量 | 用户=自然语言描述,商品=文本描述,世界=语义 |
| 冷启动能力 | ❌ 弱:新商品/新用户需要积累数据 | ✅ 强:只要有文字描述就能推荐 |
| 可解释性 | ❌ 黑盒:输出分数,难以解释原因 | ✅ 透明:生成自然语言推荐理由 |
| 实时性 | ✅ 毫秒级响应,支持亿级用户 | ❌ 秒级响应,成本高,难以支撑大规模实时推荐 |
| 协同信号捕捉 | ✅ 强:能精准学习"买了A的人70%买B" | ⚠️ 弱:不擅长捕捉纯粹的协同模式 |
| 个性化精度 | ✅ 数据充足时精度极高,能捕捉细微偏好 | ⚠️ 泛化能力强但精度可能略低 |
| 计算成本 | ✅ 低:CPU集群即可支撑 | ❌ 高:需要GPU,推理成本高 |
| 交互方式 | 被动接收:刷信息流,系统推啥看啥 | 主动对话:用户可用自然语言提出需求 |
| 更新迭代 | ✅ 成熟:每周/每天可发布新模型 | ❌ 复杂:Fine-tuning需几天,AB测试困难 |
| 适用场景 | 高频、大规模、行为数据丰富的场景 | 长尾、冷启动、对话式、解释性强的场景 |
五、实际应用与发展趋势
当前主流应用场景
1. 对话式购物助手
淘宝的"淘宝问问"、亚马逊的Rufus都是典型代表。用户可以用自然语言提问:“我想送女朋友生日礼物,她喜欢摄影和旅行,预算两千左右”,系统理解需求后推荐商品并给出解释。这种交互传统推荐系统完全无法处理。
技术实现:Prompt-based + Fine-tuning混合方案,大模型负责理解对话意图,传统系统负责商品召回。
2. 长尾内容推荐
小红书、知乎等内容平台的AI搜索功能。当用户搜索"适合新手入门的摄影技巧"时,大模型能理解"新手"意味着"基础、易懂、系统性",而不是简单地匹配关键词。
技术实现:Embedding增强方式,用大模型提取笔记的深层语义特征,提升传统推荐系统对长尾内容的理解能力。
3. 冷启动场景
新品上架、新用户注册时的推荐。例如,一款小众设计师品牌的衬衫刚上架,没有点击购买数据,大模型通过理解"原创设计、日系简约风格、适合通勤"这些描述,立即匹配给关注这类风格的用户。
技术实现:零样本推荐,直接用商品描述文本生成推荐。
4. 推荐理由生成
即使主推荐链路用传统模型,推荐理由也可以用大模型生成。例如,传统模型输出"推荐商品A(得分0.85)",大模型补充:“推荐这款是因为你最近浏览了多款降噪耳机,而这款采用主动降噪技术,续航30小时,符合你的需求。”
技术实现:异步调用大模型,不影响主推荐链路的响应速度。
工业界混合架构实践
实际生产中,几乎没有公司会完全用大模型替代传统推荐系统,而是采用分层、混合的架构:
架构一:传统模型主链路 + 大模型增强
- 召回、排序等高频环节:传统模型(毫秒级响应)
- 推荐理由、冷启动商品:大模型(异步或离线生成)
- 示例:淘宝商品推荐主链路用传统模型,推荐理由用通义千问生成
架构二:大模型特征工程
- 商品入库时:用大模型离线生成深度语义embedding
- 在线推荐时:调用预计算的embedding,和传统特征一起输入排序模型
- 示例:小红书用大模型理解笔记内容,生成多维度标签和embedding
架构三:分层处理
- 高频场景:传统模型
- 低频高价值场景:大模型
- 示例:B站主信息流用传统模型,用户主动搜索时的"AI推荐"用大模型
成本控制策略
大模型推荐的最大障碍是成本。工业界主要采用以下策略:
1. 离线预计算
能离线做的尽量离线做:
- 商品embedding:商品上架时一次性计算,存数据库
- 推荐理由:对热门商品预生成几种解释模板
- 用户画像:定期用大模型分析用户行为,更新标签
2. 缓存策略
- 热门商品推荐结果缓存Redis
- 相似用户请求结果复用
- 缓存命中率可达80%以上,大幅降低在线调用
3. 异步处理
- 用户请求先返回传统模型结果
- 大模型在后台计算,下次刷新时展示
- 适用于信息流、可多次刷新的场景
4. 模型蒸馏
用大模型(老师)训练一个小模型(学生):
