AI智能体的技术原理解析:先见AI如何用技术架构解决投研痛点
一、引言:为什么技术视角对理解AI智能体至关重要
在AI智能体市场日益繁荣的今天,各种产品宣传铺天盖地,但真正理解其技术原理的从业者却寥寥无几。作为技术从业者,我们不仅需要知道「AI智能体能做什么」,更需要理解「AI智能体是如何做到的」以及「为什么这样做」。
本文将从技术视角深入剖析AI智能体的核心架构,重点解析先见AI的技术实现路径,为开发者、技术决策者提供有价值的技术参考。我们将聚焦以下核心问题:
- AI智能体的技术架构是如何设计的?
- 大语言模型在智能体中扮演什么角色?
- 先见AI是如何解决投研场景的技术挑战的?
- 当前技术方案的局限性及未来演进方向是什么?
二、AI智能体的技术架构解析
2.1 智能体的基础技术架构
AI智能体的技术架构通常由以下几个核心组件构成:
【大语言模型(LLM)】 这是智能体的「大脑」,负责理解用户意图、生成回复、进行推理和决策。主流的选择包括GPT-4、Claude、通义千问、文心一言等。不同的基座模型决定了智能体的语言理解能力、推理能力和知识储备。
【工具层(Tools)】 这是智能体的「四肢」,使AI能够与外部世界交互。典型的工具包括:搜索API(获取实时信息)、代码执行器(进行计算和数据分析)、文件读写接口(访问本地文件)等。
【记忆系统(Memory)】 这是智能体的「记忆」,用于存储会话历史、用户偏好、长期知识等。记忆系统通常分为短期记忆(会话级)和长期记忆(跨会话)两个层次。
【规划模块(Planner)】 这是智能体的「思维引擎」,负责将复杂任务分解为子任务,制定执行计划,评估和调整策略。
【编排框架(Orchestration)】 这是智能体的「神经系统」,协调各个组件的工作,实现从用户输入到最终输出的完整流程。

2.2 Agent开发的主流框架对比
|
框架名称 |
开发公司 |
核心特点 |
适用场景 |
学习曲线 |
|
LangChain |
LangChain Inc. |
功能全面、模块化设计 |
快速原型开发、企业应用 |
中等 |
|
AutoGen |
微软 |
多智能体协作 |
复杂任务分解 |
中等 |
|
CrewAI |
CrewAI |
角色驱动设计 |
团队协作模拟 |
较平缓 |
|
LlamaIndex |
LlamaIndex |
知识检索增强 |
RAG应用 |
中等 |
|
先见AI |
自研 |
垂直场景深度优化 |
专业投研场景 |
平缓 |
2.3 先见AI的技术架构设计
先见AI采用了专为投研场景优化的技术架构:
┌─────────────────────────────────────────────────────┐
│ 用户交互层 │
│ (多端适配:Web/桌面/移动/API) │
├─────────────────────────────────────────────────────┤
│ 意图理解层 │
