LangChain开发框架,Model I/O,Chains,RAG流程,agent,添加记忆,MCP,多Agent案例
目录
2、 RecursiveCharacterTextSplitter
将多个Streamable HTTP服务器挂载到ASGI服务器
github地址:https://github.com/langchain-ai/langchain
官网地址:https://www.langchain.com/langchain
官方文档:https://docs.langchain.com/oss/python/langchain/overview
API文档:https://reference.langchain.com/python/langchain/
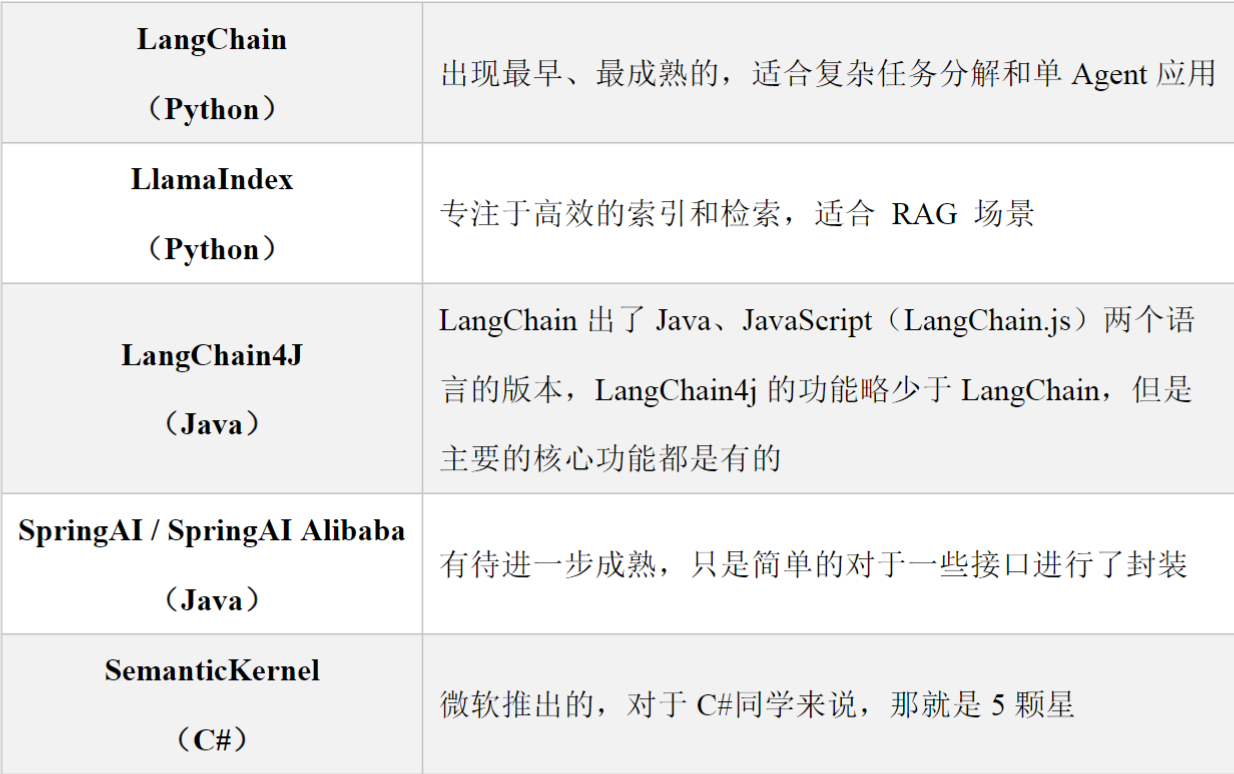
一、LangChain概述
LangChain是2022年10月,由哈佛大学的Harrison Chase(哈里森·蔡斯)发起研发的一个开源框
架,用于开发由大语言模型(LLMs)驱动的应用程序。比如,搭建Agent、问答系统(QA)、对
话机器人、文档搜索系统等。
LangChain是一个帮助你构建LLM应用的全套工具集。这里涉及到prompt构建、LLM接入、记忆管
理、工具调用、RAG、Agent开发等模块。
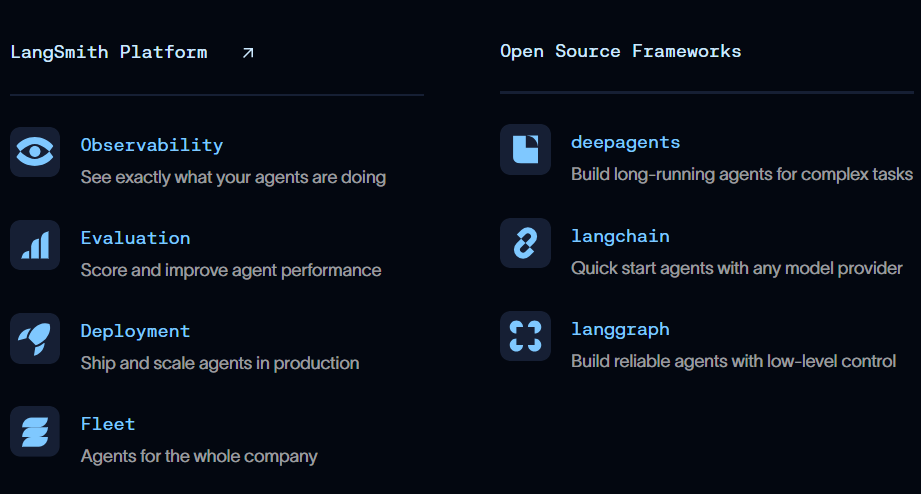
LangChain:快速搭建 Agent,灵活适配任意模型提供商。
LangGraph:精细编排 Agent 流程,支持记忆、人工介入与长时间任务管理。
LangSmith:持续测试与改进 AI 的集成平台,提供观测、评估与部署能力。
Deep Agents:构建可规划、调用子 Agent 并操作文件系统的复杂 Agent,灵感源自 Claude Code、Deep Research 与 Manus 等应用。
1、开发架构与开发场景
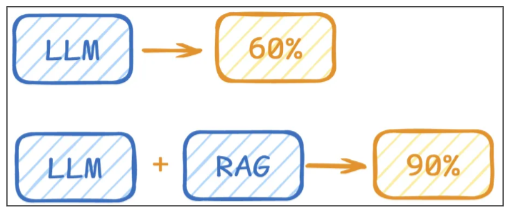
1、RAG开发
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了,而此时RAG给了一些
提示和参考,让LLM根据参考回答,最终考试的正确率从60%到了90%!
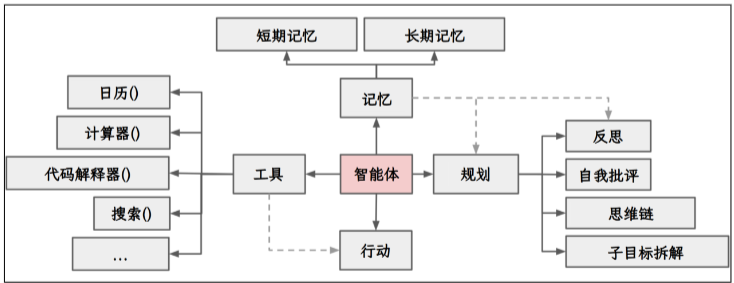
2、Agent开发
充分利用LLM的推理决策能力,通过增加规划、记忆和工具调用的能力,构造一个能够独立思考、
逐步完成给定目标的Agent。
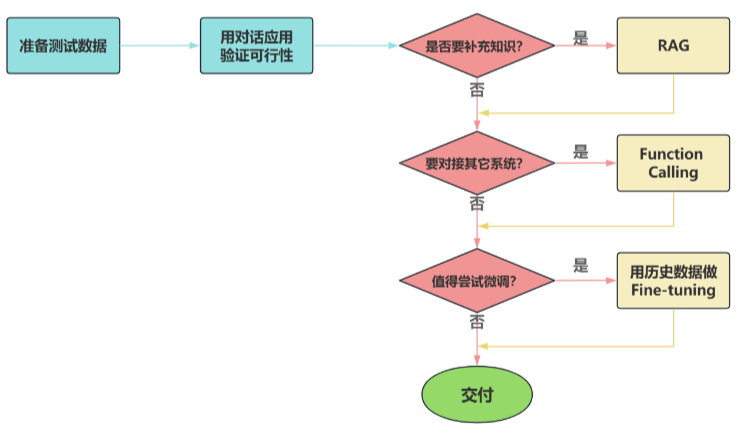
3、大模型应用开发的4个场景
1 纯 Prompt
通过自然语言与模型交互,一问一答。
2 Agent + Function Calling
Agent 主动提出调用外部功能的需求由 Function Calling 对接外部系统。例如询问天气时,Agent 先引导获取天气信息,再给出建议。
3 RAG(检索增强生成)
通过向量化、向量数据库与相似度检索,从外部知识库中查找相关内容辅助生成回答。广泛用于智能客服,类比考试时查阅资料再作答。
4 微调(Fine-tuning)
在模型基础上进行定制训练,使其长期掌握特定知识或能力。成本最高,仅当前述方式无法满足需求时使用。
2、核心组件
Model I/O、Chains、RAG、Agents。
二、Model I/O
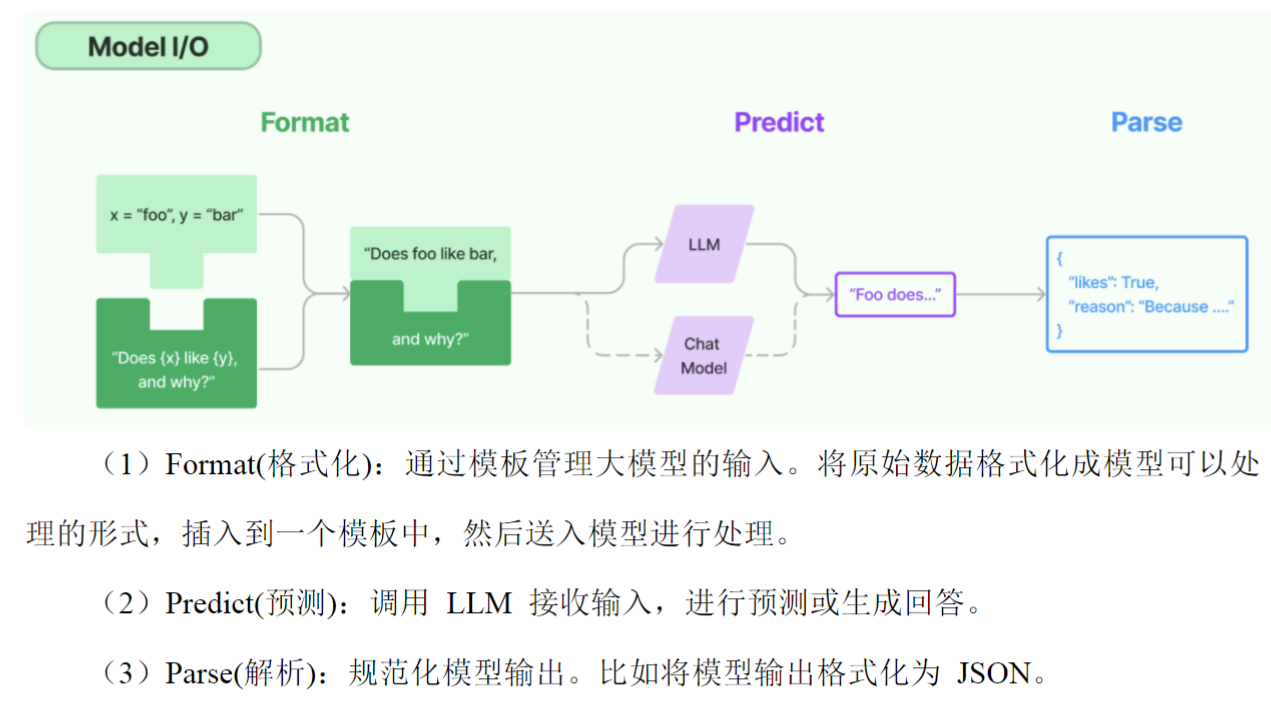
1、大模型在线平台
1)CloseAI:https://platform.closeai-asia.com/
API-Key管理:https://platform.closeai-asia.com/developer/api
API文档:https://doc.closeai-asia.com/tutorial/api/openai.html
模型:https://platform.closeai-asia.com/pricing
2)OpenRouter:https://openrouter.ai/
API-Key管理:https://openrouter.ai/settings/keys
API文档:https://openrouter.ai/docs/community/frameworks-and-integrations-overview
模型:https://openrouter.ai/models
3)阿里云百炼:https://bailian.console.aliyun.com/
API-Key管理:https://bailian.console.aliyun.com/?tab=model#/api-key
API文档:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model
模型:https://bailian.console.aliyun.com/?tab=model#/model-market/all
4)百度千帆:https://console.bce.baidu.com/qianfan/overview
API-Key管理:https://console.bce.baidu.com/qianfan/ais/console/apiKey
API文档:https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
模型:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
5)硅基流动:https://www.siliconflow.cn/
API-Key管理:https://cloud.siliconflow.cn/me/account/ak
API文档:https://docs.siliconflow.cn/cn/userguide/capabilities/text-generation
模型:https://cloud.siliconflow.cn/me/models
2、OpenAI SDK调用模型
1、直接把配置写死
from openai import OpenAI
api_key = "sk-2a44cf0e0e4e438d8c37e770269efc95"
api_base_url = "https://api.deepseek.com"
client = OpenAI(
api_key=api_key,
base_url=api_base_url,
)
response =client.chat.completions.create(model = 'deepseek-chat',messages = [{"role": "system", "content": "You are a helpful assistant."}])
print(response.choices[0].message.content)2、把配置写到环境里
写到环境变量里,然后文件目录选择当前文件
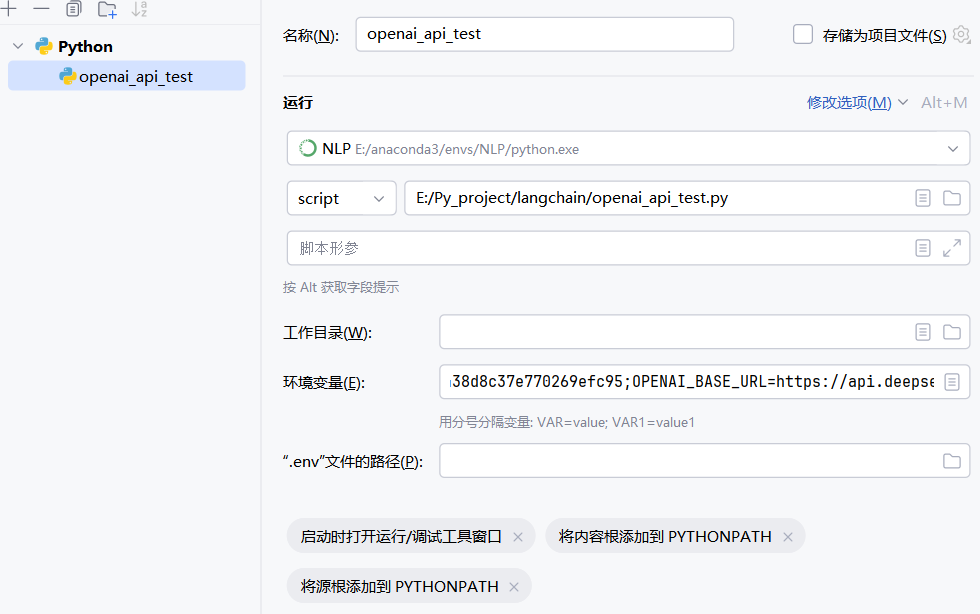
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_URL"),3、通过配置文件配置(推荐)
OPENAI_API_KEY = sk-2a44cf0e0e4e438d8c37e770269efc95
OPENAI_BASE_URL = https://api.deepseek.comfrom openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
openai_api_key = os.getenv('OPENAI_API_KEY')
openai_base_url = os.getenv('OPENAII_BASE_URL')
client = OpenAI(
api_key=openai_api_key,
base_url=openai_base_url,
)
response =client.chat.completions.create(model = 'deepseek-chat',messages = [{"role": "system", "content": "hello."}])
print(response.choices[0].message.content)3、langchain大模型API调用
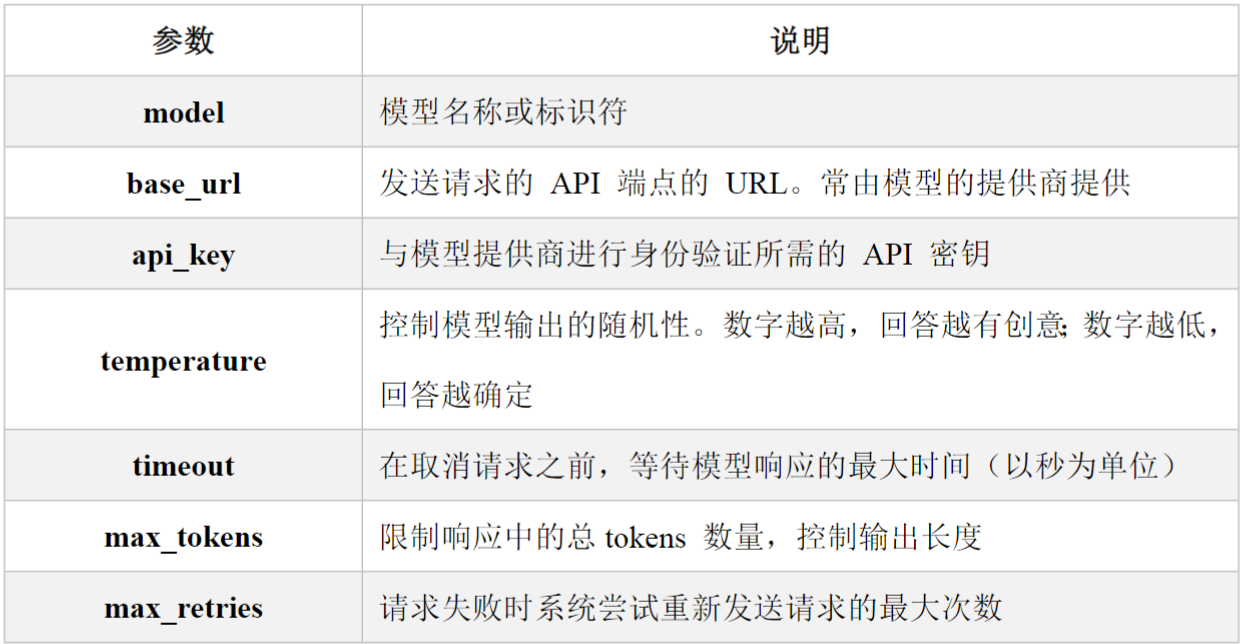
init_chat_model参数
from langchain.chat_models import init_chat_model
from langchain_core.messages import AIMessage,SystemMessage,HumanMessage
import dotenv
import os
dotenv.load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
# 获取大模型实例
model = init_chat_model(
model = 'deepseek-chat',
model_provider = 'deepseek',
api_key=api_key,
base_url = base_url
)
# 构造一个提示词模板
message = [
SystemMessage(content = "你是一个智能助手,可以帮助用户解决问题,你的名字叫小智"),
HumanMessage(content = '你是谁')
]
# 调用model的invoke方法
response = model.invoke(message)
print(response.content)4、Message
构造消息的几种方式
1、直接使用文本
![]()
2、使用HumanMessage等类的方式构建消息列表
message = [
SystemMessage(content = "你是一个智能助手,可以帮助用户解决问题,你的名字叫小智"),
HumanMessage(content = '你是谁')
]
# 调用model的invoke方法
response = model.invoke(message)
print(response.content)3、通过字典的方式构建消息列表
message = [
{'role':'system','content':'你是一个智能助手,可以帮助用户解决问题,你的名字叫小智'},
{'role':'human','content':'你是谁'},
]
# 调用model的invoke方法
response = model.invoke(message)
print(response.content)5、调用方法

1、非流式输出
这是LangChain与LLM交互时的默认行为,是最简单、最稳定的语言模型调用方式。当用户发出请
求后,系统在后台等待模型生成完整响应,然后一次性将全部结果返回。
response = model.invoke(message)
print(response.content)2、流式输出
返回一个generator
response = model.stream(message)
for chunk in response:
print(chunk.content,end='')
print(response)
你好!我是小智,一个智能助手,随时准备为你提供帮助。无论是回答问题、解决问题,还是陪你聊天,我都在这里!有什么我可以为你做的吗? 😊<generator object BaseChatModel.stream at 0x000002096C888400>3、批量输出
messages = [
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},],
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},],
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},],
]
response = model.batch(messages)
print(response[0].content)
《春日偶成》
东君执彩笔,泼洒到人间。
染绿千山树,催红万圃兰。
莺梭织烟柳,鱼影动春潭。
风暖衣衫薄,斜阳独倚栏。
