PyTorch 深度学习完全指南:从激活函数到房价预测实战
手把手教你写代码,每一行都有解释,小白也能看懂!
一、激活函数:神经元的“开关”
一句话解释:激活函数就是给神经网络加入“非线性”能力的魔法。如果没有它,无论多少层神经网络都只是在做简单的加减乘除,连 XOR(异或)问题都解决不了。
下面我们介绍三种最经典的激活函数。
1. Sigmoid:把任意实数“压”到 0 到 1 之间
数学公式:
f(x)=11+e−xf(x)=1+e−x1
这个函数做了什么:
-
当 $x$ 非常大(比如 100)时,$e^{-x}$ 接近 0,所以 $f(x)$ 接近 1。
-
当 $x$ 非常小(比如 -100)时,$e^{-x}$ 巨大,所以 $f(x)$ 接近 0。
-
当 $x=0$ 时,$f(0)=0.5$。
优缺点:
-
✅ 输出范围有限,数据传递时不会爆炸。适合二分类的输出层(输出可以解释为“属于类别 1 的概率”)。
-
❌ 梯度饱和:当 $x$ 很大或很小时,导数几乎为 0,导致深层网络的参数几乎不更新,这叫“梯度消失”。
-
❌ 输出不是零中心:所有输出都是正数,这可能导致梯度更新时走“之”字形,收敛变慢。
代码示例:画出 Sigmoid 及其导数
下面这段代码会生成 Sigmoid 函数图像和它的导数图像,让你直观看到“梯度消失”发生在哪里。
import torch
import matplotlib.pyplot as plt
# 设置中文字体,让图表中的中文正常显示(Windows 用 SimHei,Mac 可用 "Arial Unicode MS")
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示为方块的问题
# 生成输入数据:从 -10 到 10 均匀取 1000 个点,并开启梯度追踪
# requires_grad=True 表示 PyTorch 会自动计算这些点上的导数
x = torch.linspace(-10, 10, 1000, requires_grad=True)
# 创建 1 行 2 列的子图(即左右并排的两张图),整体尺寸 12x4 英寸
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# ========== 左图:Sigmoid 函数 ==========
y = torch.sigmoid(x) # 计算每个 x 对应的 Sigmoid 值
axes[0].plot(x.detach().numpy(), y.detach().numpy(), color="purple", linewidth=2)
axes[0].set_title("Sigmoid 函数", fontsize=14)
# 去掉上、右边框,让坐标轴更清爽
axes[0].spines["top"].set_visible(False)
axes[0].spines["right"].set_visible(False)
# 将左、下边框移动到 (0,0) 位置
axes[0].spines["left"].set_position("zero")
axes[0].spines["bottom"].set_position("zero")
# 添加几条水平参考线
axes[0].axhline(0.5, color="gray", linestyle="--", alpha=0.7) # y=0.5
axes[0].axhline(1.0, color="gray", linestyle="--", alpha=0.7) # y=1.0
axes[0].axhline(0.0, color="gray", linestyle="--", alpha=0.7) # y=0.0
axes[0].set_xlim(-10, 10)
axes[0].set_ylim(-0.1, 1.1)
# ========== 右图:Sigmoid 的导数 ==========
# 对 Sigmoid 的结果求和,然后反向传播。PyTorch 会自动计算出每个 x 上的梯度(导数)
torch.sigmoid(x).sum().backward()
axes[1].plot(x.detach().numpy(), x.grad.numpy(), color="purple", linewidth=2)
axes[1].set_title("Sigmoid 的导数", fontsize=14)
axes[1].spines["top"].set_visible(False)
axes[1].spines["right"].set_visible(False)
axes[1].spines["left"].set_position("zero")
axes[1].spines["bottom"].set_position("zero")
axes[1].set_ylim(0, 0.3) # 把 y 轴范围限制在 0~0.3,更容易看到梯度接近 0 的区域
axes[1].set_xlim(-10, 10)
plt.tight_layout() # 自动调整子图间距
plt.show()运行结果解读:
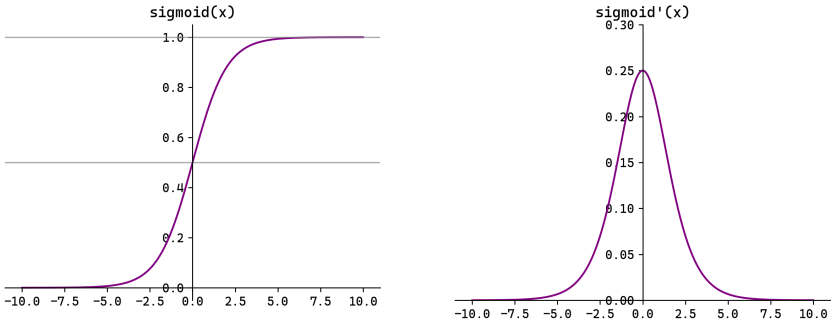
你会看到左图的 Sigmoid 曲线像一条 S 形,右图的导数像一个“小山坡”,峰值在 x=0 处只有 0.25,当 x 小于 -5 或大于 5 时,导数几乎为 0。这就是“梯度饱和”。
2. Tanh:零中心的 Sigmoid 改进版
数学公式:
f(x)=1−e−2x1+e−2xf(x)=1+e−2x1−e−2x
它和 Sigmoid 的关系:Tanh 其实就是 Sigmoid 的平移和缩放:$\tanh(x) = 2 \cdot \text{sigmoid}(2x) - 1$。所以它的输出范围是 $(-1, 1)$,均值是 0。
优缺点:
-
✅ 输出是零中心的,这比 Sigmoid 好,因为下一层神经元接收到的输入有正有负,梯度更新更高效。
-
❌ 仍然有梯度饱和问题,在深层网络中梯度还是可能消失。
代码示例:Tanh 及其导数
import torch
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# Tanh 在 [-5, 5] 区间已经饱和,所以不用取到 ±10
x = torch.linspace(-5, 5, 1000, requires_grad=True)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 左图:Tanh 函数
