▲基于QLearning强化学习的认知雷达自适应波形选择算法matlab仿真
目录
1.引言
认知雷达是一种具有感知-学习-决策闭环能力的智能雷达系统。其核心思想是通过接收机对环境和目标回波进行感知,将感知结果反馈给发射机,由发射机智能地调整发射波形,从而实现对目标更精确的检测与跟踪。在该闭环中,自适应波形选择器是智能发射器的核心组成部分:它从预先设计好的波形库中,根据当前目标状态选择最优波形进行发射。
在实际雷达跟踪场景中,目标的散射特性(如雷达截面积RCS)会随时间变化,例如目标姿态改变、机动状态切换等均会导致RCS发生跃变。这种变化可用马尔可夫链进行建模,即目标在不同散射状态之间按照一定的转移概率进行切换。然而,目标状态的转移概率矩阵在实际中通常是未知的,这使得传统的基于模型的动态规划方法难以直接应用。
为此,本文将自适应波形选择问题建模为随机动态规划问题,并提出采用Q学习(Q-Learning)这一无模型强化学习方法来求解最优波形选择策略。Q学习不依赖于环境的转移概率模型,仅通过与环境的交互经验即可逐步学习到最优策略,天然适合目标转移概率未知的场景。
2.问题建模:马尔可夫决策过程
将自适应波形选择问题建模为一个马尔可夫决策过程,其四元组定义如下:
2.1 状态空间
将目标的散射特性离散化为𝑁𝑠个状态,状态空间为:
![]()
每个状态 𝑠𝑖对应一个特定的目标RCS值 𝜎𝑖 ,代表目标不同的散射强度。例如,低RCS状态对应目标正面照射角较小的情形,高RCS状态对应目标侧面或较大散射角的情形。
2.2 动作空间
雷达波形库中包含𝑁𝑎种候选波形,动作空间为:
![]()
每种波形具有不同的带宽 𝐵𝑗和脉冲宽度 𝜏𝑗,由此决定了不同的距离分辨力和信号能量。例如,窄带长脉冲波形具有较高的信号能量(有利于检测低RCS目标),而宽带短脉冲波形则具有更高的距离分辨力。
2.3 状态转移概率
目标状态的转移服从马尔可夫链,转移概率为
2.4 即时奖励函数
当目标处于状态𝑠、雷达选择波形𝑎时,即时奖励基于接收信号与目标脉冲响应之间的互信息来定义。对于高斯信道,互信息可表示为:
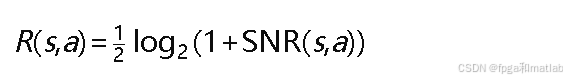
其中SNR(𝑠,𝑎)为目标在状态 𝑠下使用波形𝑎时的输出信噪比。根据雷达方程的简化形式,输出信噪比与目标RCS和波形参数相关:
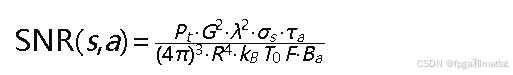
在实际设计中,还需综合考虑距离分辨力的收益。距离分辨力由带宽决定:
![]()
因此,综合奖励可设计为互信息与分辨力加权之和,以反映不同目标状态下对检测能力与分辨力的不同侧重。
2.5 优化目标
目标是寻找最优策略𝜋∗:𝑆→𝐴,使得长期累积折扣奖励最大化:
![]()
其中𝛾∈[0,1)为折扣因子,控制对未来奖励的重视程度。
3.Q学习算法原理
Q学习的核心是利用时序差分(TD)方法对Q表进行在线更新。在每个时间步𝑡,智能体处于状态𝑠𝑡,执行动作𝑎𝑡,获得即时奖励𝑟𝑡 ,并转移到新状态𝑠𝑡+1 ,Q值按如下规则更新:

4.MATLAB程序
...................................................................
