Java AI 之 DJL 实战(第 4 篇):归一化
归一化
介绍
归一化是把数据转换成固定范围(最常用 0~1) 的数据预处理操作,核心目的是让不同量纲、不同范围的数据 “站在同一水平线” 上,方便模型训练和计算,是深度学习里必用的预处理步骤。
举个例子
例如我有一个会说多种语言的朋友:
- 英语水平:雅思8分
- 日语水平:N2级
- 中文水平:HSK5级
每个考试评分标准完全不同!归一化就像一个统一的评分转换器,把所有语言能力都转换到0-100分:
- 雅思8分 → 90分
- 日语N2级 → 75分
- 中文HSK5级 → 80分
现在你能公平比较他的语言能力了!
另一个例子
有来自三个国家的人身上分别有不同数量的现金:
- 中国人:身上有5000元人民币
- 日本人:有80000日元
- 美国人:有1000美元
这些数字不能直接比较!归一化就像把所有钱都换成欧元:
- 5000元人民币 → 650欧元
- 80000日元 → 550欧元
- 1000美元 → 900欧元
示例代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
public class CurrencyNormalization {
public static void main(String[] args) {
// 1. 创建NDManager(DJL核心,用于管理NDArray)
try (NDManager manager = NDManager.newBaseManager()) {
// 2. 原始数据:[中国人(人民币), 日本人(日元), 美国人(美元)]
// create方法创建NDArray,参数1:数据数组,参数2:形状(3行1列)
NDArray originalCurrency = manager.create(new float[]{5000, 80000, 1000});
System.out.println("=== 原始现金数量 ===");
System.out.println("中国人(人民币):" + originalCurrency.getFloat(0));
System.out.println("日本人(日元):" + originalCurrency.getFloat(1));
System.out.println("美国人(美元):" + originalCurrency.getFloat(2));
// 3. 第一步:统一转换成欧元(消除货币单位差异,模拟“去量纲”)
// 汇率(示例值):1人民币≈0.13欧元,1日元≈0.006875欧元,1美元≈0.9欧元
NDArray euroRates = manager.create(new float[]{0.13f, 0.006875f, 0.9f});
NDArray euroAmount = originalCurrency.mul(euroRates); // 原始金额 × 汇率 = 欧元金额
System.out.println("\n=== 转换为欧元后 ===");
System.out.println("中国人(欧元):" + euroAmount.getFloat(0)); // 5000×0.13=650
System.out.println("日本人(欧元):" + euroAmount.getFloat(1)); // 80000×0.006875=550
System.out.println("美国人(欧元):" + euroAmount.getFloat(2)); // 1000×0.9=900
// 4. 第二步:手动实现Min-Max归一化(核心:(X - Xmin)/(Xmax - Xmin))
// 计算欧元金额的最小值和最大值
NDArray euroMin = euroAmount.min(); // 550
NDArray euroMax = euroAmount.max(); // 900
// 归一化计算
NDArray normalizedAmount = euroAmount.sub(euroMin).div(euroMax.sub(euroMin));
// 5. 输出归一化结果(0~1范围,可直接比较)
System.out.println("\n=== 归一化后(0~1范围) ===");
System.out.println("中国人:" + normalizedAmount.getFloat(0)); // (650-550)/(900-550) = 100/350 ≈ 0.2857
System.out.println("日本人:" + normalizedAmount.getFloat(1)); // (550-550)/350 = 0
System.out.println("美国人:" + normalizedAmount.getFloat(2)); // (900-550)/350 = 350/350 = 1
// 6. 验证:归一化后范围是否在0~1之间
System.out.println("\n=== 归一化范围验证 ===");
System.out.println("归一化最小值:" + normalizedAmount.min().getFloat()); // 0
System.out.println("归一化最大值:" + normalizedAmount.max().getFloat()); // 1
}
}
}
执行结果
=== 原始现金数量 ===
中国人(人民币):5000.0
日本人(日元):80000.0
美国人(美元):1000.0
=== 转换为欧元后 ===
中国人(欧元):650.0
日本人(欧元):550.0
美国人(欧元):900.0
=== 归一化后(0~1范围) ===
中国人:0.2857143
日本人:0.0
美国人:1.0
=== 归一化范围验证 ===
归一化最小值:0.0
归一化最大值:1.0
为什么要归一化数据到[0,1]范围内
用 650、550、900 这些欧元数值看似能比较,但在算法 / 模型场景下存在核心问题。 归一化到 0~1 不是 “多此一举”,而是为了让数据适配算法的运行逻辑。
上面的例子里欧元数值是 550~900,范围差 350;但如果换一组数据(
- 中国人:10000 人民币→1300 欧元
- 日本人:10000 日元→68.75 欧元
- 美国人:100 美元→90 欧元),欧元范围变成 68.75~1300,差值超 1200。
此时算法会出现两个问题:
- 权重更新失衡:深度学习模型的权重初始化通常在 [-1,1] 或 [0,1] 附近,用 1300 这种大数值计算时,梯度会变得极大 / 极小,导致模型训练不收敛(比如权重直接 “飞掉”);
- 特征重要性误判:如果同时输入 “现金(欧元)” 和 “年龄(20~80)” 两个特征,算法会默认 “现金数值大 = 更重要”,但其实年龄和现金是同等重要的特征, 这就是、 “量纲陷阱”,哪怕统一成欧元,数值范围差异依然会导致误判。
650/550/900 的 “绝对数值” 无通用参考意义
- 对人来说:知道 “900 欧元> 650 欧元” 就够了;
- 对算法来说:需要 “相对比例” 而非 “绝对数值”, 比如 “0.2857” 代表 “比最小值高 28.57%”,“1” 代表 “最大值”,这个比例在任何数据集里都有统一含义,而 650/900 这些数换个场景就失去意义(比如另一组数据是 10/20/30 欧元,650 和 10 无法直接对比比例)。
原始数据存在的问题
| 问题(用原始欧元数值) | 解决(归一化到 0~1) |
|---|---|
| 数值范围大(550~900)→ 模型梯度爆炸 / 收敛慢 | 范围压缩到 0~1 → 梯度稳定,训练效率提升(DJL 中sub/div后数值更小,计算更快) |
| 不同特征(如现金 + 年龄)范围差异大 → 模型偏向数值大的特征 | 所有特征统一到 0~1 → 模型公平对待每个特征 |
| 绝对数值无通用标准 → 跨数据集对比困难 | 相对比例(0~1)是通用标准 → 比如 A 数据集的 0.5 和 B 数据集的 0.5 都代表 “中间水平” |
| 激活函数适配差(如 sigmoid 在数值大时梯度趋近于 0) | 0~1 范围完美适配 sigmoid/tanh 等激活函数(sigmoid 在 0~1 区间梯度最大) |
示例对比:归一化如何稳定模型训练
我们用一个最简单的线性模型 消费能力 = 现金 × w + b 来预测,其中 w (权重)和 b (偏置)是模型需要学习的参数。我们分别使用原始数据和归一化数据进行训练,观察会发生什么。
前提设定:
- 初始权重
w = 0.1,偏置b = 0.5 - 学习率
η = 0.001
偏置是模型中的一个可调节的“基准线”或“起点”,它允许模型的预测函数整体向上或向下平移,以更好地拟合数据。
学习率是模型每次根据误差调整自身参数时的“步长”大小。
可以类比为学走路时,跨一大步容易摔倒,走一小步则平稳可控。学习率太大,模型会“跑过头”而无法收敛;学习率太小,模型“进步”又太慢。
最常见的学习率范围是 0.001 到 0.1
场景一:使用原始欧元数值(68.75, 1300, 90)
| 国家 | 现金 (欧元) | 计算过程 (现金 × w + b) | 预测值 |
|---|---|---|---|
| 日本人 | 68.75 | 68.75 × 0.1 + 0.5 | 7.375 |
| 美国人 | 90 | 90 × 0.1 + 0.5 | 9.5 |
| 中国人 | 1300 | 1300 × 0.1 + 0.5 | 130.5 |
问题暴露:
当我们根据预测误差来更新权重 w 时,其更新公式为 w_new = w_old - η × 梯度。这里的 “梯度” 就等于输入的特征值(现金)本身。
以中国人的数据为例进行第一次更新:
- 梯度值 = 1300 (数值极大)
- 权重更新:
w_new = 0.1 - 0.001 × 1300 = -1.2
严重后果: 权重 w 从初始的 0.1 直接跳变为 -1.2,不仅方向反了,而且幅度巨大。这会导致模型预测完全失控,后续训练将极不稳定,难以收敛到正确的解。
场景二:使用归一化后的数值(0, 1, 0.0173)
首先将现金数据归一化到 [0, 1] 范围:
- 最小值:日本人 68.75 → 0
- 最大值:中国人 1300 → 1
- 美国人:
(90 - 68.75) / (1300 - 68.75) ≈ 0.0173
| 国家 | 现金 (归一化) | 计算过程 (现金 × w + b) | 预测值 |
|---|---|---|---|
| 日本人 | 0 | 0 × 0.1 + 0.5 | 0.5 |
