开源项目解读:RAG-Anything 研报级深度拆解
引言
【内部深度思考 / Thinking Process】
=== 输入输出梳理 ===
输入:
- 任意多模态文档 (PDF / Office / 图像 / 纯文本)
- 可选: 预解析的 content_list (来自外部解析器)
- 可选: 查询时附带的多模态内容 (图表、公式)
输出:
- 知识图谱 + 向量索引 (双重表示)
- 结构化回答 (通过 local/global/hybrid/naive/mix 模式)
- VLM 增强回答 (图文一体分析)
=== 核心难点 ===
难点1: 如何将图像/表格/公式这类"哑"内容塞进纯文本知识图谱?
Trick: 用 VLM 把它们"翻译"成高质量文本描述 + 结构化 entity_info JSON
→ 变成图谱节点,和文本内容统一处理
难点2: 跨模态关系如何建立?
Trick: 在描述生成后提取sub-entities,用"belongs_to"边把它们挂到父模态节点上
(e.g. "ResNet" → "belongs_to" → "Figure 3 (image)")
难点3: 查询时如何还原图片进行视觉推理?
Trick: 先用 only_need_prompt=True 拿到 RAG context prompt
→ 用 regex 从 context 中提取图片路径 → base64 编码
→ 组装 OpenAI 多模态 messages → 送 VLM 分析
这个"先检索后看图"的两段式设计极其巧妙
难点4: LLM 返回的 JSON 格式不稳定怎么办?
Trick: 4层 fallback 策略 + <think> 标签剥离 + regex 字段提取兜底
难点5: 解析公式时 LaTeX 反斜杠会破坏 JSON 转义
Trick: progressive_quote_fix 专门处理 LaTeX 中的 \alpha 等模式
=== 合理推测 ===
- LightRAG 底层使用 nano-vectordb 或类似轻量向量库 + 自研图存储
- "global" 模式基于社区摘要/图全局遍历, "local" 基于近邻实体, "hybrid" 结合两者
- 论文中提到的 dual-graph 是指: 文本语义图 (LightRAG原有) + 跨模态关系图 (belongs_to edges)
- MinerU 内部使用了 PaddleOCR + LayoutLM 等进行文档解析
项目全局视角
来源: arXiv:2510.12323 | HKUDS 香港大学数据科学实验室 | 2025.10
业务痛点:现实世界的文档根本不是纯文本
传统 RAG 系统有一个根本性的"错觉":它们假设知识库是纯文本的。但一份典型的技术报告、学术论文或企业财报,往往由以下元素混合构成:
| 内容类型 | 占比 | 传统 RAG 的处理方式 | 导致的问题 |
|---|---|---|---|
| 正文文本 | ~50% | 正常分块 + 嵌入 | 无问题 |
| 图表/示意图 | ~25% | 直接丢弃 | 核心信息丢失 |
| 数据表格 | ~15% | 可能变乱码 | 数值关系断裂 |
| 数学公式 | ~10% | OCR 乱码 | 推理链断裂 |
这才是 RAG-Anything 的"胜负手"所在:它不仅要处理文本,还要让图表、表格、公式成为一等公民——可被检索、可被推理、可建立跨模态语义关联。
核心指标与竞争优势
根据论文,RAG-Anything 在长文档多模态基准测试上取得 SOTA,尤其在:
- 含图表的科学问答 (图表理解类问题)
- 含数据表格的分析型问答 (数值推理)
- 长文档 (50页+) 检索 (传统方法在此失效)
"胜负手"总结(三个核心创新):
- 模态感知实体化 (Modal-Aware Entityification):将每个图/表/公式都转化为知识图谱中的一个具名实体节点
- 双图索引 (Dual-Graph Indexing):文本语义图 + 跨模态
belongs_to关系图并存 - VLM 二阶段查询 (Two-Stage VLM Query):先 RAG 检索定位,后 VLM 直视图片分析
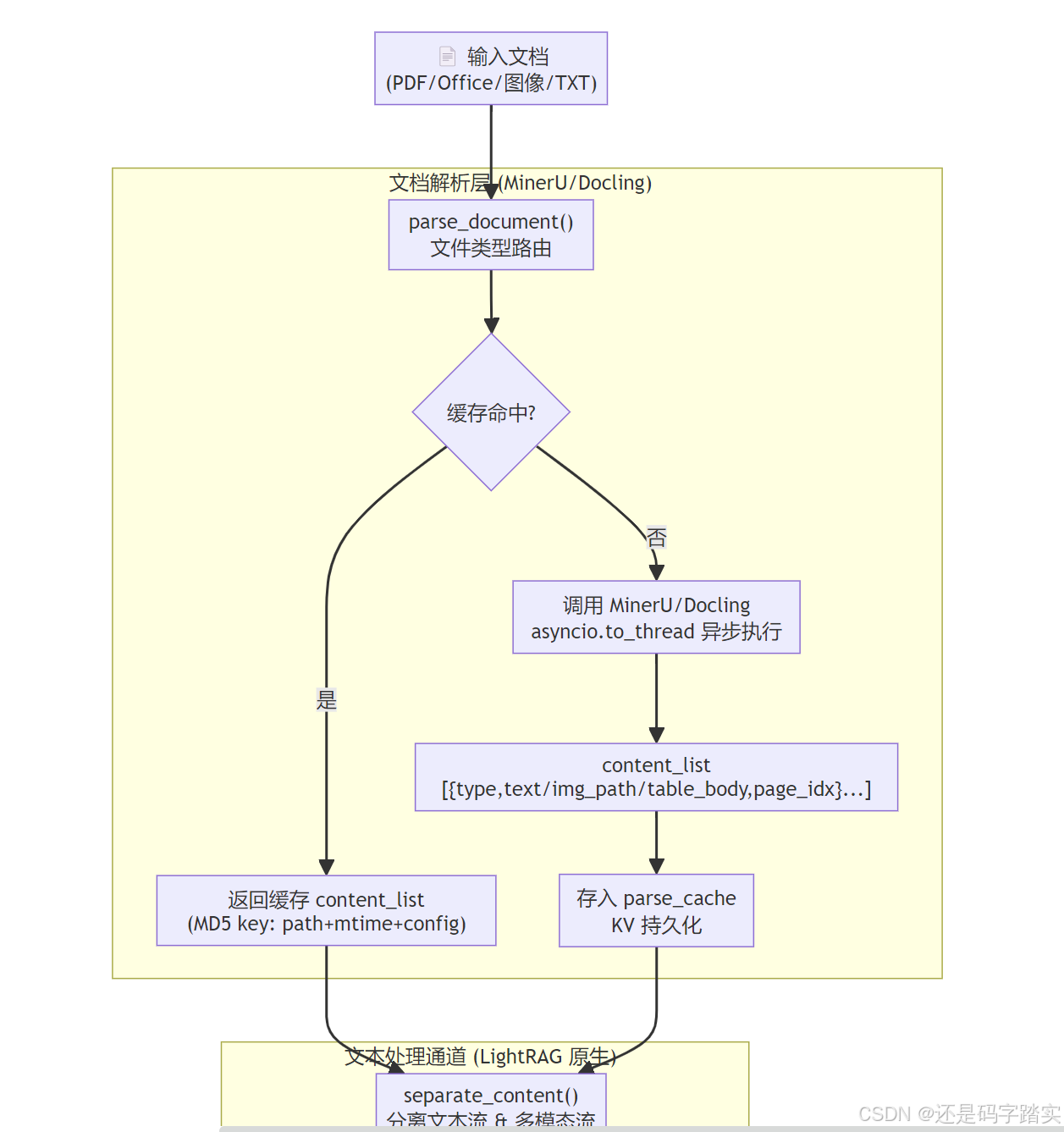
多模态数据摄入与解析 (Data Ingestion & Parsing)
解析引擎:MinerU vs Docling 双引擎策略
What: 系统支持 MinerU (主力) 和 Docling (备选) 两种文档解析器,通过 get_parser(config.parser) 工厂函数动态选择。
Why:
- MinerU (来自上海 OpenDataLab):对 PDF 和图像格式支持最佳,内置 OCR、版式分析、公式识别、表格提取,支持 GPU 加速,支持 VLM backend (可接 Qwen-VL 等本地多模态模型)。
- Docling (来自 IBM):对 Office 文档 (Word/PPT/Excel) 和 HTML 结构保持更好,两者互补。
How (从 processor.py 读到的实现细节):
