为什么敏捷开发管不了AI项目?3大替代框架+混合双轨制实战方案(附落地模板)
🍃作者介绍:AI 应用工程师 / 产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹
1、前言
相信大家在带AI项目的过程中,反复遇到一个管理困境:
周会上,我按照Scrum流程做Sprint Review,发现一个扎心的事实——团队这两周跑了5组模型实验,全部没达到预期精度。
按敏捷的标准,这个Sprint"零交付"。但作为项目负责人,我清楚这5次实验排除了5条错误路径,团队离正确方向更近了。
问题来了:我该怎么向上汇报?怎么在下一次排Sprint时给团队定合理的目标?
后来我意识到,这不是团队执行力的问题,而是管理方法和项目性质不匹配的问题。

传统软件开发有一套非常成熟的管理方法叫"敏捷开发"(Agile),在互联网行业几乎是标配。但当你用这套方法来管AI/ML项目时——它失灵了。
这篇文章是我在实际管理AI项目过程中,研究和实践的总结。先从零讲清楚"敏捷"到底是什么,再分析它为什么管不了AI项目,最后给出三套业界验证过的替代方案和一个可以立刻落地的混合管理策略。
2、先搞懂:什么是"敏捷管理"
如果你没接触过项目管理,“敏捷”、“Scrum”、"Sprint"这些词听起来可能很唬人。别慌,其实它的核心思想非常简单。
2.1 一个比喻就懂了
想象你在装修房子。
传统做法(瀑布模型):先花两个月画完所有图纸,然后开始动工。半年后装完了,你走进去一看——厨房太小了、客厅插座不够用、主卧的灯光位置不对。但水电已经走完了,改不了了。
敏捷做法:先装一间卧室,住进去体验两周。发现插座不够?下一间多装几个。发现灯光太暗?下一间换方案。每两周交付一个房间,边住边改,持续优化。
这就是敏捷的核心理念:不追求一次做完,而是小步快跑、持续交付、快速反馈。
2.2 Scrum:最流行的敏捷框架
敏捷是一种理念,而Scrum是实现这种理念最常用的具体框架。它有几个核心概念:
| 概念 | 通俗解释 |
|---|---|
| Sprint(冲刺) | 一个固定时长的工作周期,通常2周。每个Sprint结束要交付一个可用的版本 |
| Product Backlog(需求池) | 所有待做需求的优先级清单,老板想要什么都往里放 |
| Daily Standup(每日站会) | 每天15分钟,站着开会:昨天做了啥?今天做啥?有没有被卡住? |
| Sprint Review(评审会) | Sprint结束时演示成果给老板/客户看,收集反馈 |
流程如下图所示: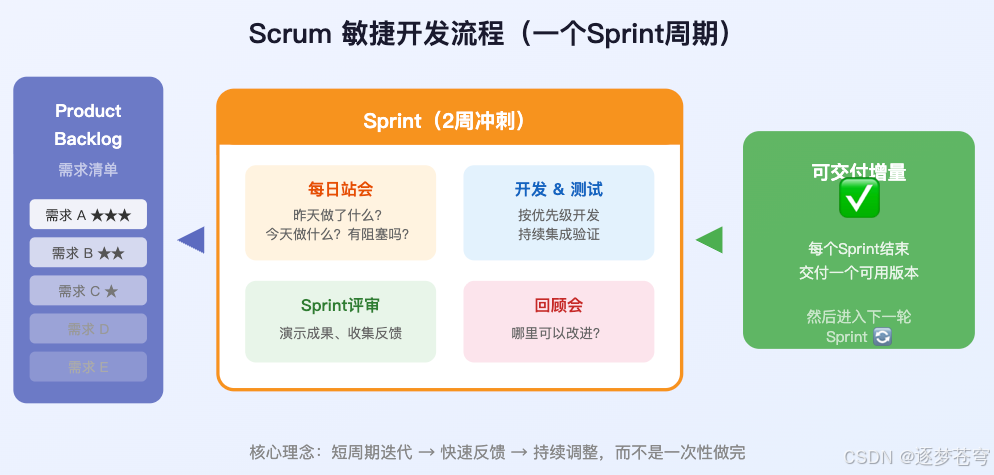
2.3 为什么软件行业都在用它
在敏捷出现之前,软件行业用的是"瀑布模型"——先花几个月写完所有需求文档,再花几个月开发,最后交付。问题是:需求在开发过程中一定会变。客户说"我要一匹更快的马",你花半年造了出来,他说"其实我想要的是汽车"。
敏捷通过短周期迭代(2周一轮),把这个风险降到了最低——每两周检查一次方向是否正确,错了马上调。
这套方法在传统软件开发中非常有效。 但是,当你把它搬到AI项目上…
3、AI项目的五大"水土不服"
先看一张对比图,直观感受下差异:
