时序异常检测鲨疯了!这两个顶会方向,一个省卡一个避坑,代码全开源!
时序异常检测在工业监控、金融及医疗等领域至关重要。传统方法多依赖数值驱动的专门模型,面临上下文理解能力不足、误报率高及基准测试集不一致等严峻挑战。
本文整合的两篇论文分别从模型架构创新与基准体系重构入手:前者提出的 VLM4TS 巧妙利用视觉语言模型(VLM)的仿人视觉推理能力,打破了分辨率与上下文的权衡难题;后者推出的 TSB-AD 则针对行业“房间里的大象”,通过构建首个大规模、高标准挖掘的异质数据集并确定了最可靠的评价指标 VUS-PR,为领域发展奠定了坚实的科学基准。
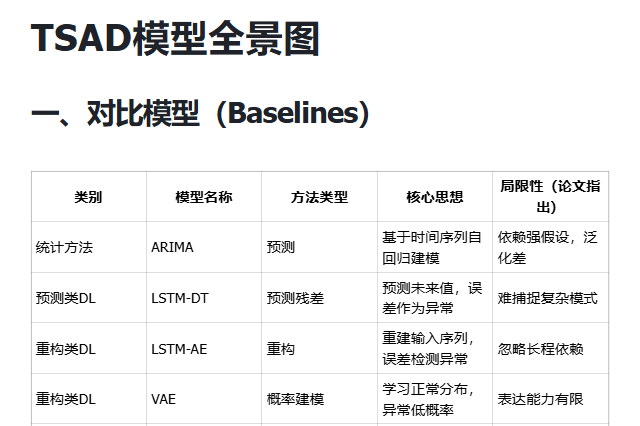
我整理了TSAD模型全景图,感兴趣的dd,希望能帮到你~
一、 论文1:[AAAI 2026] Harnessing Vision-Language Models for Time Series Anomaly Detection
方法:
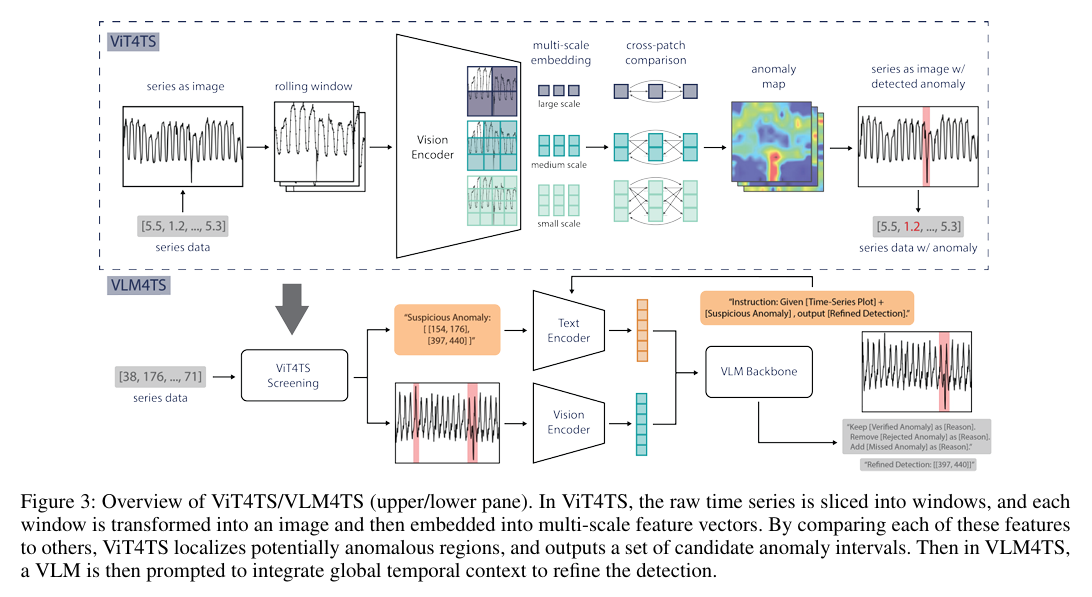
提出一种名为 VLM4TS 的两阶段框架(如图3):
-
ViT4TS(视觉筛选阶段):使用轻量级的 视觉变换器(ViT) 编码器。通过将滑动窗口内的时序数据渲染为2D线图,利用多尺度特征进行跨补丁比较(Cross-Patch Comparison),快速锁定异常候选区间。
-
VLM-Refinement(VLM验证阶段):将全量时序图及候选区间输入强力 VLM(如 GPT-4o),利用其全局上下文理解能力剔除伪异常,实现精准定位。
创新点:
-
跨模态迁移:证明了在图像数据上预训练的 VLM 无需任何时序微调即可在零样本(Zero-shot)设置下展现高超的异常识别能力。
-
多尺度补丁机制:在 ViT 编码中引入多尺度池化,有效捕捉从窄尖峰到长漂移的各类异常。其核心相似度计算公式为:
-
效率突破:通过“定位+验证”模式,规避了直接对长序列进行高分辨率图像处理带来的巨额成本。
-
