django基于python的中文起点网top500小说数据提取的设计与实现_12qz0syp
前言
在数字化时代,网络文学作为新兴的文化产业,正迅速崛起。特别是中文起点网,作为中国网络文学的代表,拥有庞大的用户群体和丰富的内容资源。然而,这些海量数据背后隐藏的用户阅读行为、内容偏好、市场趋势等信息,尚未得到充分的挖掘与分析。因此,开发一个基于Django和Python的中文起点网Top500小说数据提取系统显得尤为必要。该系统旨在通过构建一个集数据采集、深度 分析、可视化展示于一体的平台,解决现有工具的不足,实现数据的深度挖掘与直观展示,为作者提供创作指导,为编辑提供市场分析,为用户推荐个性化内容,从而推动网络文学产业的健康发展。
一、项目介绍
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库 :mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
二、功能介绍
Django基于Python的中文起点网Top500小说数据提取系统是一个利用Python语言和Django框架构建的,专注于中文起点网(如起点中文网)小说数据采集、存储、分析与可视化的平台。以下是对该系统的详细介绍:
一、系统背景与目标
在数字化时代,网络文学作为新兴的文化产业,正迅速崛起。特别是中文起点网,作为中国网络文学的代表,拥有庞大的用户群体和丰富的内容资源。然而,这些海量数据背后隐藏的用户阅读行为、内容偏好、市场趋势等信息,尚未得到充分的挖掘与分析。因此,开发一个基于Django和Python的中文起点网Top500小说数据提取系统显得尤为必要。该系统旨在通过构建一个集数据采集、深度分析、可视化展示于一体的平台,解决现有工具的不足,实现数据的深度挖掘与直观展示,为作者提供创作指导,为编辑提供市场分析,为用户推荐个性化内容,从而推动网络文学产业的健康发展。
二、系统架构与技术选型
后端框架:采用Django框架,利用其强大的数据库抽象层、路由管理和安全机制,简化Web应用的搭建和开发过程。
前端技术:结合Vue.js和ECharts等前端技术,实现数据的动态展示和交互式可视化。