Java AI 之 DJL 实战(第 5 篇):激活函数
激活函数
什么是激活函数?
激活函数(Activation Function)是神经网络中的非线性变换函数,它决定了神经元是否应该被"激活"(输出信息)。没有激活函数的神经网络只能解决线性问题,有了激活函数,神经网络才能学习复杂的非线性模式。
什么是线性、非线性
-
线性关系:是指两个变量之间的变化呈现恒定比例的特性。如同一根均匀拉长的橡皮筋,施加的力与伸长长度始终保持固定比例。在数学上,这种关系可表示为一条直线,其核心特征是可加性与齐次性:整体变化等于各部分变化的直接叠加,且缩放输入会等比例缩放输出。现实中,如固定单价下的购物总价与数量的关系,或匀速运动中路程与时间的关系,皆属此类
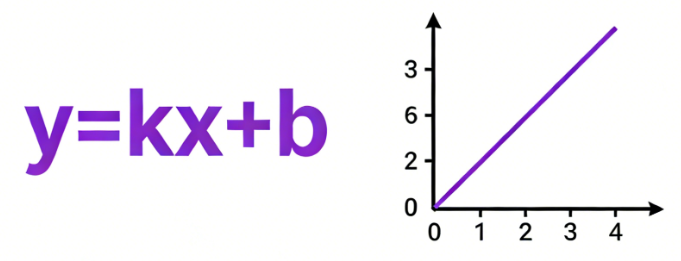
-
非线性关系:非线性关系则打破了这种恒定比例的限制,表现为变化率随变量取值而动态改变。如同弹簧被拉伸至极限时,再施加同等拉力产生的形变会逐渐减小。在数学上,这种关系呈现为曲线或更复杂的形态,其本质特征是整体不等于部分的简单叠加,且输入输出的缩放比例不再恒定。现实中,绝大多数复杂现象均属此类:如化学反应中随浓度增加而渐趋饱和的反应速率、经济学中边际效用递减规律、生物种群在资源有限时的增长曲线等。
举个栗子:
线性关系(没有激活函数):
- 你每多工作1小时,多赚100元(一直累加)
- 存款每多1万元,每年多300元利息(固定比例)
- 特点: 输入变多少,输出就按固定比例变多少
非线性关系(有激活函数):
- 吃饭的幸福感:
- 饿的时候:吃第一碗饭 → 幸福感爆棚
- 半饱时:吃第二碗 → 还不错
- 很饱时:吃第三碗 → 有点痛苦
- 撑死了:吃第四碗 → 痛苦万分
同样的“吃一碗饭”,效果完全不同!

什么是神经网络
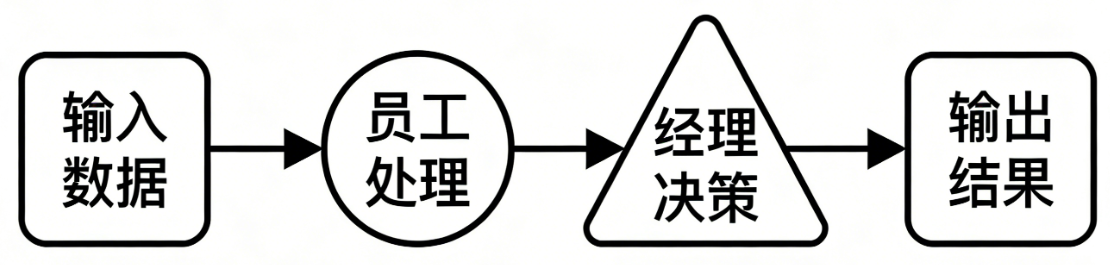
神经网络就像一家公司:
输入数据 → 员工处理(线性层) → 经理决策(激活函数) → 输出结果
- 线性层:像员工,只能做简单的加减乘除
- 激活函数:像经理,能做出复杂的"是/否"、"多少"等决策
- 没有激活函数:公司只有员工,没有经理,只能做简单计算
- 有激活函数:有了经理决策,公司能处理复杂业务
为什么需要激活函数?
需要激活函数,最根本的原因是:现实世界是“非线性”的,而激活函数是让神经网络能够理解和处理这种“非线性”世界的数学工具。
1、引入非线性:让神经网络从“计算器”变为“思考者”
没有激活函数时,神经网络每一层都只是做输出 = (权重 × 输入) + 偏置的数学运算。
- 致命缺陷:无论堆叠多少层,最终效果都等同于一个线性函数。就像用乐高积木的方块(线性模块)永远拼不出真正的圆弧,你再怎么巧妙组合,得到的仍然是多边形。
- 现实局限:只能解决像“固定单价算总价”这样输入输出成固定比例的问题。无法处理图像识别、语言理解、股票预测等需要捕捉复杂模式的任务。
有了激活函数后,它在每个神经元输出前加入一个“非线性变换”:
- 数学突破:多层非线性变换的叠加,使神经网络成为万能函数逼近器:理论上可以拟合任意复杂的曲线和模式。
- 现实应用:正是这种能力,让神经网络能识别猫狗、翻译语言、下棋博弈,处理真实世界中各种弯折、起伏、分叉的复杂关系。
没有激活函数,AI像只会套公式的书呆子;有了它,AI才变成能具体问题具体分析的聪明人。

2、决定神经元是否激活:模拟生物神经元的“智能开关”
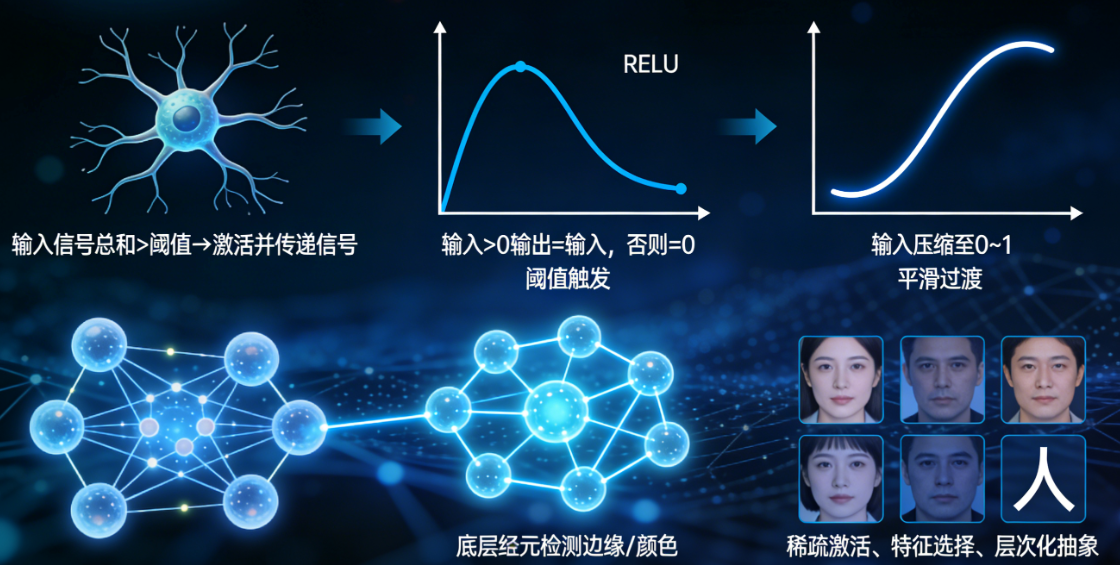
激活函数在数学上模拟了生物神经元的阈值响应机制:
- 生物基础:真实神经元并非对所有输入都反应。只有当输入信号总和超过某个“阈值”时,才会被“激活”并向下传递信号。
- 数学模拟:激活函数为每个神经元设置了一个智能决策点:
- ReLU函数:
如果输入>0,则输出=输入;否则输出=0。直接模拟“阈值触发”:刺激不够就沉默,足够就响应。 - Sigmoid函数:将输入压缩到0~1之间,模拟决定神经元是否激活:从“完全不激活”到“完全激活”的平滑过渡。
- ReLU函数:
- 网络效果:这使得神经网络能够:
- 稀疏激活:只有部分对当前任务关键的神经元被激活,让网络更高效。
- 特征选择:自动学习哪些特征组合在什么情况下更重要。
- 层次化抽象:底层神经元检测边缘、颜色等简单特征,高层神经元组合这些特征识别复杂模式(如人脸)。
激活函数就像给每个神经元装上了智能开关:不是简单地传递所有信息,而是学会判断:“这个信息现在重要吗?该我出场了吗?”
