YOLO11 改进 - 注意力机制 | DSSA双稀疏自注意力,降低计算量,并精准聚焦高信息量特征交互
前言
本文介绍了双稀疏自注意力(DSSA),一种通过空间与通道双重稀疏约束优化自注意力计算的高效模块。该方法利用局部窗口与稀疏锚点进行空间筛选,并结合动态通道门控,在大幅降低计算复杂度的同时精准聚焦关键特征。我们将 DSSA 成功集成进 YOLO11,在检测头部分对 P3、P4、P5 尺度的特征进行双稀疏增强。实验证明,集成 DSSA 的 YOLO11 在检测任务中表现优异,有效提升了模型的特征提取能力与计算效率。
文章目录: YOLO11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO11改进专栏
介绍

摘要
在分娩过程中,传统的方法包括阴道侵入性检查,但研究表明,这些方法既主观又不准确。超声辅助诊断提供了一种客观而有效的方法,通过两个关键参数来评估胎儿头部位置:进展角(AoP)和头联合距离(HSD),通过分割胎儿头部(FH)和耻骨联合(PS)来计算,这有助于临床医生确保顺利分娩过程。因此,准确分割FH和PS是至关重要的。本文提出了一种性能良好、计算效率高的稀疏自关注网络架构dsau - net,用于跳频和PS的分割,具体而言,我们在每个阶段堆叠不同数量的双稀疏选择注意(dual sparse Selection Attention, DSSA)块,形成不对称的u型编解码器网络架构。对于给定的查询,DSSA被设计为分别在区域和像素级别显式地执行一个稀疏令牌选择,这有利于进一步降低计算复杂性,同时提取最相关的特征。为了补偿上采样过程中的信息损失,设计了带卷积的跳变连接。此外,采用多尺度特征融合,丰富模型的全局和局部信息。dsau - net的性能已经在MICCAI IUGC 2024竞赛中使用主办方提供的宫内超声大挑战(IUGC)2024测试集进行了验证,我们在分类和分割任务中获得了第四名,证明了它的有效性。代码将在GitHub上提供。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
双稀疏自注意力(Dual Sparse Self-Attention, DSSA)是针对传统自注意力机制在高分辨率医学影像处理中计算复杂度激增、冗余信息干扰等问题提出的高效优化注意力模块,其核心是通过空间维度与通道维度的双重结构化稀疏约束,在大幅降低计算成本的同时,精准聚焦医学影像中与任务相关的关键特征交互,为超声图像中胎儿头部与耻骨联合的自动分割提供核心技术支撑。传统自注意力机制的计算表达式为 Attention ( Q , K , V ) = Softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQK⊤)V ,其中 Q Q Q 、 K K K 、 V V V 分别为查询、键、值投影矩阵,维度为 N × d k N \times d_k N×dk ( N N N 为像素总数, d k d_k dk 为特征维度),其 O ( N 2 ⋅ d k ) O(N^2 \cdot d_k) O(N2⋅dk) 的计算复杂度在超声图像(如 512 × 512 512 \times 512 512×512 分辨率)中会导致计算与内存开销爆炸,且全连接式注意力会引入大量无关背景与噪声信息,难以适配临床实时分割需求。
DSSA通过空间稀疏与通道稀疏的协同剪枝,构建高效且精准的注意力计算机制:空间稀疏层面,采用“局部窗口+长程稀疏锚点”的结构化设计,首先将输入特征图 X ∈ R H × W × C X \in \mathbb{R}^{H \times W \times C} X∈RH×W×C 划分为非重叠局部块,通过块级注意力筛选出包含胎儿头部、耻骨联合等关键解剖结构的语义相关块,再在选中块内进行像素级注意力计算,同时通过均匀采样少量全局关键像素作为稀疏锚点,捕捉胎头与骨盆之间的长程空间关系,其空间稀疏约束通过二进制空间掩码 M s M_s Ms 实现,仅保留高贡献度的位置交互,此时空间稀疏注意力可表示为 Attn sparse ( Q , K , V ) = Softmax ( ( Q ⊙ M s ) K ⊤ d k ) V \text{Attn}_{\text{sparse}}(Q,K,V) = \text{Softmax}\left(\frac{(Q \odot M_s)K^\top}{\sqrt{d_k}}\right)V Attnsparse(Q,K,V)=Softmax(dk(Q⊙Ms)K⊤)V ( M s M_s Ms 中1表示保留计算,0表示屏蔽);通道稀疏层面,结合医学超声分割任务特性,通过动态通道门控与静态通道分组相结合的方式,筛选出与解剖结构边缘、轮廓、灰度梯度相关的任务敏感通道,抑制无关纹理通道的干扰,通过通道稀疏掩码 M c M_c Mc 对 Q Q Q 、 K K K 、 V V V 进行筛选,得到 Q c = Q ⊙ M c Q_c = Q \odot M_c Qc=Q⊙Mc 、 K c = K ⊙ M c K_c = K \odot M_c Kc=K⊙Mc ,实现特征维度的有效精简( C ′ ≪ C C' \ll C C′≪C , C ′ C' C′ 为稀疏后通道数)。