Vue.js用于构建用户界面,提供响应式数据绑定和组件化开发能力;ECharts则用于生成各种图表,如柱状图、折线图、饼图等,直观展示数据分析结果。
数据库:选择MySQL作为数据存储和管理工具,利用其高性能、可靠性和易扩展性,确保数据的完整性和可查询性。
爬虫 技术:利用Python编写的爬虫程序,定向抓取中文起点网的小说数据,包括小说标题、作者、分类、章节内容、字数、更新时间、读者评分、评论等信息。
三、系统功能
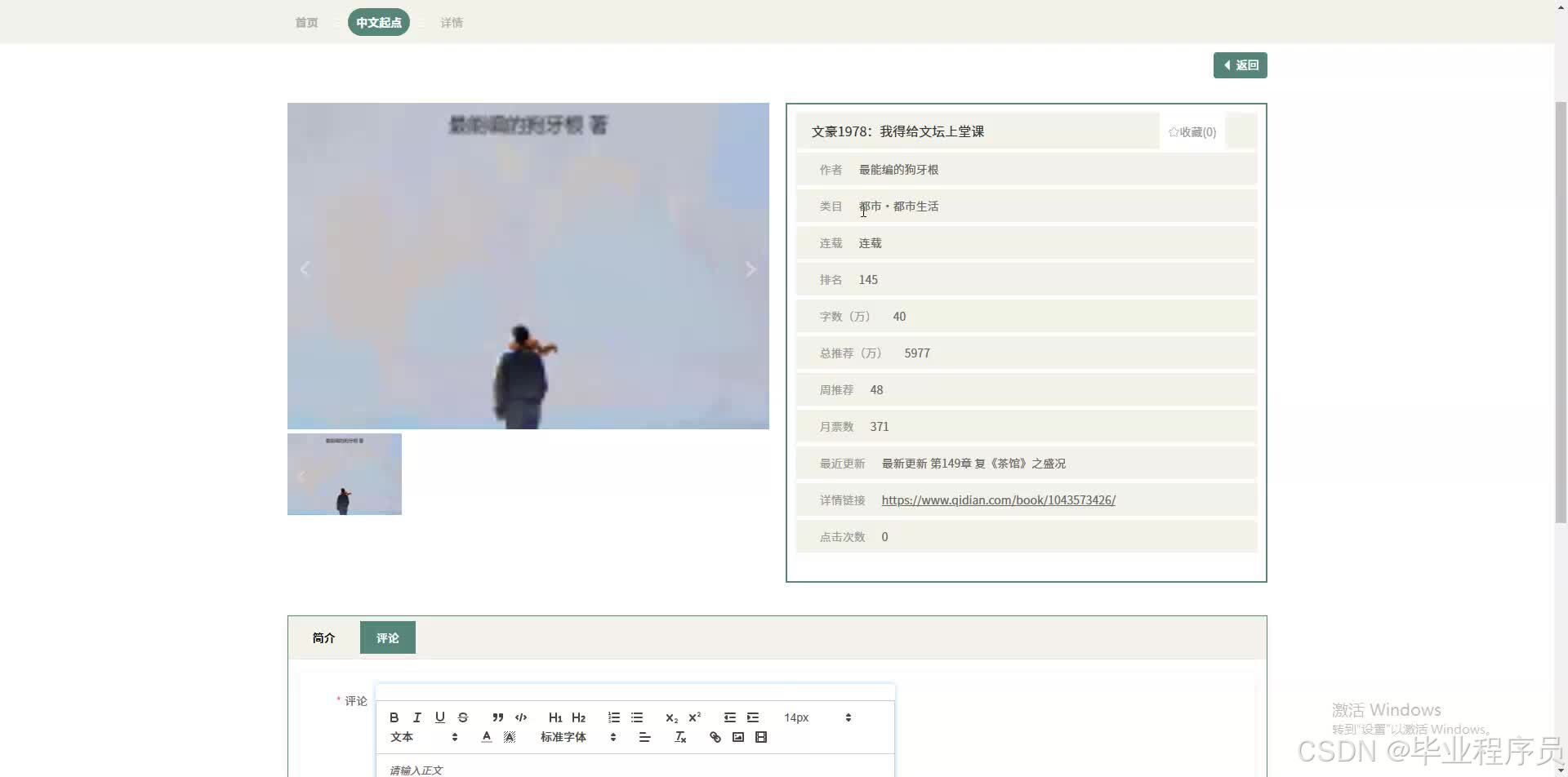
数据采集模块:通过爬虫技术,从中文起点网抓取Top500小说的相关数据,并进行初步清洗和整理。
数据存储模块:将采集到的数据存储到MySQL数据库中,设计合理的数据库结构,确保数据的完整性和可查询性。
