告别“炼丹”微调:GenoJEPA用语义对齐解锁“即插即用”的基因组特征
论文信息
标题:From nucleotides to semantics: genomic representation learning via joint-embedding predictive architecture
期刊/会议:genome as
发表时间:2026-03-22
论文链接:https://doi.org/10.64898/2026.04.02.716255
告别“炼丹”微调:GenoJEPA用语义对齐解锁“即插即用”的基因组特征
想象一下,你是一位生物学家,手头有一批珍贵的基因序列数据,想快速预测哪些区域是调控基因表达的“开关”(增强子),或者识别可能导致疾病的罕见突变。传统上,你需要一个庞大的、预训练好的基因组AI模型,但麻烦的是,这个模型就像一个需要精心调校的精密仪器——你必须投入大量的计算资源(通常是昂贵的GPU)和专业知识,对模型进行“微调”,才能让它适应你的具体任务。这个过程不仅耗时耗力,更将无数资源有限的实验室挡在了基因组AI应用的大门之外。
现在,一项来自北京邮电大学的研究可能正在改变这一局面。他们提出的GenoJEPA框架,让预训练好的基因组模型能够像一台“即插即用”的特征提取器:模型参数完全冻结,你只需接上一个简单的逻辑回归分类器,就能在55项涵盖跨物种分类、调控元件识别、表观遗传标记预测等任务上,取得媲美甚至超越那些需要“炼丹”式微调的庞大模型的性能。这意味着,普通实验室用一台普通的CPU电脑,就能利用最前沿的基因组AI能力。
一句话速览