DSSA的完整计算流程可概括为:首先对输入特征图进行线性投影生成 Q Q Q 、 K K K 、 V V V ;随后通过通道稀疏掩码 M c M_c Mc 对三者进行剪枝,得到通道稀疏后的特征 Q s Q_s Qs 、 K s K_s Ks 、 V s V_s Vs ;接着通过空间稀疏掩码 M s M_s Ms 筛选有效交互位置,计算稀疏相似度矩阵 S = Q s K s ⊤ d k ⊙ M s S = \frac{Q_s K_s^\top}{\sqrt{d_k}} \odot M_s S=dkQsKs⊤⊙Ms ,对非零元素进行稀疏Softmax归一化得到注意力权重 α \alpha α ;最后通过 Output = α V s \text{Output} = \alpha V_s Output=αVs 完成特征加权聚合,经残差连接与前馈网络输出双稀疏增强特征。与传统自注意力 O ( H W ⋅ C 2 + ( H W ) 2 ⋅ C ) O(HW \cdot C^2 + (HW)^2 \cdot C) O(HW⋅C2+(HW)2⋅C) 的复杂度相比,DSSA的复杂度降至 O ( H W ⋅ C 2 + k ⋅ H W ⋅ C ) O(HW \cdot C^2 + k \cdot HW \cdot C) O(HW⋅C2+k⋅HW⋅C) ( k k k 为每个查询平均关注的键数,且 k ≪ H W k \ll HW k≪HW ),可实现数十至百倍的计算加速,同时结构化稀疏设计能够保留医学影像的拓扑与语义一致性,有效屏蔽超声噪声与伪影,精准聚焦目标解剖结构,兼顾了分割精度与实时性,适配临床超声分割的实际应用需求。
核心代码
class nchwDSSA(nn.Module):
def __init__(self, dim, num_heads=8, n_win=7, qk_scale=None, topk=4, side_dwconv=3, auto_pad=False, attn_backend='torch'):
super().__init__()
# local attention setting
self.dim = dim
self.a_r = None
self.idx_r = None
self.num_heads = num_heads
assert self.dim % num_heads == 0, 'dim must be divisible by num_heads!'
self.head_dim = self.dim // self.num_heads
self.scale = qk_scale or self.dim ** -0.5 # NOTE: to be consistent with old models.
################side_dwconv (i.e. LCE in Shunted Transformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ regional routing setting #################
self.topk = topk
self.n_win = n_win # number of windows per row/col
##########################################
self.qkv_linear = nn.Conv2d(self.dim, 3*self.dim, kernel_size=1)
self.output_linear = nn.Conv2d(self.dim, self.dim, kernel_size=1)
if attn_backend == 'torch':
self.attn_fn = regional_routing_attention_torch
else:
raise ValueError('CUDA implementation is not available yet. Please stay tuned.')