figure('Position',[40 40 1440 960],'Color','w');
mu = mean(test_r,2); sd = std(test_r,0,2);
clr = [.2 .5 .9; .7 .7 .7; 1 .6 .2; .4 .8 .4; .9 .3 .3];
b = bar(mu,.6); b.FaceColor='flat';
for k=1:N_m, b.CData(k,:)=clr(k,:); end
hold on; errorbar(1:N_m,mu,sd,'k.','LineWidth',1.5);
set(gca,'XTickLabel',methods,'XTickLabelRotation',15,'FontSize',9);
ylabel('平均测试奖励'); title('(d) 各方法性能对比'); grid on; box on;% (e) 学习到的Q表热图
figure('Position',[40 40 1440 960],'Color','w');
imagesc(Q); colorbar; colormap(gca,parula);
xlabel('波形编号'); ylabel('目标状态');
title('(e) 学习到的Q表');
set(gca,'XTick',1:N_a,'YTick',1:N_s);
for i=1:N_s
for j=1:N_a
text(j,i,sprintf('%.1f',Q(i,j)),...
'HorizontalAlignment','center','FontSize',9,'FontWeight','bold');
end
end
%% ===================== 输出汇总 =====================
fprintf('\n========== 仿真结果汇总 ==========\n');
[~,learned_pol] = max(Q,[],2);
fprintf('学习策略: '); fprintf('WF%d ', learned_pol); fprintf('\n');
fprintf('真实最优策略: '); fprintf('WF%d ', true_opt); fprintf('\n');
fprintf('策略匹配率: %.1f%%\n', 100*mean(learned_pol==true_opt));
fprintf('\n--- 测试阶段平均奖励 ---\n');
for m=1:N_m
fprintf(' %-15s: %.3f ± %.3f\n', methods{m}, mu(m), sd(m));
end