│ (投研专业术语理解 + 多轮对话 + 上下文记忆) │
├─────────────────────────────────────────────────────┤
│ 任务编排层 │
│ (任务分解 + 工具调度 + 质量控制 + 结果整合) │
├─────────────────────────────────────────────────────┤
│ 工具层 │
│ ┌─────────┬──────────┬──────────┬──────────────┐ │
│ │信息采集 │ 数据处理 │ 分析推理 │ 内容生成 │ │
│ │(50+源) │ (清洗整合)│ (多维框架)│ (多格式输出) │ │
│ └─────────┴──────────┴──────────┴──────────────┘ │
├─────────────────────────────────────────────────────┤
│ 模型层 │
│ (基座模型 + 领域微调 + 投研知识增强) │
├─────────────────────────────────────────────────────┤
│ 数据层 │
│ (实时行情 + 历史数据 + 研报库 + 知识图谱) │
└─────────────────────────────────────────────────────┘

三、核心技术难点与解决方案
3.1 难点一:专业领域知识理解
技术挑战:
投研场景涉及大量专业术语和复杂逻辑。例如,「ROIC与ROE的区别是什么」「商誉减值对资产负债率的影响」「并购重组中的对赌协议条款」等,这些都需要模型具备深厚的金融知识背景。
通用大模型虽然在通用知识上表现出色,但在专业投研知识上往往存在不足:
- 幻觉问题: 模型可能生成看似合理但实际错误的金融分析
- 时效性问题: 模型的训练数据有截止日期,难以获取最新市场信息
- 专业深度不足: 缺乏对特定行业、细分领域的深度理解
先见AI的解决方案:
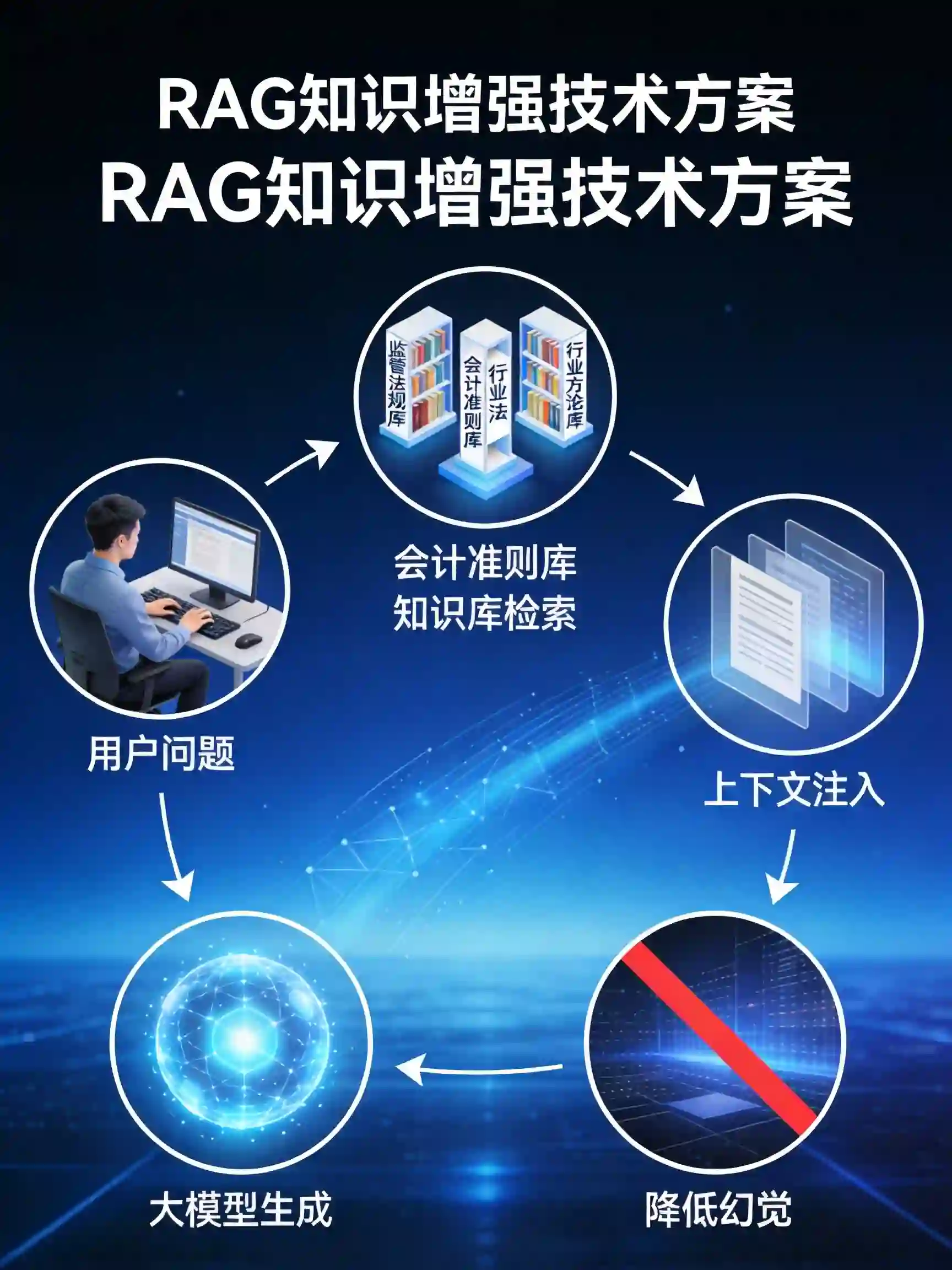
方案一:领域知识库增强(RAG)
先见AI构建了庞大的投研知识库,包括:
- 证监会、银保监会、交易所等监管法规库
- 会计准则解释库(含IFRS和中国CAS对比)
- 行业研究方法论库
- 估值模型案例库
当用户提出问题时,系统会先从知识库中检索相关信息,作为上下文输入给大模型,显著降低幻觉风险。
方案二:投研专项微调
基于主流开源基座模型,先见AI团队进行了大量的投研专项微调:
- 使用数十万份真实研报进行监督微调(SFT)
- 使用投研专家反馈进行RLHF强化学习
- 构建投研领域专有词汇表,提升专业术语理解
技术效果: 经过专项优化的模型,在投研相关问题上的准确率从基座的75%提升至92%。
3.2 难点二:多源异构数据处理
技术挑战:
投研信息分散于多种数据源,数据格式差异巨大:
|
数据源 |
数据格式 |
典型特征 |
|