def forward(self, x:Tensor, ret_attn_mask=False):
"""
Args:
x: NCHW tensor, better to be channel_last (https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html)
Return:
NCHW tensor
"""
x = x.permute(0, 3, 1, 2)
N, C, H, W = x.size()
region_size = (H//self.n_win, W//self.n_win)
# STEP 1: linear projection
qkv = self.qkv_linear.forward(x) # ncHW
q, k, v = qkv.chunk(3, dim=1) # ncHW
# STEP 2: region-to-region routing
# NOTE: ceil_mode=True, count_include_pad=False = auto padding
# NOTE: gradients backward through token-to-token attention. See Appendix A for the intuition.
q_r = F.avg_pool2d(q.detach(), kernel_size=region_size, ceil_mode=True, count_include_pad=False)
k_r = F.avg_pool2d(k.detach(), kernel_size=region_size, ceil_mode=True, count_include_pad=False) # nchw
q_r:Tensor = q_r.permute(0, 2, 3, 1).flatten(1, 2) # n(hw)c
k_r:Tensor = k_r.flatten(2, 3) # nc(hw)
a_r = q_r @ k_r # n(hw)(hw), adj matrix of regional graph
_, idx_r = torch.topk(a_r, k=self.topk, dim=-1) # n(hw)k long tensor
idx_r:LongTensor = idx_r.unsqueeze_(1).expand(-1, self.num_heads, -1, -1)
# STEP 3: token to token attention (non-parametric function)
output, attn_mat = self.attn_fn(query=q, key=k, value=v, scale=self.scale,
region_graph=idx_r, region_size=region_size
)
output = output + self.lepe(v) # ncHW
output = self.output_linear(output) # ncHW
output = output.permute(0, 2, 3, 1) # ncHW->nHWc
if ret_attn_mask:
return output, attn_mat
return output
YOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 DSSA.py为文件名的py文件, 把代码拷贝进去。
"""
Regional Routing Scaled Dot-product Attention (based on pytorch API)
author: ZHU Lei
github: https://github.com/rayleizhu
email: ray.leizhu@outlook.com
This source code is licensed under the license found in the
LICENSE file in the root directory of this source tree.
"""
import time
import torch
from torch import Tensor, LongTensor
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional, Tuple
attn_test = []
def _grid2seq(x: Tensor, region_size: Tuple[int], num_heads: int):
"""
Args:
x: BCHW tensor
region size: int
num_heads: number of attention heads
Return:
out: rearranged x, has a shape of (bs, nhead, nregion, reg_size, head_dim)
region_h, region_w: number of regions per col/row
"""
B, C, H, W = x.size()
region_h, region_w = H // region_size[0], W // region_size[1]
x = x.view(B, num_heads, C // num_heads, region_h, region_size[0], region_w, region_size[1])
x = torch.einsum('bmdhpwq->bmhwpqd', x).flatten(2, 3).flatten(-3, -2) # (bs, nhead, nregion, reg_size, head_dim)
return x, region_h, region_w
def _seq2grid(x: Tensor, region_h: int, region_w: int, region_size: Tuple[int]):
"""
Args:
x: (bs, nhead, nregion, reg_size^2, head_dim)
Return:
x: (bs, C, H, W)
"""
bs, nhead, nregion, reg_size_square, head_dim = x.size()
x = x.view(bs, nhead, region_h, region_w, region_size[0], region_size[1], head_dim)
x = torch.einsum('bmhwpqd->bmdhpwq', x).reshape(bs, nhead * head_dim,
region_h * region_size[0], region_w * region_size[1])
return x
def regional_routing_attention_torch(
query: Tensor, key: Tensor, value: Tensor, scale: float,
region_graph: LongTensor, region_size: Tuple[int],
kv_region_size: Optional[Tuple[int]] = None,
auto_pad=True) -> Tensor:
kv_region_size = kv_region_size or region_size
bs, nhead, q_nregion, topk = region_graph.size()
# Auto pad to deal with any input size
q_pad_b, q_pad_r, kv_pad_b, kv_pad_r = 0, 0, 0, 0
if auto_pad:
_, _, Hq, Wq = query.size()
q_pad_b = (region_size[0] - Hq % region_size[0]) % region_size[0]
q_pad_r = (region_size[1] - Wq % region_size[1]) % region_size[1]
if (q_pad_b > 0 or q_pad_r > 0):
query = F.pad(query, (0, q_pad_r, 0, q_pad_b)) # zero padding
_, _, Hk, Wk = key.size()
kv_pad_b = (kv_region_size[0] - Hk % kv_region_size[0]) % kv_region_size[0]
kv_pad_r = (kv_region_size[1] - Wk % kv_region_size[1]) % kv_region_size[1]
if (kv_pad_r > 0 or kv_pad_b > 0):
key = F.pad(key, (0, kv_pad_r, 0, kv_pad_b)) # zero padding
value = F.pad(value, (0, kv_pad_r, 0, kv_pad_b)) # zero padding
# to sequence format, i.e. (bs, nhead, nregion, reg_size, head_dim)
query, q_region_h, q_region_w = _grid2seq(query, region_size=region_size, num_heads=nhead)
key, _, _ = _grid2seq(key, region_size=kv_region_size, num_heads=nhead)
value, _, _ = _grid2seq(value, region_size=kv_region_size, num_heads=nhead)