# processor.py - parse_document() 核心路由逻辑
if ext in [".pdf"]:
# 异步线程调用,避免阻塞 event loop
content_list = await asyncio.to_thread(
doc_parser.parse_pdf,
pdf_path=file_path,
output_dir=output_dir,
method=parse_method, # "auto" | "ocr" | "txt"
**kwargs # 支持 lang="ch", device="cuda:0", formula=True...
)
elif ext in [".jpg", ".jpeg", ".png", ...]:
# 图像文件 → 直接走 MinerU 的图像解析通道
content_list = await asyncio.to_thread(
doc_parser.parse_image, ...
)
elif ext in [".docx", ".pptx", ".xlsx", ...]:
# Office 文档 → LibreOffice 先转 PDF,再走 MinerU
content_list = await asyncio.to_thread(
doc_parser.parse_office_doc, ...
)
关键参数深挖:
method="auto": MinerU 自动判断用版式分析还是 OCRbackend="pipeline": 经典 pipeline;backend="vlm-http-client"时可连接本地 VLM 服务(如 InternVL2)做基于视觉的解析,精度更高device="cuda:0": 启用 GPU 加速解析,对 100 页+ 文档速度提升明显
MinerU 解析输出格式 (标准化 content_list):
# MinerU 输出的 content_list 每个元素是如下字典
[
{"type": "text", "text": "...", "page_idx": 0, "text_level": 1}, # text_level>0表示标题
{"type": "image", "img_path": "/abs/path", "page_idx": 1,
"image_caption": ["图1:..."], "image_footnote": ["来源:..."]},
{"type": "table", "table_body": "| 方法 |...", "page_idx": 2,
"table_caption": ["表1:..."], "img_path": "table_img.png"},
{"type": "equation", "text": "E=mc^2", "page_idx": 3,
"text_format": "latex"},
]
这个 page_idx 字段至关重要——它是后续上下文感知处理的锚点。
智能解析缓存(Engineering Trick #1)
What: 用 LightRAG 的** KV 存储持久化解析结果,避免重复解析。**
Why: 对于 100MB 的 PDF,MinerU 解析一次可能需要 2-5 分钟(尤其涉及 OCR)。在迭代开发中这会极大拖慢效率。
How (from processor.py):
def _generate_cache_key(self, file_path: Path, parse_method: str, **kwargs) -> str:
config_dict = {
"file_path": str(file_path.absolute()),
"mtime": file_path.stat().st_mtime, # 文件修改时间,保证内容一致性
"parser": self.config.parser,
"parse_method": parse_method,
# 包含影响解析结果的关键参数
}
config_str = json.dumps(config_dict, sort_keys=True)
return hashlib.md5(config_str.encode()).hexdigest()
缓存 Key = **MD5(文件绝对路径 + 文件修改时间 + 解析器类型 + 解析方法 + 语言/设备/页码范围等)**
这意味着:文件内容不变则直接读缓存;文件更新了(mtime 变化)则自动重新解析。
内容分离与切块策略
解析完成后,separate_content(content_list) 把内容分成两流:
- 文本流:所有
type=="text"的内容拼接成纯文本 → 送 LightRAG 的标准文本 pipeline - 多模态流:所有
type in ["image", "table", "equation"]的项目 → 送模态专用处理器
文本切块策略(继承自 LightRAG):
- 基于 Token 的滑动窗口切块(默认
chunk_token_size=1200,chunk_overlap_token_size=100) - 可选:
split_by_character按特定字符(如\n\n)切块 - 使用
tiktoken精确计算 token 数
检索与召回引擎 (Retrieval & Reranking)
LightRAG 双路召回基础架构
RAG-Anything 的检索能力完全建立在 LightRAG 的**“图-向量双索引”**之上,理解这一点是理解整个系统的关键。
LightRAG 的四种检索模式(直接从 query.py 的 aquery 接口可见):
| 模式 | 机制 | 适合场景 |
|---|---|---|
naive |
纯向量相似度搜索 (chunks_vdb) | 简单事实性问答 |
local |
先找相关实体,再扩展至邻居实体和关联 chunk | 具体概念的深度挖掘 |
global |
图全局摘要/社区摘要遍历 | 宏观主题/综合分析 |
hybrid |
local + global 结合 | 通用问答(推荐) |
mix |
naive + hybrid 组合 | 最全面,但成本最高 |
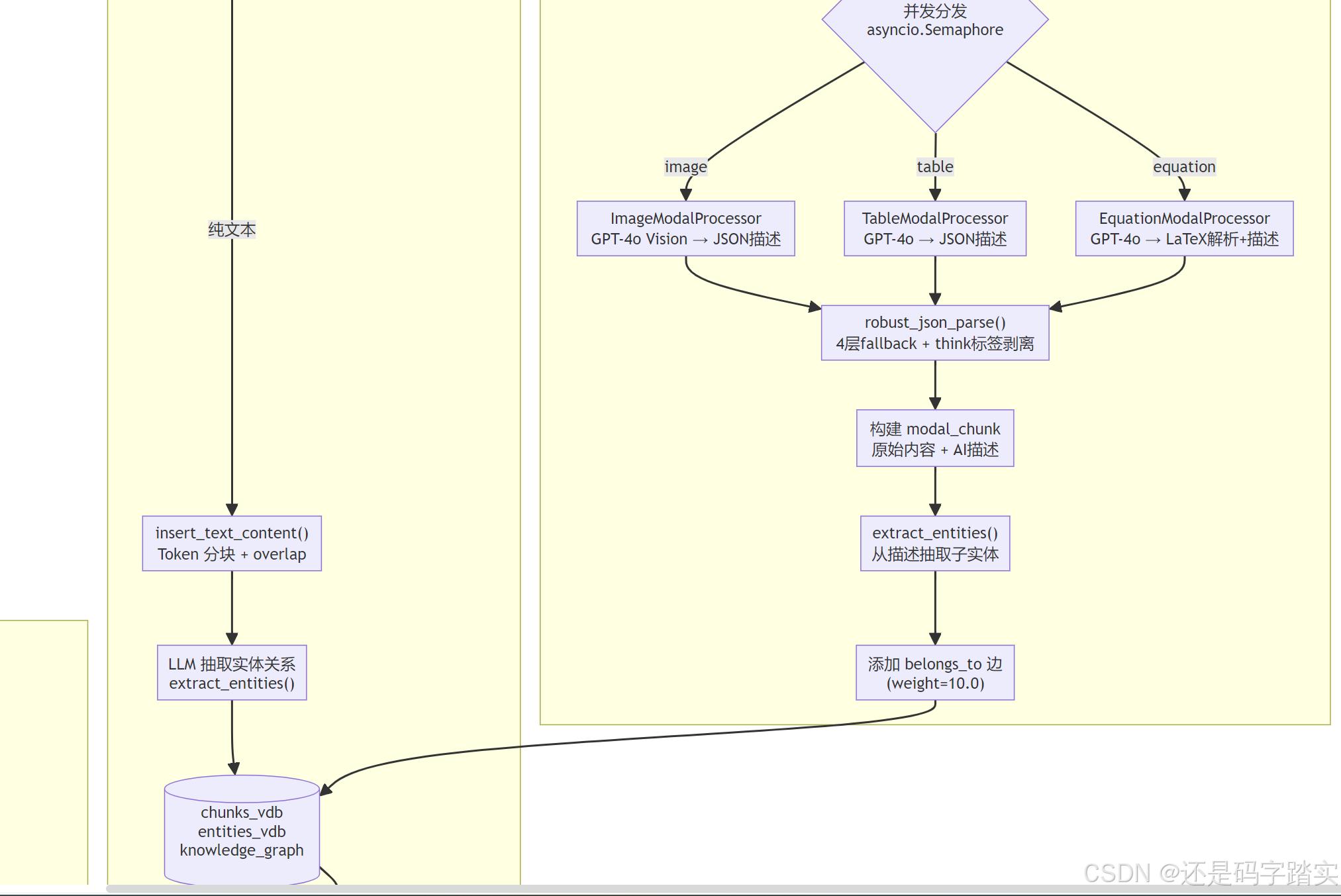
三重向量索引设计
RAG-Anything 维护了三个独立的向量数据库(从 BaseModalProcessor.__init__ 中读到):
# modalprocessors.py - BaseModalProcessor.__init__
self.text_chunks_db = lightrag.text_chunks # KV: chunk_id → 原始文本+元数据
self.chunks_vdb = lightrag.chunks_vdb # 向量库1: chunk 内容的向量索引
self.entities_vdb = lightrag.entities_vdb # 向量库2: 实体名称+描述的向量索引
self.re
lationships_vdb = lightrag.relationships_vdb # 向量库3: 关系描述的向量索引
self.knowledge_graph_inst = lightrag.chunk_entity_relation_graph # 知识图谱
检索时,系统根据 query mode 联合查询多个索引:
- Local 模式:query →
entities_vdb找 top-k 实体 → 图遍历获取邻居实体 →text_chunks_db获取源文本 - Global 模式:query → 图社区摘要生成 → 汇总
- Naive 模式:query →
chunks_vdb直接 top-k 相似 chunk
多模态内容的检索:图/表/公式的 VLM 生成描述被作为 chunk 内容存入 chunks_vdb;实体名称(如 "ResNet Architecture Diagram (image)")存入 entities_vdb。查询时,无需特殊处理,它们自然参与向量检索。
跨模态关系图(Dual-Graph 核心)
这是 RAG-Anything 相比普通多模态 RAG 的最核心创新:
How(从 processor.py 的 _batch_add_belongs_to_relations_type_aware() 中精确读到):
# processor.py - 为每个从模态描述中提取的子实体建立 belongs_to 边
for entity_name in maybe_nodes.keys():
if entity_name != modal_entity_name: # 排除自环
belongs_to_relation = {
"src_id": entity_name, # 例如:"ResNet"
"tgt_id": modal_entity_name, # 例如:"Performance Comparison Table (table)"
"description": f"Entity {entity_name} belongs to {modal_entity_name}",
"keywords": "belongs_to,part_of,contained_in",
"weight": 10.0, # 权重高于普通关系,确保图遍历优先经过此边
"source_id": chunk_id,
}
await self.knowledge_graph_inst.upsert_edge(
entity_name, modal_entity_name, relation_data
)
为什么 weight=10.0 很重要:在 LightRAG 的图遍历中,边权重影响社区发现和邻居扩展。高权重的 belongs_to 边确保了当用户查询 “ResNet” 时,系统能通过图路径找到包含 ResNet 的那张性能对比表,从而检索到完整的表格数据。
完整的跨模态关系链举例(表格描述构建KG):
用户文档中有一张"BERT vs GPT 性能对比表"
→ TableModalProcessor 生成描述: "这是一张对比 BERT 和 GPT 在各 NLP 任务上 Accuracy、F1 分数的表格,数据来自 2023 年论文..."