y = torch.tanh(x)
axes[0].plot(x.detach().numpy(), y.detach().numpy(), color="purple", linewidth=2)
axes[0].set_title("Tanh 函数", fontsize=14)
axes[0].spines["top"].set_visible(False)
axes[0].spines["right"].set_visible(False)
axes[0].spines["left"].set_position("zero")
axes[0].spines["bottom"].set_position("zero")
axes[0].axhline(-1, color="gray", linestyle="--", alpha=0.7)
axes[0].axhline(1, color="gray", linestyle="--", alpha=0.7)
axes[0].set_xlim(-5, 5)
axes[0].set_ylim(-1.2, 1.2)
# 右图:Tanh 的导数
torch.tanh(x).sum().backward()
axes[1].plot(x.detach().numpy(), x.grad.numpy(), color="purple", linewidth=2)
axes[1].set_title("Tanh 的导数", fontsize=14)
axes[1].spines["top"].set_visible(False)
axes[1].spines["right"].set_visible(False)
axes[1].spines["left"].set_position("zero")
axes[1].spines["bottom"].set_position("zero")
axes[1].set_xlim(-5, 5)
axes[1].set_ylim(-0.1, 1.1)
plt.tight_layout()
plt.show()运行结果解读:
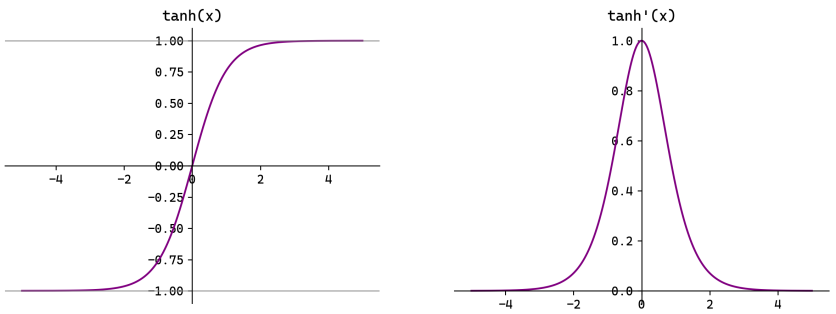
Tanh 的导数比 Sigmoid 的导数峰值更高(最大值 1),但同样在两端趋于 0,梯度饱和问题依然存在。
3. ReLU:目前最受欢迎的激活函数
数学公式:
f(x)=max(0,x)f(x)=max(0,x)
它做了什么:
-
如果输入是正数,原样输出。
-
如果输入是负数,输出 0。
导数:
f′(x)={0,x≤01,x>0f′(x)={0,1,x≤0x>0
注意在 $x=0$ 处不可导,但 PyTorch 默认取左导数(0),实际影响很小。
优缺点:
-
✅ 计算超快:只需要一个判断,没有指数运算。
-
✅ 缓解梯度消失:正半轴梯度恒为 1,梯度可以无损地传下去。
-
✅ 稀疏性:输出中有很多 0,这相当于让网络变得稀疏,有助于减轻过拟合。
-
❌ 神经元坏死:如果某个神经元的所有输入都是负数,它的输出就是 0,梯度也是 0,之后永远不会被更新,这个神经元就“死”了。解决办法是使用 Leaky ReLU 或调小学习率。
代码示例:ReLU 及其导数
import torch
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
x = torch.linspace(-5, 5, 1000, requires_grad=True)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 左图:ReLU 函数
y = torch.relu(x)
axes[0].plot(x.detach().numpy(), y.detach().numpy(), color="purple", linewidth=2)
axes[0].set_title("ReLU 函数", fontsize=14)
axes[0].spines["top"].set_visible(False)
axes[0].spines["right"].set_visible(False)
axes[0].spines["left"].set_position("zero")
axes[0].spines["bottom"].set_position("zero")
axes[0].set_xlim(-5, 5)
axes[0].set_ylim(-0.5, 5)
# 右图:ReLU 的导数
torch.relu(x).sum().backward()
axes[1].plot(x.detach().numpy(), x.grad.numpy(), color="purple", linewidth=2)
axes[1].set_title("ReLU 的导数", fontsize=14)
axes[1].spines["top"].set_visible(False)
axes[1].spines["right"].set_visible(False)
axes[1].spines["left"].set_position("zero")
axes[1].spines["bottom"].set_position("zero")
axes[1].set_xlim(-5, 5)
axes[1].set_ylim(-0.1, 1.1)
plt.tight_layout()
plt.show()运行结果解读:
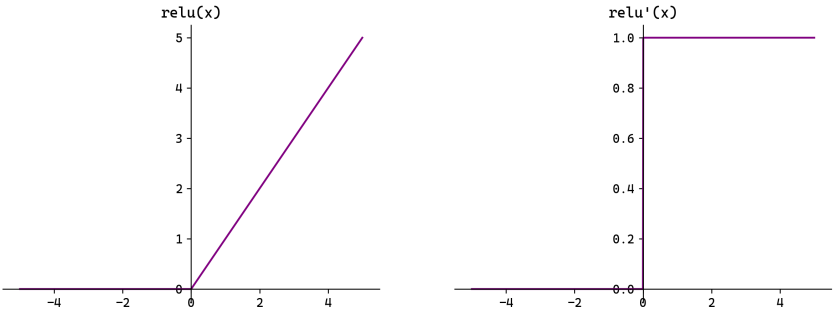
左图的 ReLU 曲线在负数部分为 0,正数部分是一条直线。右图的导数在负数部分为 0,正数部分为 1。这意味着正数区域的梯度可以无损传递。
小结:
-
对于隐藏层,优先使用 ReLU,速度快、梯度好。
-
二分类输出层用 Sigmoid(配合 BCELoss)。
-
多分类输出层用 Softmax(配合 CrossEntropyLoss,注意 CrossEntropyLoss 内部已经包含了 Softmax,所以模型最后一层不需要再加 Softmax)。
二、参数初始化:给神经网络一个“好起点”
神经网络的参数(权重和偏置)不能全设为 0,否则所有神经元会学习到相同的东西,这叫“对称性破坏”。正确的初始化可以加速收敛,避免梯度消失或爆炸。
1. 常数初始化(不推荐)
import torch.nn as nn
# 定义一个全连接层:输入 5 个特征,输出 2 个特征
linear = nn.Linear(5, 2)