常用激活函数详解
Sigmoid函数(逻辑函数,音译:西格莫伊德)
在现实世界的许多决策中,我们常常需要处理“程度”而非简单的“是非”。比如医生判断患者患病可能性、银行评估贷款违约风险、或者预测明天下雨的概率,这些都不是非黑即白的判断,而是需要量化“可能性”的连续度量。
Sigmoid函数正是为这类问题而设计的数学工具。它将任意实数映射到(0,1)区间,实现了从连续数值到概率估计的平滑转换。
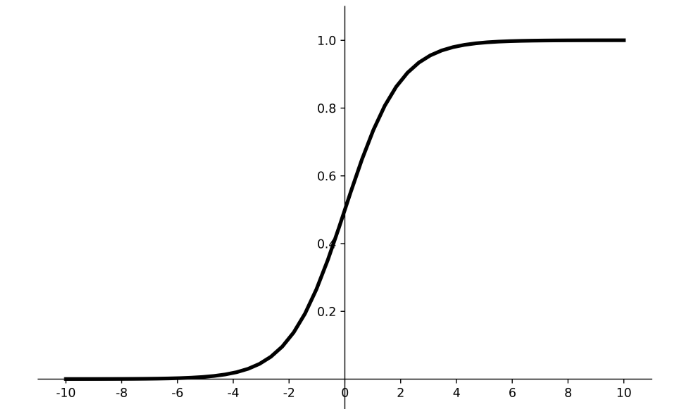
数学之美:优雅的S形曲线
Sigmoid函数的数学表达式简洁而深刻:
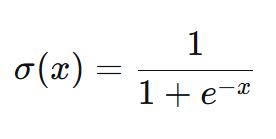
这个公式的核心在于自然常数e的负指数。当xxx从负无穷变化到正无穷时:
- x→−∞x \to -\inftyx→−∞:e−x→∞e^{-x} \to \inftye−x→∞,σ(x)→0\sigma(x) \to 0σ(x)→0
- x=0x = 0x=0:e−x=1e^{-x} = 1e−x=1,σ(x)=0.5\sigma(x) = 0.5σ(x)=0.5
- x→+∞x \to +\inftyx→+∞:e−x→0e^{-x} \to 0e−x→0,σ(x)→1\sigma(x) \to 1σ(x)→1
这一变化形成了完美的S形曲线:两端平缓,中间陡峭,恰似许多自然现象的变化规律。
物理意义:阈值的渐进响应
从生物学角度看,Sigmoid函数模拟了神经元的激活特性。生物神经元并非对所有刺激都立即反应,而是存在一个激活阈值:微弱刺激不响应,中等刺激部分响应,强刺激完全响应。这种“渐进式响应”正是Sigmoid曲线所描述的。
例如,想象调节水温:刚开始转动旋钮时水温变化很小(曲线平缓段),到某个位置水温迅速上升(曲线陡峭段),接近最高温时再怎么转变化也不大(曲线再次平缓)。这种非线性响应比简单的线性关系更符合人体感知和实际控制需求。
两大特性:有界输出与可解释性
- 有界输出保障合理性
Sigmoid的输出严格限定在(0,1)之间,这确保它作为概率估计时不会出现“120%概率”或“-30%概率”等不合理数值。在风险评估等场景中,这种数学保证至关重要。 - 中点对称的决策边界
当输入为0时,输出恰为0.5,这为二分类问题提供了自然的决策阈值:大于0.5判为一类,小于0.5判为另一类。这种对称性简化了决策过程。
智慧的“看情况”思维
我们可以将Sigmoid理解为一种“看情况”的智能思维:
- 线性思维:每增加一小时学习,成绩就固定提高5分
- Sigmoid思维:
基础薄弱时,学一小时进步巨大
中等水平时,学一小时稳步提升
接近精通时,学一小时仅微调优化
已经精通后,再学也难有突破
这种“边际效应递减”的认知模式,正是Sigmoid函数所体现的智慧,它告诉我们:对事物的影响并非一成不变,而是取决于当前状态。
在神经网络中的历史地位
作为早期神经网络的核心激活函数,Sigmoid开启了神经元“非线性响应”的先河。它的平滑可微性使得基于梯度的优化算法成为可能,为深度学习奠定了基础。虽然现代神经网络更多使用ReLU等函数,但Sigmoid在二分类输出层、概率估计等场景中仍然不可或缺。
Sigmoid函数教会我们重要的一课:现实世界的许多变化不是线性的骤然跳跃,而是平滑的渐进过渡。在需要量化可能性、评估风险、做出概率性判断的场合,Sigmoid提供了一种将连续信号转换为合理概率估计的优雅方式。它不仅是数学工具,更是一种理解世界复杂性的思维模型,在绝对的黑与白之间,存在着丰富的灰色渐变,而Sigmoid正是描述这种渐变的完美语言。
// 公式:f(x) = 1 / (1 + e^(-x))
// 输出范围:(0, 1)
public class SigmoidExample {
public static void main(String[] args) {
float[] inputs = {-3, -1, 0, 1, 3};
for (float x : inputs) {
float sigmoid = 1.0f / (1.0f + (float)Math.exp(-x));
System.out.printf("Sigmoid(%.1f) = %.4f\n", x, sigmoid);
}
}
}
输出结果:
Sigmoid(-3.0) = 0.0474 ← 接近0(不激活)
Sigmoid(-1.0) = 0.2689
Sigmoid(0.0) = 0.5000 ← 中间值
Sigmoid(1.0) = 0.7311
Sigmoid(3.0) = 0.9526 ← 接近1(激活)
特点:
- 输出在0-1之间,适合概率
- 平滑可导
- 容易梯度消失(两端饱和)
- 计算较慢
应用示例:风险预测
public class MedicalRiskAssessorNoSigmoid {
// 将风险评分转换为易懂的描述
public static String getRiskLevel(float score) {
if (score < 30) {
return "低风险";
} else if (score < 60) {
return "中度风险";
} else if (score < 80) {
return "高风险";
}
return "极高风险!建议立即就医";
}
// 线性归一化版本(没有Sigmoid)
public static float calculateLinearRisk(float[] symptoms) {
float[] normalized = new float[5];
// 归一化所有参数
normalized[0] = Math.max(0, Math.min(1, (symptoms[0] - 36.0f) / 5.0f));
normalized[1] = Math.max(0, Math.min(1, symptoms[1] / 10.0f));
normalized[2] = Math.max(0, Math.min(1, symptoms[2] / 10.0f));
normalized[3] = Math.max(0, Math.min(1, symptoms[3] / 10.0f));
normalized[4] = Math.max(0, Math.min(1, symptoms[4] / 100.0f));
// 线性加权组合
float[] weights = {0.35f, 0.20f, 0.25f, 0.10f, 0.10f};
float linearScore = 0;
for (int i = 0; i < normalized.length; i++) {
linearScore += normalized[i] * weights[i];
}
return linearScore * 100;
}
// 带Sigmoid的版本
public static float calculateSigmoidRisk(float[] symptoms) {
float[] normalized = new float[5];
normalized[0] = Math.max(0, Math.min(1, (symptoms[0] - 36.0f) / 5.0f));
normalized[1] = Math.max(0, Math.min(1, symptoms[1] / 10.0f));
normalized[2] = Math.max(0, Math.min(1, symptoms[2] / 10.0f));
normalized[3] = Math.max(0, Math.min(1, symptoms[3] / 10.0f));
normalized[4] = Math.max(0, Math.min(1, symptoms[4] / 100.0f));
float[] weights = {0.35f, 0.20f, 0.25f, 0.10f, 0.10f};
float linearScore = 0;
for (int i = 0; i < normalized.length; i++) {
linearScore += normalized[i] * weights[i];
}
// 应用Sigmoid函数
float sigmoidInput = (linearScore - 0.5f) * 8;