# gather key and values.
# TODO: is seperate gathering slower than fused one (our old version) ?
# torch.gather does not support broadcasting, hence we do it manually
bs, nhead, kv_nregion, kv_region_size, head_dim = key.size()
broadcasted_region_graph = region_graph.view(bs, nhead, q_nregion, topk, 1, 1). \
expand(-1, -1, -1, -1, kv_region_size, head_dim)
key_g = torch.gather(key.view(bs, nhead, 1, kv_nregion, kv_region_size, head_dim). \
expand(-1, -1, query.size(2), -1, -1, -1), dim=3,
index=broadcasted_region_graph) # (bs, nhead, q_nregion, topk, kv_region_size, head_dim)
value_g = torch.gather(value.view(bs, nhead, 1, kv_nregion, kv_region_size, head_dim). \
expand(-1, -1, query.size(2), -1, -1, -1), dim=3,
index=broadcasted_region_graph) # (bs, nhead, q_nregion, topk, kv_region_size, head_dim)
# token-to-token attention
# (bs, nhead, q_nregion, reg_size, head_dim) @ (bs, nhead, q_nregion, head_dim, topk*kv_region_size)
# -> (bs, nhead, q_nregion, reg_size, topk*kv_region_size)
# TODO: mask padding region
attn = (query * scale) @ key_g.flatten(-3, -2).transpose(-1, -2)
score, index = attn.topk(topk * kv_region_size // 8, dim=-1)
v_g_un = value_g.flatten(-3, -2).unsqueeze(-3).expand(-1, -1, -1, attn.size(3), -1, -1)
idx = index.unsqueeze(-1).expand(-1, -1, -1, -1, -1, head_dim)
v_g_select = torch.gather(v_g_un, dim=4, index=idx)
a_g = score.unsqueeze(-2)
a_g = torch.softmax(a_g, dim=-1)
output = (a_g @ v_g_select).squeeze(-2)
# to BCHW format
output = _seq2grid(output, region_h=q_region_h, region_w=q_region_w, region_size=region_size)
# remove paddings if needed
if auto_pad and (q_pad_b > 0 or q_pad_r > 0):
output = output[:, :, :Hq, :Wq]
return output, attn
class DSSA(nn.Module):
def __init__(self, dim, num_heads=8, n_win=7, qk_scale=None, topk=4, side_dwconv=3, auto_pad=False, attn_backend='torch'):
super().__init__()
# local attention setting
self.dim = dim
self.a_r = None
self.idx_r = None
self.num_heads = num_heads
assert self.dim % num_heads == 0, 'dim must be divisible by num_heads!'
self.head_dim = self.dim // self.num_heads
self.scale = qk_scale or self.dim ** -0.5 # NOTE: to be consistent with old models.
################side_dwconv (i.e. LCE in Shunted Transformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ regional routing setting #################
self.topk = topk
self.n_win = n_win # number of windows per row/col
##########################################
self.qkv_linear = nn.Conv2d(self.dim, 3*self.dim, kernel_size=1)
self.output_linear = nn.Conv2d(self.dim, self.dim, kernel_size=1)
if attn_backend == 'torch':
self.attn_fn = regional_routing_attention_torch
else:
raise ValueError('CUDA implementation is not available yet. Please stay tuned.')
