Claude Code都在用!扔掉向量数据库,这个开源项目让RAG准确率飙到98.7%
你还在为向量检索"查了个寂寞"而抓狂吗?PageIndex 用一招"像人一样翻目录",干掉了整个 Embedding + 向量数据库的技术栈。

先说痛点:你的 RAG 系统是不是也这样?
做过企业级文档问答系统的人,一定经历过这种崩溃:
- 用户问"2023年公司递延资产总额是多少",向量检索返回了10段"递延"相关的文本,没一段有答案
- 一份200页的财报,切成500个 chunk,embedding 后存进 Pinecone,结果关键信息正好被切成两半
- 法律文档里写着"详见附录G",向量检索根本不会帮你去翻附录G
- 审计报告问答系统上线后,准确率只有60%,业务方直接说"不如我自己Ctrl+F"
这些不是个例,而是向量 RAG 的结构性缺陷。
问题的根源在于一个被忽视了太久的事实:
语义相似 ≠ 查询相关
当你用 embedding 做检索时,你找到的是"看起来像答案"的文本,而不是"真正是答案"的文本。这在通用问答场景能凑合,但在金融、法律、审计这些差一个数字就是几个亿的专业领域,凑合不了。
PageIndex:像人类专家一样"翻目录"的 RAG
PageIndex 是 Vectify AI 开源的下一代 RAG 框架(GitHub 19.5k Star),灵感来源于 AlphaGo 的树搜索思想。它彻底抛弃了向量数据库和文本切块,转而用 LLM 推理来做检索。
核心思想只有一句话:
不做向量匹配,做推理导航。让 LLM 像人类专家一样,看着目录想一想,然后翻到正确的那一页。

它分两步完成工作:
第一步:建索引 —— 把 PDF 转化为层级树结构(类似智能目录)
第二步:做检索 —— LLM 在树结构上推理式导航,迭代定位答案
深入源码:树索引是怎么"长"出来的?
我通读了 PageIndex 的全部源码,最精彩的部分是它构建树索引的全流程——一个拥有完整自纠错机制的 pipeline:
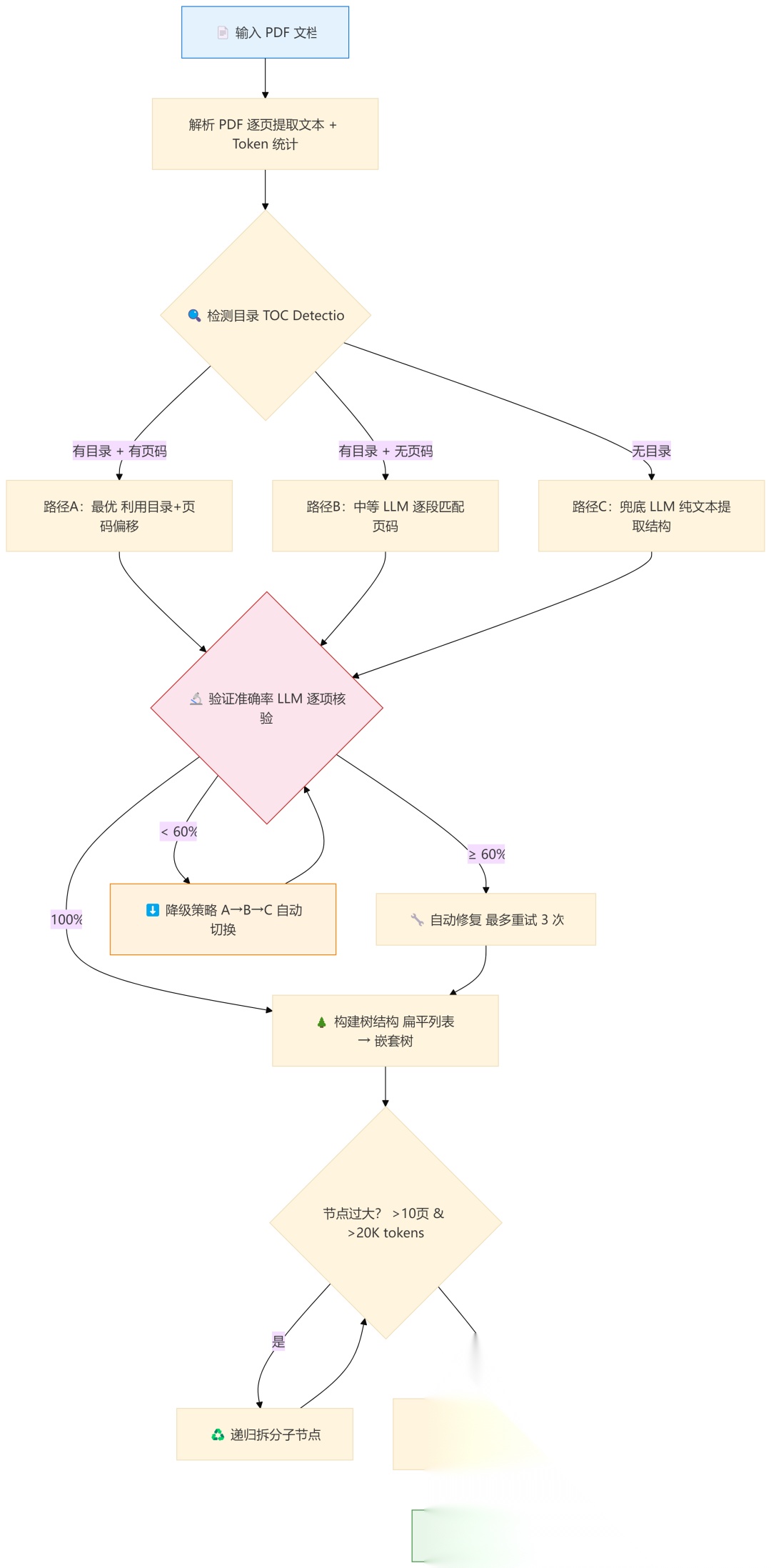
让我逐层拆解这个过程:
1. PDF 解析与 Token 统计
代码用 PyPDF2/PyMuPDF 逐页提取文本,同时用 tiktoken 计算每页 token 数。这些数据后续用于智能分组:
# utils.py - get_page_tokens()page_list = []for page in doc: page_text = page.get_text() token_length = len(enc.encode(page_text)) page_list.append((page_text, token_length))
2. 三条路径的智能检测