| 美国人 | 0.0173 | 0.0173 × 0.1 + 0.5 | 0.50173 |
| 中国人 | 1 | 1 × 0.1 + 0.5 | 0.6 |
优势体现:
同样以中国人的数据为例进行权重更新:
- 梯度值 = 1 (数值稳定)
- 权重更新:
w_new = 0.1 - 0.001 × 1 = 0.099
训练效果: 权重 w 仅从 0.1 微调至 0.099,更新非常平稳。模型能够通过成百上千次这样稳定、小幅度的迭代,逐步调整参数,最终平滑地学习到数据中的规律并成功收敛。
通过这个对比可以清晰地看到:
- 原始数据的问题: 特征数值范围过大(如1300)会导致梯度“爆炸”,使得模型更新步伐过大、方向混乱,就像用巨斧雕刻,极易损坏作品(模型)。
- 归一化的作用: 将所有特征压缩到相近的尺度(如0~1),相当于换上了精细的刻刀。每次更新(梯度下降)都变得平稳、可控,模型能够稳定、高效地学习到最优解,这是现代机器学习算法能够可靠工作的基石之一。
偏置
偏置是模型中的一个可调节的“基准线”或“起点”,它允许模型的预测函数整体向上或向下平移,以更好地拟合数据。
为了直观地理解偏置的作用,可以想象拟合一条直线(y = w*x + b)到一组数据点上:
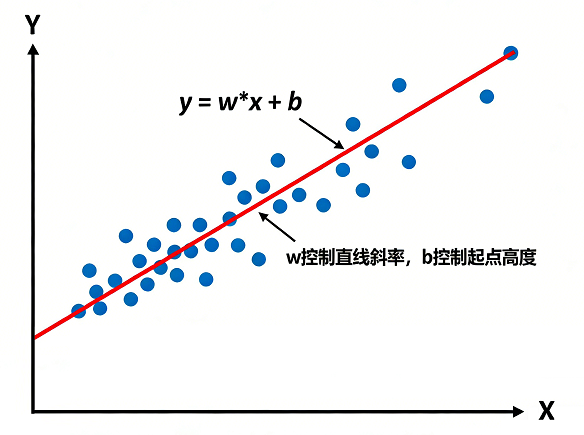
如上图所示:
- 权重 (w) 主要负责控制模型的敏感度和方向(直线有多斜)。
- 偏置 (b) 主要负责控制模型的基准位置(直线的起点高度)。
用一个现实比喻来理解:
想象一个根据“工作年限”预测“薪资”的模型:
- 公式:
预测薪资 = 权重 × 工作年限 + 偏置 - 权重 (
w= 1.5万/年):代表每多一年经验,薪资平均增加1.5万元。它控制了增长速率。 - 偏置 (
b= 8万):代表即使是零经验(工作年限为0)的应届毕业生,行业平均起薪也有8万元。它设定了预测的起点。
如果没有偏置 (b=0):
- 公式变为
薪资 = 1.5 × 工作年限。 - 那么零经验者的预测薪资将为
0,这显然不符合现实。 - 模型将被迫让权重 (
w) 既学习增长率,又试图补偿这个不合理的0起点,这会扭曲权重本应学习的核心规律,极大地限制模型的表达能力。
学习率
学习率是优化算法中的关键超参数,用于控制模型参数在每次迭代中基于梯度信息进行调整的步长大小。它决定了模型在参数空间中沿梯度负方向更新时的移动幅度。
在梯度下降及其变体算法中,学习率(通常表示为η或α)直接影响了训练过程的收敛速度与稳定性:
- 学习率过大会导致参数更新幅度过大,可能使损失函数在最优解附近振荡甚至发散,导致无法收敛;
- 学习率过小则会使参数更新过于缓慢,导致收敛速度过慢或陷入局部极小值。
现代深度学习实践中常采用动态学习率策略,如学习率预热(Warmup)、周期衰减(Cyclical Decay)或余弦退火(Cosine Annealing),以在训练不同阶段自适应调整步长,从而在训练初期加速收敛,在后期精细调优,提升模型的最终性能与训练效率。合理设置学习率是实现模型高效、稳定收敛的重要前提。
例如
学习率 = 每次调整车把的幅度
- 学习率太大(幅度大):
感觉往左倒 → 猛向右转 → 又往右倒 → 猛向左转
→ 结果:剧烈摇晃,直接摔倒(模型发散)
- 学习率太小(幅度小):
感觉往左倒 → 微微向右 → 还在往左倒 → 再微微向右
→ 结果:调整太慢,还没平衡就倒了(收敛太慢)
- 学习率适中:
感觉往左倒 → 适度向右 → 接近平衡 → 微调
→ 结果:平稳学会骑车(模型收敛)
有例如
学习率 = 每次转动热水阀的角度
- 学习率太大(转半圈):
水冷 → 猛开热水 → 烫伤 → 猛关 → 又冷...
→ 结果:永远找不到舒适水温(震荡不收敛)
- 学习率太小(转1度):
水冷 → 转1度 → 还是冷 → 再转1度...
→ 结果:要转100次才到合适温度(训练太慢)
- 学习率适中(转15度):
水冷 → 转15度 → 微凉 → 转5度 → 刚好
→ 结果:快速找到舒适水温(高效收敛)
消费能力预测例子
1.原始问题回顾
我们要预测:消费能力 = 现金 × w + b
假设我们已经知道正确答案:
- 最佳w = 0.25,最佳b = 0.3
- 但我们从w=0.1,b=0.5开始猜
2.不同学习率下的学习过程
场景:用美国人的数据(归一化现金 = 1)训练
假设真实消费能力 = 0.55
初始:w=0.1, b=0.5
预测值 = 1 × 0.1 + 0.5 = 0.6
误差 = 0.6 - 0.55 = 0.05
学习率太大
第1轮:学习率 η = 0.8
梯度计算:
对w的梯度 = 误差 × 现金 = 0.05 × 1 = 0.05
对b的梯度 = 误差 × 1 = 0.05
参数更新:
w_new = 0.1 - 0.8×0.05 = 0.1 - 0.04 = 0.06
b_new = 0.5 - 0.8×0.05 = 0.5 - 0.04 = 0.46
新预测:1×0.06 + 0.46 = 0.52(误差-0.03)
问题:
-
w从0.1→0.06,变化0.04
-
但我们需要w增加到0.25!方向都反了!
-
学习率太大导致矫正过正
第2轮:继续 η = 0.8
新误差 = 0.52 - 0.55 = -0.03
梯度 = -0.03
更新:
w = 0.06 - 0.8×(-0.03) = 0.06 + 0.024 = 0.084
b = 0.46 - 0.8×(-0.03) = 0.46 + 0.024 = 0.484
预测:0.084 + 0.484 = 0.568(误差0.018)
结果:w在0.06↔0.084来回震荡,永远到不了0.25
学习率太小
第1轮:学习率 η = 0.001
梯度 = 0.05(同上)
更新:
w_new = 0.1 - 0.001×0.05 = 0.1 - 0.00005 = 0.09995
b_new = 0.5 - 0.001×0.05 = 0.5 - 0.00005 = 0.49995
预测:0.09995 + 0.49995 ≈ 0.5999(几乎没变)
问题:
-
要增加w到0.25,需要增加0.15
-
每次只增加0.00005,需要3000轮!
-
学习率太小导致学习太慢
学习率适中
第1轮:学习率 η = 0.1
梯度 = 0.05
更新:
w_new = 0.1 - 0.1×0.05 = 0.1 - 0.005 = 0.095
b_new = 0.5 - 0.1×0.05 = 0.5 - 0.005 = 0.495
预测:0.095 + 0.495 = 0.59(误差0.04)
第2轮:
新梯度 = 0.04
w = 0.095 - 0.1×0.04 = 0.095 - 0.004 = 0.091
b = 0.495 - 0.1×0.04 = 0.495 - 0.004 = 0.491
预测:0.091 + 0.491 = 0.582(误差0.032)
进展:
- w在缓慢减小,b也在减小
- 方向正确,步伐稳定!
梯度
梯度是多元函数在某一点处的偏导数构成的向量,表征了函数值在该点处增长最快的方向及其变化率。在机器学习中,梯度指向损失函数在当前参数取值下上升最陡的方向,其负方向即为使损失函数下降最快的参数更新方向。梯度的大小反映了函数在该方向的敏感程度,是优化算法确定参数调整幅度与方向的核心依据。
梯度的 2 个核心作用
① 指示方向:梯度方向是损失函数增大最快的方向,参数沿梯度反方向更新,才能让损失函数减小(即梯度下降法核心逻辑);
② 反映速率:梯度的绝对值大小,代表损失函数随参数变化的快慢 ,绝对值越大,参数对损失影响越显著,更新幅度也越大。
例如预测消费能力的实力中
存在的问题:最终结果误差0.05太大,最优解应该是0
模型:消费能力 = w × 现金 + b
当前参数:w=0.1, b=0.5
训练数据:美国人(现金=1,真实消费能力=0.55)
预测值:1×0.1 + 0.5 = 0.6
误差:0.6 - 0.55 = 0.05
两个问题:
-
w应该增加还是减少?
-
b应该增加还是减少?
计算步骤
步骤1、定义错误程度(损失函数)
损失 = ½ × (预测值 - 真实值)²
= ½ × (0.6 - 0.55)²
= ½ × 0.05²
= ½ × 0.0025
= 0.00125
乘½是为了求导后系数为1,简化计算
“乘½是为了求导后系数为1,简化计算” 这句话怎么理解
1.1、原始损失函数(不乘½):
损失 = (预测值 - 真实值)²
= (0.6 - 0.55)²
= 0.0025
对w求导:
∂损失/∂w = ∂[(w×x+b - y_true)²]/∂w
= 2 × (w×x+b - y_true) × ∂(w×x+b)/∂w
= 2 × 误差 × x
= 2 × 0.05 × 1
= 0.1
得到梯度:0.1
1.2、乘½后的情况
损失 = ½ × (预测值 - 真实值)²
= ½ × 0.0025
= 0.00125
对w求导:
∂损失/∂w = ∂[½×(w×x+b - y_true)²]/∂w
= ½ × 2 × (w×x+b - y_true) × ∂(w×x+b)/∂w
= 1 × 误差 × x
= 1 × 0.05 × 1
= 0.05
得到梯度:0.05
1.3、为什么说「简化计算」?
比较两种梯度:
不乘½:梯度 = 2 × 误差 × x = 0.1
乘½后:梯度 = 1 × 误差 × x = 0.05
关键区别:系数从2变成了1
这带来的简化:
-
数学表达式更简洁
原式:∂L/∂w = 2·error·x 现式:∂L/∂w = error·x (少了系数2) -
更新公式更干净
原更新:w_new = w - η·(2·error·x) 现更新:w_new = w - η·(error·x) -
学习率调整更直观
假设想要实际更新步长为0.01: - 不乘½:需要设 η = 0.01/2 = 0.005 - 乘½后:直接设 η = 0.01 即可
1.4、更深入的理解
这½系数只是缩放因子
它改变的是损失函数的绝对值尺度,但不改变相对形状。
类比: 把地图按比例缩小一半
- 所有距离数值都减半
- 但北京在上海的北方这个方向关系不变
- 但北京到上海的距离这个数值变了
不影响优化结果
因为梯度下降关注的是方向而不是绝对数值:
情况A(不乘½):
损失 = error²
梯度 = 2·error·x
更新:w_new = w - η·(2·error·x)
情况B(乘½):
损失 = ½·error²
梯度 = error·x
更新:w_new = w - η·(error·x)
如果把情况B的学习率设为情况A的2倍:
情况B:w_new = w - (2η)·(error·x)
= w - η·(2·error·x)
这和情况A完全一样!