AI/ML项目和传统软件开发有本质上的差异,不是调调参数就能兼容的。具体来说,有五个核心痛点:
3.1 痛点一:结果是不确定的
传统软件是确定性的——代码逻辑写对了,功能就能用。你写一个登录接口,只要代码没Bug,它就一定能跑。
AI项目是概率性的——你用同样的算法、同样的代码,换一批数据,结果可能天差地别。"把模型精度从88%提到93%"这个目标,动手之前你根本不知道能不能做到,甚至不知道93%是不是这个数据集的天花板。
Scrum要求每个Sprint结束时交付"可工作的软件增量"。但在AI项目中,你两周的工作成果可能是:“我们验证了这条路走不通”。这是有价值的发现,但在Scrum的框架里,它就是"没有交付"。
3.2 痛点二:数据不受你控制
ML项目80%的时间花在数据上——采集、清洗、标注、特征工程。而这些工作的进度,往往不是你的团队说了算的:
- 外部数据授权可能要走三个月的审批流程
- 标注团队的产出质量参差不齐
- 数据清洗到一半才发现缺少关键字段
Gartner 2025年的报告显示:63%的组织不具备AI就绪的数据管理实践。 换句话说,你的数据基础大概率是"不及格"的,而Sprint计划是建立在"数据已就绪"的假设上的。一旦数据卡住,整个Sprint计划就会连锁崩塌。
3.3 痛点三:实验失败是常态
这是最反直觉的一点——在AI项目中,失败不是异常,而是日常。
做传统开发,如果一个功能两周没做出来,要么是需求没理解对,要么是技术方案有问题,总之是有原因、可以定位的。
做AI项目,你可能花两周跑了5组实验,结论是"这5种方法在这个场景下都不行"。这不是你能力不行,这是科学实验的正常状态——爱迪生试了上千种材料才找到合适的灯丝,你能说他前面的实验都是"浪费"吗?
但在Scrum的汇报体系里,这就成了管理者的难题:你怎么向上汇报"有价值的失败"?怎么在绩效评估中体现团队的探索性贡献? 如果管理者自己都无法定义"什么算完成",团队的士气和方向感都会出问题。
3.4 痛点四:进度无法线性衡量
传统软件的进度衡量很简单:10个功能做完了6个,就是60%完成。
AI项目的进度衡量是这样的:模型精度可能在90%卡了两个月纹丝不动,然后你换了一种特征工程方法,精度突然跳到了95%。进度不是一条斜向上的直线,而是一条长期横盘、偶尔跳涨的曲线。
Scrum中用"故事点"来估算任务复杂度,但面对"提升模型精度5个百分点"这种任务,没有人能给出靠谱的故事点估算。
3.5 痛点五:团队角色结构性错位
一个AI项目团队通常包括:数据工程师、数据科学家、ML工程师、领域专家、产品经理…这些角色的工作节奏完全不同。
数据工程师可能在搭管道(工程化、可Sprint),数据科学家可能在探索特征(实验性、无法Sprint),ML工程师可能在调参训练(等GPU跑完才知道结果)。如果管理者把他们塞进同一个Sprint、用同一套节奏去考核,结果要么是数据科学家被迫"赶工"牺牲实验质量,要么是工程师被拖慢节奏。 这不是团队的问题,是管理架构的问题。
3.6 数据不会说谎
- 87% 的AI/ML项目永远无法投入生产(VentureBeat 2019)
- Gartner预测:到2026年,30%的生成式AI项目在概念验证后终止
- 从原型到生产平均耗时 8个月,仅48%能进入生产
这些数字背后,有多少是因为"方法不对"而非"技术不行"?