注:我的仿写以传统手法勾勒春之画卷。通过“东君执笔”的意象,将自然造化喻为艺术创作,随后以“染绿”、“催红”展现春色的动态蔓延。颈联“莺梭”、“鱼影”赋予生灵精巧的灵动感,尾联在暖风与斜阳中收束于闲适的独倚,暗合古典春诗里物我相融的审美意趣。4、同步/异步调用
同步调用:多次请求串行处理
messages = [
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},],
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},],
[{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},],
]
import time
start_time = time.time()
response = [model.invoke(messages) for messages in messages]
end_time = time.time()
print(f'总耗时:{end_time - start_time}')
总耗时:15.489471912384033异步调用:model.invoke方法,返回一个协程对象,把多个协程对象打包成一个协程对象,await
最终协程对象,实现异步调用。
import time
import asyncio
async def gather_task(message:list):
tasks = [model.ainvoke(message_list) for message_list in message]
return await asyncio.gather(*tasks)
async def main():
start_time = time.time()
results = await gather_task(messages)
end_time = time.time()
print(f'总耗时{end_time - start_time}')
asyncio.run(main())
总耗时6.7416629791259775、拓展协程案例
import asyncio
async def func1():
print('func1 开始')
await asyncio.sleep(3)
print('func1 结束')
async def func2():
print('func2 开始')
await asyncio.sleep(5)
print('func2 结束')
async def func3():
print('func3 开始')
await asyncio.sleep(8)
print('func3 结束')
async def main():
await asyncio.gather(func1(), func2(), func3())
import time
start = time.time()
asyncio.run(main())
end = time.time()
func1 开始
func2 开始
func3 开始
func1 结束
func2 结束
func3 结束6、调用本地模型Ollama
Ollama官方地址:https://ollama.com
Ollama Github开源地址:https://github.com/ollama/ollama
pip install langchain-ollama首先要在ollama中下载好模型,也可以在ollama的setting中加载已经下好的模型。
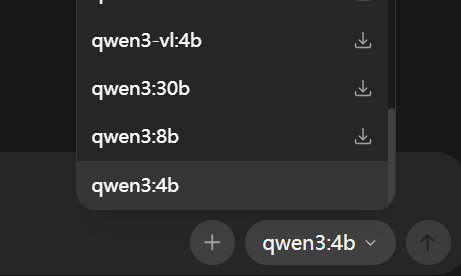

model中的模型id必须和ollama中的一样,base_url如果不写就是默认部署在本机。
from langchain_ollama import ChatOllama
# 构造ollama客户端实例
ollama = ChatOllama(
model = 'qwen3:4b',
base_url = 'xxx',
)
ollama.invoke('你好')7、PromptTemplate的实例化和调用
两种实例化方式
from langchain_core.prompts import PromptTemplate
template1 = PromptTemplate(
template = '你是一个翻译助手,帮助用户将{content}翻译成语言:{lang}',
input_variables = ['content','lang']
)
response = template1.format(content = '什么是LangChain',lang = '英语')
template2 = PromptTemplate.from_template(
template = '你是一个翻译助手,帮助用户将{content}翻译成语言:{lang}'
)两种调用方式
response1 = template1.format(content = '什么是LangChain',lang = '英语')
response2 = template1.invoke({'content':'什么是langchain','lang':'英语'})一个简单综合案例
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import dotenv
import os
import base64
dotenv.load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
client = ChatOpenAI(
model = 'gpt-4o-mini',
api_key = api_key,
base_url = base_url,
)
def encode_image(image_path):
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_path = r"C:\Users\77485\Desktop\屏幕截图 2026-03-26 214358.png"
image_base64 = encode_image(image_path)
template = ChatPromptTemplate.from_messages([
("system", "用中文简短描述图片内容"),
("user", [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{image_base64}"
}
}
])
])
prompt = template.format_messages(
image_base64=image_base64
)
res = client.invoke(prompt)
print(res.content)
这张图片中有一个人穿着带有大星星图案的黑色上衣,搭配一件外套,头发披肩,看起来像是在参加某个活动或表演。背景是黑色的,给人一种时尚和活力的感觉。8、OutputParser
输出解析器:将大模型原始自然语言类型的输出,解析成程序所需要的结构化输出,以下是原始输
出案例。
from langchain_openai import ChatOpenAI
import dotenv
dotenv.load_dotenv()
openai_llm = ChatOpenAI(
model = 'gpt-4o-mini'
)
res = openai_llm.invoke('帮我推荐几部诺兰的电影')
print(res.content)
克里斯托弗·诺兰是一位备受赞誉的导演,以其复杂的叙事结构和出色的视觉效果著称。以下是几部他的代表作品推荐:
1. **《盗梦空间》(Inception, 2010)** - 这部影片围绕梦境与现实的界限展开,讲述了一组盗贼通过侵入他人梦境来盗取信息的故事。影片充满了心理学元素和视觉奇观。
2. **《黑暗骑士三部曲》**
- **《蝙蝠侠:侠影之谜》(Batman Begins, 2005)**
- **《蝙蝠侠:黑暗骑士》(The Dark Knight, 2008)**
- **《蝙蝠侠:黑暗骑士崛起》(The Dark Knight Rises, 2012)** - 这三部影片重新定义了超级英雄电影,特别是《黑暗骑士》,其对反派小丑的刻画备受赞誉。
3. **《记忆碎片》(Memento, 2000)** - 这是一部非线性叙事的惊悚片,讲述了一位失去短期记忆的男子在追寻妻子凶手过程中的故事,思维的复杂性令人深思。
4. **《超能查派》(Interstellar, 2014)** - 这部科幻电影探讨了时间、爱与人类求生的主题,描绘了一场跨越时空的宇宙冒险。
5. **《敦刻尔克》(Dunkirk, 2017)** - 这部影片以二战敦刻尔克大撤退为背景,通过多条时间线展示了士兵们的生存斗争,形式创新且充满紧张感。
6. **《信条》(Tenet, 2020)** - 这是一部涉及时间逆转的科幻动作片,讲述了特工如何利用时间的不同流向来阻止世界大战的故事。
这些电影各有特色,展示了诺兰在讲故事和视觉呈现方面的非凡才华。希望你会喜欢!1、JSONOutputParser
##通过pydantic类去定义JSON的结构并构造JsonOutputParser的实例
##在system_message中添加需要大模型按照json结构回复的prompt,添加方式通过output_parser.get_format_instructions,接下来大模型就可以回复一个json的字符串
##通过调用output_parser.invoke方法,可以更进一步将大模型输出的字符串解析成字典对象
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel,Field
from langchain_core.prompts import ChatPromptTemplate
# 构造实例
# 构造参数pydantic_object
# pydantic包的作用:定义一个数据结构schema
# jsonoutputpaser使用pydantic定义的数据结构来定义json当中的key有哪些,分别的结构是什么
class FilmSuggestion(BaseModel):
film_name : str = Field(description='电影名称')
year : str = Field(description='上映年份')
description : str = Field(description='电影概述')
output_paser = JsonOutputParser(pydantic_object=FilmSuggestion)
output_paser.get_format_instructions()
messages = [
('system','回答用户问题,按照以下形式做输出:{output_format}'),
('user','{user_question}')
]
template = ChatPromptTemplate.from_messages(
messages
)
llm_output = openai_llm.invoke(template.invoke({'output_format':output_paser.get_format_instructions(),'user_question':'帮我推荐几部诺兰的电影'}))
output_paser.invoke(llm_output)
{'film_name': '盗梦空间',
'year': '2010',
'description': '讲述了一名专业小偷通过潜入他人的梦境中窃取机密信息的故事。'}2、StrOutputParser
我们一般情况想要知道内容是调用.content方法,比如:
from langchain_core.output_parsers import StrOutputParser
str_output_parser = StrOutputParser()
res = openai_llm.invoke('你是谁')
print(res.content)
我是一个人工智能助手,旨在回答问题和提供信息。如果你有什么想了解的,欢迎问我!但是这样很不方便,所以可以使用StrOutputParser
from langchain_core.output_parsers import StrOutputParser