# 将所有权重初始化为 0
nn.init.zeros_(linear.weight)
print("全零初始化后的权重:\n", linear.weight)
# 初始化为 1
nn.init.ones_(linear.weight)
print("全一初始化后的权重:\n", linear.weight)
# 初始化为常数 10
nn.init.constant_(linear.weight, 10)
print("常数初始化后的权重:\n", linear.weight)上面代码展示了三种常数初始化方法。注意 nn.init.zeros_ 这种带下划线的函数表示“原地修改”,它会直接改变传入的张量。实际训练中绝对不要将所有权重设成相同的值,否则网络无法学到多样化的特征。
2. 正态分布初始化
# 均值为 0,标准差为 1 的正态分布
nn.init.normal_(linear.weight, mean=0.0, std=1.0)
print("正态分布初始化:\n", linear.weight)这种初始化方法会从高斯分布中随机采样作为权重初始值。均值和标准差可以自己指定。
3. 均匀分布初始化
# 在区间 [a, b] 内均匀采样
nn.init.uniform_(linear.weight, a=0, b=10)
print("均匀分布初始化:\n", linear.weight)每个权重独立地从 $[a, b]$ 的均匀分布中随机取值。
4. Xavier 初始化(Glorot 初始化)
适用激活函数:Sigmoid、Tanh。
设计思想:让每一层的输出方差和输入方差大致相等,这样信号在前向传播时不会过快衰减或爆炸。
公式:
-
正态形式:$\mathcal{N}(0, \sqrt{\frac{2}{n_{in} + n_{out}}})$
-
均匀形式:$\mathcal{U}(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}})$
# Xavier 正态初始化
nn.init.xavier_normal_(linear.weight)
print("Xavier 正态初始化:\n", linear.weight)
# Xavier 均匀初始化
nn.init.xavier_uniform_(linear.weight)
print("Xavier 均匀初始化:\n", linear.weight)xavier_normal_ 会根据输入神经元数 $n_{in}$ 和输出神经元数 $n_{out}$ 自动计算标准差。例如输入 5、输出 2,标准差约为 $\sqrt{2/(5+2)} \approx 0.534$。
5. He 初始化(Kaiming 初始化)
适用激活函数:ReLU 及其变体(Leaky ReLU、PReLU 等)。
设计思想:因为 ReLU 会将一半的神经元输出置为 0,导致方差减半,所以 He 初始化将方差放大一倍,以保持信号稳定。
公式:
-
正态形式:$\mathcal{N}(0, \sqrt{\frac{2}{n_{in}}})$
-
均匀形式:$\mathcal{U}(-\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}})$
# Kaiming 正态初始化
nn.init.kaiming_normal_(linear.weight)
print("Kaiming 正态初始化:\n", linear.weight)
# Kaiming 均匀初始化
nn.init.kaiming_uniform_(linear.weight)
print("Kaiming 均匀初始化:\n", linear.weight)kaiming_normal_ 只需要输入神经元数 $n_{in}$。对于我们的例子 $n_{in}=5$,标准差约为 $\sqrt{2/5} \approx 0.632$,比 Xavier 的 0.534 稍大。
6. Dropout:随机关闭神经元防止过拟合
Dropout 的原理:在训练时,以概率 p 随机将某些神经元的输出置为 0。这样每次迭代都在训练一个不同的子网络,相当于做了模型集成,能有效防止过拟合。
import torch
# p=0.5 表示每个神经元有 50% 的概率被关闭
dropout = torch.nn.Dropout(p=0.5)
# 生成 10 个随机整数(1~10),并转为浮点数
x = torch.randint(1, 10, (10,)).float()
print("输入数据:", x)
# 训练模式:Dropout 生效
dropout.train()
print("训练模式下(随机失活):", dropout(x))
# 评估模式:Dropout 不生效,相当于恒等映射
dropout.eval()
print("评估模式下(保持不变):", dropout(x))-
调用 model.train() 会将模型切换到训练模式,此时 Dropout 会随机屏蔽神经元。
-
调用 model.eval() 切换到评估模式,Dropout 不再起作用,所有神经元都保留。
-
在训练完成后做预测时,一定要记得 model.eval(),否则预测结果会随机变化。
三、搭建神经网络:两种主流方式
PyTorch 中搭建模型有两种常用方法:自定义 Module 类(灵活)和 Sequential 容器(简洁)。
1. 自定义 Module 类(推荐)
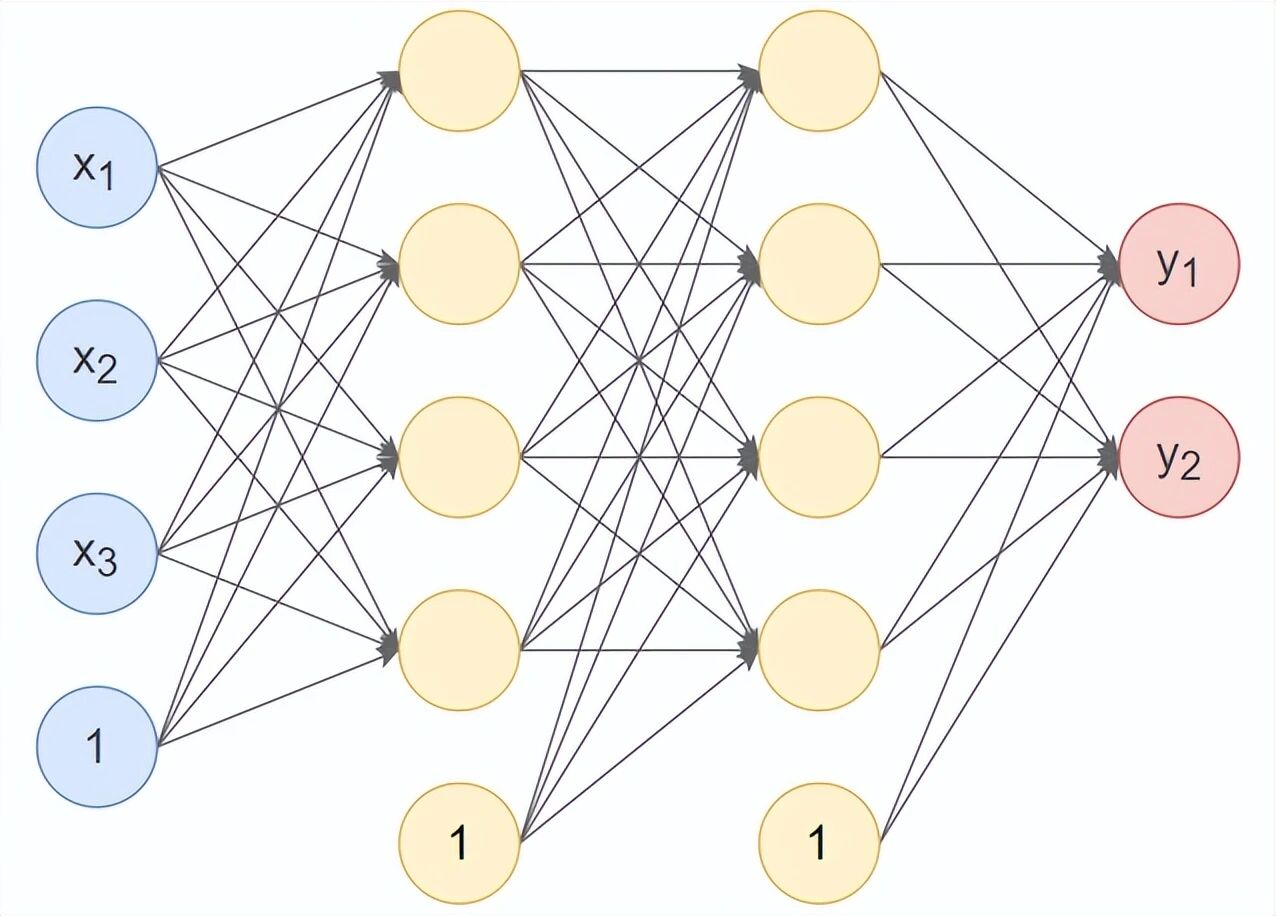
下面我们实现一个具体的网络:
-
输入 3 个特征
-
第一个隐藏层:3 → 4,使用 Tanh 激活,Xavier 初始化
-
第二个隐藏层:4 → 4,使用 ReLU 激活,He 初始化
-
输出层:4 → 2,使用 Softmax 激活(多分类)
import torch
import torch.nn as nn
class MyModel(nn.Module):
"""自定义神经网络模型"""
def __init__(self):
# 必须调用父类 nn.Module 的初始化方法
super(MyModel, self).__init__()
# 定义三个全连接层(Linear 层)
self.linear1 = nn.Linear(3, 4) # 输入3,输出4
self.linear2 = nn.Linear(4, 4) # 输入4,输出4
self.out = nn.Linear(4, 2) # 输入4,输出2
