体系结构论文(101):Agentic AI-based Coverage Closure for Formal Verification
Agentic AI-based Coverage Closure for Formal Verification
这篇文章讲的是什么
这篇文章讨论的不是“让 LLM 从零做完整 formal verification”,而是更具体的一个环节:
如何利用 agentic AI 去做 formal verification 里的 coverage closure,也就是“把还没覆盖到的 RTL 区域尽量补上”。
在已有 formal verification 流程和 Saarthi agent 框架基础上,再加两个 coverage 相关 agent,让系统能读 coverage report、定位 coverage hole、自动生成新的 SystemVerilog assertions / cover properties,然后反复跑 formal 工具,直到 coverage 提升。
所以这篇文章的定位很明确:
1. 它不是一个完整的“AI 验证工程师”从头到尾替代方案。
2. 它更像 Saarthi 的一个增强模块。
3. 它解决的是 formal flow 中非常现实、也非常耗人的一个痛点:coverage 老是收不齐。
背景知识:1. 什么是 formal verification
formal verification 可以理解成:不是靠随机仿真去“试”,而是用数学方法去“证明”设计在所有可能输入下是否满足某些性质。
比如你写一个 RTL 模块,仿真只能测一部分输入情况;formal 则是尽量在状态空间上穷举或推理,检查某个 property 是否总成立。
2. 什么是 SVA
SVA 指 SystemVerilog Assertions,也就是 SystemVerilog 里的断言/性质描述语言。你可以把它理解成:
“我希望电路在满足某个前提时,后面必须出现某种行为”的形式化表达。
例如文中的 Listing 2:
如果 `(a && b)` 在时钟上升沿成立,那么下一拍 `c` 应该等于上一拍的 `d1`。
这种 property 可以拿给 formal 工具证明,或者找反例。
3. 什么是 coverage closure
验证里有一个现实问题:你写的 property 到底有没有把 RTL 中的重要逻辑覆盖到?
比如一个 if/else:
1. if 分支被证明过、被触发过;
2. else 分支从来没被触发;那 coverage 就不完整。
formal coverage 本质上是在问:
1. 设计里的哪些 RTL 语句、分支、表达式被验证环境真正触达了?
2. 哪些还没被 exercise 到?
3. 没覆盖到是因为没写相关 property,还是因为约束太强、根本到不了?所谓 coverage closure,就是把这些 coverage hole 逐步补齐。
4. 为什么 coverage closure 很麻烦
因为它不是单纯“再写几个断言”。
你得先判断:
1. 哪些语句没覆盖;
2. 它们属于 if/else、case,还是普通语句;
3. 相关控制条件是什么;
4. 对应的时钟、reset、信号关系是什么;
5. 这个 hole 是真的可达,还是环境约束把它堵死了;
6. 新生成的 property 会不会写错、写重复、写得过强或过弱。这件事很吃经验,也非常耗人,所以作者觉得它很适合交给 agentic AI 试一试。
一、引言
引言先强调一个行业事实:验证经常占项目时间的大头,文中甚至提到可达项目时间的 60%。而 coverage 又常常是 sign-off 的硬指标。
作者的切入点不是“formal verification 自动化”这种特别大的口号,而是:
现有自动 assertion generation 和 formal execution 流程即使能跑起来,最后还是经常留下 coverage gap。
这个判断是合理的。因为很多自动化工作主要关注:
1. 根据 spec 生成 assertion;
2. 把 assertion 丢给 formal 工具跑;
但并不一定会系统性地问:
“哪些 RTL 分支其实还没被覆盖到?”