str_output_parser = StrOutputParser()
res = openai_llm.invoke('你是谁')
str_output_parser.invoke(res)
'我是一个人工智能助手,旨在回答问题和提供帮助。如果你有任何问题或需要了解的内容,随时问我!'3、大模型自身提供的Structured Output
structured_llm = openai_llm.with_structured_output(schema = FilmSuggestion)
structured_llm.invoke('帮我推荐几部诺兰的电影')
FilmSuggestion(film_name='盗梦空间', year='2010', description='讲述了一名专业盗梦者通过进入他人的梦境来窃取信息和植入思想的故事。电影探讨了现实与梦境的界限,视觉效果和复杂的叙事结构令人难以忘怀。')三、Chains
“链条”用于将多个组件组合成一个完整的流程,方便链式调用。
1、Runnable与LCEL
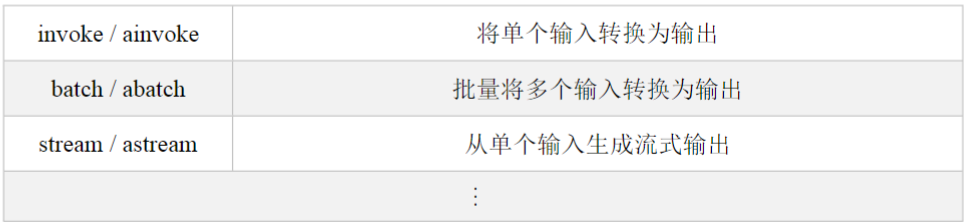
1、Runnable
Runnable是LangChain中可以调用、批处理、流式传输、转换和组合的工作单元。Runnable接口
是使用LangChain组件的基础,它在许多组件中实现,例如语言模型、输出解析器、检索器、编译
的LangGraph图等。
2、LCEL
LangChain表达式语言(LCEL,LangChain Expression Language)是一种从现有的Runnable构
建新的Runnable的声明式方法,通过“ | ”将langchain中的不同组件组装在一起构成一个chain。
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
import dotenv
dotenv.load_dotenv()
prompt_template = PromptTemplate(input_variables=['user_info'],template='{user_info}')
openai_llm = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt_template | openai_llm | output_parser
type(chain)
chain.invoke({"user_info": "你好"})
'你好!有什么可以帮助你的吗?😊'2、RunnableSequence
构造一个串行的执行链,通过runnable_sequence的实例调用invoke方法,就等于链当中每一个组
件去调用invoke,然后将调用结果传递给下一个组件。
from langchain_core.runnables import RunnableSequence
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
import dotenv
dotenv.load_dotenv()
prompt_template = PromptTemplate(input_variables=['user_info'],template='{user_info}')
openai_llm = ChatOpenAI()
output_parser = StrOutputParser()
runnable_sequence = RunnableSequence(*[prompt_template, openai_llm, output_parser])
runnable_sequence.invoke('你好,你是谁')
'你好,我是一个人工智能助手,可以和你聊天和回答问题。有什么我可以帮助你的吗?'3、RunnableParallel
from langchain_core.runnables import RunnableParallel
def fun1(a1):
return a1+'__func1_output'
def fun2(a1):
return a1+'__func2_output'
runnable_parallel = RunnableParallel({'key1': fun1, 'key2': fun2})
runnable_parallel.invoke('你好')
{'key1': '你好__func1_output', 'key2': '你好__func2_output'}具体应用:对于用户输入的同一个问题,我们想要调用不同的大模型进行回答,用户可以比对不同
大模型回答的效果。
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
from langchain_core.prompts import ChatPromptTemplate
openai_llm = ChatOpenAI(
model = 'gpt-4o-mini'
)
deepseek_llm = ChatDeepSeek(
model = 'deepseek-chat',
)
messages = [
('system','你是一个数学家'),
('user','{user_question}')
]
message_template = ChatPromptTemplate.from_messages(messages)
# 结合LCEL和RunnableParallel
chain = message_template | RunnableParallel({'openai_output': openai_llm,'deepseek_output': deepseek_llm})
chain.invoke({'user_question':'什么是哥德巴赫猜想'})
{'openai_output': AIMessage(content='哥德巴赫猜想是一个关于正偶数和素数的数学猜想,最早由德国数学家克里斯蒂安·哥德巴赫在1742年提出。它的表述可以描述为:\n\n任何一个大于2的偶数都可以表示为两个素数之和。\n\n例如:\n- 4 = 2 + 2\n- 6 = 3 + 3\n- 8 = 3 + 5\n- 10 = 5 + 5 或 7 + 3\n\n虽然这个猜想在许多偶数上得到了验证,并且计算机已检查到非常大的数值范围,但到目前为止,仍然没有被证明或反驳。哥德巴赫猜想是数学中最著名的未解难题之一,也是数论中的重要研究主题之一。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 185, 'prompt_tokens': 24, 'total_tokens': 209, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DPqbLvPitLDmvLjlwbFE39GlsmXI5', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019d4963-c8bb-7db3-ae77-7d358af7f056-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 24, 'output_tokens': 185, 'total_tokens': 209, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
'deepseek_output': AIMessage(content='哥德巴赫猜想是数论中一个著名的未解决问题,由德国数学家克里斯蒂安·哥德巴赫于1742年提出。该猜想的核心内容可以概括为:\n\n**“任何一个大于2的偶数都可以表示为两个素数之和。”**\n\n这个表述通常被称为“强哥德巴赫猜想”或“关于偶数的哥德巴赫猜想”。例如:\n- 4 = 2 + 2\n- 6 = 3 + 3\n- 8 = 3 + 5\n- 10 = 3 + 7 = 5 + 5\n- 100 = 3 + 97 = 11 + 89 = 17 + 83 等等。\n\n---\n\n### 历史背景与相关猜想\n哥德巴赫在与欧拉的通信中提出了两个相关猜想:\n1. **弱哥德巴赫猜想**(或“关于奇数的猜想”):任何大于5的奇数都可以表示为三个素数之和。这个猜想已在2013年由哈洛德·贺欧夫各特等人基本证明(依赖于广义黎曼猜想成立,或对足够大的奇数已无条件证明)。\n2. **强哥德巴赫猜想**(即通常所说的哥德巴赫猜想):如上所述,关于偶数的表述。\n\n---\n\n### 研究进展\n尽管猜想对大量偶数已验证成立(例如计算机已验证到 \\(4 \\times 10^{18}\\) 以内的偶数),但严格的数学证明仍未完成。主要进展包括:\n- **陈景润的工作(1973年)**:证明了“1+2”,即任何一个充分大的偶数都可以表示为一个素数及一个不超过两个素数的乘积之和。这是目前最接近强哥德巴赫猜想的结果。\n- **哈代-李特尔伍德圆法**:为解析数论中研究该猜想提供了重要工具。\n- **筛法的改进**:从布朗的“9+9”逐步推进到陈景润的“1+2”。\n\n---\n\n### 意义与挑战\n哥德巴赫猜想是加法数论的核心问题之一,涉及素数分布的深层结构。其证明可能需要全新的数学工具或对素数理论有更本质的理解。它不仅是数论的标志性难题,也常作为激励数学发展的源泉。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 455, 'prompt_tokens': 12, 'total_tokens': 467, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 12}, 'model_provider': 'deepseek', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache', 'id': 'acca0a80-a22d-4084-8e5d-b9124f48f955', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019d4963-c8be-7b50-908a-b8aa4be2013a-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 12, 'output_tokens': 455, 'total_tokens': 467, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})}4、RunnableLambda
from langchain_core.runnables import RunnableLambda
runnable_lambda = RunnableLambda(lambda x:x+'__lambda_x')
runnable_lambda.invoke('你好')
'你好__lambda_x'5、RunnablePassThrough
from langchain_core.runnables import RunnablePassthrough
chain = {
"text1": lambda x: x + " world",
"text2": lambda x: x + ", how are you",
} | RunnablePassthrough.assign(word_count=lambda x: len(x["text1"] +
x["text2"]))
result = chain.invoke("hello")
print(result)
# {'text1': 'hello world', 'text2': 'hello, how are you', 'word_count':29}
{'text1': 'hello world', 'text2': 'hello, how are you', 'word_count': 29}6、RunnableBranch
其实就是一个if_else操作,能够根据我们所写的判断条件,去具体执行某一个分支的逻辑。
传入方式:传入多个分支组成的列表,列表的每一个元素都是一个元组,元组的第一个元素是判断
条件,第二个元素是判断成功之后执行的逻辑。(自上而下判断)
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: isinstance(x, str), lambda x: x.upper()),