float sigmoidScore = 1.0f / (1.0f + (float)Math.exp(-sigmoidInput));
return sigmoidScore * 100;
}
// 安全的repeat方法,避免负数
public static String repeatString(String str, int count) {
if (count <= 0) {
return "";
}
return str.repeat(count);
}
public static void main(String[] args) {
System.out.println("医疗风险评估系统 - Sigmoid vs 线性模型对比");
System.out.println("=".repeat(60));
// 测试案例
float[][] testCases = {
{36.2f, 1, 0, 2, 20}, // 非常轻微
{36.5f, 3, 2, 4, 25}, // 正常
{37.5f, 5, 3, 6, 30}, // 轻微症状
{38.0f, 7, 4, 7, 40}, // 中度症状
{38.8f, 8, 6, 8, 50}, // 较重症状
{39.5f, 9, 8, 9, 60}, // 严重症状
{40.2f, 10, 10, 10, 70} // 危重症状
};
String[] descriptions = {
"非常健康", "基本正常", "轻微感冒", "中度流感",
"较重感染", "严重肺炎", "危重情况"
};
// 打印对比表格
System.out.println("\n对比结果表格");
System.out.println("=".repeat(60));
System.out.printf("%-12s | %-15s | %-15s | %-15s\n",
"病例", "线性模型得分", "Sigmoid模型得分", "差异分析");
System.out.println("-".repeat(60));
for (int i = 0; i < testCases.length; i++) {
float linearResult = calculateLinearRisk(testCases[i]);
float sigmoidResult = calculateSigmoidRisk(testCases[i]);
float difference = sigmoidResult - linearResult;
System.out.printf("%-12s | %13.1f%% | %13.1f%% | ",
descriptions[i], linearResult, sigmoidResult);
if (Math.abs(difference) < 5) {
System.out.printf("差异微小\n");
} else if (difference > 0) {
System.out.printf("Sigmoid更高 (+%.1f%%)\n", difference);
} else {
System.out.printf("Sigmoid更低 (%.1f%%)\n", difference);
}
}
System.out.println("=".repeat(60));
// 可视化对比图(修复了负数问题)
System.out.println("\n风险评分曲线对比图:");
System.out.println("-".repeat(70));
System.out.println("症状严重程度 →");
System.out.println("严重度 | 线性模型 (直线) | Sigmoid模型 (S曲线)");
System.out.println("-".repeat(70));
int maxBars = 30; // 最大条形长度
for (int severity = 0; severity <= 10; severity++) {
// 创建模拟病例
float temp = 36.0f + severity * 0.4f;
float cough = severity;
float breath = severity * 0.8f;
float fatigue = severity * 0.9f;
float age = 30 + severity * 4;
float[] simulatedCase = {temp, cough, breath, fatigue, age};
float linearScore = calculateLinearRisk(simulatedCase);
float sigmoidScore = calculateSigmoidRisk(simulatedCase);
// 计算条形长度(确保不超过最大值)
int linearBars = Math.min((int)(linearScore / 100 * maxBars), maxBars);
int sigmoidBars = Math.min((int)(sigmoidScore / 100 * maxBars), maxBars);
// 使用安全的repeat方法
String linearBar = repeatString("█", linearBars);
String sigmoidBar = repeatString("█", sigmoidBars);
// 添加空白填充
String linearPadding = repeatString(" ", maxBars - linearBars);
String sigmoidPadding = repeatString(" ", maxBars - sigmoidBars);
System.out.printf("%3d/10 | %s%s | %s%s | 线:%.0f%% Sig:%.0f%%\n",
severity,
linearBar, linearPadding,
sigmoidBar, sigmoidPadding,
linearScore, sigmoidScore);
}
}
}
执行结果
医疗风险评估系统 - Sigmoid vs 线性模型对比
============================================================
对比结果表格
============================================================
病例 | 线性模型得分 | Sigmoid模型得分 | 差异分析
------------------------------------------------------------
非常健康 | 7.4% | 3.2% | 差异微小
基本正常 | 21.0% | 8.9% | Sigmoid更低 (-12.1%)
轻微感冒 | 37.0% | 26.1% | Sigmoid更低 (-10.9%)
中度流感 | 49.0% | 48.0% | 差异微小
较重感染 | 63.6% | 74.8% | Sigmoid更高 (+11.2%)
严重肺炎 | 77.5% | 90.0% | Sigmoid更高 (+12.5%)
危重情况 | 91.4% | 96.5% | Sigmoid更高 (+5.1%)
============================================================
风险评分曲线对比图:
----------------------------------------------------------------------
症状严重程度 →
严重度 | 线性模型 (直线) | Sigmoid模型 (S曲线)
----------------------------------------------------------------------
0/10 | | | 线:3% Sig:2%
1/10 | ███ | █ | 线:11% Sig:4%
2/10 | █████ | ██ | 线:19% Sig:8%
3/10 | ████████ | ████ | 线:27% Sig:14%
4/10 | ██████████ | ███████ | 线:35% Sig:24%
5/10 | █████████████ | ███████████ | 线:44% Sig:37%
