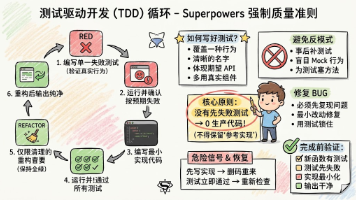
QDKT-第4次作业点评&直播答疑
二、第一节课作业点评:为什么大模型厂商呼吁不要再跟模型说谢谢了?
(一)本节课核心知识点(大模型训练基础)
- 大模型在微调阶段+RLHF(人类反馈强化学习)阶段的训练语料均为「输入+输出」的问答形式,这让模型形成必答特性——无论用户输入什么,模型都会生成回复。
- 厂商反对说“谢谢”的核心原因:用户说谢谢后,模型的必答特性会让其被迫生成无意义回复,该过程会消耗算力/计算资源,但无任何实际价值,性价比极低。
- 关键概念区分:大模型的训练过程和推理过程是完全独立的,用户的礼貌用语不会导致模型“性能下降”,也不会“污染模型训练数据”。
- 两大常见误区澄清:
- 厂商并非出于伦理诉求反对说谢谢(行业尚未到关注该类伦理的阶段);
- 厂商不会将用户的交互数据用于模型训练(用户数据良莠不齐,清洗成本极高,盲目使用会导致模型“降质”)。
(三)优秀作答要点
- 核心逻辑:模型微调和RLHF阶段的问答式语料形成了必答特性,说谢谢会让模型做无意义回复,消耗算力和计算资源,对厂商而言无性价比;
- 可结合生活化类比增强理解(如“不会对着电表说谢谢,资源要用到实处”);
- 不引入未学概念、不堆砌术语,用课程讲的核心知识点作答即可。
三、第二节课作业点评:用自己的话解释大模型是如何推理的?
(二)本节课核心知识点(大模型推理底层原理)
核心结论:大模型的推理本质是TOKEN逐一生成的迭代过程,具有概率性和单向性,无真正的“思考”能力。
- 基础概念
- TOKEN:大模型处理文字的最小单元,可理解为“文字碎片”(一个字/一个词/半个词都可能是一个TOKEN),不同模型的TOKEN词表不同;
- 向量嵌入:预训练完成后,每个TOKEN都会对应一个固定的向量表达(坐标),并非实时“打分”生成,推理阶段仅调用该预训练结果;
- 遮罩机制:模型训练和推理时,会“盖住”后面的TOKEN,只能往前看,无法看到后续内容(这是模型推理单向性的核心原因);
- 注意力机制:每个TOKEN会计算与前面所有TOKEN的相似度,找到最相关的TOKEN后调整自身向量;该过程依赖矩阵乘法,算力消耗极大,是模型上下文长度受限的核心原因;
- 线性注意力机制:对传统注意力机制的优化,通过简化矩阵乘法降低算力消耗,是Kimi、豆包等模型实现超长上下文的关键技术(主流配比1:3)。
- 大模型推理的完整步骤
① TOKEN切分:将用户输入的文字拆分为模型可识别的TOKEN;
② 向量调用:调用预训练后TOKEN的固定向量表达,无需实时打分;
③ 单向相似度计算:每个TOKEN基于注意力机制,计算与前面所有TOKEN的相似度,调整自身向量(仅往前看,遮罩机制作用);
④ 逐一生成TOKEN:模型根据概率选择下一个最可能的TOKEN(非100%固定,体现概率性),生成后追加到原上下文;
⑤ 迭代循环:将新生成的TOKEN加入后,重新执行步骤③-④,直到模型停止生成,最终将TOKEN拼接为完整文字。
- 思维链(COT)的底层逻辑
让模型输出“思考过程”,本质是让模型生成的思考TOKEN成为最终答案的“垫脚石”,通过增加迭代的上下文,提升最终答案的稳定性和准确率;若不让模型输出思考过程,模型无法“分步思考”,只能直接蒙答案,易出错/产生幻觉。
- 推理的概率性影响
模型生成下一个TOKEN时,会选择概率较高的选项,而非100%固定选项,这导致模型输出具有不可控性——同一个问题多次提问,答案可能略有不同;因此测评模型时,需对同一个问题多次测试,而非一次定结果。
(四)优秀作答要点
- 核心逻辑:大模型推理是逐TOKEN迭代生成的过程,预训练后TOKEN的向量表达固定,模型通过遮罩机制只能往前看,每个TOKEN计算与前面所有TOKEN的相似度后调整自身,再按概率生成下一个TOKEN,追加到上下文后循环,直到生成结束;
- 提及概率性:说明模型生成TOKEN是选概率高的选项,输出具有不可控性;
- 结合思维链:解释“让模型输出思考过程”能提升答案稳定性的原因(思考TOKEN成为垫脚石);
- 不堆砌术语,用通俗的语言讲清步骤,避免引入未学概念。
四、第三节课作业点评:大模型为什么没有真正的推理能力?