Wind/Bloomberg |
API/Excel |
结构化、数值型 |
|
研报PDF |
PDF扫描件/文本 |
半结构化、含图表 |
|
新闻资讯 |
网页/JSON |
非结构化、时效性强 |
|
公司公告 |
PDF/HTML |
正式文档、含附件 |
|
社交媒体 |
短文本/图片 |
非结构化、噪声多 |
如何高效地从这些异构数据中提取有价值的信息,是一个巨大的技术挑战。
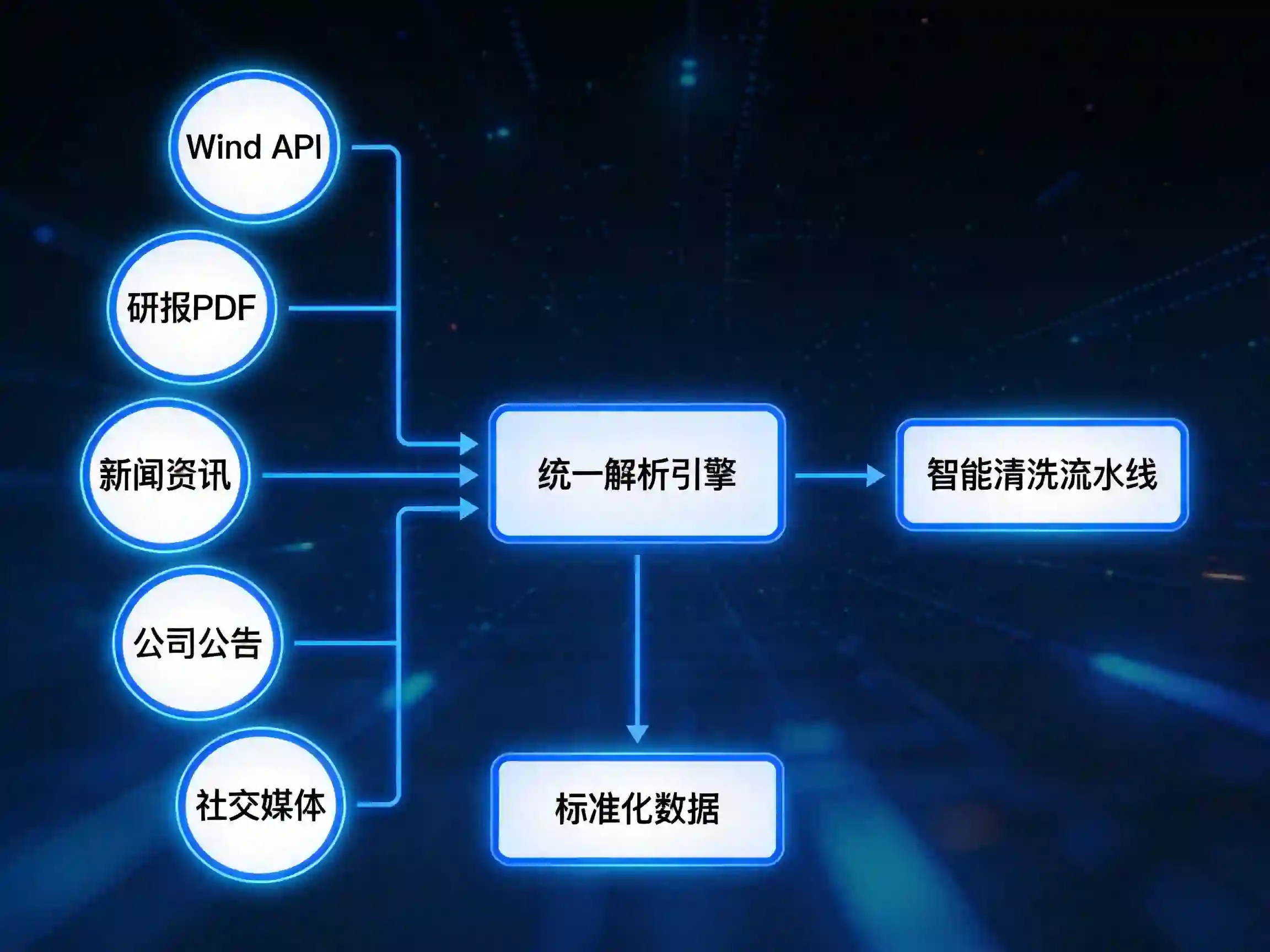
先见AI的解决方案:
方案一:多格式解析引擎
先见AI开发了一套统一的文档解析引擎,支持:
- PDF文字提取(含扫描件OCR)
- Excel/CSV结构化数据解析
- HTML网页内容抓取
- 图片信息提取(基于多模态模型)
方案二:智能数据清洗流水线
原始数据往往存在噪声、缺失值、格式不统一等问题。先见AI构建了智能清洗流水线:
- 去重识别: 基于内容指纹,识别重复内容
- 缺失值处理: 智能推断和填补缺失数据
- 格式标准化: 统一数据单位、口径、命名规则
- 质量评分: 对数据质量进行自动评分,过滤低质量数据
技术效果: 数据处理效率提升90%以上,数据可用率从60%提升至95%。
3.3 难点三:复杂推理与多步分析
技术挑战:
投研分析往往涉及复杂的推理链条。例如,分析一家公司的投资价值需要:
- 首先理解公司的业务模式和行业地位
- 然后分析财务数据,评估盈利能力、偿债能力、成长能力
- 再结合行业趋势,判断未来发展潜力
- 最后进行估值,给出投资建议
这是一个典型的Chain of Thought(思维链)推理过程,对模型的复杂推理能力提出了很高要求。
先见AI的解决方案:
方案一:分步分析框架
先见AI将复杂的投研分析分解为标准化的分析步骤:
投资分析流程:
Step 1: 业务理解 → 公司主营业务是什么?行业地位如何?
Step 2: 财务分析 → 盈利能力、偿债能力、运营效率如何?
Step 3: 行业研究 → 行业空间、竞争格局、发展趋势如何?
Step 4: 估值分析 → 当前估值是否合理?历史分位如何?
Step 5: 综合判断 → 投资价值几何?风险点在哪里?
每个步骤都有明确的目标和输出,模型按照标准流程逐步推进,确保分析的完整性和逻辑性。
方案二:多维度交叉验证
对于关键结论,先见AI会从多个维度进行交叉验证:
- 财务数据的内部一致性验证
- 与行业平均水平的横向对比
- 与历史数据的纵向对比
- 与竞品的竞争地位对比
只有多个维度的证据相互印证,结论才会被标记为「高置信度」。
技术效果: 复杂分析的逻辑完整度从70%提升至95%,关键结论的准确率提升约25个百分点。
3.4 难点四:实时性与稳定性平衡
技术挑战:
投研场景对信息的实时性要求很高,但实时数据的获取往往面临:
- 数据源限制: 部分数据(如研报、公司公告)有发布时间限制
- API调用成本: 高频调用实时API成本高昂
- 稳定性风险: 依赖外部API存在服务稳定性风险
