FAST: Efficient Action Tokenization for Vision-Language-Action Models
FAST: Efficient Action Tokenization for Vision-Language-Action Models
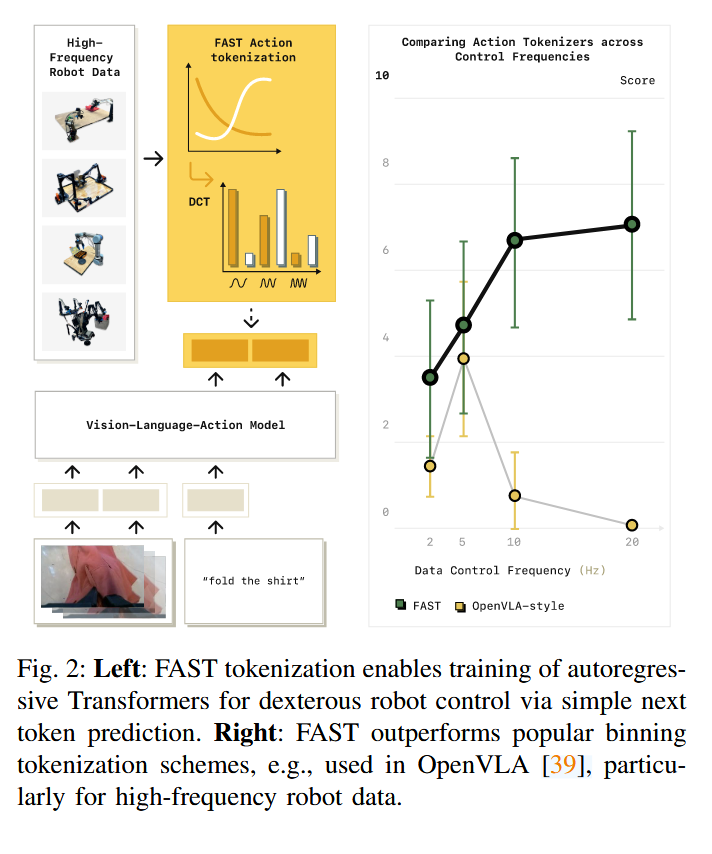
FAST:高效机器人动作分词方法详解
FAST (Frequency-space Action Sequence Tokenization) 是由 Physical Intelligence 团队提出的一种针对 VLA(视觉-语言-动作)模型的新型分词方案。它通过将动作序列从时域转换到频域,解决了自回归模型在处理高频、精细机器人动作时的效率与精度瓶颈。
1. 核心背景:为什么要提出 FAST?
在传统的自回归 VLA 模型(如 OpenVLA 或 RT-2)中,通常使用**简单分箱(Naive Binning)**方案:将每个维度的连续值直接离散化为 256 个桶。
- 痛点: 在高频控制(如 50Hz)下,相邻时间步的动作极度相似。自回归模型预测时容易陷入“直接复制上一个动作”的局部最优解,导致无法学会捏取、折叠等复杂的精细动作。
- 解决方案: 借鉴 JPEG 图像压缩原理,利用动作序列在时间上的冗余性,将其压缩为信息密度极高的频域 Token。
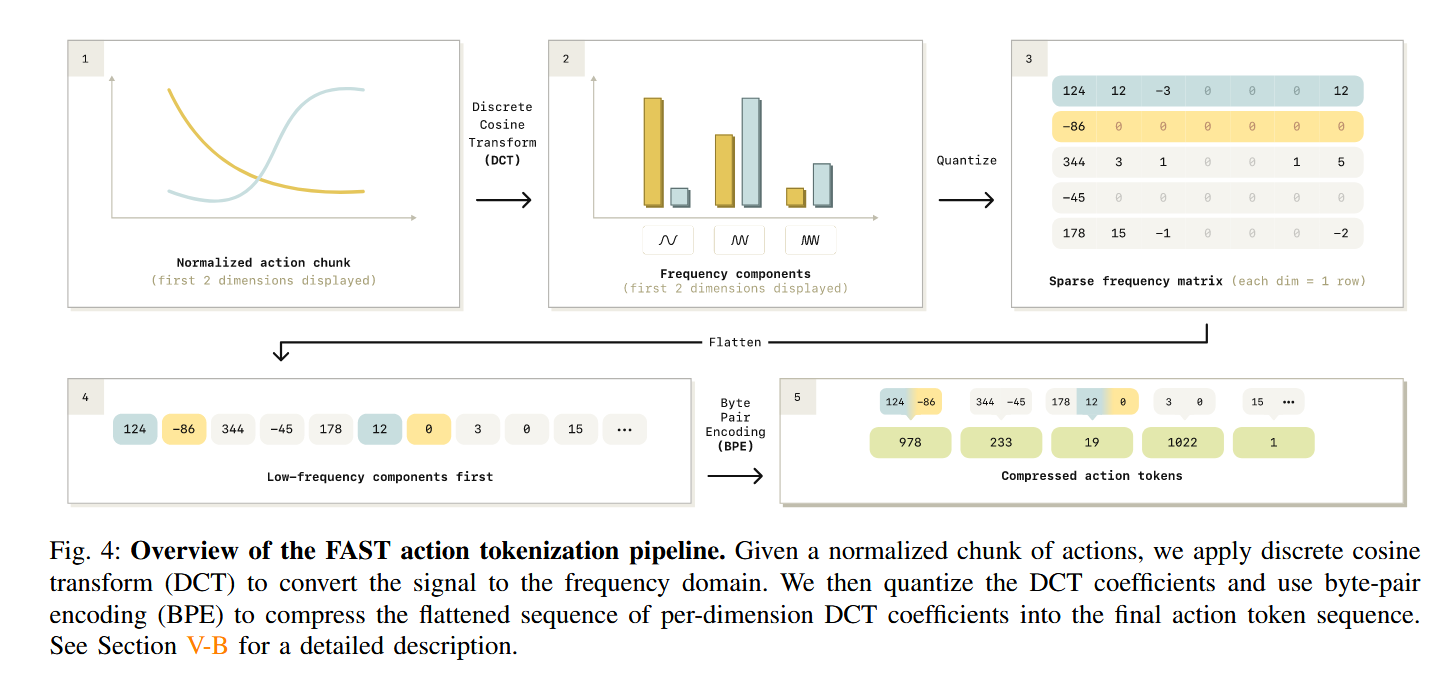
2. FAST 技术流水线 (Pipeline)
FAST 将一段动作块(Action Chunk)转化为 Token 的具体步骤如下:
-
归一化 (Normalization): 使用 1% 到 99% 分位数将原始动作数值映射到 [ − 1 , 1 ] [-1, 1] [−1,1] 之间,消除不同机器人量纲和离群点的影响。
-
离散余弦变换 (DCT): 对每个动作维度的序列单独进行 DCT 变换。由于自然动作通常是平滑的,变换后能量会高度集中在低频系数上。
-
量化 (Quantization): 引入缩放因子 γ \gamma γ(超参数),将连续的频域系数乘以 γ \gamma γ 后取整。此步会使大量不重要的高频系数直接变为 0。
-