# 对 linear1 使用 Xavier 正态初始化(适合 Tanh)
nn.init.xavier_normal_(self.linear1.weight)
nn.init.zeros_(self.linear1.bias) # 偏置初始化为0
# 对 linear2 使用 Kaiming 正态初始化(适合 ReLU)
nn.init.kaiming_normal_(self.linear2.weight)
nn.init.zeros_(self.linear2.bias)
# 输出层使用默认初始化(均匀分布)
# 不额外设置
def forward(self, x):
"""前向传播:定义数据如何流过网络"""
x = self.linear1(x) # 第一层线性变换
x = torch.tanh(x) # Tanh 激活
x = self.linear2(x) # 第二层线性变换
x = torch.relu(x) # ReLU 激活
x = self.out(x) # 输出层线性变换
x = torch.softmax(x, dim=1) # Softmax 得到概率分布(dim=1 表示对类别维度)
return x
# 实例化模型
model = MyModel()
# 生成随机输入:10 个样本,每个样本 3 个特征
dummy_input = torch.randn(10, 3)
output = model(dummy_input)
print("输出形状:", output.shape) # torch.Size([10, 2])
print("输出的概率分布(每行和为1):\n", output)
# 查看模型参数(两种方式)
print("\n--- 使用 named_parameters() 逐层查看 ---")
for name, param in model.named_parameters():
print(f"{name} 的形状:{param.shape}")
print("\n--- 使用 state_dict() 查看所有参数 ---")
print(model.state_dict())-
__init__ 方法中定义网络的“骨架”(有哪些层)。
-
forward 方法中定义数据流动的“路径”。
-
named_parameters() 返回所有参数的名称和张量,state_dict() 返回一个字典,键是参数名,值是参数值。
-
为什么要用 torch.softmax(..., dim=1)?因为每个样本的预测结果是一个长度为 2 的向量,我们要让这两个数的和为 1,表示属于两个类别的概率。dim=1 表示沿着类别维度做 Softmax。
2. 使用 torchsummary 查看模型结构和参数量
pip install torchsummaryfrom torchsummary import summary
# input_size: 每个样本的特征数;batch_size 仅用于计算显示,不影响模型
summary(model, input_size=(3,), batch_size=10, device="cpu")输出示例:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [10, 4] 16
Linear-2 [10, 4] 20
Linear-3 [10, 2] 10
================================================================
Total params: 46
Trainable params: 46
Non-trainable params: 0
-----------------------------------------------------------------
第 1 个 Linear 层:3 个输入 × 4 个输出 = 12 个权重,加上 4 个偏置,共 16 个参数。
-
第 2 个 Linear 层:4×4 = 16 个权重,加 4 个偏置,共 20 个参数。
-
第 3 个 Linear 层:4×2 = 8 个权重,加 2 个偏置,共 10 个参数。
-
总计 46 个参数,全部可训练。
3. 使用 Sequential 快速搭建
当网络是简单的“一条直线”时,nn.Sequential 可以省去写 forward 的麻烦。
import torch.nn as nn
# 直接按顺序列出各层
model_seq = nn.Sequential(
nn.Linear(3, 4),
nn.Tanh(),
nn.Linear(4, 4),
nn.ReLU(),
nn.Linear(4, 2),
nn.Softmax(dim=1)
)
# 自定义初始化函数
def init_weights(m):
"""如果 m 是 Linear 层,就用 Xavier 均匀初始化权重,偏置设为 0.01"""
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
m.bias.data.fill_(0.01)
# apply 方法会递归地遍历模型的所有子模块,对每个子模块调用 init_weights
model_seq.apply(init_weights)
# 测试
output_seq = model_seq(torch.randn(10, 3))
print("Sequential 模型输出形状:", output_seq.shape)-
model_seq 是一个容器,你只需要把层按顺序放进去,前向传播就会自动按顺序执行。
-
model.apply(init_weights) 会遍历模型内的所有层(包括嵌套的层),对每个层执行 init_weights 函数。这是初始化复杂模型的常用技巧。
四、损失函数:告诉模型“你错在哪里”
损失函数计算模型预测值与真实值之间的差距。这个差距会被反向传播用来更新参数。
1. 分类任务的损失函数
1.1 二分类:BCELoss(二元交叉熵)
公式:
L=−1n∑i=1n[yilogy^i+(1−yi)log(1−y^i)]L=−n1∑i=1n[yilogy^i+(1−yi)log(1−y^i)]
其中 $y_i$ 是真实标签(0 或 1),$\hat{y}_i$ 是预测概率(经过 Sigmoid 之后的值)。
代码示例:
import torch.nn as nn
# 真实标签(0 或 1)
target = torch.tensor([[1], [0], [0]], dtype=torch.float32)