北京邮电大学团队提出GenoJEPA,一种基于联合嵌入预测架构的基因组表示学习新范式。它通过在隐空间进行语义对齐而非重建单个核苷酸,使模型能直接输出高质量、可迁移的特征。在资源受限场景下,冻结的GenoJEPA配合轻量级分类器,即可在多项任务上超越或比肩参数量大百倍的基线模型,为基因组基础模型的普惠应用铺平道路。
背景与痛点:当“语言模型”遇见“基因组图像”
要理解GenoJEPA的突破,得先看看它要解决什么问题。近年来,受自然语言处理(NLP)巨大成功的启发,许多基因组基础模型(如DNABERT、Nucleotide Transformer)将DNA序列视为由A、T、C、G四个“字母”写成的“生物语言”。它们采用掩码语言建模(MLM)或下一词预测(NTP)等目标进行预训练,即让模型去猜测被遮盖的“词”(可能是几个核苷酸组成的k-mer)是什么。
但基因组真的是一种“语言”吗? 论文指出了关键区别:人类语言是高度精炼、信息密集、且有明确词汇边界的人工系统。而基因组序列更像是一张自然图像——它由自然过程产生,缺乏明确的语义边界,并且信噪比很低(大量序列是中性进化留下的“噪音”或“垃圾DNA”)。
强迫模型在低维的离散空间(即原始的A/T/C/G序列)去精确重建每一个被掩码的核苷酸,就像让一个图像识别模型去精确复原一张照片里每个被遮挡的像素点的RGB值。模型可能会把大量“算力”浪费在拟合那些与核心生物功能无关的高频细节和进化噪音上。这导致一个后果:预训练得到的特征表示判别力不足,下游任务严重依赖昂贵的全参数微调。一个参数量达数亿的模型,微调起来动辄需要多张高端GPU,这让许多生物实验室望而却步。
核心方法:从“像素重建”到“语义对齐”