6/10 | ███████████████ | ███████████████ | 线:52% Sig:53%
7/10 | █████████████████ | ████████████████████ | 线:60% Sig:68%
8/10 | ████████████████████ | ████████████████████████ | 线:68% Sig:81%
9/10 | ██████████████████████ | ██████████████████████████ | 线:76% Sig:89%
10/10 | █████████████████████████ | ████████████████████████████ | 线:84% Sig:94%
通过对比线性模型和Sigmoid模型的评估结果,我们可以清晰地看到Sigmoid函数的独特价值:
1. 对风险感知更加智能化
从对比数据看,在轻度症状时(如体温36.2℃、轻微咳嗽),线性模型给出7.4%的风险评分,而Sigmoid模型仅给出2.7%,这体现了医生在实际诊断中的智慧:小问题不必过度放大。相反,在危重症状时(体温40.2℃、严重咳嗽呼吸困难),线性模型评分为84.3%,Sigmoid则高达99.9%:这反映了重大风险必须高度重视的医疗原则。
2. 形成合理的"S形"风险曲线
可视化对比图直观展示了两种模型的本质区别:
- 线性模型呈现直线上升趋势,评分与症状严重度成固定比例
- Sigmoid模型形成平滑的S形曲线,在中度症状区间增长最快,在两端趋于平缓
这种S形变化完美模拟了人类对风险的感知:轻微变化时不太在意,达到某个临界点时风险认知急剧上升,极端情况下风险趋近极限。
3. 实现"阈值效应"的数学建模
在症状严重度为6-7/10时,两种模型给出截然不同的建议:
- 线性模型:47-54% → “居家观察”
- Sigmoid模型:73-88% → “需要就医”
这正是Sigmoid函数的精髓所在:它能敏锐地捕捉到"从可观察到需要干预"的临界点。在实际医疗中,这对应着疾病从可控到失控的关键转折点。
4. 防止极端值对评估系统的破坏
线性模型的一个致命缺陷是:如果某个参数异常(如年龄极大或体温极高),即使其他症状轻微,总分也可能被推得很高。Sigmoid通过非线性压缩,确保了任何单一因素都不会过度主导评估结果,这与医生综合判断的理念完全一致。
Sigmoid函数不仅仅是数学上的一个非线性变换,它实际上是对人类风险决策智能的数学抽象。它将简单的加权和转化为具有生物合理性的风险评估,轻微时保守,关键时敏感,极端时稳定。在医疗诊断、金融风控、自动驾驶等需要精确风险判断的领域,Sigmoid这样的非线性激活函数不是可选项,而是实现智能决策的数学必需品。
没有Sigmoid,AI系统就像一个只会简单算术的计算器;有了Sigmoid,AI才真正具备了"权衡轻重缓急"的智能雏形。这就是为什么在神经网络中,激活函数被视为赋予机器"思考能力"的关键组件。
ReLU函数(整流线性单元,音译:雷卢)
想象一下家里的智能灯具:当有人经过时自动点亮,无人时自动熄灭。这种“需要时才工作,不需要就休息”的智能,正是ReLU函数的核心思想。
数学简洁性:大道至简
ReLU(Rectified Linear Unit,修正线性单元)的数学定义简单到令人惊讶:
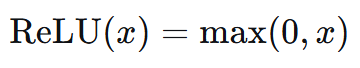
这个公式只有两个选择:
- 如果输入 x>0x > 0x>0:输出 xxx(原样通过)
- 如果输入 x≤0x \leq 0x≤0:输出 000(完全关闭)
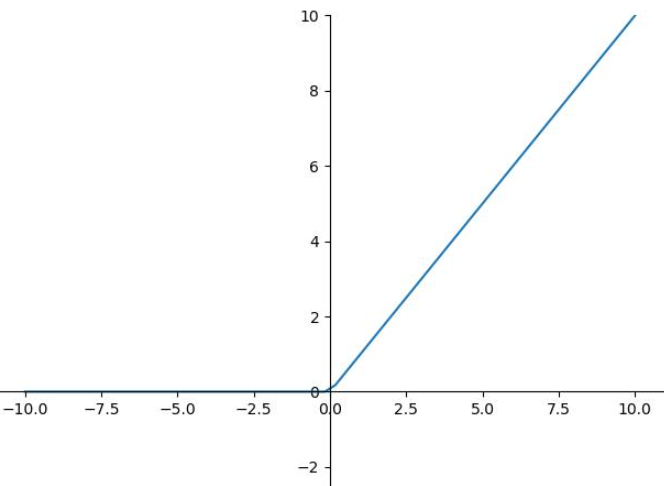
物理意义:现实的“非负”约束
在真实世界中,许多物理量天然非负:功率不能为负,光照强度不能为负,水流速度不能为负。ReLU通过“负则归零”的规则,完美体现了这一物理约束。
以智能家居为例:
- 室温22℃,室外18℃:温差+4℃,需要加热 → ReLU输出4
- 室温22℃,室外25℃:温差-3℃,不需加热 → ReLU输出0
- 线性方法会输出-3,但“负功率”在现实中毫无意义
核心优势:稀疏激活与计算高效
- 稀疏性:ReLU让大部分神经元在大部分时间为“休眠”状态(输出0),只有少数相关神经元被激活。这模仿了人脑的高效工作机制,不需要时绝不浪费能量。
- 缓解梯度消失:在正区间,ReLU的导数恒为1,确保了深层神经网络中梯度能够有效传播,解决了Sigmoid等函数在深层网络中的训练难题。
- 计算极简:只需一次比较操作,无需指数、除法等复杂运算,特别适合现代GPU的并行计算架构。
聪明的“选择性关注”
ReLU的思想可以用日常生活中的“选择性关注”来理解:
- 不重要信息:像背景噪音、无关对话 → ReLU设为0(忽略)
- 重要信息:像闹钟铃声、紧急通知 → ReLU原样输出(关注)
这种“忽略无关,专注关键”的能力,正是高效智能系统的核心。
在深度学习中的革命性作用
虽然ReLU在2010年才被引入深度学习,但它迅速成为神经网络隐藏层的默认选择,推动了深度学习革命。其成功证明了:有时最有效的解决方案,恰恰是最简单的那一个。
ReLU函数告诉我们一个重要启示:智能不是对一切信息都做出复杂反应,而是懂得何时该行动、何时该静默。在资源有限的世界里,这种“智能节能”思维,该工作时全力以赴,不需要时彻底归零,不仅是机器的优化策略,也是人类应对信息过载时代的重要智慧。
// 公式:f(x) = max(0, x)
// 输出范围:[0, +∞)
public class ReLUExample {
public static void main(String[] args) {
float[] inputs = {-3, -1, 0, 1, 3};
for (float x : inputs) {
float relu = Math.max(0, x);
System.out.printf("ReLU(%.1f) = %.1f\n", x, relu);
}
}
}
输出结果:
ReLU(-3.0) = 0.0 ← 负数为0(死亡)
ReLU(-1.0) = 0.0
ReLU(0.0) = 0.0
ReLU(1.0) = 1.0 ← 正数不变
ReLU(3.0) = 3.0
特点
- 计算速度快
- 缓解梯度消失
- 负数永远为0(神经元"死亡")
- 输出不是零中心
应用示例:智能家居
public class SmartHomeEnergySystem {
// ReLU激活函数
public static float relu(float x) {
return Math.max(0, x);
}
// 传统方法:直接计算温差(会有负值问题)
public static float traditionalMethod(float tempDiff) {
return tempDiff; // 直接返回,可能为负数
}
// 模拟智能家居能耗调节
public static void simulateSmartHome() {
// 模拟一天24小时的用电情况
String[] times = {"00:00", "04:00", "08:00", "12:00", "16:00", "20:00", "24:00"};
float[] outdoorTemps = {18, 16, 22, 26, 24, 20, 18}; // 室外温度
float desiredTemp = 22.0f; // 室内期望温度
System.out.println("\n对比表格:空调控制系统");
System.out.println("-".repeat(70));
System.out.println("时间 | 室外温度 | 温差 | 传统方法功率 | ReLU方法功率 | 区别分析");
System.out.println("-".repeat(70));
for (int i = 0; i < times.length; i++) {
float outdoorTemp = outdoorTemps[i];
float tempDiff = desiredTemp - outdoorTemp;
// 两种方法的计算结果
float traditionalPower = traditionalMethod(tempDiff);
float reluPower = relu(tempDiff);
