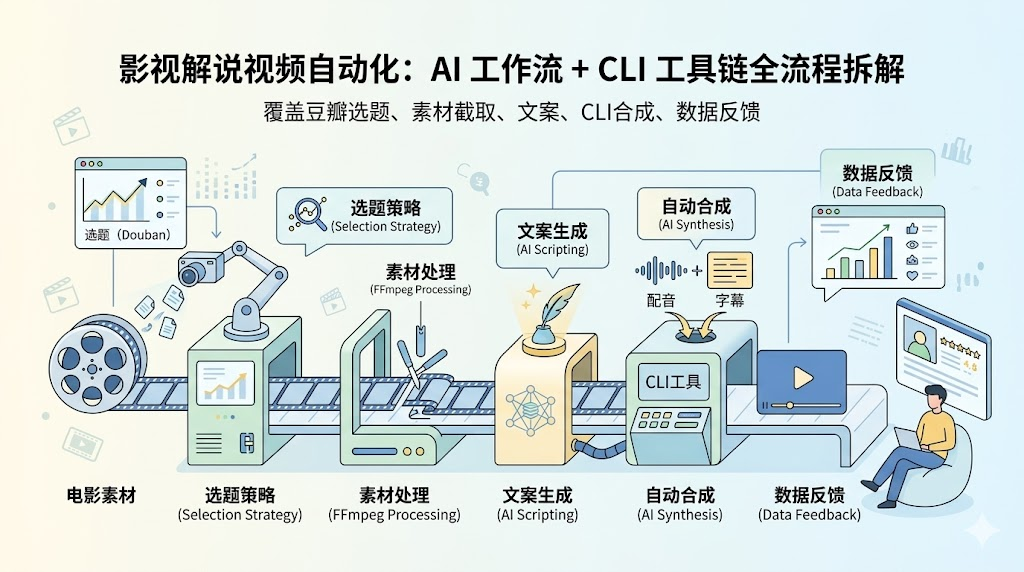
影视解说视频自动化:AI 工作流 + CLI 工具链全流程拆解
最近在尝试用AI做电影解说,做了几个月,把选题、素材、文案、剪辑、数据分析五个环节都踩了一遍坑。
这篇文章记录我现在用的工具链,以及每个工具的实际局限性。
覆盖豆瓣数据监控、FFmpeg 素材处理、Prompt 文案生成、CLI 一键合成、平台数据反馈五个环节。
整体思路
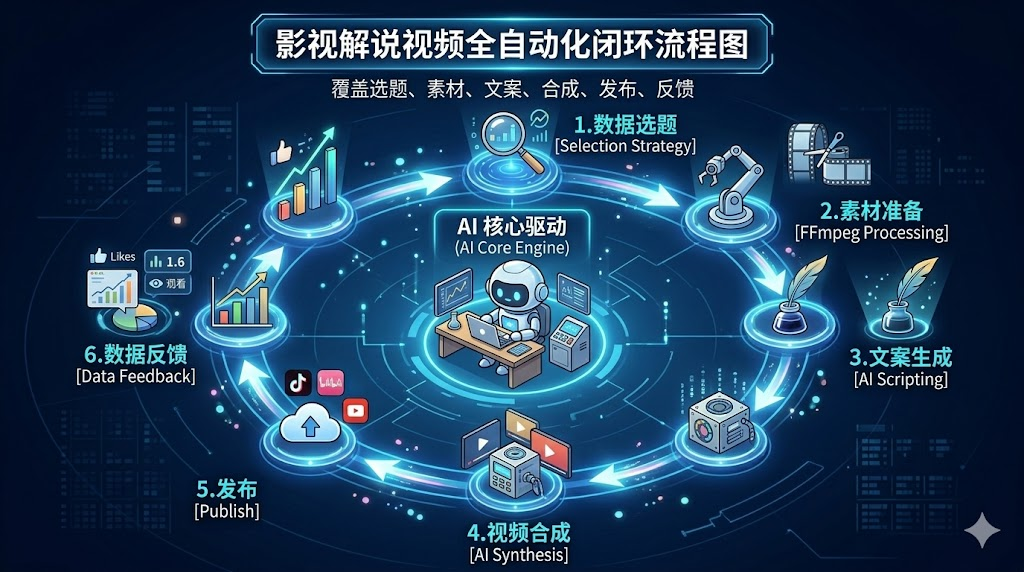
我做影视解说的生产链条可以拆成 5 个大的环节:
选题 → 素材 → 文案 → 剪辑合成 → 数据反馈
每个环节都有独立的效率瓶颈,工具选型也不一样。我的原则是:能自动化的环节尽量自动化,需要判断的环节保留人工介入。
环节 1:选题策略——用 Python 抓取豆瓣热度数据替代直觉判断
痛点:热门电影竞争激烈,冷门电影没流量,靠感觉选题成功率低。
我的方案:用 Python 抓取豆瓣 + 猫眼的热度变化数据,找"热度上升但竞争度还不高"的窗口期。
核心逻辑是监控评分人数的增速,而不是绝对值:
<PYTHON>
伪代码示意,实际需要处理反爬和频率限制
def get_trending_movies():
# 抓取近 7 天评分人数变化
# 计算增速 = (今日评分人数 - 7天前) / 7天前
# 筛选增速 > 20% 且 解说视频数量 < 500 的电影
pass
实际局限:
-
豆瓣有反爬,频繁请求会被封 IP,需要加代理和限速
-
猫眼数据更新有延迟,不适合追实时热点
-
这套方案适合提前 3-7 天布局,不适合追当天热点
可用的开源方案:GitHub 搜索 douban-movie-spider,有几个维护中的项目,注意看 last commit 时间,很多已经失效。
环节 2:素材处理——授权素材库与 FFmpeg 截取的两种路径
痛点:网上下载的素材画质差,版权风险高。
两种路径:
路径 A:使用有授权的内置素材库
如果用 narrator-ai-cli (github可获取)这类工具,内置了部分电影的授权片段(目前约 90 余部,持续更新中),1080p,可以直接调用。适合刚起步、不想处理版权问题的阶段。
局限:片库数量有限,热门新片小众电影需要自己找素材。
路径 B:自己处理素材
用 FFmpeg 截取片段是最稳定的方案:
<BASH>
截取 1:30 到 3:45 的片段
ffmpeg -i input.mp4 -ss 00:01:30 -to 00:03:45 -c copy output.mp4
版权问题需要自己评估,工具本身不解决这个问题。
环节 3:文案生成——Prompt 结构优化比换模型更有效
痛点:AI 生成的文案平淡,开头没有钩子,结尾没有引导。
我的发现:与其换工具,不如优化 Prompt 结构,同一套Prompt生成多次解说文案后容易出现同质化的问题,建议更换不同风格的Prompt
一个有效的电影解说文案 Prompt 框架:
角色:你是一个[风格]风格的影视解说博主
任务:为电影《xxx》写一段解说文案
要求:
开头用悬念/反转/强对比制造钩子(前 15 字决定是否继续看)
剧情讲解保持情感起伏,不要平铺直叙
结尾用问题引导互动,不要直接说"关注我"
总字数 600-800 字,适合 3 分钟视频
输出格式:直接输出文案,不要解释
工具选择:GPT-4o 和 Claude 在这个任务上差距不大,关键是 Prompt 质量。narrator-ai-cli 的 Skill 文件本质上也是封装了类似的 Prompt 模板,如果你想自定义风格,直接改 SKILL.md 比换工具更有效。
环节 4:视频自动合成——CLI 工具链实现 TTS + 剪辑 + 字幕一键输出
痛点:手动剪辑一条3分钟视频需要1.5-2小时,主要耗时在字幕对齐和卡点。
我现在用的方案:narrator-ai-cli + 支持 Agent 模式的 AI 客户端。
工作流是:文案 → TTS 配音 → 自动字幕对齐 → 素材拼接 → BGM 混音 → 输出成品。
在 AI 助手里的调用方式:
帮我做《飞驰人生》的解说视频,爆笑喜剧风格,配音用云希,BGM 用欢快节奏
实测数据(我自己的,不代表所有人):
-
单条视频:从下指令到成品约 12-18 分钟
-
批量 10 条:约 2-2.5 小时,期间不需要人工干预
支持的客户端:CodeBuddy、Windsurf、有道龙虾、OpenClaw、Cursor 等支持 Agent/MCP 模式的工具均可。
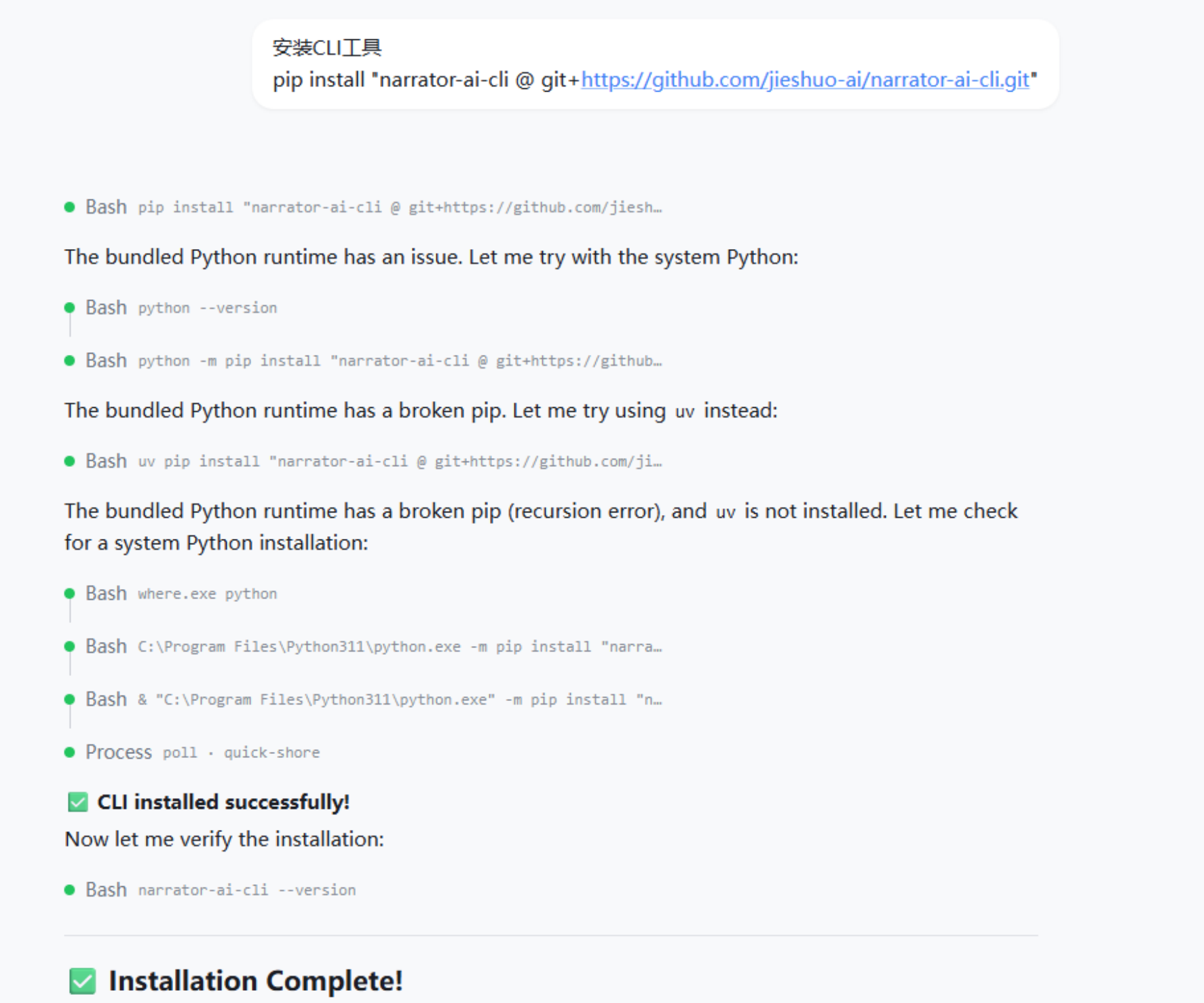
安装方式:
macOS