GenoJEPA的核心思想,是摒弃“语言建模”的类比,拥抱“视觉表示学习”的新范式。它不再让模型去猜被掩盖的“字母”,而是学习一个更本质的东西:不同视角下的序列,其核心语义特征在隐空间中应该是一致的。
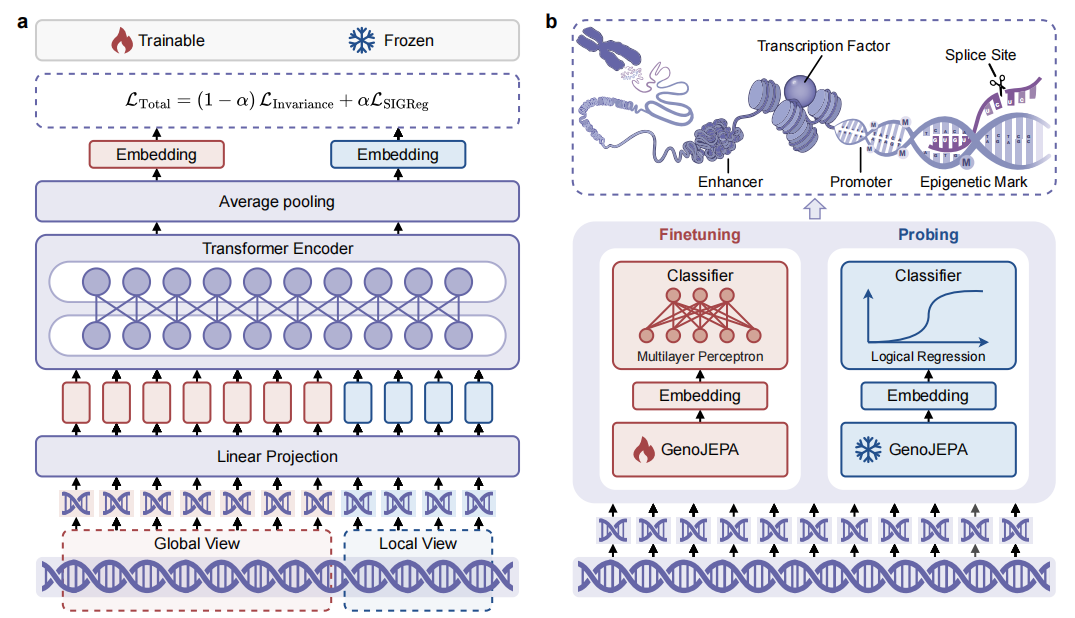
1. 连续分块:像处理图像一样处理DNA 首先,GenoJEPA改变了DNA的“输入法”。传统方法使用k-mer或BPE分词,会带来词汇表膨胀和对单点突变过于敏感的问题。GenoJEPA借鉴计算机视觉中的ViT思想,采用连续分块策略:将DNA序列切成不重叠的片段(如每16个核苷酸为一个“块”),然后通过线性投影,直接将每个块映射为一个连续的稠密向量。这避免了离散词汇表,保留了块内的生化依赖关系,并大幅压缩了序列长度。
2. 联合嵌入预测架构:学习“不变性” 这是GenoJEPA的灵魂。对于同一段DNA序列,模型通过随机裁剪生成多个“视角”:包括捕捉全局结构的“全局视角”(裁剪原序列的65%-80%)和聚焦局部模式的“局部视角”(裁剪35%-40%)。这些不同视角的序列都输入同一个编码器(一个基于ModernBERT的Transformer),得到各自的序列表示。
关键的目标函数来了:模型不再要求重建原始序列,而是要求所有视角的表示,在隐空间中都向“全局视角表示的平均值”对齐。用一个公式中的核心部分来理解:
L_Invariance = 1/|V| * Σ ||z_v - z̄_global||²
这里,z_v 是任一视角的表示,z̄_global 是所有全局视角表示的平均值(作为语义锚点)。这个不变性损失迫使模型忽略由裁剪带来的局部序列变化(可视为一种数据增强噪音),专注于提取那些在不同视角下都保持稳定的、高层次的语义特征。