1.5、实际意义
在机器学习中的惯例:
使用 ½·error² 是因为:
- 求导方便:导数就是
error,没有额外系数 - 物理意义:在物理学中,能量常与平方成正比,½系数很常见
- 数值稳定:当error很大时,½可以防止损失值过大
- 理论统一:与均方误差(MSE)公式一致:
MSE = (1/n)∑½(y_pred-y_true)²
但最终效果等价:
无论是否乘½,只要相应地调整学习率η,优化过程是完全等价的。
乘½这个操作就像在计算前先除以2,让求导后的公式少了一个系数2,使数学表达式更简洁,但通过调整学习率可以完全抵消这个差异,不影响最终的优化结果。 这是机器学习中的一种常见约定,主要是为了数学表达上的整洁性。
步骤2、计算w的梯度(∂损失/∂w)
思考过程:
- w增加 → 预测值增加 → 误差增加 → 损失增加
- 所以w的梯度应该是正数(表示w增加会使损失增加)
- 具体多少?看w对损失的影响有多大
数学计算:
预测值 y_pred = w×x + b
误差 error = y_pred - y_true
损失 loss = ½ × error²
链式求导:
∂loss/∂w = ∂loss/∂error × ∂error/∂y_pred × ∂y_pred/∂w
= error × 1 × x
= (0.6-0.55) × 1
= 0.05 × 1
= 0.05
含义解读:
梯度_w = 0.05 表示:
1. 方向:正号表示「w增加会使损失增加」
2. 大小:每增加1单位w,损失会增加0.05单位
3. 结论:w应该减少!
步骤3:计算b的梯度(∂损失/∂b)
类似计算:
∂loss/∂b = ∂loss/∂error × ∂error/∂y_pred × ∂y_pred/∂b
= error × 1 × 1
= 0.05 × 1
= 0.05
含义解读:
梯度_b = 0.05 表示:
1. 方向:正号表示「b增加会使损失增加」
2. 大小:每增加1单位b,损失会增加0.05单位
3. 结论:b也应该减少!
为什么梯度指向最陡下降方向?
可视化理解
想象损失是(w,b)的函数,形成一个「碗状」曲面:
损失
↑
| ● 我们现在在这里(w=0.1,b=0.5)
| /
| /
| /
| ● 应该去的地方
|
└─────────────────→ w,b空间
梯度向量 [0.05, 0.05] 告诉我们:
- 在w方向:往负方向走(减少w)
- 在b方向:往负方向走(减少b)
- 综合:往西南方向下山最快!
如果w、b都减少一点会怎样?
减少一点点:
- w从0.1→0.099
- b从0.5→0.499
新预测: 1×0.099 + 0.499 = 0.598
新误差: 0.598 - 0.55 = 0.048
新损失: ½×0.048² = 0.001152
对比:
原损失:0.00125
新损失:0.001152
确实减少了!
梯度大小的意义
为什么现金值会影响梯度大小?
回忆梯度公式:
梯度_w = 误差 × 现金值
情况对比:
| 数据 | 现金值 | 相同误差下的梯度_w |
|---|---|---|
| 日本人 | 0 | 0 |
| 美国人 | 0.2857 | 0.05×0.2857=0.014 |
| 中国人 | 1.0 | 0.05×1=0.05 |
解读:
- 日本人(现金=0):w对预测值没影响!怎么调w都不会改变预测值
- 美国人(现金=0.2857):w的影响中等
- 中国人(现金=1.0):w的影响最大
这就是特征缩放的重要性!
如果现金值很大(比如原始值900),梯度会变得巨大,导致更新不稳定。
结合学习率的完整更新
更新公式:
新参数 = 旧参数 - 学习率 × 梯度
三种学习率的效果对比:
- 学习率=0.8(太大)
w_new = 0.1 - 0.8×0.05 = 0.1 - 0.04 = 0.06
b_new = 0.5 - 0.8×0.05 = 0.5 - 0.04 = 0.46
问题: 步子太大,可能跨过最低点!
- 学习率=0.001(太小)
w_new = 0.1 - 0.001×0.05 = 0.09995
b_new = 0.5 - 0.001×0.05 = 0.49995
问题: 步子太小,要走很多步
- 学习率=0.1(适中)
w_new = 0.1 - 0.1×0.05 = 0.095
b_new = 0.5 - 0.1×0.05 = 0.495
正好: 稳步向目标前进
多轮训练的梯度变化
随着参数接近最优值,梯度会变小:
第1轮:预测=0.6,误差=0.05,梯度=0.05
第2轮:预测=0.59,误差=0.04,梯度=0.04
第3轮:预测=0.582,误差=0.032,梯度=0.032
...
第N轮:预测≈0.55,误差≈0,梯度≈0
为什么梯度会变小?
- 误差在减小 → 梯度在减小
- 接近最优点时,坡度变平缓
- 梯度趋近0时,参数更新几乎停止 → 模型收敛!
一句话总结梯度
梯度是损失函数的坡度计,它同时告诉我们:
- 方向:每个参数应该增加还是减少
- 程度:每个参数应该调整多少
- 优先级:哪个参数对误差影响更大
类比:
- 梯度 = 导航系统说:「前方300米右转,坡度下降5度」
- 学习率 = 你决定「以多快的速度转弯」
- 参数更新 = 你实际转动方向盘的幅度
关键洞察: 梯度不是随机的猜测,而是精确计算的调整方向,确保每一步都朝着损失最小的方向前进!
损失函数
损失函数(Loss Function),也称为代价函数(Cost Function),是一个数学评分标准,用于量化模型预测值与真实值之间的差异程度。它输出一个标量数值,这个数值越小,表明模型的预测越准确。
例如:射击打靶
损失函数 = 靶子的计分规则
预测值 = 子弹的落点
真实值 = 靶心(10环)
损失值 = 你丢失的环数(10-实际环数)
- 命中10环:损失=0环(完美)
- 命中8环:损失=2环(还不错)
- 命中3环:损失=7环(需要提高)
- 脱靶(0环):损失=10环(最差)
又例如:打高尔夫球
损失函数 = 距离洞杯的远近(分数规则)
预测值 = 球的实际落点
真实值 = 洞杯位置
损失值 = 球与洞杯的距离(越小越好)
- 一杆进洞:距离0米 → 损失=0(完美!)
- 停在洞边:距离0.1米 → 损失=0.1(很好)
- 偏离较远:距离5米 → 损失=5(需要改进)
- 打到水里:距离50米 → 损失=50(糟糕)
在消费能力预测中的具体表现
问题回顾:
- 真实消费能力 = 0.55
- 模型预测值 = 0.6
- 误差 = 0.05
常用损失函数示例:
- 均方误差(MSE)- 最常用
损失 = (预测值 - 真实值)²
= (0.6 - 0.55)²
= 0.0025
或者(带½的版本):
损失 = ½ × (0.6 - 0.55)²
= 0.00125
特点: 对大的误差惩罚更重(平方放大)
- 平均绝对误差(MAE)
损失 = |预测值 - 真实值|
= |0.6 - 0.55|
= 0.05
特点: 对异常值不敏感,更稳健
- 分位数损失
损失 = max(q×误差, (q-1)×误差)
(q是分位数,如0.5对应中位数)
损失函数的双重角色
角色1:性能评估器(成绩单)
# 训练结束后评估模型
总损失 = 0
for 每个测试样本:
预测值 = 模型预测(样本)
损失值 = 损失函数(预测值, 真实值)
总损失 += 损失值
平均损失 = 总损失 / 样本数
# 这个平均损失就是模型的「最终成绩」
角色2:训练导航仪(指南针)
# 训练过程中指导参数更新
for 每个训练批次:
# 前向传播:计算预测值
预测值 = w×现金 + b
# 计算损失
损失 = (预测值 - 真实值)²
# 关键步骤:计算梯度
梯度_w = 2×(预测值-真实值)×现金
梯度_b = 2×(预测值-真实值)
# 更新参数(向减少损失的方向)
w = w - 学习率×梯度_w
b = b - 学习率×梯度_b
关键点: 损失函数必须可导,才能计算梯度!
损失函数如何指导学习?
可视化理解
想象损失函数是(w,b)的地形图:
损失值
↑
| ● 当前位置(损失=0.1)
| / \
| / \
| / \
| ● ●
| (损失=0.05)(损失=0.15)
|
└─────────────────→ 参数(w,b)
训练过程就是:
- 计算当前位置的海拔(损失值)
- 观察周围坡度(计算梯度)
- 往最陡的下坡方向走一步(参数更新)
- 重复直到找到最低点(最小损失)
具体步骤分解:
第1步:初始化 w=0.1, b=0.5
第2步:预测值=0.6,真实值=0.55
第3步:损失 = (0.6-0.55)² = 0.0025
第4步:梯度计算 → 告诉我们应该减少w和b
第5步:更新 w=0.095, b=0.495
第6步:新损失 = (0.595-0.55)² = 0.002025
第7步:损失变小了!继续...
不同任务的损失函数
-
回归任务(预测数值)
-
MSE(均方误差):
(y_pred - y_true)² -
MAE(平均绝对误差):
|y_pred - y_true| -
Huber损失:MSE和MAE的结合,对异常值更鲁棒
-
-
分类任务(预测类别)
-
交叉熵损失:
-Σ y_true·log(y_pred)例子:预测猫/狗 真实:猫 [1, 0] 预测:猫 [0.9, 0.1] → 损失小 预测:狗 [0.1, 0.9] → 损失大 -
铰链损失(SVM用):
max(0, 1 - y_true·y_pred)
-
-
生成任务(GAN)
- 对抗损失:生成器和判别器的博弈
损失函数的重要性质
- 非负性
损失 ≥ 0
等号成立当且仅当 预测值 = 真实值
预测越准,损失越小
- 可微性
必须能够求导,否则无法计算梯度
- 凸性(理想情况)
凸函数保证只有一个全局最小值,不会陷入局部最优
- 对误差的敏感性
不同损失函数对错误的惩罚不同:
误差=1时:
MSE损失 = 1
MAE损失 = 1
误差=10时:
MSE损失 = 100 (惩罚很重!)
MAE损失 = 10 (线性增长)
总结
损失函数是模型的错误计分器
- 告诉模型:你这次预测错了多少分
- 告诉优化器:应该往哪个方向调整参数才能减少错误
- 告诉开发者:模型最终的表现如何
它是连接模型预测与参数优化的桥梁,是机器学习能够从错误中学习的数学基础。
量纲陷阱
定义
量纲陷阱指的是:当不同特征具有不同的数量级或量纲(单位)时,机器学习算法会错误地认为数值大的特征更重要,从而导致模型产生偏差。
简单说:算法被数字大小欺骗了,而不是真正理解特征的意义。
示例:选球员只看身高体重?
场景:选拔足球运动员
特征1:身高(厘米) → 范围:160-200
特征2:体重(公斤) → 范围:50-90
特征3:百米速度(秒) → 范围:10-15
特征4:年薪(万元) → 范围:100-1000
没有归一化时,算法怎么想?