# 模拟模型输出:未经过 Sigmoid 的原始分数(logits)
raw_output = torch.randn((3, 1))
# 用 Sigmoid 将 logits 转换成概率
prediction = torch.sigmoid(raw_output)
# 实例化 BCELoss
bce_loss = nn.BCELoss()
loss_value = bce_loss(prediction, target)
print("BCELoss 值:", loss_value.item())-
使用 BCELoss 之前,模型最后一层必须加 Sigmoid,确保输出在 0~1 之间。
-
如果不想手动加 Sigmoid,可以用 BCEWithLogitsLoss,它内部包含了 Sigmoid,数值上更稳定。
1.2 多分类:CrossEntropyLoss
重要提醒:nn.CrossEntropyLoss 内部已经包含了 LogSoftmax + NLLLoss,所以模型最后一层不要再加 Softmax,直接输出原始的 logits(未归一化的分数)即可。
# 情况1:真实标签是类别索引(最常用)
target_idx = torch.tensor([1, 0, 3, 2, 5, 4]) # 6 个样本,类别 0~5
# 模型输出:6 个样本,每个样本 8 个类别的原始分数(logits)
logits = torch.randn((6, 8))
ce_loss = nn.CrossEntropyLoss()
loss_val = ce_loss(logits, target_idx)
print("CrossEntropyLoss(标签索引):", loss_val.item())
# 情况2:真实标签是概率分布(软标签)
target_probs = torch.randn(6, 8).softmax(dim=1) # 模拟真实概率分布
logits = torch.randn((6, 8))
loss_val2 = ce_loss(logits, target_probs)
print("CrossEntropyLoss(概率分布):", loss_val2.item())-
当真实标签是类别索引时,CrossEntropyLoss 会自动将索引转换成 one-hot 编码。
-
当真实标签是概率分布时,可以直接传入,常用于知识蒸馏等场景。
2. 回归任务的损失函数
回归任务的目标是预测一个连续数值(如房价、温度)。
2.1 L1 Loss(MAE,平均绝对误差)
公式:$L = \frac{1}{n} \sum |y_i - \hat{y}_i|$
特点:对异常值不敏感,但在 0 点处不可导。
l1_loss = nn.L1Loss()
pred = torch.tensor([2.5, 0.0, 2.0])
target = torch.tensor([3.0, -0.5, 2.0])
loss = l1_loss(pred, target)
print("L1 Loss:", loss.item()) # (0.5 + 0.5 + 0.0) / 3 = 0.33332.2 L2 Loss(MSE,均方误差)
公式:$L = \frac{1}{n} \sum (y_i - \hat{y}_i)^2$
特点:处处可导,梯度随误差减小而减小,但对异常值非常敏感(平方放大了大误差)。
mse_loss = nn.MSELoss()
loss = mse_loss(pred, target)
print("MSE Loss:", loss.item()) # (0.25 + 0.25 + 0.0) / 3 = 0.16672.3 Smooth L1 Loss(Huber 损失的变体)
公式:
SmoothL1(x)={0.5x2,∣x∣<1∣x∣−0.5,∣x∣≥1SmoothL1(x)={0.5x2,∣x∣−0.5,∣x∣<1∣x∣≥1
特点:结合了 L1 和 L2 的优点:误差小时用 L2(光滑),误差大时用 L1(鲁棒)。
smooth_l1 = nn.SmoothL1Loss()
loss = smooth_l1(pred, target)
print("Smooth L1 Loss:", loss.item())在目标检测任务中(如 Faster R-CNN 的边界框回归),Smooth L1 Loss 是常用选择。五、优化器:如何更新参数
优化器根据损失函数计算的梯度来更新模型的参数。PyTorch 的 torch.optim 提供了多种优化算法。
1. SGD(随机梯度下降)与 Momentum
标准 SGD:$W \leftarrow W - \eta \nabla L$,其中 $\eta$ 是学习率。
Momentum:加入“惯性”,历史梯度加权和 $V$ 会参与更新,让参数更新更平滑,加速收敛。
V←αV−η∇LV←αV−η∇L
W←W+VW←W+V
import torch.optim as optim
# 假设我们有一个参数张量 params_list
params_list = [torch.tensor([1.0, 2.0], requires_grad=True)]
# 标准 SGD
sgd_optim = optim.SGD(params_list, lr=0.01)
# SGD with Momentum(动量系数 momentum 通常取 0.9)
momentum_optim = optim.SGD(params_list, lr=0.01, momentum=0.9)2. 学习率衰减调度器
随着训练进行,逐渐降低学习率有助于模型在最优解附近精细调整。
2.1 等间隔衰减(StepLR)
每 step_size 个 epoch,学习率乘以 gamma。
optimizer = optim.SGD(params_list, lr=0.1)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
# ... 训练代码 ...
scheduler.step() # 更新学习率
print(f"Epoch {epoch}, lr = {scheduler.get_last_lr()[0]}")2.2 指定间隔衰减(MultiStepLR)
在指定的 epoch 列表处乘以 gamma。
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 80, 95], gamma=0.5)2.3 指数衰减(ExponentialLR)
每个 epoch 学习率乘以 gamma^epoch。