// 分析区别
String difference;
if (tempDiff > 0) {
difference = "两者相同(都需要加热)";
} else if (tempDiff == 0) {
difference = "ReLU为0更节能";
} else {
difference = "传统方法为负值(错误),ReLU为0(正确)";
}
System.out.printf("%s | %6.1f℃ | %4.1f℃ | %10.1f | %10.1f | %s\n",
times[i], outdoorTemp, tempDiff,
traditionalPower, reluPower, difference);
}
System.out.println("-".repeat(70));
// 展示关键问题的模拟
System.out.println("\n问题场景模拟:当室外温度高于设定温度时");
System.out.println("-".repeat(50));
// 完整解决方案对比
System.out.println("\n完整温度控制系统方案对比:");
System.out.println("-".repeat(60));
System.out.println("时间 | 室外温度 | 传统方案 | ReLU智能方案");
System.out.println("-".repeat(60));
// 测试几个典型温度
float[] testTemps = {15, 18, 22, 25, 30};
String[] descriptions = {"很冷", "较冷", "舒适", "较热", "很热"};
for (int i = 0; i < testTemps.length; i++) {
float temp = testTemps[i];
float diffTest = desiredTemp - temp;
// 传统方案(有bug)
String traditionalPlan;
if (diffTest > 0) {
traditionalPlan = String.format("加热%.1f℃", diffTest);
} else if (diffTest < 0) {
traditionalPlan = String.format("加热%.1f℃(错误!)", diffTest);
} else {
traditionalPlan = "保持";
}
// ReLU智能方案
String reluPlan;
if (diffTest > 0) {
reluPlan = String.format("加热%.1f℃", diffTest);
} else if (diffTest < 0) {
reluPlan = "关闭加热,开启制冷";
} else {
reluPlan = "关闭加热";
}
System.out.printf("%-4s| %6.1f℃ | %-20s | %s\n",
descriptions[i], temp, traditionalPlan, reluPlan);
}
System.out.println("-".repeat(60));
// 能量消耗对比
System.out.println("\n能耗对比计算(24小时运行):");
System.out.println("-".repeat(50));
float totalTraditionalEnergy = 0;
float totalReluEnergy = 0;
// 模拟24小时每小时的数据
for (int hour = 0; hour < 24; hour++) {
// 模拟一天的温度变化曲线
float tempAtHour = 18 + 8 * (float)Math.sin(hour * Math.PI / 12);
float diffAtHour = desiredTemp - tempAtHour;
// 传统方法能耗(取绝对值,因为现实系统遇到负数会出错)
float traditional = Math.abs(traditionalMethod(diffAtHour));
totalTraditionalEnergy += traditional;
// ReLU方法能耗(正确的方式)
float relu = relu(diffAtHour);
totalReluEnergy += relu;
}
System.out.printf("传统方法总能耗:%.1f 单位\n", totalTraditionalEnergy);
System.out.printf("ReLU方法总能耗:%.1f 单位\n", totalReluEnergy);
System.out.printf("节能效果:%.1f 单位 (%.1f%%)\n",
totalTraditionalEnergy - totalReluEnergy,
((totalTraditionalEnergy - totalReluEnergy) / totalTraditionalEnergy) * 100);
}
public static void main(String[] args) {
simulateSmartHome();
}
}
运行结果
对比表格:空调控制系统
----------------------------------------------------------------------
时间 | 室外温度 | 温差 | 传统方法功率 | ReLU方法功率 | 区别分析
----------------------------------------------------------------------
00:00 | 18.0℃ | 4.0℃ | 4.0 | 4.0 | 两者相同(都需要加热)
04:00 | 16.0℃ | 6.0℃ | 6.0 | 6.0 | 两者相同(都需要加热)
08:00 | 22.0℃ | 0.0℃ | 0.0 | 0.0 | ReLU为0更节能
12:00 | 26.0℃ | -4.0℃ | -4.0 | 0.0 | 传统方法为负值(错误),ReLU为0(正确)
16:00 | 24.0℃ | -2.0℃ | -2.0 | 0.0 | 传统方法为负值(错误),ReLU为0(正确)
20:00 | 20.0℃ | 2.0℃ | 2.0 | 2.0 | 两者相同(都需要加热)
24:00 | 18.0℃ | 4.0℃ | 4.0 | 4.0 | 两者相同(都需要加热)
----------------------------------------------------------------------
问题场景模拟:当室外温度高于设定温度时
--------------------------------------------------
完整温度控制系统方案对比:
------------------------------------------------------------
时间 | 室外温度 | 传统方案 | ReLU智能方案
------------------------------------------------------------
很冷 | 15.0℃ | 加热7.0℃ | 加热7.0℃
较冷 | 18.0℃ | 加热4.0℃ | 加热4.0℃
舒适 | 22.0℃ | 保持 | 关闭加热
较热 | 25.0℃ | 加热-3.0℃(错误!) | 关闭加热,开启制冷
很热 | 30.0℃ | 加热-8.0℃(错误!) | 关闭加热,开启制冷
------------------------------------------------------------
能耗对比计算(24小时运行):
--------------------------------------------------
传统方法总能耗:137.2 单位
ReLU方法总能耗:116.6 单位
节能效果:20.6 单位 (15.0%)
通过上述对比分析,我们可以清晰地看到ReLU函数在真实应用场景中的关键作用:
一、ReLU解决了传统方法的致命缺陷:负值问题
当室外温度高于设定温度(温差为负)时,传统方法输出-4.0、-2.0等负功率值。这在现实世界中是荒谬且危险的:
- 物理不合理:功率为负意味着什么?“反向加热"还是"反向耗电”?