fprintf('\nQ-Learning 相比 Random 提升: %.1f%%\n', 100*(mu(1)-mu(2))/mu(2));
fprintf('Q-Learning 相比 固定最优波形 提升: %.1f%%\n', 100*(mu(1)-mu(3))/mu(3));
fprintf('Q-Learning 相比 Round-Robin 提升: %.1f%%\n', 100*(mu(1)-mu(4))/mu(4));
5.仿真结果分析
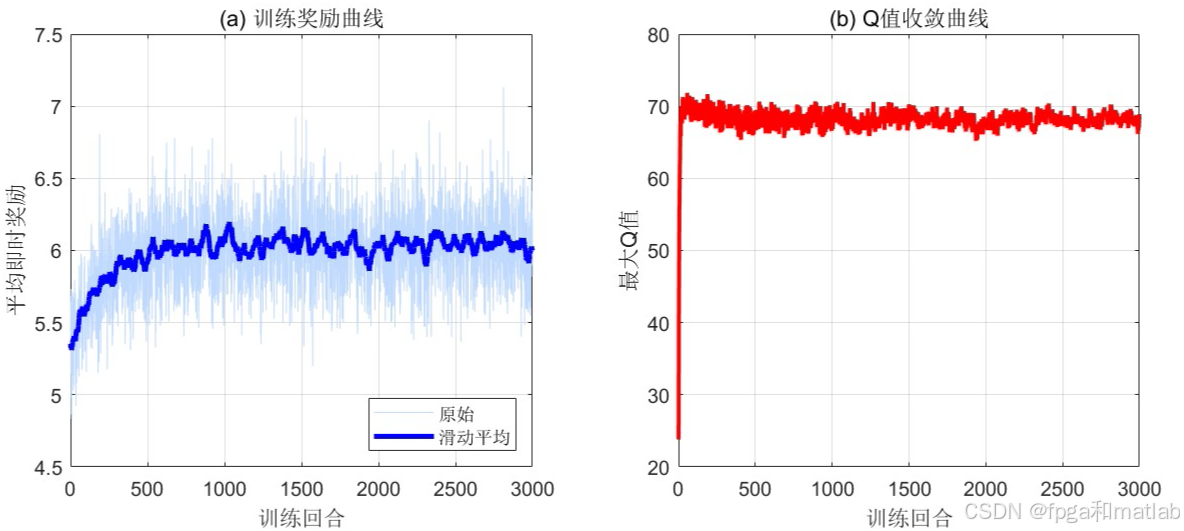
随回合数增加,平均奖励从低值逐步上升并趋于稳定 Q学习收敛,策略逐步优化
从初始约40%(随机水平)上升至80%以上 智能体已学会为不同状态选择正确波形。
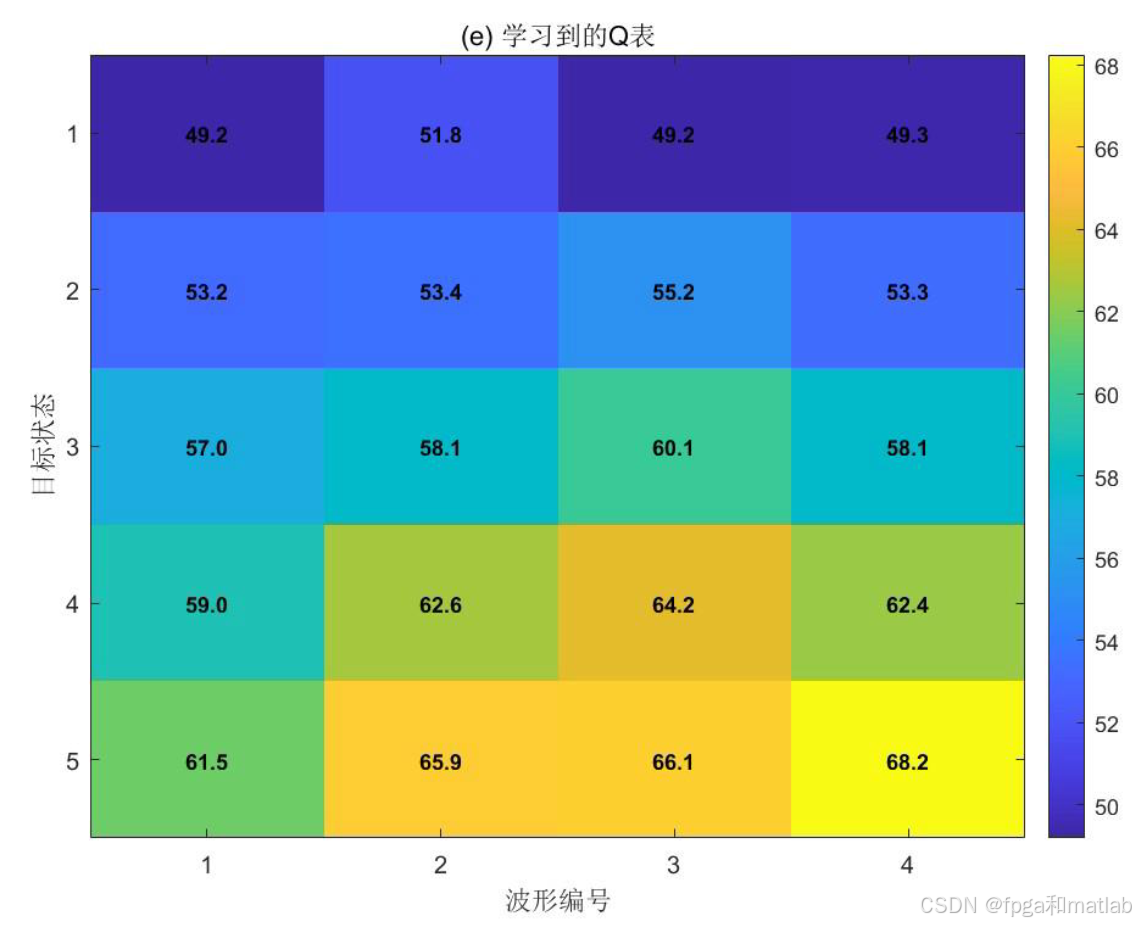
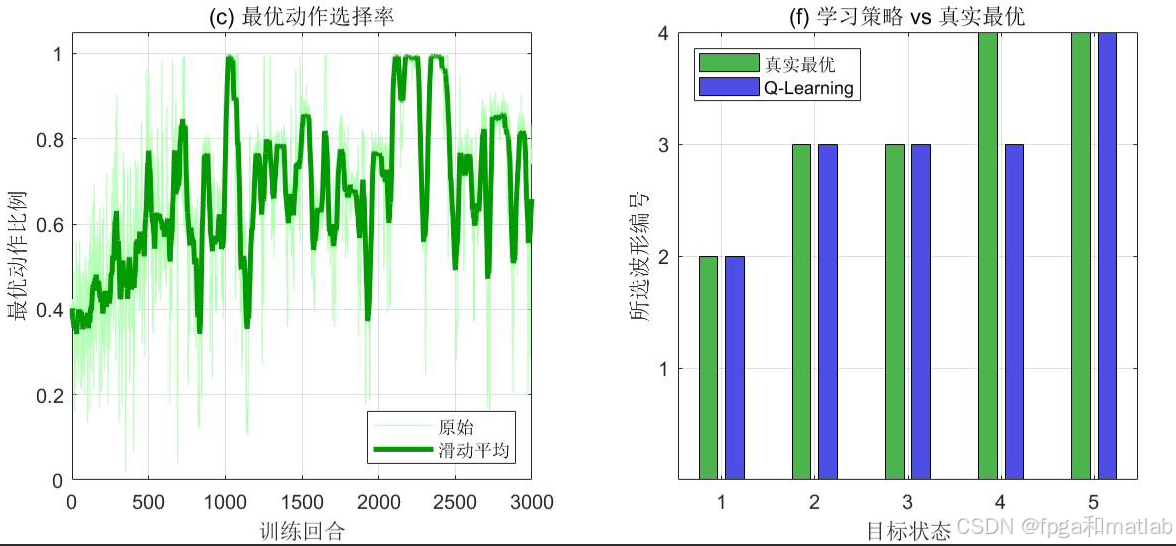
每行最大值位置对应学习到的最优波形 直观展示状态-波形映射关系。
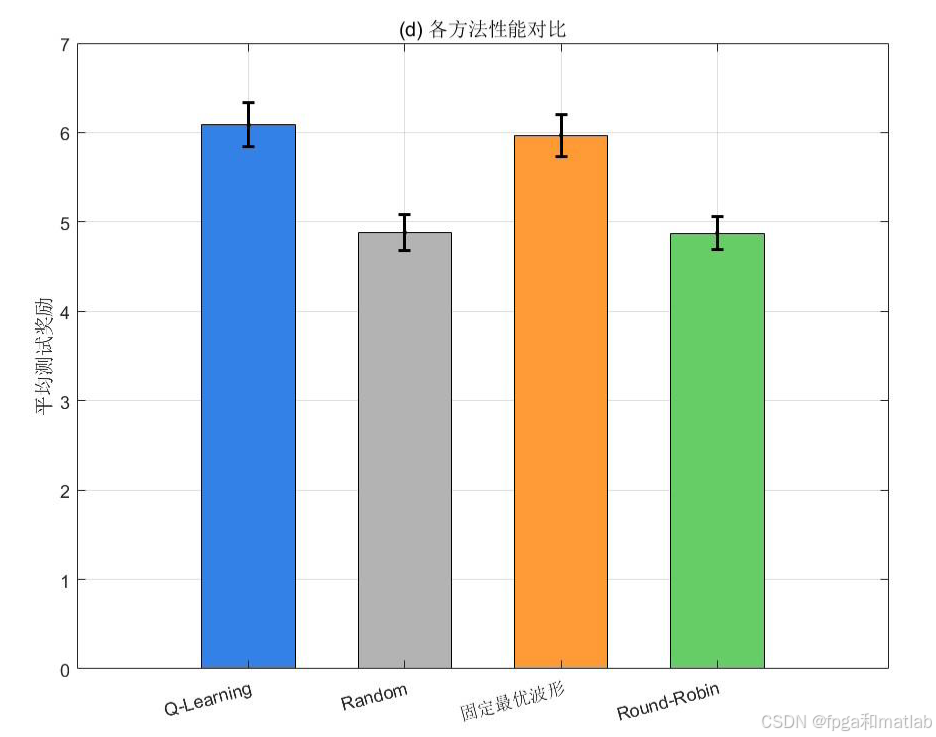
Q-Learning奖励显著优于Random、Fixed和Round-Robin。
5.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)