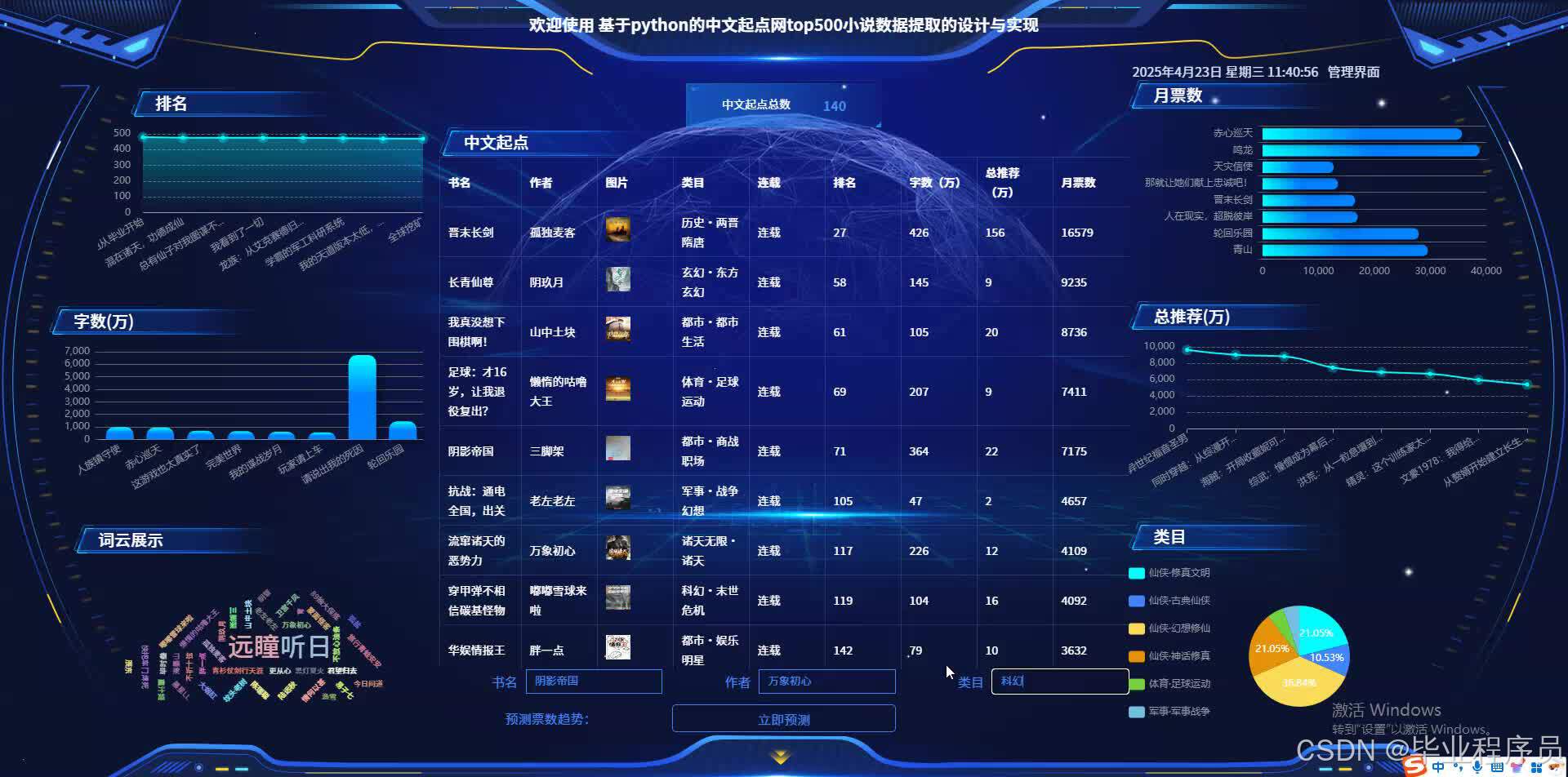
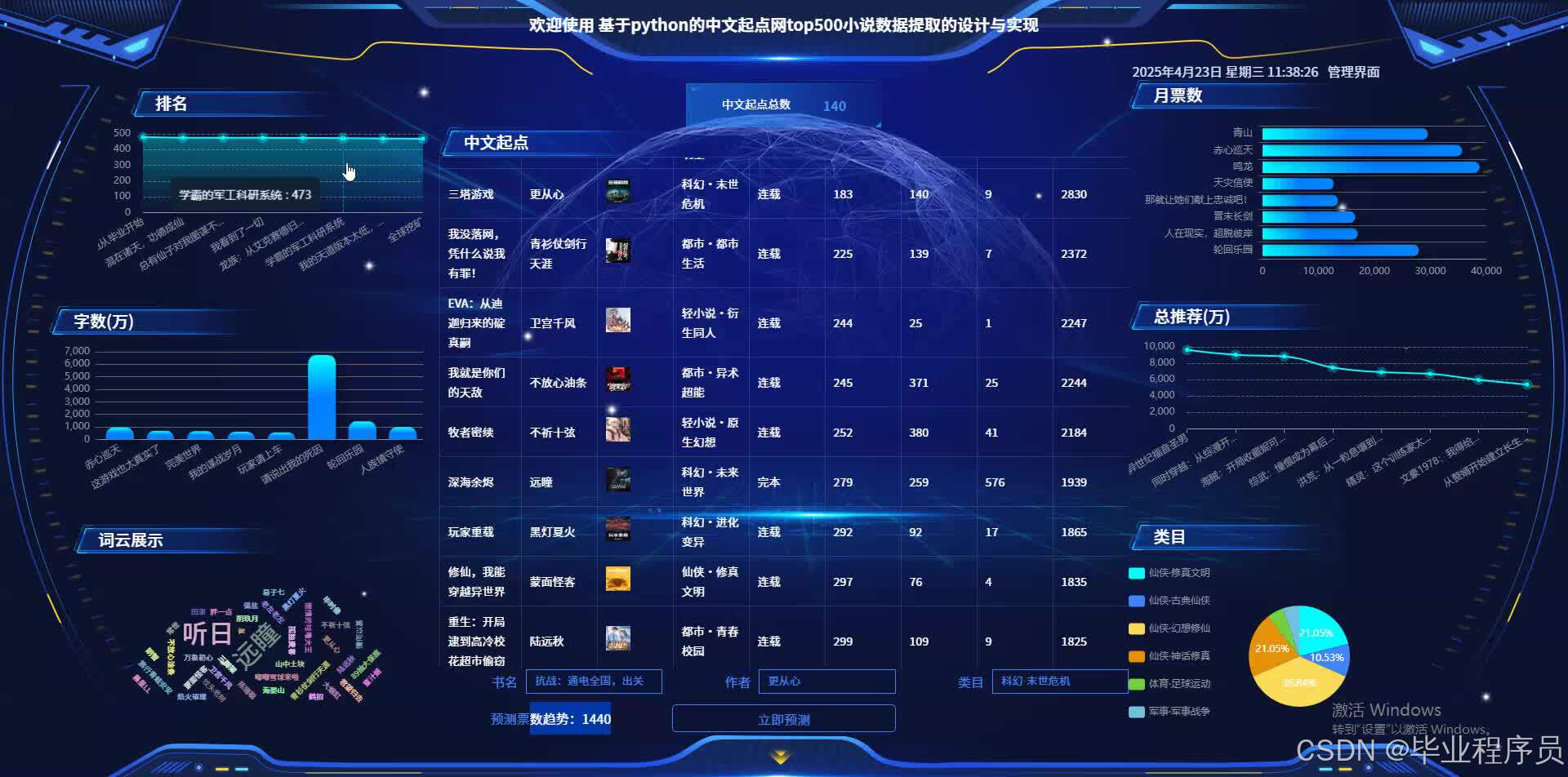
数据分析模块:从多个角度对小说数据进行分析,包括内容分析(如不同类型小说的热门元素)、读者反馈分析(如读者评分与评论)、小说传播分析(如更新时间与读者增长的关系)等。
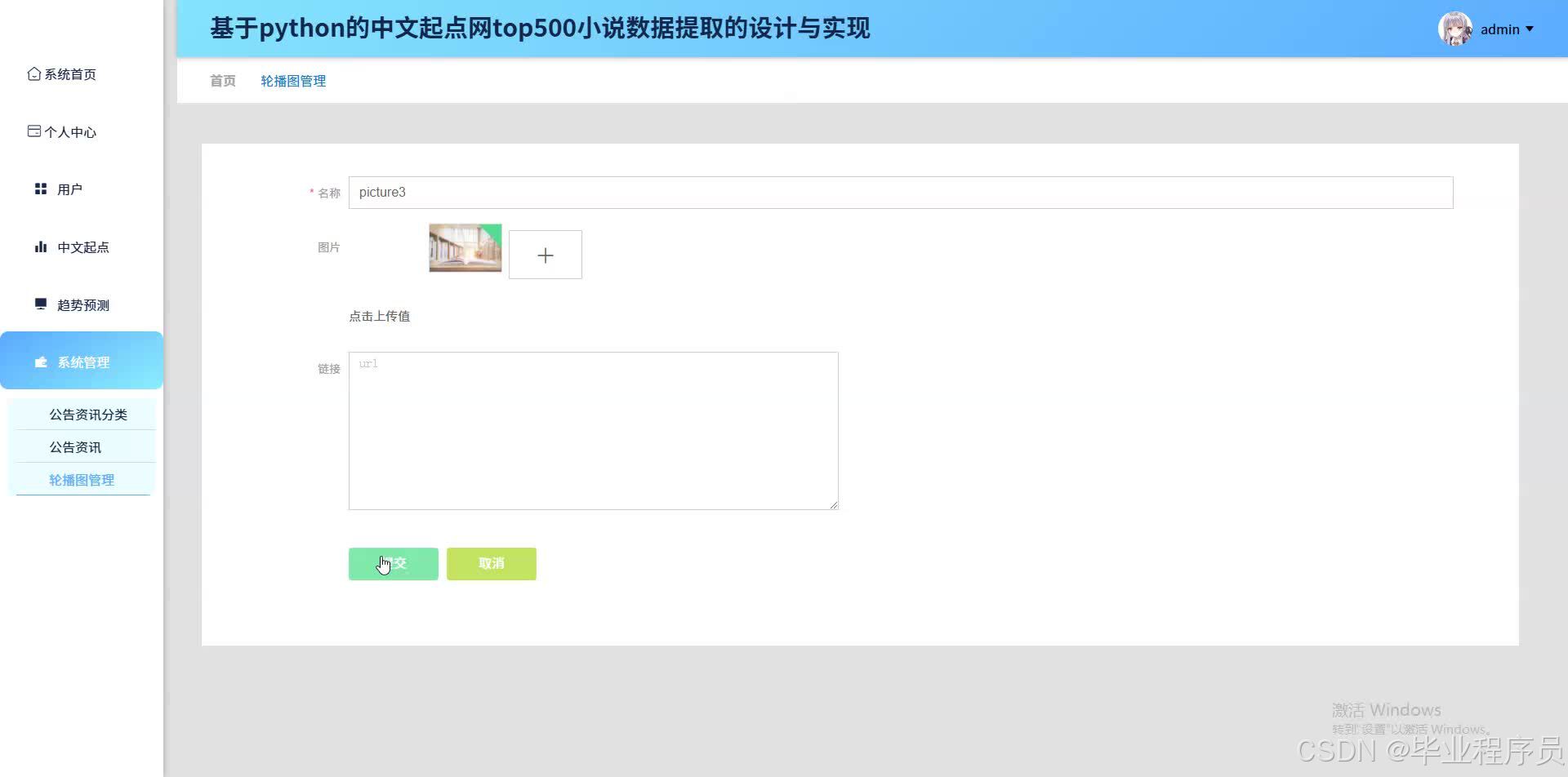
可视化展示模块:利用ECharts等前端技术,将数据分析结果以图表形式直观展示,包括用户活跃度曲线、热门题材分布图、小说评分变化趋势图等,便于决策者快速把握市场动态。
四、系统优势与创新点