(lambda x: isinstance(x, int), lambda x: x + 1),
(lambda x: isinstance(x, float), lambda x: x * 2),
lambda x: "goodbye",
)
branch.invoke("hello")
'HELLO'7、RunnableWithFallbacks
在前面的runnable出现异常时就会执行runnablewithfallbacks,通过调用runnable组件的
with_fallbacks方法,就可以得到一个runnablewithfallbacks的实例。
from langchain_openai import ChatOpenAI
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model = 'gpt-4o-mini',
)
chain = PromptTemplate.from_template("hello") | llm
# 下面传入列表是因为可以传入多个兜底逻辑
chain_with_fallback = chain.with_fallbacks([RunnableLambda(lambda x:x+"sorry")])
chain_with_fallback.invoke('hello')
'hellosorry'四、Retrieval
1、RAG介绍
RAG的基本思想为:将传统的生成式大模型和实时信息检索技术相结合,为大模型补充来自外部
的相关数据和上下文,来帮助大模型生成更加准确可靠的内容。

2、RAG流程
索引:从数据源提取数据,构建索引。
索引阶段:从各种数据源加载数据➡️将文档切分为小块➡️对文本块进行嵌入➡️存储嵌入向量。
检索生成:接受用户查询并从索引中检索相关数据,然后将其传递给模型。
检索生成阶段:根据用户输入,使用检索器从存储中检索相关文本块➡️大模型使用包含问题和检
索结果的提示生成回答。
3、加载数据
1、TextLoader
首先要pip install langchain_community
from langchain_community.document_loaders import TextLoader
# 通过textloader创建文件加载器
dataloader = TextLoader(
file_path='assets/sample.txt',
encoding='utf-8',
)
# 调用.load()方法,得到真正的文档对象
loaded_documents = dataloader.load()
print(loaded_documents[0])
print(loaded_documents[0].metadata)
print(loaded_documents[0].page_content)
page_content='LangChain 是一个用于构建基于大语言模型(LLM)应用的开发框架,旨在帮助开发者更高效地集成、管理和增强大语言模型的能力,构建端到端的应用程序。它提供了一套模块化工具和接口,支持从简单的文本生成到复杂的多步骤推理任务。' metadata={'source': 'assets/sample.txt'}
{'source': 'assets/sample.txt'}
LangChain 是一个用于构建基于大语言模型(LLM)应用的开发框架,旨在帮助开发者更高效地集成、管理和增强大语言模型的能力,构建端到端的应用程序。它提供了一套模块化工具和接口,支持从简单的文本生成到复杂的多步骤推理任务。2、CSVLoader和JSONLoader
CSV文件:
from langchain_community.document_loaders import CSVLoader
csv_loader = CSVLoader(
file_path='assets/sample.csv',
metadata_columns=['title'], # 控制把CSV中的哪一列的数据,也存到Document当中的元素信息里面
content_columns=['content'],
)
loaded_csv = csv_loader.load()
print(loaded_csv[0].metadata)
print(loaded_csv[0].page_content)
{'source': 'assets/sample.csv', 'row': 0, 'title': 'Introduction to Python'}
content: Python is a popular programming language.JSON文件:
jq_schema是提取json当中对象的一种特定方式,特定的语法。例如:'.' 就是提取整个json对象。
from langchain_community.document_loaders import JSONLoader
json_loader = JSONLoader(
file_path='assets/sample.json',
jq_schema='.data.items[].content',
text_content = False, # 是否是文本
)
loaded_json = json_loader.load()
print(len(loaded_json))
print(loaded_json[0].page_content)
3
This article explains how to parse API responses...3、加载HTML网页
一个网页组成的元素:html(组成整个网页的布局),css(样式文件),javascript(动态去调用
后端接口获取数据)。
pip install langchain_community beautifulsoup4,bs4是用来解析前端网页的。
import bs4
from langchain_community.document_loaders import WebBaseLoader
document_loader = WebBaseLoader(
#网址序列
web_paths=("https://cn.bing.com",),)
#传给BeautifulSoup的解析参数,parse_only表示只提取指定标签的元素
# bs_kwargs={"parse_only": bs4.SoupStrainer(class_="J-lemma-content")},)
res = document_loader.load()
res[0].page_content
'Search - Microsoft Bing© 2026 Microsoft增值电信业务经营许可证:合字B2-20090007京ICP备10036305号-7京公网安备11010802047360号Privacy and CookiesLegalAdvertiseAbout our adsHelpFeedback'4、加载MarkDown文件
pip install langchain_community unstructured[md]
传入mode = 'elements'可以按照markdown的标准格式去进行加载。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_loader = UnstructuredMarkdownLoader(
file_path='assets/sample.md',
mode = 'elements'
)
res = markdown_loader.load()
print(res)5、加载Docx文件
unstructured加载方式和现在使用的加载方式的区别是,前者结构化解析,适合搭配RAG
# from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# doc_loader = UnstructuredWordDocumentLoader(
# file_path='assets/sample.docx',
# mode = 'single'
# )
# loaded_doc = doc_loader.load()
from langchain_community.document_loaders import Docx2txtLoader
# 加载 docx 文档(和你原来用法完全一样)
loader = Docx2txtLoader("assets/sample.docx")
loaded_doc = loader.load()
print(loaded_doc)6、加载PDF文件
from langchain_community.document_loaders import PyPDFLoader
pdf_loader = PyPDFLoader(
file_path='assets/sample.pdf',
)
loaded_pdf = pdf_loader.load()
print(loaded_pdf)2)UnstructuredPDFLoader

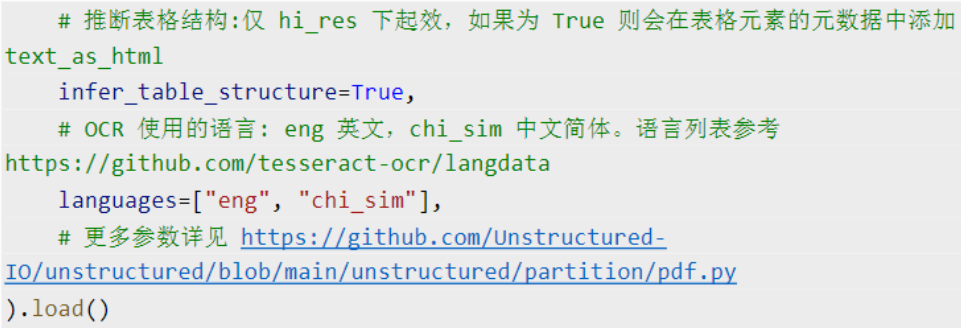
4、文档切分
将 Document 切分为 Chunk,主要是为了避免将整个 Document 输入大模型带来的问题:一是无
关内容会干扰生成效果,二是大模型对长上下文中间位置的信息利用能力较弱,三是超长文本可能
被截断导致信息丢失。以 Chunk 为单位进行存储和检索,有助于提升检索精度和模型回答质量。
1、切分策略
-
固定长度切分:按固定字符或Token数切分,实现简单,但可能切断句子。
-
递归分隔符切分:按多个分隔符递归切分,在长度限制内保持句子完整。
-
语义切分:基于句子嵌入向量的相似度识别语义边界(如用余弦距离与阈值比较),切分后合并过短的片段。语义保持好,但速度较慢,块长度不均。
2、 RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
docs = UnstructuredWordDocumentLoader(
file_path='assets/sample.docx',
model = 'single'
).load()
text_spliter = RecursiveCharacterTextSplitter(
separators=['\n\n','\n','。'],
chunk_size=400,#每个块的最大长度
chunk_overlap=50,#每个块重叠的长度
length_function=len,#可选:计算文本长度的函数,默认为字符串长度,可自定义函数来实现按token数切分
add_start_index=True,#可选:块的元数据中添加此块起始索引
)
splitted_res = text_spliter.split_documents(docs)
splitted_res5、文档嵌入embedding
Sentence-BERT改进了BERT的架构与预训练方式,生成富含语义的句子嵌入,可通过余弦相似度
等指标轻松比较,显著降低了相似句子查找等任务的计算成本。
(1)获取嵌入模型
开源模型:引入HuggingFaceEmbeddings包,传入所使用的模型名称
OpenAI闭源嵌入:引入OpenAIEmbedding类,传入OpenAI的嵌入模型名字,需要注意加载环境
变量。
(2)对文档进行嵌入
调用model.embed_documents()传入由document所构建的列表
import os
from langchain_huggingface import HuggingFaceEmbeddings
#加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser(r"C:\Users\77485\.cache\huggingface\hub\bge-base-zh-v1.5")
)
#单文本嵌入
query = "你好,世界"
print(embed_model.embed_query(query))
#多文本嵌入
docs = ["你好,世界", "你好,世界"]
print(embed_model.embed_documents(docs))6、向量存储
得到了嵌入向量,如何将嵌入向量存储到数据库当中,继而能够进行查询,做语义搜索。
有哪些向量数据库可以供选择?
