第1关:朴素贝叶斯概论
任务描述
本关任务:了解朴素贝叶斯的基本概念,完成右侧窗口内的单项选择题。
相关知识
概率的解释
现在我们站在两个统计学派的角度来深入理解什么是概率。 经典统计学认为概率表述的是一件事发生的频率,概率定义为频率的极限,或者说这叫作客观概率。如抛硬币试验时通过大量试验,发现结果基本是一半正面一半反面,因此认为正反面的概率都是 0.5,这体现了经典统计学的思想,概率是基于大量实验而得到。 但现实中有些事情我们没办法进行试验,例如今天下雨的概率 50%,某城市下个月发生地震的概率 30%,这些我们无法通过试验来验证。 贝叶斯框架下的概率理论虽然认可经典统计学的概率定义,但它同时把概率理解为人对随机事件发生可能性的一种信念,他认为概率是个人的主观概念,即主观概率,表明我们对某个事物发生的相信程度。两种对于概率的认识区分了经典统计学派(也称频率学派)和贝叶斯学派。 贝叶斯学派与经典统计学派的争论 仅仅基于总体信息和样本信息进行统计推断的统计学理论与方法称为经典统计学。经典统计学认为只要进行足够多次的试验,就能推断出隐藏在数据背后的规律,人们完全可以通过直接研究这些样本来推断总体的分布规律 。 贝叶斯学派认为任意未知量 都可以看作一个随机变量, 可以用一个概率分布去描述 的未知状况,并且这个概率最初可以通过主观经验设置。频率学派对此无法接受,他们认为参数应该是一个确定的值而不应该具有随机性。 在人们认识事物不全面的情况下,贝叶斯方法是一种很好的利用经验帮助做出更合理判断的方法,至少把概率与统计的研究与应用范围扩大到无法进行大量重复实验的问题中。当然主观概率的确定不是随意的,而是要求当事人对所考察的事件有透彻的了解和丰富的经验,甚至是这一行的专家。 贝叶斯学派和经典统计学派没有好坏之分,关键在于统计方法是否适合该问题的应用场景。数据科学不是偏袒某一方, 而是为了找出工作的最佳工具,能否解决实际问题是衡量统计方法优劣的标准,以往的实践证明两个统计学派在各自的应用领域的表现都不错,各有其适用的范围。
贝叶斯方法
贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。由于其有着坚实的数学基础,贝叶斯分类算法的误判率是很低的。贝叶斯方法的特点是结合先验概率和后验概率,即避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象。贝叶斯分类算法在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。 朴素贝叶斯算法 朴素贝叶斯算法是应用最为广泛的分类算法之一。朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。 优点:朴素贝叶斯算法假设了数据集属性之间是相互独立的,因此算法的逻辑性十分简单,并且算法较为稳定,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异。当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。 缺点:属性独立性的条件同时也是朴素贝叶斯分类器的不足之处。数据集属性的独立性在很多情况下是很难满足的,因为数据集的属性之间往往都存在着相互关联,如果在分类过程中出现这种问题,会导致分类的效果大大降低。
测试说明 完成右侧窗口内的单项选择题,平台会对你的结果进行测试。 开始你的任务吧,祝你成功!