(一)本节课核心知识点(大模型“伪推理”的本质)
核心结论:大模型的所谓“推理”只是基于语料的概率关系匹配,是“刷题式”的规律复刻,而非人类的因果逻辑判断,本质是生成式的伪推理。
1. 人类推理 vs 大模型“伪推理”的核心差异
|
维度 |
人类推理 |
大模型“伪推理” |
|
逻辑基础 |
基于已有事实找因果关系 |
基于语料相似度找概率最高的关系 |
|
纠错能力 |
能推翻原有推理,重构逻辑链 |
无回溯能力,一旦出错会在错误路径上越走越远 |
|
过程本质 |
发现事实、串联逻辑 |
生成内容、匹配规律 |
2. 大模型无真正推理能力的关键原因
- 无回溯/纠错能力:模型的推理是逐TOKEN生成的迭代过程,生成后无法“撤回”或“推翻”,一旦第一步出错,后续会基于错误内容继续生成,导致错误放大;
- 无因果判断能力:模型无法理解“因为A所以B”的因果逻辑,只能通过语料中A和B的共现概率,判断“提到A时应该接B”;
- 无真正的知识库:模型没有存储“知识”,只有预训练后的参数和向量表达,所谓“推理”只是对语料规律的匹配,类似“刷了大量题后,看到题目就选最熟悉的答案”;
- 易陷入偏执性:若被用户的先验知识带偏,模型无法自行跳出错误逻辑,会强行将无关信息串联,形成错误的推理结果。
3. 常见误区澄清
- 大模型缺乏常识、产生幻觉与“无推理能力”无直接关联,前者是语料覆盖问题,后者是底层逻辑问题;
- 模型可以分步输出推理过程(如思维链),但这只是“生成更多TOKEN作为垫脚石”,并非真正的分步思考。
(三)优秀作答要点
- 核心逻辑:大模型的推理是基于语料的概率关系匹配,无因果判断能力;而人类推理是基于事实的因果逻辑串联,且能推翻原有推理重构逻辑。同时模型的逐TOKEN生成方式让其无回溯纠错能力,一旦出错会在错误路径上越走越远,因此无真正的推理能力;
- 结合第二节课知识点:将“逐TOKEN迭代生成”与“无回溯能力”关联,体现知识的连贯性;
- 澄清误区:说明模型的“刷题式规律匹配”并非真正的推理,区分“缺乏常识”和“无推理能力”的不同。
五、第四节课作业点评:提词工程——提示词中哪些是防幻觉的?并说明原因
(一)本节课核心知识点(提示词防幻觉的核心逻辑)
- 模型幻觉的本质:模型在无相关信息/信息无效时,因“必答特性”强行生成内容,导致胡编乱造、答非所问。
- 防幻觉的核心原则:给模型设边界、留退路,避免模型强行回答——这是设计防幻觉提示词的核心,零基础可直接记此原则。
- RAG基础铺垫:给模型提供“知识资料”的核心目的,是替代模型的原有知识(不相信模型的原生回答),让模型基于指定资料作答,从源头减少幻觉;若资料无效/不相关,模型强行作答仍会产生幻觉。
(二)核心防幻觉提示词条款及原因
以下4条为提示词中核心的防幻觉条款,零基础需熟记每条的设计逻辑(均围绕“设边界、留退路”):
- 防幻觉原因:给模型留退路,避免模型在无相关信息时强行编造内容。
- 防幻觉原因:给模型设筛选边界,让模型主动过滤无效资料,避免基于错误/无关资料生成内容,降低噪音干扰。
- 防幻觉原因:给模型设输出边界,严格限定模型只能“整合资料”,不能“创造内容”,从源头杜绝无依据的生成。
- 防幻觉原因:给模型设前提边界,避免模型基于无效资料生成错误内容,是对条款2的补充。
- 防幻觉原因:提醒模型关注语义而非字面,避免按错别字/口语化表达错误解读问题,导致生成错误内容。
(四)优秀作答要点
- 答题结构:先明确标注防幻觉的条款,再逐条说明原因,逻辑清晰;
- 原因解读:紧扣“防幻觉核心原则——设边界、留退路”,不用堆砌术语,通俗说明即可;
- 细节补充:结合资料特点,补充该条款的防幻觉作用,体现思考的全面性;
- 不超纲:仅基于题目中的提示词作答,不自行设计提示词(避免设计错误)。
六、核心学习要求&实操原则(零基础必看)
- 清空先验认知,从零开始学
避免被短视频、公众号的错误内容误导(如“模型会被污染”“模型降质”等都是营销号的虚假概念);学习每节课时,假设自己未学过后续内容,做到“学哪答哪”。
- 产品经理的核心能力:一秒变傻子
清空自己的专业认知,站在普通用户的角度理解大模型;做产品/设计提示词时,避免“自己觉得简单,用户却看不懂”的情况。
- 核心概念区分,拒绝混淆
- 训练过程 ≠ 推理过程(完全独立,用户交互不影响训练);
- TOKEN ≠ 向量(TOKEN是最小单元,向量是TOKEN的预训练表达);
- 注意力机制 ≠ 线性注意力机制(后者是前者的优化,用于降低算力消耗);
- 模型无知识库,只有参数和向量表达。
- 提示词设计的底层逻辑
防幻觉的核心永远是“留退路、设边界、限输出”,零基础设计提示词时,围绕这9个字即可,不用追求复杂的术语和结构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)