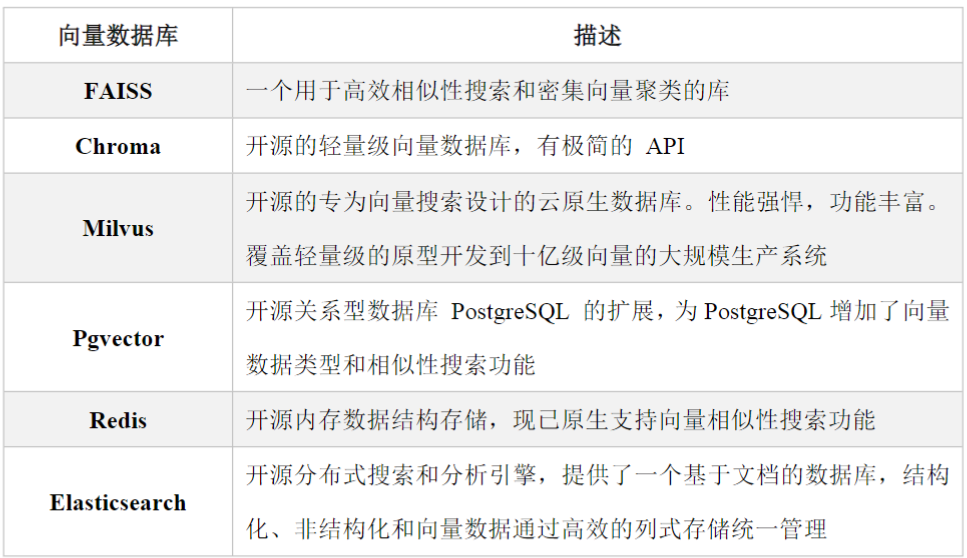
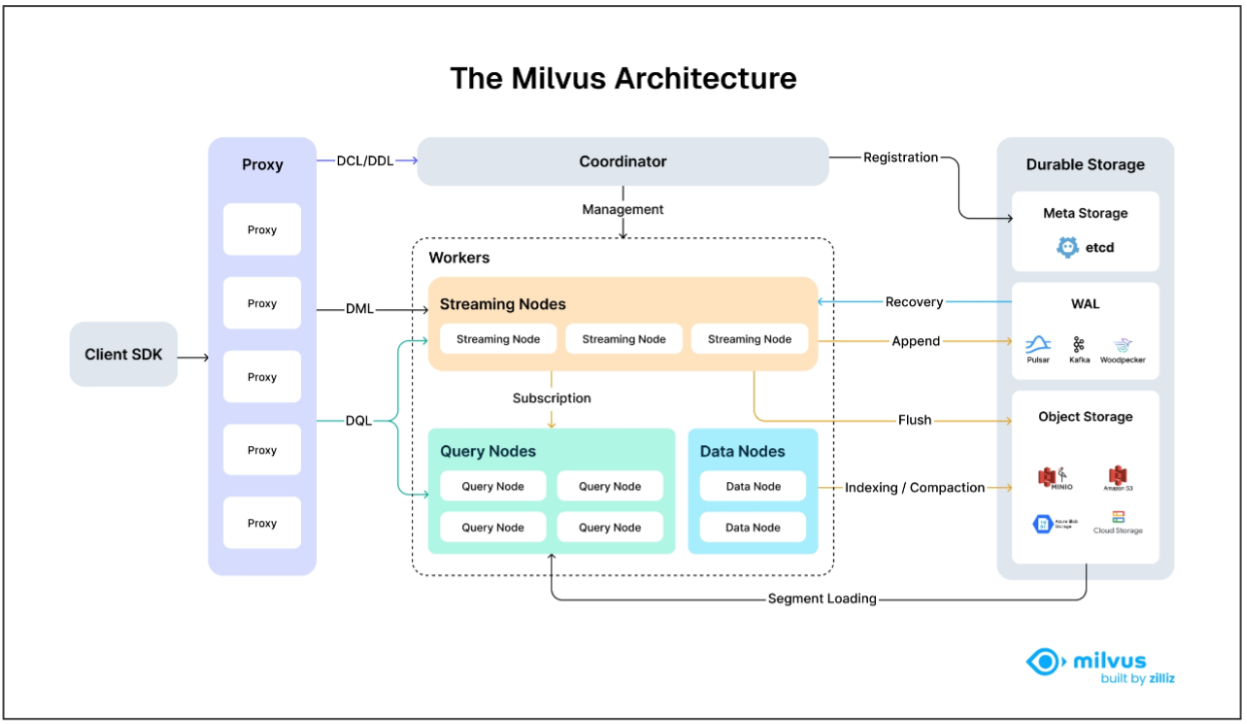
Milvus
https://milvus.io/docs/zh/install-pymilvus.md
Milvus的组件解耦良好,其中三个最关键的任务——搜索、数据插入以及索引/压缩——被设计为易
于并行化的进程,复杂逻辑被分离出来。
1、Milvus部署
下载docker desktop,这是一个桌面化的docker,可以方便管理资源,把milvus的镜像加载到
docker里,在终端输入docker load -i milvus_image.tar,然后如果是windows系统,再在终端输入
standalone.bat start。
Milvus支持百亿级向量检索,架构中查询、数据、索引节点可独立扩缩容。数据按数据库—
Collection—实体组织,类似关系型表。Collection含主键、最多4个向量字段及标量字段。稠密向
量常用HNSW或FLAT索引,稀疏向量用倒排索引(支持IP和BM25)。
2、Milvus创建collection
(1)构建schema信息;(2)添加索引(索引 = 用一种数据组织方式 + 搜索策略,减少需要比
较的向量数量);(3)创建collection。
from pymilvus import MilvusClient,DataType
def get_client():
return MilvusClient(uri="http://localhost:19530",token="")
def build_schema():
schema = MilvusClient.create_schema(
auto_id = True
).add_field(
field_name = 'id',
datatype = DataType.INT64,
is_primary = True
).add_field(
field_name = 'vector',
datatype = DataType.FLOAT_VECTOR,
dim = 1024,
).add_field(
field_name = 'sparse_vector',
datatype = DataType.SPARSE_FLOAT_VECTOR,
).add_field(
field_name = 'meatadata',
datatype = DataType.JSON
).add_field(
field_name='text',
datatype = DataType.VARCHAR,
max_length = 1500,
)
return schema
def build_index():
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name = 'vector',
index_type = 'HNSW',
metric_type = 'COSINE'
)
index_params.add_index(
field_name = 'sparse_vector',
index_type = 'SPARSE_INVERTED_INDEX',
metric_type = 'IP'
)
return index_params
def create_collection(client:MilvusClient,collection_name:str):
client.create_collection(
collection_name = collection_name,
schema = build_schema(),
index_params = build_index()
)
client = get_client()
res = client.list_collections()
create_collection(client = client,collection_name = 'demo_collection')
print(res)
介绍一下vector和sparse_vector,前者是语义向量,后者是关键词在整句中的重要性权重,往往格
式为[12:0.8,7:0.2]这样,也就是[ token序号:权重 ]。
3、Milvus插入实体
将数据构建成List[Dict]形式,其中List表示批量数据,Dict表示符合创建collection时所定义的
schema结构的数据,构建完成后,可通过client.insert方法,将数据插入到指定的collection当中。
from pymilvus import MilvusClient,DataType
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from FlagEmbedding import BGEM3FlagModel
def get_client():
return MilvusClient(uri="http://localhost:19530",token="")
def insert_data(client:MilvusClient,collection_name:str):
# 加载一个文件
doc_list = UnstructuredWordDocumentLoader('assets/sample.docx',model = 'single').load()
# 切分文件
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap=50,seperator=['\n\n','\n','。'])
splitted_doc_list = text_splitter.split_documents(doc_list)
splitted_doc_list = splitted_doc_list[0:20]
max_len = max([len(bytes(doc.page_content.encode('utf-8'))) for doc in splitted_doc_list])
print('当前最大长度',max_len)
# 构建向量:稠密向量,稀疏向量
model = BGEM3FlagModel(r"E:\models\bge-m3",devices = ['cuda:0'])
all_vectors = model.encode([doc.page_content for doc in splitted_doc_list],return_sparse=True,return_dense=True)
dense_vectors = all_vectors['dense_vecs']
sparse_vectors = all_vectors['lexical_weights']
# 准备数据:组装成List[Dict]
insert_data_list = []
for doc,dense_vectors,sparse_vectors in zip (splitted_doc_list, dense_vectors, sparse_vectors):
insert_data_list.append(
{
'vector': dense_vectors,
'sparse_vector': sparse_vectors,
'metadata': doc.metadata,
'text': doc.page_content,
}
)
# 调用client.insert()方法,插入数据
res = client.insert(
collection_name = collection_name,
data = insert_data_list,
)
print(res) # 有多少条数据插入成功
insert_data(client = get_client(),collection_name = 'demo_collection')4、Milvus检索
通过调用client.search,传入需要检索的query向量,以及需要和query向量进行比较的向量字段,
即可进行向量检索。
关键参数:
-
查询向量:待检索对象的向量表示(维度需与库内一致)。
-
向量字段:指定要检索的向量字段名。
-
TopK:返回结果的数量。
-
metric_type:相似度计算方法(如余弦相似度、欧氏距离等)。
1. 混合检索
同时使用稠密向量(语义匹配)和稀疏向量(关键词匹配)进行检索。
2. 重排序
对初步召回的结果进行二次排序,以提升排序质量。
-
典型流程:收集各检索器(如向量检索、关键词检索)返回的排名 -> 通过算法(如RRF)合并排名 -> 生成最终排序结果。
把 query 变成“双表示(语义+关键词)”,并在 Milvus 中执行“语义检索 + 关键词检索 + 融合排序”
的完整检索流程。
from pymilvus import MilvusClient
def dense_vector_search(client:MilvusClient,collection_name:str,query_vector:list,top_k:int = 3):
res = client.search(
collection_name = collection_name,
data = [query_vector],
anns_field='vector',
limit = top_k,
metric_type = 'COSINE',
output_fields=['text']
)
if res:
result = res[0]
print(result)
return result
def sparse_vector_search(client:MilvusClient,collection_name:str,query_vector:dict,top_k:int = 3):
res = client.search(
collection_name = collection_name,
data = [query_vector],
anns_field='sparse_vector',
limit = top_k,
metric_type = 'IP',
output_fields=['text']
)
if res:
result = res[0]
print(result)
return result
def hybrid_search(client:MilvusClient,collection_name:str,query_sparse_vector:dict,query_dense_vector:list,top_k:int = 3):
# 基于稀疏和稠密向量混合检索
from pymilvus import AnnSearchRequest
# 构建AnnSearchRequest对象,包含了稠密向量检索和稀疏向量检索
sparse_request = AnnSearchRequest(
data = [query_sparse_vector],
anns_field = 'sparse_vector',
limit = top_k,
param = {'nprobe':10}
)
dense_request = AnnSearchRequest(
data = [query_dense_vector],
anns_field = 'vector',
limit = top_k,
param = {'nprobe':10}
)
# 构造reranker对象RRFReranker
from pymilvus import RRFRanker
reranker = RRFRanker()
# 调用client.hybrid_search()方法,进行混合检索
res = client.hybrid_search(
collection_name = collection_name,
reqs = [sparse_request,dense_request],
ranker = reranker,
limit = top_k,
output_fields = ['metadata']
)
return res
client = MilvusClient(uri="http://localhost:19530",token="")
query = '国家所有权'
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel(r"E:\models\bge-m3")
query_vector = model.encode([query],return_sparse=True,return_dense=True)
dense_vector = query_vector['dense_vecs'][0].tolist()
sparse_vector = query_vector['lexical_weights'][0].tolist()
search_res1 = dense_vector_search(client,collection_name='demo_collection',query_vector=dense_vector)
search_res2 = sparse_vector_search(client,collection_name='demo_collection',query_vector=sparse_vector)
print(search_res1)
hybrid_res = hybrid_search(client,collection_name='demo_collection',query_sparse_vector=sparse_vector,query_dense_vector=dense_vector)
print(hybrid_res)五、Agent
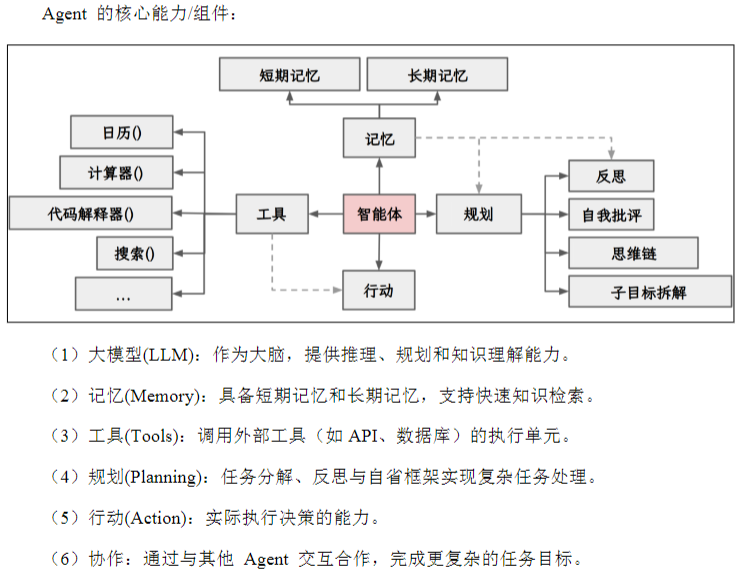
1、Agent介绍
2、Tools
1、创建tools的两种方式
方式1,通过装饰器的方式定义,在函数的上面添加@tool,这里的三引号必须要加,作为
docstring被大模型识别。
from langchain_core.tools import tool
# 方式1,通过装饰器的方式定义,在函数的上面添加@tool
@tool
def calculate_expo(base:int,expo:int):
"""
一个用于计算幂的函数
:param base:
:param expo:
:return:
"""
return base**expo
calculate_expo
StructuredTool(name='calculate_expo', description='一个用于计算幂的函数\n:param base:\n:param expo:\n:return:', args_schema=<class 'langchain_core.utils.pydantic.calculate_expo'>, func=<function calculate_expo at 0x00000196F329EA20>)方式2,通过调用tool函数去定义。
# 方式2 通过调用tool函数去定义。
def calculate_expo2(base:int,expo:int):
"""
一个用于计算幂的函数
:param base:
:param expo:
:return:
"""
return base**expo
a_new_tool = tool(calculate_expo2)
# 定义函数入参结构时,除了使用typed hint也就是(base:int)外,还可以使用pydantic
from pydantic import BaseModel,Field
def calculate_expo3(base,expo):
return base**expo
class CalcExpoSchema(BaseModel):
base: int = Field(description='幂的底数')
expo: int = Field(description='幂的指数')
calculate_expo3 = tool(calculate_expo3,args_schema=CalcExpoSchema,description='一个用于计算幂的函数')
calculate_expo3.args
{'base': {'description': '幂的底数', 'title': 'Base', 'type': 'integer'},
'expo': {'description': '幂的指数', 'title': 'Expo', 'type': 'integer'}}2、调用tools
通过调用invoke去执行tool当中的逻辑,invoke传入一个dict,键是tool的入参。
calculate_expo3.invoke({'base':2, 'expo':3})
83、大模型使用tools
手动调用tools的一个案例,流程是:先声明一个工具列表,然后创建with_tool的大模型实例,
invoke这个实例,内部会自动封装tool_calls的列表,然后遍历列表,拿出tool名和args,再
invoke一下。
这里大模型在接收tool列表信息的时候,只知道tool的名称和入参,不知道内部代码。
from langchain_openai import ChatOpenAI
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model = 'gpt-4o-mini'
)
tools = [calculate_expo3]
llm_with_tools_bound = llm.bind_tools(tools)
res = llm_with_tools_bound.invoke('帮我计算一下2的10次方是多少')
res # 当前AIMessage当中的content没有内容。当前AI无法自动去调用工具,需要我们去手动调用
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 73, 'total_tokens': 94, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DX5LKw1gCWZl3oKH5KYIIxjNs0SCy', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019db034-8d35-71f0-8af3-468ac5bbf552-0', tool_calls=[{'name': 'calculate_expo3', 'args': {'base': 2, 'expo': 10}, 'id': 'call_U3UcggQS05U1xV4xj8BVLkv6', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 73, 'output_tokens': 21, 'total_tokens': 94, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})# str2tool = {
# 'calculate_expo3':calculate_expo3,
# }
for tool_call in res.tool_calls:
print(tool_call)
tool_name = tool_call['name']
args = tool_call['args']
# tool_invoke_res = str2tool[tool_name].invoke(args)
tool_invoke_res = globals()[tool_name].invoke(args)
print(tool_invoke_res)