→ extract_entities() 从描述中抽取: BERT, GPT, Accuracy, F1分数, NLP
→ 建立 belongs_to 边: BERT → "BERT vs GPT Performance Table (table)"
GPT → "BERT vs GPT Performance Table (table)"
→ 用户查询 "BERT 的 F1 分数是多少"
→ local 模式: BERT 实体 → 图遍历 → 发现 belongs_to 边 → 找到表格实体 → 检索表格 chunk
→ 精准返回表格中的 F1 数值 ✓
关于 ColPali / Late-Interaction 的说明
需要客观指出:RAG-Anything 当前实现中并未使用 ColPali 或 ColBERT 类型的 Late-Interaction 视觉检索机制。它的视觉检索路径是:
- 索引时:VLM 生成的文本描述 → 文本嵌入 → 存入 chunks_vdb(文本向量)
- 检索时:查询文本嵌入 → 余弦相似度 → 找相似 chunk
这是一种描述代理视觉检索(Description-Proxy Visual Retrieval)策略,不是端到端的图像向量检索。这样做的好处是实现简单、不需要专用视觉嵌入模型、可以利用成熟的文本嵌入;代价是**依赖 VLM 描述的质量****,描述不全面时召回会有损失。**
Reranker
当前版本没有显式的重排序(Reranking)模块,但 LightRAG 框架预留了 rerank_model_func 接口,可通过 lightrag_kwargs 传入自定义重排器。
Agent 编排与防幻觉 (Agent Workflow & Anti-Hallucination)
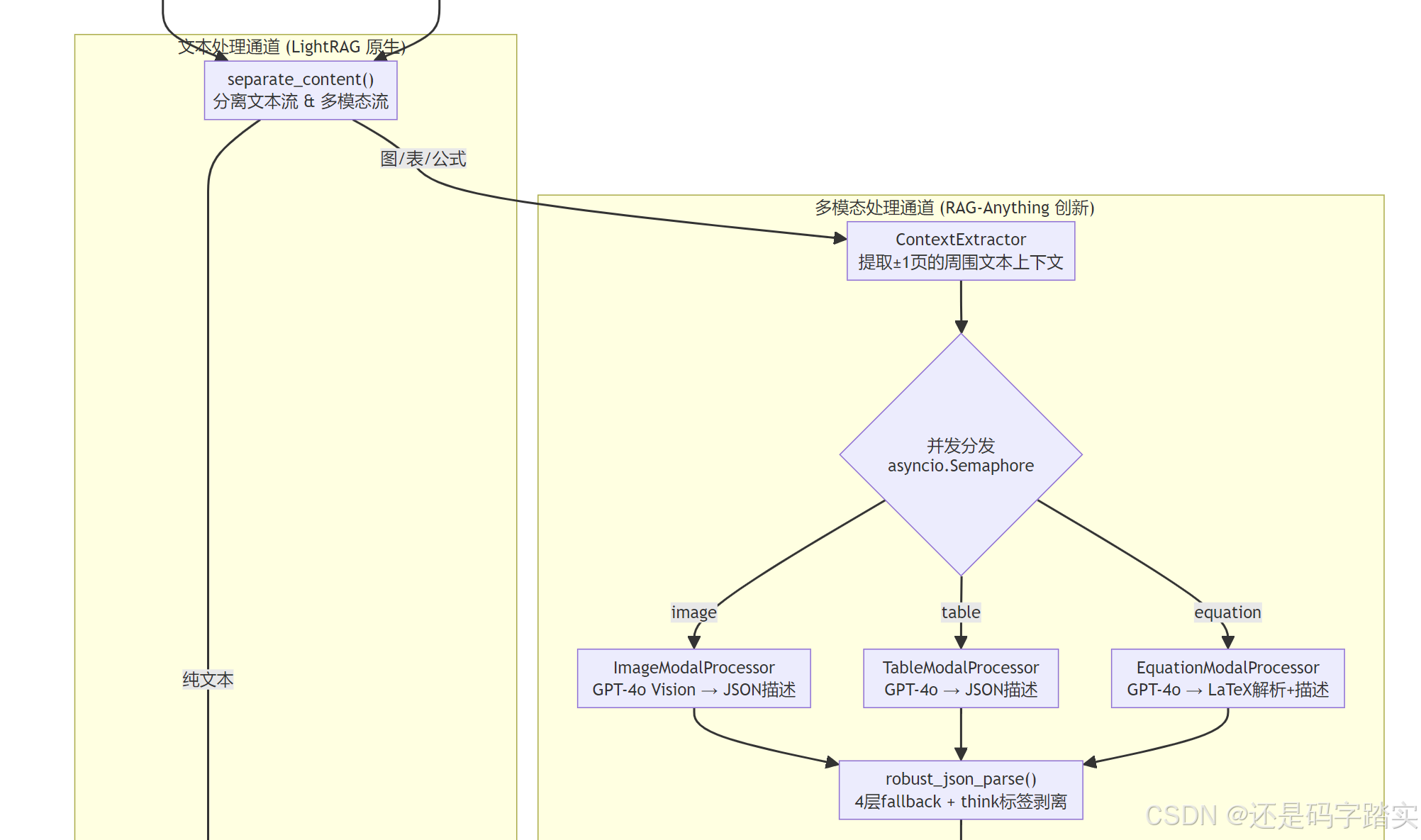
三阶段多模态处理流水线(批量并发架构)
从 _process_multimodal_content_batch_type_aware() 中读到,批处理被分为严格的 7 个阶段:
Stage 1: 并发描述生成 (asyncio.gather + Semaphore 限流)
↓
Stage 2: 转化为 LightRAG 标准 chunk 格式
↓
Stage 3: 存储 chunks 到 text_chunks + chunks_vdb
↓
Stage 3.5: 存储模态主实体到 entities_vdb + knowledge_graph + full_entities
↓
Stage 4: 批量实体关系抽取 (extract_entities)
↓
Stage 5: 添加 belongs_to 关系 (跨模态连接)
↓
Stage 6: 批量 merge_nodes_and_edges
↓
Stage 7: 更新 doc_status
为什么要这么分:Stage 1 是 IO 密集型(调用 VLM API),用 asyncio.Semaphore 控制并发数(默认 2),避免打爆 API rate limit。Stage 4-6 是计算密集型(LLM 提取实体),批量处理减少 LLM 调用次数。
# processor.py - 并发控制机制
semaphore = asyncio.Semaphore(getattr(self.lightrag, "max_parallel_insert", 2))
async def process_single_item_with_correct_processor(item, index, file_path):
async with semaphore: # 最多同时 2 个 VLM 调用
# 调用对应类型的 processor.generate_description_only()
description, entity_info = await processor.generate_description_only(...)