第1关:朴素贝叶斯分类算法流程




import numpy as np
class NaiveBayesClassifier(object):
def __init__(self):
'''
self.label_prob表示每种类别在数据中出现的概率
例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667
'''
self.label_prob = {}
'''
self.condition_prob表示每种类别确定的条件下各个特征出现的概率
例如训练数据集中的特征为 [[2, 1, 1],
[1, 2, 2],
[2, 2, 2],
[2, 1, 2],
[1, 2, 3]]
标签为[1, 0, 1, 0, 1]
那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0;
当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333;
因此self.label_prob的值如下:
{
0:{
0:{
1:0.5
2:0.5
}
1:{
1:0.5
2:0.5
}
2:{
1:0
2:1
3:0
}
}
1:
{
0:{
1:0.333
2:0.666
}
1:{
1:0.333
2:0.666
}
2:{
1:0.333
2:0.333
3:0.333
}
}
}
'''
self.condition_prob = {}
def fit(self, feature, label):
'''
对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: 无返回
'''
#********* Begin *********#
row_num=len(feature)
col_num=len(feature[0])
for c in label:
if c in self.label_prob:
self.label_prob[c]+=1
else:
self.label_prob[c]=1;
for key in self.label_prob.keys():
self.label_prob[key]/=row_num
self.condition_prob[key]={}
for i in range(col_num):
self.condition_prob[key][i]={}
for k in np.unique(feature[:,i],axis=0):
self.condition_prob[key][i][k]=0
for i in range(len(feature)):
for j in range(len(feature[i])):
if feature[i][j] in self.condition_prob[label[i]]:
self.condition_prob[label[i]][j][feature[i][j]]+=1
else:
self.condition_prob[label[i]][j][feature[i][j]]=1
for label_key in self.condition_prob.keys():
for k in self.condition_prob[label_key].keys():
total=0
for v in self.condition_prob[label_key][k].values():
total +=v
for kk in self.condition_prob[label_key][k].keys():
self.condition_prob[label_key][k][kk] /=total
#********* End *********#
def predict(self, feature):
