【英飞凌 CY8CKIT-062S2-AI评测】DEEPCRAFT训练模型与模型应用
前言
英飞凌推出的DEEPCRAFT™ Studio是一款用于在边缘设备上开发人工智能和机器学习应用的综合解决方案。这个端到端的机器学习开发平台涵盖了整个机器学习工作流程,从收集和注释高质量数据、管理、分析和处理数据,到构建、评估和选择最佳模型,最终将模型部署到目标边缘设备。
DEEPCRAFT™ Studio是专家和非专家轻松构建生产级机器学习模型的最快方式,适用于音频事件检测、语音控制、预测性维护、手势识别、跌倒检测、信号分类以及材料检测等多种应用场景。其中推出的DEEPCRAFT™ Ready模型是面向生产的 Edge AI模型,网址:https://www.imagimob.com/ready-models有提供详细的介绍。
训练模型
上次咱尝试了实时数据流收集,由于需要采集多个样本,比较繁琐,此次直接借助官方提供的已完成数据标记和预处理的AI工程,开发者可直接在此基础上进行模型的训练,而无需进行数据的收集,多个样本反复去采集。
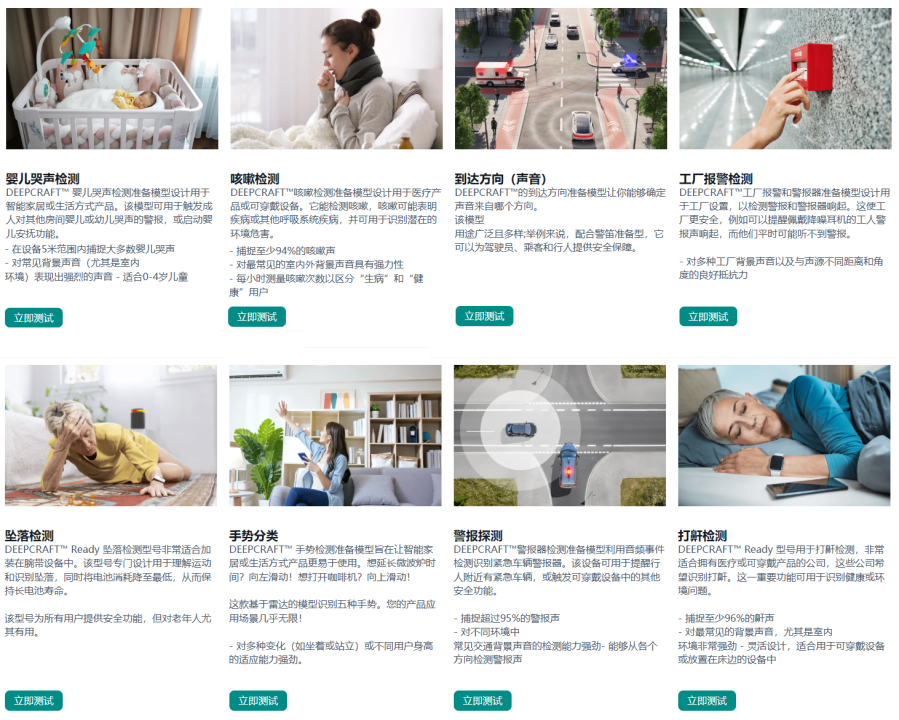
这里笔者选择麦克风下“Home Sounds Detection”参考工程,应用方向是实时检测家中异常声音检测,如下图所示:
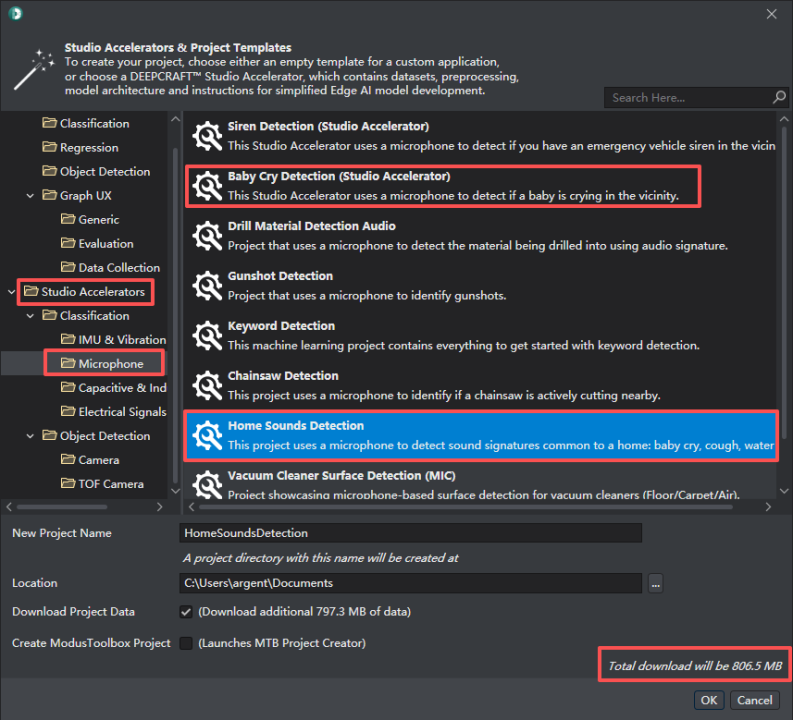
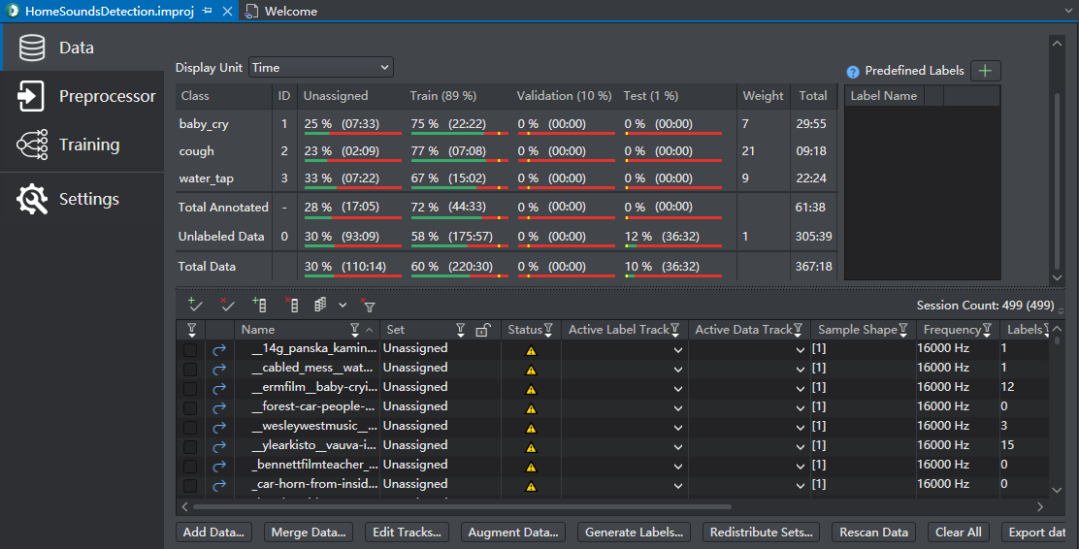
工程中默认的收集的数据包如下:
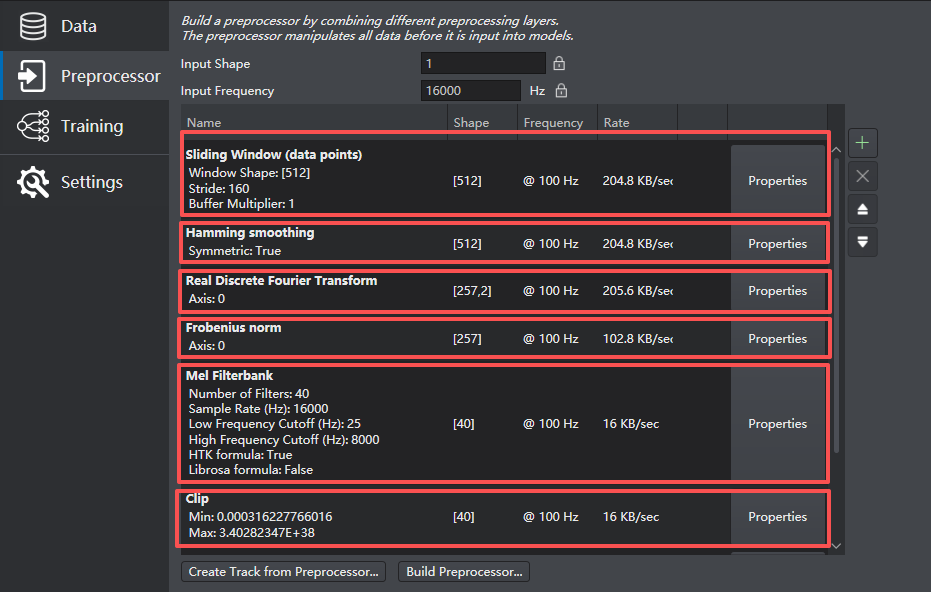