{'name': 'calculate_expo3', 'args': {'base': 2, 'expo': 10}, 'id': 'call_BeEHubi6skBBMJuiuPs2OX5j', 'type': 'tool_call'}
10243、构建Agent之Tavily
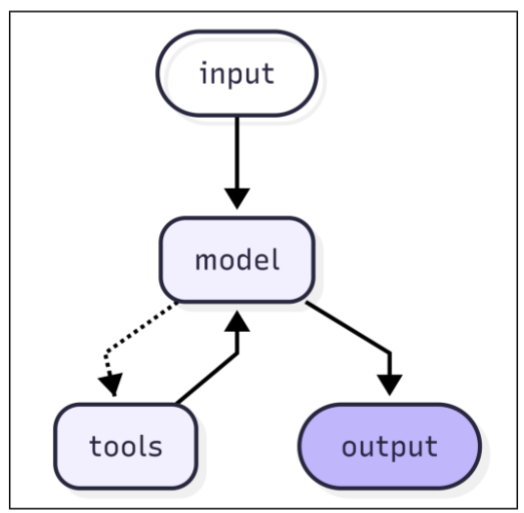
使用 create_agent 可快速构建一个基于 LangGraph 的 Agent。
-
运行机制:Agent 会循环调用“模型”和“工具”,直到模型不再请求调用工具为止。
-
参数:需传入模型和工具,可选传入系统提示词。
-
准备工作:这里使用 Tavily (搜索引擎)工具,需先获取 API-Key 并配置到环境变量中。

这一步相当于是提供给我了一个比较像样的tool,能真正做一些操作,而不是像之前的幂指数那么
幼稚。
创建Agent
这里先 pip install langchain-tavily,然后把Tavily的API维护到env中。
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model = 'gpt-4o-mini'
)
tavily_search_tool = TavilySearch(max_results = 5)# 返回搜索结果的最大数量
tools = [tavily_search_tool]
agent = create_agent(
model = llm,
tools = tools,
system_prompt='你是一个智能助手,能够选择合适的工具帮助用户解决问题'
)使用Agent
这个时候不能再传入字符串,会报错,调用需要通过messages Key和消息列表作为value来调用
res = agent.invoke({"messages":[{'role':'user','content':'帮我看一下北京天气怎么样'}]})
res['messages'][-1]
AIMessage(content='北京的天气情况如下:\n\n- 当前气温大约是18.3°C,西南风,天气晴好。\n- 今天的气温范围为10°C 到 23°C,适宜出游。\n- 风力较大,空气质量良好,但需注意感冒的风险。\n\n详细天气预报可以参考以下链接:\n1. [中央气象台](https://www.nmc.cn/publish/forecast/ABJ/beijing.html)\n2. [天气网](https://www.weather.com.cn/weather/101010100.shtml)\n\n如需进一步的天气信息,请随时询问!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 130, 'prompt_tokens': 3993, 'total_tokens': 4123, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 1152}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DXRaJeQZcVTfWsahrqZiNDNFdKWuP', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019db54d-34f4-7830-84c9-624bd835dafc-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 3993, 'output_tokens': 130, 'total_tokens': 4123, 'input_token_details': {'audio': 0, 'cache_read': 1152}, 'output_token_details': {'audio': 0, 'reasoning': 0}})4、LangSmith

把环境变量维护到env中

去langchain的官网查看
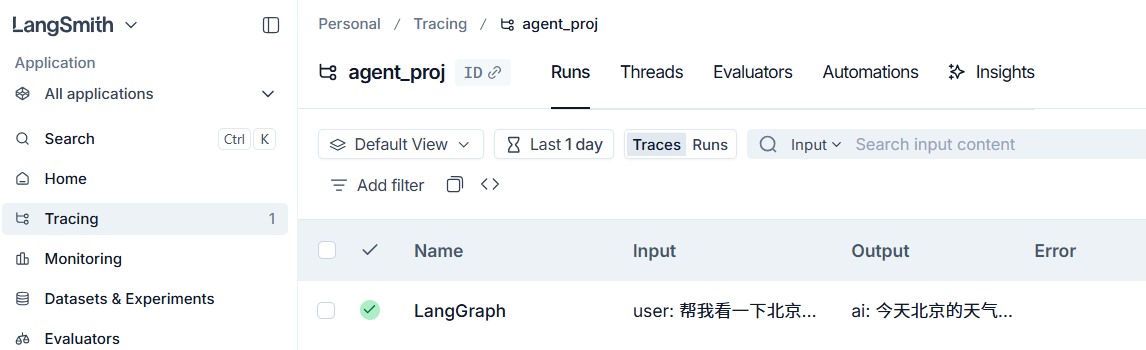
5、如何在Agent中添加记忆
在创建Agent时,传入checkpointer参数,在测试环境下,可以传入InMemorySaver(),生产环
境下,使用数据库保存记忆。
from langgraph.checkpoint.memory import InMemorySaver
agent_with_memory = create_agent(
model = llm,
tools = tools,
system_prompt='你是一个智能助手,能够选择合适的工具帮助用户解决问题',
checkpointer = InMemorySaver()
)
传入config参数,指定要保存的thread_id,就是相当于指定要保存到哪个会话的感觉。
agent_with_memory.invoke({"messages":[{'role':'user','content':'帮我看一下北京天气怎么样'}]},
config = {'configurable':{'thread_id':1}})agent_with_memory.invoke({"messages":[{'role':'user','content':'我刚才问你什么了'}]},
config = {'configurable':{'thread_id':1}})['messages'][-1]
AIMessage(content='你刚才问我关于北京的天气情况。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 13, 'prompt_tokens': 4778, 'total_tokens': 4791, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 1152}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DXS3Eyn0FtCO2KcebfnDY3W5kNPRM', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019db568-8390-75c1-91b7-f7ec7e8821f6-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 4778, 'output_tokens': 13, 'total_tokens': 4791, 'input_token_details': {'audio': 0, 'cache_read': 1152}, 'output_token_details': {'audio': 0, 'reasoning': 0}})6、MCP(Model Context Protocol)
Model Context Protocol(MCP,模型上下文协议)是一个开源协议,它标准化了大语言模型与外
部工具和数据源通信的方式,允许开发者和工具提供商只需集成一次,就能与任何兼容MCP的系
统交互。MCP就像USB-C标准:不需要为每个设备使用不同的连接器,而是使用一个端口来处理
多种类型的连接。

1、MCP架构
MCP让 tool 的“暴露方式”变成统一标准,工具开发者必须按 MCP 标准实现接口。

使用MCP的好处
-
假如不用MCP,我们现在使用阿里云百练搜索,我们在代码当中写死参数类型和参数名称,传入的参数有3个。现在代码跑起来没问题。直到,阿里云百练平台搜索工具入参发生调整。我们的代码就可能调不通。
-
在使用了MCP之后:当阿里云百练平台搜索工具入参发生调整时,MCP Server能够及时的通知给MCP客户端,MCP客户端能够及时把信息通知给LLM,LLM在构造function calling参数时,就能够按照新的入参去构建。
-
Server端去定义有哪些工具可以使用,工具的入参是什么等。客户端只需要和Server端建立连接之后,就能够获取这些信息,并且能够及时收到更新的消息。
2、MCP层级
MCP分为两个层级:
(1)数据层:基于 JSON-RPC 2.0 协议,定义消息结构与语义,涵盖生命周期管理、服务器功能(工具/资源/提示模板)、客户端功能(调用LLM、获取输入、记录消息)及其他功能(实时更新通知、长时运行操作跟踪)。
(2)传输层:定义客户端与服务器之间的通信机制与通道,包括连接建立、消息帧定界和授权。支持多种传输机制:Stdio、Streamable HTTP、SSE。
-
Stdio:使用标准输入输出流,适用于本地开发。
-
Streamable HTTP:使用 HTTP POST/GET 请求,支持流式传输、服务端推送通知及标准 HTTP 认证(令牌、API 密钥、自定义头)。
-
SSE:基于 HTTP 的服务器发送事件,为 MCP 早期传输机制,现已逐渐被 Streamable HTTP 取代。
3、MCP工作流程
(1)初始化
MCP客户端连接到服务器并存储其能力,用于确定哪些服务器可提供工具、资源、提示及是否支持实时更新。初始化三个重要作用:
-
协议版本协商:确保客户端与服务器协议版本兼容。
-
能力发现:声明各自支持的基元类型(工具、资源、提示)及通知等特性。
-
身份交换:交换身份及版本信息,便于调试与兼容性管理。
(2)工具发现
客户端通过发送 tools/list 请求发现可用工具,服务器返回 tools 数组,每个工具包含:
-
name:工具标识符
-
title:易读显示名称
-
description:工具描述
-
inputSchema:JSON Schema,定义预期输入参数(类型、必需/可选)
(3)工具执行
客户端使用 tools/call 方法执行工具,请求包含 name(工具标识符)和 arguments(输入参数)。响应返回内容对象数组,支持文本、图片、资源等多格式响应。
(4)实时更新
MCP支持服务器主动通知客户端变更。AI应用收到工具变更通知后,立即刷新工具注册表并更新LLM的可用功能,确保对话始终能访问最新工具。
4、stdio客户端服务端编码
先pip一个mcp的包
pip install mcp
mcp_stdio_server.py
from mcp.server.fastmcp import FastMCP
fast_mcp_instance = FastMCP(name = 'demo_mcp')
@fast_mcp_instance.tool()
def add_two_numbers(a:int, b:int):
return a + b
if __name__ == '__main__':
fast_mcp_instance.run(transport='stdio')mcp_stdio_client.py
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession,StdioServerParameters
async def stdio_run():
server_params = StdioServerParameters(
command = r'E:\anaconda3\envs\NLP\python.exe',
args = ['mcp_stdio_server.py'],
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add_two_numbers", {"a": 1, "b": 2})
print(call_res)
print()
asyncio.run(stdio_run())
meta=None nextCursor=None tools=[Tool(name='add_two_numbers', title=None, description='', inputSchema={'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': ['a', 'b'], 'title': 'add_two_numbersArguments', 'type': 'object'}, outputSchema=None, icons=None, annotations=None, meta=None, execution=None)]
meta=None content=[TextContent(type='text', text='3', annotations=None, meta=None)] structuredContent=None isError=False5、streamable_http
streamable_http_server
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(name = 'demo')
@mcp.tool()
def add_two_numbers(a:int, b:int):
return a + b
if __name__ == '__main__':
mcp.run(transport='streamable-http')
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)streamable_http_client
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
async def streamablehttp_run():
url = "http://127.0.0.1:8000/mcp"
async with streamablehttp_client(url, ) as (read, write, _):
async with ClientSession(read, write) as session:
#初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add_two_numbers", {"a": 1, "b": 2})
print(call_res)
print()
asyncio.run(streamablehttp_run())
meta=None nextCursor=None tools=[Tool(name='add_two_numbers', title=None, description='', inputSchema={'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': ['a', 'b'], 'title': 'add_two_numbersArguments', 'type': 'object'}, outputSchema=None, icons=None, annotations=None, meta=None, execution=None)]
meta=None content=[TextContent(type='text', text='3', annotations=None, meta=None)] structuredContent=None isError=False将多个Streamable HTTP服务器挂载到ASGI服务器
先装一下FastAPI包
pip install fastapi这边要先把之前http占用的端口8000释放了,再运行下面的代码,不然会冲突。
import uvicorn
import contextlib
from fastapi import FastAPI
from mcp.server.fastmcp import FastMCP
#创建MCP实例
tool_mcp = FastMCP("tool server")
resource_mcp = FastMCP("resource server")
prompt_mcp = FastMCP("prompt server")
#为tool_mcp实例添加工具
@tool_mcp.tool()
def add(a: int, b: int) -> int:
return a + b
#为resource_mcp实例添加资源
@resource_mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
#为prompt_mcp实例添加提示词
@prompt_mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
#设置MCP的HTTP根路径
tool_mcp.settings.streamable_http_path = "/"
resource_mcp.settings.streamable_http_path = "/"
prompt_mcp.settings.streamable_http_path = "/"
#创建一个组合生命周期来管理会话管理器
@contextlib.asynccontextmanager
async def lifespan(app: FastAPI):
async with contextlib.AsyncExitStack() as stack:
await stack.enter_async_context(tool_mcp.session_manager.run())
await stack.enter_async_context(resource_mcp.session_manager.run())
await stack.enter_async_context(prompt_mcp.session_manager.run())
yield
app = FastAPI(lifespan=lifespan)
#挂载MCP服务器
app.mount("/tool", tool_mcp.streamable_http_app())
app.mount("/resource", resource_mcp.streamable_http_app())
app.mount("/prompt", prompt_mcp.streamable_http_app())
if __name__ == "__main__":
uvicorn.run(app)
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)6、Langchain使用MCP
阿里云百炼:
https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
Smithery:
https://smithery.ai/server/@DeniseLewis200081/rail
先pip一下
pip install langchain_mcp_adaptersimport os
import asyncio
from urllib.parse import urlencode
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_mcp_adapters.client import MultiServerMCPClient
import dotenv
dotenv.load_dotenv()
# 配置MCP客户端
mcp_client = MultiServerMCPClient(
{
"WebSearch": {
"transport": "streamable_http",
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/mcp",
"headers": {
"Authorization": f"Bearer{os.getenv('DASHSCOPE_API_KEY')}"
},
},
"RailService": {
"transport": "streamable_http",
"url": f"{'https://rail--deniselewis200081.run.tools'}?"