'''
对数据进行预测,返回预测结果
:param feature:测试数据集所有特征组成的ndarray
:return:
'''
# ********* Begin *********#
result =[]
for i,f in enumerate(feature):
prob=np.zeros(len(self.label_prob.keys()))
ii=0
for label,label_prob in self.label_prob.items():
prob[ii]=label_prob
for j in range(len(feature[0])):
prob[ii] *= self.condition_prob[label][j][f[j]]
ii+=1
result.append(list(self.label_prob.keys())[np.argmax(prob)])
return np.array(result)
#********* End *********#
第1关:利用sklearn构建朴素贝叶斯模型
任务描述
本关任务:
编写一个使用贝叶斯分类器完成垃圾邮件分类的程序。 相关知识 为了完成本关任务,你需要掌握:1.朴素贝叶斯模型,2.使用sklearn构建朴素贝叶斯分类器。
朴素贝叶斯模型
贝叶斯方法是一种生成式分类模型,这是一种从概率论上延伸出来的方法。在概率论与统计学中,贝叶斯定理表达了一个事件发生的概率,而确定这一概率的方法是基于与该事件相关的条件先验知识。而利用相应先验知识进行概率推断的过程为贝叶斯推断。
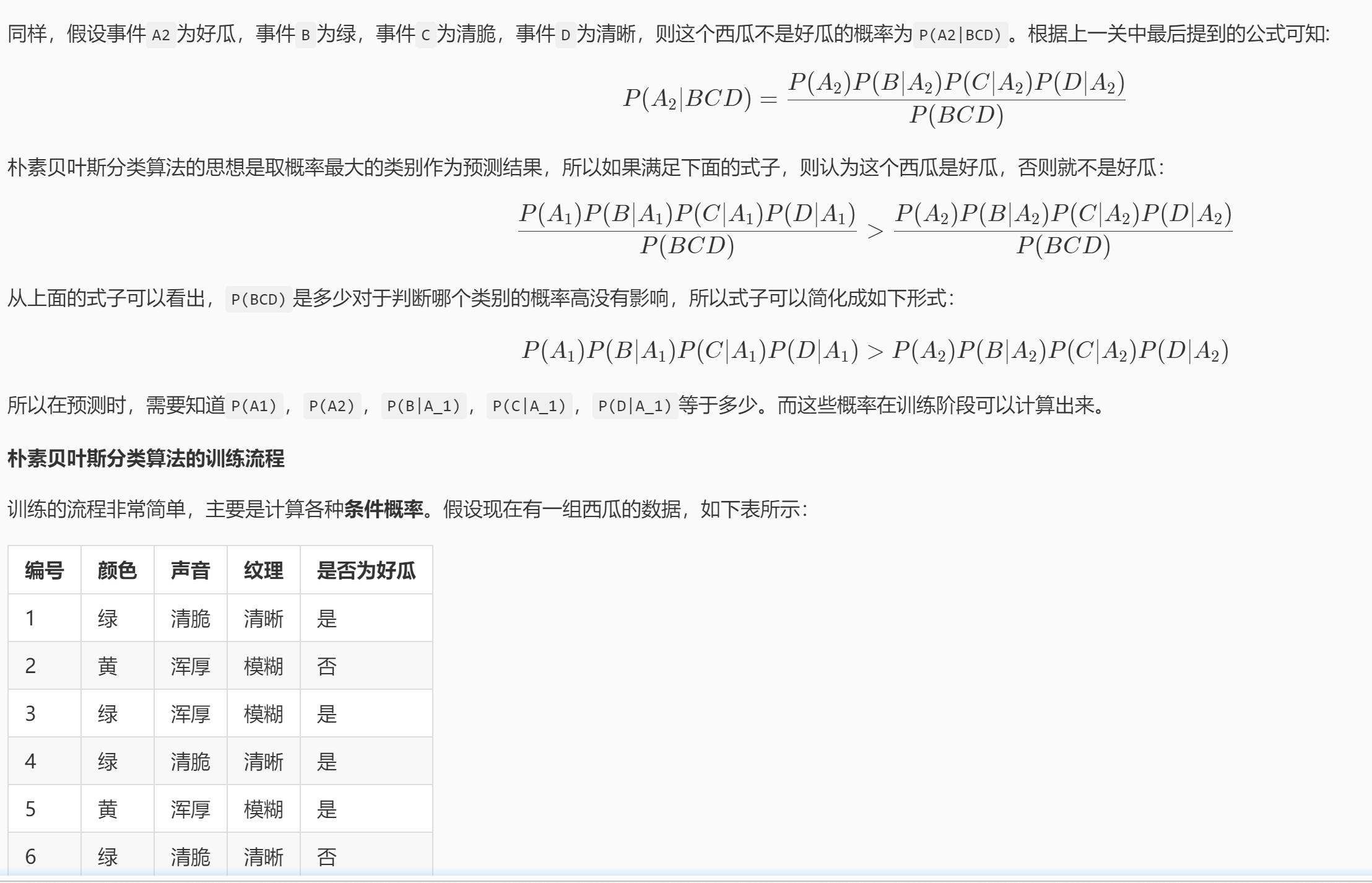
条件概率是指在事件 B 发生的情况下,事件 A 发生的概率。通常记为 P(A | B):
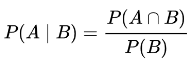
又由
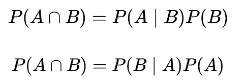
可以得到贝叶斯公式:
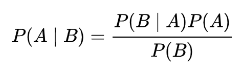
贝叶斯公式中,P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估。 P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。 所以,条件概率可以理解成下面的式子:后验概率=先验概率 x 调整因子 这就是贝叶斯推断的含义。
我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
因为在分类中,只需要找出可能性最大的那个选项,而不需要知道具体那个类别的概率是多少,所以为了减少计算量,全概率公式在实际编程中可以不使用。
而朴素贝叶斯推断,是在贝叶斯推断的基础上,对条件概率分布做了条件独立性的假设。因此可得朴素贝叶斯分类器的表达式。
因为以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,会导致算法精度在某种程度上受影响。
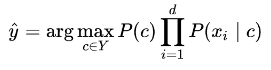
实际在机器学习的分类问题的应用中,朴素贝叶斯分类器的训练过程就是基于训练集 D 来估计类先验概率 P(c) ,并为每个属性估计条件概率 P(xi | c) 。
这里就需要使用极大似然估计 (maximum likelihood estimation, 简称 MLE) 来估计相应的概率。
令 Dc 表示训练集 D 中的第 c 类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类别的先验概率:
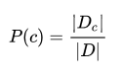