接下来是数据预处理,工具有提供多种类型的处理层,以确保模型训练的准确度。
在训练模型下,可建立模型并对模型进行训练,配置模型的参数,界面如下:
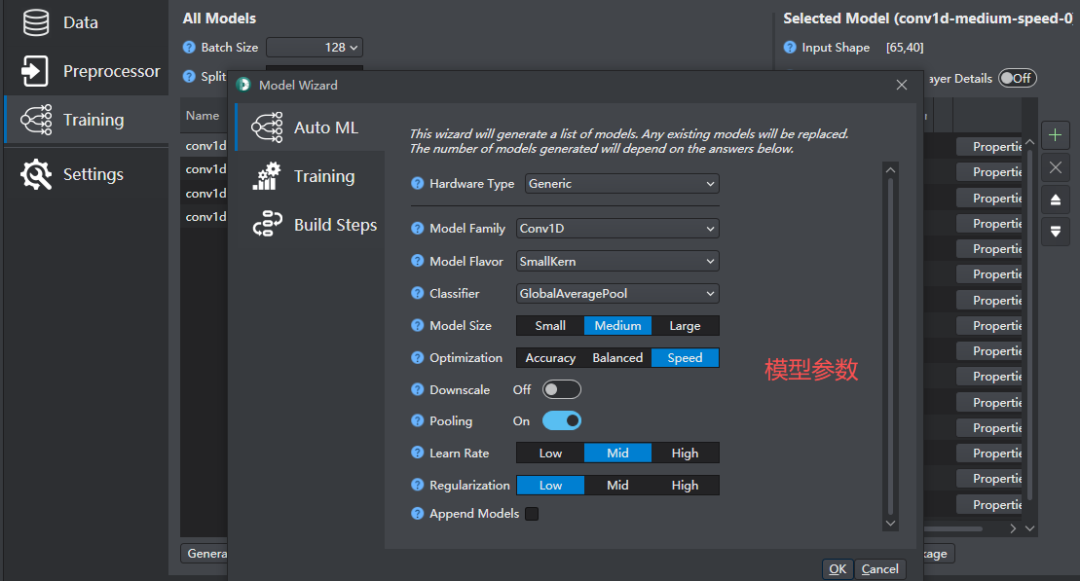
模型训练深度设置参数如下:
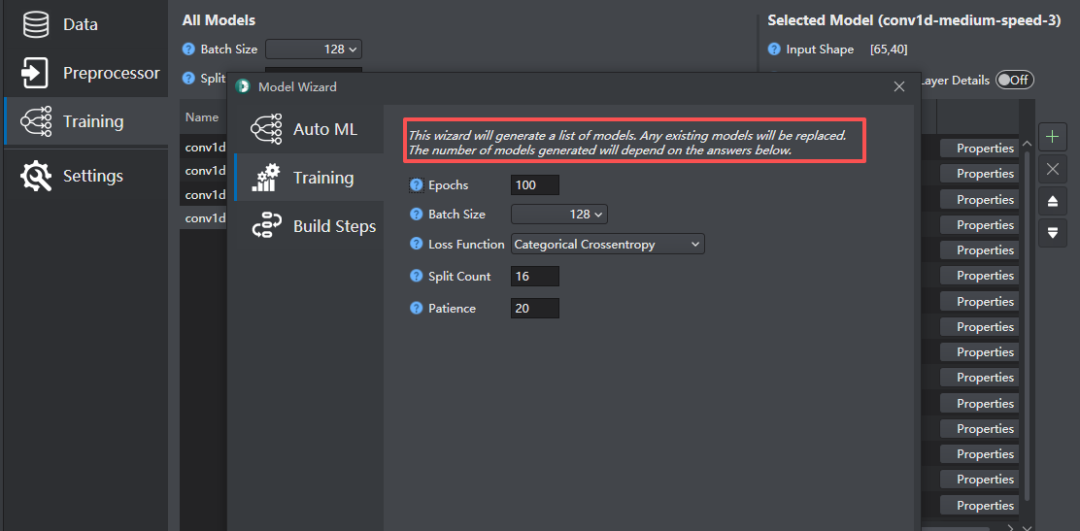
保存配置后,则可以将数据上传到云端进行模型的训练。
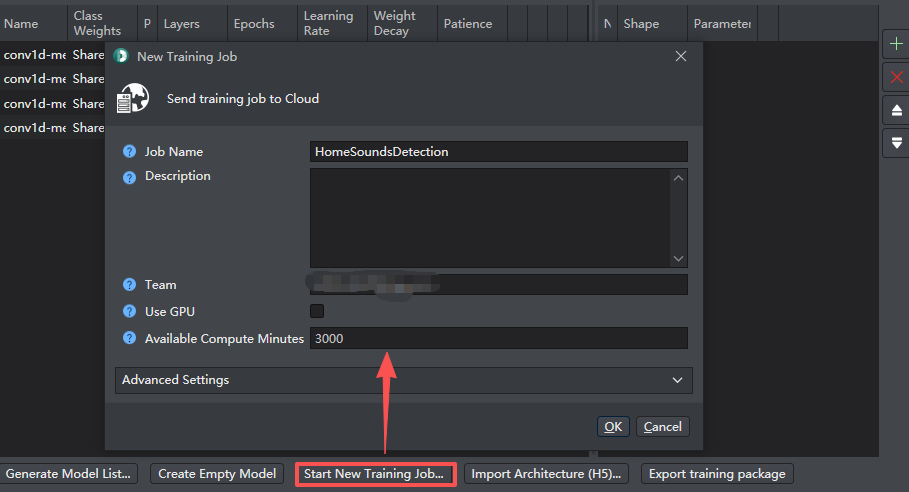
在云端进行模型训练完后,可看到云端模型训练的结果,则可以对比,下载最合适的模型,用于后续代码的生成和部署。
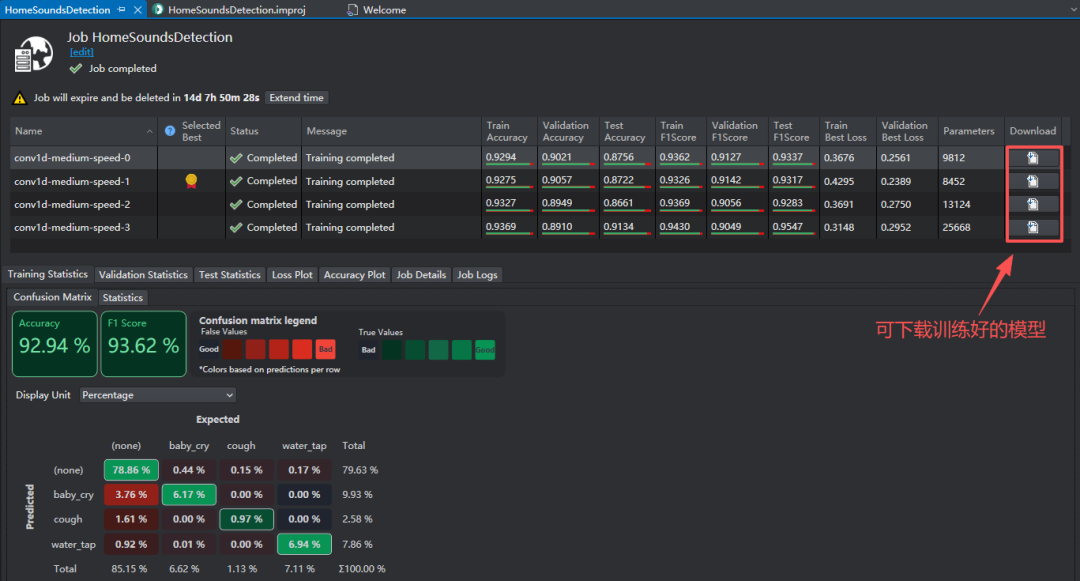
这里笔者下载模型3,如下:
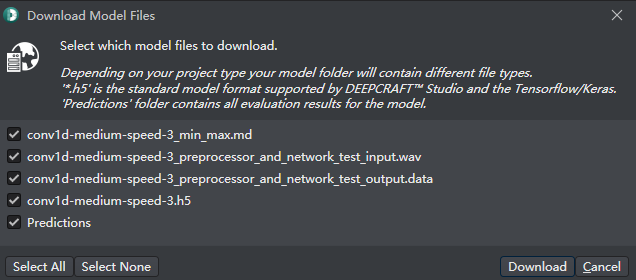
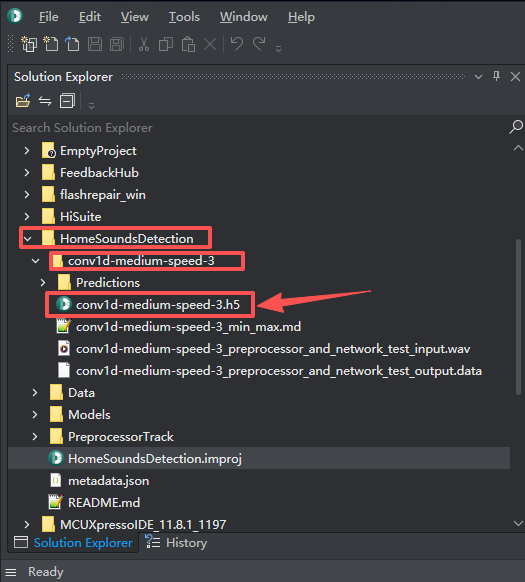
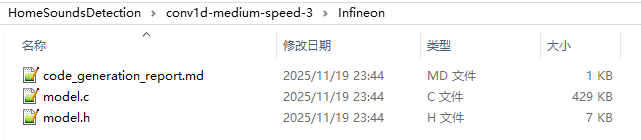
代码生成,配置相对应的硬件平台参数,并点击"生成代码"按钮,自动完成后会出具一份“代码生成报告”。目录下生成的“model.c”、"model.h"将做为训练好的模型,将替代要该模型的应用工程。
体验Ready AI Model
在IDE中,英飞凌官方已经部署了直接可使用的AI模型,Ready AI Model模型能够应用在声音识别。在Eclipse for ModusToolbox™中,新建一个Ready AI Model模型工程,
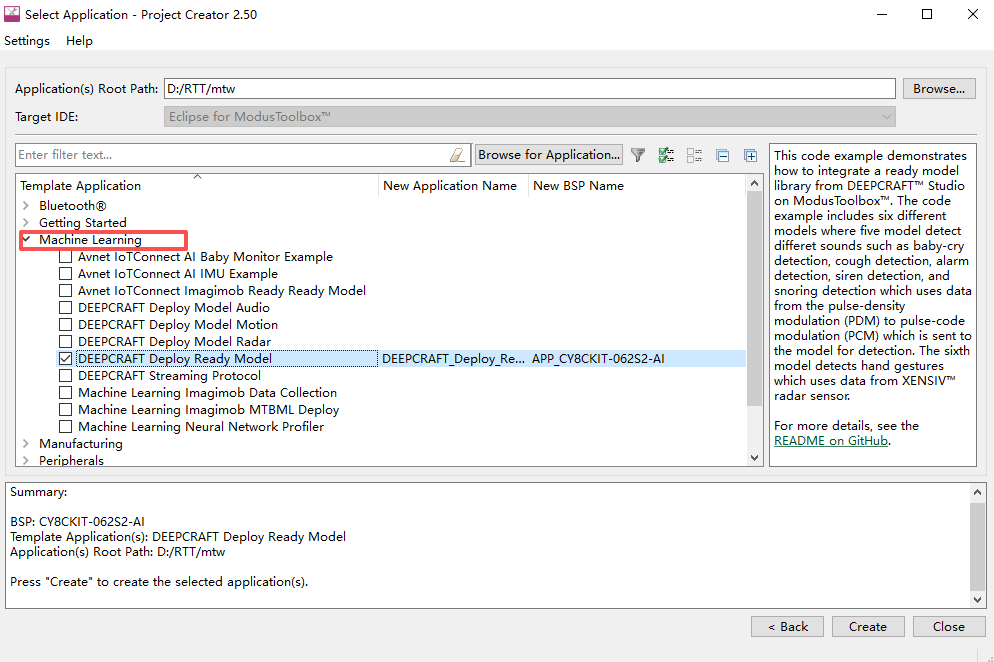