f"{urlencode({'api_key': os.getenv('SMITHERY_API_KEY')})}",
}
}
)
# 获取工具
tools = asyncio.run(mcp_client.get_tools())
llm = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
)
# 创建Agent
agent = create_agent(model=llm, tools=tools)
# 调用Agent
async def main():
async for chunk in agent.astream(
{
"messages": [
{"role": "system", "content": "你是位助手,需要调用工具来帮助用户。"},
{
"role": "user",
"content": "北京今天天气怎么样,要是还不错的话,帮我看看今天上海到北京的车票",
},
]
}
):
print(chunk, end="\n\n")
asyncio.run(main())7、supervisor监督者模式多Agent
三引号里面的东西要写精确一点。
import os
import asyncio
import smtplib
from langchain.tools import tool
from urllib.parse import urlencode
from email.mime.text import MIMEText
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_mcp_adapters.client import MultiServerMCPClient
import dotenv
dotenv.load_dotenv()
llm = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
)
# ==========创建一个有搜索功能的子Agent ==========
class SearchSubAgent:
"""带搜索功能的子Agent"""
def __init__(self):
self.tools = asyncio.run(
MultiServerMCPClient(
{
"WebSearch": {
"transport": "streamable_http",
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/mcp",
"headers": {
"Authorization": f"Bearer {os.getenv('DASHSCOPE_API_KEY')}"
},
}, #
# https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
"RailService": {
"transport": "streamable_http", # 流式HTTP:服务器作为独立进程运行,处理HTTP请求。支持远程连接和多客户端。
"url": f"{'https://rail--deniselewis200081.run.tools'}?{urlencode({'api_key': os.getenv('SMITHERY_API_KEY')})}",
}, #
# https://smithery.ai/server/@DeniseLewis200081/rail
}
).get_tools()
)
self.agent = create_agent(model=llm, tools=self.tools)
async def __call__(self, input: str) -> str:
return await self.agent.ainvoke(
{"messages": [{"role": "user", "content": input}]}
)
# ==========创建一个能发送邮件的子Agent ==========
@tool
async def send_email(to: str, subject: str, body: str) -> str:
"""
发送邮件。需要自动生成邮件主题。
Args:
to: 1277304395@qq.com
subject: 邮件主题
body: 邮件正文内容
"""
SMTP_HOST = "smtp.qq.com"
SMTP_USER = "774858386@qq.com"
SMTP_PASS = "xtfxnueirkebbfgf" # 需要在邮箱中开启SMTP并生成授权码
msg = MIMEText(body, "plain", "utf-8")
msg["From"] = SMTP_USER
msg["Subject"] = subject
msg["To"] = ",".join(to)
try:
server = smtplib.SMTP_SSL(SMTP_HOST, 465, timeout=10)
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, to, msg.as_string())
try:
server.quit()
except smtplib.SMTPResponseException as e:
if e.smtp_code == -1 and e.smtp_error == b"\x00\x00\x00":
pass # 忽略无害的关闭异常
else:
raise
return "success"
except Exception as e:
return f"Send failed: {type(e).__name__} - {e}"
class EmailSubAgent:
"""带发送邮件功能的子代理"""
def __init__(self):
self.tools = [send_email]
self.agent = create_agent(model=llm, tools=self.tools)
async def __call__(self, input: str) -> str:
return await self.agent.ainvoke(
{"messages": [{"role": "user", "content": input}]}
)
search_subagent = SearchSubAgent()
email_subagent = EmailSubAgent()
# ==========将子Agent包装为工具==========
@tool
async def search(input: str) -> str:
"""一个具有搜索功能的子Agent,功能包括:
-搜索网页
-搜索火车票相关信息
"""
return await search_subagent(input)
@tool
async def email(input: str) -> str:
"""
一个具有发送邮件功能的子Agent
"""
return await email_subagent(input)
# ==========创建主管Agent ==========
supervisor_agent = create_agent(
model=llm,
tools=[search, email],
system_prompt="你是一个主管,需要调用子Agent来帮助用户",
)
async def main():
async for chunk in supervisor_agent.astream(
{
"messages": [
{
"role": "user",
"content": f"北京明天天气怎么样,要是还不错的话,给1277304395@qq.com发送邮件告诉他我明天去北京。如果天气不好的话就告诉他我明天不去北京了。",
}
]
}
):
print(chunk, end="\n\n")
asyncio.run(main())
{'model': {'messages': [AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 138, 'total_tokens': 158, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DY41eH251eUyOYdLKpDV73Y3wy6gm', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019dbe1b-fa1f-7330-af56-dc0cca94250b-0', tool_calls=[{'name': 'search', 'args': {'input': '北京明天的天气预报'}, 'id': 'call_02t1KWiUno4k4W2YCgvBJaZD', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 138, 'output_tokens': 20, 'total_tokens': 158, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}}
{'tools': {'messages': [ToolMessage(content='{\'messages\': [HumanMessage(content=\'北京明天的天气预报\', additional_kwargs={}, response_metadata={}, id=\'7f63508e-892c-4924-9fb4-0040891e851f\'), AIMessage(content=\'\', additional_kwargs={\'refusal\': None}, response_metadata={\'token_usage\': {\'completion_tokens\': 24, \'prompt_tokens\': 745, \'total_tokens\': 769, \'completion_tokens_details\': {\'accepted_prediction_tokens\': 0, \'audio_tokens\': 0, \'reasoning_tokens\': 0, \'rejected_prediction_tokens\': 0}, \'prompt_tokens_details\': {\'audio_tokens\': 0, \'cached_tokens\': 0}}, \'model_provider\': \'openai\', \'model_name\': \'gpt-4o-mini-2024-07-18\', \'system_fingerprint\': \'fp_eb37e061ec\', \'id\': \'chatcmpl-DY41fknRUJryv6fHNymDwgldCXBDO\', \'service_tier\': \'default\', \'finish_reason\': \'tool_calls\', \'logprobs\': None}, id=\'lc_run--019dbe1b-fee1-7db2-b0c3-7f7a915a54d7-0\', tool_calls=[{\'name\': \'bailian_web_search\', \'args\': {\'query\': \'北京 明天的天气预报\'}, \'id\': \'call_326yUzIMrpZ5lICOEY2Mto3F\', \'type\': \'tool_call\'}], invalid_tool_calls=[], usage_metadata={\'input_tokens\': 745, \'output_tokens\': 24, \'total_tokens\': 769, \'input_token_details\': {\'audio\': 0, \'cache_read\': 0}, \'output_token_details\': {\'audio\': 0, \'reasoning\': 0}}), ToolMessage(content=[{\'type\': \'text\', \'text\': \'{"pages":[{"snippet":"北京 2026/04/24 ~ 2026/05/08 周四 04/23 阴转小雨 25/16℃ 今天 04/24 小雨转阴 22/9℃ 周六 04/25 阴 21/9℃ 周日 04/26 多云转阴 22/14℃ 周一 04/27 大雨转晴 23/10℃ 周二 04/28 晴 17/7℃ 周三 04/29 晴转阴 18/9℃ 周四 04/30 阴转多云 13/5℃ 周五 05/01 雨 14/4℃ 周六 05/02 雨转晴 15/5℃ 周日 05/03 雨 16/10℃ 周一 05/04 雨 19/13℃ 周二 05/05 雨 14/13℃ 周三 05/06 雨转阴 16/10℃ 周四 05/07 雨 21/14℃ 我的天空","hostname":"天气网","hostlogo":"https://img.alicdn.com/imgextra/i2/O1CN01MJh8gM28s6MYPHsm6_!!6000000007987-2-tps-32-32.png","title":"【北京天气预报15天_北京天气预报15天查询】-中国天气网","url":"http://uc.weather.com.cn/mweather15d/401090020201.shtml"},{"snippet":"北京 2026/04/24 ~ 2026/05/08 周四 04/23 阴转小雨 25/16℃ 今天 04/24 小雨转阴 22/9℃ 周六 04/25 阴 21/9℃ 周日 04/26 多云转阴 22/14℃ 周一 04/27 大雨转晴 23/10℃ 周二 04/28 晴 17/7℃ 周三 04/29 晴转阴 18/9℃ 周四 04/30 阴转多云 13/5℃ 周五 05/01 雨 14/4℃ 周六 05/02 雨转晴 15/5℃ 周日 05/03 雨 16/10℃ 周一 05/04 雨 19/13℃ 周二 05/05 雨 14/13℃ 周三 05/06 雨转阴 16/10℃ 周四 05/07 雨 21/14℃ 台风中心","hostname":"天气网","hostlogo":"https://img.alicdn.com/imgextra/i2/O1CN01MJh8gM28s6MYPHsm6_!!6000000007987-2-tps-32-32.png","title":"【北京天气预报15天_北京天气预报15天查询】-中国天气网","url":"https://e.weather.com.cn/mweather15d/401090020201.shtml"},{"snippet":"北京 2026/04/24 ~ 2026/05/08 今天 04/24 多云 25/15℃ 周六 04/25 多云 26/15℃ 周日 04/26 多云转晴 23/12℃ 周一 04/27 晴 26/13℃ 周二 04/28 晴 24/11℃ 周三 04/29 晴转多云 25/12℃ 周四 04/30 多云 26/13℃ 周五 05/01 多云 26/15℃ 周六 05/02 阴 26/15℃ 周日 05/03 多云 28/17℃ 周一 05/04 阴转雨 28/16℃ 周二 05/05 雨转晴 20/11℃ 周三 05/06 多云转晴 26/12℃ 周四 05/07 晴转多云 27/16℃ 周五 05/08 多云转阴 34/13℃ 40天预报","hostname":"天气网","hostlogo":"https://search-operate.cdn.bcebos.com/2638fa3e24e382cdcab2197ea55d66bf.png","title":"【北京天气预报15天_北京天气预报15天查询】-中国天气网","url":"https://m.weather.com.cn/mweather15d/101010100.shtml?