return {...}
tasks = [asyncio.create_task(process_single_item_with_correct_processor(item, i, fp))
for i, item in enumerate(multimodal_items)]
results = await asyncio.gather(*tasks, return_exceptions=True)
上下文感知的模态描述生成(防幻觉 Trick #1)
What: 在让 VLM 描述图表之前,先用 **ContextExtractor**** **提取周围页的文本作为背景上下文。
Why: 图表本身可能缺乏足够信息。例如,一张折线图的 y 轴没有单位,但图表旁边的文字说明了"y 轴为准确率(%)"。如果 VLM 只看图,可能会幻觉生成错误单位。有了上下文,VLM 能做出更准确的描述。
How (from modalprocessors.py - ContextExtractor._extract_page_context()):
def _extract_page_context(self, content_list, current_item_info) -> str:
current_page = current_item_info.get("page_idx", 0)
window_size = self.config.context_window # 默认 1 (前后各1页)
start_page = max(0, current_page - window_size)
end_page = current_page + window_size + 1
context_texts = []
for item in content_list:
item_page = item.get("page_idx", 0)
item_type = item.get("type", "")
# 只纳入 filter_content_types=["text"] 的内容(排除其他图表避免干扰)
if start_page <= item_page < end_page and item_type in self.config.filter_content_types:
text_content = self._extract_text_from_item(item)
if item_page != current_page:
context_texts.append(f"[Page {item_page}] {text_content}")
context = "\n".join(context_texts)
return self._truncate_context(context) # token 精准截断
def _truncate_context(self, context: str) -> str:
# 使用 LightRAG 的 tokenizer 精确截断
if self.tokenizer:
tokens = self.tokenizer.encode(context)
if len(tokens) <= self.config.max_context_tokens: # 默认2000 tokens
return context
truncated_tokens = tokens[:self.config.max_context_tokens]
truncated_text = self.tokenizer.decode(truncated_tokens)
# 尝试在句子边界截断(而非粗暴截断单词中间)
last_period = truncated_text.rfind(".")