因此,作者提出的三个贡献都围绕 coverage:
1. 自动 gap 分类;
2. 定向 property 生成;
3. 迭代式 coverage closure。
从问题定义上说,这篇文章没有夸大到“AI 取代 formal engineer”,而是瞄准 formal 工程里一个真实且可量化的子问题,这一点是加分的。
二、 Background
第二部分分成两小节:
1. Agentic workflows。
2. Formal coverage。
前半部分基本是在解释 agentic AI 的典型特征:任务拆解、提议-批判-修复循环、多 agent 协作、工具调用、人类监督等。这些内容不新,更多是铺垫。
后半部分 formal coverage 的讲解更有实际价值。作者用一个很小的 RTL 片段(Listing 1)和一个 SVA(Listing 2)说明 line coverage 是怎么来的。

1. RTL 里有一个 if/else。
2. 如果 formal tool 只证明或触达了 if 分支对应的行为,而 else 分支没有被 exercise。
3. 那么 line coverage 就不会是 100%。
作者借这个例子强调一个常被忽略的问题:
coverage 不完整,不一定是设计有 bug,也可能是:
1. assertion 没写到位;
2. environment constraint 太强;
3. proof 深度不够;
4. 某个分支根本没被形式化地驱动到。
所以 coverage closure 本身就是一个推理和建模问题,而不只是“多写点 assertion”。
三. Methodology 总览
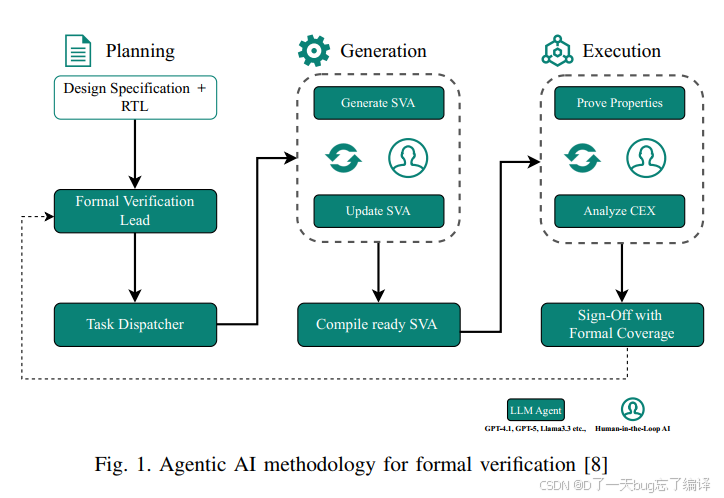
Figure 1 其实不是本文新方法图,而更像 Saarthi 的总流程示意。图里大致包含:
1. 从设计规格和 RTL 出发。
2. 生成 SVA。
3. 证明性质。
4. 分析 CEX。
5. 更新 SVA。
6. 做 formal coverage,最后 sign-off。
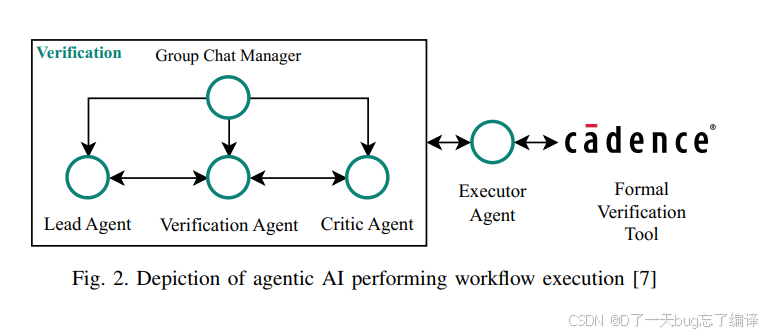
Figure 2 则把 multi-agent 执行方式画得更清楚:lead agent、verification agent、critic agent、executor agent,再加 group chat manager 和 formal tool。
为什么 coverage closure 被设计成 agent 问题:
1. 一部分 agent 负责理解任务和上下文;
2. 一部分负责生成形式化 property;
3. 一部分负责检查质量;
4. 一部分负责调用工具、看结果、决定是否继续迭代。
从研究角度讲,这两张图更多是在借已有 Saarthi 框架给本文方法做托底,而不是本文最强的原创部分。
coverage closure 子流程