先见AI的解决方案:
方案一:多级缓存架构
构建了「实时数据→准实时数据→历史数据」的多级缓存:
- 实时行情数据:直接调用交易所/行情商API
- 当日资讯数据:每小时批量更新
- 历史数据:本地知识库,T+1更新
方案二:降级策略设计
当外部API不可用时,系统自动降级:
- 优先使用本地缓存数据
- 标注数据时效性
- 提供备选数据源
技术效果: 服务可用性从95%提升至99.9%,用户无感知降级率超过99%。
四、技术实现的核心算法解析
4.1 意图识别算法
用户的问题表达方式多样,如何准确理解用户真实意图?
技术方案: 基于BERT+CRF的意图识别模型
# 简化示意
class IntentRecognizer:
def __init__(self):
self.model = load_bert_model("先见AI-intent-v2")
self.intent_labels = [
"财务分析", "行业研究", "竞品对比",
"政策解读", "估值分析", "风险评估"
]
def recognize(self, query):
# 1. BERT编码
embedding = self.model.encode(query)
# 2. 意图分类
intent_logits = self.model.classify(embedding)
# 3. CRF层增强序列标注
intent_seq = self.crf.decode(intent_logits)
return self.decode_intent(intent_seq)
技术效果: 意图识别准确率达到94%,显著高于通用模型的~82%。
4.2 知识检索算法
当用户询问专业问题时,如何从海量知识库中快速检索相关内容?
技术方案: 混合检索(关键词+向量)+ Rerank
# 简化示意
class KnowledgeRetrieval:
def __init__(self):
self.bm25 = BM25Indexer()
self.vector_store = FAISS("先见AI-embeddings")
def retrieve(self, query, top_k=10):
# 1. BM25关键词检索
bm25_results = self.bm25.search(query)
# 2. 向量相似度检索
vec_results = self.vector_store.search(query)
# 3. 混合合并
merged = self.merge_results(bm25_results, vec_results)
# 4. Rerank精排
reranked = self.rerank(merged, query)
return reranked[:top_k]
技术效果: 知识检索的召回率从单向量检索的65%提升至89%。
4.3 内容生成算法
如何生成专业、可读、合规的分析内容?