对于离散属性而言,令 Dc,xi 表示 Dc 中在第 i 个属性上取值为 xi 的样本组成的集合,则条件概率 P(xi | c) 可估计为:
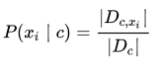
对于连续属性可考虑概率密度函数,假定 ![]() ,μ和sigma分别是第 c 类样本在第 i 个属性上取值的均值和方差,则有:
,μ和sigma分别是第 c 类样本在第 i 个属性上取值的均值和方差,则有:
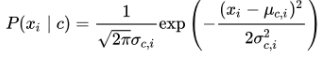
综上,贝叶斯分类器的实现流程如下:
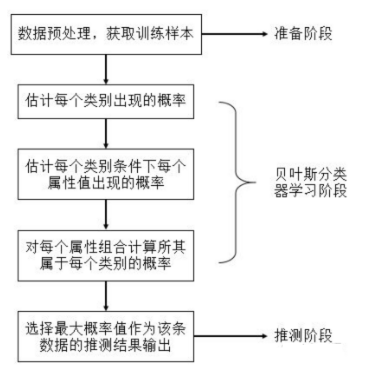
数据集的介绍 我们来了解一下我们的数据,从而明确任务,并作出针对性的分析。
垃圾邮件数据集是一个分类问题,目的是区分当前的邮件是否为无用的垃圾邮件,在数据集中每个邮件都给出了标签: ham或spam 对应正常邮件或垃圾邮件;除此之外,数据集还包含有该邮件的完整内容,这对应于我们想要利用的特征;特征与标签的表示如下: • Label: 标签; • Text: 邮件的内容。 从上述对数据的说明,我们可以看到得到这样的几个问题: 1. Text是完整的一段话,想要利用其中的信息,我们先要进行处理; 2. Label是字符型的,训练使用时要进行转化。 下面我们考虑对特征进行处理,要将text中的句子转化为我们可以利用的特征,整个过程包括以下几步:
step1. 分词:将段落切分为一个个的单词;
step2. 生成词汇表:使用切分好的单词组建一个词库;
step3. 生成词向量:根据词库,使用数值建立段落与词库的映射表示。 这里使用 sklearn 的函数 sklearn.feature_extraction.text.TfidfVectorizer 进行转换:
关键代码如下:
1.import numpy as np
2. import pandas as pd
3. from sklearn.feature_extraction.text import TfidfVectorizer
4. from sklearn.naive_bayes import MultinomialNB
5. from sklearn.model_selection import train_test_split
7. data_path ='/data/bigfiles/5297379b-7cd5-4239-bcac-e2d361753393'
8. df = pd.read_csv(data_path, delimiter='\t',header=None)
10. # 将label编码
11. df[0] = df[0].replace(to_replace=['spam', 'ham'], value=[0, 1])
13. # 完成数据划分及词向量的转化
14. X = df[1].values
15. y = df[0].values
16. X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y)
17. vectorizer = TfidfVectorizer()
18. x_train = vectorizer.fit_transform(X_train_raw) 19. x_test = vectorizer.transform(X_test_raw)
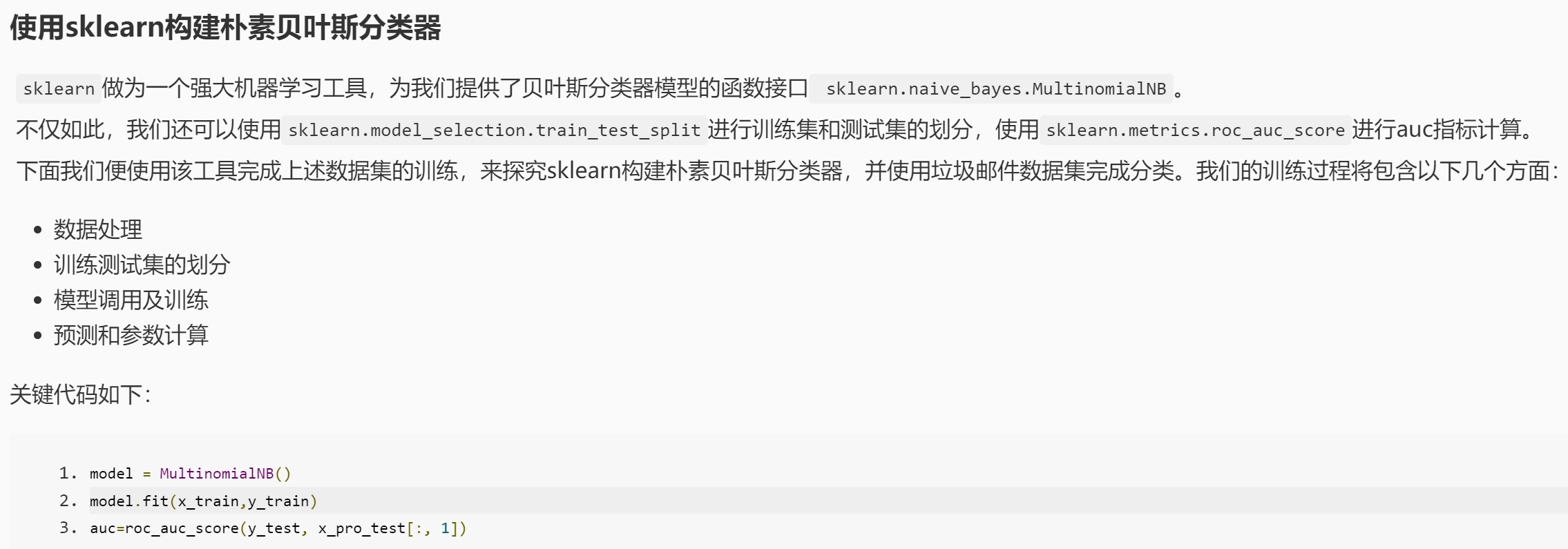
编程要求
根据提示,在右侧编辑器补充代码,完成使用sklearn构建朴素贝叶斯分类器,包括:
1. 数据处理;
2. 训练测试集的划分;
3. 模型训练;
4. 测试数据预测和AUC计算;
5. 打印AUC。 测试说明 平台会对你编写的代码进行测试:
预期输出:
提示:
参照示例完成任务
开始你的任务吧,祝你成功!