频率优先展平 (Frequency-first Flattening): 按照“先所有维度的低频,再所有维度的高频”顺序将矩阵展平。这让模型在预测时优先决定动作的整体轮廓。
-
BPE 压缩 (Byte Pair Encoding): 使用 NLP 中常用的 BPE 算法将经常出现的整数序列(如连续的 0)合并为单个 Token,进一步提升压缩率。
3. 具体数学公式推导
假设动作序列长度为 H H H(如 1 秒钟内包含 50 个步长),动作维度为 D D D。
(1) 频域转换 (DCT)
频域转换的核心思想是:与其描述每一毫秒手在哪,不如描述这个动作的“成分”是什么。
为什么要转换?(时域的烦恼)
想象你要教一个机器人**“伸手抓杯子”**,这个动作持续 1 秒钟。
在电脑里,这个动作被切成了 50 份(50Hz):
第 1 毫秒:手在 10.0cm 处
第 2 毫秒:手在 10.1cm 处
第 3 毫秒:手在 10.2cm 处
我们可以把任何一个平滑的动作,拆解成不同“速度”的波动组合:
- 低频成分(动作的大轮廓): “手整体向前移动了 20 厘米。”(这是动作的基调)
- 中频成分(动作的微调): “在移动过程中,手腕稍微旋转了 30 度。”(这是动作的细节)
- 高频成分(动作的抖动): “手指尖有 0.1 毫米的细微颤动。”(这是动作的噪声)
DCT(离散余弦变换)干的活就是: 把那 50 个极其相似的坐标点,变成 50 个描述成分的系数。
频域转换(DCT)是基于傅里叶变换的一个分支。
- 傅里叶提出:任何一段信号(比如机器人的手臂移动轨迹),都可以看作是许多个不同频率的简谐波(波浪线)叠加而成的。
- 在处理图像和动作这种“一段一段”的数据时,**余弦变换(DCT)**比普通的傅里叶变换更有效。
公式推导:
计算当前的动作序列 at与某个标准余弦波的“相似度”。
对于第 i i i 个维度的动作序列 a 1 : H i = [ a 1 i , a 2 i , … , a H i ] a^i_{1:H} = [a^i_1, a^i_2, \dots, a^i_H] a1:Hi=[a1i,a2i,…,aHi],其第 j j j 个 DCT 系数 C j i C^i_j Cji 的计算公式为:
C j i = w j ∑ t = 1 H a t i cos ( π ( 2 t − 1 ) ( j − 1 ) 2 H ) , j = 1 , … , H C^i_j = w_j \sum_{t=1}^{H} a^i_t \cos \left( \frac{\pi (2t-1)(j-1)}{2H} \right), \quad j=1, \dots, H Cji=wjt=1∑Haticos(2Hπ(2t−1)(j−1)),j=1,…,H
其中权重系数 w j w_j wj 定义为:
w j = { 1 H , j = 1 2 H , j > 1 w_j = \begin{cases} \sqrt{\frac{1}{H}}, & j=1 \\ \sqrt{\frac{2}{H}}, & j > 1 \end{cases} wj=⎩
⎨
⎧H1,H2,j=1j>1
- 频率项 (j−1):
- 当j=1 时,cos(0)=1。这计算的是动作的平均值(直流分量)。
- 随着j 增大,波变得越来越快(频率越来越高)。
- 采样项 (2t−1) 和分母 2H:
- 这是为了确保波在 H 个点内正好完成半个或整数个周期。
- (2t−1) 是一个数学上的偏移,确保采样点刚好落在每一小段动作的“中心”,避免计算偏差。
- 累加 ∑:
- 把动作序列里的每个点和余弦波上的对应点相乘再加起来。
- 物理意义: 如果动作的走势和这个波的走势非常接近,加出来的结果(系数 Cj)就会很大;如果不像,结果就会接近 0。
- 这个系数 wj 是为了满足正交性。
- 简单来说: 转换前后的总能量(数字的大小规模)必须保持一致。
- 它确保了你把动作变到频域、再变回时域后,数值不会莫名其妙地变大或变小。
(2) 量化与稀疏化
利用缩放因子 γ \gamma γ 对连续系数进行离散化,生成整数序列:
C ˉ j i = round ( γ ⋅ C j i ) \bar{C}^i_j = \text{round}(\gamma \cdot C^i_j) Cˉji=round(γ⋅Cji)
推导意义: 经过取整后,大部分代表噪声或微小抖动的高频系数会变为 0 0 0,从而实现极大的有损压缩。
(3) BPE 序列化
将序列中出现频率较高的词汇打包成新的token,FAST自己训练的BPE模型
将量化后的矩阵 C ˉ \bar{C} Cˉ 按照频率优先顺序排成一维整数序列 T T T:
T = [ C ˉ 1 1 , C ˉ 1 2 , … , C ˉ 1 D , … , C ˉ H 1 , … , C ˉ H D ] T = [\bar{C}^1_1, \bar{C}^2_1, \dots, \bar{C}^D_1, \dots, \bar{C}^1_H, \dots, \bar{C}^D_H] T=[Cˉ11,Cˉ12,…,Cˉ1D,…,CˉH1,…,CˉHD]
最后通过预训练好的 BPE 映射函数 ϕ \phi ϕ 得到最终发送给模型的 Token:
Tokens = BPE ( T , ϕ ) \text{Tokens} = \text{BPE}(T, \phi) Tokens=BPE(T,ϕ)
4. FAST实验结果
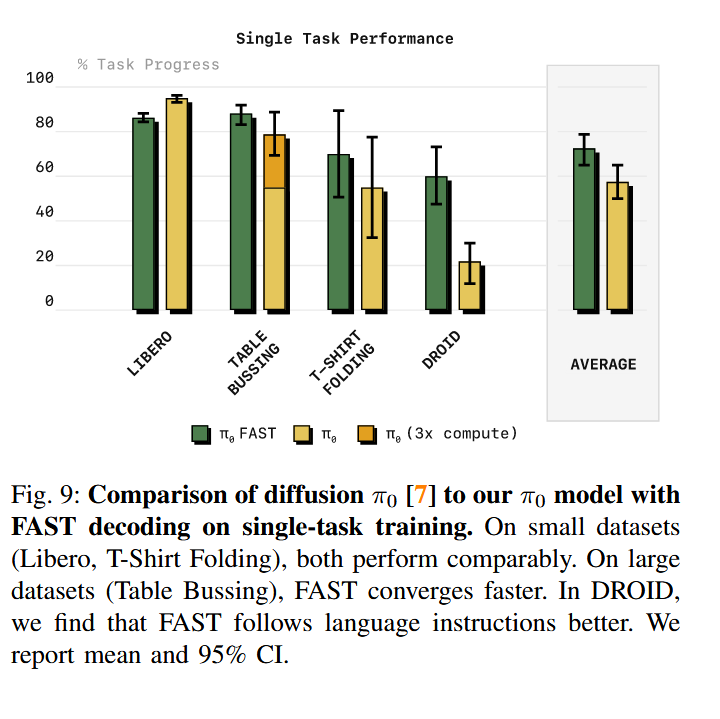
| 任务名称 | 环境 | 控制频率 | 核心挑战 | 在 FAST 论文中的意义 | 数据集内容 |
|---|---|---|---|---|---|
| LIBERO | 模拟器 | 10 Hz | 任务切换 | 基础性能评估,验证模型在标准仿真环境下的稳定性。 | 包含一系列厨房场景的操作。例如:把锅盖盖上、把物体放进碗里、把碗放进柜子等。 |
| DROID | 真实世界 | 15 Hz | 场景多样性 | 测试通用性与零样本(Zero-shot)能力,看模型能否在陌生环境下工作。 | 它不是单一的任务,而是包含了成千上万种日常操作(开关抽屉、擦桌子、拿杯子等),由全球多个实验室合作完成。 |
| TABLE BUSSING | 真实世界 | 20 Hz | 分类与精度 | 测试逻辑推理(餐具 vs 垃圾)与真实物理操作的结合。 | 机器人需要清理一张杂乱的餐桌。它必须区分什么是“垃圾”(丢进垃圾桶),什么是“餐具”(丢进洗碗盆)。 |
| T-SHIRT FOLDING | 真实世界 | 50 Hz | 高频冗余 | 核心突破点:证明在高频、高冗余任务下,必须使用频域压缩才能实现有效训练。 | 机器人从平铺状态开始,将一件 T 恤衫对折好。 |
在高自由度上取得不错的效果,例如T-SHIRT FOLDING;其他任务上基本与π0相当,但也有些任务不如π0,并不是所有任务碾压级的存在。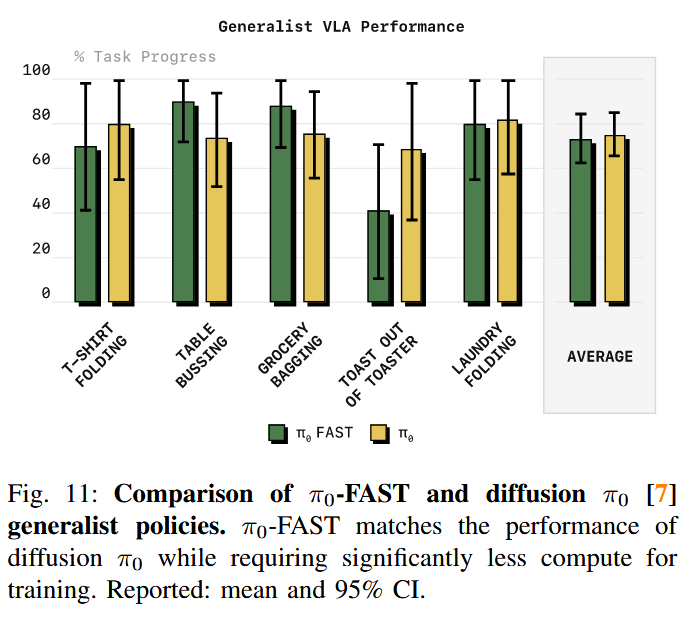
FAST 方法的表现稳定性 (依据论文 Figure 3)
在模拟插值任务的实验中,作者对比了不同频率下的重建误差:
| 频率范围 (Sampling Frequency) | 传统方法 (Naive Binning) 表现 | FAST (DCT) 方法表现 |
|---|---|---|
| 0 Hz 到 800 Hz | 误差随频率升高大幅飙升 ( 10 − 1 → 10 0 10^{-1} \to 10^0 10−1→100) | L2 误差始终稳定在 10 − 2 10^{-2} 10−2 到 10 − 3 10^{-3} 10−3 水平 |
- 抗高频干扰能力极强:传统分词方法在频率升高时会迅速失效(因为 Token 间相关性太强),而 FAST 凭借 DCT 变换成功提取了核心频率成分。
- 重建精度极高: 10 − 3 10^{-3} 10−3 级别的误差意味着在物理执行中,重建动作与原始动作的偏差仅为总量程的千分之一(例如:1 米的量程内误差仅为 1 毫米),这种误差对机器人操作而言是微不可察且极其丝滑的。
总结
| 特性 | 原始 π 0 \pi_0 π0 (Black et al.) | π 0 \pi_0 π0-FAST (Pertsch et al.) |
|---|---|---|
| 生成机制 | 流匹配 (Flow Matching / Diffusion) | 自回归 (Autoregressive) |
| 动作表示 | 连续数值 (Continuous) | 频域压缩 Token (FAST Tokens) |
| 训练计算量 | 高 (1.0x 基准) | 极低 (0.2x / 5倍加速) |
| 收敛速度 | 较慢 | 极快 |
| 推理延迟 | 约 100ms (快) | 约 750ms (较慢) |
5. FAST 的主要优势
- 极高的压缩率: 在 50Hz 控制频率下,Token 数量比传统分箱方法减少了 13.2 倍。
- 训练大幅提速: 在相同任务性能下,训练速度比 Diffusion版本的模型快 5 倍。
- 精细动作增强: 摆脱了时域上的高度冗余,使模型能够关注真正重要的动作变化,从而学会折衣服、组装纸箱等复杂任务。
- 通用分词器 (FAST+): 作者发布了基于 100 万条真实机器人轨迹预训练的通用分词器,支持单臂、双臂、移动底盘等多种形态。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)