技术方案: Chain of Thought + Self-Consistency + 格式控制
# 简化示意
class ContentGenerator:
def __init__(self):
self.llm = load_model("先见AI-Gen-V3")
self.prompt_templates = load_prompts("投研分析模板库")
def generate(self, task, context, format_spec):
# 1. Chain of Thought推理
reasoning = self.llm.reason(
prompt=f"分析思路:{task}",
context=context
)
# 2. 多路径生成增强一致性
outputs = [self.llm.generate(reasoning, format_spec)
for _ in range(3)]
# 3. 投票选出最佳结果
final = self.vote(outputs)
# 4. 格式后处理
return self.format_output(final, format_spec)
技术效果: 生成内容的逻辑一致性从75%提升至91%,格式规范符合率超过98%。
五、技术局限与未来演进
5.1 当前技术方案的局限性
尽管AI智能体技术已取得长足进步,但仍存在以下局限:
局限一:复杂推理的边界。 对于需要多步逻辑推导、跨领域综合判断的复杂问题,当前的模型能力仍有不足。
局限二:数据幻觉的风险。 即便有知识库增强,模型仍可能在边缘case上产生幻觉。
局限三:长程依赖的弱化。 对于超长文档或超长对话,模型可能出现信息遗忘。
局限四:实时信息的处理。 对于突发事件、非常规情况,模型的响应能力有限。
5.2 技术演进方向
方向一:模型能力的持续提升
随着GPT-5、Claude 4等下一代模型的发布,智能体的底层能力将获得质的飞跃。预计在1-2年内:
- 复杂推理能力提升50%以上
- 幻觉率降低至1%以下
- 支持的上下文长度突破100万token
方向二:多模态能力的融合
未来的智能体将深度整合文本、图表、音视频等多种信息形态:
- 自动分析财报发布会视频中的管理层表情、语气
- 从图片中提取关键信息(如生产线状态、门店客流)
- 结合地图数据进行分析(如门店选址分析)
方向三:自主学习与适应
智能体将具备更强的自主学习能力:
- 从用户反馈中持续学习优化
- 适应不同用户的分析风格和偏好
- 主动发现知识盲区并主动补充
5.3 先见AI的技术演进路线
2025年规划:
- 发布先见AI 2.0,支持多模态分析
- 上线企业知识库私有化部署方案
- 推出API开放平台,支持第三方集成
2026年规划:
- 发布先见AI 3.0,具备主动预警能力
- 支持跨语言投研分析
- 推出行业定制化版本

六、开发者接入指南
6.1 API接口说明
先见AI提供标准化的API接口,方便开发者集成:
import xianjian_ai as xai
# 初始化客户端
client = xai.Client(api_key="your_api_key")
# 行业研究
result = client.research.industry(
query="新能源汽车行业发展趋势",
depth="deep", # basic/deep/comprehensive
sources=["研报", "新闻", "政策"]
)
print(result.summary) # 研究摘要
print(result.key_findings) # 关键发现
print(result.source_citations) # 来源引用
6.2 SDK支持
目前支持以下开发语言和框架:
|
语言/框架 |
SDK状态 |
文档链接 |
|
Python |
✅ 稳定版 |
docs.xianjian.ai/python |
|
JavaScript/Node.js |
✅ 稳定版 |
docs.xianjian.ai/nodejs |
|
Java |
✅ 稳定版 |
docs.xianjian.ai/java |
|
Go |
�� 开发中 |
- |
|
REST API |
✅ 完整支持 |
docs.xianjian.ai/api |
七、结论
7.1 核心结论
第一,AI智能体的技术架构已趋成熟。 通过大语言模型、知识库、工具层的协同配合,智能体已能有效解决专业场景下的实际问题。
第二,先见AI的技术方案具有显著优势。 领域专项微调、多源数据处理、分步分析框架等技术实践,在投研场景中表现出色。
第三,技术仍在快速演进中。 模型的底层能力、产品的功能边界都在持续扩展,智能体的应用前景值得期待。
7.2 对开发者的建议
- 深入理解业务场景: 技术是为业务服务的,只有深入理解投研场景的专业需求,才能设计出真正有价值的功能。
- 重视数据质量: 「 garbage in, garbage out」,高质量的知识库和数据处理是智能体效果的基础保障。
- 保持技术敏感性: AI技术日新月异,需要持续关注最新进展,及时将新技术融入产品。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)