if last_period > len(truncated_text) * 0.8:
return truncated_text[:last_period + 1]
然后将 context 注入 prompt template:
# 如果有上下文,使用增强版 prompt
if context:
vision_prompt = PROMPTS["vision_prompt_with_context"].format(
context=context, # ← 关键:注入周围页的文本信息
entity_name=...,
image_path=...,
captions=captions,
footnotes=footnotes,
)
四层 JSON 解析防幻觉机制(Anti-Hallucination Trick #2)
模态处理器要求 LLM 输出标准 JSON 格式(包含 detailed_description 和 entity_info),但 LLM 的输出往往不稳定。系统实现了非常健壮的 4 层 fallback 策略:
Strategy 1 - 直接解析:json.loads(response)
Strategy 2 - 基础清洗:
def _basic_json_cleanup(self, json_str: str) -> str:
json_str = json_str.replace('"', '"').replace('"', '"') # 修复中文引号
json_str = re.sub(r',(\s*[}\]])', r'\1', json_str) # 删除尾随逗号
return json_str
Strategy 3 - LaTeX 转义修复(公式处理特有问题):
def _progressive_quote_fix(self, json_str: str) -> str:
# LaTeX 公式中 \alpha, \beta 等会干扰 JSON 转义
def fix_string_content(match):
content = match.group(1)
content = re.sub(r'\\(?=[a-zA-Z])', r'\\\\', content) # \alpha → \\alpha
return f'"{content}"'
json_str = re.sub(r'"([^"]*(?:\\.[^"]*)*)"', fix_string_content, json_str)
return json_str
Strategy 4 - 正则字段提取(最终兜底):
def _extract_fields_with_regex(self, response: str) -> dict:
desc_match = re.search(r'"detailed_description":\s*"([^"]*(?:\\.[^"]*)*)"', response)
name_match = re.search(r'"entity_name":\s*"([^"]*(?:\\.[^"]*)*)"', response)
# ... 即使 JSON 完全无法解析,也能提取出关键字段
Special Case - 思维链标签剥离(兼容 DeepSeek-R1/Qwen2.5-think):
@staticmethod
def _strip_thinking_tags(text: str) -> str:
cleaned = re.sub(r'<think>.*?</think>', '', text, flags=re.DOTALL|re.IGNORECASE)
cleaned = re.sub(r'<thinking>.*?</thinking>', '', cleaned, flags=re.DOTALL|re.IGNORECASE)
return cleaned.strip()
这个细节极为重要!DeepSeek-R1 系列模型会在最终答案前输出大段
<think>...</think>推理过程。如果不剥离,这些推理过程会污染实体描述,进而污染知识图谱。
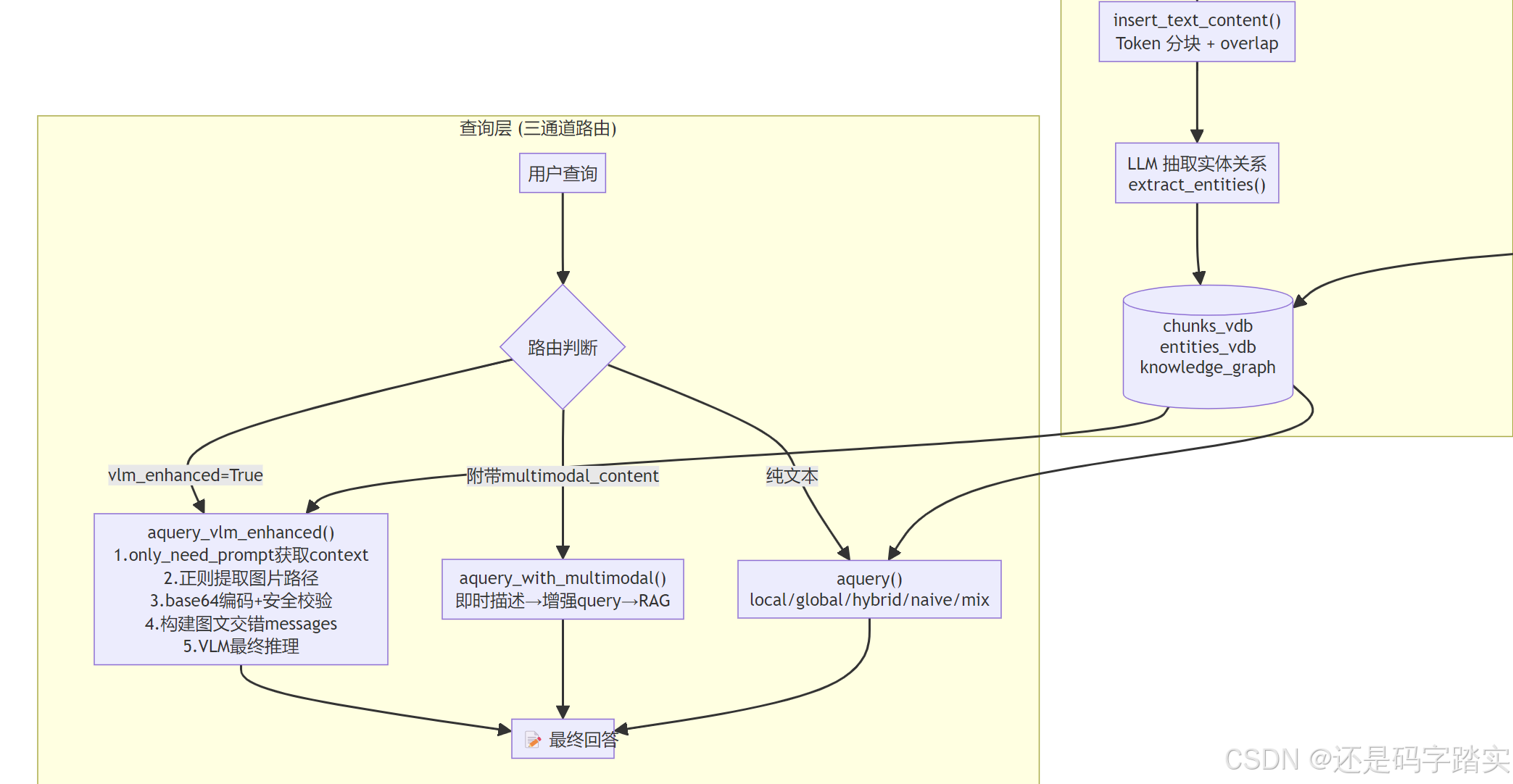
VLM 增强查询的两段式架构(最聪明的工程设计)
What: 查询时自动将 RAG 检索到的图片路径替换为实际图片,让 VLM 真正"看到"图片再回答。
How (from query.py - aquery_vlm_enhanced()):
async def aquery_vlm_enhanced(self, query: str, mode: str = "mix", ...) -> str:
# Step 1: 用 only_need_prompt=True 模式,只获取检索到的上下文 prompt,不生成答案
query_param = QueryParam(mode=mode, only_need_prompt=True)
raw_prompt = await self.lightrag.aquery(query, param=query_param)
# raw_prompt 中包含类似 "Image Path: /abs/path/to/figure1.jpg" 的内容
# Step 2: 正则提取图片路径 + base64 编码 + 安全校验
enhanced_prompt, images_found = await self._process_image_paths_for_vlm(raw_prompt)
# 安全校验:只允许 working_dir 或 parser_output_dir 内的图片(防止路径注入攻击)
# Step 3: 构建 OpenAI 多模态 messages 格式,文本和图片交错排列
messages = self._build_vlm_messages_with_images(enhanced_prompt, query)
# Step 4: 调用 VLM (GPT-4o) 进行多模态推理
result = await self._call_vlm_with_multimodal_content(messages)
return result
_build_vlm_messages_with_images() 中有一个精妙的插入机制:
# 以 [VLM_IMAGE_N] 为分隔符,将文本片段和图片交错组装
text_parts = enhanced_prompt.split("[VLM_IMAGE_")
content_parts = []
for i, text_part in enumerate(text_parts):
if i == 0:
content_parts.append({"type": "text", "text": text_part})
else:
marker_match = re.match(r"(\d+)\](.*)", text_part, re.DOTALL)
image_num = int(marker_match.group(1)) - 1
# 在原始文本位置插入对应图片
content_parts.append({"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{images_base64[image_num]}"}})