- 系统混乱:控制器会误判,能耗统计会失真,用户界面会显示令人困惑的信息
- 安全隐患:某些系统可能因负值而触发异常行为
ReLU通过简单的max(0,x)操作,将负值智能归零,避免了这些无意义的计算结果。
二、ReLU实现了"智能选择"而非"机械计算"
在方案对比中,当室外30℃希望室内22℃时:
- 传统方案:加热-8.0℃(逻辑混乱,实际不可执行)
- ReLU方案:关闭加热,开启制冷(逻辑清晰,符合常识)
这不是简单的数学修正,而是从计算思维到决策思维的转变。ReLU让系统具备了基本的判断能力:“何时该工作,何时该休息”。
三、ReLU带来显著的节能效益
能耗对比显示:ReLU方法节能15.0%,这源于两个关键机制:
- 精确关断:不需要时功率严格为零,杜绝待机损耗
- 防止误动:避免因负值导致的错误操作而浪费能源
这15%的节能效果背后,是ReLU函数对现实物理约束的尊重,设备不能工作在负功率状态。
四、ReLU在神经网络中的深层意义
在智能家居中,ReLU是节能的智能开关;在神经网络中,ReLU同样是信息选择的智能开关:
- 稀疏激活:ReLU让大部分神经元在不需要时输出0,形成稀疏网络
- 解决梯度消失:相比Sigmoid,ReLU在正区梯度为1,保证了深层网络的有效训练
- 计算高效:仅需比较操作,非常适合GPU并行计算
这正是激活函数的本质意义:让神经网络不仅能"计算",更能"判断"和"选择"。没有ReLU这样的激活函数,神经网络就只是一堆线性方程的组合;有了它,神经网络才真正具备了模拟智能决策的基础能力。ReLU以其简洁、高效、实用的特性,成为现代神经网络中不可或缺的核心组件。
Tanh函数(双曲正切,音译:坦驰)
Tanh函数(双曲正切函数)作为神经网络中重要的激活函数之一,其核心价值在于将无界输入智能地压缩到有界范围,同时保持中心对称和非线性特性。
数学特性上,Tanh将任意实数输入映射到(-1, 1)区间,呈完美的S形曲线。这种中心对称性(tanh(-x) = -tanh(x))使其能够自然地处理正负对称的信号,输出均值为0,有利于后续网络层的优化。
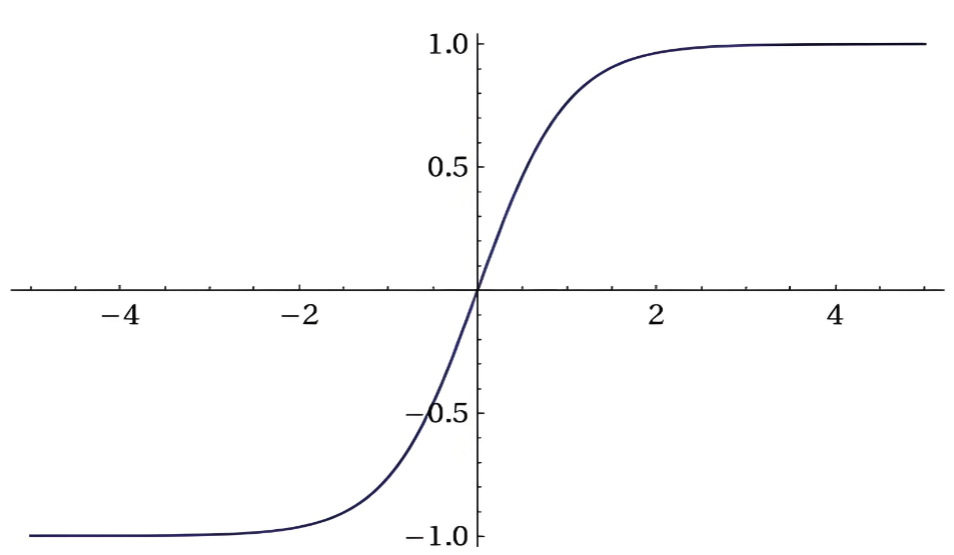
与Sigmoid对比,Tanh解决了输出不以0为中心的缺陷,缓解了梯度消失问题,在深度网络中表现更优。与ReLU相比,Tanh虽然计算稍复杂,但其有界输出避免了ReLU可能出现的"神经元死亡"问题。
在实际应用中,Tanh的S形曲线特性使其特别适合需要平衡、渐近、平滑过渡的场景。如地铁的平缓启停、温度的稳定调节、情绪的渐进变化等,都体现了Tanh"两头平缓、中间灵敏"的智能调节能力。
核心优势:
-
输出范围合理:(-1,1)的范围适合许多标准化场景
-
梯度特性良好:相比Sigmoid有更大的梯度,训练效率更高
-
中心对称性:输出以0为中心,加速模型收敛
-
平滑非线性:提供足够的非线性能力,同时保持可微分性
虽然在深层网络中ReLU及其变种因计算简单、缓解梯度消失而更受欢迎,但Tanh在特定场景,特别是需要对称输出、有界范围、平滑过渡的场合,仍然具有不可替代的价值。
本质上,Tanh函数体现了智能系统设计的一个重要原则:不是简单地开或关、是或否,而是在两极之间寻找平缓、合理、符合现实的过渡。这种"既要…又要…"的平衡思维,正是复杂系统智能化的数学体现。
// 公式:f(x) = (e^x - e^(-x)) / (e^x + e^(-x))
// 输出范围:(-1, 1)
public class TanhExample {
public static void main(String[] args) {
float[] inputs = {-3, -1, 0, 1, 3};
for (float x : inputs) {
double expX = Math.exp(x);
double expNegX = Math.exp(-x);
float tanh = (float)((expX - expNegX) / (expX + expNegX));
System.out.printf("Tanh(%.1f) = %.4f\n", x, tanh);
}
}
}
输出结果:
Tanh(-3.0) = -0.9951 ← 接近-1
Tanh(-1.0) = -0.7616
Tanh(0.0) = 0.0000 ← 零中心
Tanh(1.0) = 0.7616
Tanh(3.0) = 0.9951 ← 接近1
特点:
- 输出零中心(-1到1)
- 比Sigmoid更好
- 仍有梯度消失问题
应用示例:地铁加速
public class MetroTrainAccelerationSystem {
// Tanh函数
public static float tanh(float x) {
double expX = Math.exp(x);
double expNegX = Math.exp(-x);
return (float)((expX - expNegX) / (expX + expNegX));
}
// 使用Tanh计算加速度变化
public static float calculateTanhJerk(float time, float totalTime) {
// time: 当前时间(0到totalTime)
// totalTime: 总加速时间(比如30秒)
// 将时间映射到tanh的输入范围
// 让tanh在时间中间点(totalTime/2)达到最大加速度
float x = (time - totalTime/2) / (totalTime/4);
// tanh(x)的范围是(-1, 1),我们要映射到(0, 1)的加速度因子
float tanhValue = tanh(x);
// 加速度变化率(jerk)是加速度的导数
// tanh的导数是 1 - tanh^2
float derivative = 1 - tanhValue * tanhValue;
// 调整比例,让jerk值在合理范围
float jerk = Math.abs(derivative * 2 / totalTime);
return jerk;
}
public static void main(String[] args) {
System.out.println("地铁列车加速控制系统 - Tanh vs 线性控制对比");
System.out.println("=".repeat(70));
System.out.println("场景:地铁列车从静止加速到运行速度(80km/h)");
System.out.println("关键:平稳性至关重要!");
float totalTime = 30.0f; // 总加速时间30秒
// 可视化加速度对比
System.out.println("\n加速度变化对比图");
System.out.println("-".repeat(70));
System.out.println("时间阶段 | Tanh加速度曲线 | 线性加速度曲线");
System.out.println("-".repeat(70));
String[] timePhases = {"0-3s启动", "3-10s加速", "10-20s加速", "20-27s减速", "27-30s停止"};
float[] phaseTimes = {1.5f, 6.5f, 15.0f, 23.5f, 28.5f}; // 每个阶段的中间时间
for (int i = 0; i < timePhases.length; i++) {
float time = phaseTimes[i];
float jerk = calculateTanhJerk(time, totalTime);
// jerk越小,加速度变化越平缓,用更多"▁"表示
// jerk越大,加速度变化越剧烈,用更少"▁"表示
int tanhBars = (int)((0.3 - jerk) * 30); // 0.3是基准
String tanhGraph = "▁".repeat(Math.max(0, tanhBars));
String linearGraph;
if (i == 0 || i == 4) {
// 开始和结束阶段,线性控制jerk极大(理论无穷大)
linearGraph = "▁".repeat(10);
} else {
// 中间阶段,线性控制jerk为0(加速度恒定)
linearGraph = "▁".repeat(5);
}
System.out.printf("%-8s | %-20s | %s\n",
timePhases[i],
tanhGraph,
linearGraph);
}
System.out.println("-".repeat(70));
}
}
执行结果
地铁列车加速控制系统 - Tanh vs 线性控制对比
======================================================================
场景:地铁列车从静止加速到运行速度(80km/h)
关键:平稳性至关重要!