这是整个系统最聪明的设计。它不假设文档有目录,而是让 LLM 去探测:
- 逐页检测:前20页逐页让 LLM 判断"这一页是不是目录?"
- 连续性判断:一旦发现连续的目录页,继续往下扫;遇到非目录页就停止
- 页码检测:如果有目录,再判断目录里有没有页码
这就产生了三种处理路径,适应从"完美的正式出版物"到"随手写的内部文档"的所有场景。
3. 页码偏移量计算(路径A的精妙之处)
很多人可能没注意过:PDF 的逻辑页码和物理页码往往不一致。比如目录写"第1页",但在 PDF 里实际是第5页(因为前面有封面、目录页等)。
PageIndex 的做法极其优雅:
- 先从正文前几页中,让 LLM 识别某些章节的物理页码(通过
<physical_index_X>标签) - 和目录里的逻辑页码配对
- 统计差值的众数——这就是 offset
# 计算偏移量,取众数difference_counts = {}for diff in differences: difference_counts[diff] = difference_counts.get(diff, 0) + 1most_common = max(difference_counts.items(), key=lambda x: x[1])[0]
4. 自纠错机制:验证→修复→降级
这是我最欣赏的工程设计。生成目录后不是直接用,而是有一个完整的验证-修复-降级闭环:
| 准确率 | 动作 |
|---|---|
| 100% | 直接通过 ✅ |
| ≥ 60% | 自动修复错误项(最多3轮) 🔧 |
| < 60% | 自动降级到下一条路径 ⬇️ |
验证方式:让 LLM 检查"这个标题是否真的出现在标注的那一页"。修复方式:在前后正确项的页码范围内重新搜索。降级路径:A → B → C。
这意味着即使 PDF 格式混乱、目录残缺,系统也能兜底。
5. 大节点递归拆分
如果某个章节超过 10 页或 20000 tokens,系统会对它递归执行一次完整的"无目录"流程,给它拆出子结构。这确保了最终树的每个叶子节点都足够精细。
检索阶段:LLM 如何在树上"推理式导航"?
拿一个真实案例说明——查询 “联储的递延资产总额是多少”:

注意这里的关键动作:
- LLM 读目录推理 → 选相关章节(不是匹配关键词)
- 发现信息不够 → 主动依据文档内部引用 → 跳转到附录G
- 迭代式检索,直到信息充分才回答
向量检索根本做不到第2步——因为"详见附录G"和"递延资产总额"的 embedding 相似度约等于零。
真实输出长什么样?