算法逻辑:
- 身高:最大200,最小160 → 差异40
- 体重:最大90,最小50 → 差异40
- 速度:最大15,最小10 → 差异5
- 年薪:最大1000,最小100 → 差异900
算法结论:
"年薪差异900 >> 身高差异40 >> 速度差异5"
"所以年薪最重要!应该按年薪选球员!"
问题:
- 年薪高不代表球技好(可能是老将或商业价值)
- 速度慢0.1秒可能决定比赛胜负,但差异只有5
- 算法被数值大小误导了
量纲陷阱的数学原理
梯度下降中的问题
回忆梯度公式:梯度 = 误差 × 特征值
对于线性回归:
消费能力 = w₁×现金 + w₂×年龄 + b
梯度计算:
∂损失/∂w₁ = 误差 × 现金值(如1300)
∂损失/∂w₂ = 误差 × 年龄值(如30)
更新幅度比较:
Δw₁ ∝ 1300 × 误差
Δw₂ ∝ 30 × 误差
现金的梯度是年龄的43倍!
所以w₁更新幅度远大于w₂
结果:
训练过程:
现金权重w₁:快速调整,主导整个模型
年龄权重w₂:几乎不动,被"压制"
最终模型:
消费能力 ≈ w₁×现金 + 很小的w₂×年龄 + b
年龄特征几乎被忽略!
医疗诊断模型
特征1:体温(摄氏度) → 36.0 ~ 40.0(跨度4)
特征2:白细胞计数(10^9/L) → 4.0 ~ 20.0(跨度16)
特征3:基因表达值 → 0.0001 ~ 0.002(跨度0.0019)
特征4:医疗费用(元) → 1000 ~ 500000(跨度499000)
没有归一化时:
算法认为:
医疗费用最重要(跨度499000)
体温最不重要(跨度4)
基因表达几乎可以忽略(跨度0.0019)
但实际:
- 基因表达微小变化可能意味着癌症
- 医疗费用高可能只是用了昂贵药物
- 体温变化2度就很危险了
量纲陷阱可能导致:
- 用医疗费用预测疾病
- 忽略关键的基因信号
- 模型在现实中完全失效
解决方案:归一化/标准化
方法1:Min-Max归一化(到[0,1])
现金归一化 = (现金 - 68.75) / (1300 - 68.75)
年龄归一化 = (年龄 - 25) / (30 - 25)
结果:
现金:0 ~ 1
年龄:0 ~ 1
→ 现在算法公平对待两者!
方法2:Z-score标准化
现金标准化 = (现金 - 均值) / 标准差
年龄标准化 = (年龄 - 均值) / 标准差
结果:
两个特征都以0为中心,标准差为1
归一化后的算法视角:
特征范围:
- 现金:0 ~ 1
- 年龄:0 ~ 1
梯度计算:
Δw₁ ∝ 1 × 误差
Δw₂ ∝ 1 × 误差
现在权重更新幅度相同!
年龄特征不再被压制!
量纲陷阱的扩展影响
- 距离类算法受害最深
- KNN:距离计算被大数值特征主导
- K-means:聚类结果被扭曲
- SVM:决策边界被错误倾斜
- 正则化的不公平
L2正则化惩罚:λ × (w₁² + w₂²)
如果w₁天生就比w₂大(因为现金值大)
那么w₁会被惩罚得更重 → 更不公平!
- 学习率困境
想用合适的学习率训练:
- 对现金特征:学习率需要很小(因为梯度大)
- 对年龄特征:学习率可以大些(因为梯度小)
但只能选一个学习率 → 顾此失彼
- 激活函数饱和
sigmoid函数在|输入|>5时梯度接近0
如果现金值=1300,sigmoid(1300)梯度≈0
→ 现金特征反而学不动了!
现实中的量纲陷阱案例
案例1:信用评分
特征: 实际范围
月收入 3000~50000元
信用卡数量 1~10张
逾期次数 0~20次
存款金额 0~1000000元
量纲陷阱:
算法过度关注"存款金额"(跨度大)
忽略"逾期次数"(关键风险指标!)
案例2:推荐系统
特征: 实际范围
用户年龄 18~80岁
浏览时长 0~3600秒
购买金额 0~10000元
点击次数 0~500次
问题:
购买金额主导推荐结果
但浏览时长可能更能反映兴趣!
总结
量纲陷阱就是:算法像个只会数零的孩子,认为1000比10重要100倍,却不知道10分的高考加分可能比1000块的零花钱重要得多。
解决方案很简单:把所有特征放在同一个起跑线上(归一化),让算法关注相对重要性而不是绝对数值。
归一化进阶
二维数组的归一化
假设场景:统计 3 个人的「现金 + 月收入」两个特征(共 3 行 2 列的二维数组),先统一货币为欧元,再对每个特征维度分别做 Min-Max 归一化(保证每个特征都缩放到 0~1 范围)。
- 行:3 个人(中国人、日本人、美国人)
- 列:2 个特征(现金、月收入)
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
public class Currency2DNormalization {
public static void main(String[] args) {
// 1. 创建NDManager(DJL核心,用于管理NDArray)
try (NDManager manager = NDManager.newBaseManager()) {
// 2. 原始二维数据:3行2列(3个人 × 2个特征:[现金, 月收入])
// 数据说明:
// 中国人:现金5000人民币,月收入15000人民币
// 日本人:现金80000日元,月收入240000日元
// 美国人:现金1000美元,月收入3000美元
float[][] originalData = new float[][]{
{5000, 15000}, // 中国人:[现金(人民币), 月收入(人民币)]
{80000, 240000}, // 日本人:[现金(日元), 月收入(日元)]
{1000, 3000} // 美国人:[现金(美元), 月收入(美元)]
};
// 创建二维NDArray,Shape(3,2)表示3行2列
NDArray originalCurrency = manager.create(originalData);
System.out.println("=== 原始二维数据(3人×2特征) ===");
System.out.println("中国人:现金=" + originalCurrency.getFloat(0, 0) + "人民币,月收入=" + originalCurrency.getFloat(0, 1) + "人民币");
System.out.println("日本人:现金=" + originalCurrency.getFloat(1, 0) + "日元,月收入=" + originalCurrency.getFloat(1, 1) + "日元");
System.out.println("美国人:现金=" + originalCurrency.getFloat(2, 0) + "美元,月收入=" + originalCurrency.getFloat(2, 1) + "美元");
// 3. 第一步:统一转换成欧元(消除货币单位差异,模拟“去量纲”)
// 汇率数组:2列(对应现金、月收入,同一特征汇率一致)
// [人民币汇率, 日元汇率, 美元汇率] → 按列匹配:现金列用[0.13,0.006875,0.9],月收入列同汇率
float[][] rateData = new float[][]{
{0.13f, 0.13f}, // 人民币汇率:现金/月收入均为0.13
{0.006875f, 0.006875f}, // 日元汇率:现金/月收入均为0.006875
{0.9f, 0.9f} // 美元汇率:现金/月收入均为0.9
};
NDArray euroRates = manager.create(rateData);
// 二维数组逐元素相乘(原始金额 × 对应汇率)
NDArray euroAmount = originalCurrency.mul(euroRates);
System.out.println("\n=== 转换为欧元后(3人×2特征) ===");
System.out.println("中国人:现金=" + euroAmount.getFloat(0, 0) + "欧元,月收入=" + euroAmount.getFloat(0, 1) + "欧元");
System.out.println("日本人:现金=" + euroAmount.getFloat(1, 0) + "欧元,月收入=" + euroAmount.getFloat(1, 1) + "欧元");
System.out.println("美国人:现金=" + euroAmount.getFloat(2, 0) + "欧元,月收入=" + euroAmount.getFloat(2, 1) + "欧元");
// 4. 第二步:手动实现二维数组的Min-Max归一化(核心:按特征列分别归一化)
// 关键:对每个特征列计算min/max(axis=0表示按列计算,axis=1表示按行)
int[] axes = new int[]{0}; // 按列计算(axis=0)
NDArray euroMin = euroAmount.min(axes); // 按列取最小值:[现金列最小值, 月收入列最小值]
NDArray euroMax = euroAmount.max(axes); // 按列取最大值:[现金列最大值, 月收入列最大值]
System.out.println("\n=== 各特征列的min/max ===");
System.out.println("现金列min=" + euroMin.getFloat(0) + "欧元,max=" + euroMax.getFloat(0) + "欧元");
System.out.println("月收入列min=" + euroMin.getFloat(1) + "欧元,max=" + euroMax.getFloat(1) + "欧元");
// 归一化计算:(X - 列min) / (列max - 列min)
// 广播机制:将列min/max扩展为和euroAmount同形状(3,2),实现逐列归一化
NDArray normalizedAmount = euroAmount.sub(euroMin).div(euroMax.sub(euroMin));
// 5. 输出归一化结果(0~1范围,每个特征列独立归一化)
System.out.println("\n=== 二维数组归一化后(0~1范围) ===");
System.out.println("中国人:现金=" + normalizedAmount.getFloat(0, 0) + ",月收入=" + normalizedAmount.getFloat(0, 1));
System.out.println("日本人:现金=" + normalizedAmount.getFloat(1, 0) + ",月收入=" + normalizedAmount.getFloat(1, 1));
System.out.println("美国人:现金=" + normalizedAmount.getFloat(2, 0) + ",月收入=" + normalizedAmount.getFloat(2, 1));
// 6. 验证:每个特征列的范围是否在0~1之间
System.out.println("\n=== 归一化范围验证(按列) ===");
System.out.println("现金列归一化min=" + normalizedAmount.min(axes).getFloat(0) + ",max=" + normalizedAmount.max(axes).getFloat(0));
System.out.println("月收入列归一化min=" + normalizedAmount.min(axes).getFloat(1) + ",max=" + normalizedAmount.max(axes).getFloat(1));
}
}
}
运行结果
=== 原始二维数据(3人×2特征) ===
中国人:现金=5000.0人民币,月收入=15000.0人民币
日本人:现金=80000.0日元,月收入=240000.0日元
美国人:现金=1000.0美元,月收入=3000.0美元
=== 转换为欧元后(3人×2特征) ===
中国人:现金=650.0欧元,月收入=1949.9999欧元
日本人:现金=550.0欧元,月收入=1650.0欧元
美国人:现金=900.0欧元,月收入=2700.0欧元
=== 各特征列的min/max ===
现金列min=550.0欧元,max=900.0欧元
月收入列min=1650.0欧元,max=2700.0欧元
=== 二维数组归一化后(0~1范围) ===
中国人:现金=0.2857143,月收入=0.28571418
日本人:现金=0.0,月收入=0.0
美国人:现金=1.0,月收入=1.0
=== 归一化范围验证(按列) ===
现金列归一化min=0.0,max=1.0
月收入列归一化min=0.0,max=1.0
三维数组的归一化
假设场景:统计「2 个地区 × 3 个人 × 2 个特征」(现金 + 月收入),即三维数组维度为 Shape(2, 3, 2):
- 第一维(批次 / 地区):2 个地区(亚洲、北美);
- 第二维(样本 / 人):每个地区 3 个人(亚洲:中、日、韩;北美:美、加、墨);
- 第三维(特征):每人 2 个特征(现金、月收入)。
核心要求:按特征维度(第三维)独立归一化(保证每个特征在全量数据中缩放到 0~1),这是深度学习中多批次数据归一化的标准做法。
NDManager.create() 方法仅直接支持一维 / 二维数组,没有直接接收三维数组(float[][][])的重载方法,因此 manager.create(originalData, new Shape(2, 3, 2)) 会报错。
解决方案
将三维数组扁平化为一维数组,再通过 Shape(2,3,2) 指定三维形状,核心逻辑是:
- 把
float[][][]转成一维float[]; - 用
create(float[] data, Shape shape)方法创建三维 NDArray;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import java.nio.FloatBuffer;
public class Currency3DNormalization {
public static void main(String[] args) {
// 1. 创建NDManager管理NDArray资源
try (NDManager manager = NDManager.newBaseManager()) {
// 2. 定义三维原始数据:2地区 × 3人 × 2特征(现金、月收入)
float[][][] original3DData = new float[][][]{
// 亚洲地区(第0层):3人 × 2特征
{
{5000, 15000}, // 中国:现金5000人民币,月收入15000人民币
{80000, 240000}, // 日本:现金80000日元,月收入240000日元
{100000, 300000} // 韩国:现金100000韩元,月收入300000韩元
},
// 北美地区(第1层):3人 × 2特征
{
{1000, 3000}, // 美国:现金1000美元,月收入3000美元