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.99)3. AdaGrad:自适应学习率
为每个参数维护历史梯度的平方和 $H$,学习率除以 $\sqrt{H}$,使得稀疏参数获得更大更新。
H←H+∇2H←H+∇2
W←W−η1H+ϵ∇W←W−ηH+ϵ1∇
adagrad_optim = optim.Adagrad(params_list, lr=0.01)缺点:$H$ 不断累加,学习率会一直减小,最终可能小到无法继续学习。
4. RMSProp:解决 AdaGrad 的缺陷
使用指数加权移动平均代替累加,让历史梯度的影响逐渐衰减。
H←αH+(1−α)∇2H←αH+(1−α)∇2
rmsprop_optim = optim.RMSprop(params_list, lr=0.01, alpha=0.99)5. Adam:目前最常用的默认优化器
Adam 融合了 Momentum(一阶矩)和 RMSProp(二阶矩),并加入了偏差修正,通常不需要精细调整就能取得不错的效果。
adam_optim = optim.Adam(params_list, lr=0.001, betas=(0.9, 0.999))参数建议:
-
lr:默认 0.001,可根据任务调整(如 0.0001 到 0.01 之间)。
-
betas:一阶矩衰减系数(0.9)和二阶矩衰减系数(0.999)。
-
weight_decay:L2 正则化系数,通常设为 1e-4 或 1e-5。
6. 完整示例:不同优化器收敛对比
我们用一个简单的二维函数 $f(x_1, x_2) = 0.05 x_1^2 + x_2^2$ 来演示不同优化器的收敛轨迹。
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
def run_optimizer(optimizer, n_iters, X_init, w):
"""运行优化器并记录参数轨迹"""
X = X_init.clone().detach().requires_grad_(True)
trajectory = [X.detach().numpy().copy()]
for _ in range(n_iters):
y = w[0] * X[0]**2 + w[1] * X[1]**2 # 目标函数
y.backward()
optimizer.step()
optimizer.zero_grad()
trajectory.append(X.detach().numpy().copy())
return np.array(trajectory)
# 目标函数系数
w = torch.tensor([0.05, 1.0])
X_init = torch.tensor([-7.0, 2.0])
n_iters = 500
# 创建三个优化器,初始参数相同
X_sgd = X_init.clone().detach().requires_grad_(True)
sgd_optim = optim.SGD([X_sgd], lr=0.01)
X_mom = X_init.clone().detach().requires_grad_(True)
mom_optim = optim.SGD([X_mom], lr=0.01, momentum=0.9)
X_adam = X_init.clone().detach().requires_grad_(True)
adam_optim = optim.Adam([X_adam], lr=0.1)
# 运行
traj_sgd = run_optimizer(sgd_optim, n_iters, X_sgd, w)
traj_mom = run_optimizer(mom_optim, n_iters, X_mom, w)
traj_adam = run_optimizer(adam_optim, n_iters, X_adam, w)
# 绘制等高线和轨迹
x1 = np.linspace(-8, 8, 200)
x2 = np.linspace(-3, 3, 200)
X1, X2 = np.meshgrid(x1, x2)
Z = 0.05 * X1**2 + X2**2
plt.figure(figsize=(10, 8))
plt.contour(X1, X2, Z, levels=30, cmap='viridis', alpha=0.6)
plt.plot(traj_sgd[:,0], traj_sgd[:,1], 'r-', label='SGD', linewidth=2)
plt.plot(traj_mom[:,0], traj_mom[:,1], 'b-', label='Momentum', linewidth=2)
plt.plot(traj_adam[:,0], traj_adam[:,1], 'g-', label='Adam', linewidth=2)
plt.scatter([0], [0], color='red', marker='*', s=200, label='最小值')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend()
plt.title('不同优化器的收敛轨迹对比')
plt.grid(True, alpha=0.3)
plt.show()结果分析:
-
SGD 收敛最慢,且路径曲折。
-
Momentum 加速了收敛,震荡减小。
-
Adam 收敛最快,路径最直接。
六、实战案例:房价预测(House Prices)
我们将使用 Kaggle 上的 House Prices 数据集,完整演示一个回归任务的端到端流程。
1. 数据集简介
该数据集包含 1460 个训练样本和 79 个特征,目标是预测 SalePrice(房价)。特征包括:
-
数值型:面积、年份、房间数等
-
类别型:社区、供暖类型、车库类型等
数据集下载:https://pan.baidu.com/s/1Fd0mpdf0loqYJlUFu_YZqQ?pwd=2wbk
2. 环境准备
# 安装必要库(如果还没安装)
# pip install pandas scikit-learn matplotlib torch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
# 固定随机种子,保证结果可重复
torch.manual_seed(42)
np.random.seed(42)3. 特征工程(非常重要!)