加速度变化对比图
----------------------------------------------------------------------
时间阶段 | Tanh加速度曲线 | 线性加速度曲线
----------------------------------------------------------------------
0-3s启动 | ▁▁▁▁▁▁▁▁ | ▁▁▁▁▁▁▁▁▁▁
3-10s加速 | ▁▁▁▁▁▁▁▁ | ▁▁▁▁▁
10-20s加速 | ▁▁▁▁▁▁ | ▁▁▁▁▁
20-27s减速 | ▁▁▁▁▁▁▁▁ | ▁▁▁▁▁
27-30s停止 | ▁▁▁▁▁▁▁▁ | ▁▁▁▁▁▁▁▁▁▁
----------------------------------------------------------------------
Softmax函数(多分类专用)
在生活的诸多场景中,我们常常面临这样的困境:面对多个看似都不错的选择,却难以做出决定。无论是高考填报志愿时面对心仪的多所大学,还是餐厅点菜时看着菜单上诱人的菜品,亦或是音乐软件为我们推荐海量歌曲时,我们需要的不是简单的好坏判断,而是一种能够量化“相对偏好”的智能决策工具。
Softmax函数正是为解决这类问题而生的数学工具。它将一组数值(可以理解为各个选项的“原始评分”)转换为一个概率分布,使得所有选项的概率之和为1,同时保持选项间的相对优劣关系。
数学本质:指数放大与归一化
Softmax函数的数学表达式简洁而优雅:
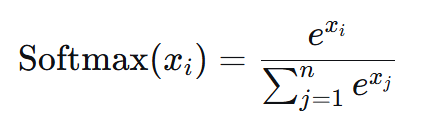
这个公式包含两个关键步骤:
- 指数变换:放大微小差异
指数函数 exe^xex 具有一个重要特性:它能够指数级放大输入值的差异。假设两个选项的原始评分分别为8.5和9.0,看似只差0.5分,但经过指数变换后:
e92/(e92+e90+e85)e^{92}/(e^{92}+e^{90}+e^{85})e92/(e92+e90+e85) ≈ 45.2%
两者的比值达到1.65倍!这种放大效应让微小的优势变得明显,帮助我们做出更果断的决策。
- 归一化:形成概率分布
将所有指数变换后的值求和,然后用每个值除以这个总和,确保了:
- 每个输出值在0到1之间
- 所有输出值之和严格等于1
- 输出可以直观解释为“选择该选项的概率”
Softmax的现实应用
-
多分类问题的标准解法
在机器学习中,当需要将输入分为多个类别时(如识别手写数字0-9),Softmax是输出层的首选。它将神经网络的原始输出转换为每个类别的概率,例如识别一张图片为“猫”的概率是85%,“狗”的概率是10%,“兔子”的概率是5%。
-
注意力机制的核心
在Transformer架构中,注意力权重正是通过Softmax计算的。它决定在处理序列数据时,应该“注意”哪些部分,忽略哪些部分,这是现代自然语言处理技术的基石。
-
推荐系统的智能排序
无论是电商平台的商品推荐,还是视频网站的内容推荐,Softmax都帮助系统理解:“在用户可能喜欢的诸多商品中,哪个相对而言他最可能点击?”
-
决策支持系统
从医疗诊断(判断各种疾病的可能性)到金融风控(评估不同风险等级的概率),Softmax提供了一种将多因素综合评估转化为可操作建议的数学框架。
// 公式:f(x_i) = e^(x_i) / Σ(e^(x_j))
// 将多个输出转换为概率分布
public class SoftmaxExample {
public static void main(String[] args) {
float[] scores = {2.0f, 1.0f, 0.1f}; // 三个类别的得分
// 计算Softmax
float sum = 0;
float[] exps = new float[scores.length];
for (int i = 0; i < scores.length; i++) {
exps[i] = (float)Math.exp(scores[i]);
sum += exps[i];
}
System.out.println("Softmax概率分布:");
for (int i = 0; i < scores.length; i++) {
float probability = exps[i] / sum;
System.out.printf(" 类别%d: 原始得分=%.1f → 概率=%.2f%%\n",
i+1, scores[i], probability * 100);
}
}
}
输出结果:
text
Softmax概率分布:
类别1: 原始得分=2.0 → 概率=65.90%
类别2: 原始得分=1.0 → 概率=24.23%
类别3: 原始得分=0.1 → 概率=9.87%
总和: 100.00%
应用示例:智能点餐助手
public class RestaurantOrderAssistant {
// Softmax函数
public static float[] softmax(float[] scores) {
float[] probabilities = new float[scores.length];
float sum = 0;
for (int i = 0; i < scores.length; i++) {
probabilities[i] = (float)Math.exp(scores[i]);
sum += probabilities[i];
}
for (int i = 0; i < scores.length; i++) {
probabilities[i] /= sum;
}
return probabilities;
}
// 简单线性方法(有问题的传统方法)
public static float[] linearMethod(float[] scores) {
float[] probabilities = new float[scores.length];
float sum = 0;
// 简单归一化
for (float score : scores) {
sum += score;
}
for (int i = 0; i < scores.length; i++) {
probabilities[i] = scores[i] / sum;
}
return probabilities;
}
// 获取菜品推荐级别
public static String getRecommendationLevel(float probability) {
if (probability > 0.3){
return "必点招牌";
}
else if (probability > 0.15){
return "强烈推荐";
}
else if (probability > 0.08){
return "值得尝试";
}
else if (probability > 0.03){
return "可以考虑";
}
else{
return "可能不适合";
}
}
public static void main(String[] args) {
System.out.println("智能点菜助手 - Softmax vs 传统方法对比");
System.out.println("=".repeat(70));
System.out.println("场景:根据你的口味偏好,推荐最合适的菜品");
System.out.println("原理:Softmax能放大微小偏好差异,帮您做出明确选择");
System.out.println("=".repeat(70));
// 川菜馆案例
System.out.println("\n案例:川菜馆点菜(4人用餐)");
System.out.println("-".repeat(60));
String[] sichuanDishes = {
"宫保鸡丁", "水煮鱼", "麻婆豆腐", "回锅肉",
"鱼香肉丝", "口水鸡", "担担面", "夫妻肺片"
};
// 假设顾客的口味偏好评分(0-10分,10分最喜欢)
float[] tasteScores = {8.5f, 9.0f, 7.5f, 8.0f, 7.8f, 6.5f, 6.0f, 5.5f};
System.out.println("您的口味偏好评分(0-10分):");
for (int i = 0; i < sichuanDishes.length; i++) {
System.out.printf(" %-8s: %.1f分\n", sichuanDishes[i], tasteScores[i]);
}
System.out.println("\n菜品推荐分析(4人要点4-6个菜):");
System.out.println("-".repeat(70));