Scrum.org自己都承认: “最常见的失误,是把为软件设计的Scrum照搬到AI项目——包括软件专属的’完成定义’和过度规格化的用户故事。”
4、三大替代方案
既然传统Scrum不适合AI项目,业界有没有更好的方法?有。下面介绍三个经过实践验证的框架。
4.1 CRISP-DM:数据科学界的"事实标准"
CRISP-DM(Cross-Industry Standard Process for Data Mining,跨行业数据挖掘标准流程)是1999年由欧盟资助发布的方法论,至今仍是数据科学领域采用率最高的流程框架——约50%的数据科学项目在使用它(KDnuggets调查)。
它包含六个阶段,形成一个可循环迭代的闭环: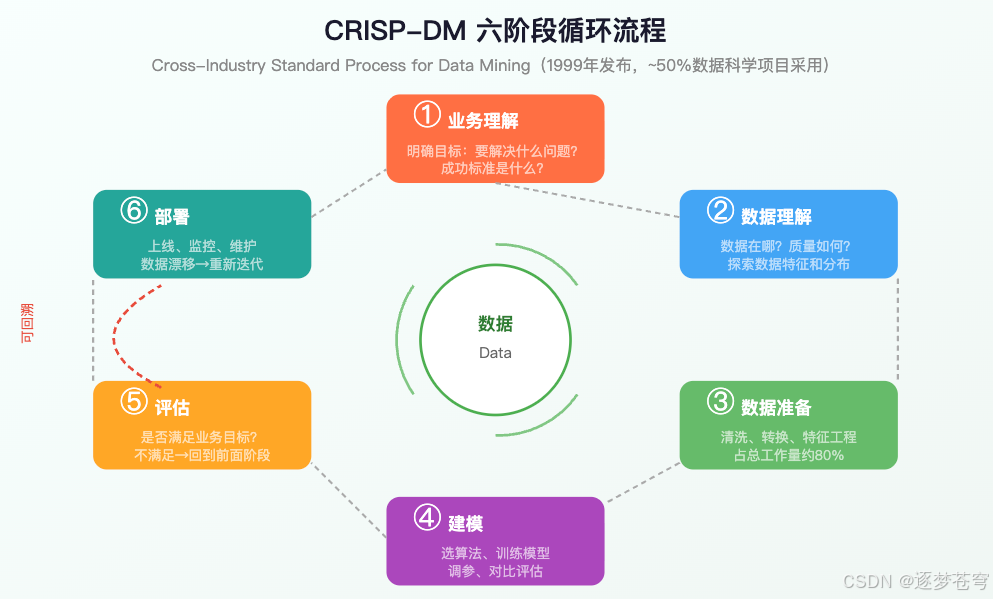
| 阶段 | 核心工作 | 通俗解释 |
|---|---|---|
| 业务理解 | 明确项目目标、定义成功标准 | 先搞清楚"我们到底要解决什么问题" |
| 数据理解 | 采集数据、探索特征、评估质量 | 看看手里有什么牌 |
| 数据准备 | 清洗、转换、特征工程 | 把牌整理好(这一步占80%工作量) |
| 建模 | 选算法、训练模型、调参评估 | 开始打牌 |
| 评估 | 模型是否满足业务目标 | 看看打得怎么样,不行就回到前面重来 |
| 部署 | 上线、监控、维护 | 正式上桌 |
CRISP-DM的核心优势:
- 允许回退:评估阶段发现不达标?可以直接回到"数据准备"甚至"业务理解"重新来。这在Scrum里是不可想象的——你不能"回退"一个Sprint
- 不强迫伪确定性:它不要求你预测每个阶段的精确时间,承认AI实验的不可预知性
- 以业务目标驱动:始终围绕"解决业务问题"而非"完成技术指标"
缺点:缺乏项目管理和团队协作规范(没有角色定义、没有会议机制),所以很多团队会把CRISP-DM和Kanban/Scrum混合使用——用CRISP-DM规定"做什么",用敏捷工具管理"怎么协作"。
4.2 TDSP:微软的"工程化升级版"
TDSP(Team Data Science Process)是微软2016年发布的方法论,可以理解为CRISP-DM的"企业工程化升级版"。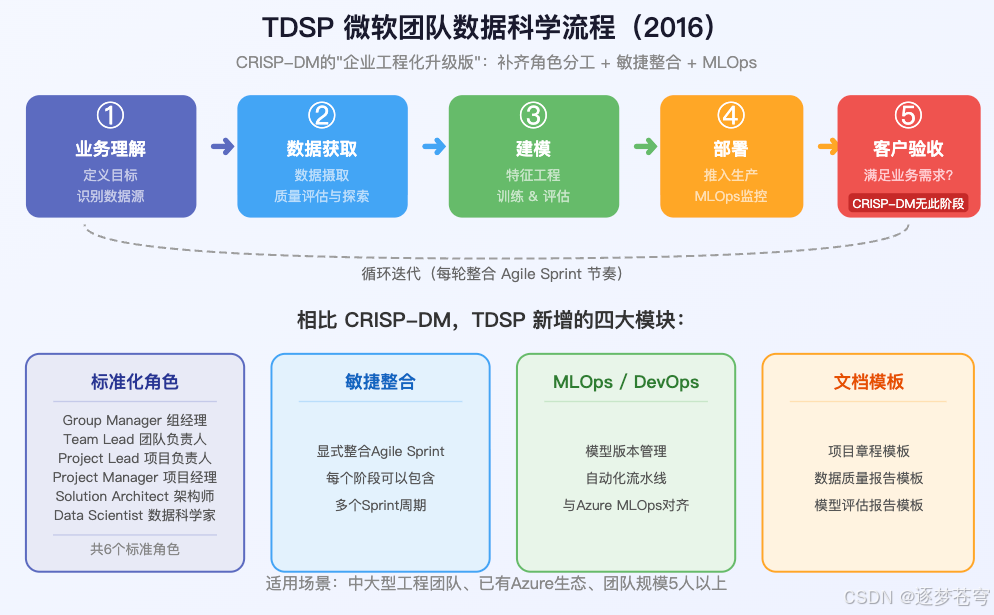
它和CRISP-DM的阶段结构类似,但有几个关键强化:
| 维度 | CRISP-DM(1999) | TDSP(2016) |
|---|---|---|
| 团队角色 | 无明确定义 | 定义了6个角色(架构师、PM、数据工程师等) |
| 敏捷整合 | 无 | 显式整合Agile Sprint |