特征工程是将原始数据转换成模型能理解的格式。我们做两件事:
-
数值特征:缺失值用均值填充,然后标准化(均值为0,方差为1)。
-
类别特征:缺失值用字符串 "NaN" 填充,然后独热编码(将每个类别变成一个 0/1 特征)。
def create_datasets(csv_path):
"""
读取原始 CSV,执行预处理,返回 PyTorch 的 DataLoader
"""
# 读取数据
data = pd.read_csv(csv_path)
# Id 列只是编号,没有预测作用,删除
data.drop("Id", axis=1, inplace=True)
# 分离特征 X 和目标 y
X = data.drop("SalePrice", axis=1)
y = data["SalePrice"]
# 划分训练集和验证集(80% 训练,20% 验证)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 自动识别数值列和类别列
numerical_features = X.select_dtypes(exclude="object").columns.tolist()
categorical_features = X.select_dtypes(include="object").columns.tolist()
# ---------- 数值特征处理流水线 ----------
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')), # 用均值填充缺失值
('scaler', StandardScaler()) # 标准化
])
# ---------- 类别特征处理流水线 ----------
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='NaN')), # 缺失值填 'NaN'
('onehot', OneHotEncoder(handle_unknown='ignore')) # 独热编码
])
# 合并两个流水线
preprocessor = ColumnTransformer(transformers=[
('num', numerical_transformer, numerical_features),
('cat', categorical_transformer, categorical_features)
])
# 对训练集进行拟合(计算均值和编码映射),同时转换训练集;对验证集只转换不拟合
X_train_processed = preprocessor.fit_transform(X_train)
X_val_processed = preprocessor.transform(X_val)
# 某些情况下返回的是稀疏矩阵,转换成稠密 NumPy 数组(特征维度不大时可以)
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, 'toarray') else X_train_processed
X_val_processed = X_val_processed.toarray() if hasattr(X_val_processed, 'toarray') else X_val_processed
# 转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_processed, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1) # 变成列向量
X_val_tensor = torch.tensor(X_val_processed, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val.values, dtype=torch.float32).view(-1, 1)
# 封装成 TensorDataset(一个简单的 (X, y) 对集合)
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
val_dataset = TensorDataset(X_val_tensor, y_val_tensor)
return train_dataset, val_dataset, X_train_processed.shape[1]-
Pipeline 将多个预处理步骤串联起来,代码更整洁。
-
ColumnTransformer 可以对不同的列应用不同的预处理。
-
fit_transform 用于训练集(学习填充值和标准化参数),transform 用于验证集(只应用学到的参数,不重新学习)。
-
最后返回的是 TensorDataset,它可以配合 DataLoader 进行批量加载。
4. 自定义损失函数:RMSLE(均方根对数误差)
在房价预测中,相对误差比绝对误差更有意义。例如:
-
预测 20 万,误差 10 万 → 相对误差 50%
-
预测 1000 万,误差 10 万 → 相对误差 1%
RMSLE 通过对数变换来关注相对误差:
RMSLE=1n∑i=1n(log(y^i+1)−log(yi+1))2RMSLE=n1∑i=1n(log(y^i+1)−log(yi+1))2
加 1 是为了避免 $\log(0)$。
def rmsle_loss(pred, target):
"""
计算 RMSLE 损失
pred: 模型预测值,形状 (batch_size, 1)
target: 真实值,形状 (batch_size, 1)
"""
# 防止预测值为负数(比如 -100),将其截断到 0
pred = torch.clamp(pred, min=0)
# log1p(x) 等价于 log(1+x),数值更稳定
log_pred = torch.log1p(pred)
log_target = torch.log1p(target)
# 先算 MSE,再开根号
mse = nn.MSELoss()
return torch.sqrt(mse(log_pred, log_target))5. 搭建神经网络模型
我们设计一个 4 层的全连接网络,中间加入 BatchNorm 和 Dropout 来防止过拟合。
class HousePriceModel(nn.Module):
def __init__(self, input_dim):
super(HousePriceModel, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 256),
nn.BatchNorm1d(256), # 批归一化:加速收敛,稳定训练
nn.ReLU(),
nn.Dropout(0.3), # 30% 的神经元随机失活
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(64, 1) # 输出房价(连续值,无激活函数)
)
# 对网络中的 Linear 层进行 He 初始化(适合 ReLU)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, x):
return self.net(x)-
BatchNorm1d 对每个特征维度进行归一化,可以加快收敛、允许使用更大的学习率。
-
Dropout 只在训练时生效,评估时会自动关闭。
-
输出层没有激活函数,因为我们要预测的房价可以取任意正数,线性输出即可。
6. 训练函数
训练函数包含了完整的训练循环、验证循环、学习率调度和损失记录。
def train_model(model, train_dataset, val_dataset, epochs=200, batch_size=64, lr=0.001, device='cpu'):
"""
训练模型,返回训练损失和验证损失列表
"""
model = model.to(device)
# Adam 优化器,加上 weight_decay 作为 L2 正则化
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5)
# ReduceLROnPlateau:当验证损失连续 patience 个 epoch 不下降时,学习率乘以 factor
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=10, verbose=True)