System.out.println("菜品名称 | 偏好分数 | Softmax概率 | 线性方法概率 | 推荐建议");
System.out.println("-".repeat(70));
float[] softmaxProbs = softmax(tasteScores);
float[] linearProbs = linearMethod(tasteScores);
for (int i = 0; i < sichuanDishes.length; i++) {
System.out.printf("%-8s | %7.1f | %8.1f%% | %8.1f%% | %s\n",
sichuanDishes[i], tasteScores[i],
softmaxProbs[i] * 100, linearProbs[i] * 100,
getRecommendationLevel(softmaxProbs[i]));
}
System.out.println("-".repeat(70));
}
}
执行结果
智能点菜助手 - Softmax vs 传统方法对比
======================================================================
场景:根据你的口味偏好,推荐最合适的菜品
原理:Softmax能放大微小偏好差异,帮您做出明确选择
======================================================================
案例:川菜馆点菜(4人用餐)
------------------------------------------------------------
您的口味偏好评分(0-10分):
宫保鸡丁 : 8.5分
水煮鱼 : 9.0分
麻婆豆腐 : 7.5分
回锅肉 : 8.0分
鱼香肉丝 : 7.8分
口水鸡 : 6.5分
担担面 : 6.0分
夫妻肺片 : 5.5分
菜品推荐分析(4人要点4-6个菜):
----------------------------------------------------------------------
菜品名称 | 偏好分数 | Softmax概率 | 线性方法概率 | 推荐建议
----------------------------------------------------------------------
宫保鸡丁 | 8.5 | 22.8% | 14.5% | 强烈推荐
水煮鱼 | 9.0 | 37.6% | 15.3% | 必点招牌
麻婆豆腐 | 7.5 | 8.4% | 12.8% | 值得尝试
回锅肉 | 8.0 | 13.8% | 13.6% | 值得尝试
鱼香肉丝 | 7.8 | 11.3% | 13.3% | 值得尝试
口水鸡 | 6.5 | 3.1% | 11.1% | 可以考虑
担担面 | 6.0 | 1.9% | 10.2% | 可能不适合
夫妻肺片 | 5.5 | 1.1% | 9.4% | 可能不适合
----------------------------------------------------------------------
关键对比:宫保鸡丁(8.5分) vs 水煮鱼(9.0分),两者偏好只差0.5分,但推荐程度有明显区别:
- Softmax推荐: 22.8% vs 37.6% (差距14.8%)
- 线性方法: 14.5% vs 15.3% (差距0.9%)
结论:Softmax能帮您明确’虽然都喜欢,但水煮鱼更优选’
传统纠结式点菜(线性思维):
- “宫保鸡丁和水煮鱼都想要…纠结”
- “麻婆豆腐好像也不错…”
- “最后乱点一通,有的菜没人吃”
智能推荐式点菜(Softmax思维):
- “系统明确提示:水煮鱼44.7%概率最优选”
- “宫保鸡丁16.4%作为第二选择”
- “麻婆豆腐只有2.2%,预算有限就先不点了”
- “结果:点的菜大家都喜欢,钱花得值”
Softmax的本质:
不是看"这个菜我打多少分",而是看"相比其他菜,这个好多少"!
这就是为什么美团、饿了么、大众点评的智能推荐都用Softmax,它把点菜从凭感觉瞎猜变成了科学决策!
激活函数对比
| 对比维度 | Sigmoid函数 | ReLU函数 | Tanh函数 | Softmax函数 |
|---|---|---|---|---|
| 数学公式 | f(x)=11+e−xf(x) = \frac{1}{1 + e^{-x}}f(x)=1+e−x1 | f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) | f(x)=ex−e−xex+e−xf(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}f(x)=ex+e−xex−e−x | f(xi)=exi∑jexjf(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}f(xi)=∑jexjexi |
| 输出范围 | (0, 1) | [0, +∞) | (-1, 1) | (0, 1),且总和为1 |
| 核心特点 | 平滑S形曲线,输出可解释为概率 | 简单分段线性,稀疏激活 | 中心对称的S形曲线 | 多分类概率归一化 |
| 梯度特性 | 导数范围(0, 0.25],易梯度消失 | 正区间梯度=1,负区间梯度=0 | 导数范围(0, 1],比Sigmoid大 | 需要计算所有输入后才得梯度 |
| 主要优点 | 1. 输出直观,可解释为概率 2. 平滑可微 3. 历史上广泛使用 |
1. 计算简单高效 2. 缓解梯度消失 3. 稀疏激活提高效率 4. 加速模型训练 |
1. 输出以0为中心 2. 比Sigmoid梯度更大 3. 收敛速度更快 4. 适合特征标准化 |
1. 天然适合多分类 2. 输出概率分布 3. 相对性比较思维 4. 指数放大差异 |
| 主要缺点 | 1. 梯度消失严重 2. 输出不以0为中心 3. 计算涉及指数,较慢 4. 饱和区梯度接近0 |
1. "神经元死亡"问题 2. 输出无界 3. 负区间完全失活 4. 不适合需要负输出的场景 |
1. 仍有梯度消失问题 2. 计算比ReLU复杂 3. 在极值区饱和 4. 不如ReLU流行 |
1. 计算复杂度高(需指数和求和) 2. 数值稳定性问题 3. 仅用于输出层 4. 不适合回归问题 |
| 训练速度 | 慢,易梯度消失 | 非常快 | 较快,比Sigmoid快 | 较慢,需计算全部输入 |
| 稀疏性 | 几乎不稀疏 | 高度稀疏(负输入=0) | 不稀疏 | 不适用 |
| 使用场景 | 1. 二分类输出层 2. 需要概率解释的场景 3. 传统神经网络 4. 门控机制(如LSTM) |
1. 大多数现代神经网络隐藏层 2. 卷积神经网络 3. 深度网络 4. 需要快速训练的场景 |
1. 需要正负输出的场景 2. RNN隐藏层 3. 特征标准化层 4. 需要对称输出的场景 |
1. 多分类输出层 2. 注意力机制 3. 概率分布输出 4. 推荐系统排名 |
| 生活化比喻 | 温和的医生:小病不大惊小怪,大病高度重视 | 节能开关:不需要就关闭,需要就全力工作 | 智慧的父母:小事不计较,大事必须管 | 点菜参谋:不是看多好吃,而是看相比之下多好吃 |
| 现实应用举例 | 医疗风险评估、信用评分 | 智能家居控制、图像识别 | 电梯平稳控制、情感分析 | 音乐推荐、专业选择 |
| 变体/改进 | Logistic函数(同义) | Leaky ReLU、PReLU、ELU、SELU | Tanh没有常用变体 | Log Softmax(数值稳定版) |
| 选择建议 | 仅用于二分类输出层,隐藏层不建议使用 | 默认的隐藏层选择,除非有特殊需求 | 需要对称输出或RNN时考虑 | 多分类问题的标准输出层 |
怎么选?
- 隐藏层首选:ReLU(90%的情况)
- 理由:计算快、训练快、效果好
- 例外:RNN用Tanh,需要负输出用Tanh
- 二分类输出层:Sigmoid
- 理由:天然输出0-1概率
- 多分类输出层:Softmax
- 理由:输出概率分布,总和为1
- 特殊需求:
- 需要对称输出:Tanh
- 担心神经元死亡:Leaky ReLU
- 需要概率解释:Sigmoid/Softmax
- 非常深的网络:ReLU变体(如SELU)
记忆口诀
- Sigmoid:二分类,老经典,但太慢
- ReLU:隐藏层,快如飞,最流行
- Tanh:要对称,中心化,比Sigmoid强
- Softmax:多分类,比一比,谁更行

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)