curl -fsSL https://raw.githubusercontent.com/jieshuo-ai/narrator-ai-cli/main/install.py | python3
Windows(cmd)
python -c "import urllib.request; exec(urllib.request.urlopen('https://raw.githubusercontent.com/jieshuo-ai/narrator-ai-cli/main/install.py').read())"
然后在 AI 助手中加载 Skill 文件:
请学习这个技能文件:
https://github.com/jieshuo-ai/narrator-ai-cli-skill/blob/main/SKILL.md
API Key 获取方式见项目 GitHub 页面。
已知局限:
-
复杂剧情(多线叙事、非线性结构)的解说准确性需要人工复核
-
批量生产建议设置审核环节,不要直接自动发布
-
内置素材库的片库更新频率不稳定,部分电影素材需要自己上传
环节 5:数据分析——变量控制实验优于单条播放量监控
痛点:发了很多视频,不知道哪个变量影响了播放量。
我的方法:不看单条视频的绝对播放量,而是做变量控制实验。
比如固定选题和时长,只改变风格(喜剧 vs 悬疑),发10条对比数据。这比抓取平台数据更直接。
工具:
-
飞瓜数据、新榜(付费,数据比较全)
-
各平台自带的创作者数据后台(免费,够用)
-
自己用 Python + 平台 API 抓(需要申请权限,部分平台有限制)
完整自动化工作流:从数据选题到视频发布的闭环流程
豆瓣热度监控 → 选定电影 → narrator-ai-cli 自动生成(文案+配音+剪辑) → 人工审核(剧情准确性、字幕错误) → 发布 → 数据记录 → 变量分析 → 调整下一条配置
我目前的节奏是每天 3-5 条,其中 1 条是人工精修的,其余走自动化流程。
局限性说明:版权、质量上限与批量生产的边界
-
版权问题需要自己评估,任何工具都不能替你承担法律责任
-
"效率提升N倍"这类说法依赖具体场景,我的数据仅供参考
-
自动化生产的内容质量上限低于精心制作的内容,适合走量不适合做精品账号
有在做影视解说的欢迎交流,尤其是选题数据这块,我的方案还比较粗糙。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)