# 创建 DataLoader,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 训练集打乱顺序
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False) # 验证集不打乱
train_losses = []
val_losses = []
for epoch in range(epochs):
# ---------- 训练阶段 ----------
model.train() # 切换到训练模式(启用 Dropout 和 BatchNorm 的统计)
train_loss = 0.0
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
optimizer.zero_grad() # 清空之前的梯度
pred = model(X_batch) # 前向传播
loss = rmsle_loss(pred, y_batch) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
train_loss += loss.item() * X_batch.size(0) # 累加损失(乘以 batch 大小)
train_loss /= len(train_dataset) # 平均损失
train_losses.append(train_loss)
# ---------- 验证阶段 ----------
model.eval() # 切换到评估模式(关闭 Dropout,BatchNorm 使用训练时的统计)
val_loss = 0.0
with torch.no_grad(): # 禁用梯度计算,节省内存和计算
for X_batch, y_batch in val_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
pred = model(X_batch)
loss = rmsle_loss(pred, y_batch)
val_loss += loss.item() * X_batch.size(0)
val_loss /= len(val_dataset)
val_losses.append(val_loss)
# 学习率调度(基于验证损失)
scheduler.step(val_loss)
# 每 20 个 epoch 打印一次进度
if (epoch+1) % 20 == 0:
print(f"Epoch {epoch+1:3d}/{epochs} | Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}")
return train_losses, val_losses-
model.train() 和 model.eval() 必须正确使用,否则 Dropout 和 BatchNorm 的行为会出错。
-
torch.no_grad() 可以大幅减少显存占用,验证时一定要加上。
-
ReduceLROnPlateau 比固定间隔衰减更智能:当模型不再进步时自动降低学习率。
7. 执行训练
# 假设数据文件路径为 "data/house_prices.csv"
# train_dataset, val_dataset, input_dim = create_datasets("data/house_prices.csv")
# 设置设备(有 GPU 就用 GPU,否则用 CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")
# 创建模型
model = HousePriceModel(input_dim)
# 训练
train_losses, val_losses = train_model(
model, train_dataset, val_dataset,
epochs=200, batch_size=64, lr=0.001, device=device
)
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='训练损失', linewidth=2)
plt.plot(val_losses, label='验证损失', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('RMSLE')
plt.title('训练与验证损失曲线')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()8. 模型评估与预测可视化
最后,我们在验证集上计算最终 RMSLE,并画出预测值与真实值的散点图。
# 在验证集上计算最终 RMSLE
model.eval()
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
all_preds = []
all_targets = []
with torch.no_grad():
for X_batch, y_batch in val_loader:
X_batch = X_batch.to(device)
pred = model(X_batch).cpu()
all_preds.append(pred)
all_targets.append(y_batch)
preds = torch.cat(all_preds, dim=0)
targets = torch.cat(all_targets, dim=0)
final_rmsle = rmsle_loss(preds, targets)
print(f"验证集最终 RMSLE:{final_rmsle.item():.4f}")
# 绘制预测值 vs 真实值散点图
plt.figure(figsize=(8, 8))
plt.scatter(targets.numpy(), preds.numpy(), alpha=0.5)
plt.plot([0, targets.max().item()], [0, targets.max().item()], 'r--', label='完美预测')
plt.xlabel('真实房价')
plt.ylabel('预测房价')
plt.title('预测值 vs 真实值')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()结果分析:
-
如果散点都落在红虚线附近,说明预测效果很好。
-
RMSLE 值越小越好,一般小于 0.2 就算不错。
完整参考代码下载:https://pan.baidu.com/s/13PirfXQdphmbFnq0D3gYNQ?pwd=hka5
七、总结
通过本文,我们系统学习了:
1. 激活函数
-
Sigmoid/Tanh:适合输出层,但容易梯度消失。
-
ReLU:隐藏层默认选择,但要注意神经元坏死。
2. 参数初始化
-
根据激活函数选择:Sigmoid/Tanh → Xavier;ReLU → He。
-
不要全零初始化。
3. 损失函数
-
分类:BCELoss(二分类)、CrossEntropyLoss(多分类)。
-
回归:MSE 常用,Smooth L1 更鲁棒,RMSLE 适合房价预测。
4. 优化器
-
Adam 是默认首选,省心高效。
-
SGD+Momentum 在精细调参后可能达到更高精度。
-
学习率调度(StepLR、ReduceLROnPlateau)是提升性能的关键。
5. 模型构建
-
nn.Module 子类化:灵活。
-
nn.Sequential:简洁。
-
正则化:Dropout、BatchNorm、weight decay。
6. 完整项目流程
-
数据预处理(填充缺失值、标准化、独热编码)。
-
划分训练/验证集,构建 DataLoader。
-
设计模型、损失函数、优化器。
-
训练循环(梯度清零、反向传播、参数更新、学习率调度)。
-
评估与可视化。
下一步可以做什么?
-
尝试更复杂的网络结构(残差网络、注意力机制)。
-
学习卷积神经网络(CNN)处理图像。
-
学习循环神经网络(RNN/LSTM)处理序列数据。
-
将模型导出为 ONNX 或 TorchScript 进行部署。
希望这篇文章能帮你打开深度学习的大门。如果觉得有用,欢迎分享给更多朋友!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)