BERT 微调实战对比:冻结参数 vs 全量微调,谁才是 NLP 任务的最优选?
一、 业务背景:为什么需要微调 BERT
在电商平台或智能客服场景中,诸如商品标题分类、意图识别 等任务,本质上都是将非结构化文本映射到特定类别的多分类问题。BERT (Bidirectional Encoder Representations from Transformers) 作为一个强大的预训练编码器,已经在海量通用文本上学习到了丰富的语言表示。
然而,预训练过程并不包含特定业务领域的标签信息(如“酒饮冲调”或“母婴”类目)。为了使 BERT 能够胜任具体的下游任务,必须在其顶层(通常是 [CLS] token 的输出位置)接上一个自定义的分类头(Linear Layer),并通过业务数据进行微调(Fine-tuning)。微调过程决定了模型如何平衡预训练知识与业务特定知识。
二、 冻结微调与全量微调的原理分析
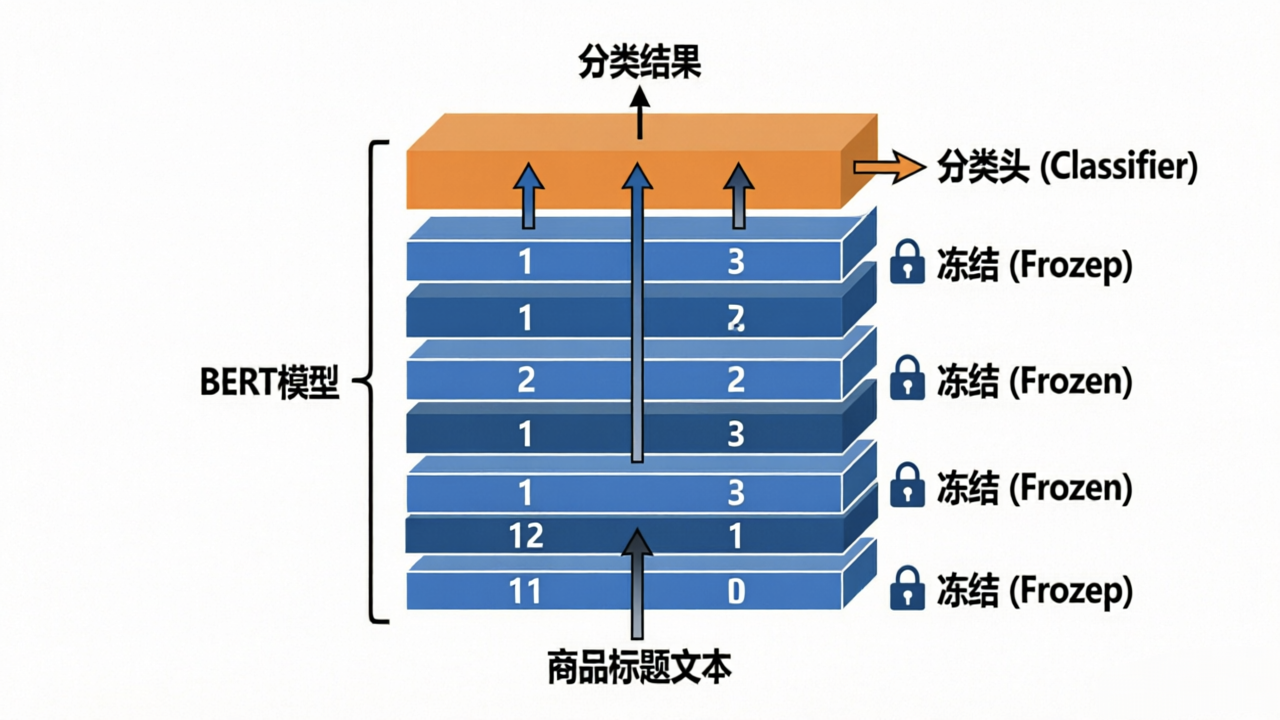
1. 冻结微调(Feature Extraction)
该方案将 BERT 视为一个静态特征提取器。在训练过程中,BERT 内部所有的 Transformer 层参数(权重和偏置)都被固定,不接受梯度更新。只有顶层的分类层会根据损失函数进行参数调整。
- 核心逻辑:保留预训练模型捕捉通用语法和语义的能力,仅让分类头学习如何根据这些特征进行分类。
2. 全量微调(Full Fine-tuning)
该方案允许业务数据穿透至 BERT 的所有层。在反向传播过程中,不仅分类头的参数会更新,BERT 内部的 12 层(或 24 层)Transformer 参数也会随之改变。
- 核心逻辑:模型会根据业务领域的语言特征(如电商缩写、特定术语)调整其内部的注意力权重(Attention Weights),实现模型底层表示的“领域自适应”。

三、 核心维度对比:实测表现分析
根据基于商品标题分类数据集的实测经验,两种策略在工程表现上存在显著差异:
|
对比维度 |
冻结参数微调 (Freeze) |
全量微调 (Full Fine-tuning) |
|
训练速度 |
更快。由于只需计算分类层的梯度,计算量极小。 |
慢。每一轮训练都需要更新数亿个参数,计算开销大。 |
|
显存占用 |
极低。无需存储 BERT 各层的梯度状态,适合低配显卡。 |
高。必须存储所有层的梯度,通常需要结合混合精度训练。 |
|
收敛速度 |
收敛极快,通常 1-2 个 Epoch 即可稳定,但容易陷入局部最优。 |
收敛较慢,需要更多 Epoch 才能充分拟合。 |
|
最终效果 |
效果上限受限,若预训练数据与业务数据差异大,表现一般。 |
效果上限更高,能捕捉到更细腻的业务语义(相对描述)。 |

四、 适用场景建议
选择冻结微调的场景:
-
- 计算资源极度受限:仅有入门级显卡或需要在 CPU 上进行微调。
- 数据集非常小:全量微调极易导致严重的过拟合。
- 快速原型验证:用于快速跑通流程,验证任务可行性。
选择全量微调的场景:
-
- 追求极致精度:业务场景对分类准确度要求极高。
- 领域差异极大:如医疗、法律等垂直领域,通用 BERT 难以直接覆盖。
- 数据量充足:有足够的样本支撑大规模参数的更新过程。
五、 代码实现:两种方案的 PyTorch 落地
在 PyTorch 中,两种方案的区别主要体现在模型定义时的 requires_grad 设置以及优化器传入的参数范围。
1. 模型类定义
通过一个参数 freeze_bert 灵活控制微调策略:
# src/model/classifier.py
from torch import nn
from transformers import AutoModel
class BertTitleClassifier(nn.Module):
def __init__(self, model_path, num_classes, freeze_bert=True):
"""
初始化分类模型
:param freeze_bert: 是否冻结 BERT 编码器参数
"""
super().__init__()
# 加载本地预训练的 BERT 模型
self.bert = AutoModel.from_pretrained(model_path)
# 定义分类头:将 BERT 输出的 [CLS] 向量映射到品类空间
self.classifier = nn.Linear(self.bert.config.hidden_size, num_classes)
# 核心逻辑:决定是否冻结 BERT 参数
if freeze_bert:
for param in self.bert.parameters():
param.requires_grad = False # 设置参数不参与梯度计算
else:
for param in self.bert.parameters():