然后导出后的模型工程如下:

将Makefile中的编译选项更改成咳嗽模型,然后再编译,部署到开发板中,结果在网上搜索了一段咳嗽声,检测效果不明显。
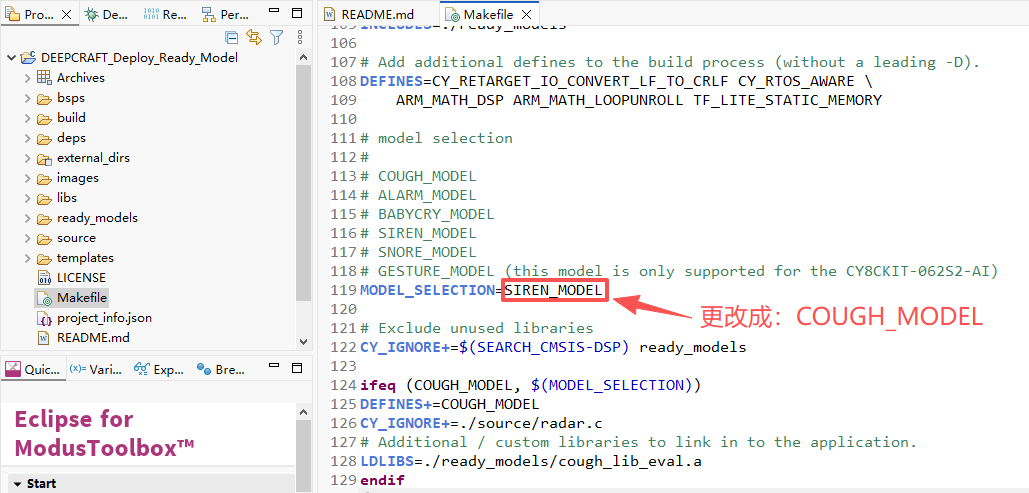
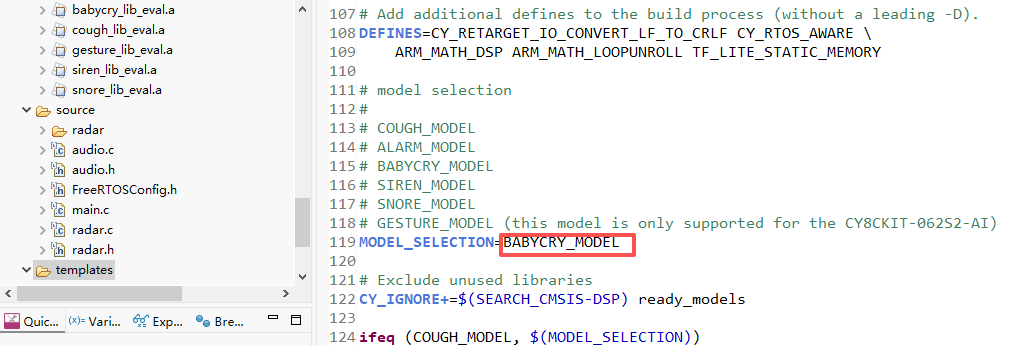
于是将上述宏定义更改成“BABYCRY_MODEL”婴儿啼哭模式,再次部署到开发板中,同样在网上搜索一段婴儿啼哭的声音,能检测出来,只是响应的速度没那么快。
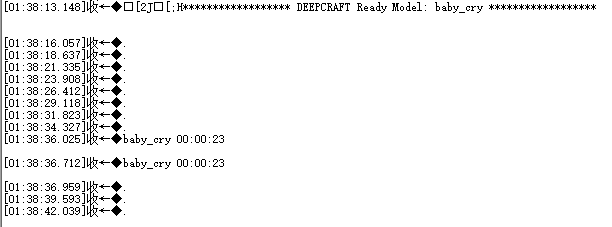
网上搜索到的婴儿啼哭声音频录制如下附件:

婴儿啼哭声.zip (360.11 KB, 下载次数: 0)
串口输出的信息如下:
小结
体验下来,整个流程是比较清晰,但是训练模式用时比较久,而且需要网络的稳定流畅才能使开发比较顺利。使用官方提供的Ready AI Model做音频识别测试,效果还不是很完善,第一点是反应速度上没那么及时;第二点是要求声音的分贝要达到一定的音量,距离稍远点就识别不了。好了,夜深了,先总结到这里,如有不同体验,欢迎回复交流。
---------------------
作者:yinwuqing110
链接:https://bbs.21ic.com/icview-3496578-1-1.html?_dsign=4087d781
来源:21ic.com
此文章已获得原创/原创奖标签,著作权归21ic所有,任何人未经允许禁止转载。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)