remaining_text = marker_match.group(2)
content_parts.append({"type": "text", "text": remaining_text})
这意味着 VLM 收到的 messages 是图文位置对应的,就像人类阅读文档一样——先看到关于图片的文字说明,紧接着看到实际图片。
意图路由机制(查询时的三通道路由)
用户查询
├── 有 vision_model_func 且 vlm_enhanced=True
│ → aquery_vlm_enhanced() (VLM 视觉增强查询)
├── 有 multimodal_content 参数
│ → aquery_with_multimodal() (查询时附带多模态内容)
└── 纯文本查询
→ aquery() → lightrag.aquery() (标准 RAG 查询)
**aquery_with_multimodal()**** 的"多模态增强查询"还有一个特别的设计:**
- 用户提交查询时附带一张新图/新表格
- 系统先用对应处理器**(ImageProcessor/TableProcessor)**生成该内容的文字描述
- 将描述拼接到原始查询,形成增强查询文本
- 再执行标准 RAG 检索
- 这实现了**“查询时的新模态内容与知识库的交叉分析”**,不需要重新索引
大白话费曼延伸 (Feynman Explanation)
类比一:图/表的"翻译官"—— 想象让一个盲人读懂一份医学报告
普通 RAG 就像给一个只会读文字的助手(盲人)看一份满是 CT 扫描图像的医学报告。他只能读旁边的文字说明,图片部分完全跳过。当你问"这个病人的肿瘤位置在哪儿",他一头雾水。
RAG-Anything 的做法是:先雇一个翻译官(VLM/GPT-4o)把每张 CT 图翻译成文字,翻译成这样的描述:“图3是一张轴向 CT 切片,在患者右肺下叶第7肋间隙处有一个约1.5cm×2cm的高密度结节,边缘不规则,疑似恶性…”。
然后这段文字被存入知识图谱,“高密度结节”、“右肺下叶”、"恶性"等关键词都成了图谱节点,并和"图3"这个实体通过 belongs_to 边连接。
当你再问"病人的肿瘤在哪儿",系统通过图谱路径找到"图3",检索出完整描述,再让翻译官直接"看"这张 CT 图给你解释——这就是 VLM 增强查询的精髓。
一句话总结:给每张图找一个专业翻译官,让图片的信息变成图谱中的知识,查询时再请翻译官直接"看图说话"。
类比二:跨模态关系图—— 想象一个超级笔记本的索引系统
你有一本超级厚的技术笔记本,里面有文字、表格、图表、公式。普通 RAG 给这个笔记本建的索引就像按关键词做的书页索引:查"ResNet",找到提到 ResNet 的所有页面。
RAG-Anything 建的是一个立体蜘蛛网索引:不仅知道 ResNet 在哪几页被提到,还知道第15页的性能对比表包含了 ResNet 的数据(belongs_to 关系),第23页的架构图展示了 ResNet 的结构,第8页的公式描述了 ResNet 的残差机制。
当你问"ResNet 的参数量是多少",系统不只看文字,而是沿着蜘蛛网找到那张包含 ResNet 参数量数据的表格,精准返回数字。这就是双图索引的威力。
降维打击与实战启发
Trick #1:模态实体化流水线——可直接复用到任何多模态 RAG 项目
这是 RAG-Anything 最核心的可复用范式:将非文本内容转化为带 belongs_to 关系的知识图谱实体。
# 可直接抄作业的核心逻辑:模态内容 → 实体 + chunk
async def process_any_modal_content(
modal_content: dict,
content_type: str, # "image" | "table" | "equation"
vlm_func, # 视觉/文本分析函数
lightrag_instance,
):
# Step 1: 用 VLM/LLM 生成结构化描述 (严格要求 JSON 输出)
prompt = build_prompt(content_type, modal_content)
raw_response = await vlm_func(prompt, image_data=encode_if_image(modal_content))
# Step 2: 多策略 JSON 解析 (防幻觉)
parsed = robust_json_parse(raw_response) # 4层fallback
description = parsed["detailed_description"]
entity_info = parsed["entity_info"] # {entity_name, entity_type, summary}
# Step 3: 构建标准化 chunk (让描述可被向量检索)
chunk_content = f"""
[{content_type.upper()}]
Path/Data: {modal_content.get('img_path', modal_content.get('table_body', ''))}
Caption: {modal_content.get('caption', 'None')}
AI Analysis: {description}
"""
chunk_id = compute_mdhash_id(chunk_content, prefix="chunk-")
await lightrag_instance.text_chunks.upsert({chunk_id: {"content": chunk_content, ...}})
await lightrag_instance.chunks_vdb.upsert({chunk_id: {"content": chunk_content, ...}})
# Step 4: 在知识图谱中创建实体节点
await lightrag_instance.chunk_entity_relation_graph.upsert_node(
entity_info["entity_name"],
{"entity_type": content_type, "description": entity_info["summary"], ...}
)
# Step 5: 从描述中提取子实体,建立 belongs_to 关系
sub_entities = await extract_entities_from_text(description, lightrag_instance)
for sub_entity in sub_entities:
await lightrag_instance.chunk_entity_relation_graph.upsert_edge(
sub_entity, entity_info["entity_name"],
{"keywords": "belongs_to", "weight": 10.0} # ← 高权重是关键!