真正属于本文自己的部分,是 Section III-B 以及 Figure 3、Figure 4 展示的 coverage pipeline。
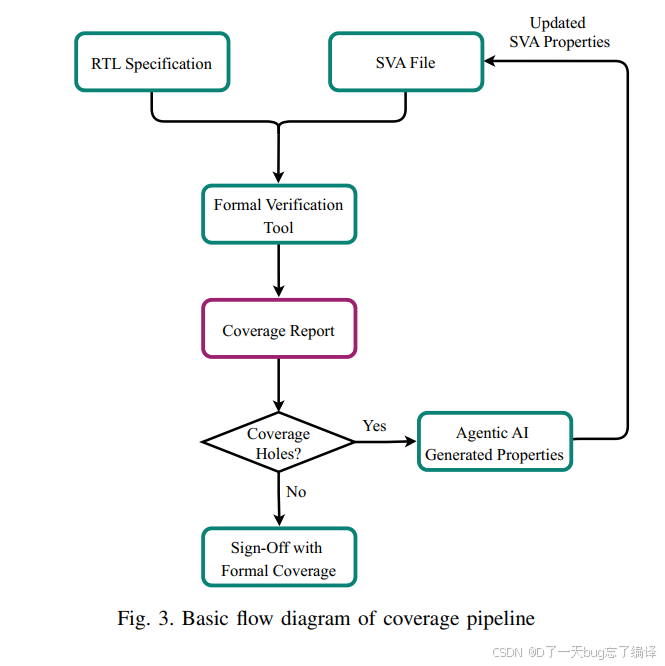
作者的方法流程可以概括成:
1. 先把 RTL、已有 SVA 文件送进 formal verification tool。
2. tool 跑完后生成 coverage report。
3. 如果没有 hole,就直接 sign-off。
4. 如果有 hole,就进入 agentic AI coverage stage。
5. coverage hole analyzer 读取 coverage report 和 RTL 上下文,定位未覆盖区域。
6. SVA property generator 根据分析结果生成新的 assertions / cover properties。
7. 把新 property 合并进 SVA 文件。
8. 再次调用 formal tool,重新跑 coverage。
9. 重复这个循环。
Figure 3 画的就是这个最基础的闭环。它虽然不复杂,但很重要,因为它把“coverage 提升”这个目标落到了一个明确的输入输出链条里。
Coverage Hole Analyzer
Coverage Hole Analyzer 的任务不是直接写 assertion,而是先把“coverage hole 到底是什么”结构化。
论文里说它会做几件事:
1. 定位未覆盖 RTL 代码的位置。
2. 恢复 surrounding context,也就是周围的结构和语义上下文。
3. 识别 hole 所属模块、时序行为、输入输出信号、前置条件。
4. 判断它属于 if/else、case、always_ff、always_comb 等哪种结构。
5. 把这些信息压成精简 JSON,供下游 agent 使用。
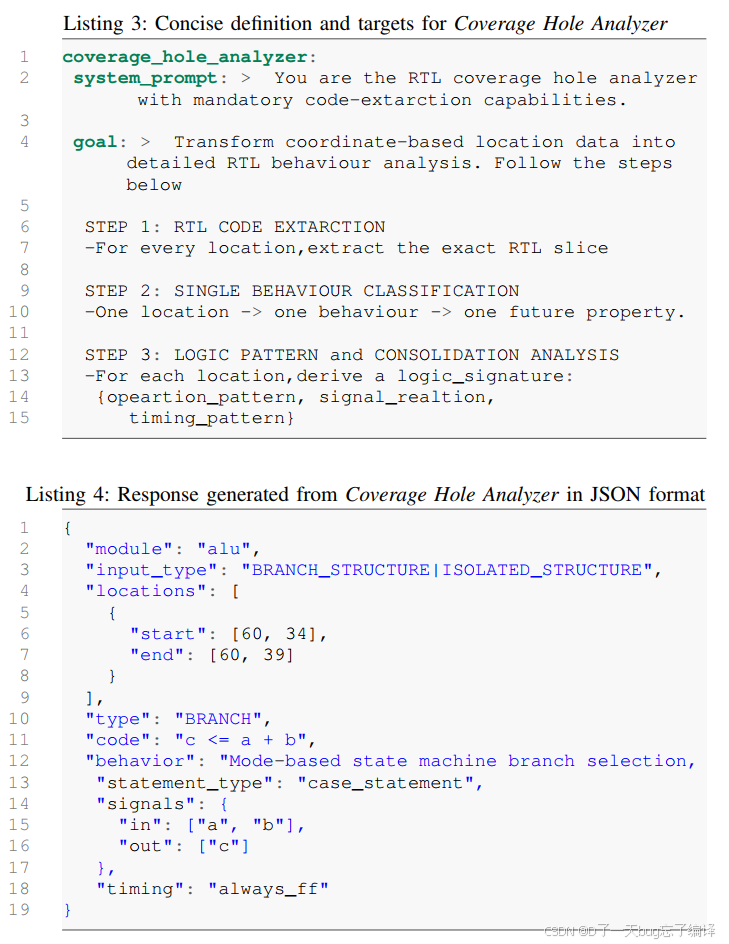
文章中 Listing 3 给了 agent 的 system prompt 和目标,大意是让它做 RTL coverage hole 分析,并带强制代码抽取能力。Listing 4 则展示了一个 JSON 输出例子。
这里的设计思路是合理的:
1. 不让生成 agent 直接啃原始 coverage report 和整份 RTL。
2. 先做一次“结构化中间表示”。
3. 再让 property 生成建立在这个中间表示之上。
这相当于把大模型任务拆成“理解 hole”与“生成 property”两步,降低了复杂度。
但这一块也带来一个明显风险:如果 analyzer 的抽取不准,后面所有步骤都会被污染。作者在实验分析里也承认,coverage hole analyzer 的 RTL 抽取质量会直接影响最终 proven rate。
SVA Property Generator