| DevOps | 无 | 包含MLOps实践,与Azure对齐 |
| 文档模板 | 无标准工具包 | 提供项目章程、数据报告、模型报告模板 |
| 新增阶段 | 无 | 增加"客户验收"阶段 |
TDSP适合什么团队? 如果你的团队有一定的工程化基础、团队规模在5人以上、需要明确的角色分工和标准化文档,TDSP是一个非常结构化的选择。虽然它由微软推出,配套工具偏向Azure生态,但方法论本身是平台无关的——角色定义、阶段流程、文档模板这些核心价值,用什么技术栈都能落地。
缺点:流程相对较重,小团队可能觉得"杀鸡用牛刀"。
4.3 DDS:为数据科学量身定制的Scrum变种
DDS(Data-Driven Scrum,数据驱动Scrum)由Jeff Saltz和Alex Sutherland提出,它的核心创新只有一个:
用"功能性迭代"(可变长度)替代固定Sprint。
传统Scrum的Sprint是固定2周——时间到了,不管做没做完都得结束。DDS说:迭代的边界不应该是日历时间,而应该是"一个完整的实验闭环"。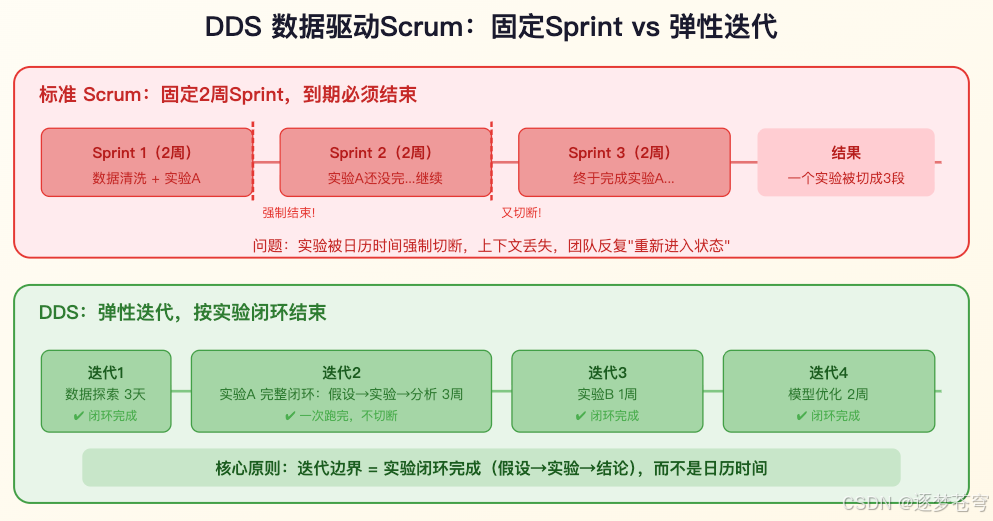
一次实验的完整闭环 = 提出假设 → 实现实验 → 观察分析结果
这个闭环可能3天就完成,也可能需要3周。DDS允许迭代长度根据实际工作调整,而不是削足适履塞进2周。
DDS vs 标准Scrum 关键区别:
| 维度 | 标准Scrum | DDS |
|---|---|---|
| 迭代时长 | 固定(通常2周) | 可变(按实验完成) |
| 估算要求 | 故事点 / 工时 | 仅高层次估算 |
| 迭代边界 | 日历时间 | 逻辑工作块完成 |
| 并行性 | 单Sprint线性推进 | 允许迭代重叠 |
DDS最大的价值:它解决了那个最尴尬的问题——“Sprint到期了但实验还没跑完怎么办?” 答案是:别硬切,让实验跑完。
4.4 三大框架对比总结

| 维度 | CRISP-DM | TDSP | DDS |
|---|---|---|---|
| 定位 | 数据科学生命周期 | 企业级团队协作 | 敏捷改良 |
| 核心亮点 | 允许回退、循环迭代 | 角色分工+MLOps | 弹性迭代长度 |
| 学习成本 | 低 | 中 | 低 |
| 适合团队 | 数据科学为主 | 中大型工程团队 | 已有Scrum基础的团队 |
| 缺点 | 缺协作规范 | 流程较重,小团队偏重 | 较新,案例少 |
5、最佳实践:混合双轨制
说了这么多框架,到底怎么用?业界最成熟的做法是——不选一个,而是混合。
核心思想叫 “双轨制”(Dual-Track Agile):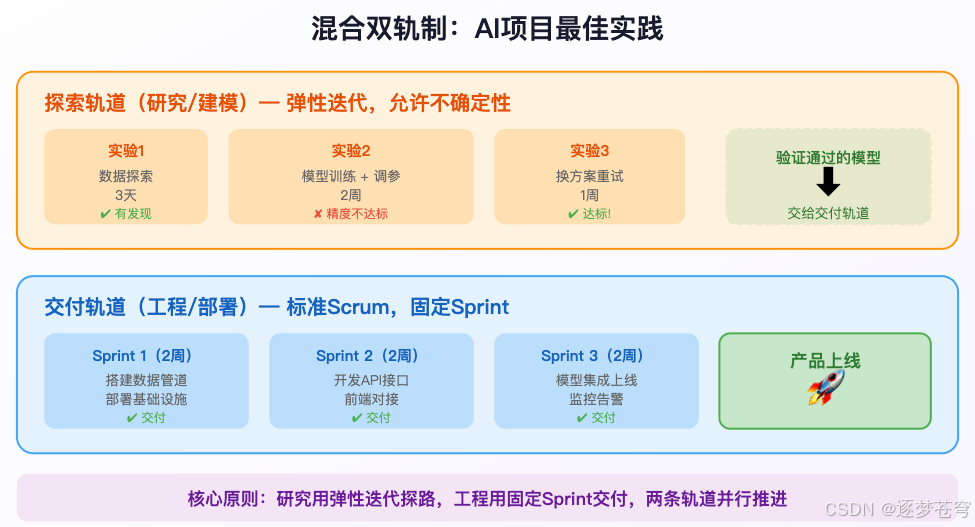