{1200, 3600}, // 加拿大:现金1200加元,月收入3600加元
{20000, 60000} // 墨西哥:现金20000比索,月收入60000比索
}
};
// 关键步骤:将三维数组扁平化为一维数组
float[] flatOriginalData = flatten3DArray(original3DData);
// 创建三维NDArray:一维数组 + Shape(2,3,2)指定维度
NDArray originalCurrency = manager.create(flatOriginalData, new Shape(2, 3, 2));
System.out.println("=== 三维原始数据(2地区×3人×2特征) ===");
// 遍历三维数组:地区→人→特征
String[] regions = {"亚洲", "北美"};
String[][] people = {{"中国人", "日本人", "韩国人"}, {"美国人", "加拿大人", "墨西哥人"}};
String[] features = {"现金", "月收入"};
for (int r = 0; r < 2; r++) {
System.out.println("【" + regions[r] + "】");
for (int p = 0; p < 3; p++) {
System.out.print(people[r][p] + ":");
for (int f = 0; f < 2; f++) {
System.out.print(features[f] + "=" + originalCurrency.getFloat(r, p, f) + ",");
}
System.out.println();
}
}
// 3. 统一转换为欧元(汇率数组同样扁平化处理)
float[][][] rate3DData = new float[][][]{
// 亚洲地区汇率
{
{0.13f, 0.13f}, // 人民币汇率
{0.006875f, 0.006875f}, // 日元汇率
{0.0006f, 0.0006f} // 韩元汇率
},
// 北美地区汇率
{
{0.9f, 0.9f}, // 美元汇率
{0.75f, 0.75f}, // 加元汇率
{0.05f, 0.05f} // 比索汇率
}
};
float[] flatRateData = flatten3DArray(rate3DData);
NDArray euroRates = manager.create(flatRateData, new Shape(2, 3, 2));
NDArray euroAmount = originalCurrency.mul(euroRates); // 三维数组逐元素相乘
System.out.println("\n=== 转换为欧元后(2地区×3人×2特征) ===");
for (int r = 0; r < 2; r++) {
System.out.println("【" + regions[r] + "】");
for (int p = 0; p < 3; p++) {
System.out.print(people[r][p] + ":");
for (int f = 0; f < 2; f++) {
System.out.print(features[f] + "=" + euroAmount.getFloat(r, p, f) + "欧元,");
}
System.out.println();
}
}
// 4. 三维数组Min-Max归一化(按特征全局归一化)
// axis=(0,1):沿地区、人维度聚合,仅保留特征维度的min/max
NDArray euroMin = euroAmount.min(new int[]{0, 1});
NDArray euroMax = euroAmount.max(new int[]{0, 1});
System.out.println("\n=== 各特征全局min/max(所有地区+所有人) ===");
System.out.println("现金特征min=" + euroMin.getFloat(0) + "欧元,max=" + euroMax.getFloat(0) + "欧元");
System.out.println("月收入特征min=" + euroMin.getFloat(1) + "欧元,max=" + euroMax.getFloat(1) + "欧元");
// 归一化计算(DJL自动广播Shape(2)→Shape(2,3,2))
NDArray normalizedAmount = euroAmount.sub(euroMin).div(euroMax.sub(euroMin));
// 5. 输出归一化结果
System.out.println("\n=== 三维数组归一化后(0~1范围) ===");
for (int r = 0; r < 2; r++) {
System.out.println("【" + regions[r] + "】");
for (int p = 0; p < 3; p++) {
System.out.print(people[r][p] + ":");
for (int f = 0; f < 2; f++) {
System.out.print(features[f] + "=" + String.format("%.4f", normalizedAmount.getFloat(r, p, f)) + ",");
}
System.out.println();
}
}
// 6. 验证归一化范围
System.out.println("\n=== 归一化范围验证(全局) ===");
System.out.println("现金特征归一化min=" + normalizedAmount.min(new int[]{0, 1}).getFloat(0) + ",max=" + normalizedAmount.max(new int[]{0, 1}).getFloat(0));
System.out.println("月收入特征归一化min=" + normalizedAmount.min(new int[]{0, 1}).getFloat(1) + ",max=" + normalizedAmount.max(new int[]{0, 1}).getFloat(1));
}
}
/**
* 辅助方法:将三维float数组扁平化为一维数组
* @param threeDArray 三维数组
* @return 扁平化后的一维数组
*/
private static float[] flatten3DArray(float[][][] threeDArray) {
// 计算总元素数:层数 × 行数 × 列数
int layerCount = threeDArray.length;
int rowCount = threeDArray[0].length;
int colCount = threeDArray[0][0].length;
float[] flatArray = new float[layerCount * rowCount * colCount];
// 遍历三维数组,按「层→行→列」顺序填充一维数组
int index = 0;
for (int layer = 0; layer < layerCount; layer++) {
for (int row = 0; row < rowCount; row++) {
for (int col = 0; col < colCount; col++) {
flatArray[index++] = threeDArray[layer][row][col];
}
}
}
return flatArray;
}
}
运行结果
=== 三维原始数据(2地区×3人×2特征) ===
【亚洲】
中国人:现金=5000.0,月收入=15000.0,
日本人:现金=80000.0,月收入=240000.0,
韩国人:现金=100000.0,月收入=300000.0,
【北美】
美国人:现金=1000.0,月收入=3000.0,
加拿大人:现金=1200.0,月收入=3600.0,
墨西哥人:现金=20000.0,月收入=60000.0,
=== 转换为欧元后(2地区×3人×2特征) ===
【亚洲】
中国人:现金=650.0欧元,月收入=1949.9999欧元,
日本人:现金=550.0欧元,月收入=1650.0欧元,
韩国人:现金=60.000004欧元,月收入=180.00002欧元,
【北美】
美国人:现金=900.0欧元,月收入=2700.0欧元,
加拿大人:现金=900.0欧元,月收入=2700.0欧元,
墨西哥人:现金=1000.0欧元,月收入=3000.0欧元,
=== 各特征全局min/max(所有地区+所有人) ===
现金特征min=60.000004欧元,max=1000.0欧元
月收入特征min=180.00002欧元,max=3000.0欧元
=== 三维数组归一化后(0~1范围) ===
【亚洲】
中国人:现金=0.6277,月收入=0.6277,
日本人:现金=0.5213,月收入=0.5213,
韩国人:现金=0.0000,月收入=0.0000,
【北美】
美国人:现金=0.8936,月收入=0.8936,
加拿大人:现金=0.8936,月收入=0.8936,
墨西哥人:现金=1.0000,月收入=1.0000,
=== 归一化范围验证(全局) ===
现金特征归一化min=0.0,max=1.0
月收入特征归一化min=0.0,max=1.0
使用DJL内置归一化层
DJL(Deep Java Library)的内置归一化层是其神经网络模块(ai.djl.nn)中封装的、用于数据 / 特征归一化的标准化组件,本质是对深度学习中经典归一化算法(BatchNorm、LayerNorm、InstanceNorm 等)的 Java 实现,适配不同深度学习引擎(PyTorch/MXNet/TensorFlow),无需手动实现归一化逻辑,且与 DJL 的神经网络体系深度集成。
核心特性
- 引擎无关性:同一归一化层 API 可适配不同底层引擎(如 PyTorch/MXNet),无需针对引擎修改代码;
- 维度自适应:自动处理多维数组(2D/3D/4D)的广播、维度对齐,适配深度学习中 “批次 - 样本 - 特征” 的张量结构;
- 训练 / 推理模式兼容:区分训练(使用批次统计量)和推理(使用移动平均统计量)模式,符合工业级模型部署要求;
- 参数可配置:支持 epsilon(防除零)、axis(归一化维度)、momentum(移动平均系数)等核心参数调优。
常用的内置归一化层
| 归一化层 | 全类名 | 核心用途 | 适用场景 |
|---|---|---|---|
| BatchNorm | ai.djl.nn.norm.BatchNorm |
沿批次维度对每个特征归一化(计算批次内特征的均值 / 方差) | 卷积神经网络(CNN)、批量样本训练 |
| LayerNorm | ai.djl.nn.norm.LayerNorm |
沿特征维度对每个样本归一化(计算单个样本所有特征的均值 / 方差) | 循环神经网络(RNN)、Transformer |
| InstanceNorm | ai.djl.nn.norm.InstanceNorm |
沿通道 / 特征维度对每个样本的单个特征归一化(逐实例归一化) | 图像风格迁移、生成式模型 |
| GroupNorm | ai.djl.nn.norm.GroupNorm |
将特征分组,沿组维度归一化(BatchNorm 的改进,适配小批次场景) | 小批次训练、医学图像分析 |
核心归一化层详解
- BatchNorm(批次归一化)
- 核心逻辑:对同一批次中所有样本的同一特征计算均值 / 方差,将特征缩放到均值≈0、标准差≈1;
- 三维数组场景:输入
Shape(2,3,2)(2 地区 / 批次、3 人 / 样本、2 特征),BatchNorm 沿 “批次维度(2)” 计算每个特征(现金 / 月收入)的全局均值 / 方差,最终让每个特征在批次内分布标准化; - 关键参数:
axis:指定特征维度(如axis=-1表示最后一维为特征维度);epsilon:防除零的极小值(默认 1e-5);momentum:训练时更新移动平均统计量的系数(默认 0.9)。
- LayerNorm(层归一化)
- 核心逻辑:对单个样本的所有特征计算均值 / 方差,不依赖批次,适配样本独立归一化场景;
- 三维数组场景:输入
Shape(2,3,2),LayerNorm 对每个 “人(样本)” 的 2 个特征(现金 + 月收入)单独归一化,结果仅与该样本自身特征相关,与批次无关; - 关键参数:
normalizedShape:指定归一化的特征维度大小(如new Shape(2)适配你的 2 个特征);axis:指定归一化的维度(默认最后一维)。
与手动归一化的区别
| 维度 | DJL 内置归一化层 | 手动归一化(如 Min-Max) |
|---|---|---|
| 算法类型 | 标准化(均值≈0、标准差≈1) | 归一化(缩放到 [0,1] 区间) |
| 集成性 | 可直接嵌入神经网络模型(SequentialBlock) |
仅能作为预处理步骤,无法嵌入模型 |
| 训练 / 推理适配 | 自动处理移动平均统计量(推理时复用训练统计) | 需手动保存 / 加载 min/max,无动态适配能力 |
| 多维支持 | 自动广播维度,适配任意张量形状 | 需手动 reshape、计算维度,易出错 |
| 引擎兼容性 | 适配 PyTorch/MXNet 等,无需修改逻辑 | 需针对不同引擎调整数组操作(如广播方式) |
示例代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.nn.norm.BatchNorm;
import ai.djl.nn.norm.LayerNorm;
import ai.djl.training.ParameterStore;
public class SimpleCurrencyNormalization {
public static void main(String[] args) {
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建三维数据(需要先展平)
float[][][] original3DData = new float[][][]{
{{5000, 15000}, {80000, 240000}, {100000, 300000}},
{{1000, 3000}, {1200, 3600}, {20000, 60000}}
};
// 展平为一维数组
float[] flatData = flatten3DArray(original3DData);
// 转换为NDArray(2个地区,3个人,2个特征)
NDArray originalCurrency = manager.create(flatData, new Shape(2, 3, 2));
System.out.println("原始数据形状: " + originalCurrency.getShape());
System.out.println("原始数据内容: " + originalCurrency);