3. 防止“表征坍塌”:理论驱动的正则化 如果只做对齐,所有输入可能会被映射到同一个点,这叫“表征坍塌”。GenoJEPA采用了一个理论驱动的正则化项——SIGReg。它巧妙地通过随机投影和特征函数测试,引导隐空间中的特征分布趋向于一个各向同性的高斯分布。这确保了特征既具有语义一致性,又保持了足够的多样性和可分性,为下游分类任务打下了良好基础。
最终,总损失是不变性损失和SIGReg正则化损失的加权和。整个训练过程无需动量编码器、停止梯度等启发式技巧,更加简洁稳定。
实验结果:“小模型”的“大能量”
研究团队在涵盖55个子任务的三大标准基因组评测集上,将GenoJEPA与5个代表性基线模型(HyenaDNA、CaduceusPh、GROVER、DNABERT-2、NT-v2)进行了全面对比。结果令人印象深刻。
1. 冻结探测:即插即用的特征提取器 这是最能体现GenoJEPA实用价值的测试。所有预训练模型参数完全冻结,仅用其提取的特征训练一个逻辑回归分类器(可在CPU上运行)。
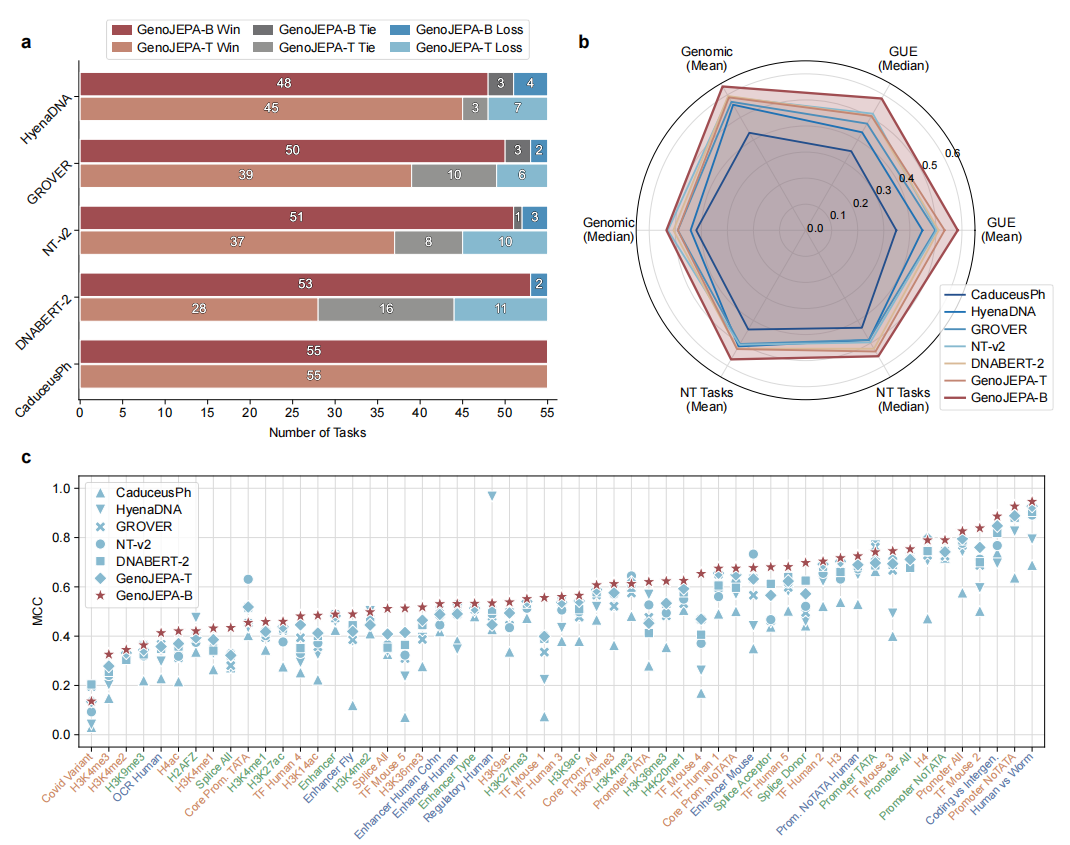
结果如图2所示,参数量仅5200万的GenoJEPA-B,在55个任务的整体探测性能上排名第一。更惊人的是,参数量仅600万的“轻量版”GenoJEPA-T,其探测性能竟与参数量近5亿、使用相同多物种数据预训练的NT-v2模型不相上下,甚至在多数任务上胜出。这意味着,GenoJEPA用百分之一甚至千分之一的参数量,学到了判别力更强的“冻结”特征。