定制化分析:针对网络文学行业的特点,提供定制化的数据分析服务,满足行业特定的分析需求。
精准的数据模型:利用先进的自然语言处理技术和机器学习算法,构建精准的数据分析模型,深入挖掘用户行为和市场趋势。
直观的可视化效果:通过ECharts等前端技术,生成各种直观、交互式的图表,提高数据展示的效果和用户体验。
高效的数据采集与处理:利用Python编写的爬虫程序和Django框架的高效数据处理能力,实现数据的快速采集和实时更新。
三、核心代码
部分代码:
四、效果图

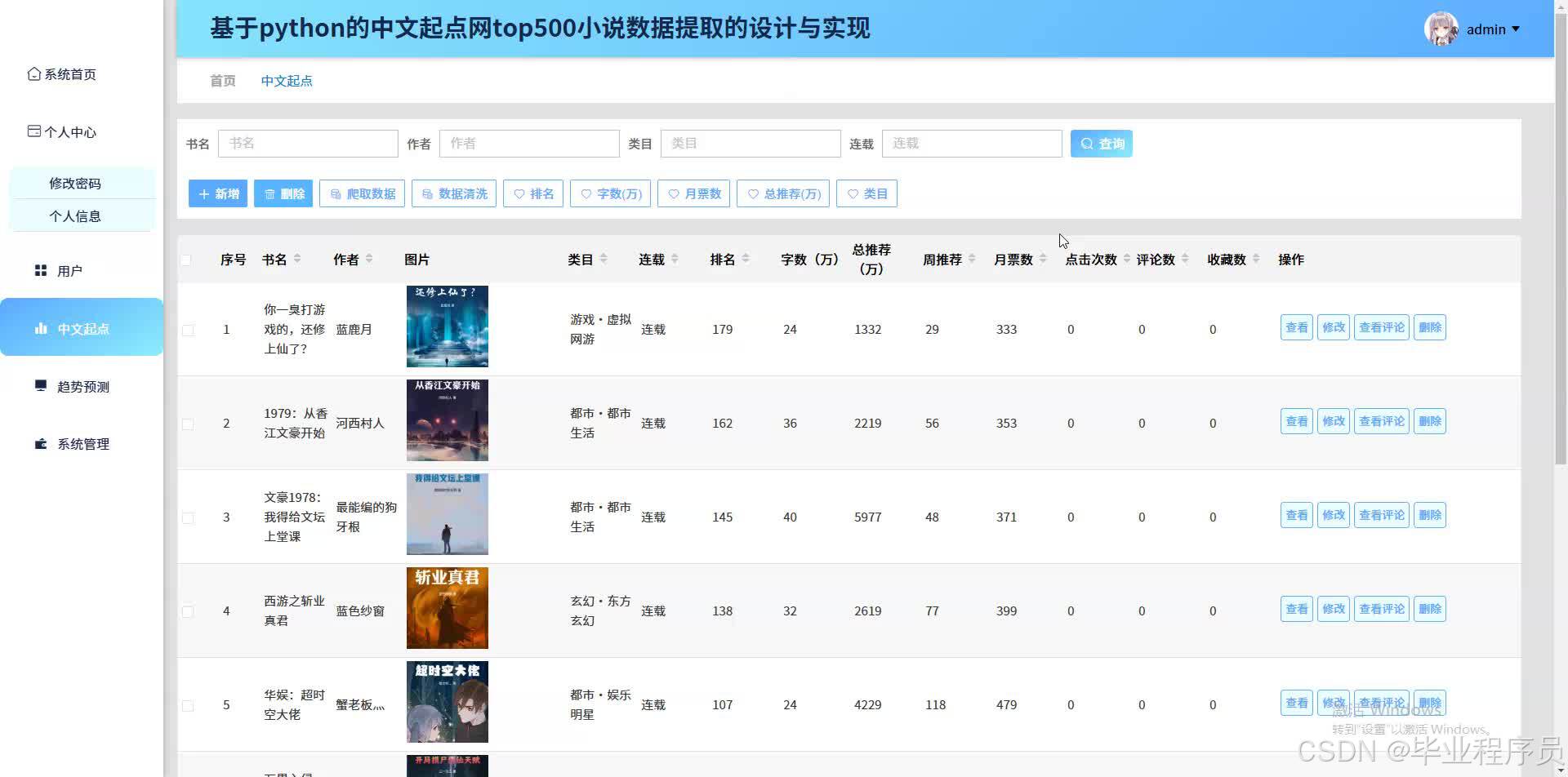

源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)