def forward(self, x:Tensor, ret_attn_mask=False):
"""
Args:
x: NCHW tensor
Return:
NCHW tensor
"""
N, C, H, W = x.size()
region_size = (max(1, H//self.n_win), max(1, W//self.n_win))
# STEP 1: linear projection
qkv = self.qkv_linear(x) # ncHW
q, k, v = qkv.chunk(3, dim=1) # ncHW
# STEP 2: region-to-region routing
# NOTE: ceil_mode=True, count_include_pad=False = auto padding
# NOTE: gradients backward through token-to-token attention. See Appendix A for the intuition.
q_r = F.avg_pool2d(q.detach(), kernel_size=region_size, ceil_mode=True, count_include_pad=False)
k_r = F.avg_pool2d(k.detach(), kernel_size=region_size, ceil_mode=True, count_include_pad=False) # nchw
q_r = q_r.permute(0, 2, 3, 1).flatten(1, 2) # n(hw)c
k_r = k_r.flatten(2, 3) # nc(hw)
a_r = q_r @ k_r # n(hw)(hw), adj matrix of regional graph
_, idx_r = torch.topk(a_r, k=self.topk, dim=-1) # n(hw)k long tensor
idx_r = idx_r.unsqueeze_(1).expand(-1, self.num_heads, -1, -1)
# STEP 3: token to token attention (non-parametric function)
output, attn_mat = self.attn_fn(query=q, key=k, value=v, scale=self.scale,
region_graph=idx_r, region_size=region_size
)
output = output + self.lepe(v) # ncHW
output = self.output_linear(output) # ncHW
if ret_attn_mask:
return output, attn_mat
return output
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.DSSA import DSSA
步骤2
修改def parse_model(d, ch, verbose=True):
elif m is DSSA:
args = [ch[f], *args]
配置yolo11-DSSA.yaml
ultralytics\cfg\models\11\yolo11-DSSA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 8 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, DSSA, []]
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, DSSA, []]
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [-1, 1, DSSA, []]
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/11/yolo11-DSSA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='DSSA',
)
结果
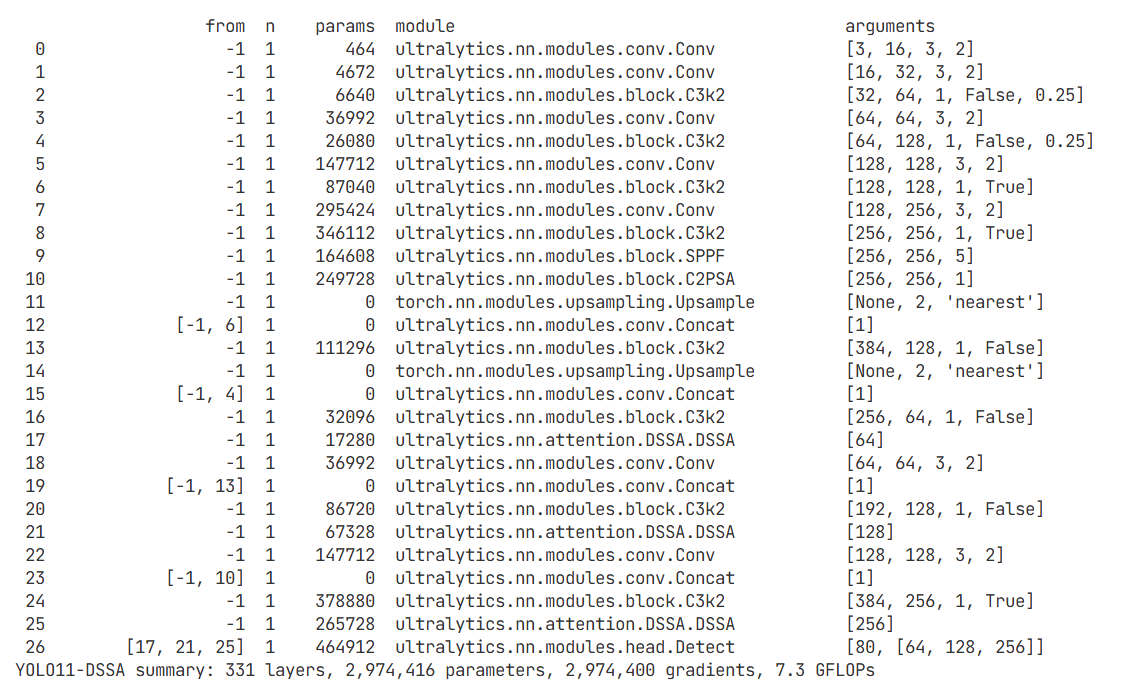

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)