2. 全参数微调:依然竞争力十足 当允许全参数微调时(如图3),GenoJEPA-B的平均性能超越了所有基线。GenoJEPA-T也大幅超越了参数量相近的HyenaDNA和CaduceusPh,甚至超过了参数量大10倍以上的GROVER。这表明,即使在追求极致性能的场景下,GenoJEPA学到的初始权重也提供了更优的起点。
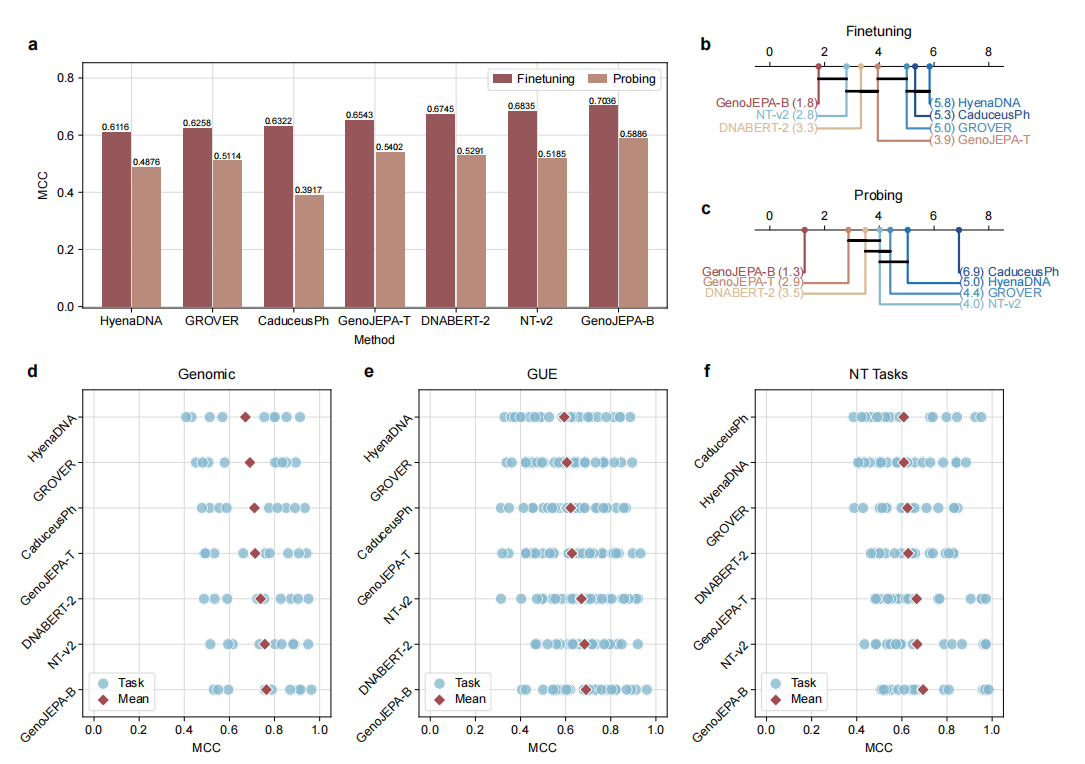
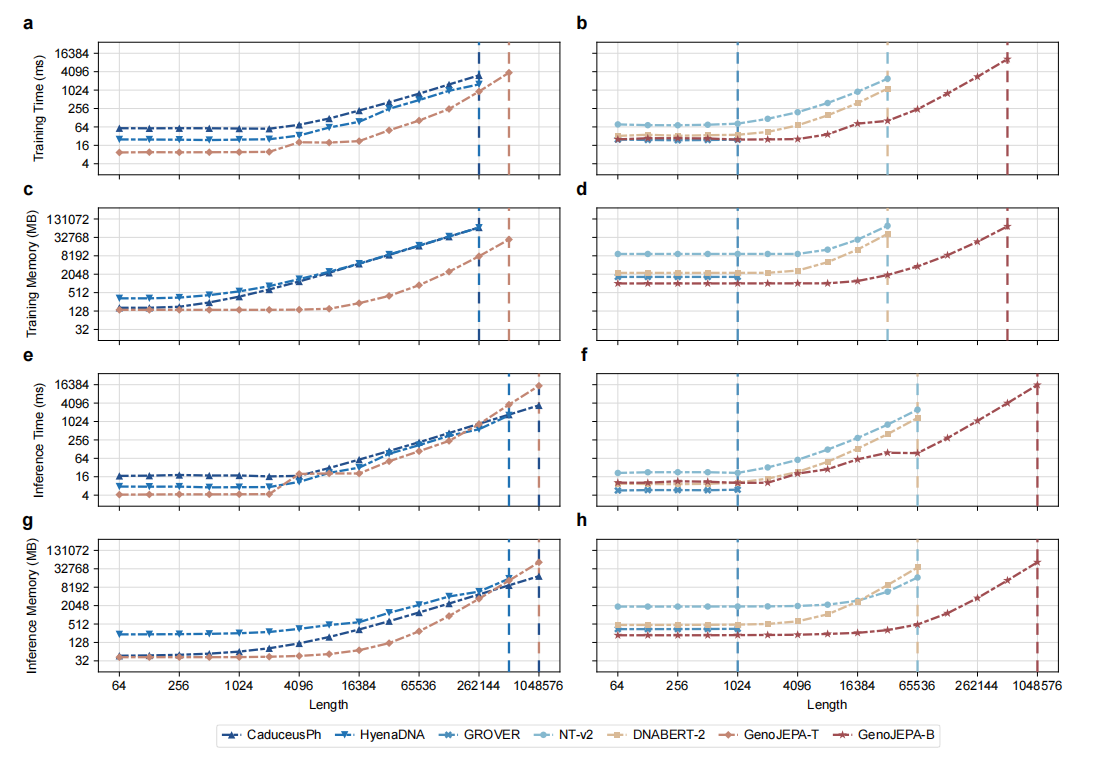
3. 效率与数据需求:务实的选择 在计算和内存效率测试中(图4),GenoJEPA表现出了出色的稳定性。尤其是在与同样为轻量级设计的CaduceusPh和HyenaDNA对比时,GenoJEPA-T在大多数序列长度下,训练和推理的内存占用更低、速度更快,打破了“理论复杂度低等于实际效率高”的迷思。
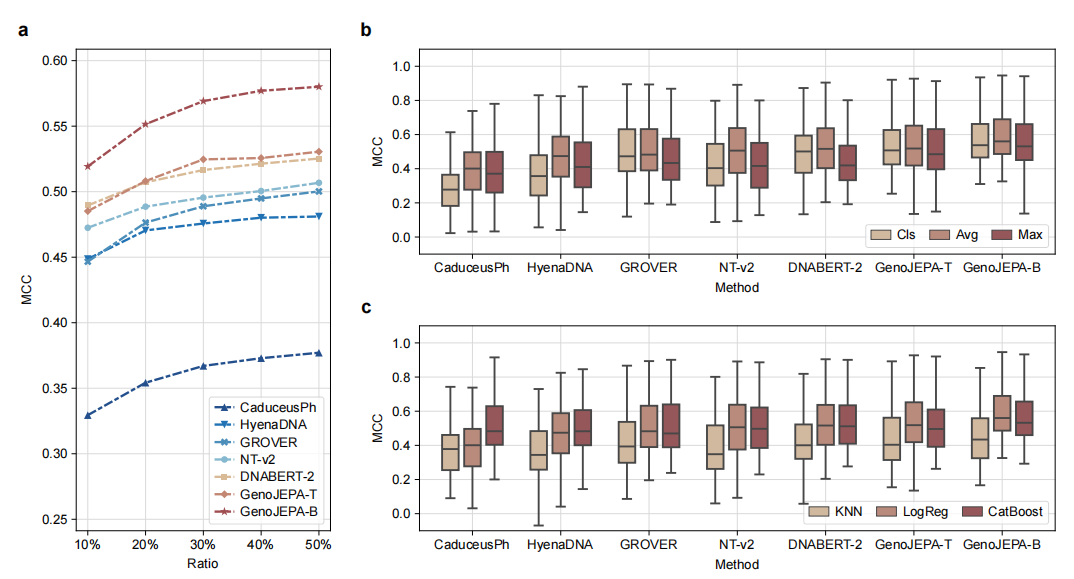
此外,在少样本学习测试中(图5a),GenoJEPA仅用10%的训练数据,就能达到其他基线模型使用50%甚至100%数据时的性能,展现了强大的数据效率。
意义与展望:通往普惠基因组AI的路径
GenoJEPA工作的意义,远不止于又一项刷榜的SOTA模型。
首先,它验证了基因组表示学习新范式的有效性。 将DNA序列视为“自然图像”而非“语言”,采用隐空间语义对齐而非离散符号重建,这条路径被证明能更高效地提取具有生物学意义的、可迁移的语义特征。这为未来基因组基础模型的设计提供了新的方向。
其次,也是最重要的,它极大地降低了基因组AI的应用门槛。 “冻结模型+轻量级分类器”的可行性与强大性能,使得广大计算资源有限的生物医学实验室、临床机构能够真正地将前沿的基因组基础模型用于自己的研究。特征提取可以在云端完成,分析可以在本地笔记本电脑上进行,这构建了一种全新的、普惠的工作流。