)
Trick #2:VLM 增强查询的"先检索再看图"范式
这个两阶段设计可以推广到任何需要图像理解的 RAG 场景:
async def vlm_enhanced_rag_query(query: str, rag_instance, vlm_func):
"""
Phase 1: RAG 检索上下文 (不生成答案)
Phase 2: VLM 直接分析检索到的图片 + 上下文 → 最终回答
优势: 利用 RAG 的精准检索 + VLM 的视觉推理,两者互补
"""
# Phase 1: 只取 prompt,不生成答案 (LightRAG 专有参数)
raw_prompt = await rag_instance.aquery(
query,
param=QueryParam(mode="hybrid", only_need_prompt=True) # ← 关键:only_need_prompt=True
)
# Phase 2: 从 prompt 中提取图片路径
image_paths = re.findall(
r"Image Path:\s*([^\r\n]*?\.(?:jpg|jpeg|png|gif|bmp|webp|tiff|tif))",
raw_prompt
)
# Phase 3: 验证路径安全性 + base64 编码
images_b64 = []
for path in image_paths:
if is_safe_path(path) and Path(path).exists():
images_b64.append(encode_image_to_base64(path))
# Phase 4: 构建交错的图文消息
messages = build_interleaved_messages(raw_prompt, images_b64, query)
# Phase 5: 调用 VLM 最终回答
return await vlm_func("", messages=messages)
Trick #3:4 层 JSON 解析 + 思维链剥离(可复用到所有 LLM 结构化输出场景)
def robust_json_parse_with_thinking_strip(response: str) -> dict:
"""
通用鲁棒 JSON 解析器,可处理:
- DeepSeek-R1 / Qwen2.5 的 <think>...</think> 标签
- GPT 输出的中文引号 " "
- 尾随逗号
- LaTeX 公式中的反斜杠转义问题
"""
import re, json
# Step 0: 剥离推理模型的思维链标签
cleaned = re.sub(r'<think>.*?</think>', '', response, flags=re.DOTALL|re.IGNORECASE)
cleaned = re.sub(r'<thinking>.*?</thinking>', '', cleaned, flags=re.DOTALL|re.IGNORECASE)
cleaned = cleaned.strip()
# Step 1: 提取所有 JSON 候选(代码块、平衡括号、正则)
candidates = []
# 代码块内的 JSON
candidates.extend(re.findall(r'```(?:json)?\s*(\{.*?\})\s*```', cleaned, re.DOTALL))
# 平衡括号匹配
brace_count, start = 0, -1
for i, char in enumerate(cleaned):
if char == '{':
if brace_count == 0: start = i
brace_count += 1
elif char == '}':
brace_count -= 1
if brace_count == 0 and start != -1:
candidates.append(cleaned[start:i+1])
# Step 2-3: 对每个候选尝试直接解析 → 基础清洗 → 转义修复
for cand in candidates:
for process_func in [lambda x: x, basic_cleanup, progressive_quote_fix]:
try:
return json.loads(process_func(cand))
except (json.JSONDecodeError, ValueError):
continue
# Step 4: 正则提取关键字段(终极兜底)
return {
"detailed_description": extract_field(cleaned, "detailed_description") or cleaned[:500],
"entity_info": {
"entity_name": extract_field(cleaned, "entity_name") or "unknown_entity",
"entity_type": extract_field(cleaned, "entity_type") or "generic",
"summary": extract_field(cleaned, "summary") or cleaned[:100],
}
}
def basic_cleanup(s):
return re.sub(r',(\s*[}\]])', r'\1',
s.replace('"', '"').replace('"', '"')
.replace(''', "'").replace(''', "'"))
def progressive_quote_fix(s):
def fix(match):
content = re.sub(r'\\(?=[a-zA-Z])', r'\\\\', match.group(1))
return f'"{content}"'
return re.sub(r'"([^"]*(?:\\.[^"]*)*)"', fix, s)
def extract_field(text, field_name):
match = re.search(rf'"{field_name}":\s*"([^"]*(?:\\.[^"]*)*)"', text, re.DOTALL)
return match.group(1) if match else None
架构流程图
总结
RAG-Anything 的本质
用一句话概括:**RAG-Anything = **LightRAG (图-向量双索引 RAG) + 模态感知实体化 (VLM 翻译图表为图谱节点) + VLM 二阶段查询
它的核心贡献不在于发明了新的检索算法,而在于:
- 找到了一种将任意模态内容无缝纳入图 RAG 框架的方法(模态实体化 + belongs_to 边)
- 设计了查询阶段的图文还原机制(先 RAG 定位,再 VLM 直视原图)
- 提供了大量工程鲁棒性设计(缓存、并发控制、多层 JSON 解析、思维链剥离)
值得深挖的延伸方向
| 方向 | 现状 | 可改进点 |
|---|---|---|
| 视觉检索精度 | 文本嵌入代理视觉检索 | 引入 ColPali/CLIP 直接图像向量检索 |
| 公式理解深度 | LLM 文字描述公式 | 接入 Mathematica/SymPy 做符号计算验证 |
| 表格结构理解 | Markdown 表格 → 文字描述 | 引入 TabFact 类数值推理 |
| 跨文档实体合并 | 每文档独立实体 | 实体消解 (Entity Resolution) 跨文档融合 |
| 检索重排序 | 无显式 Reranker | 加入 BGE-Reranker 或 Cohere Rerank |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)