_t=1479051347142"},{"snippet":"北京 2026/04/16 ~ 2026/04/30 今天 04/16 小雨 18/11℃ 周五 04/17 晴 24/13℃ 周六 04/18 晴 28/15℃ 周日 04/19 多云 28/13℃ 周一 04/20 多云转晴 22/10℃ 周二 04/21 晴转多云 22/10℃ 周三 04/22 多云 22/11℃ 周四 04/23 多云 19/11℃ 周五 04/24 阴 24/13℃ 周六 04/25 多云 24/9℃ 周日 04/26 阴 19/10℃ 周一 04/27 多云转阴 22/13℃ 周二 04/28 阴 24/12℃ 周三 04/29 雨转阴 16/12℃ 周四 04/30 阴 22/11℃ 40天预报","hostname":"无","hostlogo":"https://img.alicdn.com/imgextra/i2/O1CN01MJh8gM28s6MYPHsm6_!!6000000007987-2-tps-32-32.png","title":"【北京天气预报15天_北京天气预报15天查询】-中国天气网","url":"http://sq2.weather.com.cn/mweather15d/101010100.shtml"},{"snippet":"北京 2026/04/16 ~ 2026/04/30 今天 04/16 小雨 20/11℃ 周五 04/17 晴 24/13℃ 周六 04/18 晴 28/15℃ 周日 04/19 多云 27/12℃ 周一 04/20 晴 22/10℃ 周二 04/21 晴转多云 23/10℃ 周三 04/22 阴转多云 22/11℃ 周四 04/23 多云 19/11℃ 周五 04/24 阴 24/13℃ 周六 04/25 多云 24/9℃ 周日 04/26 阴 19/10℃ 周一 04/27 多云转阴 22/13℃ 周二 04/28 阴 24/12℃ 周三 04/29 雨转阴 16/12℃ 周四 04/30 阴 22/11℃ 40天预报","hostname":"无","hostlogo":"https://img.alicdn.com/imgextra/i2/O1CN01MJh8gM28s6MYPHsm6_!!6000000007987-2-tps-32-32.png","title":"天气","url":"https://qq.weather.com.cn/mweather15d/101010100.shtml"}],"request_id":"1fc918da-93a0-9647-a817-91743fc40bea","tools":[{"result":"北京市北京市2026-04-25基本天气信息:\\\\n天气:多云\\\\n温度:26/15℃\\\\n风向:西南风\\\\n风力:null","type":"weather"}],"status":0}\', \'id\': \'lc_44c9c15b-bbe3-4cbb-a76c-c6e4f5fba84f\'}], name=\'bailian_web_search\', id=\'a7d7397d-8558-4fcf-8bfa-bbce65377118\', tool_call_id=\'call_326yUzIMrpZ5lICOEY2Mto3F\'), AIMessage(content=\'\', additional_kwargs={\'refusal\': None}, response_metadata={\'token_usage\': {\'completion_tokens\': 12, \'prompt_tokens\': 2459, \'total_tokens\': 2471, \'completion_tokens_details\': {\'accepted_prediction_tokens\': 0, \'audio_tokens\': 0, \'reasoning_tokens\': 0, \'rejected_prediction_tokens\': 0}, \'prompt_tokens_details\': {\'audio_tokens\': 0, \'cached_tokens\': 0}}, \'model_provider\': \'openai\', \'model_name\': \'gpt-4o-mini-2024-07-18\', \'system_fingerprint\': \'fp_eb37e061ec\', \'id\': \'chatcmpl-DY41iti6SBQxY24ItBxJqSoImFpXy\', \'service_tier\': \'default\', \'finish_reason\': \'tool_calls\', \'logprobs\': None}, id=\'lc_run--019dbe1c-08f0-7660-b890-c85fbbc48410-0\', tool_calls=[{\'name\': \'get-current-date\', \'args\': {}, \'id\': \'call_SMSxsWv70UQSBWkFQNC0nh8h\', \'type\': \'tool_call\'}], invalid_tool_calls=[], usage_metadata={\'input_tokens\': 2459, \'output_tokens\': 12, \'total_tokens\': 2471, \'input_token_details\': {\'audio\': 0, \'cache_read\': 0}, \'output_token_details\': {\'audio\': 0, \'reasoning\': 0}}), ToolMessage(content=[{\'type\': \'text\', \'text\': \'2026-04-24\', \'id\': \'lc_1340ee0b-e1df-4d31-844b-89f835822a61\'}], name=\'get-current-date\', id=\'d8cd20b4-5889-404a-bde3-08501908b715\', tool_call_id=\'call_SMSxsWv70UQSBWkFQNC0nh8h\'), AIMessage(content=\'明天(2026年4月25日)北京的天气预报如下:\\n\\n- 天气:多云\\n- 温度:26°C / 15°C\\n\\n请注意天气变化和适时增减衣物!\', additional_kwargs={\'refusal\': None}, response_metadata={\'token_usage\': {\'completion_tokens\': 50, \'prompt_tokens\': 2485, \'total_tokens\': 2535, \'completion_tokens_details\': {\'accepted_prediction_tokens\': 0, \'audio_tokens\': 0, \'reasoning_tokens\': 0, \'rejected_prediction_tokens\': 0}, \'prompt_tokens_details\': {\'audio_tokens\': 0, \'cached_tokens\': 2432}}, \'model_provider\': \'openai\', \'model_name\': \'gpt-4o-mini-2024-07-18\', \'system_fingerprint\': \'fp_eb37e061ec\', \'id\': \'chatcmpl-DY41lR49iptKlVCDmdXM8CmkW8nn7\', \'service_tier\': \'default\', \'finish_reason\': \'stop\', \'logprobs\': None}, id=\'lc_run--019dbe1c-1605-7580-8dc2-06b4ff07470b-0\', tool_calls=[], invalid_tool_calls=[], usage_metadata={\'input_tokens\': 2485, \'output_tokens\': 50, \'total_tokens\': 2535, \'input_token_details\': {\'audio\': 0, \'cache_read\': 2432}, \'output_token_details\': {\'audio\': 0, \'reasoning\': 0}})]}', name='search', id='2593f5c7-d02a-42b1-8ae7-360b93331fcd', tool_call_id='call_02t1KWiUno4k4W2YCgvBJaZD')]}}
{'model': {'messages': [AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 61, 'prompt_tokens': 3113, 'total_tokens': 3174, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DY41nu3ZGVClTnkus2VssmFPPfpEc', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019dbe1c-1b9a-7bb2-ad9a-f0a3db86c91b-0', tool_calls=[{'name': 'email', 'args': {'input': '明天(2026年4月25日)北京的天气预报如下:\n\n- 天气:多云\n- 温度:26°C / 15°C\n\n因此,我将明天去北京。'}, 'id': 'call_wLWmua0RrL6SZTIrcelx4zxH', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 3113, 'output_tokens': 61, 'total_tokens': 3174, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}}
{'tools': {'messages': [ToolMessage(content="{'messages': [HumanMessage(content='明天(2026年4月25日)北京的天气预报如下:\\n\\n- 天气:多云\\n- 温度:26°C / 15°C\\n\\n因此,我将明天去北京。', additional_kwargs={}, response_metadata={}, id='008a1e7d-8b0c-4440-bea0-ba264ceb2647'), AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 87, 'prompt_tokens': 126, 'total_tokens': 213, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DY41oxtXHQT3CRKg8UIeD29qlismD', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019dbe1c-20fa-71d3-84c1-d9972a068a41-0', tool_calls=[{'name': 'send_email', 'args': {'to': '1277304395@qq.com', 'subject': '明天北京旅行安排', 'body': '您好!我希望通知您,我计划于明天(2026年4月25日)前往北京。根据天气预报,明天北京的天气为多云,预计温度在26°C到15°C之间。请做好相关准备。谢谢!'}, 'id': 'call_sCwfCnjB9MefL18oOhbnx1it', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 126, 'output_tokens': 87, 'total_tokens': 213, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='success', name='send_email', id='b3614a0b-d1e4-48c9-9407-8135d7ce52db', tool_call_id='call_sCwfCnjB9MefL18oOhbnx1it'), AIMessage(content='我已向您发送了一封电子邮件,通知您明天(2026年4月25日)将前往北京的行程安排。邮件中包含了天气预报信息。请查收!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 47, 'prompt_tokens': 221, 'total_tokens': 268, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DY41rEWUJEPgO6T7cnKSSCmya58VW', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019dbe1c-2bb4-73a0-9509-f949741a35f6-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 221, 'output_tokens': 47, 'total_tokens': 268, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}", name='email', id='faf67904-0e79-41cb-a994-ba7469ee8f76', tool_call_id='call_wLWmua0RrL6SZTIrcelx4zxH')]}}
{'model': {'messages': [AIMessage(content='明天(2026年4月25日)北京的天气预报如下:\n\n- 天气:多云\n- 温度:26°C / 15°C\n\n我已经向指定邮箱(1277304395@qq.com)发送了通知,告知将前往北京的行程安排及天气信息。请查收!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 73, 'prompt_tokens': 4067, 'total_tokens': 4140, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 3072}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_eb37e061ec', 'id': 'chatcmpl-DY41s9BLjtgJvgIFdFlOnAGK1sjFY', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019dbe1c-308e-79e3-94ed-ab21a9f8b4b5-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 4067, 'output_tokens': 73, 'total_tokens': 4140, 'input_token_details': {'audio': 0, 'cache_read': 3072}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}}可以去langsmith里追踪一下,如果tool_calls里有内容的话,基本上就是成功了。
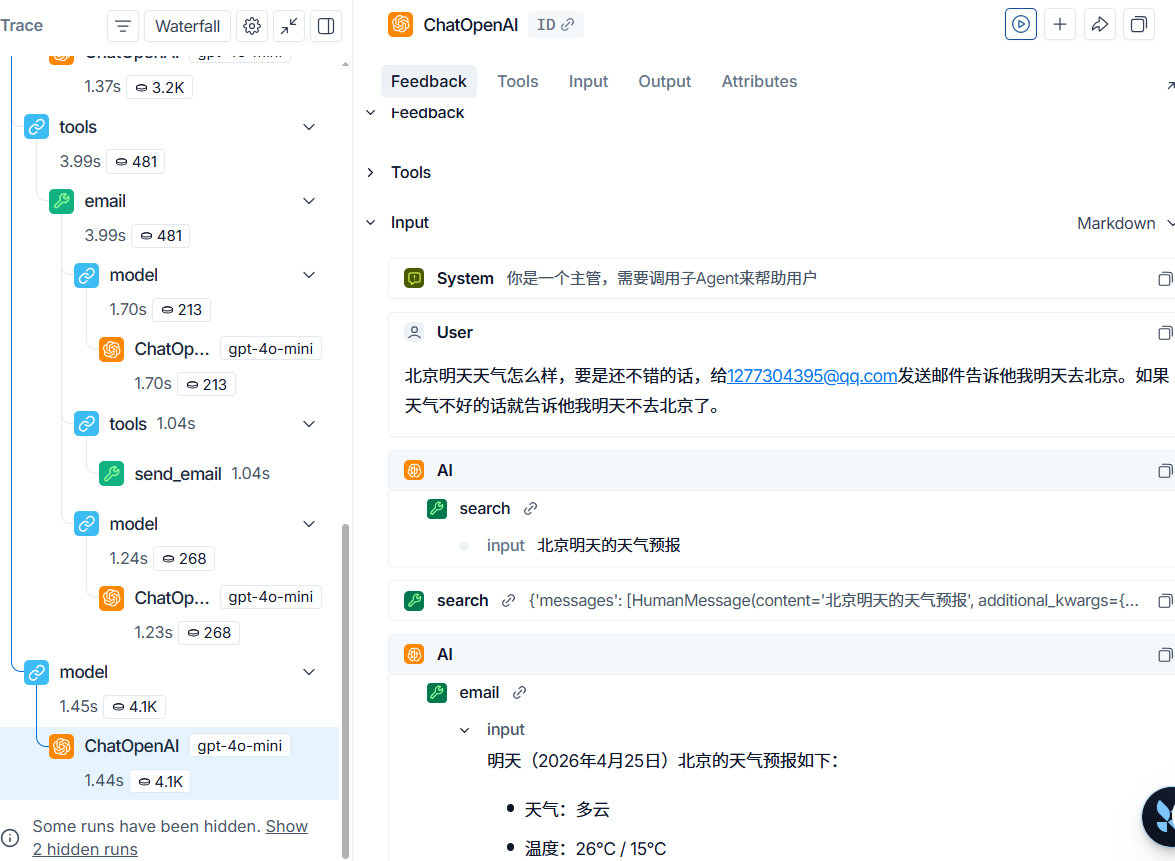

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)