知网AIGC查重的原理与降AI的实用技巧
很多同学看到查重报告里AIGC指数飙升时,第一反应是恐慌,觉得系统看出了文章不是自己写的。其实没必要把检测系统想得太智能,它根本读不懂文章的内容。
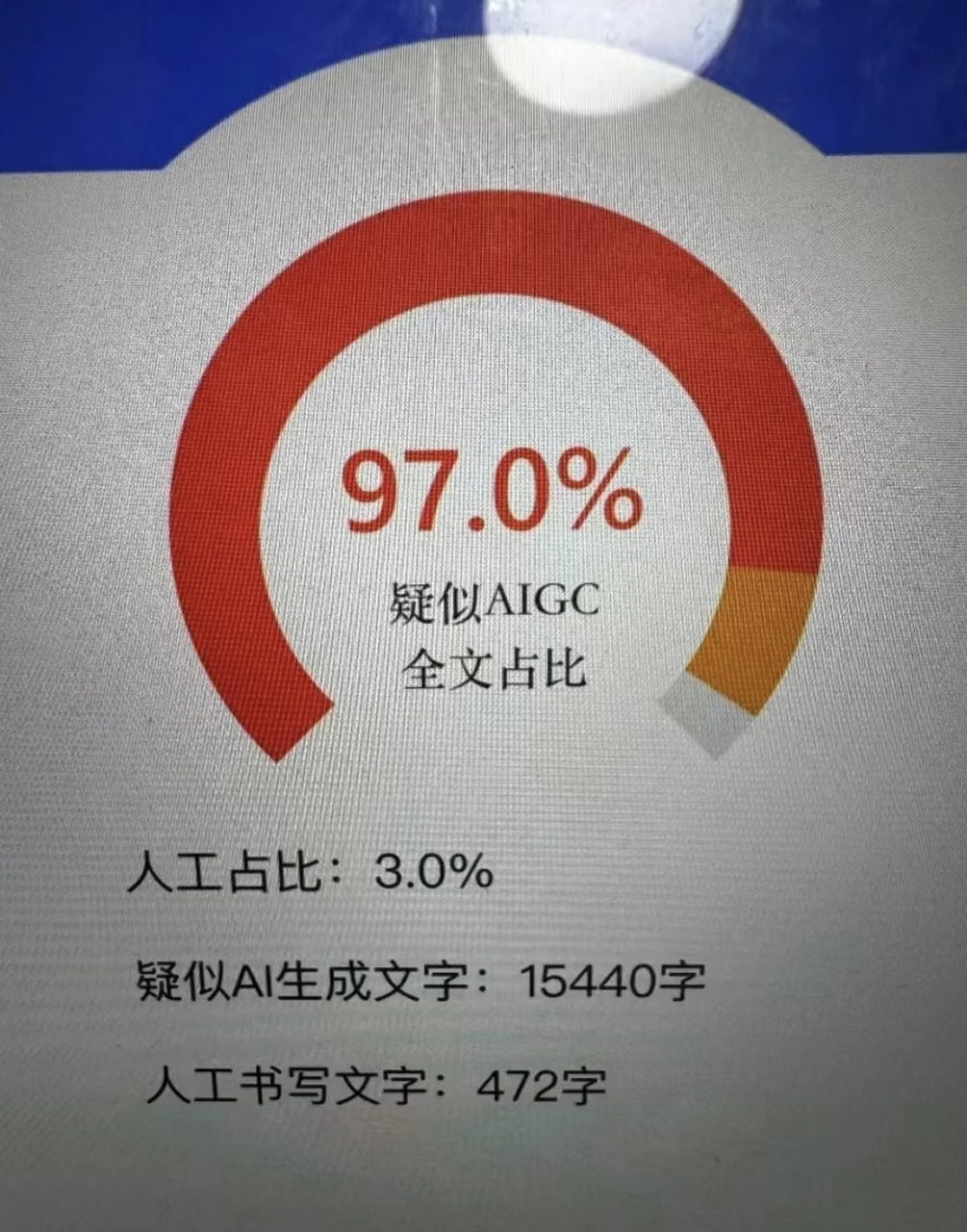
目前的检测逻辑主要基于两个核心统计学指标:困惑度和突发性。只要搞懂这两个概念,你就能明白为什么你的文章会被标红,以及如何修正。
第一部分:知己知彼,AI检测到底在查什么?
很多同学以为AI检测器是真能读懂你的文章,其实不是。它就是个数学统计模型,它在找你的统计学漏洞。
1、文本过于顺滑(低困惑度)
AI模型的生成逻辑是为了求稳,它在生成句子时,永远倾向于选择概率最高的词汇组合。
比如说到随着科技的……,AI大概率会接发展或进步。如果你整篇文章的词汇搭配都处于这种高概率区间,系统就能轻易预测你下一个词要说什么,这种极高的可预测性,就是判定AI生成的铁证,人类写作时思维更跳跃,会使用冷门词汇或非线性逻辑,这会让系统感到困惑,从而降低AI疑似度。

2、句式结构太单一(低突发性)
AI生成的文本,无论内容多么不同,其句子的长短分布、节奏感通常非常均匀,呈现出一种机械的稳定性,而人类写作受情绪和思维影响,句式长短是不稳定的,可能这一段是长篇大论的严谨推导,下一句突然变成简短的结论。这种句式长度和结构的剧烈波动,被称为突发性,是区分真人与AI的重要指标。
第二部分:实操干货,3招教你暴力降AI
懂了原理,接下来我们要做的核心事情就是:破坏AI的统计规律,注入人类的不完美痕迹。
1、破坏原本的逻辑结构
AI生成的内容通常遵循标准的总-分-总或首先-其次-最后的结构。在修改时,不要保留这种死板框架。你可以尝试倒叙,先把结论抛出来,或者从一个具体的、反常规的案例切入,打乱系统对文章结构的预期。
2、清洗高频特征词
很多词汇是AI的常用词。例如综上所述、至关重要、在……领域起到了关键作用。这些词在AI语料库中出现频率极高。把这些词全部替换掉,不要用重要作用,改用更具体的行业术语;不要用必然选择,换成具有个人色彩的表达。
3、增加主观视角与具象细节
AI很难生成带有强烈主观色彩或具体生活细节的内容。在文中加入个人的批判性思考,甚至是一些纠结的矛盾心理,能有效增加文本的人类特征,同时,避免使用搜索引擎能直接找到的大众案例,改用你实地调研的、局部的、具体的微观数据。
第三部分:借助工具打破算法特征
理解原理后,你会发现手动降AI本质上是在做句式重组和同义词替换的工作,这确实有效,但对精力的消耗极大,尤其是面对几万字的论文时,逐句修改句式长短、替换高频词非常耗时。
在这个环节,完全可以利用工具来对抗算法。
目前市面上像笔灵AI这类工具,其底层的降AI逻辑其实就是针对上述两个指标设计的,当你把一段AI味很重的文字放进去,它会自动打散原本平铺直叙的句式,插入更自然的连接词,并替换掉那些容易触发警报的高频模板词。
也就是说,它是在模拟人类写作的不规则性和高突发性,对于赶时间的同学来说,先用笔灵AI把全文的统计学特征打乱,把80%的AI味洗掉,剩下的20%再配合自己对专业内容的微调,是目前效率最高的路径。

就连论文格式它都是100%完美保留的~

传送门我就放在最后了,感兴趣的大家可以直接复制链接去电脑端浏览器查看⬇️

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)