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
data_path ='/data/bigfiles/5297379b-7cd5-4239-bcac-e2d361753393'
df = pd.read_csv(data_path, delimiter='\t',header=None)
######Begin ######
# 将label编码
df[0] = df[0].replace(to_replace=['spam', 'ham'], value=[0, 1])
# 完成数据划分及词向量的转化
X = df[1].values
y = df[0].values
X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y,random_state = 0)
vectorizer = TfidfVectorizer()
x_train = vectorizer.fit_transform(X_train_raw)
x_test = vectorizer.transform(X_test_raw)
# 构建模型及训练
model = MultinomialNB()
model.fit(x_train,y_train)
#对于测试集x_test进行预测
x_pre_test=model.predict(x_test)
x_pro_test = model.predict_proba(x_test)
#计算验证集的auc值,参数为预测值和概率估计
auc=roc_auc_score(y_test, x_pro_test[:, 1])
###### End ######
print("auc的值:{}".format(auc))第1关:朴素贝叶斯——新闻分类
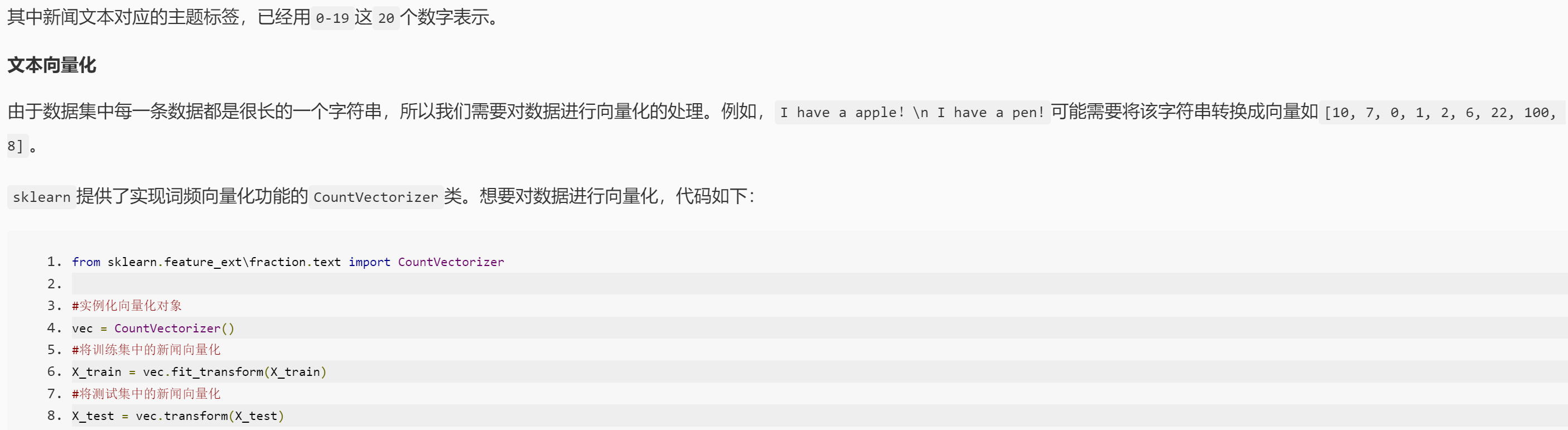
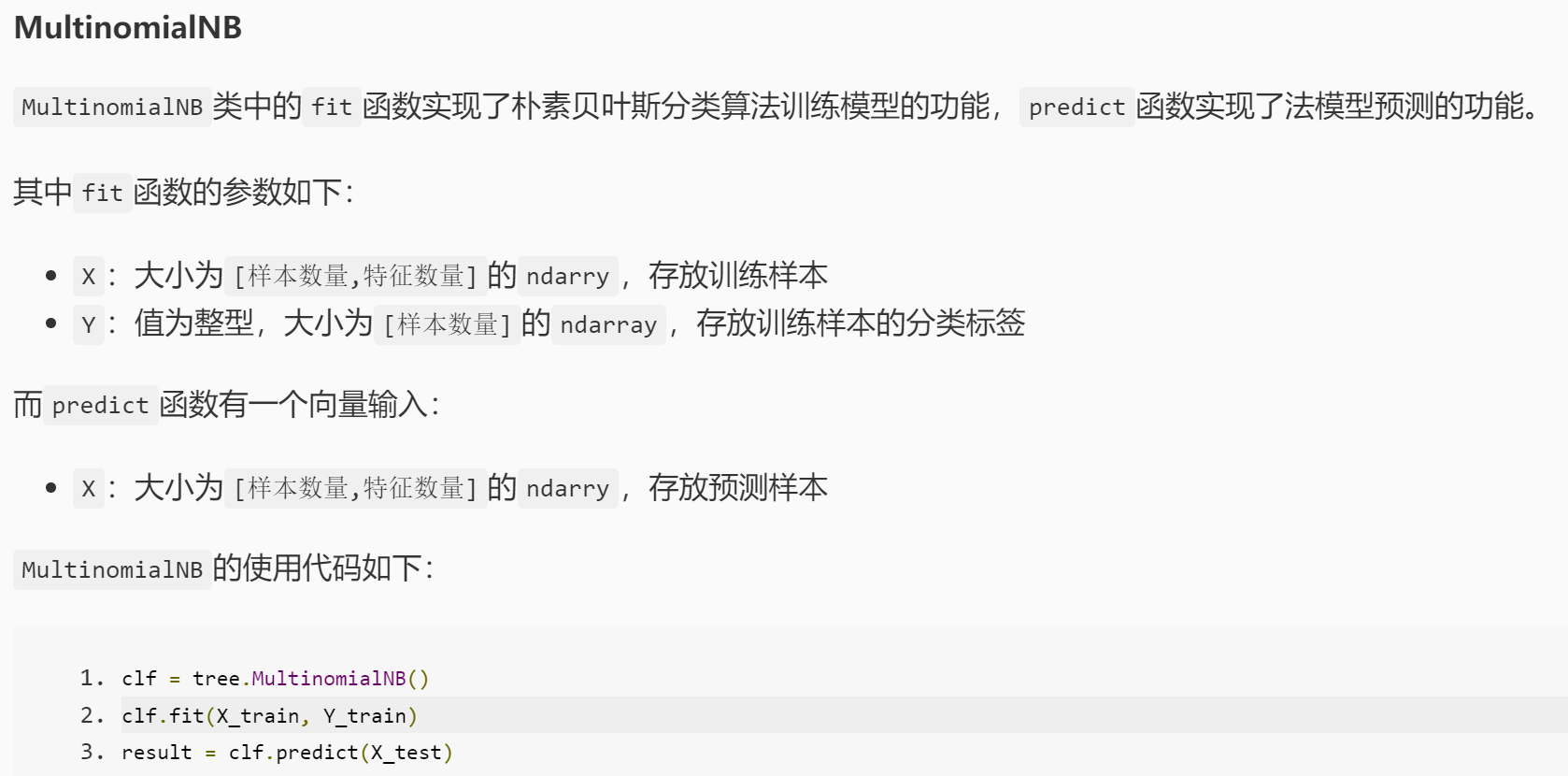

from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
def news_predict(train_sample, train_label, test_sample):
'''
训练模型并进行预测,返回预测结果
:param train_sample:原始训练集中的新闻文本,类型为ndarray
:param train_label:训练集中新闻文本对应的主题标签,类型为ndarray
:param test_sample:原始测试集中的新闻文本,类型为ndarray
:return 预测结果,类型为ndarray
'''
#********* Begin *********#
vec=CountVectorizer()
train_sample=vec.fit_transform(train_sample)
test_sample=vec.transform(test_sample)
tfidf=TfidfTransformer()
train_sample =tfidf.fit_transform(train_sample)
test_sample=tfidf.transform(test_sample)
mnb=MultinomialNB(alpha=0.01)
mnb.fit(train_sample,train_label)
predict=mnb.predict(test_sample)
return predict
#********* End *********#

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)