论文链接:https://arxiv.org/pdf/2506.06836
二、 论文2:[NeurIPS 2024] The Elephant in the Room: Towards A Reliable Time-Series Anomaly Detection Benchmark
方法:
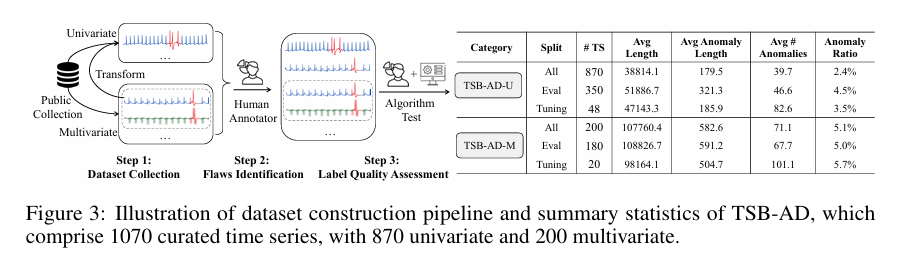
构建了名为 TSB-AD 的系统化基准体系(如图3):
-
数据清洗流水线:从40个数据集中提取1070条高质量时序,通过算法辅助+人工核对剔除误标和琐碎样本。
-
指标可靠性评估:对10种评价指标进行压力测试。
-
算法大模型评测:涵盖从传统统计法到最新基础模型(Foundation Models)(如 MOMENT, Chronos)的40种算法。
创新点:
-
数据集规模与质量:提供了目前最大规模的、经过人类感知与模型解释双重校验的异质数据集(含单变量与多变量)。
-
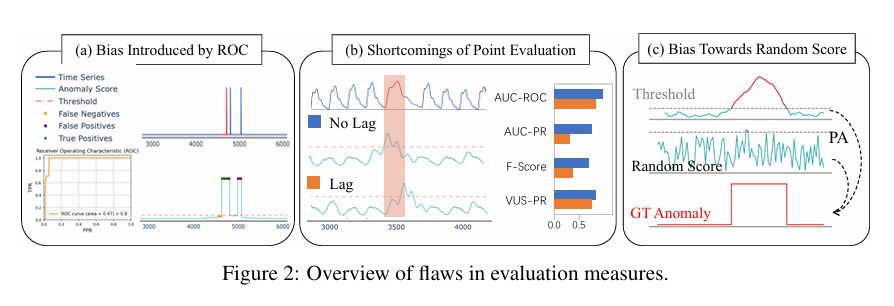
评价指标纠偏:通过实验证明 VUS-PR(曲线下面积体积) 是最可靠、对时延(Lag)最鲁棒的指标,而传统的 点调整(Point Adjustment, PA) 存在严重偏向随机噪声的隐患(如图2(c))。
-
发现统计学力量:研究发现基于 PCA 的变体 Sub-PCA 等简单方法在多项任务中排名第一,挑战了“深度架构必然更优”的行业共识。
-
VUS指标量化公式(以 VUS-PR 为例):
(注:该指标通过增加缓冲区处理边界模糊问题。)
-
论文链接:https://proceedings.neurips.cc/paper_files/paper/2024/file/c3f3c690b7a99fba16d0efd35cb83b2c-Paper-Datasets_and_Benchmarks_Track.pdf

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)