// 2. 创建汇率数据并转换
float[][][] rate3DData = new float[][][]{
{{0.13f, 0.13f}, {0.006875f, 0.006875f}, {0.0006f, 0.0006f}},
{{0.9f, 0.9f}, {0.75f, 0.75f}, {0.05f, 0.05f}}
};
float[] flatRates = flatten3DArray(rate3DData);
NDArray euroAmount = originalCurrency.mul(manager.create(flatRates, new Shape(2, 3, 2)));
System.out.println("转换为欧元后的形状: " + euroAmount.getShape());
System.out.println("转换为欧元后的内容: " + euroAmount);
// 3. 直接使用DJL内置归一化
System.out.println("\n=== DJL内置归一化 ===");
// 3.1 BatchNorm - 重塑为2D使用
NDArray batchInput = euroAmount.reshape(6, 2); // 6个样本,2个特征
BatchNorm batchNorm = BatchNorm.builder().build();
// 前向传播执行归一化
NDArray batchResult = forwardNorm(batchNorm, manager, batchInput);
System.out.println("BatchNorm结果形状: " + batchResult.getShape());
// 恢复三维形状查看
NDArray batchResult3D = batchResult.reshape(2, 3, 2);
printStats("BatchNorm", batchResult3D);
// 3.2 LayerNorm - 直接使用三维数据
LayerNorm layerNorm = LayerNorm.builder().build();
// 前向传播执行归一化
NDArray layerResult = forwardNorm(layerNorm, manager, euroAmount);
printStats("LayerNorm", layerResult);
// 4. 简化神经网络
System.out.println("\n=== 简化神经网络 ===");
SequentialBlock net = new SequentialBlock()
.add(Linear.builder().setUnits(4).build())// 4个隐藏单元
.add(LayerNorm.builder().build())// 对每个样本归一化
.add(ai.djl.nn.Activation::relu) // 非线性激活
.add(Linear.builder().setUnits(2).build()); // 2个输出单元
// 4.1 初始化网络参数
net.initialize(manager, DataType.FLOAT32, euroAmount.getShape());
// 4.2 前向传播执行神经网络
ParameterStore ps = new ParameterStore(manager, false);
NDArray output = net.forward(ps, new NDList(euroAmount), false)
.singletonOrThrow();
System.out.println("网络输出形状: " + output.getShape());
// 5. 简单Min-Max归一化
System.out.println("\n=== 简单Min-Max归一化 ===");
NDArray minMax = simpleMinMax(euroAmount);
System.out.println("归一化后内容: " + minMax);
System.out.println("\nMin-Max范围: [" +
String.format("%.4f", minMax.min().toFloatArray()[0]) + ", " +
String.format("%.4f", minMax.max().toFloatArray()[0]) + "]");
}
}
// 展平三维数组为一维
private static float[] flatten3DArray(float[][][] data) {
int totalSize = data.length * data[0].length * data[0][0].length;
float[] flat = new float[totalSize];
int idx = 0;
for (float[][] matrix : data) {
for (float[] row : matrix) {
for (float value : row) {
flat[idx++] = value;
}
}
}
return flat;
}
// 通用归一化前向传播
private static NDArray forwardNorm(ai.djl.nn.Block norm, NDManager manager, NDArray input) {
// 初始化归一化层参数
norm.initialize(manager, DataType.FLOAT32, input.getShape());
// 前向传播执行归一化
ParameterStore ps = new ParameterStore(manager, false);
// 执行归一化并返回结果
return norm.forward(ps, new NDList(input), false).singletonOrThrow();
}
// 打印统计信息
private static void printStats(String name, NDArray arr) {
float mean = arr.mean().toFloatArray()[0];
float std = arr.sub(mean).pow(2).mean().sqrt().toFloatArray()[0];
System.out.printf("%s - 均值: %.4f, 标准差: %.4f\n", name, mean, std);
System.out.println("归一化后内容: " + arr);
}
// 简单Min-Max归一化
private static NDArray simpleMinMax(NDArray input) {
NDArray min = input.min(new int[]{0, 1});
NDArray max = input.max(new int[]{0, 1});
NDArray range = max.sub(min).add(1e-8f);
return input.sub(min.reshape(1, 1, 2)).div(range.reshape(1, 1, 2));
}
}
运行结果
原始数据形状: (2, 3, 2)
原始数据内容: ND: (2, 3, 2) cpu() float32
[[[ 5000., 15000.],
[ 80000., 240000.],
[100000., 300000.],
],
[[ 1000., 3000.],
[ 1200., 3600.],
[ 20000., 60000.],
],
]
转换为欧元后的形状: (2, 3, 2)
转换为欧元后的内容: ND: (2, 3, 2) cpu() float32
[[[ 650., 1950.],
[ 550., 1650.],
[ 60., 180.],
],
[[ 900., 2700.],
[ 900., 2700.],
[1000., 3000.],
],
]
=== DJL内置归一化 ===
BatchNorm结果形状: (6, 2)
BatchNorm - 均值: 1353.3265, 标准差: 979.2748
归一化后内容: ND: (2, 3, 2) cpu() float32
[[[ 649.9968, 1949.9901],
[ 549.9973, 1649.9917],
[ 59.9997, 179.9991],
],
[[ 899.9955, 2699.9866],
[ 899.9955, 2699.9866],
[ 999.995 , 2999.9849],
],
]
LayerNorm - 均值: 0.0000, 标准差: 1.0000
归一化后内容: ND: (2, 3, 2) cpu() float32
[[[-0.2664, 1.5562],
[-0.4066, 1.1356],
[-1.0936, -0.9253],
],
[[-1.0292, 0.8872],
[-1.0292, 0.8872],
[-0.9227, 1.2066],
],
]
=== 简化神经网络 ===
网络输出形状: (2, 3, 2)
=== 简单Min-Max归一化 ===
归一化后内容: ND: (2, 3, 2) cpu() float32
[[[0.6277, 0.6277],
[0.5213, 0.5213],
[0. , 0. ],
],
[[0.8936, 0.8936],
[0.8936, 0.8936],
[1. , 1. ],
],
]
Min-Max范围: [0.0000, 1.0000]
简化版
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.norm.BatchNorm;
import ai.djl.nn.norm.LayerNorm;
import ai.djl.training.ParameterStore;
public class Minimal3DNormalization {
public static void main(String[] args) {
try (NDManager manager = NDManager.newBaseManager()) {
// 创建三维数据(先展平再指定形状)
float[] flatData = {
5000, 15000, 80000, 240000, 100000, 300000,
1000, 3000, 1200, 3600, 20000, 60000
};
NDArray data = manager.create(flatData, new Shape(2, 3, 2));
System.out.println("数据形状: " + data.getShape());
// BatchNorm(需要重塑为2D)
BatchNorm bn = BatchNorm.builder().build();
NDArray batchInput = data.reshape(6, 2);
bn.initialize(manager, data.getDataType(), batchInput.getShape());
ParameterStore ps = new ParameterStore(manager, false);
NDArray bnResult = bn.forward(ps, new NDList(batchInput), false).singletonOrThrow();
System.out.println("BatchNorm结果形状: " + bnResult.getShape());
System.out.println("BatchNorm结果: " + bnResult);
// LayerNorm(可以直接处理3D)
LayerNorm ln = LayerNorm.builder().build();
ln.initialize(manager, data.getDataType(), data.getShape());
NDArray lnResult = ln.forward(ps, new NDList(data), false).singletonOrThrow();
System.out.println("LayerNorm结果形状: " + lnResult.getShape());
System.out.println("LayerNorm结果: " + lnResult);
}
}
}
运行结果
数据形状: (2, 3, 2)
BatchNorm结果形状: (6, 2)
BatchNorm结果: ND: (6, 2) cpu() float32
[[ 4999.975, 14999.925],
[ 79999.602, 239998.797],
[ 99999.5 , 299998.5 ],
[ 999.995, 2999.985],
[ 1199.994, 3599.982],
[ 19999.9 , 59999.699],
]
LayerNorm结果形状: (2, 3, 2)
LayerNorm结果: ND: (2, 3, 2) cpu() float32
[[[-1.0729, -0.9823],
[-0.3929, 1.0578],
[-0.2116, 1.6018],
],
[[-0.6493, -0.5552],
[-0.6399, -0.527 ],
[ 0.2447, 2.1268],
],
]
通过上述示例,我们掌握了BatchNorm和LayerNorm的独立使用方法。但需要认识到:
- 功能局限:只能处理静态数据,无法处理动态生成的隐藏层特征
- 无参数学习:γ(缩放)和β(偏移)参数固定,无法自适应任务
- 脱离训练流程:不参与反向传播,无法随网络一起优化
- 预处理性质:属于"前处理"步骤,而非模型内在能力
神经网络中的归一化
在前面的"使用DJL内置归一化层"部分,我们学习了如何独立使用BatchNorm和LayerNorm对数据进行标准化处理。这些示例展示了归一化层的核心功能:调整数据分布、加速收敛、提高模型稳定性。
但在实际深度学习项目中,归一化层很少单独使用,而是作为神经网络的关键组件集成到整个网络架构中。让我们通过对比理解归一化层角色的转变:
| 维度 | 独立使用归一化层 | 神经网络中的归一化层 |
|---|---|---|
| 角色定位 | 数据预处理工具 | 网络架构的核心组件 |
| 使用场景 | 数据清洗、特征工程 | 隐藏层激活值标准化 |
| 参数更新 | 无梯度传播 | 参与反向传播,学习γ/β参数 |
| 数据流 | 静态数据处理 | 动态前向传播链的一环 |
| 与网络关系 | 外部工具 | 网络内部结构的一部分 |
这种转变的本质是:从"数据处理"到"模型构建"的升级。在完整神经网络中,归一化层:
- 嵌入网络结构:成为SequentialBlock、ParallelBlock等网络块中的标准层
- 参与端到端训练:参数随网络一同更新,适应具体任务需求
- 处理中间特征:不仅处理原始输入,更处理网络产生的隐藏特征
- 自动适配模式:根据训练/推理模式自动切换统计量计算方式
理解了归一化层的独立使用后,我们现在进入深度学习实践的核心环节:将归一化层集成到神经网络架构中。这种集成不是简单的"加法",而是让归一化层成为学习过程的有机组成部分。