在拿到 JSON 输出后,SVA Property Generator 开始生成针对性 property。

文中 Listing 5 给了这个 agent 的定义和目标。它的约束很具体,例如:
1. 只能使用已有信号。
2. 要匹配现有 timing style。
3. 对 `always_ff` 优先使用 `|=>` 这种时序写法。
4. 尽量生成单 statement 形式的 property。
这些约束非常像真实工程经验。
1. 写法是否符合原工程习惯;
2. 命名是否重复;
3. 是否和已有 SVA 文件兼容;
4. reset、clock 语义是否正确;
5. property 是否 traceable 到原 coverage location。

Listing 6 给了一个生成例子:
这个例子本身不复杂,但它能帮助你理解作者想做的事情:
对于一个未覆盖的简单语句 `c <= a + b`,agent 不是写自然语言解释,而是生成一个真正能送进 formal 工具的 SVA。
这一步把“语言理解”落到了“EDA artifact 生成”上,是整篇文章最实际的部分。
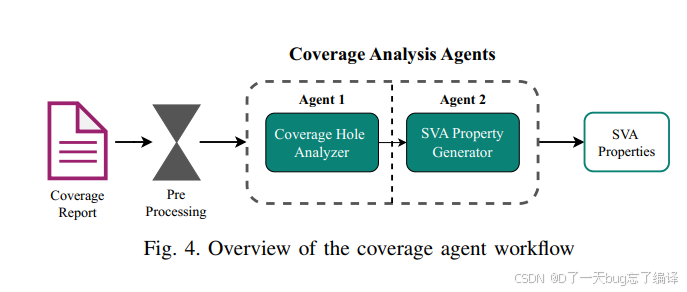
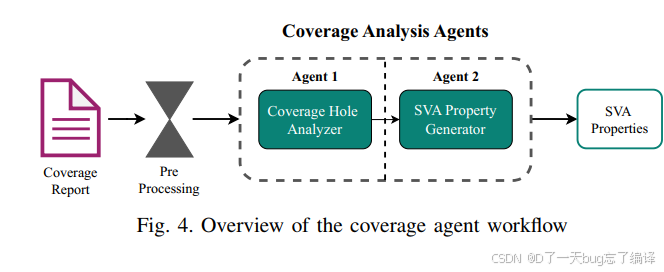
Figure 4 把两个 coverage agent 以及 preprocessing 的关系画了出来:
1. coverage report 先经过预处理;
2. 进入 Coverage Hole Analyzer;
3. 输出给 SVA Property Generator;
4. 生成新 SVA;
5. 再回 formal verification。
coverage closure 不是一次性问答,而是一个流水线。
也就是说,作者并没有把这个问题建模成“给 LLM 一份 report,让它一次性吐出所有答案”;而是设计成一个可迭代、可插拔、可插入 HIL 的流程。
迭代机制
论文提到每次更新 SVA 文件后,formal tool 会重新执行,生成新的 coverage report。然后 agent 再根据新的 hole 更新 property 集合,直到达到目标 coverage。
这其实比“生成一个最终 property 集合”更接近现实。
因为真实项目里 coverage 是动态变化的:
1. 你补了一条 property,可能带出新的 uncovered branch;
2. 也可能让某些原来被掩盖的问题暴露出来;
3. 甚至可能生成过强 property,导致证明难度上升。
作者还提到,遇到纯静态分析解决不了的情况,可以引入 expert agent 或 HIL 来避免 over-constraint 和复杂边界误判。
四、实验
实验部分用更新后的 Saarthi + coverage agents,在多个设计上做比较,包括:
1. ECC
2. CIC Decimator
3. AXI4LITE
4. Automotive IP
5. Memory Scheduler
这里既有开源设计,也有内部工业设计。虽然规模不算特别大。
作者使用两个 KPI:
1. Proven percentage:LLM 生成的 property 中,有多少最终被证明成功。
2. Coverage:经过完整 formal flow 之后得到的 coverage。
coverage 提升和 property 质量不完全等价。你可能生成了很多 property,coverage 上去了,但 proven rate 反而下来了。
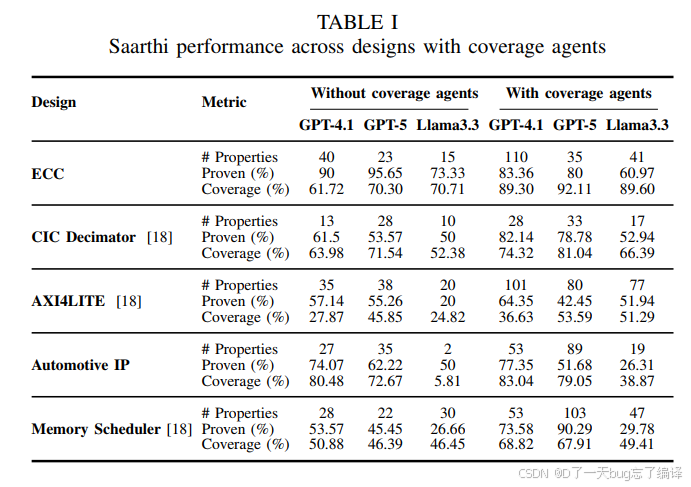
Table I 对比了“without coverage agents”和“with coverage agents”,并分别测试 GPT-4.1、GPT-5、Llama3.3。
这张表最值得读的地方,不是单纯看 coverage 有没有提升,而是看三个变量之间的关系:
1. 生成了多少 property;
2. proven rate 变化如何;
3. coverage 最终涨了多少。
先看 ECC:
1. 不加 coverage agents 时,GPT-5 coverage 是 70.30%。
2. 加了 coverage agents 后,GPT-5 coverage 到 92.11%。
这个提升非常显著,说明在这类设计上,coverage closure agent 确实有效。
再看 AXI4LITE:
1. GPT-5 从 45.85% 提升到 53.59%。
2. GPT-4.1 从 27.87% 提升到 36.63%。
3. Llama3.3 从 24.82% 提升到 51.29%。
这里也能看到明显提升,但不同模型差异很大,说明这个流程对基础模型能力仍然敏感。
再看 Automotive IP:
1. GPT-4.1 coverage 从 80.48% 到 83.04%,提升有限。
2. GPT-5 反而从 72.67% 到 79.05%,有提升但不夸张。
3. Llama3.3 从 5.81% 到 38.87%,提升巨大但绝对值仍不算高。
这说明:当设计复杂、或者模型本身能力不稳定时,这套流程并不能保证所有维度都漂亮。
再看 Memory Scheduler:
1. GPT-5 coverage 从 46.39% 到 67.91%,提升显著。
2. proven rate 也从 45.45% 到 90.29%,这一点很亮眼。
综合看,Table I 能支撑一个中等强度的结论:
coverage agents 大多数情况下能提升 coverage,而且复杂设计中提升往往更明显。
但它不能支撑“agentic AI 已经稳定解决 formal coverage closure”这种更强结论。
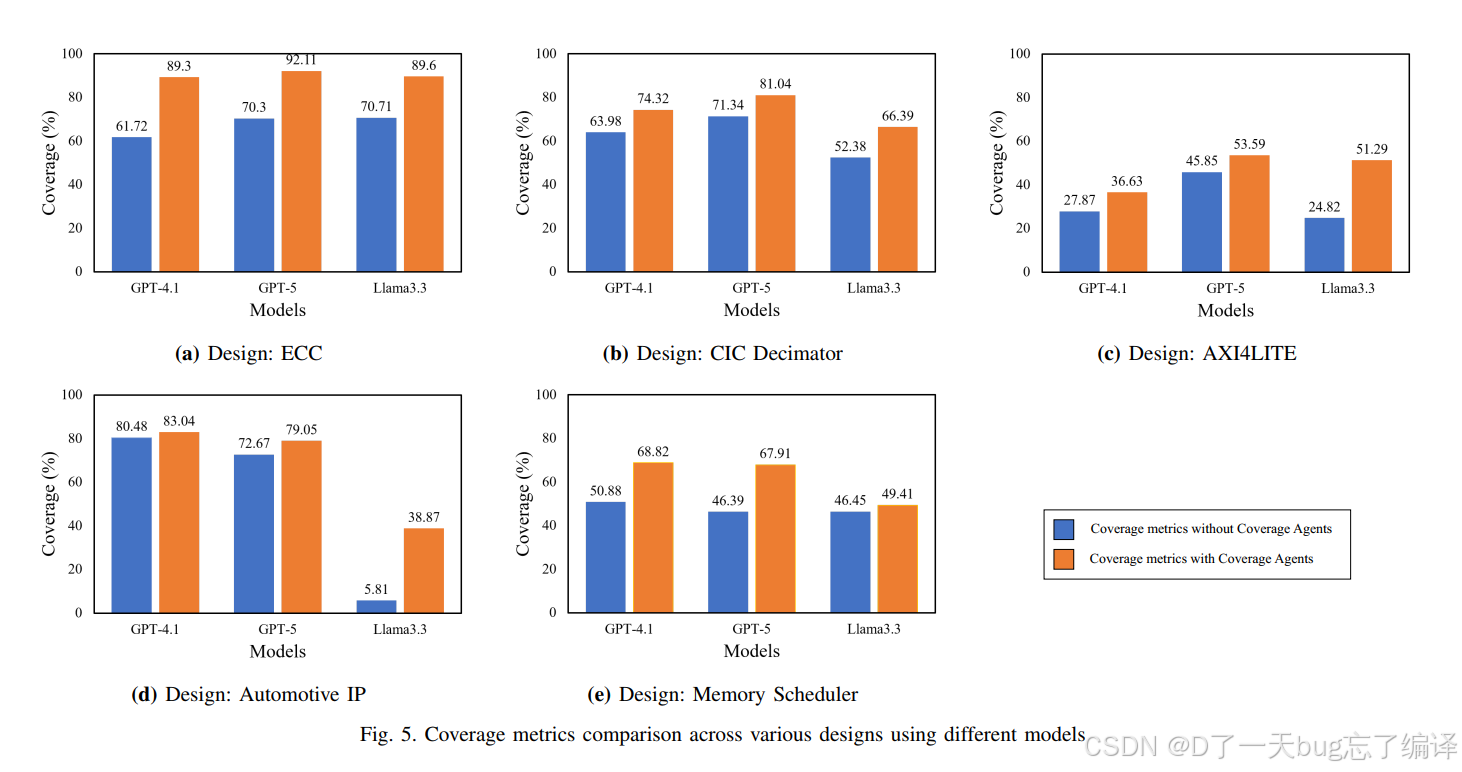