5.1 两条轨道怎么分
| 探索轨道 | 交付轨道 | |
|---|---|---|
| 负责什么 | 数据探索、特征实验、模型训练 | 数据管道、API开发、部署上线 |
| 节奏 | 弹性迭代,以实验闭环为边界 | 标准Scrum Sprint(2周) |
| "完成"的定义 | 得出可验证的结论(无论成功或失败) | 交付可运行的功能 |
| 失败的处理 | "此路不通"是有效产出 | 未完成即Sprint失败 |
两条轨道并行推进: 探索轨道的输出(验证通过的模型)持续"喂给"交付轨道进行工程化集成。
5.2 业界谁在这么干
- Netflix:用Metaflow框架支持研究→生产平滑过渡,工程用Agile短周期,研究独立迭代
- Google / Uber / Spotify:实验基础设施独立于产品功能开发,形成事实上的双轨运作
- Slalom:ML项目中区分"Sprint 0"(搭环境、选算法)与增量建模Sprint,并设置"精度提升止损线"——连续两个Sprint精度无显著提升则停止该方向
5.3 四个关键实践
- Sprint 0:在正式开发前,用一个Sprint专门搭建ML工作台、数据管线、候选算法筛选
- 解耦数据Backlog:数据准备、清洗、标注的任务池独立于模型开发的任务池,避免互相阻塞
- API优先策略:前端和AI模型团队通过接口契约解耦,模型没ready时前端用Mock数据先做
- 时间盒止损:给探索性实验设一个最大时间限制。比如:连续3周精度无提升 → 停下来,换方向或降低目标
6、实战落地:我在项目中的具体做法
理论讲完了,下面说说我自己在实际管理AI项目时的做法。团队不大,但这套思路从第一天就能用——核心不在于形式多完整,而在于管理思维的转变。
6.1 第一步:项目分类,区别管理
我现在拿到一个AI项目,第一件事就是按这个标准做分类:
| 类型 | 特征 | 举例 | 管理方式 |
|---|---|---|---|
| 确定性交付 | 方案成熟、结果可预期 | RPA自动化、OCR文档识别、规则引擎 | 标准Sprint,每2周交付 |
| 探索性项目 | 结果不确定、需要实验验证 | 新场景RAG优化、VLA方案探索、创新应用 | 弹性迭代 + Demo检查点 |
光是做完这个分类,管理上就清晰了一大半——大多数AI团队的混乱,就来自于用同一套Sprint管两种完全不同性质的工作。
6.2 第二步:探索性项目用"检查点"替代"截止线"
管理探索性项目时,我不再给团队设"两周后精度必须到93%"这种硬截止线,而是设检查点:
- 第1周检查点:数据质量评估完成,确认特征候选列表
- 第2周检查点:至少完成2组对比实验,输出实验报告