以迪士尼2025年Q1财报为例,PageIndex 生成的树索引结构:
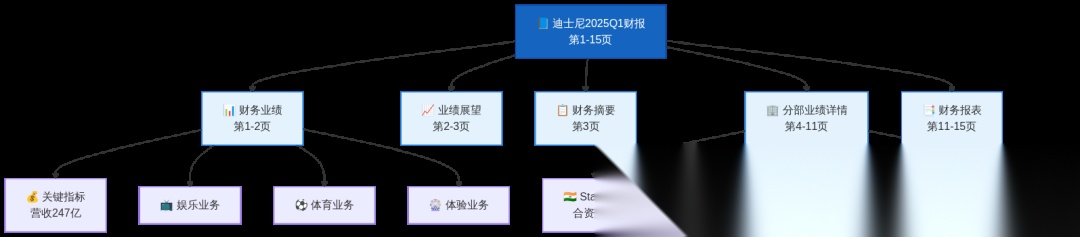
每个节点都有:
- title:章节标题
- start_index / end_index:对应 PDF 页码范围
- summary:LLM 生成的章节摘要
- node_id:唯一标识符
- nodes:子节点(递归嵌套)
你问"ESPN广告收入增长了多少",LLM 看一眼目录就知道该去"分部业绩详情→体育分部"找,而不是在500个 chunk 里碰运气。
五大痛点,逐个击破
| 传统向量 RAG 的痛点 | PageIndex 的解法 |
|---|---|
| 查询 ≠ 知识 空间不匹配 用户问的"意图"和文档的"内容"在向量空间里可能距离很远 | LLM 推理定位:“递延资产通常在财务报表章节”——用领域知识推理,不靠语义匹配 |
| 相似 ≠ 相关 金融文档里大量段落语义相似但含义完全不同 | 按结构+上下文检索完整章节,不是按"像不像"匹配碎片 |
| 硬切块破坏语义 一个表格被切成两段,关键数字和表头分家 | 保留文档原生章节结构,不做人为切割,一个节点就是一个完整段落 |
| 无法整合对话历史 上一轮问了"资产",这轮问"那负债呢?",检索器不知道 | 推理过程感知上下文,知道应该在同一份报告的相邻章节找 |
| 无法跟踪文内引用 “详见附录G”,向量检索不会帮你翻过去 | LLM 直接在树索引中导航跳转到被引用的章节 |
竞争力分析:为什么不是又一个 RAG 轮子?
1. 零基础设施依赖
传统 RAG 需要:Embedding 模型 + 向量数据库 + 分块策略调优 + 重排序模型……
PageIndex 只需要:一个 OpenAI API Key。
没有 Pinecone 账单,没有 Milvus 运维,没有 chunk size 的玄学调参。对中小团队来说,这是巨大的降本。
2. FinanceBench 98.7% SOTA
这不是 demo 数据集上的自嗨。FinanceBench 是金融领域权威的文档 QA 基准测试,包含真实的 SEC 财报问答。98.7% 的准确率显著超过所有向量 RAG 方案。
3. 可解释、可审计
每个答案都可以追溯到具体的页码和章节。在金融合规、法律审查等场景,"答案从哪来的"比"答案是什么"更重要。向量 RAG 的 top_k=5 返回的来源往往是黑盒。
4. Claude Code 同源思路
值得注意的是,Anthropic 的 Claude Code 也已经放弃了向量 RAG,转而使用类似的推理式 agentic 检索来查找代码。这不是巧合——是行业在向"推理替代匹配"的范式转移。
5. 多种部署方式
| 方式 | 适合谁 |
|---|---|
| 开源自部署(本仓库) | 有技术能力的团队,完全掌控数据 |
| Chat 平台 | 快速体验,类 ChatGPT 交互 |
| MCP / API | 集成到现有系统,接入 Claude/Cursor 等 |
| 企业私有部署 | 数据不出域的合规场景 |
上手体验
安装
git clone https://github.com/VectifyAI/PageIndex.gitcd PageIndexpip3 install --upgrade -r requirements.txt
配置
创建 .env 文件:
CHATGPT_API_KEY=your_openai_key_here
运行
# 处理 PDFpython3 run_pageindex.py --pdf_path /path/to/your/document.pdf# 处理 Markdownpython3 run_pageindex.py --md_path /path/to/your/document.md
也可以在 Python 中直接调用:
from pageindex import page_indexresult = page_index( "your_document.pdf", model="gpt-4o-2024-11-20", if_add_node_summary="yes")
输出就是一个完整的 JSON 树结构,可以直接用于下游的推理式 RAG 检索。
适用场景
- 金融分析:年报、财报、SEC 文件、招股书——差一个数字就是几个亿
- 法律合规:法规解读、合同审查、监管文件——需要精准到条款
- 学术研究:论文、教材、技术手册——需要理解章节间的逻辑关系
- 企业知识库:内部文档、技术规范——超出上下文窗口的长文档
最后
PageIndex 代表了 RAG 领域一个重要的范式转移:从"向量匹配"到"推理导航"。
就像 AlphaGo 用树搜索击败了人类棋手,PageIndex 用树搜索让 LLM 像专家一样理解文档。它不是向量 RAG 的增强版,而是一个全新的路线。
在"AI 能力越来越强,但检索还停留在余弦相似度"的今天,也许是时候重新审视 RAG 系统的基本假设了。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献184条内容
已为社区贡献184条内容

所有评论(0)