Figure 5 把不同设计、不同模型、加不加 coverage agents 的 coverage 指标画成对比图。
这张图的作用主要是让趋势更直观:
1. 几乎所有设计在加 coverage agents 后都比基线更高;
2. GPT-5 整体表现最好;
3. Llama3.3 波动较大;
4. 提升幅度和设计复杂度、基础 coverage 状态都有关系。
图和表配合起来看,会更容易得出一个客观判断:
这篇文章的方法不是“在所有设计上都暴涨”,而是“多数情况下稳定增益,个别场景提升有限甚至伴随 proven rate 下降”。
我认为这篇文章一个比较好的地方,是它没有把结果写成无条件胜利叙事。
作者明确提到:
1. 有些情况下,coverage 上升了,但 proven rate 下降了。
2. 原因是新加入 property 虽然能覆盖更多 RTL,但这些 property 可能更难证明。
3. 如果 Coverage Hole Analyzer 抽取上下文不准,或者 LLM 生成了错误/重复 property,也会影响 proven rate。
这一点很重要,因为 formal verification 不是“多写一点 property 就一定更好”。如果 property 写得不严谨、过强、过弱、重复、甚至和设计 intent 不一致,反而可能制造新的噪声。
作者还说,目前这些结果是在没有 HIL 的情况下获得的,未来把 HIL 插进去,可能会进一步提高效果。
这句话可以理解成两面:
1. 正面:说明纯自动流程已经有一定效果,还有提升空间。
2. 反面:也说明当前 fully autonomous 还不够稳,很多时候还是需要人把关。
四、个人看法
问题
第一,创新性更多来自 workflow 集成,而不是新算法。它更像工程整合型工作。
第二,实验规模有限。
第三,评测深度还不够。
第四,依赖上游抽取质量。
Coverage Hole Analyzer 一旦定位错、抽 context 错、理解 precondition 错,下游 property 生成就会被带偏。这使得系统鲁棒性很依赖第一步。
第五,coverage closure 不等于 verification closure。
文章提升了 formal coverage,但这不自动意味着:
1. property 语义就都正确;
2. design intent 就被完整刻画;
3. sign-off 风险就真的消失了。
如果只盯 coverage 数字,可能会高估系统实际价值。
这篇文章说明了一个现实趋势:EDA 里的 agent 真正有价值的地方,往往不是“替代所有工程师”,而是吃掉某个高重复、高上下文依赖、但又能通过工具反馈闭环的子任务。coverage closure 就很符合这个特点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)