潜在应用场景广泛:
-
临床变异解读:快速筛查基因组数据中的致病性突变。
-
调控元件挖掘:在没有昂贵实验验证的情况下,初步预测非编码区的增强子、启动子等。
-
跨物种比较基因组学:利用模型学到的跨物种保守特征,研究基因调控网络的进化。
-
药物靶点发现:分析基因序列与特定表型(如疾病、药物反应)的关联。
局限性与未来方向
当然,这项工作也有其局限。目前预训练的序列长度最长为4096bp,这虽然覆盖了大多数基因尺度的任务,但对于需要更长程依赖分析(如拓扑关联域边界识别)的任务仍显不足。此外,最大的GenoJEPA-B模型参数量为5200万,探索更大规模模型的缩放规律将是未来的重点。论文中展示的效率优势,为向更长上下文、更大模型规模的扩展提供了乐观的预期。
结语
GenoJEPA的出现,标志着基因组AI领域的一个务实转向:从一味追求模型规模和微调性能,到同时关注模型的可部署性、实用性和普惠价值。它告诉我们,有时换一种视角看问题——把DNA看作图像而非文本,并调整学习的目标——从重建细节到对齐语义,就能以小博大,释放出巨大的潜力。
这项研究也引发了一个更深层的思考:我们长期以来套用NLP范式来理解基因组,是否在某种程度上限制了我们捕捉其本质生物学逻辑的想象力?GenoJEPA借鉴了计算机视觉的思想,那么,未来是否会有受其他学科(如信号处理、复杂系统)启发的新范式,能进一步揭开基因组这部“天书”更深奥的语法呢?在你看来,解码生命之书,我们最需要从哪个领域汲取下一个灵感?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)