独立模式:原始数据 → 归一化层 → 标准化数据
集成模式:输入数据 → 线性层 → 归一化层 → 激活函数 → 下一层
两种模式对比示例:
/**
* 对比:独立归一化 vs 网络集成归一化
* 展示两种使用方式的差异
*/
public class NormalizationComparison {
// 独立归一化模式(前处理)
public static NDArray standaloneNormalization(NDArray data) {
BatchNorm bn = BatchNorm.builder().build();
bn.initialize(manager, DataType.FLOAT32, data.getShape());
ParameterStore ps = new ParameterStore(manager, false);
return bn.forward(ps, new NDList(data), false).singletonOrThrow();
}
// 网络集成归一化模式(端到端)
public static SequentialBlock createNetworkWithNorm() {
return new SequentialBlock()
.add(Linear.builder().setUnits(64).build()) // 特征提取
.add(BatchNorm.builder().build()) // 集成归一化
.add(ai.djl.nn.Activation::relu) // 非线性激活
.add(Linear.builder().setUnits(10).build()); // 输出层
}
}
神经网络代码示例1
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.nn.norm.BatchNorm;
import ai.djl.training.ParameterStore;
/**
* 极简版:神经网络 + 归一化层
* 核心:二维数据 + 线性层 + BatchNorm(归一化层)
*/
public class SimpleNNWithNormalization {
public static void main(String[] args) {
// 1. 创建ND管理器(自动释放内存,核心组件)
try (NDManager manager = NDManager.newBaseManager()) {
// 2. 准备简单输入数据:4个样本,2个特征(模拟收入数据)
// 形状:(4, 2) → [样本数, 特征数]
float[][] simpleData = {
{5000, 15000}, // 样本1:现金5000,月收入15000
{80000, 240000}, // 样本2:现金80000,月收入240000
{1000, 3000}, // 样本3:现金1000,月收入3000
{20000, 60000} // 样本4:现金20000,月收入60000
};
// 转换为DJL的NDArray(神经网络输入格式)
NDArray input = manager.create(simpleData);
System.out.println("=== 原始输入数据 ===");
System.out.println(input);
// 3. 构建极简神经网络(顺序执行:线性层 → 归一化层)
SequentialBlock simpleNN = new SequentialBlock();
// 线性层:2个输入特征 → 4个输出特征
simpleNN.add(Linear.builder().setUnits(4).build());
// BatchNorm层:对线性层输出做归一化(让数据分布更稳定)
simpleNN.add(BatchNorm.builder().build());
// 4. 初始化神经网络(必须步骤:绑定数据类型和输入形状)
simpleNN.initialize(manager, DataType.FLOAT32, new Shape(4, 2));
// 5. 执行神经网络前向传播(推理模式,无训练)
ParameterStore ps = new ParameterStore(manager, false);
NDArray output = simpleNN.forward(ps, new NDList(input), false)
.singletonOrThrow();
// 6. 输出结果
System.out.println("=== 神经网络输出(归一化后) ===");
System.out.println(output);
} // try-with-resources自动释放NDManager内存
}
}
运行结果
=== 原始输入数据 ===
ND: (4, 2) cpu() float32
[[ 5000., 15000.],
[ 80000., 240000.],
[ 1000., 3000.],
[ 20000., 60000.],
]
=== 神经网络输出(归一化后) ===
ND: (4, 4) cpu() float32
[[ 38998.293, 14029.01 , 17149.336, 18523.918],
[623972.688, 224464.156, 274389.375, 296382.688],
[ 7799.659, 2805.802, 3429.867, 3704.783],
[155993.172, 56116.039, 68597.344, 74095.672],
]
示例 1 通过最基础的「线性层 + BatchNorm 归一化层」组合,演示了神经网络对原始数据的基础变换能力,但从输出结果能看到:仅靠线性层和归一化层的组合,输出数据仍保留原始数据的数值量级特征(未体现非线性表达能力)。
为了让神经网络具备学习复杂数据模式的能力(比如从「现金 + 月收入」预测「消费能力」这类非线性问题),我们在示例 2 中对基础网络结构进行了扩展 —— 在原有线性层、归一化层的基础上,新增了激活函数层(ReLU)和输出层,同时调整了输入数据场景(欧元计价的收入数据),让网络从「单纯的数据变换」升级为「具备预测能力的简易任务模型」。
简单来说,示例 1 是「神经网络的最小可行版本」,聚焦「数据变换 + 归一化」核心概念;示例 2 则是在其基础上,补全了神经网络解决实际预测问题的关键组件,更贴近真实场景的网络结构设计。
神经网络代码示例2
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* 简易神经网络示例:基于收入数据预测消费能力
* 核心逻辑:线性层+归一化+激活函数+输出层的基础网络结构
*/
public class SimpleNeuralNetworkExample {
public static void main(String[] args) {
// ========== 核心组件1:NDManager(NDArray资源管理器) ==========
// try-with-resources语法:自动关闭管理器,释放Native内存(避免内存泄漏)
// NDManager是DJL中创建/管理NDArray的核心类,所有张量操作必须绑定管理器
try (NDManager manager = NDManager.newBaseManager()) {
// ========== 步骤1:准备输入数据 ==========
// 输入数据:6个样本,每个样本2个特征(现金、月收入),单位:欧元
// 一维数组格式:按「样本1特征1, 样本1特征2, 样本2特征1, 样本2特征2...」顺序排列
float[] euroMoney = {
650, 1950, // 样本1:现金650欧,月收入1950欧
550, 1650, // 样本2:现金550欧,月收入1650欧
60, 180, // 样本3:现金60欧,月收入180欧
900, 2700, // 样本4:现金900欧,月收入2700欧
1000, 2700, // 样本5:现金1000欧,月收入2700欧
1000, 3000 // 样本6:现金1000欧,月收入3000欧
};
// ========== 核心API:创建输入张量(NDArray) ==========
// manager.create(数据数组, 目标形状):将普通数组转为DJL的张量(神经网络输入格式)
// Shape(6, 2):定义张量形状,参数含义:(样本数, 特征数) → 6个样本,每个样本2个特征
// NDArray:DJL中存储多维数据的核心结构(类似NumPy的ndarray)
NDArray input = manager.create(euroMoney, new Shape(6, 2));
System.out.println("输入数据:");
System.out.println(input); // 打印张量内容,格式:ND: (形状) 设备 数据类型
// ========== 步骤2:构建神经网络(SequentialBlock顺序网络) ==========
// SequentialBlock:顺序执行的网络块(类似搭积木),层按添加顺序依次执行
// 适合构建简单的前馈神经网络,是初学者最易理解的网络结构
SequentialBlock network = new SequentialBlock();
// ========== 积木1:线性层(Linear) ==========
// Linear层:实现线性变换 y = w*x + b(w=权重,b=偏置),学习特征间的线性关系
// Linear.builder():构建器模式创建线性层
// setUnits(3):核心参数,定义输出特征数为3 → 输入2维特征 → 输出3维特征
// 输入特征数无需手动设置,后续initialize时会自动推导
network.add(Linear.builder().setUnits(3).build());
// ========== 积木2:BatchNorm层(批量归一化) ==========
// BatchNorm:对线性层输出做归一化(均值≈0,标准差≈1),解决数据分布不均问题
// 核心作用:加速网络训练、防止梯度消失/爆炸,提升模型稳定性
// builder():默认配置(沿最后一维归一化,适配特征维度)
network.add(ai.djl.nn.norm.BatchNorm.builder().build());
// ========== 积木3:ReLU激活函数 ==========
// Activation::relu:方法引用,添加ReLU激活层(非线性变换)
// 核心作用:引入非线性,让网络能学习复杂的特征关系(无激活则网络等价于单层线性变换)
// ReLU公式:f(x) = max(0, x) → 负数置0,正数保留,解决梯度消失问题
network.add(ai.djl.nn.Activation::relu);
// ========== 积木4:输出层(线性层) ==========
// setUnits(1):输出特征数为1 → 最终预测结果为「消费能力得分」(单值)
// 输出层无激活函数:直接输出原始得分,适合回归类任务(预测连续值)
network.add(Linear.builder().setUnits(1).build());
// ========== 步骤3:初始化神经网络(必须步骤) ==========
// network.initialize(管理器, 数据类型, 输入形状):
// 1. 为网络层分配参数(权重w、偏置b),随机初始化
// 2. 绑定输入形状,推导各层的输入/输出维度(如线性层的输入特征数)
// input.getDataType():获取输入张量的数据类型(默认FLOAT32)
// input.getShape():输入张量形状(6,2),告知网络「每次输入6个样本,每个样本2个特征」
network.initialize(manager, input.getDataType(), input.getShape());
// ========== 步骤4:神经网络前向传播(预测) ==========
// ParameterStore:参数存储类,管理网络的权重/偏置参数
// 构造参数:(管理器, isTraining) → false=推理模式(无梯度计算),true=训练模式
ParameterStore ps = new ParameterStore(manager, false);
// network.forward():前向传播,数据通过网络得到输出
// 参数1:参数存储(提供网络层的权重/偏置)
// 参数2:输入数据(封装为NDList,DJL要求网络输入必须是NDList)
// 参数3:isTraining → false=推理模式(不更新参数)
// singletonOrThrow():从NDList中取出唯一的输出张量(无输出则抛异常)
NDArray output = network.forward(ps, new ai.djl.ndarray.NDList(input), false)
.singletonOrThrow();
// ========== 步骤5:解析并显示结果 ==========
System.out.println("\n神经网络预测结果(预测消费能力):");
// 遍历6个样本的预测结果
for (int i = 0; i < 6; i++) {
// output.getFloat(i):获取第i个样本的预测得分(输出张量形状为(6,1),单值)
float score = output.getFloat(i);
// 格式化输出:保留4位小数,直观展示消费能力得分
System.out.printf(" 第%d人: %.4f\n", i+1, score);
}
// ========== 步骤6:可视化网络结构 ==========
System.out.println("\n神经网络结构:");
// 每层的输入输出形状说明:
// [6,2]:输入层(6样本×2特征)
// [6,3]:线性层/BatchNorm/ReLU层(6样本×3特征)
// [6,1]:输出层(6样本×1预测得分)
System.out.println("输入层 → 线性层 → BatchNorm → ReLU → 输出层");
System.out.println("[6,2] → [6,3] → [6,3] → [6,3] → [6,1]");
}
}
}
运行结果
输入数据:
ND: (6, 2) cpu() float32
[[ 650., 1950.],
[ 550., 1650.],
[ 60., 180.],
[ 900., 2700.],
[1000., 2700.],
[1000., 3000.],
]
神经网络预测结果(预测消费能力):
第1人: 268.8257
第2人: 227.4679
第3人: 24.8147
第4人: 372.2197
第5人: 404.9319
第6人: 413.5776
自定义归一化处理器
什么是自定义归一化处理器?