- 让小模型学习大模型的推荐逻辑
- 小模型推理快、成本低
- 效果接近大模型的90%
5. 流量控制
- 只对高价值用户开启大模型推荐
- 只在特定场景(如搜索、详情页)调用
- 控制调用比例在5%以内
评估方法的差异
传统推荐系统的评估很直接:
- 短期指标:点击率、转化率、人均浏览量
- A/B测试:一周就能看到效果差异
大模型推荐需要更复杂的评估:
- 业务指标:点击率(依然重要)
- 体验指标:推荐理由的合理性、用户满意度调查
- 质量指标:生成内容是否有"幻觉"、是否符合事实
- 长期指标:用户留存、品牌认知度(可能需要观察数月)
人工评估在大模型推荐中变得更重要:
- 随机抽取推荐结果,由人工打分(1-5分)
- 评估维度:相关性、合理性、新颖性、多样性
- 可能需要额外的模型来辅助评估生成质量
未来发展趋势
1. 多模态推荐
当前主要基于文本,未来会融合:
- 商品图片:理解视觉风格、颜色搭配
- 视频内容:理解视频主题、情感倾向
- 用户行为序列:结合点击、滑动、停留时长等行为
2. Agent化推荐助手
不只是被动推荐,而是主动询问:
- “你最近对户外徒步感兴趣,需要我推荐装备吗?”
- 多轮对话澄清需求:“你说的’适合通勤’是指地铁还是开车?预算在什么范围?”
- 主动解释推荐逻辑:“我没有推荐A商品,是因为根据你的历史,你更看重性价比而非品牌”
3. 个性化大模型
目前所有用户共享同一个大模型,未来可能:
- 为每个用户微调轻量化的适配器(LoRA技术)
- 模型能记住用户的长期偏好和反馈
- 实现真正的千人千模型
4. 边缘计算优化
解决延迟问题:
- 模型量化、剪枝,让大模型能在边缘设备运行
- 端侧推理,保护用户隐私
- 适用于对延迟极其敏感的场景
5. 与传统模型的深度融合
不是简单的拼接,而是端到端联合训练:
- 传统模型的输出作为Prompt的一部分输入大模型
- 大模型的embedding直接参与传统模型的梯度计算
- 实现优势互补,而不是功能堆砌
六、总结与思考
核心知识点总结
一句话概括:传统推荐模型是"经验派",记住历史数据中的模式;大模型是"理解派",读懂内容的语义。两者不是替代关系,而是互补关系。
关键差异:
- 数据表示:ID化 vs 语义化
- 冷启动:无能为力 vs 零样本推荐
- 可解释性:黑盒分数 vs 自然语言解释
- 工程成本:成熟可控 vs 昂贵复杂
- 适用场景:大规模高频 vs 长尾低频
工业界实践:
没有银弹,只有混合架构。传统模型负责主链路的大规模召回排序,大模型在冷启动、推荐理由、对话交互等特定场景发挥价值。
深度思考
技术的本质是为场景服务。大模型不是来"颠覆"推荐系统的,而是扩展了推荐的可能性边界。就像电力革命没有让蒸汽机完全消失,而是在特定场景(如核电站)继续使用。推荐系统的未来不是非此即彼的选择,而是根据业务特点、用户规模、成本约束,选择最合适的技术组合。
成本意识的觉醒。大模型时代,我们第一次如此关注"计算成本"。传统推荐系统优化的是"效果",现在我们要在"效果-成本-延迟"三维空间中寻找最优解。这可能催生出新的技术方向——如何让大模型更轻量、如何让传统模型更智能、如何让两者更高效协作。
交互方式的革命。传统推荐是"系统推,用户看"的单向传播。大模型让推荐变成了"用户问,系统答"的对话式交互。这不仅改变了技术实现,更改变了用户与信息的关系——从被动接受到主动探索,从模糊猜测到精准表达。
推荐系统的终极价值。无论是传统模型还是大模型,推荐系统的本质都是解决信息过载问题,提高信息匹配效率。技术会变,但目标不变。作为从业者,我们不应被技术表象迷惑,而要始终思考:我的推荐系统是否真正帮助用户发现了有价值的信息?是否尊重了用户的选择权?是否在商业价值和用户体验间保持了平衡?
最后,记住这句话:大模型让推荐系统从"记住用户行为"进化到"理解用户需求",但这个进化还在进行中,我们需要保持开放而审慎的态度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)