param.requires_grad = True # 全量更新
def forward(self, input_ids, attention_mask=None):
# 获取 BERT 输出:last_hidden_state
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
# 取 [CLS] token 对应的向量作为句子的整体表示
cls_output = outputs.last_hidden_state[:, 0, :]
# 通过线性层得到最终 logits
logits = self.classifier(cls_output)
return logits
2. 训练循环实现
无论选择哪种策略,建议引入**早停机制(Early Stopping)以防止过拟合,并使用自动混合精度(AMP)**提升效率。
# src/runner/train.py
import torch
from torch import nn, optim
from model.classifier import BertTitleClassifier
def train_bert(freeze_strategy=True):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 实例化模型
model = BertTitleClassifier(
model_path="pretrained/bert-base-chinese",
num_classes=15,
freeze_bert=freeze_strategy
).to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 优化器设置:全量微调通常使用较小的学习率 (如 1e-5),冻结微调可稍大
lr = 1e-5 if not freeze_strategy else 1e-3
optimizer = optim.Adam(model.parameters(), lr=lr)
# 引入梯度缩放器,支持混合精度训练
scaler = torch.amp.GradScaler()
# 简化的训练循环
for epoch in range(5):
model.train()
# 假设已获取 dataloader
for batch in train_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
# 开启自动混合精度上下文
with torch.autocast(device_type=device.type, dtype=torch.float16):
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
# 反向传播与更新
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
print(f"Epoch {epoch} 完成训练")
六、 踩坑经验分享
1. 全量微调中的学习率灾难
坑点:在全量微调时,如果直接使用常规的 $10^{-3}$ 学习率,BERT 预训练的权重会被业务数据迅速“冲洗”,导致模型在第一个 Epoch 就发生梯度爆炸或完全丢失通用语义。 对策:全量微调务必将学习率设在 $10^{-5}$ 级别(如 2e-5 或 5e-5)。
2. 冻结模式下的推理模式缺失
坑点:部分开发者认为冻结了 BERT 就不需要设置 model.eval()。实际上,即使权重不更新,Dropout 层的行为在训练和推理模式下依然不同。 对策:在评估或推理时,务必调用 model.eval() 并在上下文中使用 with torch.no_grad(),这不仅是为了逻辑正确,更能显著节省显存并加速计算。
3. 混合精度下的模型加载
坑点:使用混合精度训练保存的 checkpoint.pt,如果直接在不支持半精度的 CPU 环境下加载,可能会出现 dtype 冲突。 对策:在 torch.load 时显式指定 map_location="cpu",并确保在加载后根据环境决定是否继续开启 autocast。
七、 总结与建议
该方案的实测结果表明:全量微调在复杂语义理解任务中具有不可替代的效果优势,而冻结参数策略则是轻量化开发与资源受限环境下的最优解。 在实际工程中,建议先通过冻结微调快速建立 Baseline,随后根据业务对精度的需求,逐步放开后几层 Transformer 参数进行局部微调,最后尝试全量微调以追求性能极限。
如果觉得有帮助,点个赞支持一下! 你更喜欢冻结微调还是全量微调?欢迎留言讨论!
收藏备用,总有一天用得上!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)