自定义归一化处理器是指在标准归一化方法(如BatchNorm、LayerNorm)基础上,根据特定业务需求或数据特性定制开发的归一化算法或组件。它可以是:
- 对现有归一化方法的改进或组合
- 针对特定数据类型的专用归一化
- 结合领域知识的特殊处理逻辑
为什么需要自定义归一化?
标准归一化方法的局限性
| 标准方法 | 局限性 | 需要自定义的场景 |
|---|---|---|
| BatchNorm | 需要足够大的批量,对时序数据不友好 | 在线学习、小批量训练、实时推理 |
| LayerNorm | 假设特征重要性相同,忽略特征差异 | 不同特征有不同重要性的场景 |
| Min-Max | 对异常值敏感,破坏数据分布 | 含有异常值但需保留分布的数据 |
| Z-Score | 假设数据正态分布 | 非正态分布的金融、医疗数据 |
自定义归一化的主要用途
- 领域特定数据适配
// 示例:医疗数据归一化(考虑正常值范围)
public class MedicalNormalization {
// 血压数据:收缩压正常范围90-140,舒张压60-90
public NDArray normalizeBloodPressure(NDArray bpData) {
NDArray systolic = bpData.get(":, 0"); // 收缩压
NDArray diastolic = bpData.get(":, 1"); // 舒张压
// 不是简单的0-1归一化,而是映射到健康范围
NDArray normalizedSystolic = systolic.sub(90).div(50); // 90-140 → 0-1
NDArray normalizedDiastolic = diastolic.sub(60).div(30); // 60-90 → 0-1
// 超出范围的特殊处理
return NDArrays.concat(new NDList(
clipToRange(normalizedSystolic, 0, 1),
clipToRange(normalizedDiastolic, 0, 1)
), 1);
}
}
- 多模态数据融合
// 示例:融合文本、图像、数值数据的归一化
public class MultiModalNormalizer {
public NDList normalizeMultiModalData(TextData text, ImageData image, NumericData numbers) {
// 文本:基于词频的归一化
NDArray textNorm = normalizeTextByTFIDF(text);
// 图像:感知归一化(考虑人眼敏感度)
NDArray imageNorm = perceptualNormalize(image);
// 数值:业务规则归一化
NDArray numericNorm = businessRuleNormalize(numbers);
return new NDList(textNorm, imageNorm, numericNorm);
}
// 感知归一化:考虑人眼对亮度、对比度的敏感度
private NDArray perceptualNormalize(NDArray image) {
// 1. 转换为HSV/YCbCr等感知相关颜色空间
// 2. 对亮度、饱和度等分量分别归一化
// 3. 考虑人眼非线性响应(gamma校正)
// 4. 返回归一化结果
}
}
- 时序数据动态归一化
// 示例:股票价格数据的自适应归一化
public class TimeSeriesNormalizer {
// 滑动窗口归一化:适应市场变化
public NDArray slidingWindowNormalize(NDArray stockPrices, int windowSize) {
NDArray normalized = manager.zeros(stockPrices.getShape());
for (int i = 0; i < stockPrices.size(0) - windowSize; i++) {
NDArray window = stockPrices.get("{}:{}", i, i + windowSize);
// 使用窗口内的统计量,而非全局统计量
NDArray windowMean = window.mean();
NDArray windowStd = window.sub(windowMean)
.pow(2)
.mean()
.sqrt()
.add(1e-8);
// 归一化当前点
NDArray normalizedPoint = stockPrices.get(i)
.sub(windowMean)
.div(windowStd);
normalized.set(new NDIndex(i), normalizedPoint);
}
return normalized;
}
// 考虑交易量的加权归一化
public NDArray volumeWeightedNormalize(NDArray prices, NDArray volumes) {
// 高交易量的价格变化赋予更大权重
NDArray weightedMean = prices.mul(volumes).sum().div(volumes.sum());
NDArray weightedVar = prices.sub(weightedMean)
.pow(2)
.mul(volumes)
.sum()
.div(volumes.sum());
return prices.sub(weightedMean).div(weightedVar.sqrt().add(1e-8));
}
}
实际应用案例
案例1:电商推荐系统的归一化
public class ECommerceNormalizer {
/**
* 电商用户行为数据归一化
* 考虑:点击率、购买率、停留时间、评价分数
* 每种行为的重要性不同,需要加权归一化
*/
public NDArray normalizeUserBehavior(UserBehaviorData behavior) {
NDArray result = manager.zeros(new Shape(behavior.size(0), 4));
// 点击率:log归一化(点击次数遵循幂律分布)
NDArray clicks = behavior.getClicks();
NDArray normalizedClicks = clicks.add(1).log()
.div(clicks.max().add(1).log());
// 购买率:直接归一化
NDArray purchases = behavior.getPurchases();
NDArray normalizedPurchases = purchases.div(purchases.max().add(1e-8));
// 停留时间:分段归一化(短、中、长时间权重不同)
NDArray dwellTime = normalizeDwellTime(behavior.getDwellTime());
// 评价分数:考虑评价数量的置信度
NDArray ratings = confidenceWeightedRating(
behavior.getRatings(),
behavior.getRatingCounts()
);
// 组合并加权
return NDArrays.concat(new NDList(
normalizedClicks.mul(0.3), // 点击率权重30%
normalizedPurchases.mul(0.4), // 购买率权重40%
dwellTime.mul(0.2), // 停留时间权重20%
ratings.mul(0.1) // 评价权重10%
), 1);
}
}
案例2:自动驾驶感知数据归一化
public class AutonomousDrivingNormalizer {
/**
* 自动驾驶传感器数据归一化
* 特殊需求:
* 1. 不同传感器有不同的误差特性
* 2. 不同距离范围需要不同的归一化策略
* 3. 实时性要求高
*/
public NDArray normalizeSensorData(SensorData sensors) {
NDArray lidarData = adaptiveLidarNormalize(sensors.getLidar());
NDArray cameraData = cameraPerceptualNormalize(sensors.getCamera());
NDArray radarData = radarConfidenceNormalize(sensors.getRadar());
// 传感器融合归一化
return fuseSensorData(lidarData, cameraData, radarData);
}
// LiDAR点云:距离越远,精度越低,归一化要考虑置信度
private NDArray adaptiveLidarNormalize(NDArray lidarPoints) {
NDArray distances = calculateDistances(lidarPoints);
NDArray confidence = distances.neg().div(100).exp(); // 距离衰减置信度
// 置信度加权的归一化
NDArray weightedMean = lidarPoints.mul(confidence).sum()
.div(confidence.sum());
NDArray weightedStd = lidarPoints.sub(weightedMean)
.pow(2)
.mul(confidence)
.sum()
.div(confidence.sum())
.sqrt();
return lidarPoints.sub(weightedMean)
.div(weightedStd.add(1e-8));
}
}
适用场景:
- 领域知识关键:数据有特殊意义或结构
- 医疗数据:正常值范围、临床阈值
- 金融数据:交易规则、风险边界
- 工业数据:设备规格、安全范围
- 数据特性特殊:标准假设不成立
- 非独立同分布数据
- 非正态分布数据
- 多峰分布数据
- 性能需求特殊:
- 实时系统:需要快速归一化
- 边缘设备:内存/计算受限
- 在线学习:数据流式到达
- 业务规则复杂:
- 加权归一化(不同特征重要性不同)
- 条件归一化(不同场景不同规则)
- 分级归一化(不同级别不同处理)
不需要自定义的场景:
- 通用数据:没有特殊领域知识
- 标准任务:图像分类、文本分类等成熟任务
- 资源有限:没有能力开发和验证自定义方法
- 数据充足:深度学习可以自动学习数据分布

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)