- 第3周检查点:Demo当前最优模型的效果,团队决定是继续还是换方向
区别在于:检查点是"到这个时间点同步进展、集体决策",截止线是"到这个时间必须完成"。前者给团队方向感,后者给团队压迫感。管理AI实验,只能用前者。
6.3 第三步:重新定义"交付物",让失败也被看见
这是我认为最重要的管理动作——在团队内部建立一个共识:"排除一条错误路径"和"走通一条正确路径"同样是有价值的产出。
具体做法:我要求团队每次实验结束后(无论成败),都输出一份简短的实验记录:
- 假设是什么?
- 做了什么?
- 结论是什么?
- 下一步建议是什么?
这样做有两个管理上的好处:
- 对上汇报有据可依:不是"这两周什么都没做出来",而是"排除了3条路径,方向范围缩小到2个候选方案"
- 团队知识沉淀:后来的人不会重复踩坑,项目换人也不会丢失探索记录
7、总结
回到开头的问题:传统敏捷管不了AI项目,怎么办?
答案不是"扔掉敏捷",而是改造它。
核心认知转变:
- AI项目是探索,不是施工。 管理者必须从"确定性交付"的思维切换到"管理不确定性"的思维
- 有三个成熟的替代框架。 CRISP-DM(数据科学标准流程)、TDSP(微软工程化方案)、DDS(弹性迭代Scrum),不需要从零发明
- 最佳实践是混合双轨制。 工程工作用标准Sprint,研究工作用弹性迭代,两条轨道并行推进
- 今天就可以开始。 项目分类、检查点替代截止线、重新定义交付物——三个管理动作,立刻见效
AI团队管理的核心能力,不是让团队跑得更快,而是在不确定性中找到正确的节奏。 好的管理方法论不会让实验成功率变高,但会让团队在探索中不迷失方向、在失败中不丧失士气、在汇报中不丢失价值。
这也是我一直在实践和思考的方向——AI时代的项目管理,需要的不是更严格的计划,而是对不确定性的尊重和驾驭。
参考来源:
- VentureBeat Transform 2019:87%的ML项目失败率
- Gartner 2025:AI数据就绪性报告
- KDnuggets 2014:数据科学方法论采用率调查
- Scrum.org:AI4Agile Practitioners Report
- datascience-pm.com:Agile AI/ML项目管理系列
- Microsoft Learn:TDSP官方文档
- Jeff Saltz & Alex Sutherland:Data-Driven Scrum
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注公众号 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)